持续进化,快速转录,Faster-Whisper对视频进行双语字幕转录实践(Python3.10)
Faster-Whisper是Whisper开源后的第三方进化版本,它对原始的 Whisper 模型结构进行了改进和优化。这包括减少模型的层数、减少参数量、简化模型结构等,从而减少了计算量和内存消耗,提高了推理速度,与此同时,Faster-Whisper也改进了推理算法、优化计算过程、减少冗余计算等,用以提高模型的运行效率。
本次我们利用Faster-Whisper对日语视频进行双语(日语/国语)转录实践,看看效率如何。
构建Faster-Whisper转录环境
首先确保本地已经安装好Python3.10版本以上的开发环境,随后克隆项目:
git clone https://github.com/ycyy/faster-whisper-webui.git
进入项目的目录:
cd faster-whisper-webui
安装项目依赖:
pip3 install -r requirements.txt
这里需要注意的是,除了基础依赖,还得再装一下faster-whisper依赖:
pip3 install -r requirements-fasterWhisper.txt
如此,转录速度会更快。
模型的下载和配置
首先在项目的目录建立模型文件夹:
mkdir Models
faster-whisper项目内部已经整合了VAD算法,VAD是一种音频活动检测的算法,它可以准确的把音频中的每一句话分离开来,并且让whisper更精准的定位语音开始和结束的位置。
所有首先需要配置VAD模型:
git clone https://github.com/snakers4/silero-vad
然后将克隆下来的vad模型放入刚刚建立的Models文件夹中即可。
接着下载faster-whisper模型,下载地址:
https://huggingface.co/guillaumekln/faster-whisper-large-v2
这里建议只下载faster-whisper-large-v2模型,也就是大模型的第二版,因为faster-whisper本来就比whisper快,所以使用large模型优势就会更加的明显。
模型放入models文件夹的faster-whisper目录,最终目录结构如下:
models
├─faster-whisper
│ ├─large-v2
└─silero-vad ├─examples │ ├─cpp │ ├─microphone_and_webRTC_integration │ └─pyaudio-streaming ├─files └─__pycache__
至此,模型就配置好了。
本地推理进行转录
现在,我们可以试一试faster-whisper的效果了,以「原神」神里绫华日语视频:《谁能拒绝一只蝴蝶忍呢?》为例子,原视频地址:
https://www.bilibili.com/video/BV1fG4y1b74e/
项目根目录运行命令:
python cli.py --model large-v2 --vad silero-vad --language Japanese --output_dir d:/whisper_model d:/Downloads/test.mp4
这里–model指定large-v2模型,–vad算法使用silero-vad,–language语言指定日语,输出目录为d:/whisper_model,转录视频是d:/Downloads/test.mp4。
程序输出:
D:\work\faster-whisper-webui>python cli.py --model large-v2 --vad silero-vad --language Japanese --output_dir d:/whisper_model d:/Downloads/test.mp4
Using faster-whisper for Whisper
[Auto parallel] Using GPU devices ['0'] and 8 CPU cores for VAD/transcription.
Creating whisper container for faster-whisper
Using parallel devices: ['0']
Created Silerio model
Parallel VAD: Executing chunk from 0 to 74.071224 on CPU device 0
Loaded Silerio model from cache.
Getting timestamps from audio file: d:/Downloads/test.mp4, start: 0, duration: 74.071224
Processing VAD in chunk from 00:00.000 to 01:14.071
C:\Users\zcxey\AppData\Roaming\Python\Python310\site-packages\torch\nn\modules\module.py:1501: UserWarning: operator () profile_node %669 : int[] = prim::profile_ivalue(%667) does not have profile information (Triggered internally at ..\third_party\nvfuser\csrc\graph_fuser.cpp:108.) return forward_call(*args, **kwargs)
VAD processing took 2.474104000022635 seconds
Transcribing non-speech:
[{'end': 75.071224, 'start': 0.0}]
Parallel VAD processing took 8.857761900057085 seconds
Device 0 (index 0) has 1 segments
Using device 0
(get_merged_timestamps) Using override timestamps of size 1
Processing timestamps:
[{'end': 75.071224, 'start': 0.0}]
Running whisper from 00:00.000 to 01:15.071 , duration: 75.071224 expanded: 0 prompt: None language: None
Loading faster whisper model large-v2 for device None
WARNING: fp16 option is ignored by faster-whisper - use compute_type instead.
[00:00:00.000->00:00:03.200] 稲妻神里流 太刀術免許開伝
[00:00:03.200->00:00:04.500] 神里綾香
[00:00:04.500->00:00:05.500] 参ります!
[00:00:06.600->00:00:08.200] よろしくお願いします
[00:00:08.200->00:00:12.600] こののどかな時間がもっと増えると嬉しいのですが
[00:00:13.600->00:00:15.900] 私って欲張りですね
[00:00:15.900->00:00:18.100] 神里家の宿命や
[00:00:18.100->00:00:19.900] 社部業の重りは
[00:00:19.900->00:00:23.600] お兄様が一人で背負うべきものではありません
[00:00:23.600->00:00:27.700] 多くの方々が私を継承してくださるのは
[00:00:27.700->00:00:30.900] 私を白鷺の姫君や
[00:00:30.900->00:00:34.600] 社部業神里家の霊嬢として見ているからです
[00:00:34.600->00:00:38.500] 彼らが継承しているのは私の立場であって
[00:00:38.500->00:00:41.700] 綾香という一戸人とは関係ございません
[00:00:41.700->00:00:43.400] 今の私は
[00:00:43.400->00:00:47.300] 皆さんから信頼される人になりたいと思っています
[00:00:47.300->00:00:49.700] その気持ちを鼓舞するものは
[00:00:49.700->00:00:52.300] 肩にのしかかる銃石でも
[00:00:52.300->00:00:54.800] 他人からの期待でもございません
[00:00:54.800->00:00:56.700] あなたがすでに
