第 04 章_逻辑架构
第 04 章_逻辑架构
1. 逻辑架构剖析
1. 1 服务器处理客户端请求
那服务器进程对客户端进程发送的请求做了什么处理,才能产生最后的处理结果呢?这里以查询请求为
例展示:
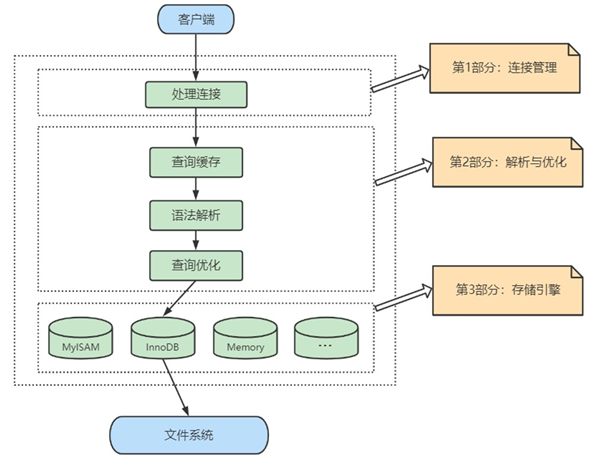
下面具体展开看一下:
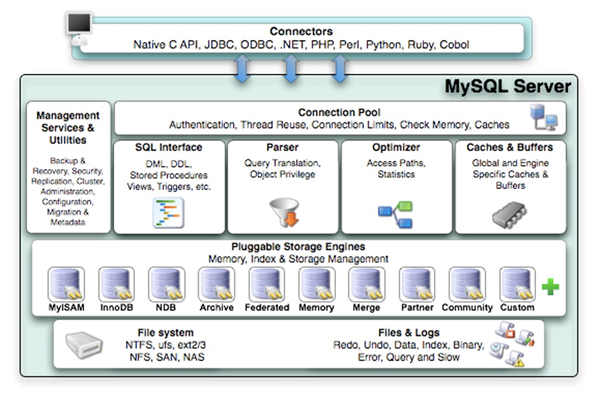
1.2 Connectors
1.3 第 1 层:连接层
系统(客户端)访问MySQL服务器前,做的第一件事就是建立TCP连接。
经过三次握手建立连接成功后,MySQL服务器对TCP传输过来的账号密码做身份认证、权限获取。
- 用户名或密码不对,会收到一个Access denied for user错误,客户端程序结束执行
- 用户名密码认证通过,会从权限表查出账号拥有的权限与连接关联,之后的权限判断逻辑,都将依
赖于此时读到的权限
TCP连接收到请求后,必须要分配给一个线程专门与这个客户端的交互。所以还会有个线程池,去走后
面的流程。每一个连接从线程池中获取线程,省去了创建和销毁线程的开销。
1.4 第 2 层:服务层
- SQL Interface: SQL接口
- 接收用户的SQL命令,并且返回用户需要查询的结果。比如SELECT … FROM就是调用SQL
Interface - MySQL支持DML(数据操作语言)、DDL(数据定义语言)、存储过程、视图、触发器、自定
义函数等多种SQL语言接口
- 接收用户的SQL命令,并且返回用户需要查询的结果。比如SELECT … FROM就是调用SQL
- Parser: 解析器
- 在解析器中对 SQL 语句进行语法分析、语义分析。将SQL语句分解成数据结构,并将这个结构
传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的。如果在分解构成中遇到错
误,那么就说明这个SQL语句是不合理的。 - 在SQL命令传递到解析器的时候会被解析器验证和解析,并为其创建语法树,并根据数据字
典丰富查询语法树,会验证该客户端是否具有执行该查询的权限。创建好语法树后,MySQL还
会对SQl查询进行语法上的优化,进行查询重写。
- 在解析器中对 SQL 语句进行语法分析、语义分析。将SQL语句分解成数据结构,并将这个结构
- Optimizer: 查询优化器
- SQL语句在语法解析之后、查询之前会使用查询优化器确定 SQL 语句的执行路径,生成一个执行计划。
- 这个执行计划表明应该使用哪些索引进行查询(全表检索还是使用索引检索),表之间的连接顺序如何,最后会按照执行计划中的步骤调用存储引擎提供的方法来真正的执行查询,并将查询结果返回给用户。
- 它使用“选取-投影-连接”策略进行查询。例如:
这个SELECT查询先根据WHERE语句进行选取,而不是将表全部查询出来以后再进行gender过
滤。 这个SELECT查询先根据id和name进行属性投影,而不是将属性全部取出以后再进行过
滤,将这两个查询条件连接起来生成最终查询结果。
Caches & Buffers: 查询缓存组件
MySQL内部维持着一些Cache和Buffer,比如Query Cache用来缓存一条SELECT语句的执行结
果,如果能够在其中找到对应的查询结果,那么就不必再进行查询解析、优化和执行的整个过
程了,直接将结果反馈给客户端。
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等 。
这个查询缓存可以在不同客户端之间共享。
从MySQL 5.7.20开始,不推荐使用查询缓存,并在MySQL 8.0中删除。
1. 5 第 3 层:引擎层
插件式存储引擎层( Storage Engines), 真正的负责了MySQL中数据的存储和提取,对物理服务器级别
维护的底层数据执行操作 ,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样
我们可以根据自己的实际需要进行选取。
MySQL 8.0.25默认支持的存储引擎如下:
1. 6 存储层
所有的数据,数据库、表的定义,表的每一行的内容,索引,都是存在文件系统上,以文件的方式存
在的,并完成与存储引擎的交互。当然有些存储引擎比如InnoDB,也支持不使用文件系统直接管理裸设
备,但现代文件系统的实现使得这样做没有必要了。在文件系统之下,可以使用本地磁盘,可以使用
DAS、NAS、SAN等各种存储系统。
SELECT id,name FROM student WHERE gender = '女';
小故事:
如果我问你9+8×16-3×2×17的值是多少,你可能会用计算器去算一下,最终结果 35 。如果再问你一遍9+8×16-
3×2×17的值是多少,你还用再傻呵呵的再算一遍吗?我们刚刚已经算过了,直接说答案就好了。
1. 7 小结
MySQL架构图本节开篇所示。下面为了熟悉SQL执行流程方便,我们可以简化如下:
简化为三层结构:
1. 连接层:客户端和服务器端建立连接,客户端发送 SQL 至服务器端;
2. SQL 层(服务层):对 SQL 语句进行查询处理;与数据库文件的存储方式无关;
3. 存储引擎层:与数据库文件打交道,负责数据的存储和读取。
2. SQL执行流程
2. 1 MySQL 中的 SQL执行流程
MySQL的查询流程:
1. 查询缓存 :Server 如果在查询缓存中发现了这条 SQL 语句,就会直接将结果返回给客户端;如果没
有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在 MySQL8.0 之后就抛弃
了这个功能。
