NLP之Bert实现文本分类
文章目录
- 1. 代码展示
- 2. 整体流程介绍
- 3. 代码解读
- 4. 报错解决
- 4.1 解决思路
- 4.2 解决方法
- 5. Bert介绍
- 5.1 什么是Bert
- BERT简介:
- BERT的核心思想:
- BERT的预训练策略:
- BERT的应用:
- 为什么BERT如此受欢迎?
- 总结:
1. 代码展示
from tqdm import tqdm # 可以在循环中添加进度条x = [1, 2, 3] # list
print(x[:10] + [0] * -7)from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")labels = []
train_list = []
with open("../data/ChnSentiCorp.txt", mode='r', encoding='utf-8') as file:for line in tqdm(file.readlines()):line = line.strip().split(',')labels.append(int(line[0]))text = tokenizer.encode(line[1])token = text[:80] + [0] * (80 - len(text))train_list.append(token)
import numpy as nplabels = np.array(labels)
train_list = np.array(train_list)# 已经把数据转化成了词向量 (Bert不需要词嵌入) RNN --> LSTM
from transformers import TFBertForSequenceClassificationmodel = TFBertForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=2)model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
result = model.fit(x=train_list, y=labels, batch_size=128, epochs=10)
print(result.history)
2. 整体流程介绍
首先,概述一下代码的主要目的和流程。
主要目的:
此代码的主要目的是使用BERT模型进行序列分类。具体来说,它似乎是在处理某种情感分析任务,因为代码中读取了标签和文本,并试图用BERT模型来进行分类(假设为正面或负面情感,因为num_labels=2)。
整体流程:
-
导入所需库:
tqdm:用于显示循环的进度条。transformers:提供预训练的模型和相关的工具。
-
数据预处理:
- 定义了两个空列表
labels和train_list,用于存储从文件中读取的标签和文本数据。 - 打开一个名为
ChnSentiCorp.txt的文件,并从中读取数据。假设每行的格式是“标签,文本”。 - 使用BERT的tokenizer将每行文本转化为token。然后,确保每行文本的token长度为80,如果长度不足80,则用0填充。
- 定义了两个空列表
-
转换数据格式:
- 将labels和train_list列表转换为numpy数组。
-
加载和初始化BERT模型:
- 使用
TFBertForSequenceClassification.from_pretrained方法加载bert-base-chinese预训练模型,并指定类别数量为2。 - 编译模型,设置损失函数和评估指标,并显示模型摘要。
- 使用
-
模型训练:
- 使用处理后的
train_list作为输入和labels作为目标进行模型训练。 - 显示训练历史。
- 使用处理后的
综上,代码的整体流程是:导入库→数据预处理→数据格式转换→加载和初始化BERT模型→模型训练。
3. 代码解读
像debug一样逐步解释您提供的代码。
from tqdm import tqdm # 可以在循环中添加进度条
这一行导入了tqdm库,它是一个在循环中显示进度条的库。
x = [1, 2, 3] # list
print(x[:10] + [0] * -7)
这里首先定义了一个列表x。接下来,x[:10]表示获取列表x的前10个元素,但因为x只有3个元素,所以它其实会返回整个x。[0] * -7将产生一个空列表,因为乘以一个负数的结果是空。所以print语句的输出将是[1, 2, 3]。
from transformers import AutoTokenizer
这里从transformers库中导入了AutoTokenizer。transformers库提供了很多预训练模型及其相关的工具,AutoTokenizer是其中的一个。
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
使用bert-base-chinese这个预训练模型的tokenizer。这个tokenizer是针对中文BERT模型的。
labels = []
train_list = []
with open("../data/ChnSentiCorp.txt", mode='r', encoding='utf-8') as file:for line in tqdm(file.readlines()):line = line.strip().split(',')labels.append(int(line[0]))text = tokenizer.encode(line[1])token = text[:80] + [0] * (80 - len(text))train_list.append(token)
这段代码读取文件ChnSentiCorp.txt并从中获取标签和文本数据。每一行都是由一个标签和文本组成的,两者之间用逗号分隔。文本数据被tokenized并被截断或填充至长度80。
import numpy as nplabels = np.array(labels)
train_list = np.array(train_list)
这里首先导入了numpy库,并将labels和train_list转换为numpy数组。
from transformers import TFBertForSequenceClassification
从transformers库中导入了用于序列分类的TFBert模型。
model = TFBertForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=2)
初始化一个预训练的BERT模型用于序列分类。这里指定了类别数量为2。
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
模型被编译,使用了sparse_categorical_crossentropy作为损失函数,并设置了accuracy作为评估指标。model.summary()会显示模型的结构和参数信息。
model.summary()会输出如下内容。
Model: "tf_bert_for_sequence_classification"
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================bert (TFBertMainLayer) multiple 102267648 dropout_37 (Dropout) multiple 0 classifier (Dense) multiple 1538 =================================================================
Total params: 102,269,186
Trainable params: 102,269,186
Non-trainable params: 0
_________________________________________________________________
result = model.fit(x=train_list, y=labels, batch_size=128, epochs=10)
Epoch 1/10
