Pytorch从零开始实战08
Pytorch从零开始实战——YOLOv5-C3模块实现
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——YOLOv5-C3模块实现
- 环境准备
- 数据集
- 模型选择
- 开始训练
- 可视化
- 模型预测
- 总结
环境准备
本文基于Jupyter notebook,使用Python3.8,Pytorch2.0.1+cu118,torchvision0.15.2,需读者自行配置好环境且有一些深度学习理论基础。本次实验的目的理解YOLOv5-C3模块。
第一步,导入常用包
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn.functional as F
import random
from time import time
import numpy as np
import pandas as pd
import datetime
import gc
import os
import copy
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
设置随机数种子
torch.manual_seed(428)
torch.cuda.manual_seed(428)
torch.cuda.manual_seed_all(428)
random.seed(428)
np.random.seed(428)
创建设备对象,并且查看GPU数量
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device, torch.cuda.device_count() # (device(type='cuda'), 2)
数据集
本次数据集是使用之前用过的天气识别的数据集,分别有四个类别,cloudy、rain、shine、sunrise,不同的类别存放在不同的文件夹中,文件夹名是类别名。
使用pathlib查看类别
import pathlib
data_dir = './data/weather_photos/'
data_dir = pathlib.Path(data_dir) # 转成pathlib.Path对象
data_paths = list(data_dir.glob('*'))
classNames = [str(path).split("/")[2] for path in data_paths]
classNames # ['cloudy', 'sunrise', 'shine', 'rain']
使用transforms对数据集进行统一处理,并且根据文件夹名映射对应标签
all_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])total_data = datasets.ImageFolder("./data/weather_photos/", transform=all_transforms)
total_data.class_to_idx # {'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3}
随机查看五张图片
def plotsample(data):fig, axs = plt.subplots(1, 5, figsize=(10, 10)) #建立子图for i in range(5):num = random.randint(0, len(data) - 1) #首先选取随机数,随机选取五次#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据#而展示图像用的imshow函数最常见的输入格式也是3通道npimg = torchvision.utils.make_grid(data[num][0]).numpy()nplabel = data[num][1] #提取标签 #将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取axs[i].imshow(np.transpose(npimg, (1, 2, 0))) axs[i].set_title(nplabel) #给每个子图加上标签axs[i].axis("off") #消除每个子图的坐标轴plotsample(total_data)