大多数情况查询缓存就是个鸡肋,为什么呢?
查询缓存是提前把查询结果缓存起来,这样下次不需要执行就可以直接拿到结果。需要说明的是,在
MySQL 中的查询缓存,不是缓存查询计划,而是查询对应的结果。这就意味着查询匹配的鲁棒性大大降
低,只有相同的查询操作才会命中查询缓存。两个查询请求在任何字符上的不同(例如:空格、注释、
大小写),都会导致缓存不会命中。因此 MySQL 的查询缓存命中率不高。
同时,如果查询请求中包含某些系统函数、用户自定义变量和函数、一些系统表,如 mysql 、
information_schema、 performance_schema 数据库中的表,那这个请求就不会被缓存。以某些系统函数
举例,可能同样的函数的两次调用会产生不一样的结果,比如函数NOW,每次调用都会产生最新的当前
时间,如果在一个查询请求中调用了这个函数,那即使查询请求的文本信息都一样,那不同时间的两次
查询也应该得到不同的结果,如果在第一次查询时就缓存了,那第二次查询的时候直接使用第一次查询
的结果就是错误的!
此外,既然是缓存,那就有它缓存失效的时候。MySQL的缓存系统会监测涉及到的每张表,只要该表的
结构或者数据被修改,如对该表使用了INSERT、 UPDATE、DELETE、TRUNCATE TABLE、ALTER
TABLE、DROP TABLE或 DROP DATABASE语句,那使用该表的所有高速缓存查询都将变为无效并从高
速缓存中删除!对于更新压力大的数据库来说,查询缓存的命中率会非常低。
2. 解析器 :在解析器中对 SQL 语句进行语法分析、语义分析。
分析器先做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面
的字符串分别是什么,代表什么。 MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语
句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。
SELECT employee_id,last_name FROM employees WHERE employee_id = 101;
接着,要做“语法分析”。根据词法分析的结果,语法分析器(比如:Bison)会根据语法规则,判断你输
入的这个 SQL 语句是否满足 MySQL 语法。
select department_id,job_id,avg(salary) from employees group by department_id;
如果SQL语句正确,则会生成一个这样的语法树:
在查询优化器中,可以分为逻辑查询优化阶段和物理查询优化阶段。
4. 执行器 :
截止到现在,还没有真正去读写真实的表,仅仅只是产出了一个执行计划。于是就进入了执行器阶段。
select * from test 1 join test 2 using(ID)
where test 1 .name='zhangwei' and test 2 .name='mysql高级课程';
方案 1 :可以先从表 test 1 里面取出 name='zhangwei'的记录的 ID 值,再根据 ID 值关联到表 test 2 ,再判
断 test 2 里面 name的值是否等于 'mysql高级课程'。
方案 2 :可以先从表 test 2 里面取出 name='mysql高级课程' 的记录的 ID 值,再根据 ID 值关联到 test 1 ,
再判断 test 1 里面 name的值是否等于 zhangwei。
这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。优化
器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段。
如果你还有一些疑问,比如优化器是怎么选择索引的,有没有可能选择错等。后面讲到索引我们再谈。
下面是Sql词法分析的过程步骤:
3.优化器 :在优化器中会确定SQL语句的执行路径,比如是根据全表检索,还是根据索引检索等。
举例:如下语句是执行两个表的join:
在执行之前需要判断该用户是否具备权限。如果没有,就会返回权限错误。如果具备权限,就执行 SQL
查询并返回结果。在 MySQL8.0 以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
比如:表 test 中,ID 字段没有索引,那么执行器的执行流程是这样的:
至此,这个语句就执行完成了。对于有索引的表,执行的逻辑也差不多。
SQL 语句在 MySQL 中的流程是:SQL语句→查询缓存→解析器→优化器→执行器。
select * from test where id= 1 ;
调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 1 ,如果不是则跳过,如果是则将这行存在结果集中;
调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
2. 2 MySQL 8 中SQL执行原理
1. 确认profiling 是否开启
profiling=0 代表关闭,我们需要把 profiling 打开,即设置为 1 :
2. 多次执行相同SQL查询
然后我们执行一个 SQL 查询(你可以执行任何一个 SQL 查询):
3. 查看profiles
查看当前会话所产生的所有 profiles:
mysql> select @@profiling;
mysql> show variables like 'profiling';
mysql> set profiling= 1 ;