[00:00:56.800->00:00:58.800] そのようなお方だからです
[00:00:58.800->00:01:00.500] 今から言うことは
[00:01:00.500->00:01:03.900] 稲妻幕府社部業神里家の肩書きに
[00:01:03.900->00:01:06.200] ふさわしくないものかもしれません
[00:01:06.200->00:01:11.100] あなたは私のわがままを受け入れてくださる方だと信じています
[00:01:11.100->00:01:12.500] 神里流
[00:01:12.500->00:01:14.000] 壮烈
Whisper took 22.232674299972132 seconds
Parallel transcription took 31.472856600070372 seconds
Max line width 80
Closing parallel contexts
Closing pool of 1 processes
Closing pool of 8 processes
可以看到,1分14秒的视频,vad用了8秒,whisper用了22秒,转录一共用了31秒。
注意,这里只是用了whisper原版的算法,现在我们添加–whisper_implementation faster-whisper参数来使用faster-whisper改进后的算法:
python cli.py --whisper_implementation faster-whisper --model large-v2 --vad silero-vad --language Japanese --output_dir d:/whisper_model d:/Downloads/test.mp4
程序返回:
Running whisper from 00:00.000 to 01:15.071 , duration: 75.071224 expanded: 0 prompt: None language: None
Loading faster whisper model large-v2 for device None
WARNING: fp16 option is ignored by faster-whisper - use compute_type instead.
[00:00:00.000->00:00:03.200] 稲妻神里流 太刀術免許開伝
[00:00:03.200->00:00:04.500] 神里綾香
[00:00:04.500->00:00:05.500] 参ります!
[00:00:06.600->00:00:08.200] よろしくお願いします
[00:00:08.200->00:00:12.600] こののどかな時間がもっと増えると嬉しいのですが
[00:00:13.600->00:00:15.900] 私って欲張りですね
[00:00:15.900->00:00:18.100] 神里家の宿命や
[00:00:18.100->00:00:19.900] 社部業の重りは
[00:00:19.900->00:00:23.600] お兄様が一人で背負うべきものではありません
[00:00:23.600->00:00:27.700] 多くの方々が私を継承してくださるのは
[00:00:27.700->00:00:30.900] 私を白鷺の姫君や
[00:00:30.900->00:00:34.600] 社部業神里家の霊嬢として見ているからです
[00:00:34.600->00:00:38.500] 彼らが継承しているのは私の立場であって
[00:00:38.500->00:00:41.700] 綾香という一戸人とは関係ございません
[00:00:41.700->00:00:43.400] 今の私は
[00:00:43.400->00:00:47.300] 皆さんから信頼される人になりたいと思っています
[00:00:47.300->00:00:49.700] その気持ちを鼓舞するものは
[00:00:49.700->00:00:52.300] 肩にのしかかる銃石でも
[00:00:52.300->00:00:54.800] 他人からの期待でもございません
[00:00:54.800->00:00:56.700] あなたがすでに
[00:00:56.800->00:00:58.800] そのようなお方だからです
[00:00:58.800->00:01:00.500] 今から言うことは
[00:01:00.500->00:01:03.900] 稲妻幕府社部業神里家の肩書きに
[00:01:03.900->00:01:06.200] ふさわしくないものかもしれません
[00:01:06.200->00:01:11.100] あなたは私のわがままを受け入れてくださる方だと信じています
[00:01:11.100->00:01:12.500] 神里流
[00:01:12.500->00:01:14.000] 壮烈
Whisper took 10.779123099986464 seconds
Parallel transcription took 11.567014200030826 seconds
大模型只用了10秒,这效率,绝了。
中文字幕
在以往的Whisper模型中,如果我们需要中文字幕,需要通过参数–task translate翻译成英文,然后再通过第三方的翻译接口将英文翻译成中文,再手动匹配字幕效果,比较麻烦。
现在,我们只需要将语言直接设置为中文即可,程序会进行自动翻译:
python cli.py --whisper_implementation faster-whisper --model large-v2 --vad silero-vad --language Chinese --output_dir d:/whisper_model d:/Downloads/test.mp4
这里的–language参数改为Chinese。
程序返回:
Running whisper from 00:00.000 to 01:15.071 , duration: 75.071224 expanded: 0 prompt: None language: None
Loading faster whisper model large-v2 for device None
WARNING: fp16 option is ignored by faster-whisper - use compute_type instead.
[00:00:00.000->00:00:03.200] 稲妻神里流太刀術免許改練
[00:00:03.200->00:00:04.400] 神里綾香
[00:00:04.400->00:00:05.400] 來吧
[00:00:06.600->00:00:08.200] 請多多指教
[00:00:08.200->00:00:12.600] 希望能有更多的這段寂靜的時間
[00:00:13.600->00:00:15.800] 我真是太有興趣了
[00:00:15.800->00:00:20.000] 神里家的宿命和社部行的重量
[00:00:20.000->00:00:23.600] 不應該由哥哥一個人承擔
[00:00:23.600->00:00:27.400] 很多人都敬重我
[00:00:27.600->00:00:28.800] 是因為他們把我視為
[00:00:28.800->00:00:34.600] 神里家的宿命和社部行的重量
[00:00:34.600->00:00:38.600] 他們敬重的是我的立場
[00:00:38.600->00:00:41.800] 與我自己的身分無關
[00:00:41.800->00:00:43.400] 現在的我
[00:00:43.400->00:00:47.400] 是想成為大家信任的一個人
[00:00:47.400->00:00:49.800] 那些敬重我的人
[00:00:49.800->00:00:52.400] 無論是肩上的重石
[00:00:52.400->00:00:54.800] 或是別人的機器
[00:00:54.800->00:00:58.800] 都是因為你已經是這樣的一個人
[00:00:58.800->00:01:00.400] 我現在要說的話
[00:01:00.400->00:01:03.800] 可能不適合
[00:01:03.800->00:01:06.200] 神里家的宿命和社部行
[00:01:06.200->00:01:11.000] 但我相信你能接受我的自私
[00:01:11.000->00:01:12.400] 神里流
[00:01:12.400->00:01:14.000] 消滅
Whisper took 18.85215839999728 seconds
字幕就已经是中文了,注意转录+翻译一共花了18秒,时间成本比直接转录要高。
双语字幕效果:

