TensorFlow案例学习:使用 YAMNet 进行迁移学习,对音频进行识别
前言
上一篇文章 TensorFlow案例学习:简单的音频识别 我们简单学习了音频识别。这次我们继续学习如何使用成熟的语音分类模型来进行迁移学习
官方教程: 使用 YAMNet 进行迁移学习,用于环境声音分类
模型下载地址(需要科学上网): https://tfhub.dev/google/yamnet/1
YAMNet简介
YAMNet(Yet Another Music Recognition Network)是由谷歌开发的音乐识别模型。它是一个基于深度学习的模型,可以用于识别音频中的各种环境音、乐器音、人声等。
YAMNet 使用了卷积神经网络(CNN)作为主要的网络结构。它的输入是音频波形数据,通过一系列卷积和池化层来捕获不同尺度的特征。训练过程中,YAMNet 使用大量的带有标签的音频数据,通过监督学习的方式来学习到不同音频类别的特征表示。
YAMNet 的输出是一个分类器,可以将输入的音频波形数据预测为音频对应的类别。在预测过程中,YAMNet 会将输入音频进行分帧处理,并对每一帧进行分类。最后,通过对所有帧的分类结果进行平均,得到整个音频的分类结果。
YAMNet 的优势在于它专门用于音频场景的识别,可以识别出许多现实生活中的环境声音,包括动物叫声、乐器音、机械声、交通声等。它在对音频进行标签分类的任务中表现出色,并且在公开数据集上取得了很好的性能。
YAMNet 的开源实现可供使用,并提供了训练好的模型权重,可以直接应用于音频识别任务。它可以用于音频分类和标签预测,也可以作为其他音频应用中的基础模块。
安装tensorflow-io
我这里遇到一个问题,安装成功后一直提示找不到模块,我这里使用librosa来解决这部分问题
基本使用
加载模型
yamnet_model = hub.load('./yamnet_1')
print("yamnet_model:", yamnet_model)
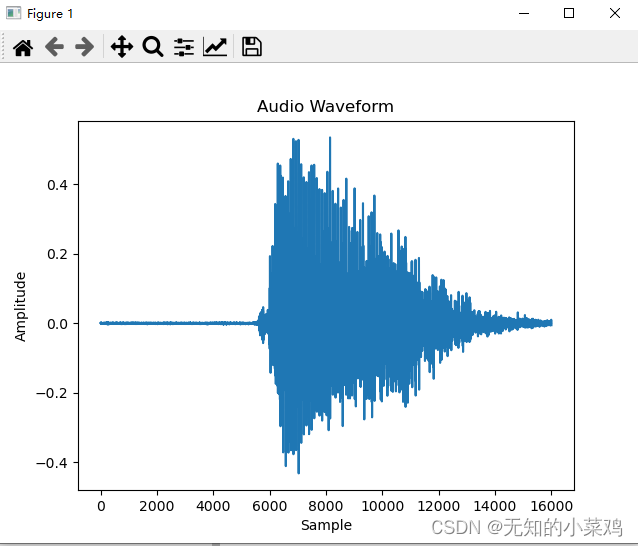
绘制音频波形
# 加载本地wav文件,并制定采样率为16000和单声道的形式进行重采样
def load_wav_16k_mono(filename):wav, sample_rate = librosa.load(filename, sr=16000, mono=True)return wavtesting_wav_data = load_wav_16k_mono('./test_data/down.wav')# 创建x轴坐标,以样本点为单位
x = np.arange(len(testing_wav_data))
# 绘制波形图
plt.plot(x, testing_wav_data)
plt.xlabel('Sample')
plt.ylabel('Amplitude')
plt.title('Audio Waveform')
plt.show()
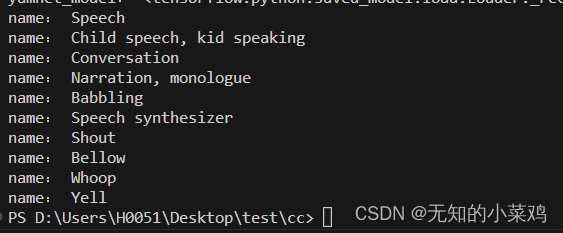
加载类映射
# 加载类映射
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names = list(pd.read_csv(class_map_path)['display_name'])for name in class_names[0:10]:print("name:", name)
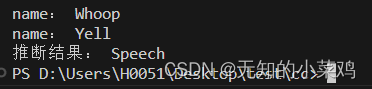
预测
# 预测,获取最大可能性
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores,axis=0)
top_class = tf.math.argmax(class_scores)
inferred_class = class_names[top_class]print("推断结果:",inferred_class)
迁移学习一
处理数据集
下载数据集并解压到项目里
ESC-50数据集下载地址: https://github.com/karoldvl/ESC-50/archive/master.zip
该数据集由2000个50秒的环境音频记录的标记集合,该数据集由40个类组成。
筛选数据
官方文档筛选的是狗和猫,这里我们使用狗、猫、羊
my_classes = ['dog', 'cat', 'sheep']
map_class_to_id = {'dog': 0, 'cat': 1, 'sheep': 2}pd_data = pd.read_csv('./ESC-50-master/meta/esc50.csv')
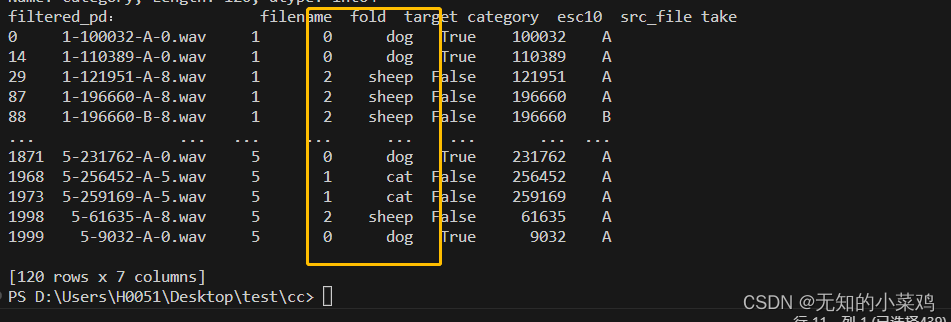
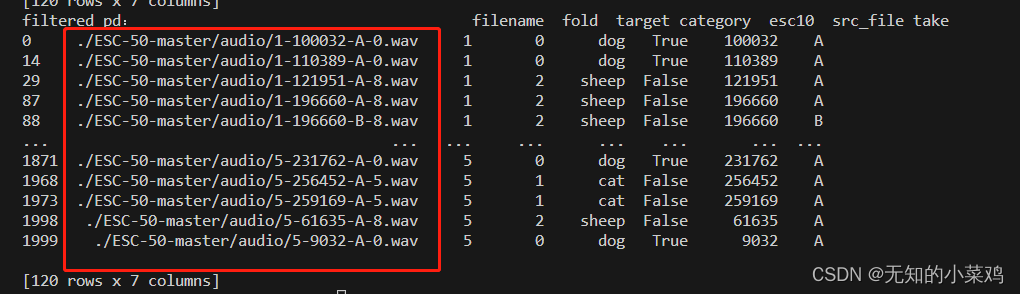
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
print("filtered_pd:", filtered_pd)class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
print("class_id:",class_id)filtered_pd = filtered_pd.assign(target=class_id)