mysql> select * from employees;
mysql> show profiles; # 显示最近的几次查询
4. 查看profile
显示执行计划,查看程序的执行步骤:
当然你也可以查询指定的 Query ID,比如:
查询 SQL 的执行时间结果和上面是一样的。
此外,还可以查询更丰富的内容:
继续:
mysql> show profile;
mysql> show profile for query 7 ;
mysql> show profile cpu,block io for query 6 ;
mysql> show profile cpu,block io for query 7 ;
2. 3 MySQL 5. 7 中SQL执行原理
上述操作在MySQL5.7中测试,发现前后两次相同的sql语句,执行的查询过程仍然是相同的。不是会使用
缓存吗?这里我们需要显式开启查询缓存模式。在MySQL5.7中如下设置:
1. 配置文件中开启查询缓存
在 /etc/my.cnf 中新增一行:
2. 重启mysql服务
3. 开启查询执行计划
由于重启过服务,需要重新执行如下指令,开启profiling。
4. 执行语句两次:
5. 查看profiles
query_cache_type= 1
systemctl restart mysqld
mysql> set profiling= 1 ;
mysql> select * from locations;
mysql> select * from locations;
6. 查看profile
显示执行计划,查看程序的执行步骤:
mysql> show profile for query 1 ;
mysql> show profile for query 2 ;
结论不言而喻。执行编号 2 时,比执行编号 1 时少了很多信息,从截图中可以看出查询语句直接从缓存中
获取数据。
2.4 SQL语法顺序
随着Mysql版本的更新换代,其优化器也在不断的升级,优化器会分析不同执行顺序产生的性能消耗不同
而动态调整执行顺序。
需求:查询每个部门年龄高于 20 岁的人数且高于 20 岁人数不能少于 2 人,显示人数最多的第一名部门信息
下面是经常出现的查询顺序:
2.5 Oracle中的SQL执行流程(了解)
Oracle 中采用了共享池来判断 SQL 语句是否存在缓存和执行计划,通过这一步骤我们可以知道应该采用
硬解析还是软解析。
我们先来看下 SQL 在 Oracle 中的执行过程:
从上面这张图中可以看出,SQL 语句在 Oracle 中经历了以下的几个步骤。
1 .语法检查: 检查 SQL 拼写是否正确,如果不正确,Oracle 会报语法错误。
2 .语义检查: 检查 SQL 中的访问对象是否存在。比如我们在写 SELECT 语句的时候,列名写错了,系统
就会提示错误。语法检查和语义检查的作用是保证 SQL 语句没有错误。
3 .权限检查: 看用户是否具备访问该数据的权限。
4.共享池检查: 共享池(Shared Pool)是一块内存池, 最主要的作用是缓存 SQL 语句和该语句的执行计
划。 Oracle 通过检查共享池是否存在 SQL 语句的执行计划,来判断进行软解析,还是硬解析。那软解析
和硬解析又该怎么理解呢?
在共享池中,Oracle 首先对 SQL 语句进行 Hash 运算,然后根据 Hash 值在库缓存(Library Cache)中
查找,如果存在 SQL 语句的执行计划,就直接拿来执行,直接进入“执行器”的环节,这就是软解析。
如果没有找到 SQL 语句和执行计划,Oracle 就需要创建解析树进行解析,生成执行计划,进入“优化器”
这个步骤,这就是硬解析。
5. 优化器:优化器中就是要进行硬解析,也就是决定怎么做,比如创建解析树,生成执行计划。
6. 执行器:当有了解析树和执行计划之后,就知道了 SQL 该怎么被执行,这样就可以在执行器中执
行语句了。
共享池是 Oracle 中的术语,包括了库缓存,数据字典缓冲区等。我们上面已经讲到了库缓存区,它主要
缓存 SQL 语句和执行计划。而数据字典缓冲区存储的是 Oracle 中的对象定义,比如表、视图、索引等对
象。当对 SQL 语句进行解析的时候,如果需要相关的数据,会从数据字典缓冲区中提取。
库缓存这一个步骤,决定了 SQL 语句是否需要进行硬解析。为了提升 SQL 的执行效率,我们应该尽量
避免硬解析,因为在 SQL 的执行过程中,创建解析树,生成执行计划是很消耗资源的。
你可能会问,如何避免硬解析,尽量使用软解析呢?在 Oracle 中,绑定变量是它的一大特色。绑定变量
就是在 SQL 语句中使用变量,通过不同的变量取值来改变 SQL 的执行结果。这样做的好处是能提升软解
析的可能性,不足之处在于可能会导致生成的执行计划不够优化,因此是否需要绑定变量还需要视情况
而定。
举个例子,我们可以使用下面的查询语句:
你也可以使用绑定变量,如:
这两个查询语句的效率在 Oracle 中是完全不同的。如果你在查询 player_id = 10001 之后,还会查询
10002 、 10003 之类的数据,那么每一次查询都会创建一个新的查询解析。而第二种方式使用了绑定变
量,那么在第一次查询之后,在共享池中就会存在这类查询的执行计划,也就是软解析。
因此, 我们可以通过使用绑定变量来减少硬解析,减少 Oracle 的解析工作量。 但是这种方式也有缺点,
使用动态 SQL 的方式,因为参数不同,会导致 SQL 的执行效率不同,同时 SQL 优化也会比较困难。
Oracle的架构图:
SQL> select * from player where player_id = 10001 ;
