HDFS架构介绍
数新网络_让每个人享受数据的价值浙江数新网络有限公司是一家开源开放、专注于云数据智能操作系统和数据价值流通的服务商。公司自主研发的DataCyber云数据智能操作系统,主要包括数据平台CyberData、人工智能平台CyberAI、数据智能引擎CyberEngine、数据安全平台CyberSecurity。数新网络可提供大数据开发管理、安全合规、建模分析、价值流通等多种服务,让大数据、AI和数据价值安全流通得到高质量结合,助力客户实现数字化、智能化转型,激活数据要素潜能,提升企业整体竞争力。![]() https://www.datacyber.com/
https://www.datacyber.com/
背景
互联网的发展日新月异,每天产生的各种数据爆炸式增长,下面是来自一些重要领域的统计数据。
1、到2025年,全球数据领域将有 175 ZB 的数据(来自 Seagate UK)。
1字节(Byte) = 8位(bit)
1KB( KB,千字节) = 1024B
1MB( MB,兆字节) = 1024K
1GB( GB,吉字节,千兆) = 1024MB
1TB( TB,万亿字节,太字节) = 1024GB
1PB( PB,千万亿字节,拍字节) = 1024TB
1EB( EB,百亿亿字节,艾字节) = 1024PB
1ZB(ZB,十万亿亿字节,泽字节) = 1024EB
2、Google、Facebook、Microsoft 和Amazon 至少存储了1200PB 的信息(来自 Science Focus)。
3、截至2020年7月,全球五联网用户超过48亿(来自Internet World Stats)。
4、截至2020年3月,字节跳动拥有近10亿固定用户(来自维基百科)。
不仅数据量庞大,而且数据的形式多种多样,有音视频、图片、文字,甚至还有最基础的二进内容,因此如何安全、高效地存储及访问这些数据显得尤为重要。同时还应该考虑存储的兼容性及前瞻性,因为数据还在持续增长。
当前存储数据的介质产品非常丰富。例如,单台机器就能轻松存储数十TB 数据,不过使用单机存储数据存在以下不足:
1、容量大小受限,存在存储上限
2、访问受限,通常只能允许数十个用户同时访问
3、故障保障低,一旦机器出现问题,有可能造成所有用户都不能正常访问
针对以上不足,很多企业通常会选择分布式存储系统来存储量级较大的数据。什么是分布式存储?通俗地讲,分布式存储是指采用便捷的分布式网络,将数据分散地存储在多台独立的机器设备上,同时利用多台存储服务器分担存储负荷,利用数据管理服务器定位存储信息,从而提高系统的可靠性、可用性和存取效率,易于拓展。
一、分布式文件系统部署架构
基于中心化的系统具有良好的稳定性,且实施复杂度低。这种分布式系统集群存在部分管理节点(Master)和数据节点(Slave)。

