NLP 模型中的偏差和公平性检测
一、说明
近年来,自然语言处理 (NLP) 模型广受欢迎,彻底改变了我们与文本数据交互和分析的方式。这些基于深度学习技术的模型在广泛的应用中表现出了卓越的能力,从聊天机器人和语言翻译到情感分析和文本生成。然而,NLP 模型并非没有挑战,它们面临的最关键问题之一是存在偏见和公平性问题。本文探讨了 NLP 模型中的偏见和公平性概念,以及用于检测和缓解它们的方法。埃弗顿·戈梅德(Everton Gomede)博士
在NLP模型中维护公平性不是一种选择;它是未来的道德指南针,人工智能弥合了差距,而不是加深了鸿沟。
二、了解 NLP 模型中的偏差
NLP 模型中的偏见是指基于种族、性别、宗教或民族等特征对某些群体或个人存在不公平或偏见的待遇。这些偏差可能会在模型的训练和微调阶段出现,因为训练数据通常反映了数据源中存在的偏差。NLP 模型根据它们在训练数据中观察到的模式来学习预测和生成文本。如果训练数据有偏差,模型将不可避免地在其输出中拾取并传播这些偏差。
NLP 模型中可能会出现不同类型的偏差,例如:
- 刻板印象偏见:这种偏见涉及强化对某些群体的刻板印象,导致模型输出中的不公平概括和歪曲表示。
- 代表性不足偏差:如果某些组在训练数据中的代表性不足,则模型在处理与这些组相关的文本时可能会表现不佳。
- 历史偏见:NLP 模型可以从包含过去偏见的历史文本中学习,这可能会使过时和有害的观点永久化。
三、检测 NLP 模型中的偏差
检测 NLP 模型中的偏差是在其应用中实现公平和公正的关键一步。有几种方法和技术用于偏差检测:
- 偏差审计: 这涉及手动检查模型的输出是否有偏差迹象。人工审核员会评估系统的行为,以识别可能产生有偏见的内容的情况。
- 偏差指标: 研究人员开发了各种指标来量化 NLP 模型中的偏差。这些指标通过分析模型对不同人口统计群体的预测来衡量模型表现出偏差的程度。
- 反事实评估: 在反事实评估中,研究人员修改输入数据,以评估当某些属性或特征发生变化时模型的输出如何变化。这种方法有助于识别与特定属性相关的偏差。
- 差分隐私: 差分隐私等技术可用于在训练过程中保护敏感属性,使模型在学习和传播偏见方面更具挑战性。
四、NLP 模型中的公平性
确保 NLP 模型的公平性涉及解决在系统行为中检测到的偏差。要实现公平,就必须采取措施避免不公正的歧视,并为所有人口群体提供平等机会。
- 数据预处理:数据预处理技术(例如对代表性不足的群体进行重新采样、重新加权训练数据和删除有偏见的示例)可以帮助减轻训练数据中的偏差。
- 公平性约束:研究人员可以在模型训练期间引入公平性约束,确保模型的预测不会不成比例地偏袒或损害任何特定群体。
- 对抗性训练:对抗性训练涉及训练一个单独的模型来识别和减轻主 NLP 模型中的偏见。这种对抗性模型旨在减少输出中偏置属性的影响。
- 去偏置后处理:训练模型后,可以使用后处理技术来识别和减轻其输出中的偏差。这可能涉及重新排名或改写结果以减少偏差。
五、挑战与未来方向
解决 NLP 模型中的偏见和公平性是一项复杂且持续的挑战。实现公平性并不是一个放之四海而皆准的解决方案,需要仔细考虑上下文、正在处理的数据以及 NLP 模型的具体应用。此外,还需要考虑权衡取舍,因为消除所有偏差可能会导致模型的准确性降低。
随着 NLP 领域的进步,计算机科学家、伦理学家、社会学家和领域专家之间越来越需要跨学科合作,以开发更强大的方法来检测和减轻 NLP 模型中的偏见。此外,道德准则和法规可能在促进 NLP 模型开发和部署中的公平性和问责制方面发挥关键作用。
六、代码
检测和减轻 NLP 模型中的偏差是一项复杂的任务,通常需要专门的工具和专业知识。此处提供的代码将指导您使用 IBM AI Fairness 360 (AIF360) 库中的“Fairness Audit”工具完成 NLP 模型中的偏差和公平性检测过程。该工具将帮助您分析给定数据集中的偏差并生成绘图以获得更好的可视化效果。请注意,此代码假定您已经安装了 AIF360。
让我们从代码开始:
import pandas as pd
import numpy as np
import random
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from aif360.datasets import BinaryLabelDataset
from aif360.metrics import ClassificationMetric# Original dataset
data = pd.DataFrame({"gender": ["Male", "Female", "Male", "Female", "Male", "Male", "Female", "Male", "Female", "Female"],"income": [1, 0, 1, 0, 1, 0, 0, 1, 1, 0]
})# Define the number of additional observations to generate
num_additional_observations = 10000 # Increase the number# Define the proportion of positive income for each gender (adjust as needed)
male_positive_proportion = 0.7 # Adjust based on your desired distribution
