Diango项目-简易个人博客项目
-
项目实现功能
- 在admin后台自定义添加上传文档。
- 对展示在首页的文章分页显示。
- 在首页点击文章的阅读全文按钮可进入该文章全文详情页进行浏览。
- 对文章实现了内容分类何以发布时间进行归档分类。
- 使用django的whoose搜索引擎对全文实现内容的搜索。
-
项目涉及技术
Mysql Django Python redis
-
项目核心实现流程
- 确定索要发布的文章展示的样式排版(时间,作者,标签,分类,简介等等),在django的models确定对应的字段形式(注意表与表之间,字段与字段之间的对应关系,一对多OR多对多,比如文章和分类可以实现多对一(一个分类包含多篇文章类型),文章与标签之间是多对多的关系)
- object.get.all()获取数据库的对象内容,在首页的前端页面循环遍历显示即可,至于点击阅读全文按钮进入详情页面在url给定路由后path('page/<int:num>',views.queryAll),我们这里根据点击识别的不同文章的id来获取该文章的内容,
postid = int(postid)
# 根据postid查询帖子的详情信息
post = Post.objects.get(id=postid)然后再详情内容页面讲该文章post.各种字段(分类,简介,内容,时间等等)放在页面对应的变迁文本里即可。 -
分页:使用Django的自带的Pagintor,技术步骤如下结合自己的项目中需要展示的数据库里的数据即可1.导入Paginator类和EmptyPage、PageNotAnInteger异常类; 2.获取需要分页的数据列表; 3.创建Paginator对象,指定每页显示的数据条数; 4.获取当前页码数,如果没有获取到则默认为第一页; 5.获取当前页的数据,如果页码数不是整数或者超出范围则抛出异常; 6.根据总页数决定显示的页码范围; 7.将分页后的数据传递给模板进行渲染
-
对文章的归档(按照类别,时间),
#1.获取分类信息
r_catepost =Post.objects.values('category__cname','category').annotate(c=Count('*')).order_by('-c')
#2.近期文章
r_recpost = Post.objects.all().order_by('-created')[:3]
#3.获取日期归档信息
from django.db import connection
cursor = connection.cursor()
cursor.execute("select created,count('*') c from t_post GROUP BY DATE_FORMAT(created,'%Y-%m') ORDER BY c desc,created desc")
r_filepost = cursor.fetchall()
以上代码用来获取以不同划分特点来获取数据库中的指定内容对象,
分类url:
<a class="category-list-link"
href="/post/category/{{ cp.category }}">{{ cp.category__cname }}</a>
归档url:
<a class="archive-list-link"
href="/post/archive/{{ fp.0|date:'Y' }}/{{ fp.0|date:'m' }}">{{ fp.0|date:'Y年m月' }}</a>
最近文章url(同阅读全文链接地址):<a href="/post/post/{{ rp.id }}" target="_blank">{{ rp.title|truncatechars:10 }}</a>
5.分享,直接调用百度分享的api接口即可:代码如下:
<div class="bdsharebuttonbox"><a href="#" class="bds_more" data-cmd="more"></a><a href="#" class="bds_qzone" data-cmd="qzone"></a><a href="#" class="bds_tsina" data-cmd="tsina"></a><a href="#" class="bds_tqq" data-cmd="tqq"></a><a href="#" class="bds_renren" data-cmd="renren"></a><a href="#" class="bds_weixin" data-cmd="weixin"></a></div><script>window._bd_share_config={"common":{"bdSnsKey":{},"bdText":"","bdMini":"2","bdPic":"","bdStyle":"0","bdSize":"16"},"share":{},"image":{"viewList":["qzone","tsina","tqq","renren","weixin"],"viewText":"分享到:","viewSize":"16"},"selectShare":{"bdContainerClass":null,"bdSelectMiniList":["qzone","tsina","tqq","renren","weixin"]}};with(document)0[(getElementsByTagName('head')[0]||body).appendChild(createElement('script')).src='http://bdimg.share.baidu.com/static/api/js/share.js?v=89860593.js?cdnversion='+~(-new Date()/36e5)];</script></div>6:全局搜索(whoose);
在Django中使用Whoosh搜索需要使用django-haystack模块。首先需要安装django-haystack和Whoosh,可以使用pip install django-haystack Whoosh命令进行安装。安装完成后,需要在settings.py文件中进行配置,包括搜索引擎的类型、路径等信息。接着需要定义搜索的模型,即在哪些模型中进行搜索。最后需要定义搜索视图和模板,即搜索结果的展示方式。具体的使用方法可以参考django-haystack的官方文档
-
项目部分代码:
- 分页:
def queryAll(request, num=1):num = int(num)postList = Post.objects.all().order_by('-created')# 创建分页器对象pageObj = Paginator(postList, 2)# 获取当前页的数据perPageList = pageObj.page(num)# 生成页码数列表# 每页开始页码begin = (num - int(math.ceil(10.0 / 2)))if begin < 1:begin = 1# 每页结束页码end = begin + 9if end > pageObj.num_pages:end = pageObj.num_pagesif end <= 10:begin = 1else:begin = end - 9pageList = range(begin, end + 1)return render(request, 'index.html', {'postList': perPageList, 'pageList': pageList, 'currentNum': num}) - 全局搜索:
#coding=UTF-8 from haystack import indexes from post.models import * import sys # 导入sys模块 sys.setrecursionlimit(3000) # 将默认的递归深度修改为3000 #注意格式(模型类名+Index) class PostIndex(indexes.SearchIndex,indexes.Indexable):text = indexes.CharField(document=True, use_template=True)#给title,content设置索引title = indexes.NgramField(model_attr='title')content = indexes.NgramField(model_attr='content')def get_model(self):return Postdef index_queryset(self, using=None):return self.get_model().objects.order_by('-created')tokenizer.py
#coding=utf-8 import jieba from whoosh.analysis import Tokenizer, Token class ChineseTokenizer(Tokenizer):def __call__(self, value, positions=False, chars=False,keeporiginal=False, removestops=True,start_pos=0, start_char=0, mode='', **kwargs):t = Token(positions, chars, removestops=removestops, mode=mode,**kwargs)seglist = jieba.cut(value, cut_all=False) # (精确模式)使用结巴分词库进行分词# seglist = jieba.cut_for_search(value) #(搜索引擎模式) 使用结巴分词库进行分词for w in seglist:# print wt.original = t.text = wt.boost = 1.0if positions:t.pos = start_pos + value.find(w)if chars:t.startchar = start_char + value.find(w)t.endchar = start_char + value.find(w) + len(w)yield t # 通过生成器返回每个分词的结果tokendef ChineseAnalyzer():return ChineseTokenizer()
-
项目部分截图