61/61 [==============================] - 2293s 36s/step - loss: 0.9221 - accuracy: 0.3204
Epoch 2/10
61/61 [==============================] - 2139s 35s/step - loss: 0.6931 - accuracy: 0.3147
Epoch 3/10
61/61 [==============================] - 2078s 34s/step - loss: 0.6931 - accuracy: 0.3147
Epoch 4/10
61/61 [==============================] - 1897s 31s/step - loss: 0.6931 - accuracy: 0.3147
Epoch 5/10
61/61 [==============================] - 1898s 31s/step - loss: 0.6931 - accuracy: 0.3147
Epoch 6/10
61/61 [==============================] - 1904s 31s/step - loss: 0.6931 - accuracy: 0.3147
Epoch 7/10
61/61 [==============================] - 1895s 31s/step - loss: 0.6931 - accuracy: 0.3147
Epoch 8/10
61/61 [==============================] - 1887s 31s/step - loss: 0.6931 - accuracy: 0.3147
Epoch 9/10
61/61 [==============================] - 1878s 31s/step - loss: 0.6931 - accuracy: 0.3147
Epoch 10/10
61/61 [==============================] - 1875s 31s/step - loss: 0.6931 - accuracy: 0.3147
print(result.history)
{'loss': [0.9221097230911255, 0.6931471228599548, 0.6931471228599548, 0.6931471228599548, 0.6931471228599548, 0.6931471228599548, 0.6931471228599548, 0.6931471228599548, 0.6931471228599548, 0.6931471228599548],
'accuracy': [0.3204120993614197, 0.3147456645965576, 0.3147456645965576, 0.3147456645965576, 0.3147456645965576, 0.3147456645965576, 0.3147456645965576, 0.3147456645965576, 0.3147456645965576, 0.3147456645965576]
}
模型训练过程。使用train_list作为输入数据,labels作为标签。批大小设置为128,总共训练10轮。训练完毕后,会打印训练历史数据。
4. 报错解决
执行下面的代码的时候报错:
from transformers import TFBertForSequenceClassification
model = TFBertForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=2)
报错信息如下:
requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /bert-base-chinese/resolve/main/pytorch_model.bin (Caused by ConnectTimeoutError(<urllib3.connection.VerifiedHTTPSConnection object at 0x000001AAEB8F3700>, 'Connection to huggingface.co timed out. (connect timeout=10)'))
4.1 解决思路
您的报错信息提示了连接超时问题。当您尝试从huggingface的服务器加载预训练的模型时,出现了这个问题。
以下是可能的原因及其解决方案:
-
网络问题:您的机器可能无法访问huggingface的服务器。这可能是由于网络速度慢、防火墙设置、网络断开或其他网络相关问题。
解决方案:
- 请确保您的网络连接正常。
- 试试是否可以手动访问
huggingface.co网站。 - 检查您的防火墙或代理设置,确保它们没有阻止您访问huggingface的服务器。
-
Huggingface服务器问题:有时,由于服务器的高负载或其他问题,huggingface的服务器可能会暂时不可用。
解决方案:
- 稍后再试。
-
使用代理:如果您处于一个需要代理访问外部网站的网络环境中(如在某些公司或国家),那么可能需要配置代理。
解决方案:
- 设置Python的代理,或使用VPN。
-
下载模型并本地加载:如果以上方法都不起作用,您可以手动下载模型,然后从本地加载。
解决方案:
- 手动从huggingface的模型库中下载
bert-base-chinese模型。 - 将下载的模型存放在本地目录中,然后使用
from_pretrained方法加载该目录。
- 手动从huggingface的模型库中下载
例如:
model = TFBertForSequenceClassification.from_pretrained("/path_to_directory/bert-base-chinese", num_labels=2)
其中/path_to_directory/bert-base-chinese是您存放模型文件的本地目录。
4.2 解决方法
科学上网
5. Bert介绍
5.1 什么是Bert
当然可以!
BERT简介:
BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年提出的一个预训练的深度学习模型,用于自然语言处理(NLP)任务。BERT的突出特点是其双向性,即它可以同时考虑文本中的前后上下文,从而捕捉更丰富的语义信息。
BERT的核心思想:
- 双向性:传统的语言模型,如LSTM和GRU,是单向的,只能考虑前面的上下文或后面的上下文。BERT通过同时考虑前后上下文来捕捉更复杂的语义信息。
- 预训练和微调:BERT首先在大量无标签文本上进行预训练,然后可以用少量的标注数据进行微调,以适应特定的NLP任务。
- Transformer架构:BERT基于Transformer架构,它是一个高效的自注意力机制,可以捕捉文本中长距离的依赖关系。
BERT的预训练策略:
- Masked Language Model (MLM):随机遮蔽句子中的一些单词,并让模型预测这些遮蔽单词。这样,模型必须学习理解文本的上下文信息,以预测遮蔽的部分。
- Next Sentence Prediction (NSP):模型接收两个句子作为输入,并预测第二个句子是否是第一个句子的下一个句子。
BERT的应用:
经过预训练后的BERT模型可以被微调并应用于各种NLP任务,如文本分类、命名实体识别、问答系统等。由于BERT能够捕捉丰富的上下文信息,它在许多NLP任务中都取得了当时的最先进性能。
为什么BERT如此受欢迎?
- 强大的性能:BERT在多种NLP任务上都达到了当时的最先进的性能。
- 通用性:同一个预训练的BERT模型可以被微调并应用于多种NLP任务,无需从头开始训练。
- 可用性:由于Google和其他组织发布了预训练的BERT模型和相关工具,开发者可以轻松地使用BERT进行自己的NLP项目。
总结:
BERT是当前NLP领域的一个里程碑,它改变了我们如何处理和理解文本的方式。对于初学者,理解BERT及其工作原理是深入研究现代NLP的关键。希望这个简介能帮助您对BERT有一个初步的了解!
相关文章:

