Java8 Stream API全面解析——高效流式编程的秘诀
文章目录
- 什么是 Stream Api?
- 快速入门
- 流的操作
- 创建流
- 中间操作
- filter 过滤
- map 数据转换
- flatMap 合并流
- distinct 去重
- sorted 排序
- limit 限流
- skip 跳过
- peek 操作
- 终结操作
- forEach 遍历
- forEachOrdered 有序遍历
- count 统计数量
- min 最小值
- max 最大值
- reduce 聚合
- collect 收集
- anyMatch 任意匹配
- allMatch 全匹配
- noneMatch 全不匹配
- findFirst 查找第一个
- findAny
什么是 Stream Api?
Stream流的由来可以追溯到函数式编程语言,特别是Haskell语言的概念。函数式编程强调以函数为基本构建块,并通过组合和转换函数来操作数据。
Java 8引入了Lambda表达式,使得函数式编程在Java中更加方便和实用。为了能够更好地支持函数式编程的思想,Java 8也引入了Stream流这个概念。
Stream流的设计目标是提供一种高效且易于使用的方式来对集合数据进行处理。它的设计灵感来源于Unix Shell和函数式编程语言中的管道操作符(|)。Stream流可以看作是对集合数据进行流式操作的抽象,它将数据的处理过程抽象成一系列的操作步骤,可以链式地进行操作。
通过使用Stream流,我们可以以一种声明式的方式来描述对数据的操作,而无需关心底层的实现细节。这样的好处是我们可以编写更简洁、可读性更高的代码,并且Stream API还可以自动优化并行执行,提高运行效率。
因此,Stream流的引入使得Java语言更加接近函数式编程的理念,提供了一种更现代化、高效的数据处理方式。它的出现大大简化了对集合数据的处理,使得代码更加简洁、易读,并且提供了更好的性能。
Stream 流可以让我们以一种声明式的方式对集合数据进行操作,从而简化代码并提高代码可读性和可维护性。同时,在使用流时还可以结合Lambda表达式,进一步简化代码。
Stream流的优点:
-
代码简洁:使用Stream API可以用更少的代码实现相同的功能,使代码更加简洁、易读。
-
并行支持:Stream可以自动优化并行执行,可以利用多核CPU提高运行效率。
-
延迟执行:Stream支持延迟执行,只有在需要输出结果的时候才会进行计算,可以减少一部分不必要的计算。
Lambda表达式的优点:
-
简洁高效:Lambda表达式可以让我们写出更加简洁高效的代码。
-
可读性好:Lambda表达式可以让代码变得更加易读,减少了冗余代码。
-
面向函数编程:Lambda表达式可以让Java开发者更加容易地采用函数式编程的思想。
例如,假设我们有一个整数列表,要求将其中所有大于10的数加倍,然后将结果存储在另一个列表中。
使用传统的方法,可能需要写出以下代码:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);List<Integer> newList = new ArrayList<>();for (Integer i : list) {if (i > 10) {newList.add(i * 2);}
}
使用Stream和Lambda表达式则可以写出更为简洁的代码:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);List<Integer> newList = list.stream().filter(i -> i > 10).map(i -> i * 2).collect(Collectors.toList());
这段代码使用了Stream的filter和map方法,以及Lambda表达式,可以一行代码实现要求。
快速入门
我们先通过一个简单的快速入门案例,体验以下Stream流的强大功能。
题目: 假设我们有一个整数列表,需要筛选出其中所有大于5的数,并将它们加倍后输出。
-
使用 for 循环的方式实现:
public class StreamExample {public static void main(String[] args) {// 创建一个整数集合List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 创建一个结果集合List<Integer> result = new ArrayList<>();//循环遍历for (Integer n : numbers) {if (n > 5) {result.add(n * 2);}}// 输出结果System.out.println(result);} } -
使用 Stream 流的方式实现:
public class StreamExample {public static void main(String[] args) {// 创建一个整数集合List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 使用Stream流对列表进行筛选和转换操作List<Integer> result = numbers.stream().filter(n -> n > 5) // 筛选出大于5的数.map(n -> n * 2) // 将选中的数加倍.collect(Collectors.toList()); // 将结果转换为新的列表// 输出结果System.out.println(result);} }在代码中,我们首先创建了一个整数列表
numbers,包含了1到10的整数。接下来,我们使用
stream()方法将列表转换为一个流对象。然后,通过调用filter()方法来筛选出大于5的数,使用map()方法将选中的数加倍。最后使用collect()方法将结果转换为一个新的列表。最终,通过