根据8比2划分数据集和测试集,并且利用DataLoader划分批次和随机打乱
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_ds, test_ds = torch.utils.data.random_split(total_data, [train_size, test_size])batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,batch_size=batch_size,shuffle=True,)
test_dl = torch.utils.data.DataLoader(test_ds,batch_size=batch_size,shuffle=True,)len(train_dl.dataset), len(test_dl.dataset) # (901, 226)
模型选择
此次模型借用K同学所绘制的模型图
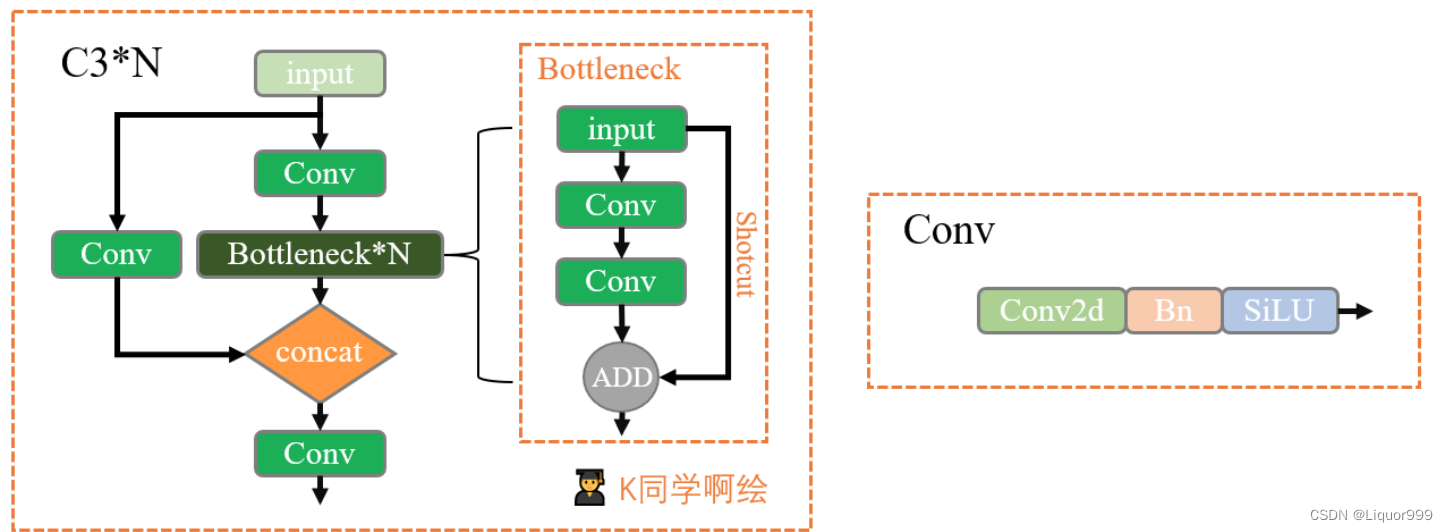
定义了一个autopad函数,用于确定卷积操作的填充,如果提供了p参数,则函数将使用提供的填充大小,否则函数中的填充计算将根据卷积核的大小k来确定,如果k是整数,那么将应用方形卷积核,填充大小将设置为k // 2,如果k是一个包含两个整数的列表,那么将应用矩形卷积核,填充大小将分别设置为列表中两个值的一半。
def autopad(k, p=None): if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] return p
定义自定义卷积层,在init方法中:创建了一个卷积层 self.conv,使用了 nn.Conv2d,该卷积层接受输入通道数 c1,输出通道数 c2,卷积核大小 k,步幅 s,填充 p,分组数 g,并且没有偏置项(bias=False)。创建了一个批归一化层 self.bn,用于规范化卷积层的输出。创建了一个激活函数层 self.act,其类型取决于 act 参数。如果 act 为 True,它将使用 SiLU(Sigmoid Linear Unit)激活函数;如果 act 为其他的 nn.Module 类,它将直接使用提供的激活函数;否则,它将使用恒等函数(nn.Identity)作为激活函数。其中,SiLU激活函数为SiLU(x) = x * sigmoid(x)。
class Conv(nn.Module):def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))
定义Bottleneck类,这个模块的作用是实现标准的残差连接,以提高网络性能。在 init方法中:计算了中间隐藏通道数 c_,它是输出通道数 c2 乘以扩张因子 e 的整数部分。创建了两个 Conv 模块 self.cv1 和 self.cv2,分别用于进行卷积操作。self.cv1 使用 1x1 的卷积核,将输入特征图的通道数从 c1 变换为 c_。self.cv2 使用 3x3 的卷积核,将通道数从 c_ 变换为 c2。创建了一个布尔值 self.add,用于指示是否应用残差连接。self.add 为 True 的条件是 shortcut 为 True 且输入通道数 c1 等于输出通道数 c2。
在forward 方法中,首先,通过 self.cv1(x) 将输入 x 传递给第一个卷积层,然后通过self.cv2(self.cv1(x)) 将结果传递给第二个卷积层。最后,根据 self.add 的值来决定是否应用残差连接。如果 self.add 为 True,将输入 x 与第二个卷积层的输出相加,否则直接返回第二个卷积层的输出。这样模块在需要时应用残差连接,以保留和传递更多的信息。
class Bottleneck(nn.Module):def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
C3模块整体如上图所示,cv1 和 cv2 是两个独立的卷积操作,它们的输入通道数都是 c1,并经过相应的卷积操作后,输出通道数变为 c_。这是为了将输入特征映射进行降维和变换。cv3 接受 cv1 和 cv2 的输出,并且希望在这两部分特征上进行进一步的操作。为了能够将它们连接起来,cv3 的输入通道数必须匹配这两部分特征的输出通道数的总和,因此是 2 * c_。其中这个模块可以叠加n个Bottleneck块。
class C3(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
最后定义我们的模型
class model_K(nn.Module):def __init__(self):super(model_K, self).__init__()# 卷积模块self.Conv = Conv(3, 32, 3, 2) # C3模块1self.C3_1 = C3(32, 64, 3, 2)# 全连接网络层,用于分类self.classifier = nn.Sequential(nn.Linear(in_features=802816, out_features=100),nn.ReLU(),nn.Linear(in_features=100, out_features=4))def forward(self, x):x = self.Conv(x)x = self.C3_1(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xmodel = model_K().to(device)
使用summary查看模型架构
from torchsummary import summary
summary(model, input_size=(3, 224, 224))