female_positive_proportion = 0.3 # Adjust based on your desired distribution# Create additional observations
additional_observations = []for _ in range(num_additional_observations):gender = random.choice(["Male", "Female"])if gender == "Male":income = 1 if random.random() < male_positive_proportion else 0else:income = 1 if random.random() < female_positive_proportion else 0additional_observations.append({"gender": gender, "income": income})# Append the additional observations to the original dataset
data = data.append(additional_observations, ignore_index=True)# Shuffle the dataset to randomize the order
data = data.sample(frac=1, random_state=42).reset_index(drop=True)# Your dataset now contains more observations and may have improved bias balance.# Define the sensitive attribute(s) and the target label
sensitive_attribute = "gender"
target_label = "income"# Encode the sensitive attribute using one-hot encoding
data = pd.get_dummies(data, columns=[sensitive_attribute])# Split the data into training and test sets
train, test = train_test_split(data, test_size=0.2, random_state=42)# Train a simple NLP model. Replace this with your NLP model.
# Here, we're using a RandomForestClassifier as an example.
X_train = train.drop(target_label, axis=1)
y_train = train[target_label]
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train, y_train)# Predict on the test dataset
X_test = test.drop(target_label, axis=1)
y_pred = clf.predict(X_test)# Create BinaryLabelDatasets for the original test dataset and predicted labels
privileged_group = test[test[sensitive_attribute + "_Male"] == 1]
unprivileged_group = test[test[sensitive_attribute + "_Female"] == 1]# Check if both privileged and unprivileged groups have instances
if len(privileged_group) > 0 and len(unprivileged_group) > 0:# Disparate Impactprivileged_positive_rate = np.sum(y_pred[test.index.isin(privileged_group.index)] == 1) / len(privileged_group)unprivileged_positive_rate = np.sum(y_pred[test.index.isin(unprivileged_group.index)] == 1) / len(unprivileged_group)disparate_impact = privileged_positive_rate / unprivileged_positive_rate# Statistical Parity Differencestatistical_parity_difference = privileged_positive_rate - unprivileged_positive_rate# Create a ClassificationMetric for fairness evaluationmetric = ClassificationMetric(original_dataset, predicted_dataset, unprivileged_groups=[{"gender_Female": 1}],privileged_groups=[{"gender_Male": 1}])equal_opportunity_difference = metric.equal_opportunity_difference()# Plot fairness metricsfairness_metrics = ["Disparate Impact", "Statistical Parity Difference", "Equal Opportunity Difference"]metrics_values = [disparate_impact, statistical_parity_difference, equal_opportunity_difference]plt.figure(figsize=(8, 6))plt.bar(fairness_metrics, metrics_values)plt.xlabel("Fairness Metric")plt.ylabel("Value")plt.title("Fairness Metrics")plt.show()# Interpret the fairness metricsif disparate_impact < 0.8:print("The model exhibits potential bias as Disparate Impact is below the threshold (0.8).")else:print("The model demonstrates fairness as Disparate Impact is above the threshold (0.8).")if statistical_parity_difference < 0.1:print("Statistical Parity is nearly achieved, indicating fairness in impact between groups.")else:print("Statistical Parity is not achieved, suggesting potential disparities in outcomes.")if equal_opportunity_difference < 0.1:print("Equal Opportunity is nearly achieved, indicating fairness in equal access to positive outcomes.")else:print("Equal Opportunity is not achieved, suggesting potential disparities in equal access to positive outcomes.")
else:print("The privileged or unprivileged group is empty, unable to calculate fairness metrics.")在此代码中,需要替换为自己的数据集的路径。该代码假定您有一个具有“性别”敏感属性和“收入”目标标签的数据集。您可以根据数据集调整这些属性。"your_dataset.csv"
此代码执行以下步骤:
- 加载数据集并将其拆分为训练集和测试集。
- 为训练数据集和测试数据集创建 BinaryLabelDataset 对象。
- 在训练数据集上训练一个简单的 NLP 模型(在本例中为 RandomForestClassifier)。
- 使用模型预测测试数据集上的标签。
- 计算各种公平性指标(差异影响、统计奇偶校验差异、平等机会差异)。
- 生成并显示图以可视化公平性指标。
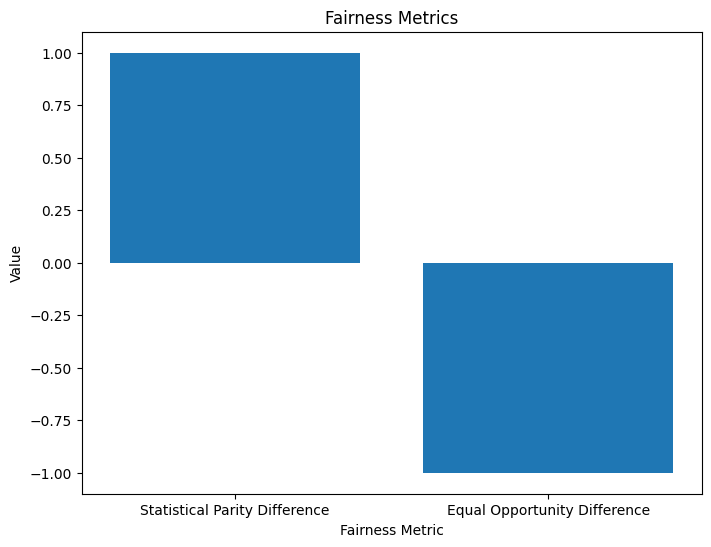
The model demonstrates fairness as Disparate Impact is above the threshold (0.8).
Statistical Parity is not achieved, suggesting potential disparities in outcomes.
Equal Opportunity is nearly achieved, indicating fairness in equal access to positive outcomes.在运行此代码之前,请确保在 Python 环境中安装了必要的库和依赖项,包括 AIF360 和 scikit-learn。此外,根据您的特定用例调整数据集、敏感属性和目标标签。
七、结论
NLP 模型中的偏差和公平性检测是负责任的 AI 开发的一个重要方面。随着 NLP 模型继续集成到各种应用程序和领域中,解决可能出现的偏见并采取措施确保公平性至关重要。检测和减轻偏见需要结合人为监督、技术解决方案和道德考虑。通过促进 NLP 模型的公平性,我们可以构建更具包容性和公平性的 AI 系统,使不同的用户和上下文受益
相关文章:
NLP 模型中的偏差和公平性检测
一、说明 近年来,自然语言处理 (NLP) 模型广受欢迎,彻底改变了我们与文本数据交互和分析的方式。这些基于深度学习技术的模型在广泛的应用中表现出了卓越的能力,从聊天机器人和语言翻译到情感分析和文本生成。然而&…...