System.out.println()将结果输出到控制台。
流的操作
创建流
在Java 8中提供了多种方式去完成Stream流的创建,常用方式如下:
-
通过单列集合创建:对于实现了
java.util.Collection接口的集合,比如List、Set等,可以直接调用stream()方法来创建流对象。List<String> list = Arrays.asList("apple", "banana", "orange"); Stream<String> stream = list.stream(); -
通过数组创建:可以通过调用
Arrays.stream()方法来创建一个数组的流对象。Integer[] array = {1, 2, 3, 4, 5}; Stream<Integer> stream = Arrays.stream(array); -
通过双列集合创建:
-
使用
entrySet().stream()方法:对于Map类型的双列集合,可以先通过entrySet()方法获取键值对的Set集合,然后再调用stream()方法创建流对象。Map<String, Integer> map = new HashMap<>(); // map.put() 添加元素 Set<Map.Entry<String, Integer>> entrySet = map.entrySet(); Stream<Map.Entry<String, Integer>> stream = entrySet.stream(); -
使用
values().stream()方法:对于Map类型的双列集合,也可以只获取值的集合,然后再调用stream()方法创建流对象。Map<String, Integer> map = new HashMap<>(); // map.put() 添加元素 Stream<Integer> stream = map.values().stream();
-
-
通过静态方法创建:可以通过调用
Stream.of()或Stream.iterate()来创建一个包含指定元素或无限元素的流对象。-
Stream.of()方法:Stream<Integer> stream1 = Stream.of(1, 2, 3, 4, 5); -
Stream.iterate()方法:Stream<Integer> stream2 = Stream.iterate(0, n -> n + 2).limit(5);使用
Stream.iterate()方法创建了一个包含无限元素的流对象,每个元素都是由前一个元素应用函数生成的。在这个例子中,流对象的第一个元素为0,然后每次通过应用lambda表达式(n -> n + 2)来生成下一个元素,即将前一个元素加上2。接着,使用
limit()方法来限制流对象的元素数量,使其只包含前5个元素。最终返回一个含有5个整数的Stream流对象。注:由于
Stream.iterate()方法创建的是一个无限流对象,如果不调用limit()方法或者其他的限制操作,那么该流对象将一直产生新的元素,直到程序耗尽内存空间并抛出异常。因此,在使用Stream.iterate()方法创建流对象时,一定要注意对其进行限制,以避免程序崩溃。
-
-
通过文件创建:可以通过调用
Files.lines()方法来创建一个文件的流对象。Path path = Paths.get("file.txt"); Stream<String> stream = Files.lines(path);
中间操作
Stream 流的中间操作是指那些对流进行转换、筛选、映射等操作,并返回一个新的流的操作。Stream 对象是惰性求值的,也就是说,在我们对 Stream 对象应用终端操作之前,中间操作并不会立即执行,只有等到终端操作触发时才会执行。这样可以提高性能,避免不必要的计算。
filter 过滤
通过使用 filter() 方法,我们可以根据自定义的条件对流进行过滤操作,只保留符合条件的元素,从而得到一个新的流。
Stream<T> filter(Predicate<? super T> predicate);
filter() 方法接受一个 Predicate(谓词:对主语动作状态或特征的陈述或说明)作为参数,并返回一个包含满足条件的元素的新流。
具体来说,filter() 方法会对流中的每个元素应用给定的谓词,如果谓词返回 true,则该元素被包含在新流中;如果谓词返回 false,则该元素被过滤掉:
@FunctionalInterface
public interface Predicate<T> {boolean test(T t);
}
Predicate接口被声明为@FunctionalInterface,这意味着它可以用作 Lambda 表达式或方法引用的目标。
Predicate接口代表一个断言,用于对给定的输入进行判断。它只有一个抽象方法 test,接受一个参数并返回一个boolean值,表示输入是否满足谓词条件。
同时也意味着任何实现了Predicate接口的类或 Lambda 表达式都必须实现 test 方法,并且该方法可以在任何地方被调用或覆盖。
以下是一个示例,演示如何使用 filter() 进行过滤操作:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
numbers.stream().filter(n->n%2==0).forEach(System.out::println);
在上述示例中,我们首先创建了一个包含整数元素的列表 numbers。然后,使用 stream() 方法将其转换为流对象。接下来,我们调用 filter() 方法,并传入一个谓词 n -> n % 2 == 0用于筛选出偶数。最后,使用 forEach() 终端操作遍历过滤后的流,并打印每个元素。
执行 filter 过滤操作后,流内的元素变化如下:

map 数据转换