结语
由于 Faster-Whisper 的速度更快,它可以扩展到更多的应用领域,包括实时场景和大规模的数据处理任务。这使得 Faster-Whisper 在语音识别、自然语言处理、机器翻译、智能对话等领域中具有更广泛的应用潜力,当然了,更重要的是,当您的电脑里D盘中的爱情片还没有中文字幕时,您当然知道现在该做些什么了。
相关文章:
持续进化,快速转录,Faster-Whisper对视频进行双语字幕转录实践(Python3.10)
Faster-Whisper是Whisper开源后的第三方进化版本,它对原始的 Whisper 模型结构进行了改进和优化。这包括减少模型的层数、减少参数量、简化模型结构等,从而减少了计算量和内存消耗,提高了推理速度,与此同时,Faster-Whi…...
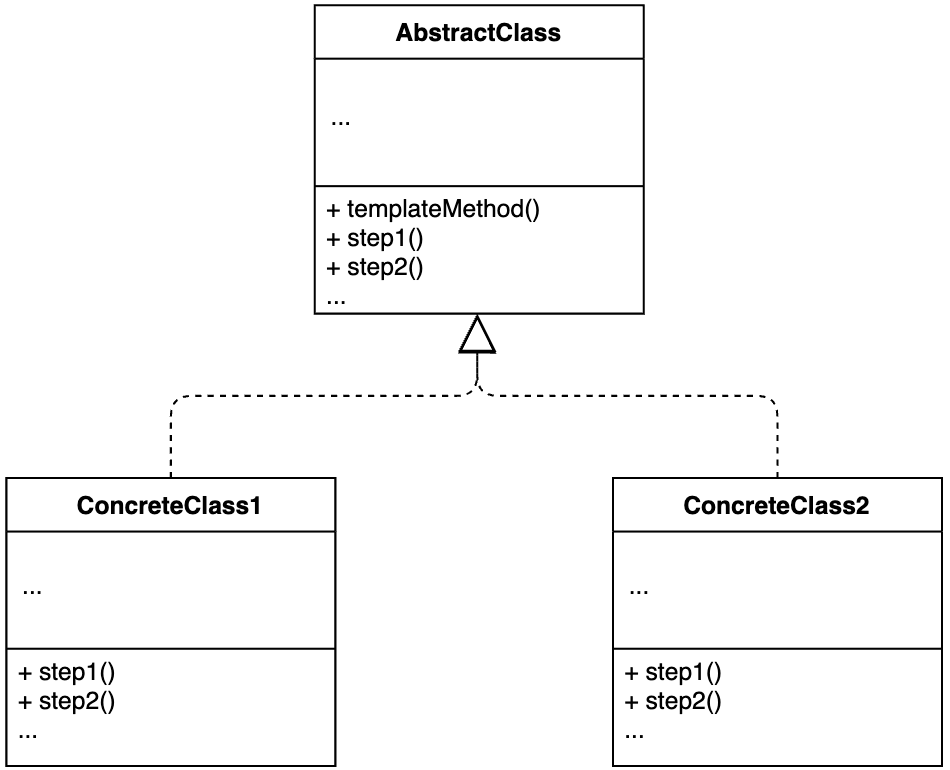
【设计模式】第24节:行为型模式之“模板方法模式”
一、简介 模板方法模式在一个方法中定义一个算法骨架,并将某些步骤推迟到子类中实现。模板方法模式可以让子类在不改变算法整体结构的情况下,重新定义算法中的某些步骤。 模板模式有两大作用:复用和扩展。其中,复用指的是&#…...
| 线代及概率论部分)
【考研数学】数学“背诵手册”(二)| 线代及概率论部分
文章目录 引言二、线代施密特正交化分块矩阵转置、逆、伴随之间的运算关于秩定义性质 三、概统常见分布的期望及方差 引言 这数一全部内容太多了,放在一篇文章里的话,要编辑就很困难,就把线代和概率放在这篇文章里吧。 二、线代 施密特正交…...
)
Android WMS——WindowState介绍(十三)
前面文章中的 addWindow 方法,首先获取了 DisplayContent,紧接着判断窗口的 type 类型并标记。然后获取 token 信息,且该信息是通过 DisplayContent 中的方法获取的。最后就是创建并保存 WindowState 信息。 一、简介 在窗口管理系统(Window Manager Service,WMS)中,Wi…...
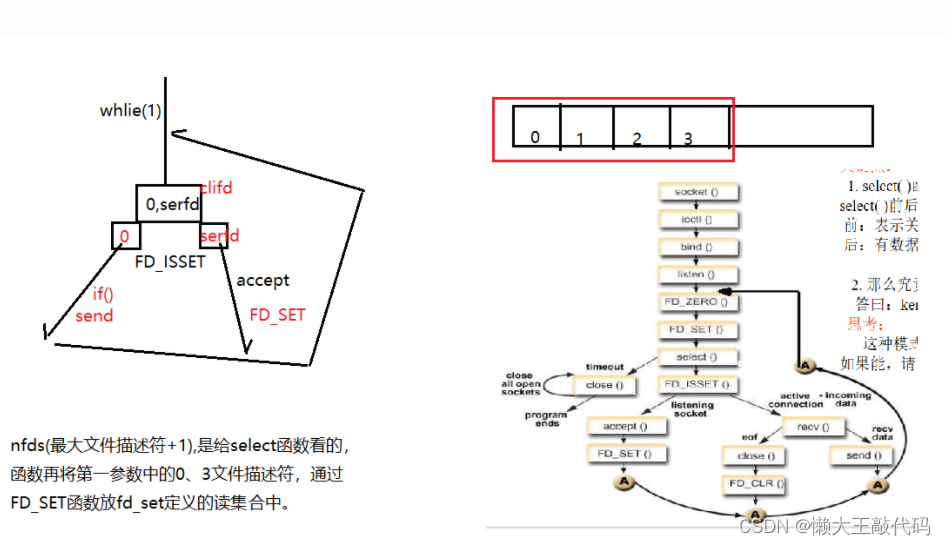
C/C++网络编程基础知识超详细讲解第二部分(系统性学习day12)
懒大王感谢大家的关注和三连支持~ 目录 前言 一、UDP编程 UDP特点: UDP框架: UDP函数学习 发送端代码案例如下: 二、多路复用 前提讲述 select poll 三、图解如下 总结 前言 作者简介: 懒大王敲代码,…...