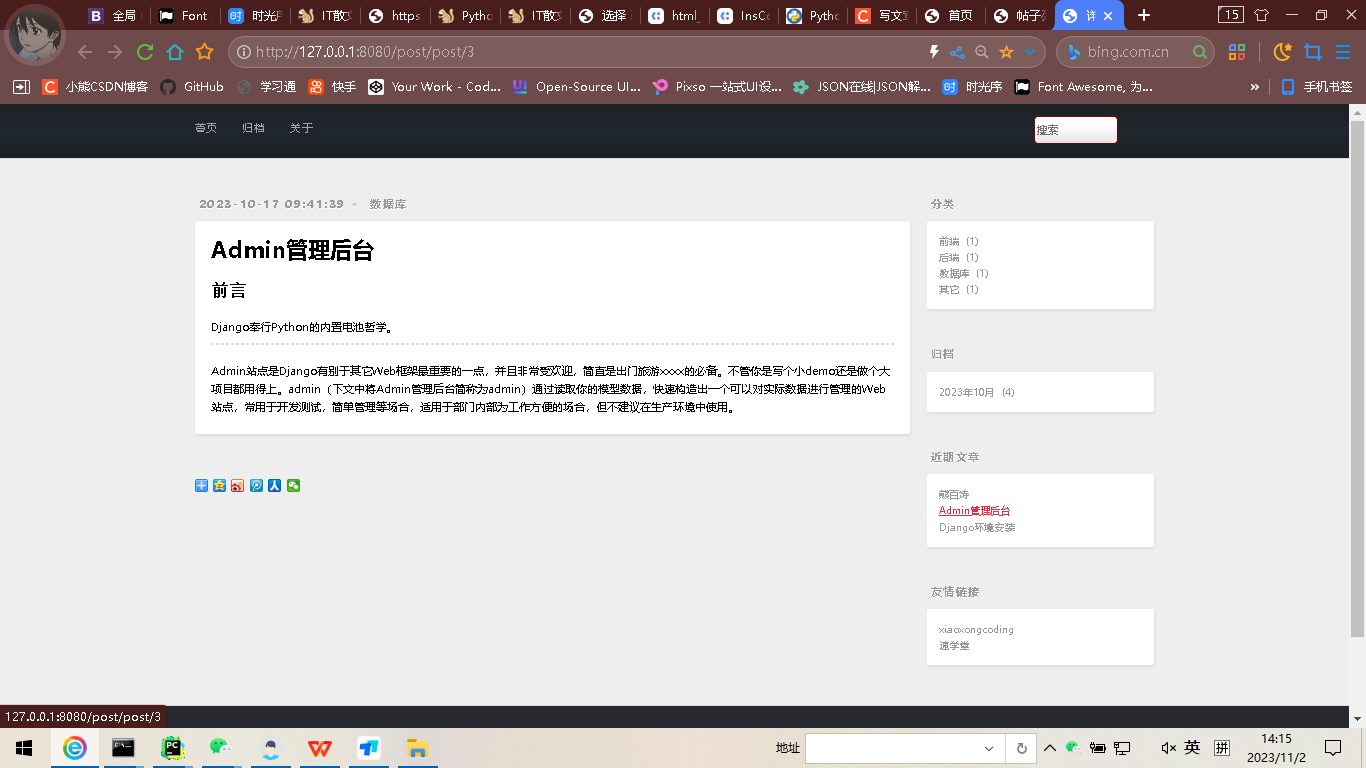
-
结语:
写的有点急,具体内容没有详细写出来,只是简单提了一下,如Pagintor分页的使用以及whoose全局搜索使用等,下次有时间在针对具体技术讲解,这个小项目当时写出来也就是用来回顾一下django的相关技术内容的,写的不好,在此致歉。
相关文章:
Diango项目-简易个人博客项目
项目实现功能 在admin后台自定义添加上传文档。对展示在首页的文章分页显示。在首页点击文章的阅读全文按钮可进入该文章全文详情页进行浏览。对文章实现了内容分类何以发布时间进行归档分类。使用django的whoose搜索引擎对全文实现内容的搜索。 项目涉及技术 Mysql Djan…...