基本架构分为3部分,各部分主要作用如下:
Master:负责文件定位、维护文件元 (meta) 信息、集群故障检测、管理数据迁移、分发数据备份、提供有关数据的操作命令或对外调用接口。
Slave:负责提供数据的存储介质,定期和 Master交互汇报自身的数据信息,或执行 Master 分发的命令,同时也会对外提供一些可访问的接口方式。
Client:通常是一组需要计算的任务,或者仅执行数据的获取任务。在有中心节点的架构下,通常会先和Master交互,然后根据位置信息再和Slave通信。在有中心节点的部署方案里,一般中心节点并不参与真正的数据读写,而是将文件 meta 信息保存并管理起来,Client从Master获取meta信息之后即可与slave通信。
二、HDFS的服务视图
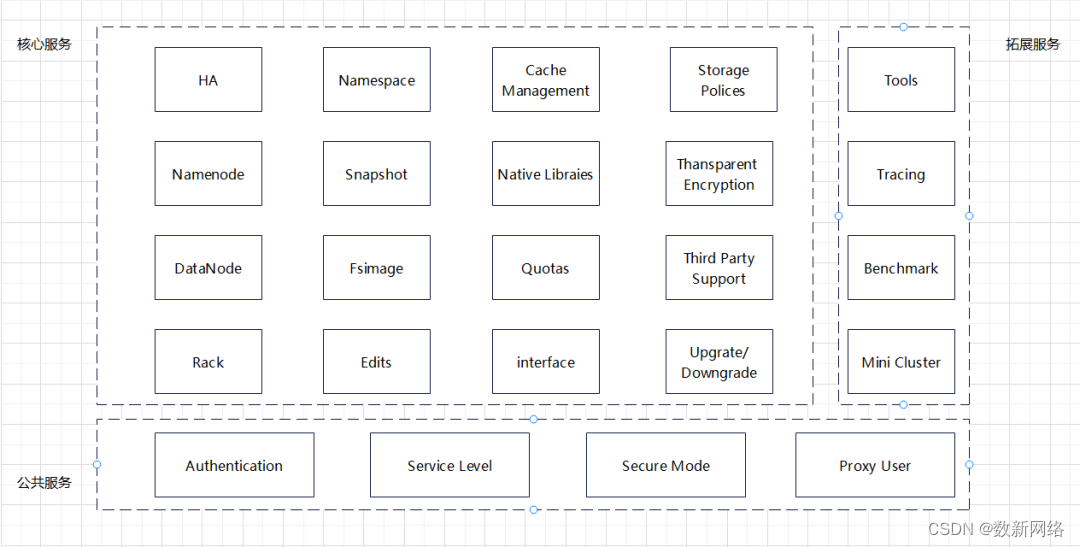
核心服务
Namenode:HDFS 系统采用中心化设计,即 Master/Slave 架构。这里的Namenode即是 Master,作用是管理整个文件系统的meta信息并管理Client对文件的访问。一个HDFS集群可以由多个namenode组成。
DataNode:DataNode 是 HDFS中的Slave 角色,主要作用是存储从Client 写入的数据,并负责处理来自Client的直接读写请求。DataNode还会处理来自Namenode 的指令。一个HDFS集群可以音龙百上千个 DataNode 节点。
HA (High Availability,高可用):HDFS 提供了高可用机制。在实际使用中,一个集群会部署两个Namenode节点,一个处于Active 状态,另一个处于 Standby 状态。Active Namenode 负责集群户端操作。当集群发生故障,Active 节点不可用时,HDFS 会快速完成状态转移,原先 Standby变成Active状态,原先Active 节点会变成Standby 状态,从而保障集群正常工作。
Namespace:随着业务访问量的增大,一个Active Namenode 在处理所有 Client 请求时会存这时需要对该Namenode 减压。一种有效的方法是将原先一个Namenode处理的业务分离出去一部分。因此,HDFS提供了Namespace 的概念,支持部署多个 Namespace,由每个 Namespace处理一部分client的请求。
Snapshot (快照):快照是数据在某个只读时间上的副本,通常是用来作为数据备份,防止用户误操作,实现数据的容灾恢复。
FsImage:Client 访问过的数据对应的 meta 会在Namenode 中记录,并分别在两处保存。一处是在Namenode内存中,另一处是在硬盘。Namenode会定期将内存中的结构数据持久化,持久化的这部分数据成为FsImage,主要作用是防止数据丢失。
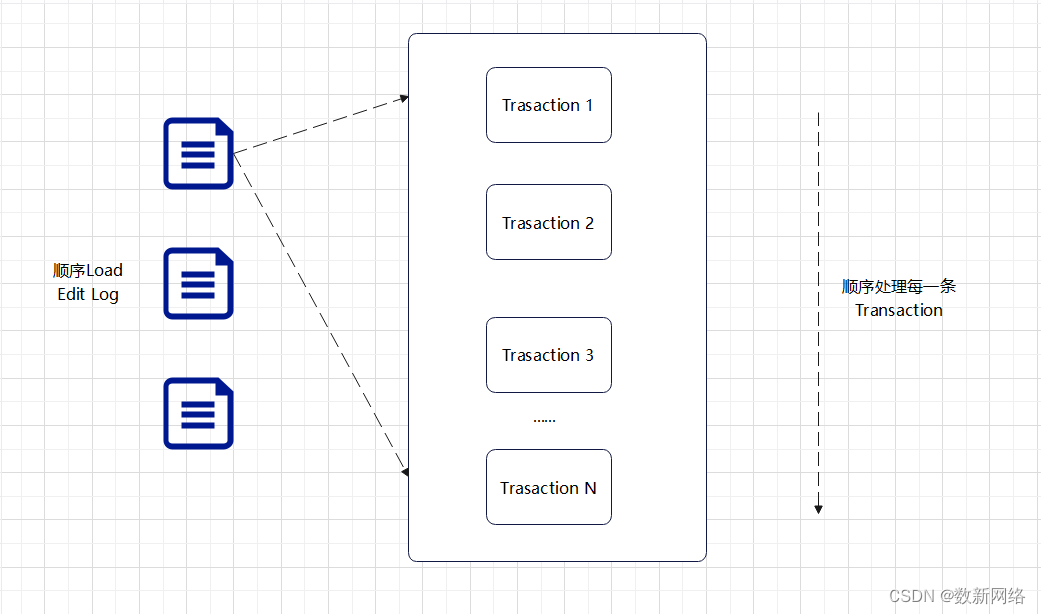
Edits:Client 访问HDFS 时,如果是更新操作,会生成一条 Transaction 记录,记录本次操作的具体内容。这个记录会被保存到 Edits 文件中,之后会定期被Standby Namenode处理。
Cache Management:在 HDFS 中,Cache 采用集中式管理。Cache 的使用能有效提升 Client读写数据的效率。
Native Libraries (本地):本地的作用是可以提高压缩和解压的效率,同时提供本地方法调用接口,比如和C、C++交互。
Quotas(限流):当访问HDFS 的Client不断增加、集群存在压力时,需要适当控制流入HDFS 的请求。HDFS 提供了Ouotas 限流功能,可以对文件数量和流量限流。
Interface:HDFS 提供了对外接人的统一访问接口,可以支持 RPC、REST或C API
Slorage Policies:HDFS支持的存储非常丰富,有 DISK、SSD、内存存储、Archive和第三方存储介质。存储策略上支持热存储、温存储、冷存储等。
Thanspruret Bneypton:HDFS中的加密是透明的端到端的。对数据加密后,无须Client修改程序。
Thind Party Support:HDFS 提供了对第三方的拓展机制,支持对 Amazon S3、OpenStack等的拓展,也支持自定义一些特性。
Upgrade/Dowmgrade:当有新版本需要替换时,HDFS提供滚动升级和滚动降级版等功能。
Rack (机架):Hadoop 组件都能识别机架感知,HDFS 也不例外。数据块 ( Block) 副本放置在不同机架上可以实现容错,这是使用机架感知来实现的。通过网络交换机和机器位置可以在机器故障的情况下区分数据的可用性。
公共服务(处理统一流程)
Secure Mode:HDFS的安全功能包括身份认证、服务级别授权、Web 控制合身份验证和数据机密性验证等。
Authentication:HDFS 的权限和认证支持很强大。可以通过 Kerberos、SSL认证、Posix样式权限和Ranger授权。
Service Level:服务层级花费是 HDFS 的一大亮点,可以支持让某些用户只访问其中一部分服务来控制集群风险,如只运行 User A访问 DataNode服务
Proxy User:HDFS 的用户系统支持超级用户、普通用户和代理用户。其中,代表另一个用户问HDFS集群的用户被称为代理用户。
拓展服务
通常用来辅助管理集群,比如额外使用的工具、提供测试功能等。
三、HDFS的架构(Master/Slave)