开始训练
定义训练函数
def train(dataloader, model, loss_fn, opt):size = len(dataloader.dataset)num_batches = len(dataloader)train_acc, train_loss = 0, 0for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)opt.zero_grad()loss.backward()opt.step()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
定义测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_acc, test_loss = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss += loss.item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
定义学习率、损失函数、优化算法
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.0001
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
开始训练,epoch设置为30
import time
epochs = 30
train_loss = []
train_acc = []
test_loss = []
test_acc = []T1 = time.time()best_acc = 0
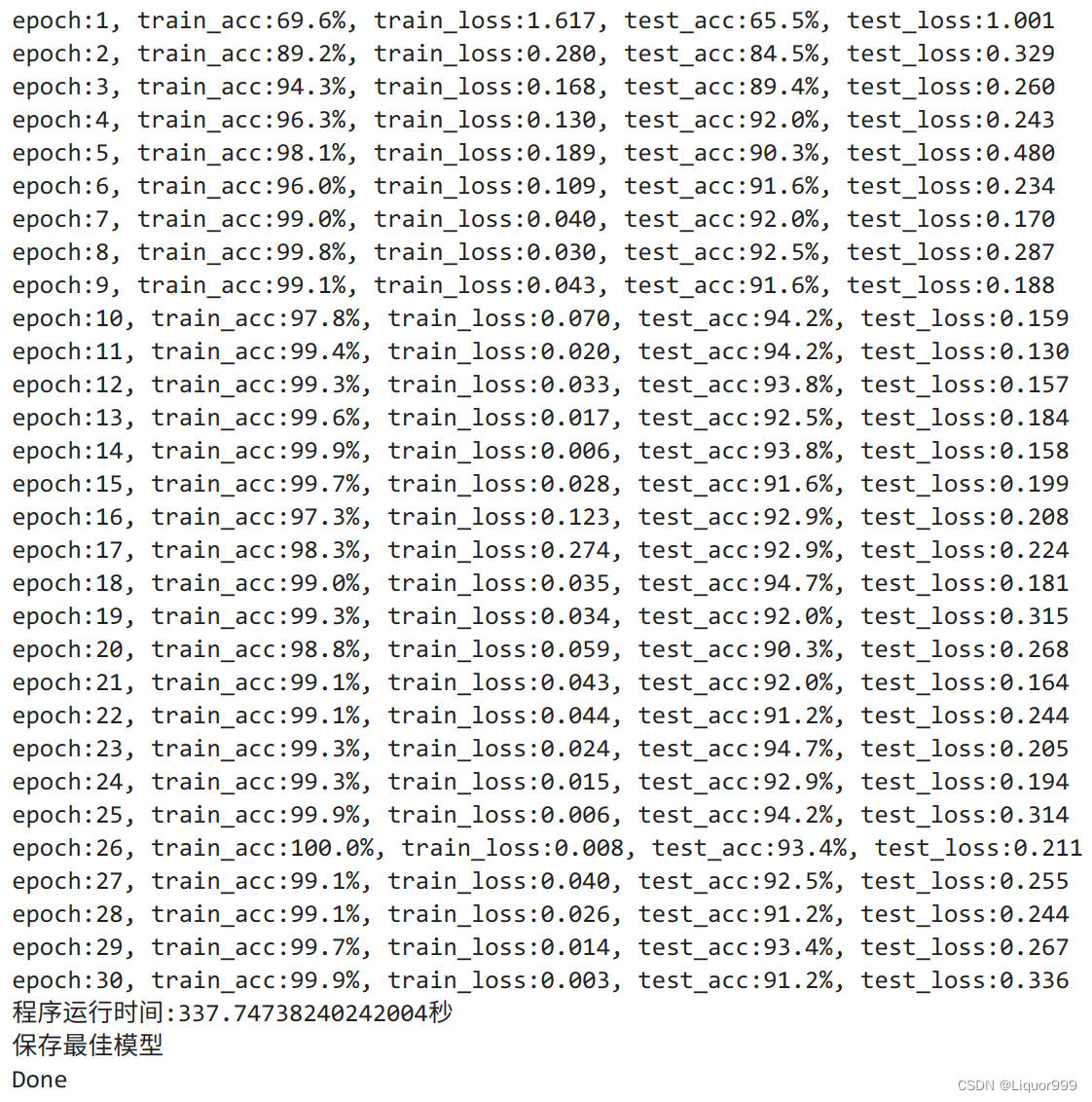
best_model = 0for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval() # 确保模型不会进行训练操作epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)if epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))T2 = time.time()
print('程序运行时间:%s秒' % (T2 - T1))PATH = './best_model.pth' # 保存的参数文件名
if best_model is not None:torch.save(best_model.state_dict(), PATH)print('保存最佳模型')
print("Done")
可视化
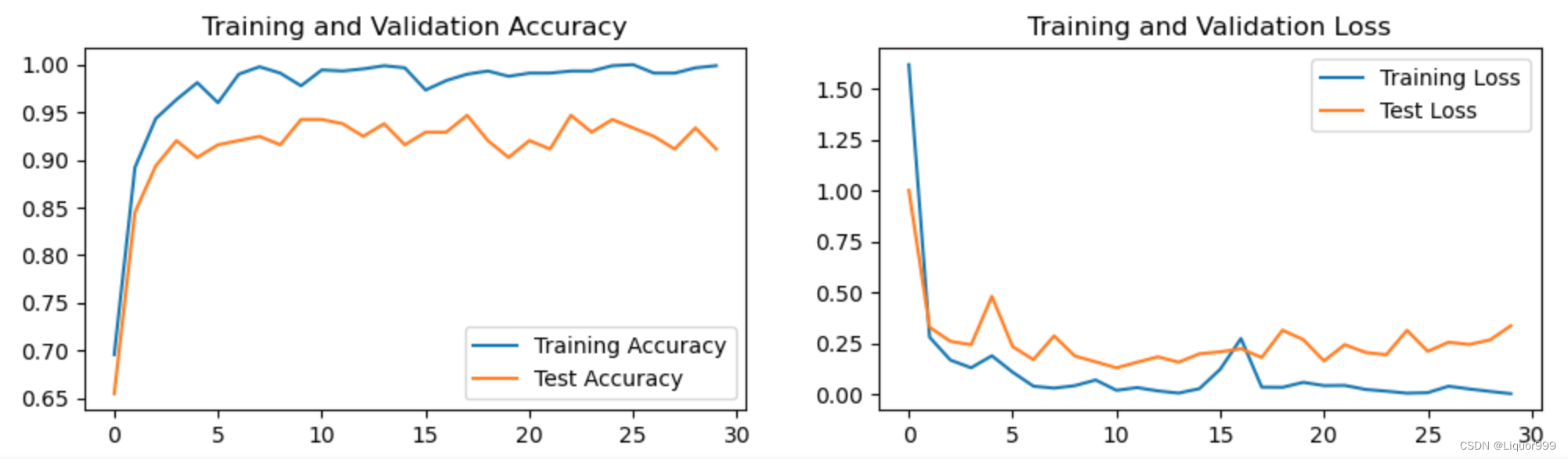
将训练与测试过程可视化
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
模型预测
定义预测函数
