如何使用Scrapy提取和处理数据
目录
一、安装和设置Scrapy
二、创建爬虫
三、提取数据
四、处理数据
五、存储数据
六、进阶操作
七、注意事项
总结
Scrapy是一个强大且灵活的Python库,用于创建网页爬虫,提取和处理数据。本文将为您深入讲解如何使用Scrapy进行数据处理,包含具体的代码示例和逻辑解释。

一、安装和设置Scrapy
在开始使用Scrapy之前,你需要先将其安装到你的Python环境中。这通常可以通过pip命令完成:
pip install scrapy安装完成后,你可以通过命令行工具创建一个新的Scrapy项目:
scrapy startproject myproject二、创建爬虫
在Scrapy中,爬虫是一个用于从网站抓取数据的类。你可以通过命令行工具创建一个新的爬虫:
cd myproject
scrapy genspider example example.com这将在你的项目中创建一个名为“example”的新爬虫,该爬虫会爬取example.com网站。
三、提取数据
在Scrapy中,数据提取通常通过使用XPath或CSS选择器定位并提取HTML文档中的元素。例如,假设我们要提取一个网页中所有的文章标题,我们可以在爬虫的parse方法中这样做:
def parse(self, response): for title in response.xpath('//h2/text()').getall(): yield {'title': title}在这个例子中,xpath('//h2/text()')会返回一个包含所有h2元素文本的列表,然后我们通过yield语句将每个标题作为一个字典返回。
四、处理数据
提取数据后,你可能需要进行一些处理,例如清洗、转换或存储数据。Scrapy提供了许多内置的方法来处理这些数据。例如,你可以使用Python的内置函数来处理数据:
def parse(self, response): for title in response.xpath('//h2/text()').getall(): cleaned_title = title.strip() # 去除标题前后的空格 yield {'title': cleaned_title}你也可以在Scrapy中使用更复杂的数据处理流程,例如使用正则表达式进行匹配,或者使用Python的日期和时间模块处理日期和时间数据。
五、存储数据
Scrapy提供了多种方式来存储提取的数据,包括CSV、JSON、XML等。最常见的方式是将数据保存到CSV或JSON文件中。例如,要将数据保存为CSV文件,你可以执行以下命令:
scrapy crawl example -o items.csv要将数据保存为JSON文件,你可以执行:
scrapy crawl example -o items.json六、进阶操作
至此,你已经了解了如何使用Scrapy提取、处理和存储数据的基本流程。然而,Scrapy的功能远不止于此。
例如,你可以使用Scrapy的中间件来处理请求和响应,或者使用管道来处理和存储提取的数据。你还可以使用Scrapy的内置支持来处理ajax请求、登录表单以及cookie和session处理等等。这些功能使得Scrapy成为一个强大而灵活的数据抓取和处理工具。
七、注意事项
在使用Scrapy进行数据提取和处理时,有一些注意事项需要牢记:
- 遵守网站的使用条款和机器人协议:在爬取网站数据时,必须遵守网站的使用条款和机器人协议(robots.txt)。否则,可能会导致IP被封禁或者面临法律风险。
- 限制爬取速率:为了避免对目标网站服务器造成过大压力,需要限制爬虫的爬取速率。Scrapy提供了自动限速的设置,也可以在代码中自定义速率。
- 深度限制:为了避免爬虫进入无限循环或者爬取无关页面,需要设置爬取的深度限制。这样可以让爬虫在达到一定深度后停止爬取。
- 错误处理:网络爬取过程中可能会遇到各种错误,如网络中断、超时等。Scrapy提供了异常处理机制,可以定制化的处理这些错误,保证爬虫的稳定性。
- 数据清洗和处理:在提取数据后,一般需要进行数据清洗和处理,以便于后续的分析和使用。需要根据实际的数据情况进行适当的处理,例如去除HTML标签、处理特殊字符等。
- 存储方式选择:在选择存储方式时,需要根据实际需求选择适当的存储方式。例如,如果需要后续进行大数据分析,可以选择存储为CSV或JSON格式。
总的来说,Scrapy是一个强大的工具,但也需要在使用时注意遵守规则,同时根据实际情况进行适当的优化和调整,这样才能更好地发挥它的作用。
总结
Scrapy是一个功能强大的Python爬虫框架,它提供了一套完整的解决方案来抓取、处理和存储网页数据。通过理解和掌握Scrapy的这些基本功能,你可以有效地抓取和处理任何网站的数据,满足你的数据处理需求。
相关文章:
如何使用Scrapy提取和处理数据
目录 一、安装和设置Scrapy 二、创建爬虫 三、提取数据 四、处理数据 五、存储数据 六、进阶操作 七、注意事项 总结 Scrapy是一个强大且灵活的Python库,用于创建网页爬虫,提取和处理数据。本文将为您深入讲解如何使用Scrapy进行数据处理&#x…...