Namenode管理文件系统的 Metadata,并处理 Client 请求。
发生故障时,Active Namenode和Standby Namenode 快速实现高可用(HA)。
Client访问时,先通过 Namenode定位文件所在位置,然后直接和 Datanode 交互。
Client 写人的数据会以数据块 (Block) 的形式存储在个 Datanode,每个 Block 通常会有多个副本(Replication)。
HDFS通常会部署多个 Datanode 节点,这些节点在机架 (Rack) 上有各自的位置。
四、元数据架构
背景:
和很多分布式存储系统一样,HDFS 有自己独特的元数据架构。元数据在HDFS中以两种形式被维护:一个是内存,时刻维护集群最新的数据信息;另一个是磁盘,对内存中的信息进行维护存人内存是为了快速处理 Client 的请求,存储磁盘是为了将数据持久化,以便于在故障发生时能够及时恢复。
介绍namenode的启动(包含加载元数据)
加载预先生成的持久化文件FsImage
注:FsImage 是一种持久化到磁盘上的文件,里面包含了集群大部分的 meta数据,持久化的目的是为了防止 meta数据丢失,也就是在 HDFS 不可用的情况下还能够保证绝大多数的数据是正常的。
加载没有完成处理的Edit Log
注:FsImage保存了集群大部分的 meta而且Fsmage 定期被持久化,对于一个处理在线业务的分布式系统,这样是为了保证存储数据不丢失。还有另外一部分 meta 被单独持久化,这就是 Edit Log,Edit Log和事务相关。系统宕机,记录会消失。
等待Slave节点注册和汇报其所包含的Block数据
Edit Log加载顺序:
meta视图:
meta数据(由namenode管理)– 关于文件或目录的描述信息,如文件路径、名称、文件类型等,这些信息被称为元(meta)数据。
对文件来说,包括文件的 Block、各 Block 所在 DataNode,以及它们的修改时间、访时间等;
对目录来说,包括修改时间和访问权限控制信息,如权限、所属组等。
meta数据采用内存和持久化的方式维护。
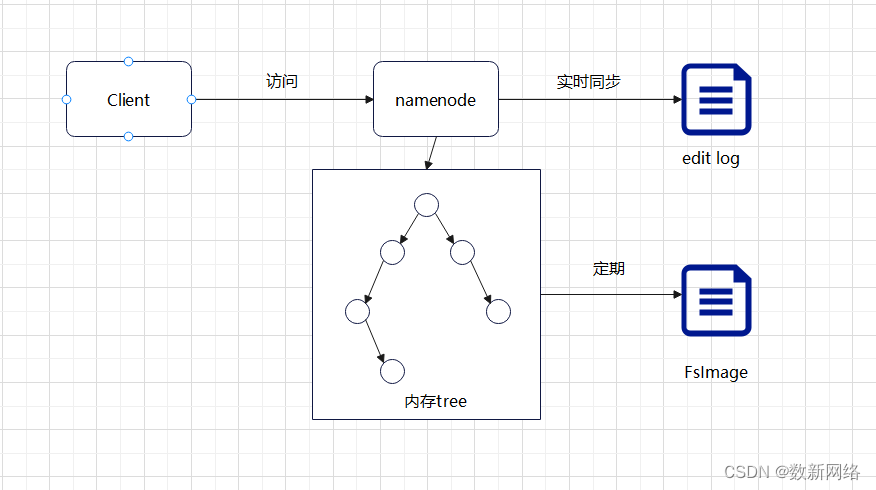
Namenode以树形结构维护在内存中的meta,被称为内存 Tree。每次有新的请求时,都会实时同步内存tree,同时在Edit Log中产生一条Transaction,内存tree会定期被持久化。
五、NameNode管理、DataNode注册
Namenode作为Master 节点,除了负责管理数据外,还负责管理资源。这里所说的资源其实就是指对DataNode的管理。
DataNode启动后会定期向Namenode发送心跳,以此向Namenode证明自己还处存活状态。
此时 Namenode 会处理心跳信息,如发现此前没有保存 DataNode 的信息,这时会通知DataNode做一次注册。注册的目的是为了检测该DataNode是否是“意外节点”。
Datanode定时通过RPC一次性将所有Block数据发给namenode,超出阈值会分批report。