NLP之Bert实现文本分类
文章目录 1. 代码展示2. 整体流程介绍3. 代码解读4. 报错解决4.1 解决思路4.2 解决方法 5. Bert介绍5.1 什么是BertBERT简介:BERT的核心思想:BERT的预训练策略:BERT的应用:为什么BERT如此受欢迎?总结: 1. 代…...
Pytorch从零开始实战08
Pytorch从零开始实战——YOLOv5-C3模块实现 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——YOLOv5-C3模块实现环境准备数据集模型选择开始训练可视化模型预测总结 环境准备 本文基于Jupyter notebook,使用Python3.8,…...
docker部署Jenkins(Jenkins+Gitlab+Maven实现CI/CD)
GitLab介绍 GitLab是一个用于仓库管理系统的开源项目,使用Git作为代码管理工具,并在此基础上搭建起来的Web服务,可通过Web界面进行访问公开的或者私人项目。它拥有与Github类似的功能,能够浏览源代码,管理缺陷和注释。…...
mapbox使用marker创建html点位信息
mapbox使用marker创建html点位信息 codePen地址 mapboxgl.accessToken "pk.eyJ1IjoibGl1emhhbzI1ODAiLCJhIjoiY2xmcnV5c2NtMDd4eDNvbmxsbHEwYTMwbCJ9.T0QCxGEJsLWC9ncE1B1rRw"; const center [121.29786, 31.19365]; const map new mapboxgl.Map({container: &quo…...
项目构建工具maven的基本配置
👑 博主简介:知名开发工程师 👣 出没地点:北京 💊 2023年目标:成为一个大佬 ——————————————————————————————————————————— 版权声明:本文为原创文…...