Stream 接口定义的map方法的声明如下:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
map() 方法接受一个Function(函数)类型的参数,并将流中的每个元素按照指定的映射规则进行转换,返回一个新的Stream流。
@FunctionalInterface
public interface Function<T, R> {R apply(T t);
}
Function接口中只有一个抽象方法apply(T t),它将一个类型为T的参数作为输入,并返回一个类型为R的结果。
具体来说,map方法将对流中的每个元素应用提供的映射函数,并将其转换为另一种类型。最后将新类型的结果组合成一个新的流对象并返回。
注:
map方法只会对流中的每个元素应用映射操作,不会改变流的大小或顺序。它返回的是一个新的流,因此可以链式调用其他的流操作方法。
以下是一个示例,演示如何使用 map() 进行转换操作:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
numbers.stream().map(n->"Number:"+n).forEach(System.out::println);
在上述示例中,我们创建了一个包含整数元素的列表 numbers。然后,使用 stream() 方法将其转换为流对象。接下来,我们调用 map() 方法,并传入一个函数 n -> "Number: " + n,该函数用于将每个整数元素转换为以 "Number: " 开头的字符串。最后,使用 forEach() 终端操作遍历转换后的流,并打印每个元素。
执行 map 转换操作后,流的元素变化如下:

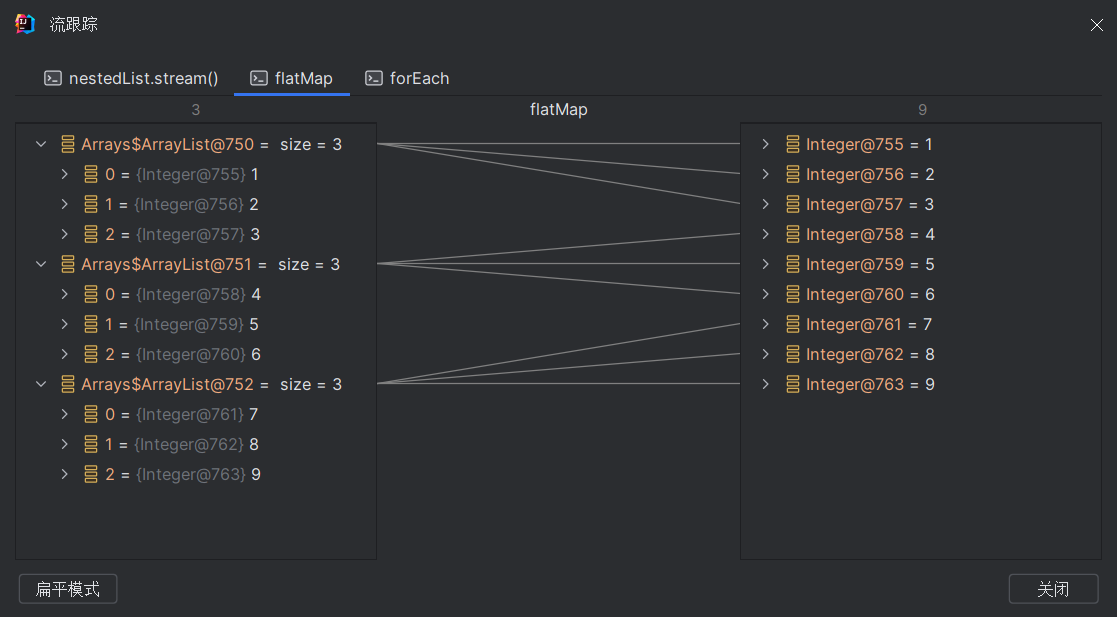
flatMap 合并流
flatMap可以将一个流中的每个元素映射为另一个流,并将这些流合并成一个单独的流。
具体来说,flatMap方法接受一个将每个元素转换为流的函数,然后将所有转换后的流合并成一个单独的流。因此,它可以用于将嵌套的流平铺开来。
方法签名如下:
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
示例用法如下:
List<List<Integer>> nestedList = Arrays.asList(Arrays.asList(1, 2, 3),Arrays.asList(4, 5, 6),Arrays.asList(7, 8, 9)
);nestedList.stream().flatMap(Collection::stream).forEach(System.out::println);
在上述示例中,我们有一个嵌套列表nestedList,其中包含三个子列表。我们首先将其转换为流,然后调用flatMap方法,传递一个方法引用Collection::stream作为映射函数。该方法引用将每个子列表转换为一个流,并将所有的流合并成一个单独的流。最终,我们得到了一个包含所有元素的扁平化流flattenedStream。
执行flatMap转换操作后,流的元素变化如下:
同时flatMap方法支持数据转换:
List<List<Integer>> nestedList = Arrays.asList(Arrays.asList(1, 2, 3),Arrays.asList(4, 5, 6),Arrays.asList(7, 8, 9)
);nestedList.stream().flatMap(ns-> ns.stream().map(n->"Number:"+n)).forEach(System.out::println);
distinct 去重
distinct() 返回一个包含流中不重复元素的新流。新流中的元素顺序与原始流中的元素顺序相同。
具体来说,distinct() 方法会基于元素的 equals() 方法判断元素是否重复。如果流中有多个元素与当前元素相等,则只保留其中的一个元素。其他重复元素将被过滤掉。在去重过程中,保留的是第一次出现的元素,后续重复出现的元素将被忽略。
方法签名如下:
Stream<T> distinct();
以下是一个示例,演示如何使用 distinct() 方法进行去重操作:
List<Integer> numbers = Arrays.asList(1, 2, 2, 3, 3, 4, 5);numbers.stream().distinct().forEach(System.out::println);
在上述示例中,我们创建了一个包含整数元素的列表 numbers,其中存在重复的元素。然后,使用 stream() 方法将其转换为流对象。接下来,我们调用 distinct() 方法,该方法会返回一个新的流,其中只包含不重复的元素。最后,使用 forEach() 终端操作遍历去重后的流,并打印每个元素。
使用 distinct() 方法后,流的元素变化如下:

注:
distinct()方法会基于元素的equals()方法判断元素是否重复,因此必须保证元素的equals()方法正确实现,才能准确判断元素是否重复。
sorted 排序
通过调用 sorted() 方法,我们可以对流中的元素进行排序操作。并返回一个包含按自然顺序或指定比较器排序的元素的新流。
sorted() 方法有两种重载形式:
//默认排序规则
Stream<T> sorted();
//指定排序规则
Stream<T> sorted(Comparator<? super T> comparator);
- 若调用时不传入任何参数,则会根据元素的自然顺序(即调用元素的
compareTo()方法进行比较)完成排序。如果流中的元素不支持自然排序(即元素类型未实现Comparable接口或者实现了该接口但未正确实现compareTo()方法),则会抛出ClassCastException异常。 - 若调用时传入一个比较器(Comparator)作为参数,则会使用指定的比较器对元素进行排序。