【教3妹学编程-算法题】117. 填充每个节点的下一个右侧节点指针 II
2哥 : 3妹,听说你昨天去面试了,怎么样啊? 3妹:嗨,别提了,让我回去等通知,估计是没有通知了, 还浪费我请了一天假。 2哥 : 你又请假了啊, 你是怎么跟你那个严厉的老板请假…...
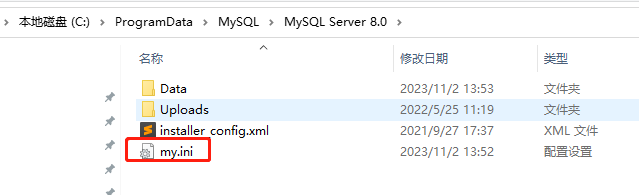
window10 mysql8.0 修改端口port不生效
mysql的默认端口是3306,我想修改成3307。 查了一下资料,基本上都是说先进入C:\Program Files\MySQL\MySQL Server 8.0这个目录。 看看有没有my.ini,没有就新建。 我这里没有,就新建一个,然后修改port: […...
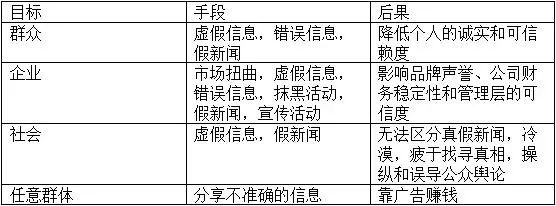
欧盟网络安全威胁:虚假与错误信息
如今,数字平台已是新闻媒体的主战地。社交网站、新闻媒体、甚至搜索引擎都是现在大多数人的信息来源。由于这些网站的运作方式是通过吸引人们来产生网站流量,这些抓人眼球的信息通常是推广广告,有些甚至没有经过审查。 国际现状 恶意攻击者现…...
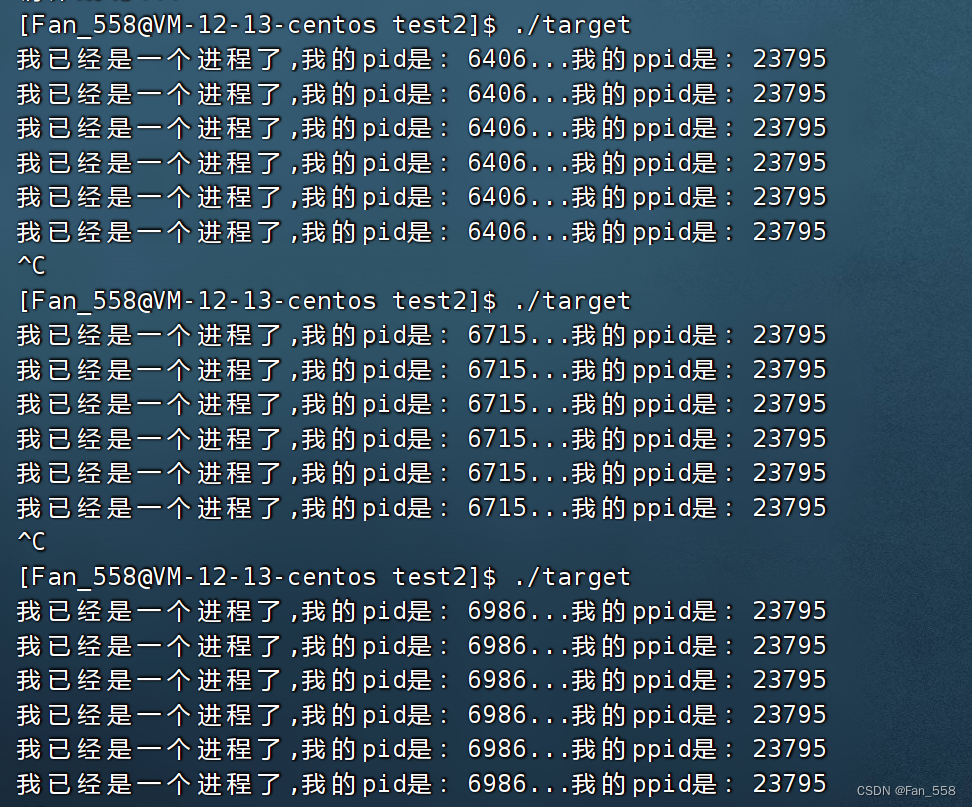
006 Linux 进程的概念 | 获取进程的PID
前言 本文将会向您进程的概念,程序与进程的区别,如何获取进程的标识符-pid 文章重点 1.描述进程——PCB 进程与程序的区别 CPU对进程列表的处理 2.获取进程PID 描述进程-PCB 进程概念 课本概念:程序的一个执行实例或正在执行的程序 内核…...
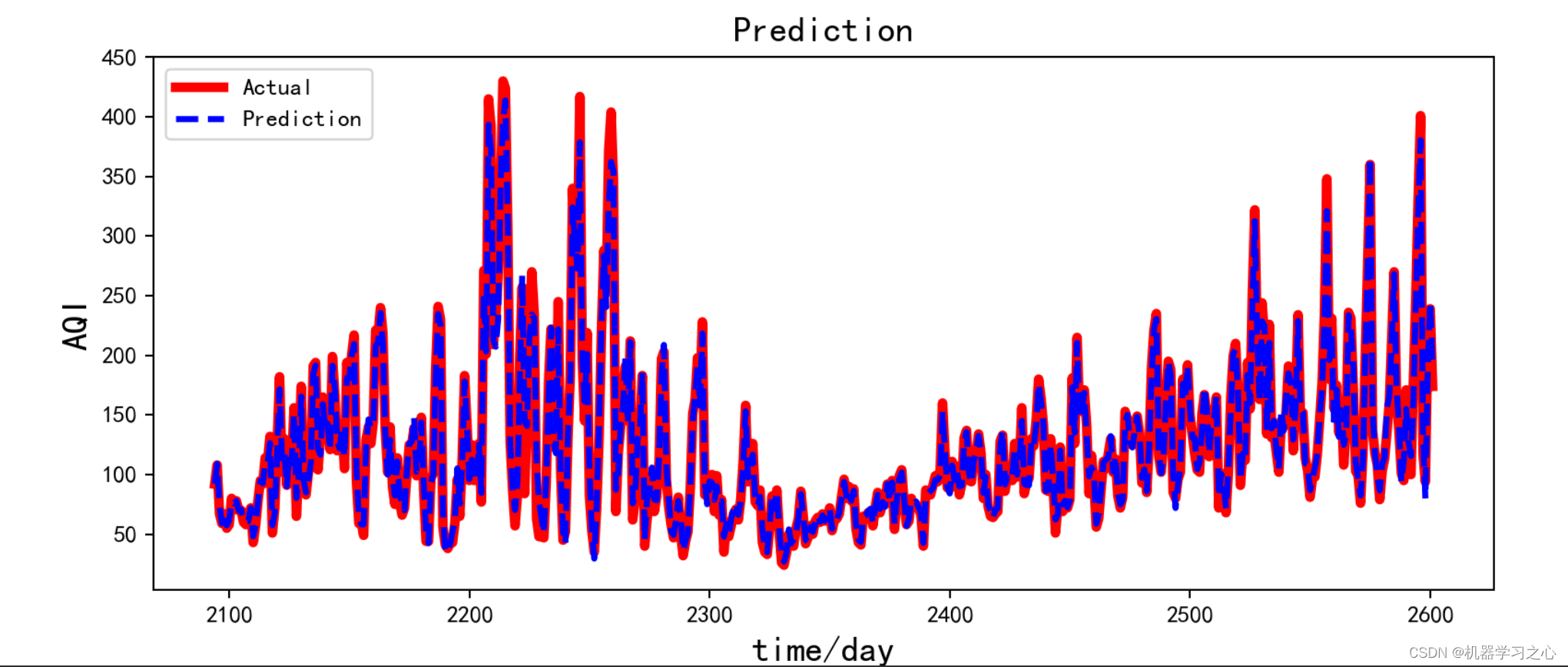
时序预测 | Python实现ARIMA-CNN-LSTM差分自回归移动平均模型结合卷积长短期记忆神经网络时间序列预测
时序预测 | Python实现ARIMA-CNN-LSTM差分自回归移动平均模型结合卷积长短期记忆神经网络时间序列预测 目录 时序预测 | Python实现ARIMA-CNN-LSTM差分自回归移动平均模型结合卷积长短期记忆神经网络时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 时序预测 …...