超详细docker学习笔记
关于docker 一、基本概念什么是docker?docker组件:我们能用docker做什么Docker与配置管理:Docker的技术组件Docker资源Docker与虚拟机对比 二、安装docker三、镜像命令启动命令帮助命令列出本地主机上的镜像在远程仓库中搜索镜像查看占据的空间删除镜像…...
Adobe acrobat 11.0版本 pdf阅读器修改背景颜色方法
打开菜单栏,编辑,首选项,选择辅助工具项,页面中 勾选 替换文档颜色,页面背景自己选择一个颜色,然后确定,即可!...
HCIA数据通信——路由协议
数据通信——网络层(OSPF基础特性)_咕噜跳的博客-CSDN博客 数据通信——网络层(RIP与BGP)_咕噜跳的博客-CSDN博客 上述是之前写的理论知识部分,懒得在实验中再次提及了。这次做RIP协议以及OSPF协议。不过RIP协议不常用…...

十种常见典型算法
什么是算法? 简而言之,任何定义明确的计算步骤都可称为算法,接受一个或一组值为输入,输出一个或一组值。(来源:homas H. Cormen, Chales E. Leiserson 《算法导论第3版》) 可以这样理…...

python-列表推导式、生成器表达式
一、列表推导式 列表推导式:用一句话来生成列表 语法:[结果 for循环 判断] 筛选模式: 二、生成器表达式...
NLP 模型中的偏差和公平性检测
一、说明 近年来,自然语言处理 (NLP) 模型广受欢迎,彻底改变了我们与文本数据交互和分析的方式。这些基于深度学习技术的模型在广泛的应用中表现出了卓越的能力,从聊天机器人和语言翻译到情感分析和文本生成。然而&…...

YUV图像格式详解
1.概述 YUV是一种图像颜色编码方式。 相对于常见且直观的RGB颜色编码,YUV的产生自有其意义,它基于人眼对亮度比色彩的敏感度更高的特点,使用Y、U、V三个分量来表示颜色,并通过降低U、V分量的采样率,尽可能保证图像质…...

软考高项-质量管理措施
质量规划 编制《项目质量规划书》、《项目验收规范》等质量文件,对文件进行评审,对项目成员进行质量管理培训; 质量保证 评审、过程分析、定期对项目进行检查并跟踪改进情况; 质量控制 测试、因果分析、变更、统计抽样等。 80/…...
)
Redis那些事儿(一)
说到redis大家都不陌生,其中包括:共有16个数据库,默认为第0个数据库;数据以key-value键值的形式存储;数据类型包括String、List、Hash、Set等,其中最常用的是字符串;是单线程的、基于内存的&…...

【多媒体文件格式】M3U8
M3U8 M3U8文件是指UTF-8编码格式的M3U文件(M3U使用Latin-1字符集编码)。M3U文件是一个记录索引的纯文本文件,打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放。 m3u8基本上可以认为就是.m3u格式文件&#x…...

linux中xargs的实用技巧
在Linux命令行中,有许多强大的工具可以帮助我们处理和操作文件、目录以及其他数据。其中之一就是xargs命令。xargs命令可以将标准输入数据转换成命令行参数,从而提高命令的效率和灵活性。本文将介绍xargs命令的基本用法,并通过生动的代码和输…...