以下是两个示例,分别演示了使用自然顺序和比较器进行排序的情况:
-
使用自然顺序进行排序:
List<Integer> numbers = Arrays.asList(5, 3, 2, 4, 1);numbers.stream().sorted().forEach(System.out::println);在上述示例中,我们创建了一个包含整数元素的列表
numbers。然后,使用stream()方法将其转换为流对象。接下来,我们调用sorted()方法,该方法会返回一个新的流,其中的元素按照自然顺序进行排序。最后,使用
forEach()终端操作遍历排序后的流,并打印每个元素。经过
sorted()方法后,流的元素变化如下:
-
使用比较器进行排序:
List<Integer> numbers = Arrays.asList(5, 3, 2, 4, 1);numbers.stream().sorted(Comparator.reverseOrder()).forEach(System.out::println);在上述示例中,我们创建了一个包含整数元素的列表
numbers。然后,使用stream()方法将其转换为流对象。接下来,我们创建了一个比较器reverseOrder,该比较器会按逆序对元素进行排序。最后,我们调用
sorted()方法,并传入比较器作为参数,返回一个新的流,其中的元素按照指定的比较器进行排序。经过
sorted()方法后,流的元素变化如下:
注:使用
sorted()方法对流中的元素进行排序时,元素类型必须实现Comparable接口,或者提供比较器来指定排序规则。
limit 限流
limit() 方法用于截取流中的前 n 个元素,并返回一个新的流。该方法的语法如下:
Stream<T> limit(long maxSize)
其中,maxSize 参数指定了要截取的元素个数。
注:如果输入的流中元素的数量不足
maxSize,则返回的新流中只包含所有元素。此外,如果maxSize小于等于 0,或者输入的流为空,则返回的新流也将为空。
以下是一个示例,演示了如何使用 limit() 方法对流进行截取:
List<Integer> numbers = Arrays.asList(5, 3, 2, 4, 1);numbers.stream().limit(3).forEach(System.out::println);
在上述示例中,我们创建了一个包含整数元素的列表 numbers。然后,使用 stream() 方法将其转换为流对象。接下来,我们调用 limit(3) 方法,截取流中的前三个元素。
最后,使用 forEach() 终端操作遍历截取后的流,并打印每个元素。
使用 limit() 方法后,流的元素变化如下:

skip 跳过
skip() 方法用于跳过流中的前 n 个元素,并返回一个新的流。该方法的语法如下:
Stream<T> skip(long n)
其中,n 参数指定了要跳过的元素个数。
注:如果输入的流中元素的数量不足
n,则返回的新流将为空。此外,如果n小于等于 0,或者输入的流为空,则返回的新流将包含原始流中的所有元素。
以下是一个示例,演示了如何使用 skip() 方法跳过流中的元素:
List<Integer> numbers = Arrays.asList(5, 3, 2, 4, 1);numbers.stream().skip(3).forEach(System.out::println);
根据你提供的代码,创建了一个包含整数元素的列表 numbers。然后,使用 stream() 方法将其转换为流对象。接下来,我们调用 skip(3) 方法,跳过流中的前三个元素。
最后,使用 forEach() 终端操作遍历跳过后的流,并打印每个元素。
使用 skip() 方法后,流的元素变化如下:

peek 操作
peek() 方法提供了一种在流元素处理过程中插入非终端操作的机制,即在每个元素的处理过程中执行某些操作,例如调试、日志记录、统计等。
该方法的语法如下:
Stream<T> peek(Consumer<? super T> action)
其中,action 参数是一个 Consumer 函数式接口,用于定义要在流元素处理过程中执行的操作。对于每个元素,peek() 方法都会调用 action 函数,并传递该元素作为参数。
以下是一个示例,演示了如何使用 peek() 方法:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);numbers.stream().filter(n -> n % 2 == 0).peek(n -> System.out.println("Found even number: " + n)).map(n -> n * 2).forEach(System.out::println);
在上述示例中,我们创建了一个包含整数元素的列表 numbers。然后,我们使用 stream() 方法将其转换为流对象。接下来,我们使用 filter() 方法过滤出所有偶数,并使用 peek() 方法插入一条打印语句,以便在每个偶数被消耗时显示一条消息。
然后,我们使用 map() 方法对每个偶数进行乘法运算,并最终使用 forEach() 终端操作打印每个结果。
控制台打印结果:
Found even number: 2
4
Found even number: 4
8
使用 peek() 方法时,流的元素变化如下:

终结操作
终结操作(Terminal Operation)是 Stream 流的最后一个操作,用于触发流的处理并产生最终的结果或副作用。执行终结操作后,流将会被关闭,因此在调用终结操作之后,流将不再可用。
forEach 遍历
forEach() 是 Stream 流的一个终端操作方法,用于对流中的每个元素执行指定的操作。它接受一个 Consumer 函数式接口作为参数,并将该操作应用于流中的每个元素。