print("filtered_pd:", filtered_pd)
这段代码的作用就是对三种动物进行筛选,并按照{'dog': 0, 'cat': 1, 'sheep': 2}进行划分,三种动物共120条数据
# 筛选数据:2、获取到文件完整的路径
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
print("filtered_pd:", filtered_pd)
加载音频文件
# 加载音频文件并检索嵌入:1、filenames文件路径,target类别,
# fold每个音频文件所属的交叉验证折叠,可以理解为将不同种类的文件放在一个文件夹里,这个fold代表这个文件是在哪一个文件夹里,相当于文件夹的标记
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
print("filenames-targets-folds", filenames[0], targets[0], folds[0])# 加载音频文件并检索嵌入:2、创建包含三个元素:filenames、targets和folds的一个数据集对象
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
print("main_ds:", main_ds)
print("element_spec:", main_ds.element_spec)# 加载音频文件并检索嵌入:3、将音频变成单声道的16kHz采样的音频数据,使其符合模型的输入
def load_wav_16k_mono(filename):file_contents = tf.io.read_file(filename)wav, sample_rate = tf.audio.decode_wav(file_contents,desired_channels=1)wav = tf.squeeze(wav, axis=-1)sample_rate = tf.cast(sample_rate, dtype=tf.int64)wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)return wavdef load_wav_for_map(filename, label, fold):return load_wav_16k_mono(filename), label, foldmain_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
处理训练集数据
# 处理训练集数据
def extract_embedding(wav_data, label, fold):scores, embeddings, spectrogram = yamnet_model(wav_data)num_embeddings = tf.shape(embeddings)[0]return (embeddings,tf.repeat(label, num_embeddings),tf.repeat(fold, num_embeddings))main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
拆分数据
将数据拆分为训练集、验证集、测试集
# 拆分数据
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)# 删除fold列,训练时不需要def remove_fold_column(embedding, label, fold): return (embedding, label)train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
创建模型
# 创建模型,这里的1024与512是怎么来的一直没搞明白
my_model = tf.keras.Sequential([tf.keras.layers.Input(shape=(1024), dtype=tf.float32,name="input_embedding"),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dense(len(my_classes))
], name="my_model")my_model.summary()
编译训练模型
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),optimizer="adam",metrics=['accuracy'])callback = tf.keras.callbacks.EarlyStopping(monitor='loss',patience=3,restore_best_weights=True)
history = my_model.fit(train_ds,epochs=20,validation_data=val_ds,callbacks=callback)评估模型
loss, accuracy = my_model.evaluate(test_ds)print("Loss: ", loss)
print("Accuracy: ", accuracy)