六、active node和standby namenode
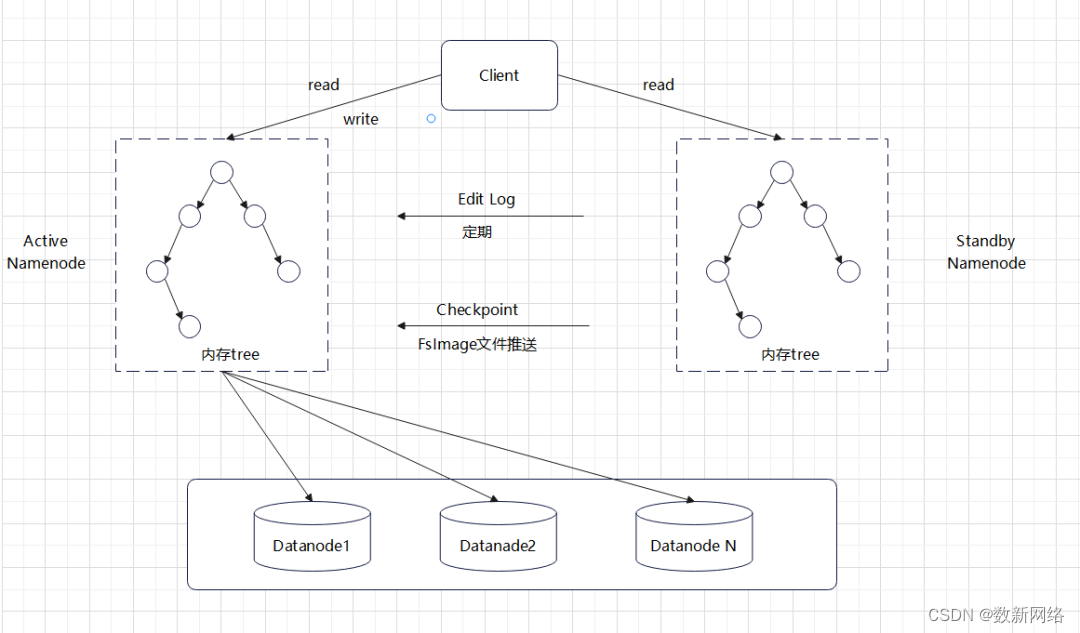
active namenode
● 处理客户端的读写请求
● 维护Namespace的文件和目录
● 维护整个Namespace下的 meta
● 管理 DataNode
● 维护Block副本(不同namespace)
standby namenode
● 维护 Namespace 下的 meta
● HA备份(自动感知namenode状态并自动切换)
● 通知Edit Log 文件刷新
● 触发 Checkpoint(持久化)
七、通信(HDFS RPC)
RPC(Remote Procedure Call)在HDFS中应用广泛,无论是来自 Client 的请求,或是集群间资源调度。它以Protocol Buffers 为基础,可以实现轻量化的高效数据访问,以及持久化等功能。
Protocol Buffers是Google 开源的用于序列化结构性数据的语言无关平台无关、具有可拓展机制的数据存储格式。很适合做数据存储或 RPC 数据交换格式。目前提供了 Java C++、C#、Dart、Go、Kotlin和Python等语言支持,这也是HDFS 支持多语言的基础。
gRPC(google):
gRPC是Google开源的一个高性能、通用RPC框架,以Protocol Buffers为其IDL(接口定义语言)和底层数据交换格式。可以在过程中实现服务负载均衡、跟踪、健康检查和身份认证检查,并且提供了数据中心内和跨数据中心连接请求,非常适用于分布式系统中。同其他 RPC 实现一样,只要在Client和Server端实现相同接口的不同外理逻辑即可像在本地访问一样。
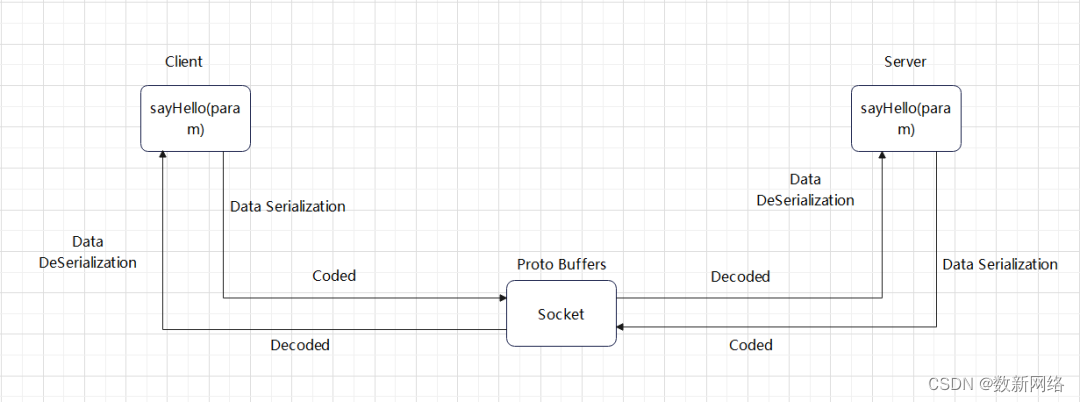
Client在正式向 Server 发送请求前,会对数据进行持久化处理,在数据经过网络的过程中,访问也会被编码,保证数据安全且尽量减少对网络资源的占用,访问到达Server 前会被解码,待用到数据时,也会被反向序列化。之后 Server 端会对做具体的处理逻辑,返回过程中会做相同的编解码机制。
Socket技术通常用于创建客户端-服务器模型。在这种模型中,服务器程序在特定的IP地址和端口上等待客户端连接,客户端则通过Socket连接到服务器程序并进行通信。通过Socket技术,可以实现不同操作系统和编程语言之间的通信,使得网络应用程序的开发更加灵活和方便。
八、位置策略
Block 是相对于 Namenode 来说的,以元数据和视图的形式呈现。
副本是实际存在于 DataNode 节点上的物理空间。副本位置策略决定了副本在集群内的存储位置,由位置选择策略和存储策略共同决定。副本存储位置选择是否合适会对读写性能及数据高可用性造成影响。
这里机架级别的位置策略(BlockPlacementPolicyRackFaultTolerant):这种策略可以实现机架级的容灾。
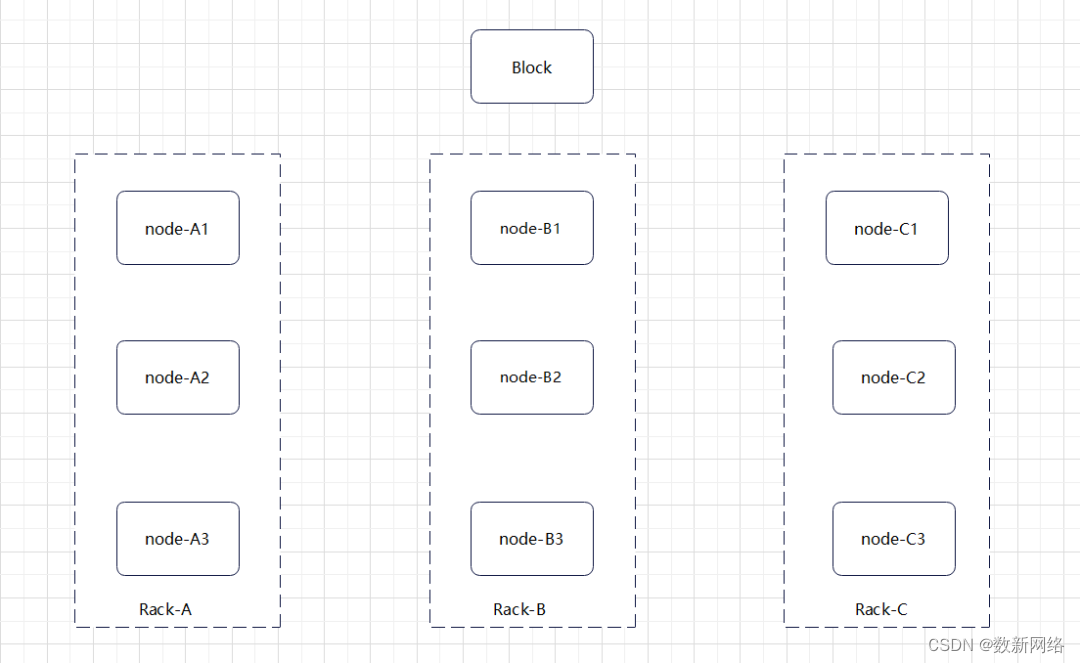
如果副本数小于集群中的机架数量,则随机选择机架中的节点。
如果副本数大于集群中的机架数量,准确填充每个机架副本。如果还有剩余副本数没有被安置,则为每个机架多放置1个副本,直到达到副本数量。
九、ZKFC解
HA (High Availability)是 HDFS 支持的一个重要特性,可以有效解决Active Namenode遇到故障时,将可用的 Standby 节点变成新的 Ative 状态的问题,使集群能够正常工作。目前支持两种方式:冷切换通过手动触发,缺点是不能够及时恢复集群。
实际生产中以应用热切换为主,通过自主检查 Namenode健康状态、Zookeeper 维护 Active信息、多种 namenode隔离方案,可以动态感应故障发生并实现自主切换。伴随有 ZKFC 运行进程的 Namenode都会参与选举。