forEach() 方法没有返回值,因此它只用于执行一些针对每个元素的操作,并不能产生新的流或结果。
以下是 forEach() 方法的语法:
void forEach(Consumer<? super T> action)
其中,action表示要对每个元素执行的操作,它是一个接受一个参数并且没有返回值的函数式接口。在Lambda表达式中,可以使用该参数执行自定义的操作。
以下是一个示例,演示了如何使用 forEach() 方法对流中的每个元素执行操作:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);numbers.stream().forEach(System.out::println);
首先,我们创建了一个包含整数元素的列表 numbers。接下来,我们通过调用 stream() 方法将该列表转换为一个流对象。然后,我们使用 forEach() 方法对每个元素执行一条打印语句。
在打印语句中,我们使用了方法引用(Method Reference)的方式,即 System.out::println,它代表了一个输出流操作,将流中的每个元素输出到控制台上。也可以使用 lambda 表达式的方式,即 (x) -> System.out.println(x)。
运行上述代码,控制台输出结果如下:
1
2
3
4
5
forEachOrdered 有序遍历
forEachOrdered() 方法与 forEach() 方法相似,用于对流中的每个元素执行指定的操作。但与 forEach() 不同的是,forEachOrdered() 方法能够保证操作按照流中元素的顺序依次执行。
以下是 forEachOrdered() 方法的语法:
void forEachOrdered(Consumer<? super T> action)
其中,action 参数是一个 Consumer 函数式接口,用于定义要在每个元素上执行的操作。对于流中的每个元素,forEachOrdered() 方法都会调用 action 函数,并将该元素作为参数传递给它。这些操作将按照流中元素的顺序依次执行,而不是在并行流中产生竞争条件。
以下是一个示例,演示了如何使用 forEachOrdered() 方法对流中的每个元素执行操作:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);numbers.parallelStream().forEachOrdered(System.out::println);
在上述示例中,我们创建了一个包含整数元素的列表 numbers。然后,我们使用 parallelStream() 方法将该列表转换为一个并行流对象。并行流允许并行处理流中的元素,以提高处理速度。
接下来,我们使用 forEachOrdered() 方法将并行流中的每个元素输出到控制台。
控制台输出结果如下:
1
2
3
4
5
由于我们在这里使用了并行流,而并行流的处理顺序可能会受到多线程的调度和执行时间的影响,因此如果使用 forEach() 方法,则打印顺序可能是随机的。但是,由于我们使用了 forEachOrdered() 方法,所以不会受到并行处理的影响,最终的输出顺序将与原始列表中的顺序一致。
parallelStream() 并行流中的元素变化如下:

count 统计数量
count 用于统计 Stream 流中元素的个数。该方法返回一个 long 类型的值,表示流中元素的数量。
count的语法如下:
long count()
它返回一个long类型的值,表示流中元素的个数。
以下是一个示例,演示了如何使用 count() 方法计算一个整数流中的元素数量:
List<String> fruits = Arrays.asList("apple", "banana", "orange");// 统计水果的个数
long count = fruits.stream().count();System.out.println("水果的个数为:" + count);
首先我们创建了一个 Integer 类型的列表 numbers。然后,通过调用 stream() 方法将列表转换为顺序流。接着,使用 count() 方法来计算顺序流中的元素数量,并将结果赋值给变量 count。
最后,使用 System.out.println() 方法将计算出的元素数量输出到控制台。
控制台输出结果如下:
5
注:
count()方法只能用于非并行流或无限流。如果在并行流或无限流中调用该方法,则可能会导致程序挂起或陷入死循环等不良情况。
min 最小值
min() 用于获取流中的最小值。它可以用于处理基本类型和对象类型的流。以下是 min() 方法的语法:
Optional<T> min(Comparator<? super T> comparator)
它接收一个 Comparator 对象作为参数,用于确定最小值的比较方式。返回一个 Optional 对象,表示流中的最小值(如果存在)。
下面是一个示例代码,演示了如何使用 min() 方法找到整数流中的最小值:
List<Integer> numbers = Arrays.asList(5, 2, 8, 1, 9);// 找到最小值
Optional<Integer> min = numbers.stream().min(Integer::compareTo);System.out.println("最小值为:" + min.get());
上述代码中,我们将一个包含五个整数的 List 转换成了 Stream 流,并使用 min 方法找到流中的最小值。通过传入 Integer 类的 compareTo 方法作为比较器,可以实现对整数的比较。最后,我们将结果输出到控制台。
经过 min() 方法后流中的元素变化如下:

max 最大值