from PIL import Image classes = list(total_data.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')
预测一张图片
predict_one_image(image_path='./data/weather_photos/cloudy/cloudy10.jpg', model=model, transform=all_transforms, classes=classes) # 预测结果是:cloudy
查看一下最佳模型的epoch_test_acc, epoch_test_loss
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss # (0.9469026548672567, 0.18065014126477763)
总结
通过这个实验可以了解如何在模型中实现残差连接,这对于训练深度神经网络特别有用。残差连接允许在模块之间传递和保留信息,有助于缓解梯度消失问题和训练更深的网络。
相关文章:
Pytorch从零开始实战08
Pytorch从零开始实战——YOLOv5-C3模块实现 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——YOLOv5-C3模块实现环境准备数据集模型选择开始训练可视化模型预测总结 环境准备 本文基于Jupyter notebook,使用Python3.8,…...
docker部署Jenkins(Jenkins+Gitlab+Maven实现CI/CD)
GitLab介绍 GitLab是一个用于仓库管理系统的开源项目,使用Git作为代码管理工具,并在此基础上搭建起来的Web服务,可通过Web界面进行访问公开的或者私人项目。它拥有与Github类似的功能,能够浏览源代码,管理缺陷和注释。…...
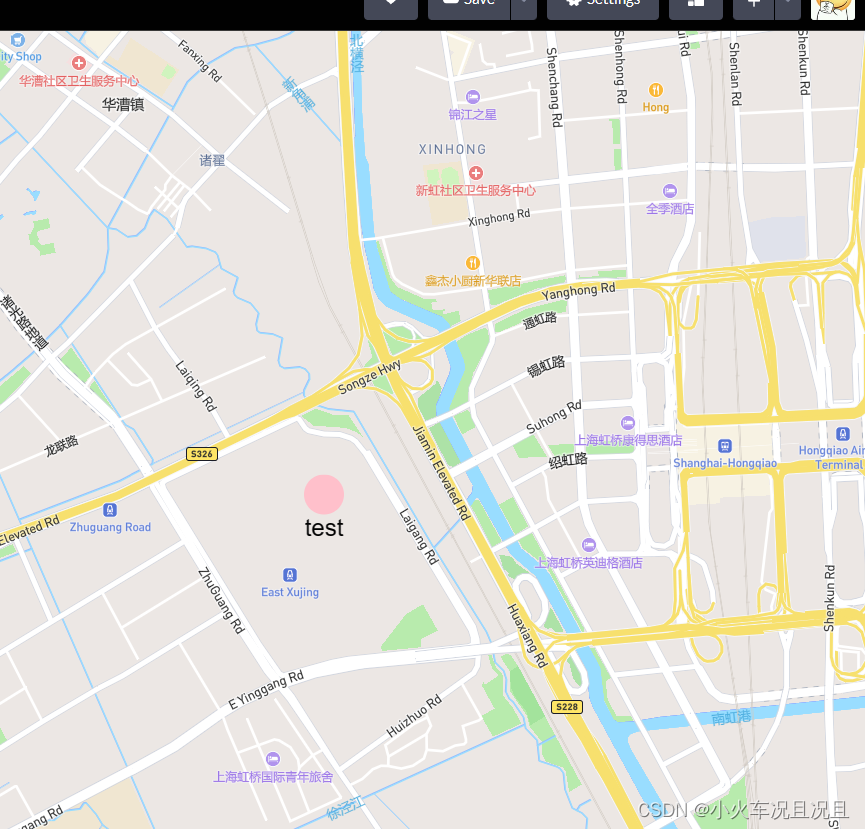
mapbox使用marker创建html点位信息
mapbox使用marker创建html点位信息 codePen地址 mapboxgl.accessToken "pk.eyJ1IjoibGl1emhhbzI1ODAiLCJhIjoiY2xmcnV5c2NtMDd4eDNvbmxsbHEwYTMwbCJ9.T0QCxGEJsLWC9ncE1B1rRw"; const center [121.29786, 31.19365]; const map new mapboxgl.Map({container: &quo…...
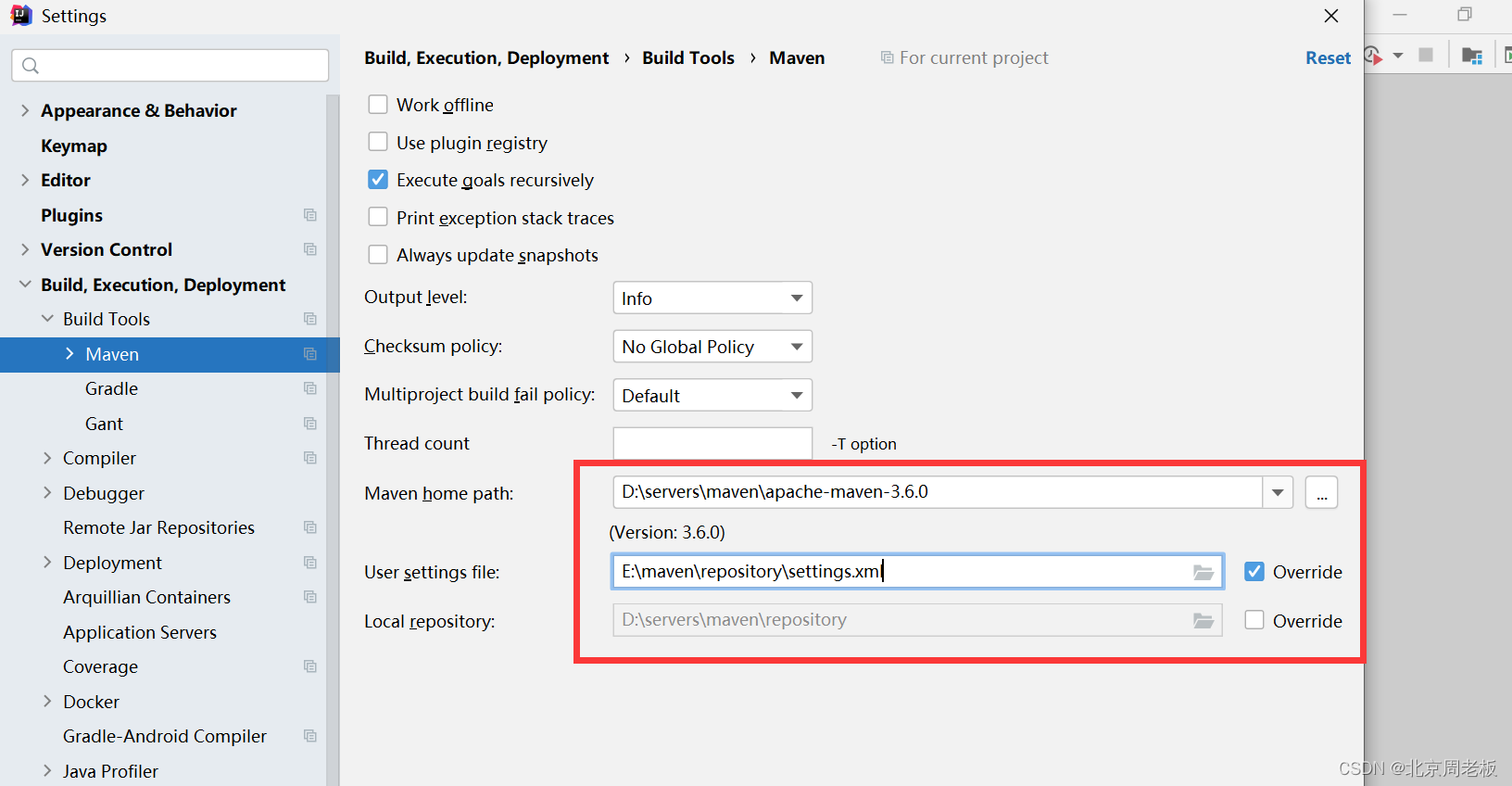
项目构建工具maven的基本配置
👑 博主简介:知名开发工程师 👣 出没地点:北京 💊 2023年目标:成为一个大佬 ——————————————————————————————————————————— 版权声明:本文为原创文…...