ZKFC的默认实现者是DFSZKFailoverController,运行的时候需要独立开启一个JVM进程,并且和NameNode位于同一个节点–这样可以近距离的观察Namenode的状态。
ZKFC主要由以下几个部分组成:
HealthMonitor:负责及时获取本地Namenode的监控状态,辅助ActiveStandbyElector做参考。
ActiveStandbyEletor:控制和监控ZK上的节点的状态。
DFSZKFailoverController:协调HealMonitor和ActiveStandbyElector对象,处理它们发来的event变化事件,完成自动切换的过程。
ZK的状态变化及策略处理:
ZKFC除了及时知道本地Namenode状态外,还需要了解其余 Namenode 节点是否存活,这样做目的是在任何满足选举的情况下进行更新,实现的方式–Zookeeper 的分布式锁。
当某个namenode被选举成为active时,会创建两个znode:
ActiveStandbyElectorLock: 临时 node。表示创建本节点成功,意味着谁属于 Active。znode会存Active 节点信息。
ActiveBreadCrumb:永久znode。防止active的namenode非正常状态退出后恢复导致异常。
十、缓存
分布式缓存和本地缓存的比较:
● 支持大数据量缓存
● 支持高可用、高吞吐的性能
● 访问性能低于本地
memory-locality:cache是由NameNode统一管理的,那么HDFS client(例如MapReduce、Impala)就可以根据block被cache的分布情况去调度任务。

例如:hdfs cacheadmin -addDirective -path /user/hive/warehouse/fact.db/city -pool financial -replication 1
DFSClient读取文件时向NameNode发送getBlockLocations RPC请求。NameNode会返回一个LocatedBlock列表给DFSClient,这个LocatedBlock对象里有这个block的replica所在的DataNode和cache了这个block的DataNode。可以理解为把被cache到内存中的replica当做三副本外的一个高速的replica。
相关文章:
HDFS架构介绍
数新网络_让每个人享受数据的价值浙江数新网络有限公司是一家开源开放、专注于云数据智能操作系统和数据价值流通的服务商。公司自主研发的DataCyber云数据智能操作系统,主要包括数据平台CyberData、人工智能平台CyberAI、数据智能引擎CyberEngine、数据安全平台Cyb…...

微信小程序提示确认框 wx.showModal
核心实现代码如下 wx.showModal({ title: 确认, content: 确定要删除吗?, success (res) { if (res.confirm) { console.log(用户点击确定) } else if (res.cancel) { console.log(用户点击取消) } } })title 是确认框的标题,content 是确认…...
如何设置OBS虚拟摄像头给钉钉视频会议使用
环境: OBS Studio 29.1.3 Win10 专业版 钉钉7.1.0 问题描述: 如何设置OBS虚拟摄像头给钉钉视频会议使用 解决方案: 1.打开OBS 底下来源这添加视频采集设备 选择OBS虚拟摄像头 2.源那再建一个图像,随便选一张图片 3.点击虚…...
SpringCloud 微服务全栈体系(十一)
第十章 RabbitMQ 三、SpringAMQP SpringAMQP 是基于 RabbitMQ 封装的一套模板,并且还利用 SpringBoot 对其实现了自动装配,使用起来非常方便。 SpringAmqp 的官方地址:https://spring.io/projects/spring-amqp SpringAMQP 提供了三个功能&…...
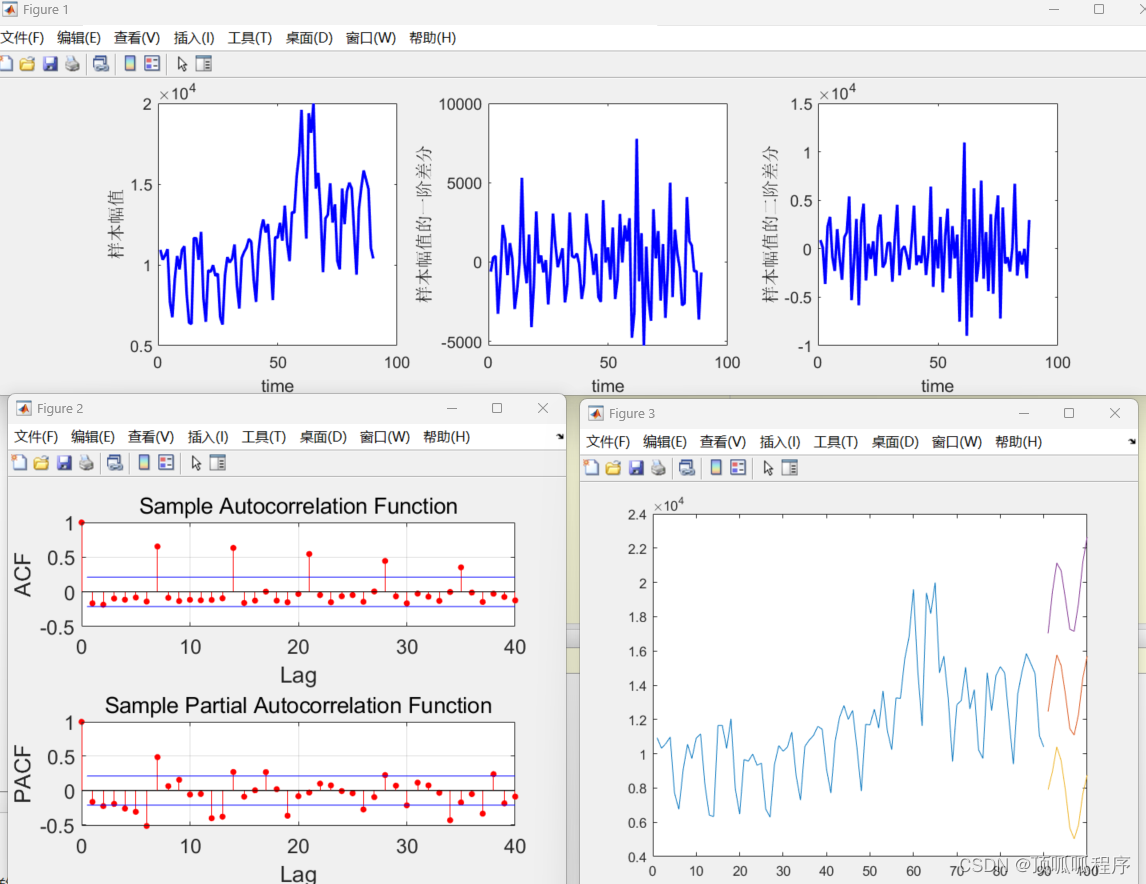
45基于matlab的ARIMA:AutoregressiveIntegratedMovingAverage model。
基于matlab的ARIMA:AutoregressiveIntegratedMovingAverage model。自回归差分移动平均模型(p,d,q),AR自回归模型,MA移动平均模型,时间序列模型步骤包括:1. 数据平稳性检验;2. 确定模型参数;3. …...