YUV图像格式详解
1.概述 YUV是一种图像颜色编码方式。 相对于常见且直观的RGB颜色编码,YUV的产生自有其意义,它基于人眼对亮度比色彩的敏感度更高的特点,使用Y、U、V三个分量来表示颜色,并通过降低U、V分量的采样率,尽可能保证图像质…...

软考高项-质量管理措施
质量规划 编制《项目质量规划书》、《项目验收规范》等质量文件,对文件进行评审,对项目成员进行质量管理培训; 质量保证 评审、过程分析、定期对项目进行检查并跟踪改进情况; 质量控制 测试、因果分析、变更、统计抽样等。 80/…...
)
Redis那些事儿(一)
说到redis大家都不陌生,其中包括:共有16个数据库,默认为第0个数据库;数据以key-value键值的形式存储;数据类型包括String、List、Hash、Set等,其中最常用的是字符串;是单线程的、基于内存的&…...

【多媒体文件格式】M3U8
M3U8 M3U8文件是指UTF-8编码格式的M3U文件(M3U使用Latin-1字符集编码)。M3U文件是一个记录索引的纯文本文件,打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放。 m3u8基本上可以认为就是.m3u格式文件&#x…...

linux中xargs的实用技巧
在Linux命令行中,有许多强大的工具可以帮助我们处理和操作文件、目录以及其他数据。其中之一就是xargs命令。xargs命令可以将标准输入数据转换成命令行参数,从而提高命令的效率和灵活性。本文将介绍xargs命令的基本用法,并通过生动的代码和输…...

【Jmeter】生成html格式接口自动化测试报告
jmeter自带执行结果查看的插件,但是需要在jmeter工具中才能查看,如果要向领导提交测试结果,不够方便直观。 笔者刚做了这方面的尝试,总结出来分享给大家。 这里需要用到ant来执行测试用例并生成HTML格式测试报告。 一、ant下载安…...
如何将极狐GitLab 漏洞报告导出为 HTML 或 PDF 格式或导出到 Jira
目录 导出为 HTML/PDF 将漏洞信息导出到 Jira 参考资料 极狐GitLab 的漏洞报告功能可以让开发人员在统一的平台上面管理代码,对其进行安全扫描、管理漏洞报告并修复漏洞。但有些团队更喜欢使用类似 Jira 的单独工具来管理他们的安全漏洞。他们也可能需要以易于理…...
uniapp原生插件之安卓文字转拼音原生插件
插件介绍 安卓文字转拼音插件,支持转换为声调模式和非声调模式,支持繁体和简体互相转换 插件地址 安卓文字转拼音原生插件 - DCloud 插件市场 超级福利 uniapp 插件购买超级福利 详细使用文档 uniapp 安卓文字转拼音原生插件 用法 在需要使用插…...
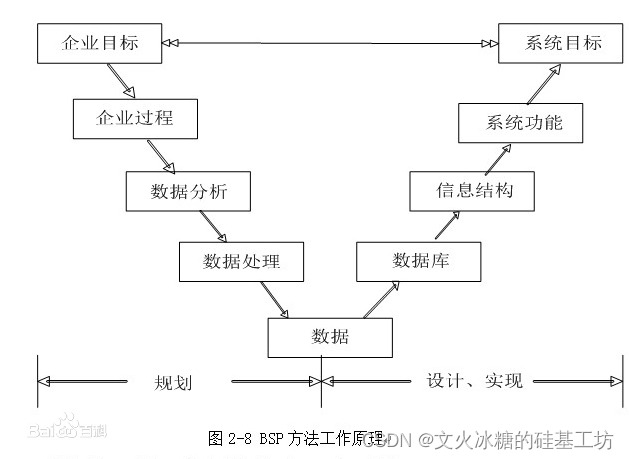
[架构之路-254/创业之路-85]:目标系统 - 横向管理 - 源头:信息系统战略规划的常用方法论,为软件工程的实施指明方向!!!
目录 总论: 一、数据处理阶段的方法论 1.1 企业信息系统规划法BSP 1.1.1 概述 1.1.2 原则 1.2 关键成功因素法CSF 1.2.1 概述 1.2.2 常见的企业成功的关键因素 1.3 战略集合转化法SST:把战略目标转化成信息的集合 二、管理信息系统阶段的方法论…...