测试模型
testing_wav_data = load_wav_16k_mono('./ESC-50-master/audio/1-57795-A-8.wav')
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')

将模型保存为可直接将WAV文件作为输入的模型
当您将嵌入作为输入时,您的模型就会起作用。
在实际场景中,您需要使用音频数据作为直接输入。
为此,您需要将 YAMNet 与模型合并到一个模型中,您可以导出该模型以供其他应用程序使用。
class ReduceMeanLayer(tf.keras.layers.Layer):def __init__(self, axis=0, **kwargs):super(ReduceMeanLayer, self).__init__(**kwargs)self.axis = axisdef call(self, input):return tf.math.reduce_mean(input, axis=self.axis)saved_model_path = './dogs_cats_sheep_yamnet'input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer('./yamnet_1',trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
完整代码
import tensorflow_hub as hub
import tensorflow as tfimport numpy as np
import pandas as pd
import os
import tensorflow_io as tfioyamnet_model = hub.load('./yamnet_1')base_data_path = './ESC-50-master/audio/'# 筛选数据
# 筛选数据:1、将数据按照{'dog': 0, 'cat': 1, 'sheep': 2}进行划分
my_classes = ['dog', 'cat', 'sheep']
map_class_to_id = {'dog': 0, 'cat': 1, 'sheep': 2}
pd_data = pd.read_csv('./ESC-50-master/meta/esc50.csv')
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
#print("filtered_pd:", filtered_pd)class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
#print("class_id:", class_id)filtered_pd = filtered_pd.assign(target=class_id)
#print("filtered_pd:", filtered_pd)
# 筛选数据:2、获取到文件完整的路径
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
#print("filtered_pd:", filtered_pd)# 加载音频文件并检索嵌入
# 加载音频文件并检索嵌入:1、filenames文件路径,target类别,
# fold每个音频文件所属的交叉验证折叠,可以理解为将不同种类的文件放在一个文件夹里,这个fold代表这个文件是在哪一个文件夹里,相当于文件夹的标记
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
print("filenames-targets-folds", filenames[0], targets[0], folds[0])# 加载音频文件并检索嵌入:2、创建包含三个元素:filenames、targets和folds的一个数据集对象
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
# print("main_ds:", main_ds)
# print("element_spec:", main_ds.element_spec)# 加载音频文件并检索嵌入:3、将音频变成单声道的16kHz采样的音频数据,使其符合模型的输入def load_wav_16k_mono(filename):file_contents = tf.io.read_file(filename)wav, sample_rate = tf.audio.decode_wav(file_contents,desired_channels=1)wav = tf.squeeze(wav, axis=-1)sample_rate = tf.cast(sample_rate, dtype=tf.int64)wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)return wavdef load_wav_for_map(filename, label, fold):return load_wav_16k_mono(filename), label, foldmain_ds = main_ds.map(load_wav_for_map)
print("main_ds:", main_ds)
# main_ds.element_spec# 处理训练集数据def extract_embedding(wav_data, label, fold):scores, embeddings, spectrogram = yamnet_model(wav_data)num_embeddings = tf.shape(embeddings)[0]return (embeddings,tf.repeat(label, num_embeddings),tf.repeat(fold, num_embeddings))main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec# 拆分数据
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)# 删除fold列,训练时不需要def remove_fold_column(embedding, label, fold): return (embedding, label)train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)# 创建模型,这里的1024与512是怎么来的一直没搞明白
my_model = tf.keras.Sequential([tf.keras.layers.Input(shape=(1024), dtype=tf.float32,name="input_embedding"),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dense(len(my_classes))
], name="my_model")my_model.summary()# 编译训练模型
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),optimizer="adam",metrics=['accuracy'])callback = tf.keras.callbacks.EarlyStopping(monitor='loss',patience=3,restore_best_weights=True)
history = my_model.fit(train_ds,epochs=20,validation_data=val_ds,callbacks=callback)
# 评估模型
loss, accuracy = my_model.evaluate(test_ds)print("Loss: ", loss)
print("Accuracy: ", accuracy)# 导出模型
class ReduceMeanLayer(tf.keras.layers.Layer):def __init__(self, axis=0, **kwargs):super(ReduceMeanLayer, self).__init__(**kwargs)self.axis = axisdef call(self, input):return tf.math.reduce_mean(input, axis=self.axis)saved_model_path = './dogs_cats_sheep_yamnet'input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer('./yamnet_1',trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)测试模型
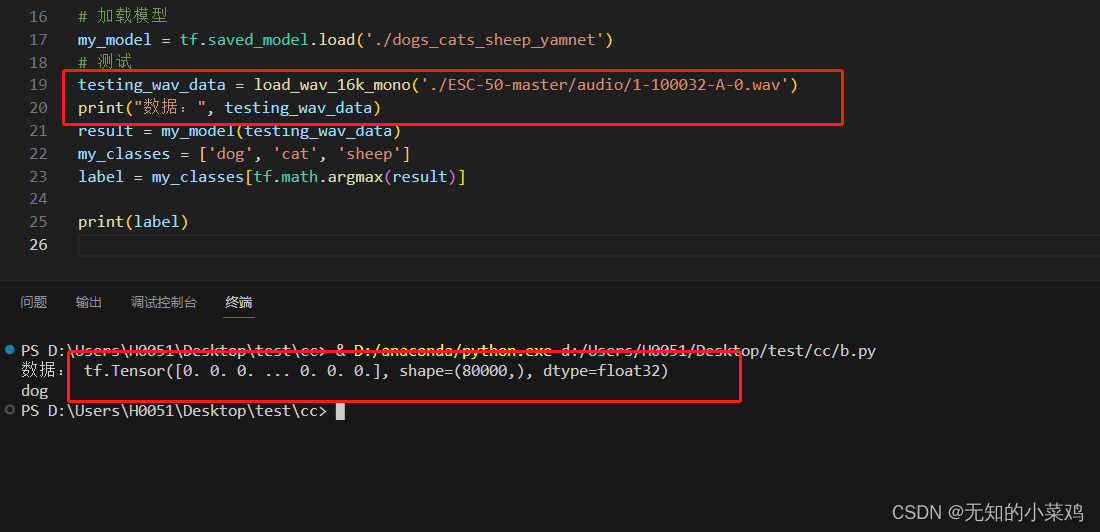
import tensorflow as tf
import tensorflow_io as tfiodef load_wav_16k_mono(filename):file_contents = tf.io.read_file(filename)wav, sample_rate = tf.audio.decode_wav(file_contents,desired_channels=1)wav = tf.squeeze(wav, axis=-1)sample_rate = tf.cast(sample_rate, dtype=tf.int64)wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)return wav# 加载模型
my_model = tf.saved_model.load('./dogs_cats_sheep_yamnet')
# 测试
testing_wav_data = load_wav_16k_mono('./ESC-50-master/audio/1-100032-A-0.wav')
result = my_model(testing_wav_data)
my_classes = ['dog', 'cat', 'sheep']
label = my_classes[tf.math.argmax(result)]print(label)

迁移学习二
上面的迁移学习一直是按照教程来的,使用的数据集ESC-50 数据集 格式也不怎么常见。那么我们能不能根据这个格式,来构建自己的数据集,使代码可以复用。
数据集这里选择上一篇文章中的 mini_speech_commands 数据集。共有8种类别的音频,这里我们采用每种类别选择5个音频,一共40个音频,来构建自己的数据集。
说一下测试结果,由于数据太少,一个类别才5条数据。并且有3条数据是训练数据、1条数据是验证数据、1条数据是测试数据。导致测试结果不好,只有当数据是训练数据时能够得出正确结果,是其他数据时结果大部分适合都是不对的。
因此如果真的要使用的话,数据要多一点。上面的官方教程是共120条数据,一个类别有40条数据,训练数据要尽可能的多一些。