【Jmeter】生成html格式接口自动化测试报告
jmeter自带执行结果查看的插件,但是需要在jmeter工具中才能查看,如果要向领导提交测试结果,不够方便直观。 笔者刚做了这方面的尝试,总结出来分享给大家。 这里需要用到ant来执行测试用例并生成HTML格式测试报告。 一、ant下载安…...
如何将极狐GitLab 漏洞报告导出为 HTML 或 PDF 格式或导出到 Jira
目录 导出为 HTML/PDF 将漏洞信息导出到 Jira 参考资料 极狐GitLab 的漏洞报告功能可以让开发人员在统一的平台上面管理代码,对其进行安全扫描、管理漏洞报告并修复漏洞。但有些团队更喜欢使用类似 Jira 的单独工具来管理他们的安全漏洞。他们也可能需要以易于理…...
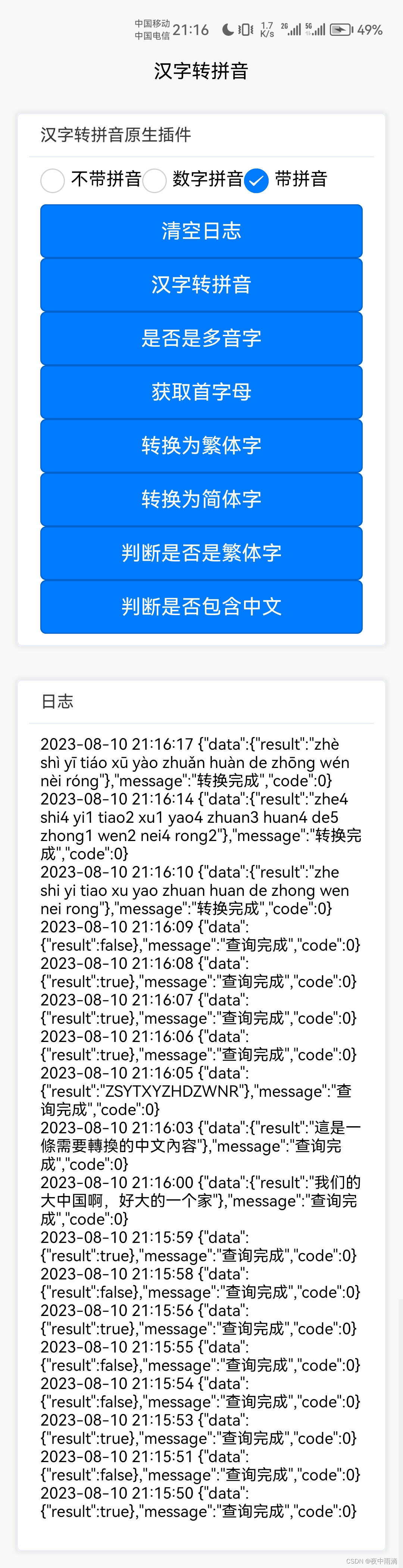
uniapp原生插件之安卓文字转拼音原生插件
插件介绍 安卓文字转拼音插件,支持转换为声调模式和非声调模式,支持繁体和简体互相转换 插件地址 安卓文字转拼音原生插件 - DCloud 插件市场 超级福利 uniapp 插件购买超级福利 详细使用文档 uniapp 安卓文字转拼音原生插件 用法 在需要使用插…...
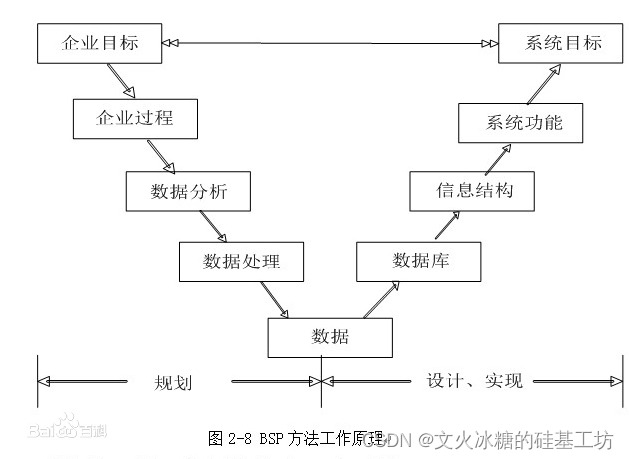
[架构之路-254/创业之路-85]:目标系统 - 横向管理 - 源头:信息系统战略规划的常用方法论,为软件工程的实施指明方向!!!
目录 总论: 一、数据处理阶段的方法论 1.1 企业信息系统规划法BSP 1.1.1 概述 1.1.2 原则 1.2 关键成功因素法CSF 1.2.1 概述 1.2.2 常见的企业成功的关键因素 1.3 战略集合转化法SST:把战略目标转化成信息的集合 二、管理信息系统阶段的方法论…...