CSP-J 2023真题解析
T1 小苹果 一、题目链接 P9748 [CSP-J 2023] 小苹果 二、题目大意 现有 n n n 个苹果从左到右排成一列,编号为从 1 1 1 到 n n n。 每天都会从中拿走一些苹果。拿取规则是,从左侧第 1 1 1 个苹果开始、每隔 2 2 2 个苹果拿走 1 1 1 个苹果。随…...
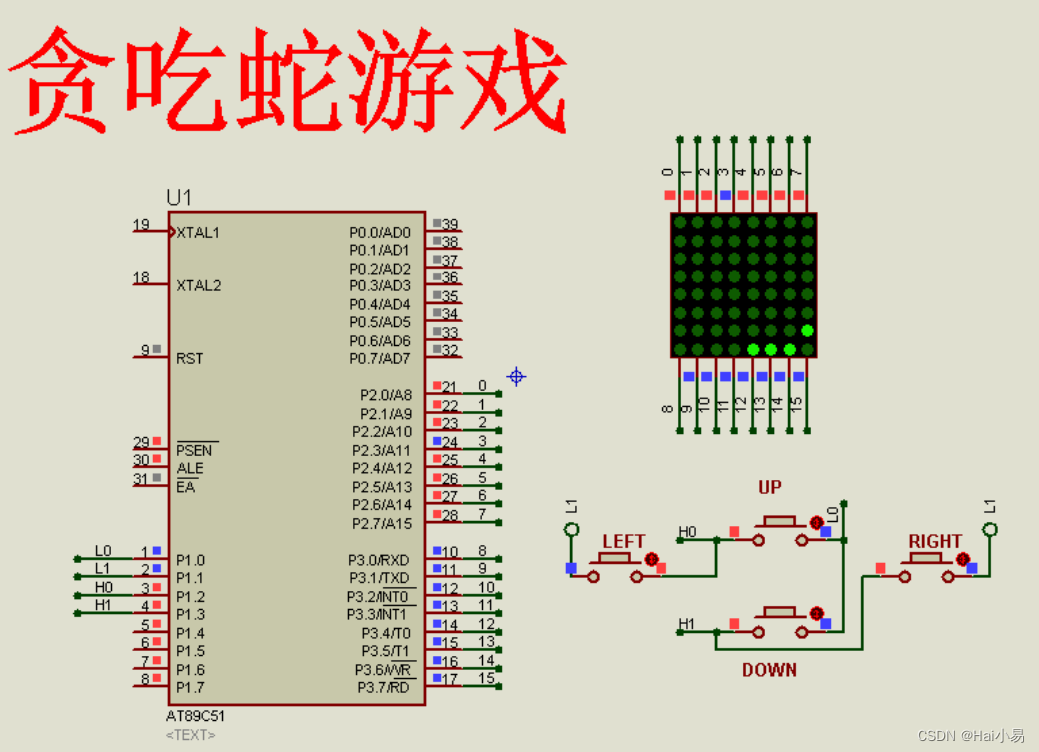
【Proteus仿真】【51单片机】贪吃蛇游戏
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真51单片机控制器,使用8*8LED点阵、按键模块等。 主要功能: 系统运行后,可操作4个按键控制小蛇方向。 二、软件设计 /* 作者:嗨小易…...
)
Android 原生定位开发(解决个别手机定位失败问题)
文章目录 前言一、实现步骤二、使用步骤1.服务启动工具类2.实现LocationService 总结 前言 在android开发中地图和定位是很多软件不可或缺的内容,这些特色功能也给人们带来了很多方便。定位一般分为三种发方案:即GPS定位、Google网络定位以及基站定位。…...

uni-app 中如何实现数据组件间传递?
在 uni-app 中,实现数据组件间传递可以使用 Props 或 Vuex。 Props 是一种组件通信的方式,通过向子组件传递数据来实现组件间的数据传递。下面是一个示例: 父组件: <template><child :message"hello">&l…...
SpringBoot整合自签名SSL证书,转变HTTPS安全访问(单向认证服务端)
前言 HTTP 具有相当优秀和方便的一面,然而 HTTP 并非只有好的一面,事物皆具两面性,它也是有不足之处的。例如: 通信使用明文(不加密),内容可能会被窃听。不验证通信方的身份,因此有可能会遭遇…...

k8s:endpoint
在 Kubernetes 中,Endpoint 是一种 API 对象,它用于表示集群内某个 Service 的具体网络地址。换句话说,它连接到一组由 Service 选择的 Pod,从而使它们能够提供服务。每个 Endpoint 对象都与相应的 Service 对象具有相同的名称&am…...
最新版星火官方搬运工具6.0,高级搬运,100%过原创,短视频上热门搬运软件黑科技【搬运脚本+使用技术教程】
软件介绍: 高级搬运,条条过原创 短视频暴力热门搬运黑科技 自研摄像头内录突破性技术6.0 无需任何繁琐准备工作安装即用 无需复杂售后培训看教程即可学会 直装直用自研技术更好卖 无需root 无需框架 更方便 无需xposed 无需vcam更安全 适配99%以…...
轧钢厂安全生产方案:AI视频识别安全风险智能监管平台的设计
一、背景与需求 轧钢厂一般都使用打包机对线材进行打包作业,由于生产需要,人员需频繁进入打包机内作业,如:加护垫、整包、打包机检修、调试等作业。在轧钢厂生产过程中,每个班次生产线材超过300件,人员在一…...