audio存放音频文件,commands.csv 存放音频的信息。从后面代码看我们只需要在commands.csv 中维护三列就行
filename文件名target文件所属的类别序号category文件所属的类别名称fold标识,代表这个文件是在哪一个文件夹里
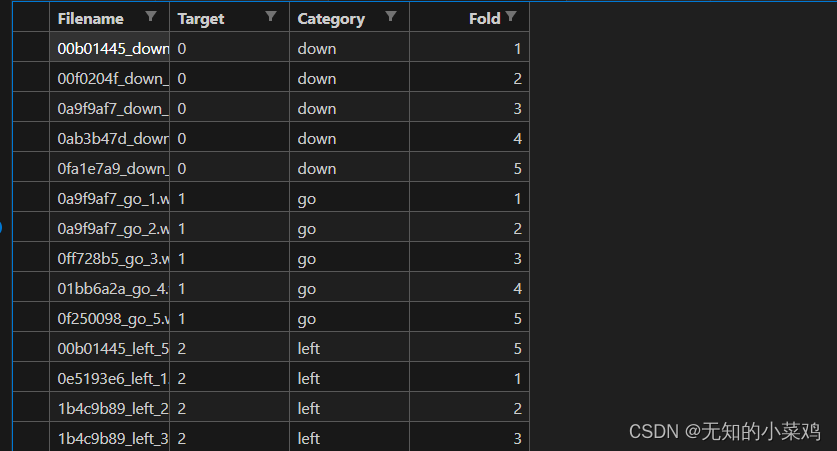
target的值要与你设置的相对应
map_class_to_id = {'down': 0, 'go': 1, 'left': 2,'no': 3, 'right': 4, 'stop': 5, 'up': 6, 'yes': 7}
修改训练文件
import tensorflow_hub as hub
import tensorflow as tfimport numpy as np
import pandas as pd
import os
import tensorflow_io as tfioyamnet_model = hub.load('./yamnet_1')base_data_path = './commands/audio'
csv_path = './commands/commands.csv'# 筛选数据
my_classes = ['down', 'go', 'left', 'no', 'right', 'stop', 'up', 'yes']
map_class_to_id = {'down': 0, 'go': 1, 'left': 2,'no': 3, 'right': 4, 'stop': 5, 'up': 6, 'yes': 7}
pd_data = pd.read_csv(csv_path)
#print("pd_data:", pd_data)
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
# 筛选数据获取完整路径
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
#print("filtered_pd:", filtered_pd)# 加载音频文件并检索嵌入
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
print("filenames-targets-folds", filenames[0], targets[0], folds[0])
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
# print("main_ds:",main_ds)# 将音频变成单声道的16kHz采样的音频数据,使其符合模型的输入def load_wav_16k_mono(filename):file_contents = tf.io.read_file(filename)wav, sample_rate = tf.audio.decode_wav(file_contents,desired_channels=1)wav = tf.squeeze(wav, axis=-1)sample_rate = tf.cast(sample_rate, dtype=tf.int64)wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)return wavdef load_wav_for_map(filename, label, fold):return load_wav_16k_mono(filename), label, foldmain_ds = main_ds.map(load_wav_for_map)
print("main_ds:", main_ds)# 处理训练集数据def extract_embedding(wav_data, label, fold):scores, embeddings, spectrogram = yamnet_model(wav_data)num_embeddings = tf.shape(embeddings)[0]return (embeddings,tf.repeat(label, num_embeddings),tf.repeat(fold, num_embeddings))main_ds = main_ds.map(extract_embedding).unbatch()# 拆分数据
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)# 删除fold列,训练时不需要def remove_fold_column(embedding, label, fold): return (embedding, label)train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)# 创建模型,这里的1024与512是怎么来的一直没搞明白
my_model = tf.keras.Sequential([tf.keras.layers.Input(shape=(1024), dtype=tf.float32,name="input_embedding"),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dense(len(my_classes))
], name="my_model")my_model.summary()# 编译训练模型
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),optimizer="adam",metrics=['accuracy'])callback = tf.keras.callbacks.EarlyStopping(monitor='loss',patience=3,restore_best_weights=True)
history = my_model.fit(train_ds,epochs=20,validation_data=val_ds,callbacks=callback)
# 评估模型
loss, accuracy = my_model.evaluate(test_ds)print("Loss: ", loss)
print("Accuracy: ", accuracy)# 导出模型class ReduceMeanLayer(tf.keras.layers.Layer):def __init__(self, axis=0, **kwargs):super(ReduceMeanLayer, self).__init__(**kwargs)self.axis = axisdef call(self, input):return tf.math.reduce_mean(input, axis=self.axis)saved_model_path = './command_yamnet'input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer('./yamnet_1',trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
补充
如果想直接在浏览器里使用,需要解决的一个问题就是如何将一个音频文件变成符合模型的输入,下面是我找到的方式(没有测试,不知道是否可以)
async function audioFileToTensor(audioFile) {// 读取音频文件const audioBuffer = await fetch(audioFile).then(response => response.arrayBuffer()).then(arrayBuffer => audioContext.decodeAudioData(arrayBuffer));// 获取音频数据const audioData = audioBuffer.getChannelData(0); // 获取音频的第一个通道的数据// 创建一个全零的Tensorconst tensor = tf.tensor(audioData, [audioData.length]);return tensor;
}// 使用示例
const audioFile = 'path/to/your/audio/file.mp3';
const audioContext = new AudioContext();
const tensor = await audioFileToTensor(audioFile);
console.log(tensor);
本质上就行需要想办法处理音频,让音频变成符合的格式。
相关文章:
TensorFlow案例学习:使用 YAMNet 进行迁移学习,对音频进行识别
前言 上一篇文章 TensorFlow案例学习:简单的音频识别 我们简单学习了音频识别。这次我们继续学习如何使用成熟的语音分类模型来进行迁移学习 官方教程: 使用 YAMNet 进行迁移学习,用于环境声音分类 模型下载地址(需要科学上网&…...

MySQL CHAR 和 VARCHAR 的区别
文章目录 1.区别1.1 存储方式不同1.2 最大长度不同1.3 尾随空格处理方式不同1.4 读写效率不同 2.小结参考文献 在 MySQL 中,CHAR 和 VARCHAR 是两种不同的文本数据类型,CHAR 和 VARCHAR 类型声明时需要指定一个长度,该长度指示您希望存储的最…...