超详细docker学习笔记
关于docker 一、基本概念什么是docker?docker组件:我们能用docker做什么Docker与配置管理:Docker的技术组件Docker资源Docker与虚拟机对比 二、安装docker三、镜像命令启动命令帮助命令列出本地主机上的镜像在远程仓库中搜索镜像查看占据的空间删除镜像…...
Adobe acrobat 11.0版本 pdf阅读器修改背景颜色方法
打开菜单栏,编辑,首选项,选择辅助工具项,页面中 勾选 替换文档颜色,页面背景自己选择一个颜色,然后确定,即可!...
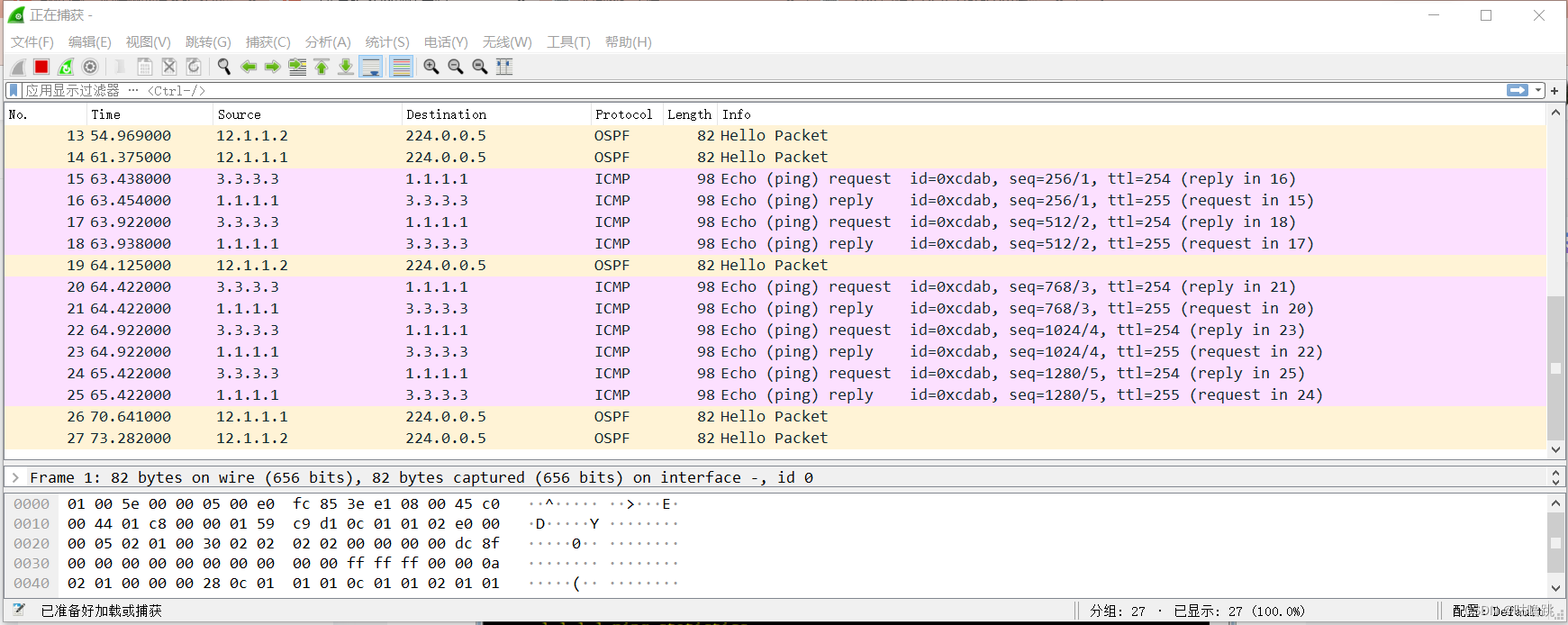
HCIA数据通信——路由协议
数据通信——网络层(OSPF基础特性)_咕噜跳的博客-CSDN博客 数据通信——网络层(RIP与BGP)_咕噜跳的博客-CSDN博客 上述是之前写的理论知识部分,懒得在实验中再次提及了。这次做RIP协议以及OSPF协议。不过RIP协议不常用…...