在 Java 中,max() 是一个流的终端操作,用于获取流中的最大值。它可以用于处理基本类型和对象类型的流。
以下是 max() 方法的语法:
Optional<T> max(Comparator<? super T> comparator)
它接收一个 Comparator 对象作为参数,用于确定最大值的比较方式。返回一个 Optional 对象,表示流中的最大值(如果存在)。
下面是一个示例代码,演示了如何使用 max() 方法找到整数流中的最大值:
List<Integer> numbers = Arrays.asList(5, 2, 8, 1, 9);// 找到最大值
Optional<Integer> max = numbers.stream().max(Integer::compareTo);System.out.println("最大值为:" + max.get());
上述代码中,我们将一个包含五个整数的 List 转换成了 Stream 流,并使用 max 方法找到流中的最大值。通过传入 Integer 类的 compareTo 方法作为比较器,可以实现对整数的比较。最后,我们将结果输出到控制台。
经过 min() 方法后流中的元素变化如下:

reduce 聚合
reduce() 用于将流中的元素进行聚合操作,生成一个最终的结果。它可以用于处理基本类型和对象类型的流。
以下是 reduce() 方法的三种语法:
-
单个参数:
Optional<T> reduce(BinaryOperator<T> accumulator)参数含义如下:
accumulator是一个函数接口BinaryOperator<T>的实例,定义了一个二元操作符,用于将流中的元素逐个进行操作。
使用这种形式的
reduce()方法时,它会将流中的元素依次与累加器进行操作,最终将所有元素聚合成一个结果。返回值类型是
Optional<T>,因为如果流为空,没有元素可以进行聚合操作,此时返回的是一个空的Optional对象。下面是一个示例代码,演示了如何使用带有一个参数的
reduce()方法对整数流进行求和操作:List<Integer> numbers = Arrays.asList(5, 2, 8, 1, 9);Optional<Integer> reduce = numbers.stream().reduce((a, b) -> a + b);System.out.println("Sum:" + reduce.get());在上述示例中,我们首先创建了一个整数流
numbers。然后,我们调用reduce()方法来对流中的元素进行求和操作。二元操作符使用 lambda 表达式(a, b) -> a + b进行相加操作。最后,打印求和结果:
Sum:25注:
reduce()方法默认将流中的第一个元素作为初始化值,依次与后面的元素进行累加器操作。 -
两个参数:
T reduce(T identity, BinaryOperator<T> accumulator)参数含义如下:
identity是初始值,用于处理空流的情况。accumulator是一个函数接口BinaryOperator<T>的实例,定义了一个二元操作符,用于将流中的元素逐个与累加器进行操作。
使用这种形式的
reduce()方法时,如果流中有元素,则将第一个参数作为初始值,然后依次将流中的元素与初始值进行操作。如果流为空,则直接返回初始值。下面是一个示例代码,演示了如何使用带有两个参数的
reduce()方法对整数流进行求和操作:List<Integer> numbers = Arrays.asList(5, 2, 8, 1, 9);Integer reduce = numbers.stream().reduce(1, Integer::sum);System.out.println("Sum:" + reduce);在上述示例中,我们首先创建了一个整数流
numbers。然后,我们调用reduce()方法来对流中的元素进行求和操作。初始值设置为 1,元素进行相加操作。最后,我们将求和结果输出到控制台:
Sum:26 -
三个参数:
<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner)每个参数含义如下:
identity是初始值,用于处理空流的情况。accumulator是一个函数接口BiFunction<U, ? super T, U>的实例,定义了一个二元操作符,用于将流中的元素逐个与累加器进行操作。combiner是一个函数接口BinaryOperator<U>的实例,用于在并行流的情况下,将多个部分结果进行合并。
在处理并行流时,
reduce()方法会将流分成多个部分,并发地执行累加操作。然后,使用combiner函数将各个部分的结果进行合并,最终生成一个最终的结果。下面是一个示例代码,演示了如何使用带有三个参数的
reduce()方法对整数流进行求和操作:List<Integer> numbers = Arrays.asList(5, 2, 8, 1, 9);Integer reduce = numbers.parallelStream().reduce(0, (a, b) -> a + b, Integer::sum);System.out.println("Sum:" + reduce);在上述示例中,我们首先创建了一个整数流
numbers。然后,我们调用reduce()方法来对流中的元素进行求和操作。初始值设置为 0,二元操作符使用 lambda 表达式(a, b) -> a + b进行相加操作。combiner函数使用了方法引用Integer::sum,用于在并行流的情况下合并部分结果。最后,我们将求和结果输出到控制台:
Sum:25reduce()方法后流中的元素变化如下:
collect 收集
collect() 方法是用于将流中的元素收集到集合或者其他数据结构中的操作。它可以将流中的元素进行转换、分组、过滤等操作,并将结果存储到指定的集合中。