SQL> select * from player where player_id = :player_id;
简图:
小结:
Oracle 和 MySQL 在进行 SQL 的查询上面有软件实现层面的差异。Oracle 提出了共享池的概念,通过共享
池来判断是进行软解析,还是硬解析。
3. 数据库缓冲池(buffer pool)
了解了缓冲池的作用之后,我们还需要了解缓冲池的另一个特性:预读。
缓冲池的作用就是提升I/o效率,而我们进行读取数据的时候存在一个“局部性原理”,也就是说我们使用了一些数
据,大概率还会使用它周围的一些数据,因此采用“预读”的机制提前加载,可以减少未来可能的磁盘I/О操作。
InnoDB存储引擎是以页为单位来管理存储空间的,我们进行的增删改查操作其实本质上都是在访问页
面(包括读页面、写页面、创建新页面等操作)。而磁盘 I/O 需要消耗的时间很多,而在内存中进行操
作,效率则会高很多,为了能让数据表或者索引中的数据随时被我们所用,DBMS 会申请占用内存来作为
数据缓冲池,在真正访问页面之前,需要把在磁盘上的页缓存到内存中的Buffer Pool之后才可以访
问。
这样做的好处是可以让磁盘活动最小化,从而减少与磁盘直接进行 I/O 的时间。要知道,这种策略对提
升 SQL 语句的查询性能来说至关重要。如果索引的数据在缓冲池里,那么访问的成本就会降低很多。
3. 1 缓冲池 vs 查询缓存
缓冲池和查询缓存是一个东西吗?不是。
1. 缓冲池(Buffer Pool)
首先我们需要了解在 InnoDB 存储引擎中,缓冲池都包括了哪些。
在 InnoDB 存储引擎中有一部分数据会放到内存中,缓冲池则占了这部分内存的大部分,它用来存储各种
数据的缓存,如下图所示:
从图中,你能看到 InnoDB 缓冲池包括了数据页、索引页、插入缓冲、锁信息、自适应 Hash 和数据字典
信息等。
缓存池的重要性:
缓存原则:
“位置 * 频次”这个原则,可以帮我们对 I/O 访问效率进行优化。
首先,位置决定效率,提供缓冲池就是为了在内存中可以直接访问数据。
其次,频次决定优先级顺序。因为缓冲池的大小是有限的,比如磁盘有 200 G,但是内存只有 16 G,缓冲
池大小只有 1 G,就无法将所有数据都加载到缓冲池里,这时就涉及到优先级顺序,会优先对使用频次高
的热数据进行加载。
缓冲池的预读特性:
了解了缓冲池的作用之后,我们还需要了解缓冲池的另一个特性:预读。
缓冲池的作用就是提升I/O效率,而我们进行读取数据的时候存在一个“局部性原理”,也就是说我们使
用了一些数据,大概率还会使用它周围的一些数据,因此采用“预读”的机制提前加载,可以减少未来
可能的磁盘I/О操作。
2. 查询缓存
那么什么是查询缓存呢?
查询缓存是提前把查询结果缓存起来,这样下次不需要执行就可以直接拿到结果。需要说明的是,在
MySQL 中的查询缓存,不是缓存查询计划,而是查询对应的结果。因为命中条件苛刻,而且只要数据表
发生变化,查询缓存就会失效,因此命中率低。
3. 2 缓冲池如何读取数据
缓冲池管理器会尽量将经常使用的数据保存起来,在数据库进行页面读操作的时候,首先会判断该页面
是否在缓冲池中,如果存在就直接读取,如果不存在,就会通过内存或磁盘将页面存放到缓冲池中再进
行读取。
缓存在数据库中的结构和作用如下图所示:
如果我们执行 SQL 语句的时候更新了缓存池中的数据,那么这些数据会马上同步到磁盘上吗?
3. 3 查看/设置缓冲池的大小
如果你使用的是 InnoDB 存储引擎,可以通过查看 innodb_buffer_pool_size 变量来查看缓冲池的大
小。命令如下:
你能看到此时 InnoDB 的缓冲池大小只有 134217728 / 1024 / 1024 = 128 MB。我们可以修改缓冲池大小,比如
改为 256 MB,方法如下:
show variables like 'innodb_buffer_pool_size';
set global innodb_buffer_pool_size = 268435456 ;
或者:
然后再来看下修改后的缓冲池大小,此时已成功修改成了 256 MB:
3.4 多个Buffer Pool实例
这样就表明我们要创建 2 个Buffer Pool实例。
我们看下如何查看缓冲池的个数,使用命令:
那每个Buffer Pool实例实际占多少内存空间呢?其实使用这个公式算出来的:
也就是总共的大小除以实例的个数,结果就是每个Buffer Pool实例占用的大小。
3.5 引申问题
Buffer Pool是MySQL内存结构中十分核心的一个组成,你可以先把它想象成一个黑盒子。
黑盒下的更新数据流程
[server]
innodb_buffer_pool_size = 268435456
[server]
innodb_buffer_pool_instances = 2
show variables like 'innodb_buffer_pool_instances';
innodb_buffer_pool_size/innodb_buffer_pool_instances
我更新到一半突然发生错误了,想要回滚到更新之前的版本,该怎么办?连数据持久化的保证、事务回
滚都做不到还谈什么崩溃恢复?
答案: Redo Log & Undo Log
相关文章:
第 04 章_逻辑架构
第 04 章_逻辑架构 1. 逻辑架构剖析 1. 1 服务器处理客户端请求 那服务器进程对客户端进程发送的请求做了什么处理,才能产生最后的处理结果呢?这里以查询请求为 例展示: 下面具体展开看一下: 1.2 Connectors 1.3 第 1 层&…...