《异常检测——从经典算法到深度学习》23 TimesNet: 用于常规时间序列分析的时间二维变化模型
zz# 《异常检测——从经典算法到深度学习》 0 概论1 基于隔离森林的异常检测算法 2 基于LOF的异常检测算法3 基于One-Class SVM的异常检测算法4 基于高斯概率密度异常检测算法5 Opprentice——异常检测经典算法最终篇6 基于重构概率的 VAE 异常检测7 基于条件VAE异常检测8 Don…...
)
计算机网络(59)
1. OSI 的七层模型分别是?各自的功能是什么? 2. 为什么需要三次握手?两次不行? 3. 为什么需要四次挥手?三次不行? 4. TCP与UDP有哪些区别?各自应用场景? 5. HTTP1.0,1.1&…...
【CSS】CSS基础知识扫盲
1、 什么是CSS? CSS即层叠样式表 (Cascading Style Sheets). CSS 能够对网页中元素位置的排版进行像素级精确控制, 实现美化页面的效果. 能够做到页面的样式和结构分离 2、 CSS引入方式 CSS代码编写的时候有多种引入方式: 内部样式、外部样式、内联样…...

React中的状态管理
目录 前言 1. React中的状态管理 1.1 本地状态管理 1.2 全局状态管理 Redux React Context 2. React状态管理的优势 总结 前言 当谈到前端开发中的状态管理时,React是一个备受推崇的选择。React的状态管理机制被广泛应用于构建大型、复杂的应用程序…...