思维训练3
题目描述1 Problem - A - Codeforces 题目分析 样例1解释: 对于此题,我们采用贪心的想法,从1到n块数越少越好,故刚好符合最少的块数即可,由于第1块与第n块是我们必须要走的路,所以我们可以根据这两块砖的…...

初识FFmpeg
前言 无意间见到群里的小伙伴展示视频工具。功能比较多,包括视频编码修改,画质处理,比例处理、名称提取,剪辑、标题拆解。因此开始了FFmpeg学习。以下摘自百度百科的解释。 FFmpeg是一套可以用来记录、转换数字音频、视频…...

分布式多主关系数据库的底线业务优势
当今的应用程序(包括企业应用程序)需要始终开启且始终可用,并且通常必须为全球用户提供服务,这些用户无论身在何处都希望获得几乎即时的响应时间。 应对这些挑战不仅仅意味着让用户更满意:每个能够解决低延迟和超高可…...
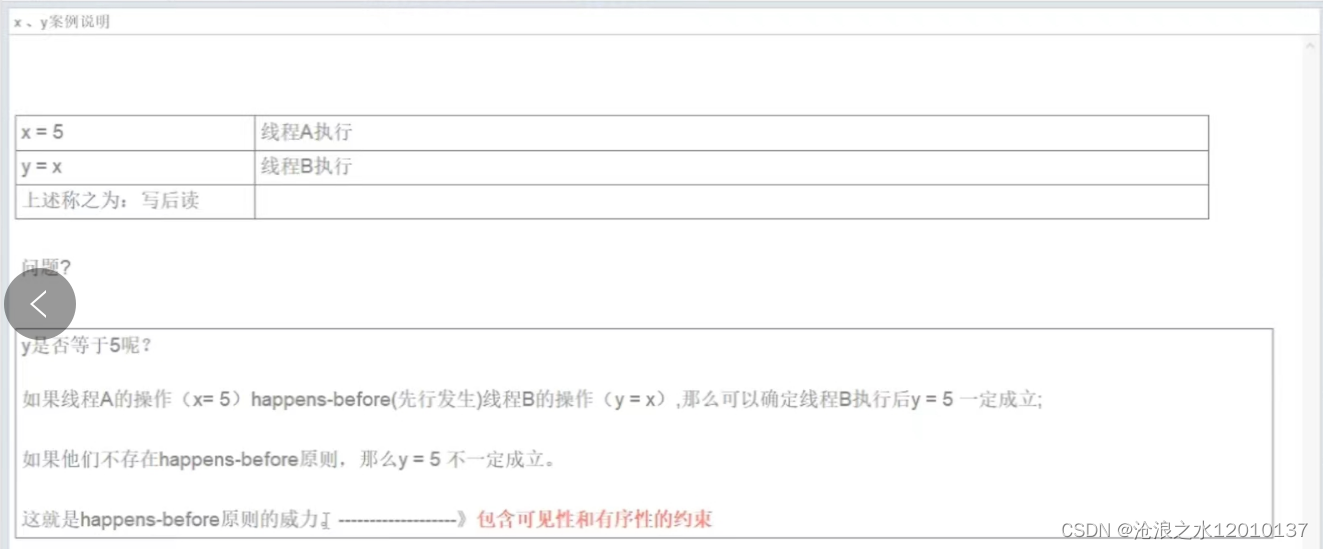
JMM讲解
一:为什么要有JMM,它为什么出现? CPU的运行并不是直接操作内存而是先把内存里面的数据读到缓存,而内存的读和写操作的时候会造成不一致的问题。JVM规范中试图定义一种Java内存模型来屏蔽掉各种硬件和操作系统的内存访问差异&…...
小程序获取头像和昵称的思路
小程序获取头像和昵称的基本方法是调用小程序自带的API wx.getUserProfile(),这也是小程序官方目前最推荐的做法。成功获取用户名头像之后,小程序允许保存调用的结果,以便下一次打开页面的时候自动显示头像和名字。保存用户名和头像并不是保存…...