免费API接口资源推荐
企业基本信息(含联系方式):通过公司名称/公司ID/注册号或社会统一信用代码获取企业基本信息和企业联系方式,包括公司名称或ID、类型、成立日期、电话、邮箱、网址等字段的详细信息。企业投资:获取企业对外投资信息,对外投资信息包…...
--miniz - 简易zlib压缩)
LuatOS-SOC接口文档(air780E)--miniz - 简易zlib压缩
示例 -- 准备好数据 local bigdata "123jfoiq4hlkfjbnasdilfhuqwo;hfashfp9qw38hrfaios;hfiuoaghfluaeisw" -- 压缩之, 压缩得到的数据是zlib兼容的,其他语言可通过zlib相关的库进行解压 local cdata miniz.compress(bigdata) -- lua 的 字符串相当于有长度的cha…...

一整套智慧工地源码,劳务实名制、施工安全管理、绿色施工、危大工程设备监测、视频AI识别功能
智慧工地系统充分利用计算机技术、互联网、物联网、云计算、大数据等新一代信息技术,以PC端,移动端,设备端三位一体的管控方式为企业现场工程管理提供了先进的技术手段。让劳务、设备、物料、安全、环境、能源、资料、计划、质量、视频监控等…...
世微 DC-DC平均电流双路降压恒流驱动器 LED车灯AP2813
产品描述 AP2813 是一款双路降压恒流驱动器,高效率、外 围简单、内置功率管,适用于 5-80V 输入的高精度降 压 LED 恒流驱动芯片。内置功率管输出最大功率可达 12W,最大电流 1.2A。 AP2813 一路直亮,另外一路通过 MODE1 切换 全亮,…...