【优选算法系列】【专题九链表】第一节.链表常用技巧和操作总结(2. 两数相加)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、链表常用技巧和操作总结二、两数相加 2.1 题目描述 2.2 题目解析 2.2.1 算法原理 2.2.2 代码编写总结 前言 一、链表常…...
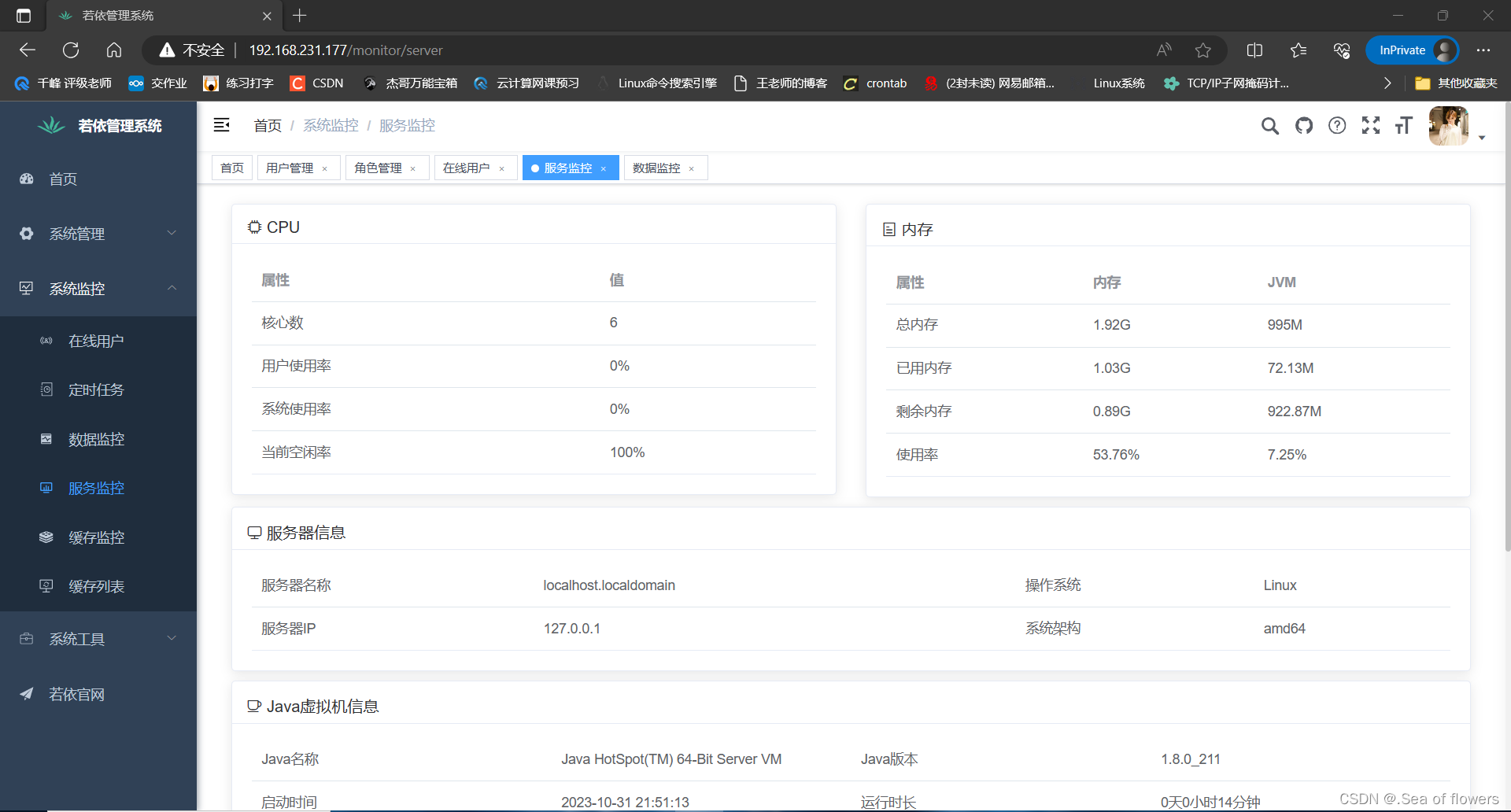
上线Spring boot-若依项目
基础环境 所有环境皆关闭防火墙与selinux 服务器功能主机IP主机名服务名称配置前端服务器192.168.231.177nginxnginx1C2G后端服务器代码打包192.168.231.178javajava、maven、nodejs4C8G数据库/缓存192.168.231.179dbmysql、redis2C4G Nginx #配置Nginxyum源 [rootnginx ~]…...
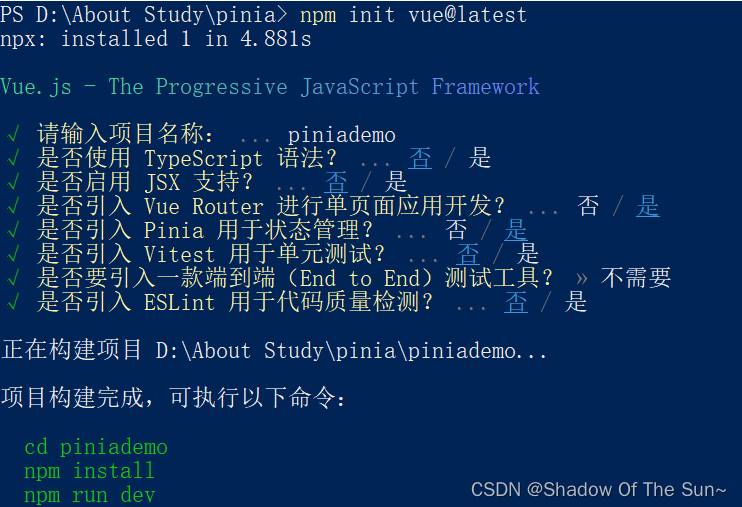
pinia简单使用