拟合与过拟合
拟合跟过拟合 过拟合:将泛化误差分解为偏差跟方差 偏差:学习者不断学习相同错误事物的倾向 方差:学习随机信号而不考虑真实情况的趋势 过拟合:所建的机器学习模型或者深度学习模型在训练样本中表现得过于优越,导致测试数据集表现…...

科学化决策数据分析,先从量化开始
在当今信息爆炸的时代,数据已经成为我们生活和工作中不可或缺的一部分。在各行各业,人们越来越依赖数据来指导决策和优化业务。在这个背景下,量化成为了一种重要的方法论,通过收集、分析和解读数据,为我们提供了更准确…...
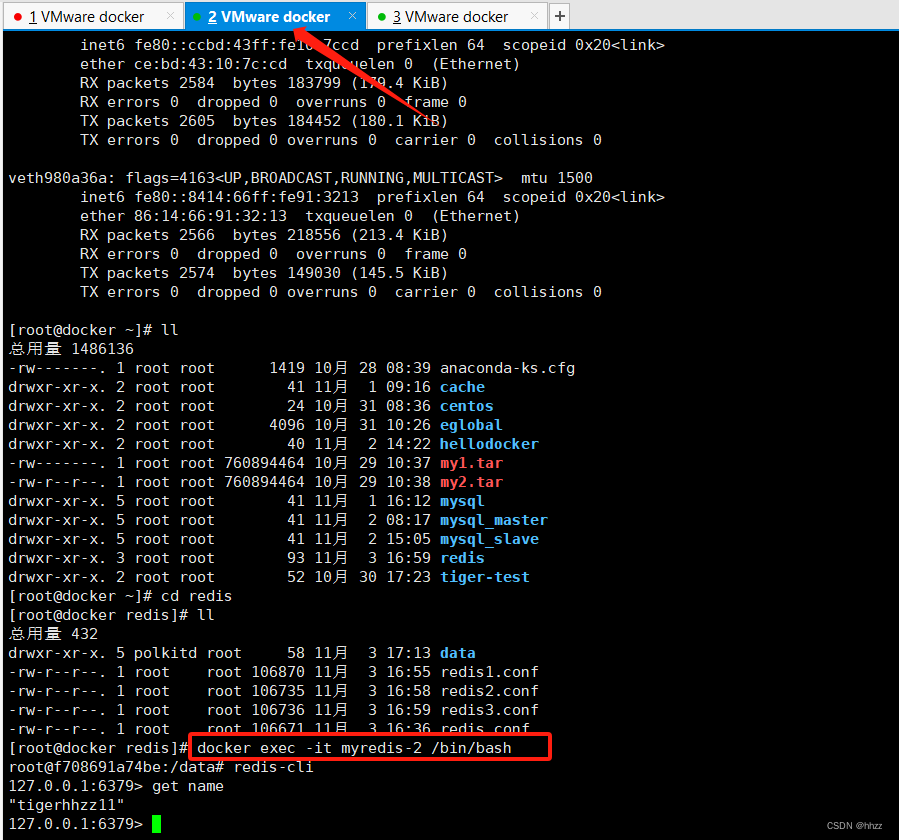
使用Docker搭建一个“一主两从”的 Redis 集群(超详细步骤)
目录 1、Redis 单机版安装1.1 拉取 Redis1.2 创建数据卷目录1.3 修改 redis.conf1.4 启动 Redis 容器1.5 进入容器连接 Redis 2、Redis 一主两从集群搭建2.1 复制三份 redis.conf2.2 启动 master2.3 启动 两个redis slave2.4 三者关系查看2.5 数据测试 1、Redis 单机版安装 1.…...