虚拟机 ping: www.baidu.com:未知的名称或服务
1、打开ifcfg-ens33文件 vi /etc/sysconfig/network-scripts/ifcfg-ens332、如下,加上网关和dns就行了,紫色部分,也就是DNS1“114.114.114.114” TYPE"Ethernet" PROXY_METHOD"none" BROWSER_ONLY"no" BOOTP…...
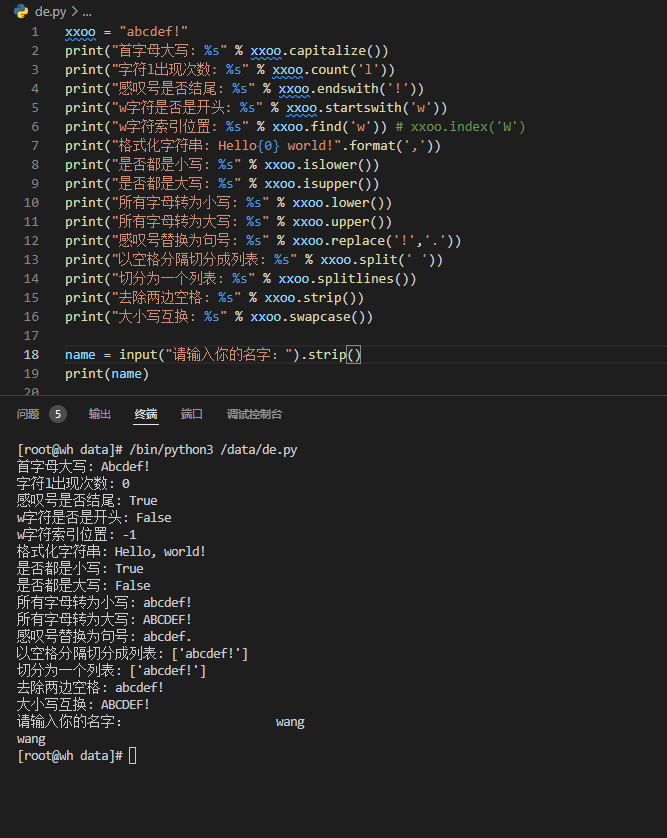
第二章 Python字符串处理
系列文章目录 第一章 Python 基础知识 第二章 python 字符串处理 第三章 python 数据类型 第四章 python 运算符与流程控制 第五章 python 文件操作 第六章 python 函数 第七章 python 常用内建函数 第八章 python 类(面向对象编程) 第九章 python 异常处理 第十章 python 自定…...

混合编程 ATPCS规范及案例(汇编调用C、C调用汇编、内联汇编)
1.混合编程的规范 2.汇编调用C 2.C调用汇编 3.内联汇编 例子:...

使用Gorm进行CRUD操作指南
使用GORM在Go中创建、读取、更新和删除记录的逐步教程 在数据库管理中,CRUD操作是应用程序的支柱,它们使数据的创建、检索、更新和删除成为可能。强大的Go对象关系映射库GORM通过抽象SQL语句的复杂性,使这些操作变得轻松。本文将作为您全面指…...
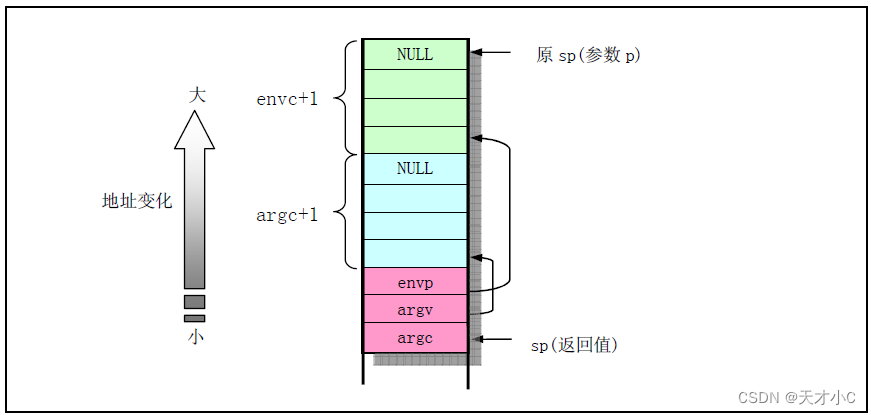
Linux0.11内核源码解析-exec.c
主要实现对二进制可执行文件和shell文件的加载和执行,其中主要的函数是do_execve(),它是系统中断调用int 0x80的功能号__NR_execve()调用,是exec()函数的主要实现以下几点功能: 1.执行对参数和环境参数空间页面的初始化操作,初始…...

百度竞价排名推广对比自然排名哪一个更具优势-华媒舍
在搜索引擎结论网页页面(SERP)中,我们经常会看到一些网站链接及其广告栏。这种连接一般分为两种类型:百度竞价推广排名推广与自然排名。究竟哪个更有优势?本文将对这几种排名形式进行科谱详细介绍。 什么叫百度竞价推广…...
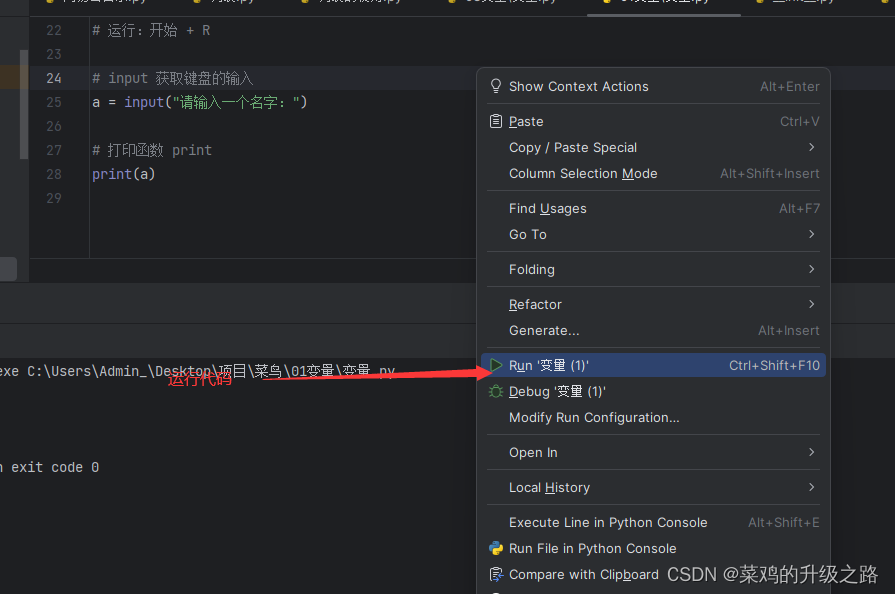
python第一课 变量
1.离线的情况下首选txt文档 2.有道云笔记 3.思维导图 xmind mindmaster 4.博客 5.wps流程图 # 变量的命名规则 1.变量名只能由数字字母下划线组成 2.变量名不能以数字开头 3.变量名不能与关键字重名 快捷键 撤销:Ctrl/Command Z 新建:Ctrl/Com…...