新命令-创建vue3项目 vue create 方式使用脚手架创建项目,vue cli处理, vue3后新的脚手架工具create-vue 使用npm init vuelatest 命令创建即可。 在pinia中,将使用的组合式函数识别为状态管理内容 自动将ref 识别为stste,computed 相当于 ge…...
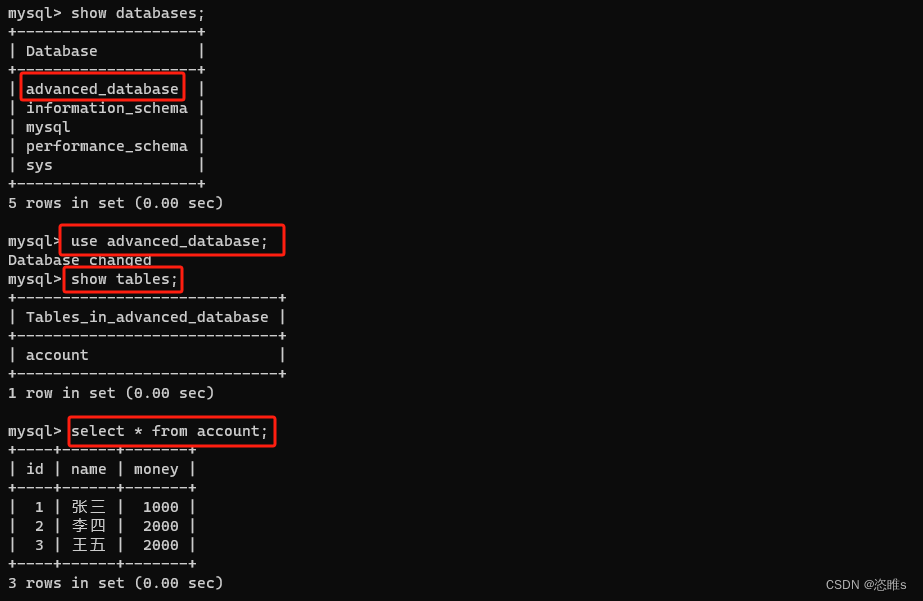
数据库进阶教学——数据库故障恢复(日志文件)
目录 一、日志简介 二、日志文件操作 1、查看日志状态 2、开启日志功能 3、查看日志文件 4、查看当前日志 5、查看日志中的事件 6、删除日志文件 7、查看和修改日志文件有效期 8、查看日志文件详细信息 三、删除的数据库恢复 一、日志简介 日志是记录所有数据库表结…...
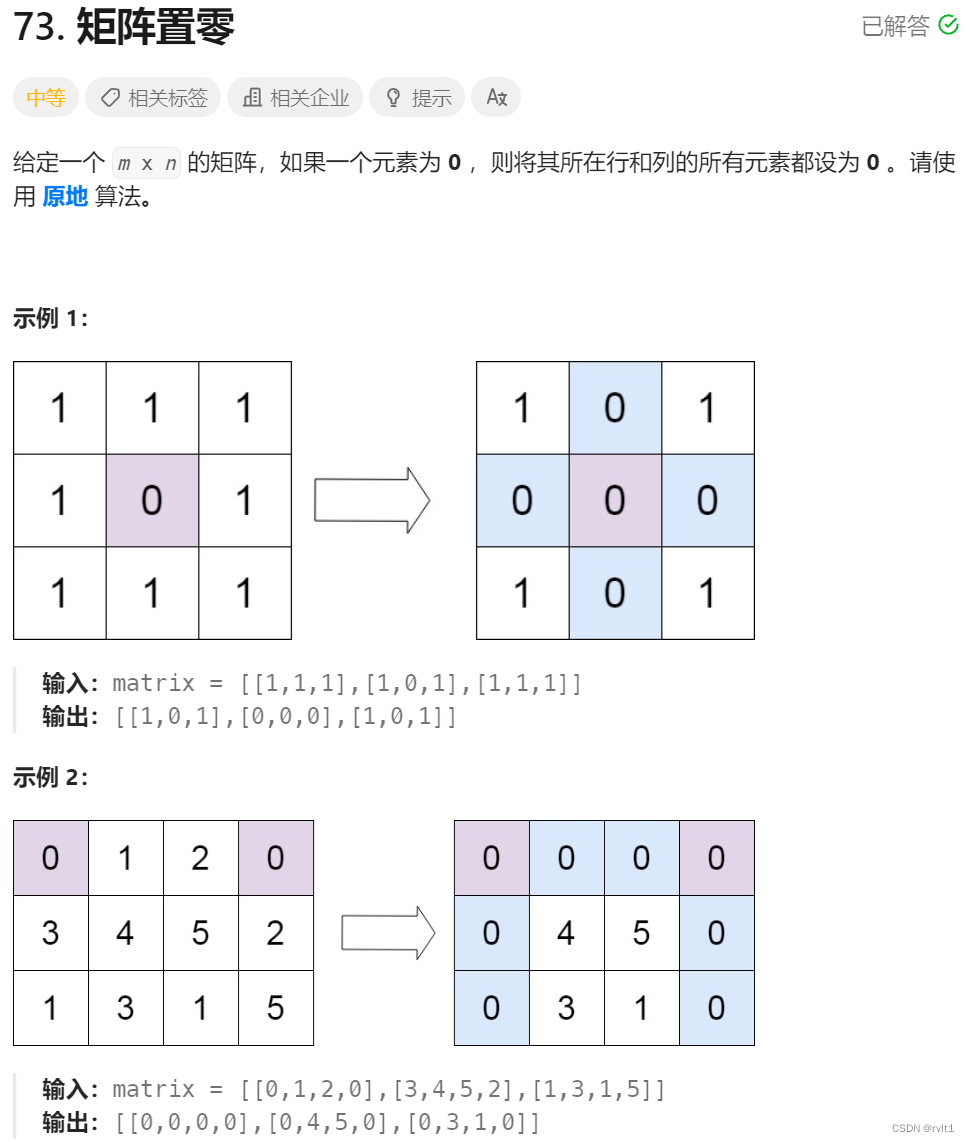
Leetcode 73 矩阵置0
class Solution {//1.用矩阵的第一行和第一列来标记该行或该列是否应该为0,但是这样的话忽视了第一行或第一列为0的情况//2.用标记row0和column0来标记第一行或第一列是否该为0public void setZeroes(int[][] matrix) {int n matrix.length;int m matrix[0].length;boolean r…...