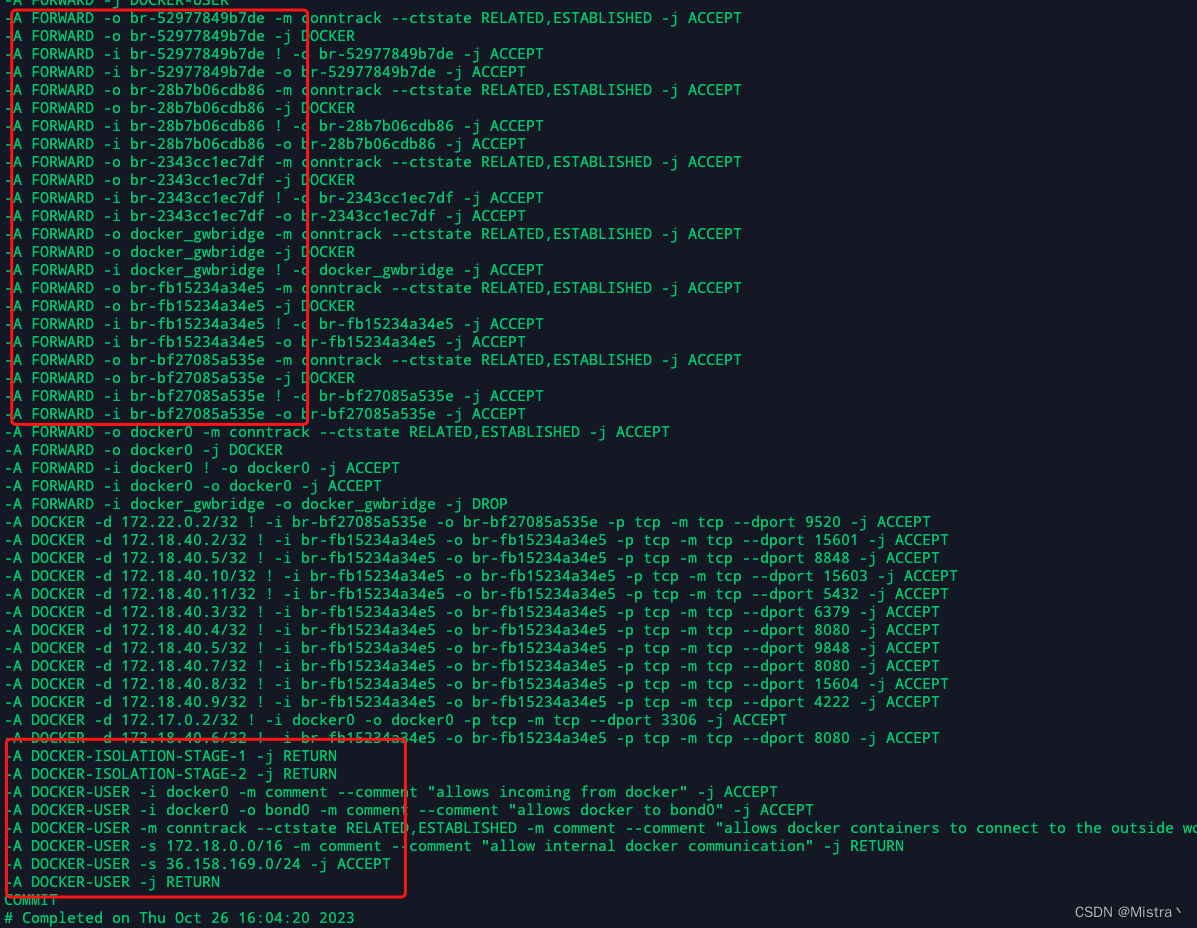
关于docker网络实践中遇到的问题
1.禁用docker自动修改iptables规则 查看docker.service文件/usr/lib/systemd/system/docker.service 默认在宿主机部署容器,映射了端口的话,docker能自己修改iptables规则,把这些端口暴露到公网。 如果要求这些端口不能暴露到公网…...
C#完成XML文档节点的自动计算功能
一个项目涉及XML文档中节点的自动计算,就是XML文档的每个节点都参与运算,要求: ⑴如果节点有计算公式则按照计算公式进行; ⑵如果节点没有计算公式则该节点的值就是所有子节点的值之和; ⑶节点有4种类型,计…...
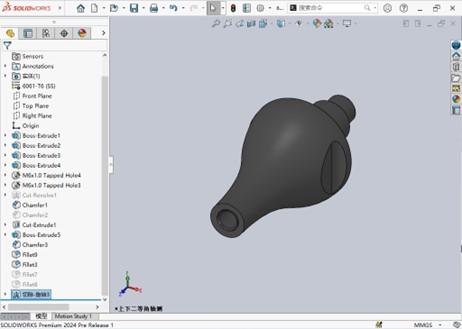
体验SOLIDWORKS旋转反侧切除增强 硕迪科技
大家在设计中经常使用的旋转切除命令在solidworks2024版本中迎来了新的增强,添加了旋转反侧切除选项。在设计过程中不必修改复杂的草图即可切除掉我们不需要的部分。使设计工作更加方便快捷。 打开零部件后,点击键盘上的S键并输入旋转切除以搜索该命令&a…...
)
分布式ID系统设计(3)
分布式ID系统设计第三集 id-service-SnowFlake方案 第二集说了id-service-Segment-DB可以生成趋势递增的ID,但是ID号是可以计算的。不太适用于一些订单ID生成的场景。因为存在数据暴露的风险 比如我可以对比两天的订单ID号来大致计算出公司一天的订单量。这个有点危险。 所以…...