collect() 方法使用 Collector 对象来定义收集操作的行为。Collector 接口提供了一系列静态方法,可以创建常见的收集器实例,如 toList()、toSet()、toMap() 等。
以下是 collect() 方法的语法:
<R, A> R collect(Collector<? super T, A, R> collector)
这里的参数含义如下:
collector是一个Collector对象,用于定义收集操作的行为。
返回值类型是根据收集器的定义而确定的。
下面是一些示例代码,展示了如何使用 collect() 方法进行常见的收集操作:
-
将流中的元素收集到一个列表中:
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5);List<Integer> numberList = numbers.collect(Collectors.toList());System.out.println("Number List: " + numberList); -
将流中的元素收集到一个集合中:
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5);Set<Integer> numberSet = numbers.collect(Collectors.toSet());System.out.println("Number Set: " + numberSet); -
将流中的元素收集到一个映射表中:
Stream<String> names = Stream.of("Alice", "Bob", "Charlie");Map<String, Integer> nameLengthMap = names.collect(Collectors.toMap(name -> name,name -> name.length() ));System.out.println("Name Length Map: " + nameLengthMap);
anyMatch 任意匹配
anyMatch() 方法是用于检查流中是否存在满足指定条件的元素。它返回一个boolean值,表示流中是否存在匹配的元素。
以下是anyMatch()方法的语法:
boolean anyMatch(Predicate<? super T> predicate)
参数含义如下:
predicate是一个Predicate函数接口的实例,用于定义匹配条件。
返回值是一个boolean值,如果流中至少有一个元素满足predicate定义的条件,则返回true,否则返回false。
下面是一个示例代码,演示了如何使用anyMatch()方法来检查整数流中是否存在大于10的元素:
Stream<Integer> numbers = Stream.of(5, 8, 12, 3, 9);boolean hasNumberGreaterThanTen = numbers.anyMatch(number -> number > 10);System.out.println("Has Number Greater Than Ten: " + hasNumberGreaterThanTen);
在上述示例中,我们创建了一个整数流numbers。然后调用anyMatch()方法检查是否存在大于10的元素。
allMatch 全匹配
allMatch() 方法用于检查流中的所有元素是否都满足指定的条件。它返回一个布尔值,表示流中的所有元素是否都满足条件。
以下是 allMatch() 方法的语法:
boolean allMatch(Predicate<? super T> predicate)
参数含义如下:
predicate是一个Predicate函数接口的实例,用于定义匹配条件。
返回值是一个布尔值,如果流中的所有元素都满足 predicate 定义的条件,则返回 true,否则返回 false。
下面是一个示例代码,演示了如何使用 allMatch() 方法来检查整数流中的所有元素是否都为偶数:
Stream<Integer> numbers = Stream.of(2, 4, 6, 8, 10);boolean allEven = numbers.allMatch(number -> number % 2 == 0);System.out.println("All Even: " + allEven);
在上述示例中,创建了一个整数流 numbers,然后调用 allMatch() 方法检查流中的所有元素是否都为偶数。
noneMatch 全不匹配
noneMatch()方法用于检查流中是否没有任何元素满足指定的条件。它返回一个boolean值,表示流中是否不存在满足条件的元素。
以下是noneMatch()方法的语法:
boolean noneMatch(Predicate<? super T> predicate)
这里的参数含义如下:
predicate是一个Predicate函数接口的实例,用于定义匹配条件。
返回值是一个boolean值,如果流中没有任何元素满足predicate定义的条件,则返回true,否则返回false。
下面是一个示例代码,演示了如何使用noneMatch()方法来检查整数流中是否没有负数元素:
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5);boolean noNegativeNumbers = numbers.noneMatch(number -> number < 0);System.out.println("No Negative Numbers: " + noNegativeNumbers);
在上述示例中,创建了一个整数流numbers,调用noneMatch()方法检查流中是否没有负数元素。