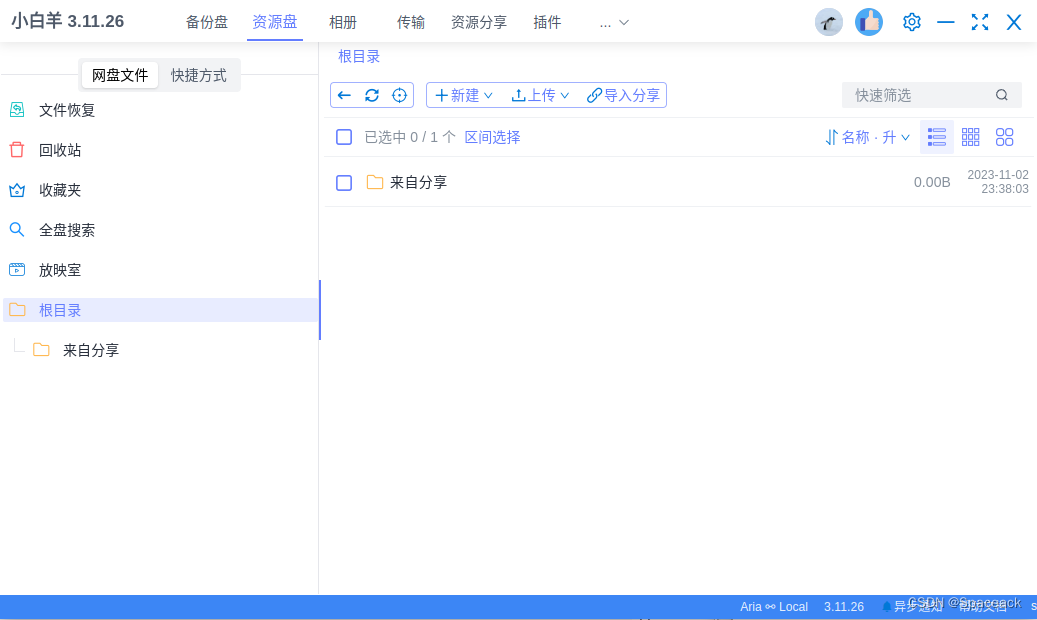
阿里云盘第三方linux客户端“小白羊”云盘“Aria2本地连接已断开”错误的解决方法
简介 随着数据的不断增长,我们需要更大的存储空间来保存我们的信息。阿里云盘是阿里巴巴推出的一款云存储服务,它提供了大量可扩展的存储空间。然而,阿里云盘官方没有提供Linux操作系统的客户端。 在这种情况下,“小白羊”云盘…...
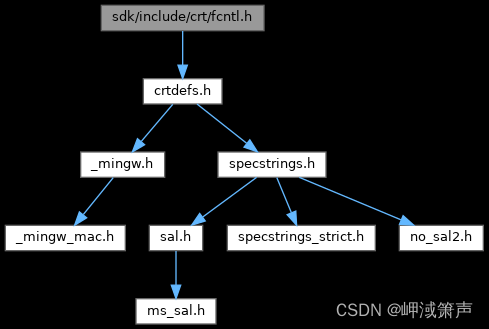
Linux flock和fcntl函数详解
文章目录 flock函数描述返回值和错误码笔记 fcntl函数描述复制文件描述符文件描述标志文件状态标志 咨询锁强制锁管理信号租赁文件和目录变更通知改变管道容量 返回值错误备注遗留问题 flock函数 主要功能是在已打开的文件应用或者删除共享锁或者独占锁。sys/file.h声明了这个…...