shell之netstat的用法
shell之netstat的用法 所有参数应用举例 所有参数 1)-A<网络类型>或–<网络类型> 列出该网络类型连线中的相关地址。 2)-i 显示所有网络接口的信息。 3)-r 显示路由表的信息。 4)-s 显示按各个协议的统计信息。 5&am…...
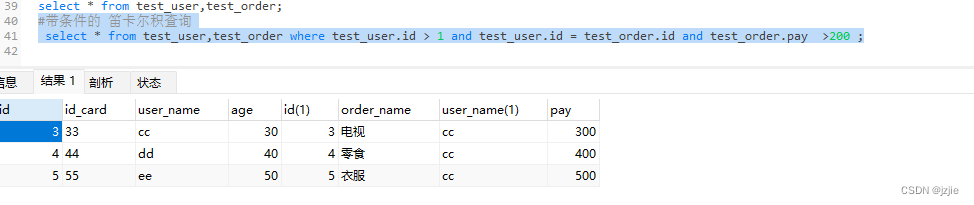
MSQL系列(十二) Mysql实战-为什么索引要建立在被驱动表上
Mysql实战-为什么索引要建立在被驱动表上 前面我们讲解了BTree的索引结构,也详细讲解下 left Join的底层驱动表 选择原理,那么今天我们来看看到底如何用以及如何建立索引和索引优化 开始之前我们先提一个问题, 为什么索引要建立在被驱动表上…...

C语言,数据结构指针,结构构体操作符 •,->,*的区别,看这篇就够了
在朋友们学习指针和数据结构这一章的时候,对各种操作符云里雾里。当你看到这么文章之后你就会明白了。 一 • 和 ->运算符 • 运算符:是结构变量访问结构体成员时用的操作符 -> 运算符:这是结构体指针访问结构体成员时调用的运算符。 …...

axios 多个baseURL配置、实现不同前缀代理到不同的服务器的几种方式
前言: 在开发中,有可能遇到每部分的功能的需要调用另一台服务器的地址。这个时候就需要设置不同的请求前缀首先代理到不同的服务器地址。 一、axios封装实例以及代理:(不是完整的封装实例,重点在于baseURL的区别) 文件路径&…...
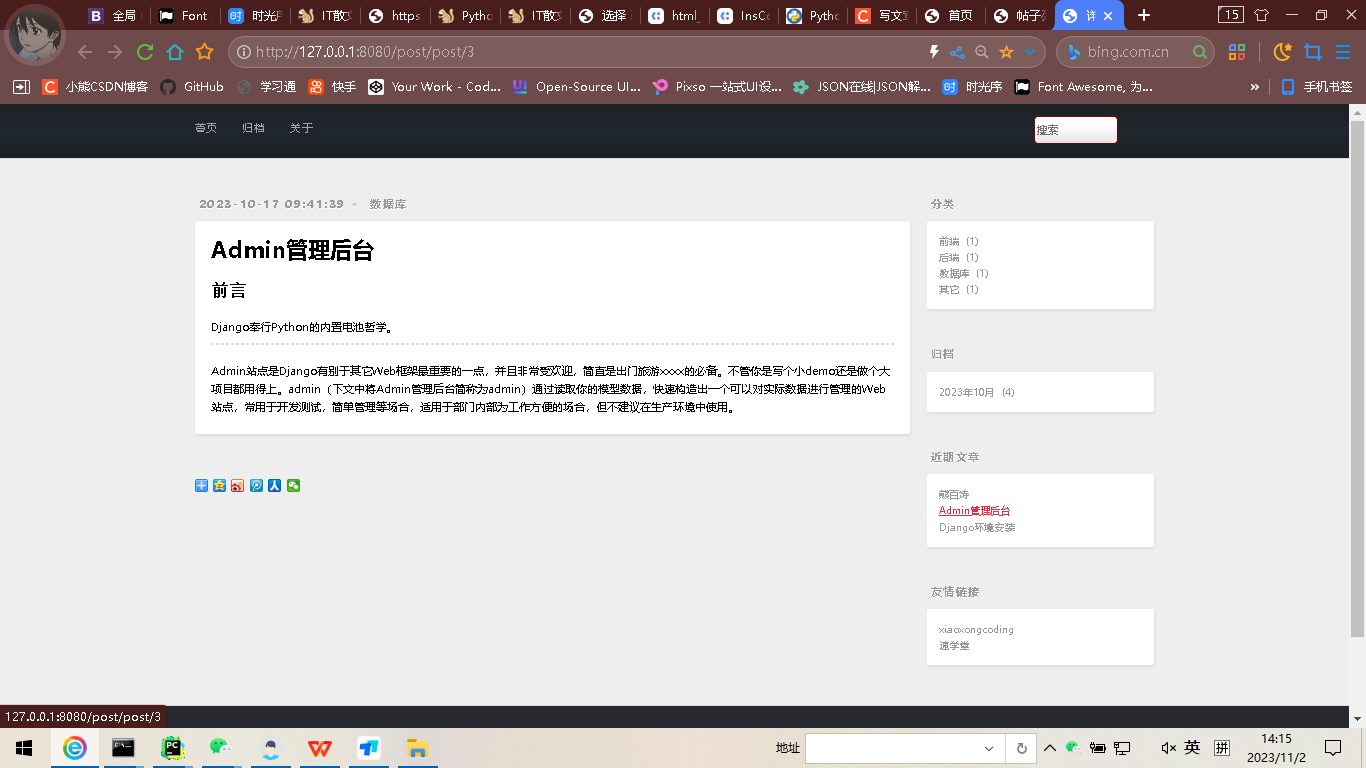
Diango项目-简易个人博客项目
项目实现功能 在admin后台自定义添加上传文档。对展示在首页的文章分页显示。在首页点击文章的阅读全文按钮可进入该文章全文详情页进行浏览。对文章实现了内容分类何以发布时间进行归档分类。使用django的whoose搜索引擎对全文实现内容的搜索。 项目涉及技术 Mysql Djan…...