2010年408计网
下列选项中, 不属于网络体系结构所描述的内容是(C)A. 网络的层次B. 每层使用的协议C. 协议的内部实现细节D. 每层必须完成的功能 本题考查网络体系结构的相关概念 再来看当今世界最大的互联网,也就是因特网。它所采用的TCP/IP 4层网络体系结…...

初谈Linux-Linux环境搭建(阿里云免费服务器+xshell)
文章目录 前言Linux环境搭建结尾 前言 Linux is not unix 本篇文章小编初谈Linux并搭建Linux环境(阿里云免费服务器shell) Linux Linux是一个开源的操作系统 环境搭建 1.点击阿里云ECS免费学生服务器 2.注册后完成学生认证 3.购买云服务器…...
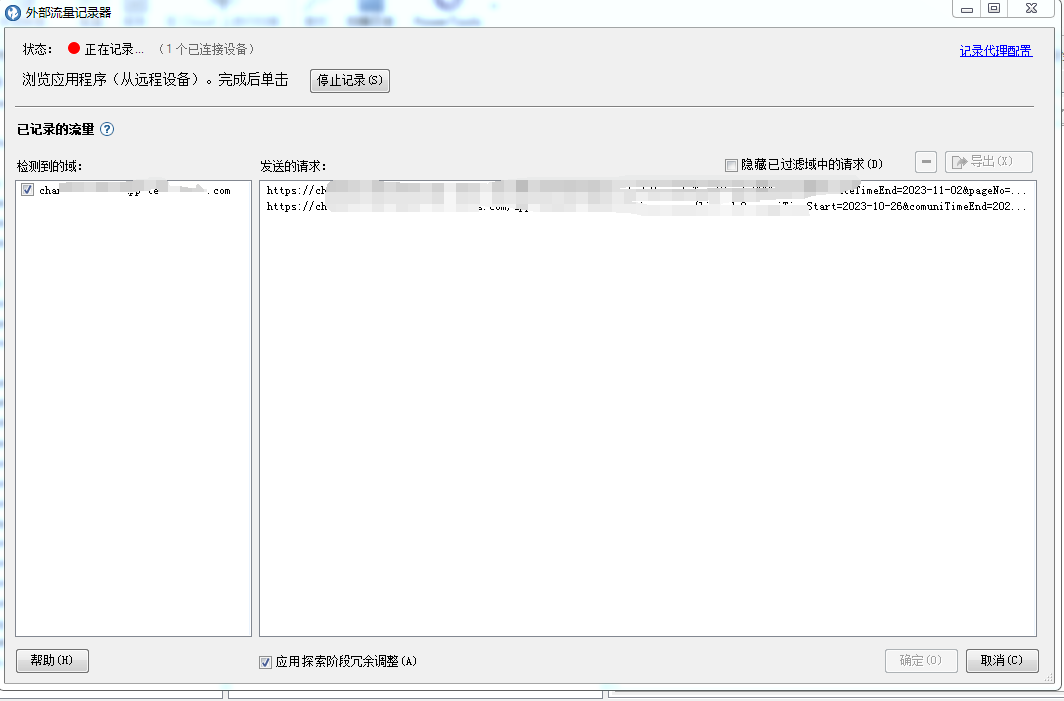
如何利用AppScan扫描H5页面,进行安全测试?
前期项目组接触的都是Web安全测试,今天做安全测试的时候,有一个项目刚好有H5页面,用以前那种AppScan内置浏览器的探索方式是不行的,研究了下,可以使用外部设备进行探索。 AppScan有两种手动探索方式,一种是…...