React 组件点击事件
点击事件 点击事件方式1、传统类方法(不推荐)2、传统类方法 16.3.0 - 自动绑定(不推荐)3、箭头函数3.1、类组件3.2、函数组件3.3、内联箭头函数 4、useState Hook 点击事件方式 1、传统类方法(不推荐) 当…...
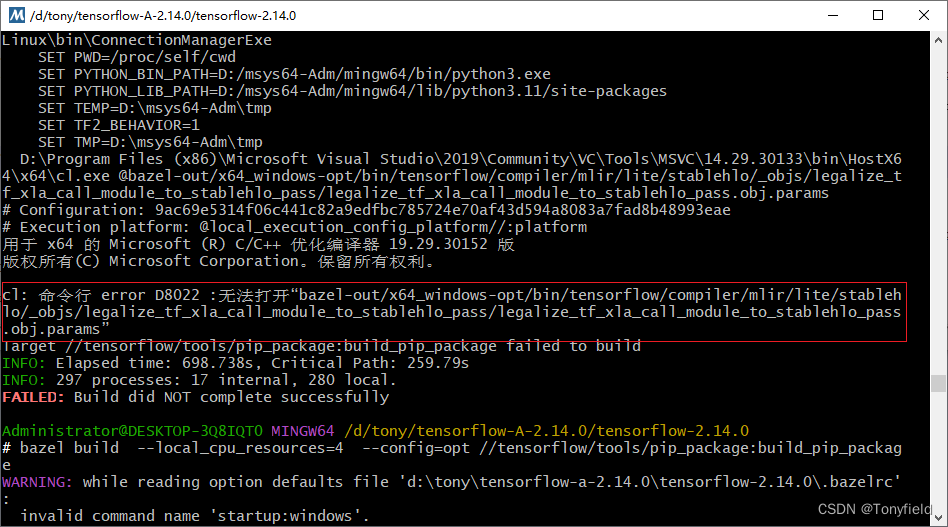
Windows 下编译 TensorFlow 2.9.1 CC库
参考 Intel 的 tensorflow 编译指导,不过项目还是可以用 TF原本的,不是一定要选择Intel 的TF版本。 安装 MSVC 2019 安装 Intel OneDNN OneMKL 似乎也可以不安装 ( & ) https://www.intel.cn/content/www/cn/zh/developer/articles/tool/one…...

Databricks 入门之连接外部数据库
连接方式应该很多,现在记录本人目前学习到的一种方式。 一、读取外部数据库 1.notebook执行语言为sql时可以通过JDBC方式加载数据库数据。 以下代码将可以将sqlserver中的表加载到databricks视图中,当然也可创建表来接收外部数据。 %sqlCREATE TEMPOR…...

家庭互动新维度:TikTok的亲子体验
在数字时代,家庭互动的方式正在发生翻天覆地的改变。社交媒体平台TikTok崭露头角,不仅在年轻用户中广受欢迎,还为家庭带来了全新的互动维度。本文将深入探讨TikTok如何成为家庭互动的新元素,以及它如何改变亲子体验。 TikTok&…...

redis教程 一 redis中的常用命令
文章目录 redis常见命令Redis数据结构介绍redis通用命令String类型String的常见命令Key结构 Hash类型List类型Set类型SortedSet类型 redis常见命令 Redis数据结构介绍 Redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样&…...
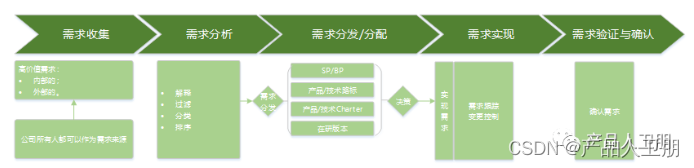
【第28例】IPD体系进阶 | 需求管理:需求实现过程
目录 简介 内容详解 CSDN学院相关推荐 作者简介 简介 继续 IPD 体系中的需求管理相关的专题。 先来看看整个需求管理涉及的过程内容: 需求管理流程主要包含五个阶段: 需求收集; 需求分析; 需求分发/分配;...