思维训练3
题目描述1 Problem - A - Codeforces 题目分析 样例1解释: 对于此题,我们采用贪心的想法,从1到n块数越少越好,故刚好符合最少的块数即可,由于第1块与第n块是我们必须要走的路,所以我们可以根据这两块砖的…...

初识FFmpeg
前言 无意间见到群里的小伙伴展示视频工具。功能比较多,包括视频编码修改,画质处理,比例处理、名称提取,剪辑、标题拆解。因此开始了FFmpeg学习。以下摘自百度百科的解释。 FFmpeg是一套可以用来记录、转换数字音频、视频…...

分布式多主关系数据库的底线业务优势
当今的应用程序(包括企业应用程序)需要始终开启且始终可用,并且通常必须为全球用户提供服务,这些用户无论身在何处都希望获得几乎即时的响应时间。 应对这些挑战不仅仅意味着让用户更满意:每个能够解决低延迟和超高可…...
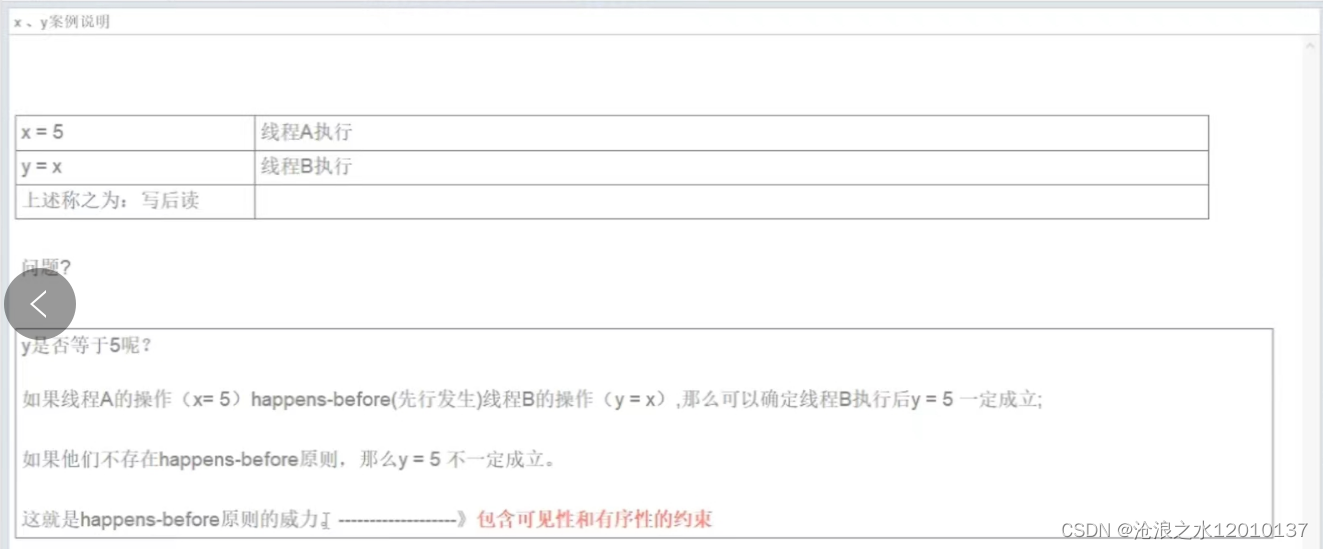
JMM讲解
一:为什么要有JMM,它为什么出现? CPU的运行并不是直接操作内存而是先把内存里面的数据读到缓存,而内存的读和写操作的时候会造成不一致的问题。JVM规范中试图定义一种Java内存模型来屏蔽掉各种硬件和操作系统的内存访问差异&…...
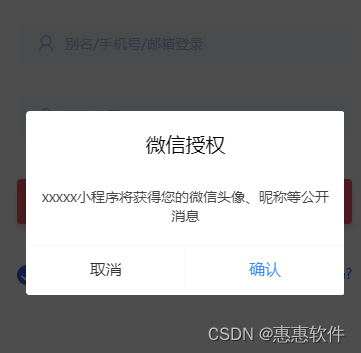
小程序获取头像和昵称的思路
小程序获取头像和昵称的基本方法是调用小程序自带的API wx.getUserProfile(),这也是小程序官方目前最推荐的做法。成功获取用户名头像之后,小程序允许保存调用的结果,以便下一次打开页面的时候自动显示头像和名字。保存用户名和头像并不是保存…...
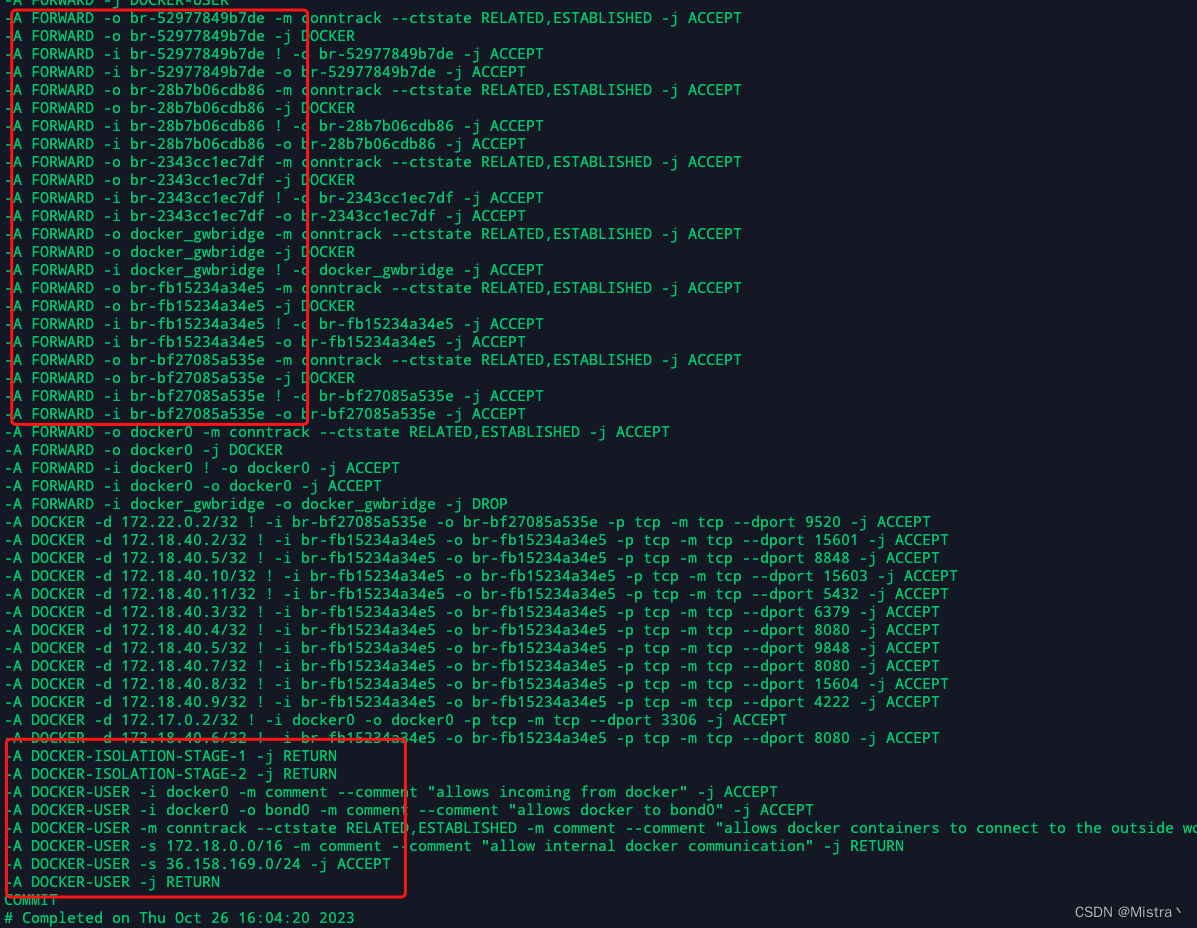
关于docker网络实践中遇到的问题
1.禁用docker自动修改iptables规则 查看docker.service文件/usr/lib/systemd/system/docker.service 默认在宿主机部署容器,映射了端口的话,docker能自己修改iptables规则,把这些端口暴露到公网。 如果要求这些端口不能暴露到公网…...