十种常见典型算法
什么是算法? 简而言之,任何定义明确的计算步骤都可称为算法,接受一个或一组值为输入,输出一个或一组值。(来源:homas H. Cormen, Chales E. Leiserson 《算法导论第3版》) 可以这样理…...

python-列表推导式、生成器表达式
一、列表推导式 列表推导式:用一句话来生成列表 语法:[结果 for循环 判断] 筛选模式: 二、生成器表达式...
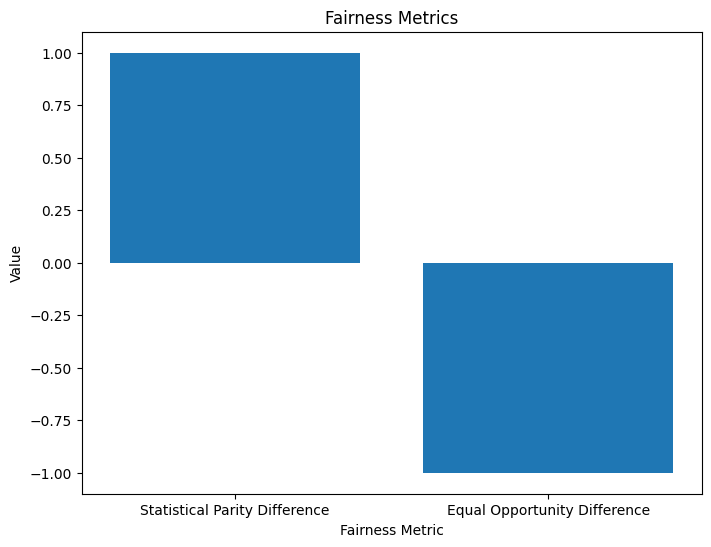
NLP 模型中的偏差和公平性检测
一、说明 近年来,自然语言处理 (NLP) 模型广受欢迎,彻底改变了我们与文本数据交互和分析的方式。这些基于深度学习技术的模型在广泛的应用中表现出了卓越的能力,从聊天机器人和语言翻译到情感分析和文本生成。然而&…...

YUV图像格式详解
1.概述 YUV是一种图像颜色编码方式。 相对于常见且直观的RGB颜色编码,YUV的产生自有其意义,它基于人眼对亮度比色彩的敏感度更高的特点,使用Y、U、V三个分量来表示颜色,并通过降低U、V分量的采样率,尽可能保证图像质…...

软考高项-质量管理措施
质量规划 编制《项目质量规划书》、《项目验收规范》等质量文件,对文件进行评审,对项目成员进行质量管理培训; 质量保证 评审、过程分析、定期对项目进行检查并跟踪改进情况; 质量控制 测试、因果分析、变更、统计抽样等。 80/…...
)
Redis那些事儿(一)
说到redis大家都不陌生,其中包括:共有16个数据库,默认为第0个数据库;数据以key-value键值的形式存储;数据类型包括String、List、Hash、Set等,其中最常用的是字符串;是单线程的、基于内存的&…...

【多媒体文件格式】M3U8
M3U8 M3U8文件是指UTF-8编码格式的M3U文件(M3U使用Latin-1字符集编码)。M3U文件是一个记录索引的纯文本文件,打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放。 m3u8基本上可以认为就是.m3u格式文件&#x…...

linux中xargs的实用技巧
在Linux命令行中,有许多强大的工具可以帮助我们处理和操作文件、目录以及其他数据。其中之一就是xargs命令。xargs命令可以将标准输入数据转换成命令行参数,从而提高命令的效率和灵活性。本文将介绍xargs命令的基本用法,并通过生动的代码和输…...