工作备忘录【微信】
这工作备忘录【微信】里写自定义目录标题 unionid获取用户基本信息无 unionid EasyWeChat"overtrue/wechat": "^4.6" 与 "overtrue/wechat": "~3.1" 使用方式有异 unionid 微信 unionid 有关备忘录 获取用户基本信息无 unionid htt…...

Window下SRS服务器的搭建
---2023.7.23 准备材料 srs下载:GitHub - ossrs/srs at 3.0release 目前srs release到5.0版本。 srs官方文档:Introduction | SRS (ossrs.net) Docker下载:Download Docker Desktop | Docker 进入docker官网选择window版本直接下载。由…...

Canvas绘制简易雨滴碰撞效果
实现会动的图形,向下播放多张静态的图片。一秒内要大于屏幕刷新的帧数(60) 也就是每隔1/60s执行一次函数在每次绘制的正方形上添加一个背景色为白色蒙板。 效果图 源代码 <!DOCTYPE html> <html lang"en"><head><meta charset"…...

【五、http】go的http的信息提交
一、post提交的几种 form表单json文件 1、提交表单 //http的postfunc requstPost(){params : make(url.Values)params.Set("name", "kaiyue")params.Set("age", "18")formDataStr : []byte(params.Encode())formDataByte : bytes.N…...

第六讲:VBA与ACCESS的ADO连接中,所涉及的对象
《VBA数据库解决方案》教程(10090845)是我推出的第二套教程,目前已经是第二版修订了。这套教程定位于中级,是学完字典后的另一个专题讲解。数据库是数据处理的利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法和实…...
【计算机网络】同源策略及跨域问题
1. 同源策略 同源策略是一套浏览器安全机制,当一个源的文档和脚本,与另一个源的资源进行通信时,同源策略就会对这个通信做出不同程度的限制。 同源策略对 同源资源 放行,对 异源资源 限制。因此限制造成的开发问题,称…...

uniapp在APP端使用swiper进行页面不卡顿滑动
uniapp在APP端使用swiper进行页面会卡顿,主要是渲染的数据有点多,这里只渲染三个数据就不好那么卡顿了,每次滑动后更新数据 <view><swiper change"changePoint" circular :disable-touch"disableTouch"><…...