ES6~ES13新特性(一)
文章目录 一、ES6中对象的增强1.字面量的增强2.解构Destructuring3.解构的应用场景 二、手写实现apply、call、bind方法1.apply、call方法2.bind方法 三、ECMA新描述概念1.新的ECMA代码执行描述2.词法环境(Lexical Environments)3.词法环境和变量环境4.环…...
基于 Amazon EC2 和 Amazon Systems Manager Session Manager 的堡垒机的设计和自动化实现
文章目录 1. 背景2. 云上堡垒机设计2.1 安全设计2.2 高可用和弹性设计2.3 监控告警设计2.4 自动化部署设计2.4.1 堡垒机代码设计2.4.2 Session Manager 配置设计2.4.3 堡垒机 IAM 角色设计 3. 部署堡垒机3.1 堡垒机部署架构图3.2 堡垒机自动化部署 4. 堡垒机使用场景4.1 堡垒机…...

RFID管理方案有效提升电力物资管理效率与资产安全
在电力行业,电力资产的管理是一项重要的任务,为了实现对电力资产的精细化管理、入出库监控管理、盘点管理和巡查管理等,电力公司多采用电力资产RFID管理系统,该系统能够实时监控出入库过程,有效防止出入库错误…...

leetcode:389. 找不同
一、题目 函数原型:char findTheDifference(char * s, char * t) 二、思路 作者原先的思路是先将两个字符串从小到大排序,然后两个字符串依次比较。若出现字符串t中的元素和字符串s不相等,则说明该元素就是被添加的字母。 但是,该…...

c 函数调用过程中,调用函数的栈帧一旦被修改,被调用函数则无法正确返回。( X )
当一个函数被调用时,它的栈帧会被创建并压入调用栈中。栈帧包含了函数的局部变量、参数以及返回地址等信息。当函数执行完毕后,栈帧会被弹出,返回到调用函数的位置继续执行。 下面是一个示例代码,展示了调用函数栈帧被修改但不影…...
专为个人打造专注工作的便签APP工具推荐哪个
工作中很多人都比较懒散,工作起来动力不足,常常拖延消极怠工,等到一天结束后进行工作盘点时才发现很多项任务都没有处理完;这和日常工作不能专注于工作有很大的关系。 专注工作,在日常办公时可以选择一些好用的手机便…...

代码随想录算法训练营第四十二天 | LeetCode 1049. 最后一块石头的重量 II、494. 目标和、474. 一和零
代码随想录算法训练营第四十二天 | LeetCode 1049. 最后一块石头的重量 II、494. 目标和、474. 一和零 文章链接:最后一块石头的重量 II 目标和 一和零 视频链接:最后一块石头的重量 II 目标和 一和零 1. LeetCode 1049. 最后一块石头的重量 II 1.1 思路…...

Windows PowerShell 和 Linux BashShell 极简对比
声明:本文不会涉及原理,详细的介绍,也不是入门文章。仅仅从使用上进行简单比较 命令 在 bash 中,一个命令是一个单独的进程;而在 PowerShell 中,命令被称为 cmdlets,他们不是独立的可执行程序&…...

校验验证码是否过期(定时刷新验证码)
需求: 我们在登录的时候会遇到通过接口请求验证码的操作,这里的验证码会有过期的时间,当我们验证码过期了,我们要进行重新刷新验证码。 我们这里根据后端返回的当前时间和过期时间判断,过期的时间超过了当前时间的时候…...