Oracle数据库中的table@xyz是什么意思?
是DBlink访问外部表的语法。xyz是其他Oracle数据库在你所登录的用户下建立的Dblink名。通过这种方式访问其他数据库中的表。 在Oracle数据库中,表名后跟着符号和一个连接字符串(xyz)是一种用法,它用于指定要访问的远程数据库。 …...

springboot常见网络相关错误及原因解析
在基于spring-boot开发过程尤其是上线后,经常出现网络相关的错误,令人难以琢磨和下手,所以就spring-boot使用过程中可能碰到的网络相关问题进行分析,结合网络转包、日志报错和前端输出,针对网络连接超时、连接被拒绝、…...
】.md updata:23/11/03)
【C语言_线程pthread_互斥锁mutex_条件触发cond 之解析与示例 (开源)】.md updata:23/11/03
文章目录 线程 pthread线程 vs 进程线程退出 等待 消息传递join:等待,传参void*; exit:退出,对参数赋值void**; 互斥锁 mutex互斥锁mutex条件cond_等待wait、触发signal 控制线程执行 补充: 宏-静态初始化 互斥锁/条件 线程 pthread 线程 vs…...

mongodb如何删除数据并释放空间
mongodb删除数据后不会直接释放内存空间,是因为使用了一种称为“延迟删除”的策略。这意味着当一个文档被删除时,它仍然会占用一定的内存空间,直到这个空间被垃圾回收器(Garbage Collector)回收。 删除数据操作前建议先…...

k8s之集群调度
目录 调度 工作机制 调度过程 调度算法 优先级 指定调度节点 调度 Kubernetes 是通过 List-Watch 的机制进行每个组件的协作,保持数据同步的,每个组件之间的设计实现了解耦。 用户是通过 kubectl 根据配置文件,向 APIServer 发送命令…...
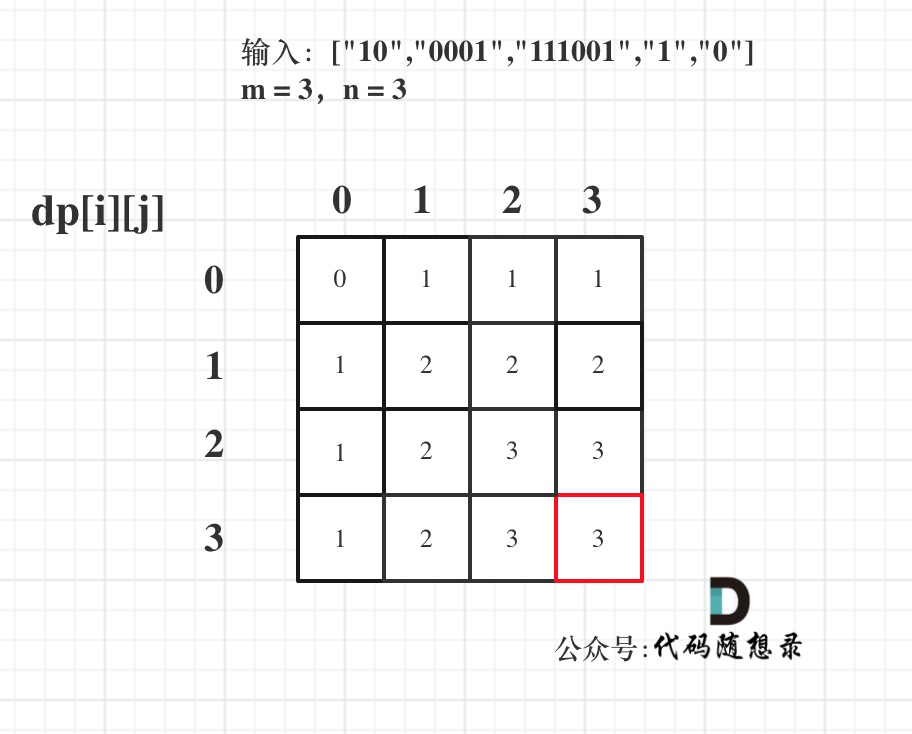
代码随想录算法训练营第四十二天丨 动态规划part05
1049.最后一块石头的重量II 思路 本题其实就是尽量让石头分成重量相同的两堆,相撞之后剩下的石头最小,这样就化解成01背包问题了。 感觉和昨天讲解的416. 分割等和子集 (opens new window)非常像了。 本题物品的重量为 stones[i],物品的价…...

[css] flex 子元素自动撑开父元素宽度
对于水平排列的情况,我们可以设置父元素的flex-direction属性为row。这样,子元素将会水平排列在一行内,并自动撑开父元素的宽度。如果子元素的宽度总和超过了父元素的宽度,则子元素会被压缩,以适应父元素的宽度。 对于…...
全新干货!一招教你迅速提升流量主收入!包你轻松月入过万
也不怕大家笑话,才哥以前收入每天才一块钱,连瓶水都买不了, 可是自从我开始接触老年粉私域后,一个搬运公众号的流量主收益两个月后就可以用“浴火重生”来形容了。 一个搬运公众号一天的流量主收益比我原创两年的个人公众号收益还…...