聊聊我对AI Agents技术的一些看法
小伙伴们!我来兑现承诺啦~ ps:接下来期待什么内容,欢迎在评论区留言! 今天,我们就来聊聊大模型 Agent。 最近这几个月,Agent 这一概念可谓火出天际,从 AutoGPT 一周 6 万 star 刷新…...
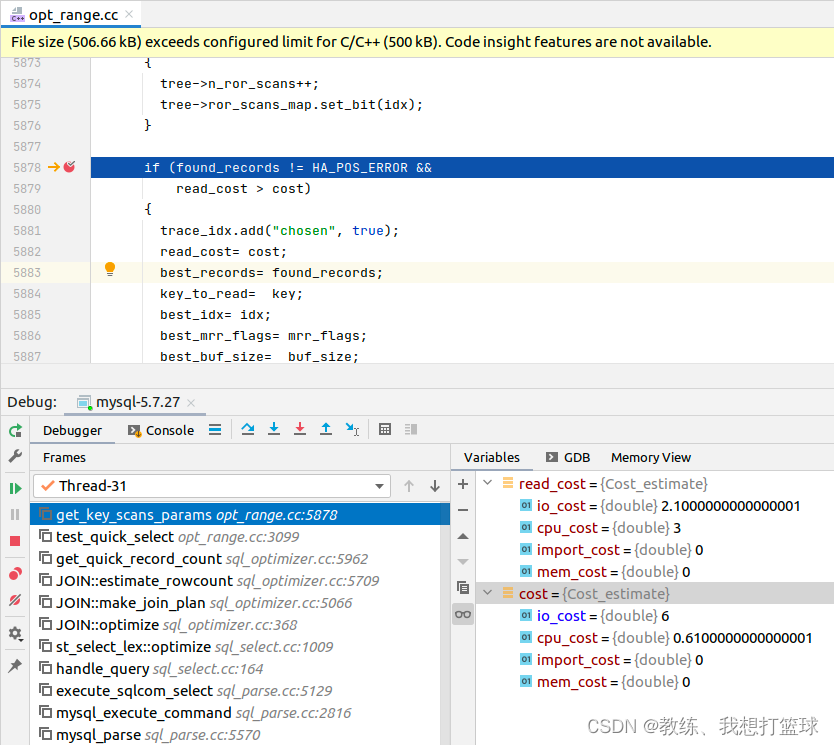
32 mysql in 的实现
前言 这里我们主要是来探讨一下 mysql 中 in 的使用, find_in_set 的使用 这两者 在我们实际应用中应该也是 非常常用的了 测试数据表如下 CREATE TABLE tz_test (id int(11) unsigned NOT NULL AUTO_INCREMENT,field1 varchar(16) DEFAULT NULL,field2 varchar(16) DEFAU…...

Qt QtCreator添加自定义注释
在写代码的时候我们为了规范化,一般会加文件注释、类注释和函数注释;用注释来说明我们的代码,也方便模块化开发,那么我们在写注释的时候经常会写一些重复的内容,我们会复制粘贴。这样一来二去,就显得很繁琐…...

docker 各种命令
-v 或 --volume 由三个由冒号(:)分隔的字段组成,[HOST-DIR:]CONTAINER-DIR[:OPTIONS]。 HOST-DIR 代表主机上的目录或数据卷的名字。省略该部分时,会自动创建一个匿名卷。如果是指定主机上的目录,需要使用绝对路径。 C…...

【优选算法系列】【专题五位运算】第一节.常见的位运算(面试题 01.01. 判定字符是否唯一和268. 丢失的数字)
文章目录 前言常见的位运算一、判定字符是否唯一 1.1 题目描述 1.2 题目解析 1.2.1 算法原理 1.2.2 代码编写二、丢失的数字 2.1 题目描述 2.2 题目解析 2.2.1 算法原理 2.2.2 代码编写总结 前言 常见的…...

学习笔记二十八:K8S控制器Daemonset入门到企业实战应用
DaemonSet控制器:概念、原理解读 DaemonSet概述DaemonSet工作原理:如何管理PodDaemonset典型的应用场景DaemonSet 与 Deployment 的区别DaemonSet资源清单文件编写技巧 DaemonSet使用案例:部署日志收集组件fluentdDaemonset管理pod࿱…...

您对互联网有多“上瘾”?
萨里大学的科学家决定检查现代用户的网络成瘾程度。他们的一篇文章最近发表在 《旅行与旅游营销杂志》上 ,其中包含对受此问题困扰的年轻人(而不仅仅是年轻人)的研究和分类结果。 796名不同年龄段的人参加了实验。科学家们仔细监测了他们的行…...
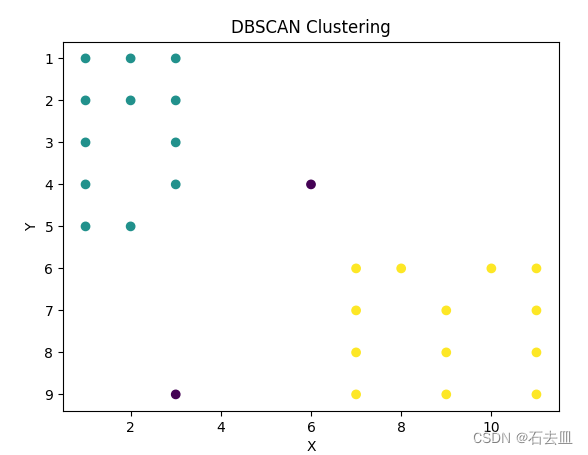
数据挖掘题目:设ε= 2倍的格网间距,MinPts = 6, 采用基于1-范数距离的DBSCAN算法对下图中的实心格网点进行聚类,并给出聚类结果(代码解答)
问题 代码 import matplotlib.pyplot as plt import numpy as np from sklearn.cluster import DBSCAN #pip install matplotlib #pip install numpy #pip install scikit-learn # 实心格网点的坐标 solid_points np.array([[1, 1], [2, 1],[3, 1], [1, 2], [2, 2], [3, 2],[…...
)
「国内直连」Claude Code安装与API配置保姆级教程:从Node.js到调用,小白少踩坑(亲测跑通)
前言 国内用户最头疼的就是海外账号和网络问题,其实找对中转接口就能省不少事。 这篇文章把从Node.js安装到Claude Code启动的全流程整理清楚,用88api做接口中转(国内直连,不用翻墙),尽量让每个步骤都能照…...