windows idea本地执行spark sql避坑
本地安装了IDEA,并配置好了相关POM,可以在本机使用sparkSession连接数据,并在数据库执行sql,在idea展示执行结果。 但是,如果将数据的查询结果建立到spark中,再展示,就会报错 Error while run…...
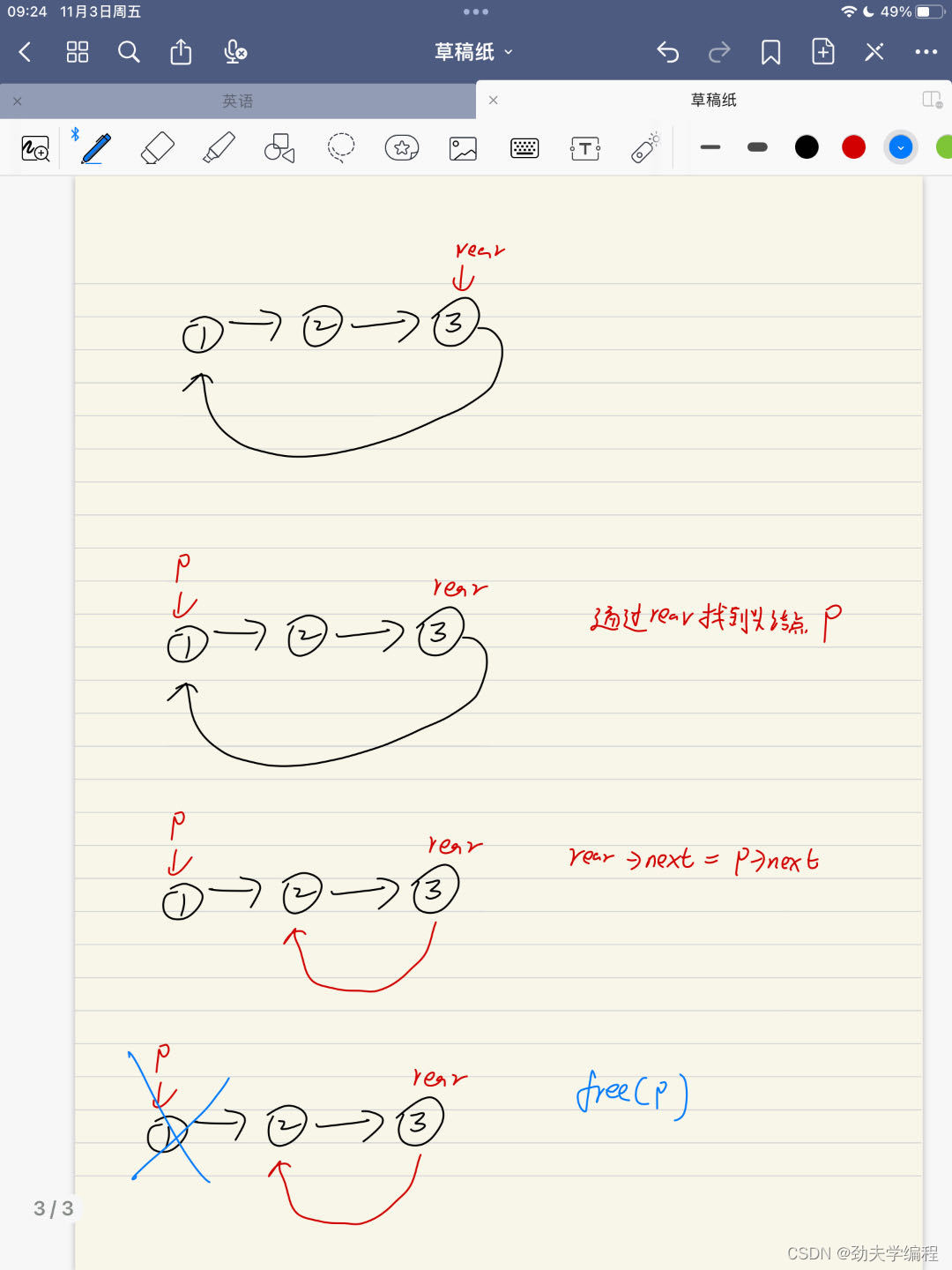
在一个循环链队中只有尾指针(记为rear,结点结构为数据域data,指针域next),请给出这种队列的入队和出队操作实现过程
在一个循环链队中只有尾指针(记为rear,结点结构为数据域data,指针域next),请给出这种队列的入队和出队操作实现过程 入队过程如下图: 先创一个结点,用于存储要插入的结点数据 然后就是老套路了…...

智能客服系统应用什么技术?
随着科技的飞速发展,智能客服系统逐渐出现在我们的生活中。这些系统不仅能够提供即时的客户服务,还可以通过人工智能等技术实现更加高效和准确的服务。那么,智能客服系统究竟应用了哪些技术呢?本文将详细解析。 1、机器学习技术 …...

亚马逊、美客多卖家测评:如何建立养号团队实现运营化式测评?
大家好,我是跨境电商测评养号7年从事经验的珑哥。养号环境软件开发,深度解决各跨境平台矩阵养号防关联、砍单、F号问题。关注珑哥解决更多跨境养号测评问题。 测评,相信这个词对于大部分跨境卖家来说,想必都不陌生,因…...