连接两个dataframe
concat import pandas as pd df1 pd.DataFrame({‘A’: [1, 2, 3], ‘B’: [4, 5, 6]}) df2 pd.DataFrame({‘A’: [7, 8, 9], ‘B’: [10, 11, 12]}) result pd.concat([df1, df2]) # 在行上连接 merge import pandas as pd df1 pd.DataFrame({‘key’: [‘A’, ‘B…...
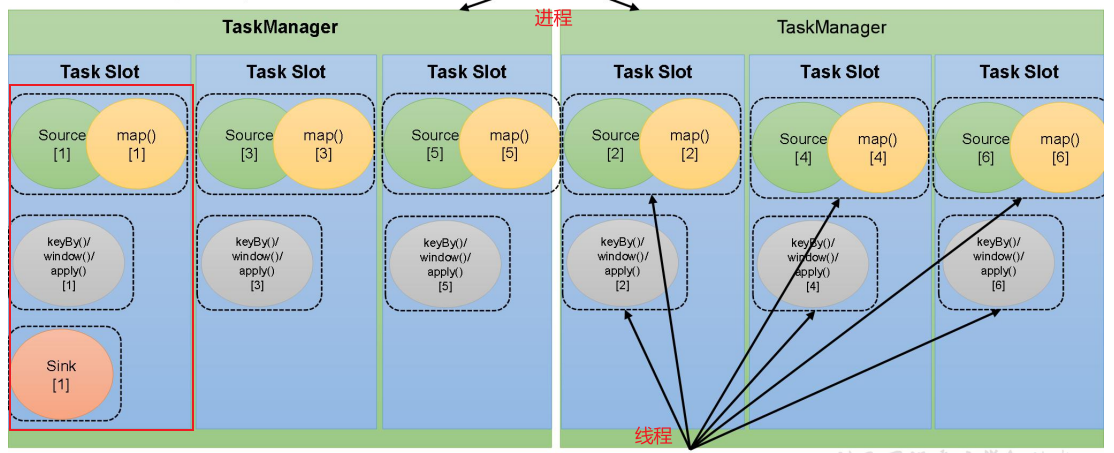
【入门Flink】- 05Flink运行时架构以及一些核心概念
系统架构 Flink运行时架构Standalone会话模式为例 1)作业管理器(JobManager) JobManager 是一个 Flink 集群中任务管理和调度的核心,是控制应用执行的主进程。每个应用都应该被唯一的 JobManager 所控制执行。 JobManger 又包含…...
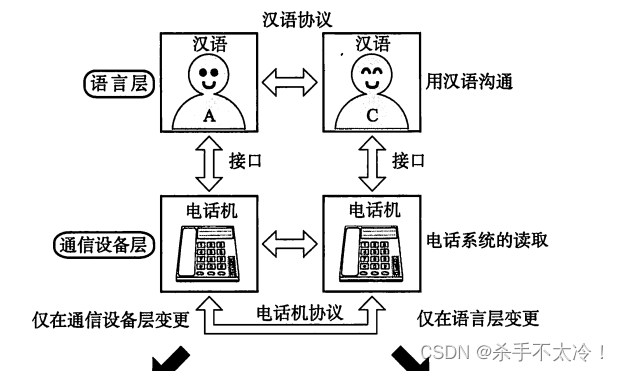
网络协议的基本概念
网络协议的基本概念 随处可见的协议 在计算机网络与信息通信领域里,人们经常提及“协议”一词。互联网中常用的具有代表性的协议有IP、TCP、HTTP等。 “计算机网络体系结构”将这些网络协议进行了系统归纳。TCP/IP就是IP、TCP、HTTP等协议的集合。现在࿰…...

广汽传祺E9上市,3DCAT实时云渲染助力线上3D高清看车体验
今年5月21日,中国智电新能源旗舰MPV——广汽传祺智电新能源E9在北京人民大会堂举办上市发布会。 发布会现场(图源官方) 为了让更多的消费者能够在线上感受到广汽传祺E9的魅力,3DCAT实时渲染云与大圣科技合作为广汽传祺打造了一款…...

Vivado 2022.1里Floating-point IP核的隐藏技巧:如何优化开方运算的延迟与资源消耗
Vivado 2022.1浮点开方IP核深度调优:从参数配置到硬件实现的黄金法则 在FPGA信号处理系统中,浮点运算单元往往是性能瓶颈所在。当设计一个实时性要求极高的雷达信号处理链路时,我曾在某型号的Xilinx UltraScale器件上遭遇过这样的困境&#x…...

深入理解强化学习基础:价值函数、策略梯度与PPO算法核心原理
深入理解强化学习基础:价值函数、策略梯度与PPO算法核心原理 【免费下载链接】LLM-RL-Visualized 🌟100 原创 LLM / RL 原理图📚,《大模型算法》作者巨献!💥(100 LLM/RL Algorithm Maps &#x…...

OpCore-Simplify:30分钟完成专业级黑苹果配置的终极指南
OpCore-Simplify:30分钟完成专业级黑苹果配置的终极指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的黑苹果配置而烦恼吗&…...

ARM1176JZF芯片架构与时钟管理深度解析
1. ARM1176JZF芯片架构概览 ARM1176JZF是ARMv6架构中的经典处理器内核,广泛应用于嵌入式系统和移动设备。这款芯片采用了先进的流水线设计和动态时钟调节技术,在性能与功耗之间实现了出色的平衡。开发芯片版本特别集成了完整的调试功能和性能监控单元&am…...

扛住十万并发的“冷面保安”:一文扒透限流的四大经典算法与代码实战
在高并发架构中,如果说缓存和 MQ 是替服务器扛伤害的“防弹衣”,那么限流(Rate Limiting)就是守在系统大门外的“冷面保安”。他的核心逻辑极其冷酷:不管外面排队的人有多急,只要超过了系统的最大接待能力&…...

5分钟解锁学术付费墙:Unpaywall浏览器扩展让你的研究之路畅通无阻
5分钟解锁学术付费墙:Unpaywall浏览器扩展让你的研究之路畅通无阻 【免费下载链接】unpaywall-extension Firefox/Chrome extension that gives you a link to a free PDF when you view scholarly articles 项目地址: https://gitcode.com/gh_mirrors/un/unpaywa…...

CSL编辑器技术深度解析:基于HTML5的学术引用样式编辑全栈指南
CSL编辑器技术深度解析:基于HTML5的学术引用样式编辑全栈指南 【免费下载链接】csl-editor cslEditorLib - A HTML 5 library for searching and editing CSL styles 项目地址: https://gitcode.com/gh_mirrors/csl/csl-editor CSL编辑器是一个基于HTML5技术…...

Linux音频驱动开发实战:为TLV320ADC5120编写ALSA Codec驱动
1. 项目概述:从一块“哑巴”音频芯片到Linux系统的“耳朵”最近在折腾一块基于TI TLV320ADC5120的音频采集板,想把它接到我的RK3568开发板上用。芯片手册、硬件原理图都齐了,但一上电,系统里arecord -l根本找不到设备,…...

ThinkPHP8.x全面升级:现代化PHP开发新标杆
好的,我们来梳理一下 ThinkPHP 8.x 版本(通常指 8.0 及后续小版本)的主要特性和改进方向。相较于之前的版本(如 5.x),8.x 版本在架构、性能、规范性和安全性上都有显著提升:核心方向与重大变更&…...

Cortex-R52+中断控制器与定时器深度解析
1. Cortex-R52中断控制器架构解析 在嵌入式实时系统中,中断管理机制直接影响系统的响应速度和确定性。Cortex-R52采用GICv2架构的中断控制器,通过硬件级优先级管理和虚拟化支持,为实时应用提供可靠的中断处理能力。我曾在一个汽车ECU项目中&a…...