Linux Dotnet 程序堆栈监控
# 查看进程 dotnet-stack ps #显示如下2014067 dotnet /usr/share/dotnet/dotnet k1 --LogLevel4 2014087 dotnet /usr/share/dotnet/dotnet --LogLevel4 2014089 dotnet /usr/share/dotnet/dotnet --LogLevel4 # 根据PID查看这个进程每个线程的堆栈 dotnet-stack repor…...

后端设计PG liberty的作用和增量式生成
Liberty(俗称LIB和DB),是后端设计中重要的库逻辑描述文件,这里边包含了除过physical(当然也有一点点涉及)以外所有的信息,对整个后端设计实现有非常大的作用。借此机会,一起LIB做一个…...

Electron应用上鸿蒙PC,安装包从180MB压到45MB,我做了哪些骚操作
Electron应用上鸿蒙PC,安装包从180MB压到45MB,我做了哪些骚操作 上个月老板丢给我一个任务:把现有的Electron应用搬到鸿蒙PC上。我花了两天把代码跑通了,build了一版安装包,一看体积——180MB。老板看了一眼࿰…...

如何构建高效科研知识库:Obsidian文献管理系统的3种创新策略
如何构建高效科研知识库:Obsidian文献管理系统的3种创新策略 【免费下载链接】obsidian_vault_template_for_researcher This is an vault template for researchers using obsidian. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian_vault_template_for_r…...

GameEngineFromScratch输入管理系统:跨平台输入事件处理机制终极指南 [特殊字符]
GameEngineFromScratch输入管理系统:跨平台输入事件处理机制终极指南 🎮 【免费下载链接】GameEngineFromScratch 配合我的知乎专栏写的项目 项目地址: https://gitcode.com/gh_mirrors/ga/GameEngineFromScratch GameEngineFromScratch输入管理系…...

高性能Go Web框架Volo:设计原理、核心功能与生产实践
1. 项目概述:一个高性能的Go语言Web框架最近在折腾一个需要处理高并发请求的API服务,选型时又一次把目光投向了Go生态。说实话,Go的Web框架选择不少,从轻量级的Gin、Echo,到功能更全的Beego、Iris,各有各的…...

Apollo2 BLE自定义服务开发指南:GATT数据库配置与回调实现
1. 项目概述与核心价值最近在折腾一个基于Apollo2 Blue的低功耗蓝牙项目,需要自定义一个服务(Service)来实现特定的数据交互功能。如果你也在用Ambiq Micro的Apollo2或Apollo3 Blue系列芯片做BLE开发,大概率会遇到类似的需求&…...

用51单片机和28BYJ-48做个智能小装置:角度控制云台/旋转展示架的完整项目
用51单片机和28BYJ-48打造智能旋转云台的实战指南 项目构思与核心价值 在创客圈里,28BYJ-48步进电机因其低廉的价格和稳定的性能,成为了许多DIY项目的首选动力元件。但很多初学者拿到这个电机后,往往止步于简单的正反转控制,没能充…...

Flowable 6.7.2 适配达梦数据库踩坑实录:从驱动到Liquibase源码修改全攻略
Flowable 6.7.2 深度适配达梦数据库实战指南:从驱动配置到源码级改造 在国产化替代浪潮中,数据库迁移往往是技术团队面临的首要挑战。当工作流引擎Flowable遇上国产数据库达梦(DM),两者的"语言不通"会导致一系列兼容性问题。本文将…...

3个神奇步骤:用QRazyBox轻松修复任何损坏的二维码
3个神奇步骤:用QRazyBox轻松修复任何损坏的二维码 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾经遇到过这种情况:一张重要的二维码因为打印模糊、表面划伤或…...

解锁游戏时间魔法:OpenSpeedy如何重塑你的单机游戏体验
解锁游戏时间魔法:OpenSpeedy如何重塑你的单机游戏体验 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾在游戏中经历过这样的时刻:冗长的剧情…...
)
【电脑自动化助手】 OpenClaw 一键部署教程(包含安装包)
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟养出你的数字员工 2026 年备受关注的开源 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标超 28 万,凭借本地运行 零代码 自动执行任务的特点收获大量…...