苹果IOS系统webglcontextlost问题-解决方案
问题描述 在IOS手机 解码视频流的时候,第一次可以正常播放,但只要IOS手机熄屏,再重新唤醒,就会一直播放失败,无论换哪个浏览器都不行。安卓手机则一切正常。 经过排查,发现 IOS手机 的浏览器会无故 webGL…...

供应链ERP之合同:创建、修订与模板
本人详解 作者:王文峰,参加过 CSDN 2020年度博客之星,《Java王大师王天师》 公众号:JAVA开发王大师,专注于天道酬勤的 Java 开发问题中国国学、传统文化和代码爱好者的程序人生,期待你的关注和支持!本人外号:神秘小峯 山峯 转载说明:务必注明来源(注明:作者:王文峰…...

终极指南:如何用天津大学LaTeX论文模板彻底告别格式烦恼
终极指南:如何用天津大学LaTeX论文模板彻底告别格式烦恼 【免费下载链接】TJUThesisLatexTemplate LaTeX templates for TJU graduate thesis. Originally forked from code.google.com/p/tjuthesis 项目地址: https://gitcode.com/gh_mirrors/tj/TJUThesisLatexT…...

HC7251晨芯阳科技内置MOS开关降压型LED恒流驱动器
HC7251是一款内置60V功率MOS 高效率、高精度的开关降压型大功率LED 恒流驱动芯片。HC7251采用固定关断时间的峰值电流控制方式,关断时间可通过外部电容进行调节,工作频率可根据用户要求而改变。HC7251通过调节外置的电流采样电阻,能控制高亮度…...

深入解析RoboMaster电机数据包:从CAN原始字节到速度、角度、电流的转换全流程
深入解析RoboMaster电机数据包:从CAN原始字节到速度、角度、电流的转换全流程 在机器人竞赛和工业控制领域,CAN总线通信因其高可靠性和实时性成为电机控制的黄金标准。大疆RoboMaster系列电机通过CAN协议传递的8字节数据包,就像一串精心设计的…...
)
告别手动配置!用Matlab+LUA脚本自动化DCA1000雷达数据采集(附1843配置实例)
雷达数据采集自动化:Matlab与LUA脚本的高效协作方案 在毫米波雷达研发领域,数据采集是每个工程师日常工作中不可或缺的环节。传统的手动配置方式不仅耗时耗力,还容易因人为操作失误导致数据质量不稳定。本文将介绍如何通过Matlab与LUA脚本的协…...
到底怎么配?)
别再搞混了!SAP物料主数据、BOM、工艺路线里的三种损耗率(Scrap)到底怎么配?
SAP三大损耗率配置实战指南:从物料主数据到工艺路线的精准决策 在SAP PP模块实施过程中,物料损耗率的配置往往成为顾问团队争论的焦点。我曾参与过一个汽车零部件制造项目,由于初期对三种损耗率的理解偏差,导致MRP运算结果与实际情…...

介绍一种免费使用小米 MiMo-V2.5-pro模型的方法
1. MiMo-V2.5-Pro是什么? MiMo-V2.5-Pro 是一个拥有 1.02 万亿参数的混合专家模型,其中包含 420 亿个激活参数,基于混合注意力架构构建,上下文窗口长度达 100 万 token。其通用智能体能力、复杂软件工程能力和长周期任务处理能力…...

如何用四探针精确测量半导体电阻率
在半导体行业中,准确测量晶圆电阻率是材料研发和制程质量控制的关键环节。随着工艺节点不断缩小,器件对电性一致性的要求日益严格,仅靠经验无法满足现代制造的需求。因此工程师们大量采用四探针方法对电阻率进行高精度测量。相比传统测量方式…...
)
OriginPro 2023 相关性热图插件 CorrelationPlot 保姆级安装与配置指南(附资源下载)
OriginPro 2023 CorrelationPlot插件全流程配置指南:从零基础到高效科研可视化 科研数据处理中,相关性热图(Correlation Plot)是揭示变量间关联强度的利器。对于非编程背景的研究者而言,OriginPro的CorrelationPlot插件…...

CANN/hcomm集群信息初始化API
HcclCommInitClusterInfo 【免费下载链接】hcomm HCOMM(Huawei Communication)是HCCL的通信基础库,提供通信域以及通信资源的管理能力。 项目地址: https://gitcode.com/cann/hcomm 产品支持情况 Ascend 950PR/Ascend 950DT࿱…...

Bifrost:跨平台三星固件下载神器,解锁设备管理的全新境界
Bifrost:跨平台三星固件下载神器,解锁设备管理的全新境界 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 你是否曾为寻找三星官方固件而烦…...