扩散模型在机器人控制中的多模态优化应用
1. 扩散模型在近似模型预测控制中的创新应用在机器人控制领域,模型预测控制(MPC)因其优秀的约束处理能力和优化性能而广受青睐。然而,传统MPC需要在线求解优化问题,计算成本高昂,难以满足高速实时控制的需求…...

RedisDesktopManager Windows版:5分钟掌握免费Redis数据库可视化工具
RedisDesktopManager Windows版:5分钟掌握免费Redis数据库可视化工具 【免费下载链接】RedisDesktopManager-Windows RedisDesktopManager Windows版本 项目地址: https://gitcode.com/gh_mirrors/re/RedisDesktopManager-Windows RedisDesktopManager Windo…...

双核Delfino架构解析:如何解决复杂实时控制系统的性能瓶颈
1. 项目概述:从“双核”到“创新架构”的深度解构最近在和一些做工业控制、新能源以及高端医疗器械的朋友交流时,发现一个词被反复提及,那就是“双核Delfino”。乍一听,这像是一个具体的芯片型号,但深入聊下去…...
)
从新手到认证专家:NotebookLM总结能力跃迁路径图(含Google官方未公开的评估矩阵V2.1)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM总结能力跃迁路径总览 NotebookLM 是 Google 推出的面向研究者与开发者的情境化 AI 助手,其核心突破在于将用户上传的文档(PDF、TXT、Google Docs)转化为可…...

10个必须知道的simplex-noise.js实战技巧:从基础到高级应用
10个必须知道的simplex-noise.js实战技巧:从基础到高级应用 【免费下载链接】simplex-noise.js A fast simplex noise implementation in Javascript / Typescript. 项目地址: https://gitcode.com/gh_mirrors/si/simplex-noise.js simplex-noise.js是一个快…...

终极指南:如何在Windows上免费扩展虚拟显示器,轻松打造多屏工作空间
终极指南:如何在Windows上免费扩展虚拟显示器,轻松打造多屏工作空间 【免费下载链接】virtual-display-rs A Windows virtual display driver to add multiple virtual monitors to your PC! For Win10. Works with VR, obs, streaming software, etc …...

探索高效存储:STM32F4系列SD卡读写与FATFS文件系统移植
探索高效存储:STM32F4系列SD卡读写与FATFS文件系统移植 【下载地址】SD卡读写与FATFS文件系统移植SPI模式 本仓库提供了一个完整的SD卡读写程序,并成功移植了FATFS文件系统,适用于STM32F4系列微控制器。通过SPI模式,您可以轻松实现…...

如何高效使用AutoHotkey编译器:Ahk2Exe完整指南与实战技巧
如何高效使用AutoHotkey编译器:Ahk2Exe完整指南与实战技巧 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 对于Windows自动化脚本开发者而言ÿ…...

【Perplexity实时学术搜索终极指南】:20年科研老兵亲授3大避坑法则与5倍效率提升实战技巧
更多请点击: https://codechina.net 第一章:Perplexity实时学术搜索的核心原理与定位 Perplexity 实时学术搜索并非传统关键词匹配型检索系统,而是构建在语义理解、动态上下文建模与多源可信度验证三位一体架构之上的新一代学术信息交互范式…...