【Jmeter】生成html格式接口自动化测试报告
jmeter自带执行结果查看的插件,但是需要在jmeter工具中才能查看,如果要向领导提交测试结果,不够方便直观。 笔者刚做了这方面的尝试,总结出来分享给大家。 这里需要用到ant来执行测试用例并生成HTML格式测试报告。 一、ant下载安…...
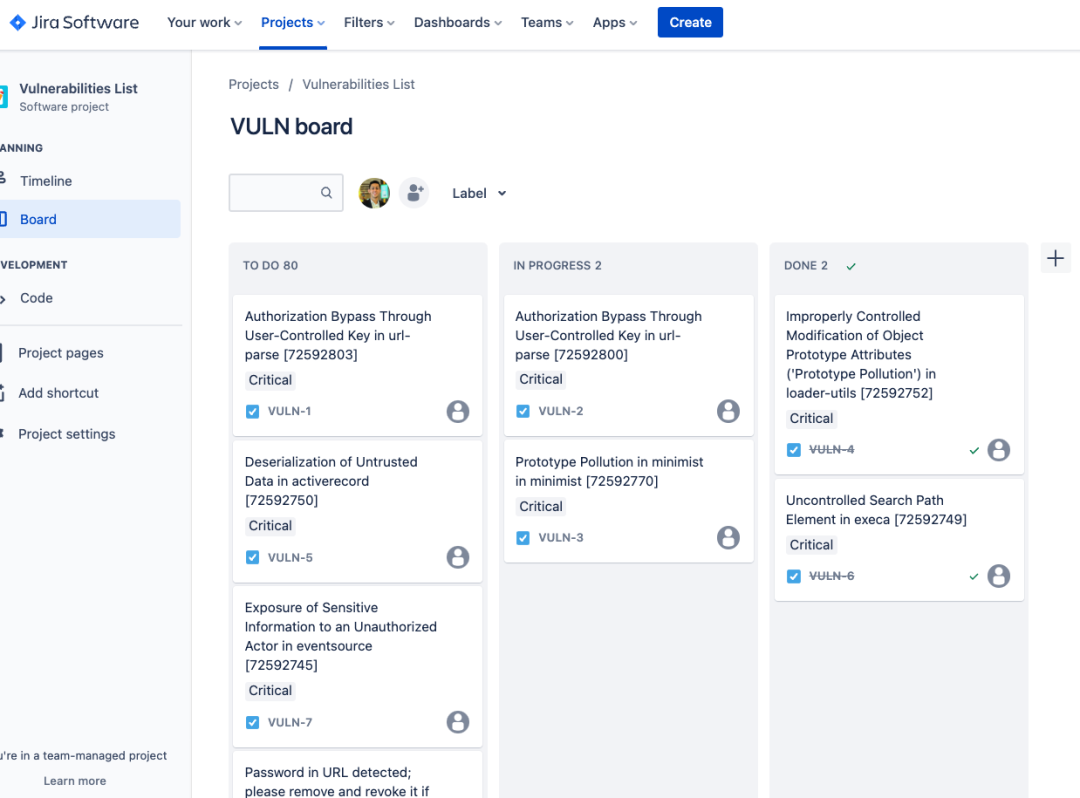
如何将极狐GitLab 漏洞报告导出为 HTML 或 PDF 格式或导出到 Jira
目录 导出为 HTML/PDF 将漏洞信息导出到 Jira 参考资料 极狐GitLab 的漏洞报告功能可以让开发人员在统一的平台上面管理代码,对其进行安全扫描、管理漏洞报告并修复漏洞。但有些团队更喜欢使用类似 Jira 的单独工具来管理他们的安全漏洞。他们也可能需要以易于理…...
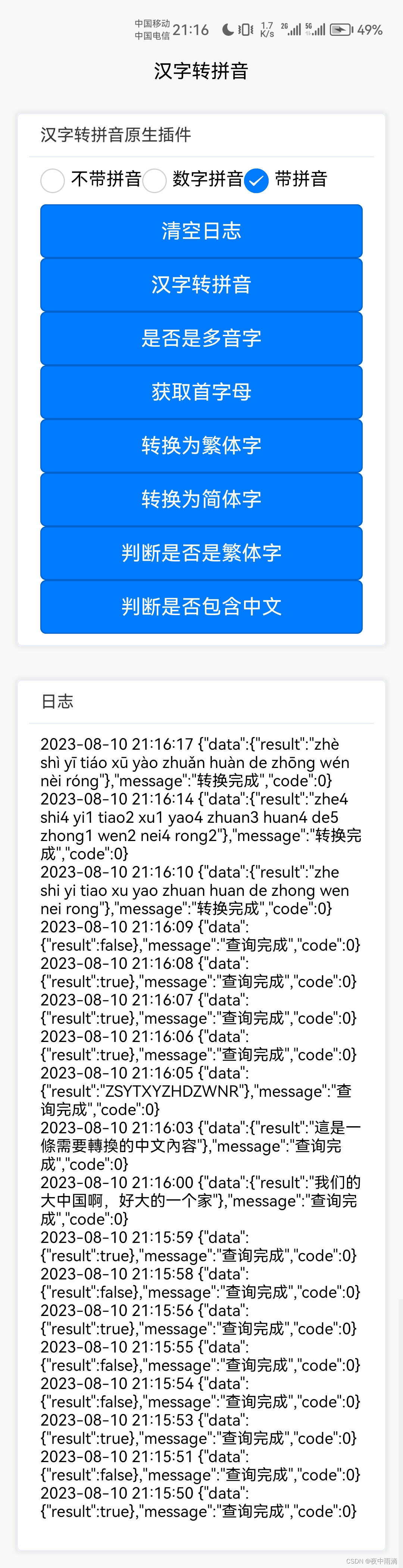
uniapp原生插件之安卓文字转拼音原生插件
插件介绍 安卓文字转拼音插件,支持转换为声调模式和非声调模式,支持繁体和简体互相转换 插件地址 安卓文字转拼音原生插件 - DCloud 插件市场 超级福利 uniapp 插件购买超级福利 详细使用文档 uniapp 安卓文字转拼音原生插件 用法 在需要使用插…...
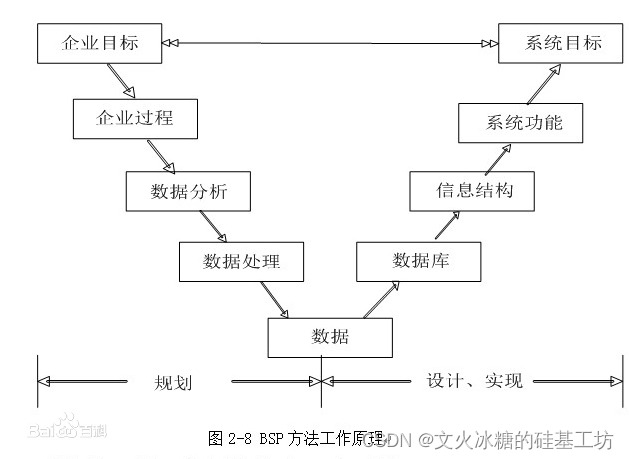
[架构之路-254/创业之路-85]:目标系统 - 横向管理 - 源头:信息系统战略规划的常用方法论,为软件工程的实施指明方向!!!
目录 总论: 一、数据处理阶段的方法论 1.1 企业信息系统规划法BSP 1.1.1 概述 1.1.2 原则 1.2 关键成功因素法CSF 1.2.1 概述 1.2.2 常见的企业成功的关键因素 1.3 战略集合转化法SST:把战略目标转化成信息的集合 二、管理信息系统阶段的方法论…...