【免费下载】 探索三维世界的利器:Qt+OpenGL三维地形显示项目
探索三维世界的利器:QtOpenGL三维地形显示项目 项目介绍 在数字化的时代,三维地形显示技术已经成为地理信息系统(GIS)、游戏开发、虚拟现实等领域不可或缺的一部分。QtOpenGL三维地形显示项目 是一个开源的、跨平台的三维地形显示…...

【亲测免费】 Python Qt 图形界面编程资源下载
Python Qt 图形界面编程资源下载 【下载地址】PythonQt图形界面编程资源下载 《Python Qt 图形界面编程》课程涵盖了PySide2、PyQt5、PyQt和PySide等框架的使用,帮助学习者掌握Python图形化界面编程的核心知识。课程内容详实,适合初学者入门,…...

别再死记硬背!用Python+Verilog双视角图解2ASK/2FSK调制解调原理
PythonVerilog双视角图解2ASK/2FSK调制解调原理 通信工程的学习者常常陷入理论公式与硬件实现之间的认知断层。当教科书上的数学表达式突然变成硬件描述语言时,那种手足无措的感觉我深有体会——三年前第一次接触Verilog实现调制解调时,盯着代码里那些分…...

如何永久保存微信聊天记录:WeChatMsg开源工具的完整解决方案
如何永久保存微信聊天记录:WeChatMsg开源工具的完整解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we…...

LinkSwift:2025年开源网盘直链下载助手的完整指南
LinkSwift:2025年开源网盘直链下载助手的完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...
)
手把手教你用YOLACT训练自己的数据集:从COCO格式准备到模型推理全流程(附Python源码)
YOLACT实战指南:从数据标注到工业级实例分割模型部署 1. 实例分割技术演进与YOLACT核心优势 在计算机视觉领域,实例分割一直被视为目标检测与语义分割的结合体。不同于简单的边界框检测或像素级分类,实例分割要求算法能够区分同一类别的不同个…...

如何彻底摆脱网盘限速:8大主流网盘直链下载助手完整指南
如何彻底摆脱网盘限速:8大主流网盘直链下载助手完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...
)
从零到一:用面包板和晶体管手搓一个4bit加法器(附完整电路图与避坑指南)
从零到一:用面包板和晶体管手搓一个4bit加法器(附完整电路图与避坑指南) 深夜的实验室里,面包板上横七竖八地插着几十个三极管和电阻,当我第三次测量到错误的输出电平时,终于意识到——这个看似简单的4bit加…...

手把手拆解FD-SOI工艺流程:从SOI衬底到应变硅外延的保姆级图解
从SOI衬底到应变硅外延:FD-SOI工艺全流程拆解指南 想象一下建造一座微型城市,每一栋建筑只有头发丝直径的万分之一大小。这就是FD-SOI工艺工程师的日常工作——在硅片上用原子级精度"建造"晶体管。与传统的体硅工艺不同,FD-SOI&…...
)
从SPI到QSPI:你的Flash读写速度慢?可能是模式没选对(以W25Q128JV为例)
从SPI到QSPI:解锁W25Q128JV Flash的隐藏性能 在嵌入式系统开发中,存储器的读写速度往往是制约整体性能的关键瓶颈。许多工程师在使用常见的SPI Flash芯片如W25Q128JV时,可能已经习惯了标准的SPI接口操作,却不知道通过简单的模式切…...