高效图像浏览:解锁90+格式的轻量级解决方案
高效图像浏览:解锁90格式的轻量级解决方案 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 在数字时代,我们每天都要与各种图像格式打交道࿰…...

解决MicroBlaze程序启动难题:Vivado中bit与elf文件合并的完整流程
解决MicroBlaze程序启动难题:Vivado中bit与elf文件合并的完整流程 在FPGA开发中,MicroBlaze软核处理器的应用越来越广泛,但许多开发者都会遇到一个共同的痛点:每次下载程序都需要分别加载bit文件和elf文件,这不仅增加了…...

从零到一:基于LLaMA-Factory与Ollama的本地大模型定制化实战
1. 为什么需要本地定制化大模型? 最近两年,大语言模型的发展速度简直让人瞠目结舌。从最初的GPT-3到现在的Llama 3,模型能力越来越强,但随之而来的问题是:这些通用大模型真的能满足我们每个人的特定需求吗?…...

Babylon.js 官方Demo速查手册:按技术点分类的实战预览图+源码直达
Babylon.js 技术全景速查手册:从核心功能到高阶实战 当你第一次打开Babylon.js官网的Demo页面时,可能会被上百个案例晃花了眼。作为一款功能强大的Web3D引擎,它几乎涵盖了从基础渲染到高级特效的所有技术点。但问题来了:当你想实现…...

告别环境混乱:Python3.9镜像实战教程,独立环境管理如此简单
告别环境混乱:Python3.9镜像实战教程,独立环境管理如此简单 1. 为什么需要Python3.9镜像 在Python开发中,最令人头疼的问题莫过于环境冲突。想象一下这样的场景:你正在开发一个需要TensorFlow 2.4的项目,但同时还要维…...

告别纯理论:用OAI 5G开源平台+USRP B210硬件,实测端到端5G SA数据业务
从零构建5G SA实验环境:OAI开源平台与USRP B210实战指南 当5G技术从实验室走向商业化应用时,许多开发者面临一个尴尬的现实:理论知识与实际操作之间存在巨大鸿沟。本文将带你跨越这道鸿沟,使用OAI开源平台和USRP B210软件定义无线…...

阿里开源CosyVoice2-0.5B:快速部署声音克隆应用,小白友好教程
阿里开源CosyVoice2-0.5B:快速部署声音克隆应用,小白友好教程 1. 项目简介与核心能力 CosyVoice2-0.5B是阿里开源的一款轻量级语音克隆工具,专为快速部署和简单使用而设计。这个模型最吸引人的特点是: 3秒极速复刻:…...

终极指南:3分钟掌握原神圣遗物扫描工具Amenoma的完整使用技巧 [特殊字符]
终极指南:3分钟掌握原神圣遗物扫描工具Amenoma的完整使用技巧 🎯 【免费下载链接】Amenoma A simple desktop application to scan and export Genshin Impact Artifacts and Materials. 项目地址: https://gitcode.com/gh_mirrors/am/Amenoma 还…...
)
从WiFi4到WiFi7:一张表格看懂所有代际的真实网速差距(附选购建议)
从WiFi4到WiFi7:四代协议性能全景对比与智能组网决策指南 当你在电商平台搜索"WiFi6路由器"时,超过200款不同价位的设备会瞬间涌入视野。从299元的入门款到4999元的旗舰机型,商家宣传的"AX3000"、"BE6500"等参…...

喜马拉雅音频下载工具:技术实现与高效使用指南
喜马拉雅音频下载工具:技术实现与高效使用指南 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 在数字化学习与娱乐场景…...