CSP-J 2023真题解析
T1 小苹果 一、题目链接 P9748 [CSP-J 2023] 小苹果 二、题目大意 现有 n n n 个苹果从左到右排成一列,编号为从 1 1 1 到 n n n。 每天都会从中拿走一些苹果。拿取规则是,从左侧第 1 1 1 个苹果开始、每隔 2 2 2 个苹果拿走 1 1 1 个苹果。随…...

从API密钥管理角度感受Taotoken控制台的安全与便捷
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API密钥管理角度感受Taotoken控制台的安全与便捷 作为项目或团队的技术负责人,管理多个大模型服务的API密钥是一项既…...

如何构建拼多多数据采集系统:面向电商决策者的战略投资方案
如何构建拼多多数据采集系统:面向电商决策者的战略投资方案 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 在拼多多平台占据中国电商市场重要份额的…...

长期使用聚合API平台,对账单清晰度与费用追溯的满意度反馈
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用聚合API平台,对账单清晰度与费用追溯的满意度反馈 作为一名长期负责项目维护的开发者,我所在团队在…...

Windows触控板驱动终极实战:让苹果设备在Windows平台重获新生
Windows触控板驱动终极实战:让苹果设备在Windows平台重获新生 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/ma/mac-precision-touc…...

终极免费二维码修复方案:QRazyBox专业工具完全指南
终极免费二维码修复方案:QRazyBox专业工具完全指南 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 还在为损坏的二维码无法扫描而烦恼吗?QRazyBox这款强大的QR二维码修…...

Illustrator批量替换脚本终极指南:5分钟掌握高效设计自动化
Illustrator批量替换脚本终极指南:5分钟掌握高效设计自动化 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 你是否曾经在Adobe Illustrator中花费数小时手动替换数十个甚…...

Go 入门 08:goroutine 与 channel
Go 入门 08:goroutine 与 channel 并发是 Go 的招牌特性。Rob Pike 提出 “Don’t communicate by sharing memory; share memory by communicating”——不要通过共享内存来通信,而要通过通信来共享内存。这正是 goroutine channel 的核心哲学。 一、g…...
开发的经验总结)
使用AI(龙虾)开发的经验总结
一、使用AI辅助开发的两个核心前提 1.先搞清楚再开口:明确问题边界与目标 在向AI描述问题之前,开发者必须自己先理清整个业务流程、技术上下文和预期目标。这包括: 代码需要改哪里? 明确具体的文件、类、方法或模块。改什么&#…...

【亲测免费】 普冉PY32F002A移植FreeRTOS资源文件
普冉PY32F002A移植FreeRTOS资源文件 【下载地址】普冉PY32F002A移植FreeRTOS资源文件 本资源文件提供了将FreeRTOS V9.0移植到普冉M0芯片PY32F002A的完整示例。开发环境基于KEIL,并使用了LL库进行移植。该示例展示了如何在PY32F002A芯片上运行四个任务,并…...

【亲测免费】 TSK UF系列Prober操作手册下载
TSK UF系列Prober操作手册下载 【下载地址】TSKUF系列Prober操作手册下载 本仓库提供TSK UF系列Prober的操作手册下载,具体为UF190/UF200系列的manual。TSK UF系列Prober是半导体厂针测的重要设备,该手册详细介绍了设备的各项功能、操作步骤以及维护保养…...