Rust学习日记(二)变量的使用--结合--温度换算/斐波那契数列--实例
前言: 这是一个系列的学习笔记,会将笔者学习Rust语言的心得记录。 当然,这并非是流水账似的记录,而是结合实际程序项目的记录,如果你也对Rust感兴趣,那么我们可以一起交流探讨,使用Rust来构建程…...

本地Perplexity服务突然中断?:排查systemd服务崩溃、GPU显存溢出与模型权重校验失败的5分钟应急清单
更多请点击: https://codechina.net 第一章:Perplexity本地服务查询 Perplexity 作为一款强调实时信息溯源与多源验证的 AI 助手,其官方未提供公开的本地化部署方案。但开发者可通过构建轻量级本地代理服务,模拟 Perplexity 的查…...

【笔记】旧AI,新人类
AI擅长"旧",人类擅长"新" 关于人机分工的一点思考 不久前,一场颇具戏剧性的"人机对决"在餐饮界引起了不小的波澜。"美膳狮"智能炒菜机器人与湘菜厨师杨孙同台竞技,共同炒制三道菜:XO酱笋…...

告别驱动烦恼:用TI官方CCS开发MSP430,为什么比第三方IAR更省心?
嵌入式开发者的效率革命:为什么TI官方CCS是MSP430开发的最优解? 在嵌入式开发领域,工具链的选择往往决定了项目的启动速度和开发体验。对于MSP430系列微控制器的开发者而言,面对IAR、GCC和TI官方的Code Composer Studio(CCS)等多种…...

LabVIEW项目实战:用‘类+队列’模式管理仪器参数,告别全局变量混乱
LabVIEW工程实践:基于类与队列的仪器参数管理框架设计 在工业自动化测试系统中,仪器参数管理一直是困扰工程师的典型难题。当系统需要同时控制网口、串口、GPIB等多种接口的测试设备时,传统的全局变量方案会导致参数耦合、修改不同步等问题。…...

【2026】知云文献翻译安装使用指南:学术PDF划选即译,研究生必备工具
读英文文献最烦的不是词汇,是格式。复制到翻译软件,格式全乱、公式变问号、图注和正文混在一起。知云文献翻译的解法是直接在PDF里划选翻译,格式不动,原文译文左右对照,不用来回切换窗口。 这篇从安装到核心功能配置一…...

别让严谨变成AI味!实测5大主流降AI工具,这款能完美保留原格式
最近看了一些行业报告,AI工具在写作方面的普及率真的已经超乎想象了。 很多大学生在写论文时也都习惯用AI来辅助寻找灵感、提高效率。 与此同时,相关部门针对人工智能写作出台了一系列规定,各大学术检测平台也都在不断升级AIGC检测算法。 现…...

RT-Thread实战:基于STM32与软件I2C的IST8310磁力计驱动开发与模块化设计
1. 项目概述与设计思路在RoboMaster这类对实时性和可靠性要求极高的机器人竞赛中,电控系统的稳定与高效是取胜的基石。很多队伍在初期会选择裸机开发,但随着功能模块的增加,任务调度、资源管理、驱动适配等问题会迅速让代码变得臃肿且难以维护…...
)
STD算法实战:用Python从零复现激光SLAM中的“稳定三角形”回环检测(附代码)
STD算法实战:用Python从零复现激光SLAM中的“稳定三角形”回环检测 激光SLAM技术正在重新定义机器人导航的精度上限,而回环检测作为其核心模块,直接决定了建图与定位的长期稳定性。传统基于点云局部特征的方案在视角变化场景中表现欠佳&#…...

2026 酒店无人直播服务商推荐:警惕一次性收费陷阱,用心服务才是核心
"一次购买,无任何后续费用!"—— 这样的宣传语让不少酒店经营者心动不已,以为找到了低成本获客的捷径。然而,现实往往事与愿违:软件使用不到1个月,算力耗尽无法开播;直播间频繁卡顿、…...

智慧树视频自动播放插件:3分钟搞定所有课程学习的终极指南
智慧树视频自动播放插件:3分钟搞定所有课程学习的终极指南 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台繁琐的手动操作而烦恼吗&#x…...