遗憾
《遗憾》 文/罗光记 岁月匆匆如梦过, 回首往事泪沾裳。 遗憾犹存心深处, 青春岁月已成伤。...

hustoj 平台
1.大部分功能和选项的开关和参数调整都在配置文件中,安装后几个重要配置文件的位置如下: /home/judge/etc/judge.conf #判题judged/judge_client /home/judge/src/web/include/db_info.inc.php #Web debian-sys-maint gdfNPYOdITxtDEK1 修改MySQl管…...

如何使用Scrapy提取和处理数据
目录 一、安装和设置Scrapy 二、创建爬虫 三、提取数据 四、处理数据 五、存储数据 六、进阶操作 七、注意事项 总结 Scrapy是一个强大且灵活的Python库,用于创建网页爬虫,提取和处理数据。本文将为您深入讲解如何使用Scrapy进行数据处理&#x…...

独立开发者如何借助Taotoken模型广场为应用选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken模型广场为应用选型 对于独立开发者而言,启动一个新项目往往意味着在有限的预算和时间内做…...

Animockup代码实现分析:深入理解Canvas录制和视频转换技术
Animockup代码实现分析:深入理解Canvas录制和视频转换技术 【免费下载链接】animockup Create animated mockups in the browser 🔥 项目地址: https://gitcode.com/gh_mirrors/an/animockup Animockup是一个强大的开源项目,它允许用户…...

深入解析ACP Bridge:构建高效微服务通信与数据同步的协议转换桥梁
1. 项目概述与核心价值最近在折腾一个跨平台数据同步的项目,遇到了一个挺有意思的组件——allvegetable/acp-bridge。乍一看这个名字,可能会有点摸不着头脑,acp是什么?bridge又在这里扮演什么角色?实际上,这…...

别再只盯着X16了!深入聊聊M.2、Mini-PCIE这些‘变种’接口的电路设计异同与选型指南
别再只盯着X16了!深入聊聊M.2、Mini-PCIE这些‘变种’接口的电路设计异同与选型指南 在高速接口的世界里,X16规格的PCIe插槽往往占据着聚光灯下的位置。但当我们把视线转向紧凑型设备、嵌入式系统或高性能存储解决方案时,M.2和Mini-PCIe这些&…...
)
告别RaiDrive广告!用rclone+Alist免费打造Windows云盘本地文件夹(含开机自启脚本)
开源云盘本地化方案:Alist与rclone的无缝整合指南 在数字资产管理日益重要的今天,云存储已成为个人和企业不可或缺的工具。然而,商业软件的广告推送、订阅费用和功能限制常常让用户感到困扰。本文将介绍一套完全开源、零成本的解决方案&#…...

明日方舟自动化:用MAA重构你的游戏体验,告别重复劳动
明日方舟自动化:用MAA重构你的游戏体验,告别重复劳动 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: h…...

两阶段目标检测器核心原理与流程详解
两阶段目标检测器的核心思想是:第一阶段先找候选区域,第二阶段再对候选区域做分类和精修。典型代表是: R-CNN Fast R-CNN Faster R-CNN Mask R-CNN现在最典型的是 Faster R-CNN / Mask R-CNN,所以我以它为主来讲。1. 两阶段目标检…...

物业临时工考勤记录管理痛点与栎偲考勤神器技术实现方案
物业行业临时工考勤一直是HR管理的“老大难”:人员流动性大、班次碎片化(如早班/晚班/临时替班)、外勤打卡场景多(如园区巡检、设备维修),传统Excel统计不仅耗时,还常因数据错漏引发薪资纠纷。本…...

对比直接使用官方API,体验通过Taotoken进行多模型选型与切换的便捷性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API,体验通过Taotoken进行多模型选型与切换的便捷性 在实际的开发工作中,我们常常需要根据…...

车载ETH数据链路层
以太网帧协议是数据链路层的核心封装格式,遵循IEEE 802.3标准。 标准以太网帧结构(IEEE 802.3): 前导码(7B)| 帧起始符(1B)| 目标 MAC (6B) | 源 MAC (6B) | EtherType (2B) | Payload (46-1500B) | FCS (4B) | 1. 前导码 (Preamble) 长度…...