findFirst 查找第一个
findFirst() 方法用于返回流中的第一个元素(按照流的遍历顺序)。它返回一个 Optional 对象,可以用于处理可能不存在的情况。
以下是 findFirst() 方法的语法:
Optional<T> findFirst()
返回值类型是 Optional<T>,其中 T 是流中元素的类型。如果流为空,则返回一个空的 Optional 对象;否则,返回一个包含第一个元素的 Optional 对象。
下面是一个示例代码,演示了如何使用 findFirst() 方法来获取整数流中的第一个元素:
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5);Optional<Integer> firstNumber = numbers.findFirst();if (firstNumber.isPresent()) {System.out.println("First Number: " + firstNumber.get());
} else {System.out.println("Stream is empty");
}
在上述示例中,创建了一个整数流 numbers,调用 findFirst() 方法,返回一个 Optional 对象,表示流中的第一个元素。
findAny
findAny() 方法用于返回流中的任意一个元素。它返回一个 Optional 对象,可以用于处理可能不存在的情况。
以下是 findAny() 方法的语法:
Optional<T> findAny()
返回值类型是 Optional<T>,其中 T 是流中元素的类型。如果流为空,则返回一个空的 Optional 对象;否则,返回一个包含任意一个元素的 Optional 对象。
findAny() 方法与 findFirst() 方法类似,但不保证返回的是流中的第一个元素,而是返回任意一个元素。这在并行流中尤为有用,因为它可以并行处理流的不同部分,然后返回其中的任意一个元素。
下面是一个示例代码,演示了如何使用 findAny() 方法来获取整数流中的任意一个元素:
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5);Optional<Integer> anyNumber = numbers.findAny();if (anyNumber.isPresent()) {System.out.println("Any Number: " + anyNumber.get());
} else {System.out.println("Stream is empty");
}
上述示例中,创建了一个整数流 numbers,调用 findAny() 方法,返回一个 Optional 对象,表示流中的任意一个元素。
相关文章:
Java8 Stream API全面解析——高效流式编程的秘诀
文章目录 什么是 Stream Api?快速入门流的操作创建流中间操作filter 过滤map 数据转换flatMap 合并流distinct 去重sorted 排序limit 限流skip 跳过peek 操作 终结操作forEach 遍历forEachOrdered 有序遍历count 统计数量min 最小值max 最大值reduce 聚合collect 收集anyMatch…...
分享一下微信小程序里怎么开店
如何在微信小程序中成功开店:从选品到运营的全方位指南 一、引言 随着微信小程序的日益普及,越来越多的人开始尝试在微信小程序中开设自己的店铺。微信小程序具有便捷、易用、即用即走等特点,使得开店门槛大大降低。本文将详细介绍如何在微…...

uniapp小程序刮刮乐抽奖
使用canvas画布画出刮刮乐要被刮的图片,使用移动清除画布。 当前代码封装为刮刮乐的组件; vue代码: <template><view class"page" v-if"merchantInfo.cdn_static"><image class"bg" :src&q…...

Qt 窗口无法移出屏幕
1 使用场景 设计一个缩进/展开widget的效果,抽屉效果。 看到实现的方法有定时器里move窗口,或是使用QPropertyAnimation。 setWindowFlags(Qt::Dialog | Qt::FramelessWindowHint |Qt::X11BypassWindowManagerHint); 记得在移…...
java毕业设计基于springboot+vue线上教学辅助系统
项目介绍 本论文主要论述了如何使用JAVA语言开发一个线上教学辅助系统 ,本系统将严格按照软件开发流程进行各个阶段的工作,采用B/S架构,面向对象编程思想进行项目开发。在引言中,作者将论述线上教学辅助系统的当前背景以及系统开…...
开源 Wiki 软件 wiki.js
wiki.js简介 最强大、 可扩展的开源Wiki 软件。使用 Wiki.js 美观直观的界面让编写文档成为一种乐趣!根据 AGPL-v3 许可证发布。 官方网站:https://js.wiki/ 项目地址:https://github.com/requarks/wiki 主要特性: 随处安装&a…...
STM32基本定时器中断
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、STM32定时器的结构?1. 51定时器的结构1.1如何实现定时1s的功能? 2. stm32定时器的结构2.1 通用定时器 二、使用步骤1.开启时钟2.初始…...

学习历程_基础_精通部分_达到手搓的程度
1. 计算机网络(更新版) 1.1 计算机网络-43题 1.2 2. 操作系统(更新版) 3. ACM算法(更新版) 4. 数据库(更新版) 5. 业务开发算法(更新版) 6. 分布式类(更新版) 7. 设计模式(更新版ÿ…...

Redis中的List类型
目录 List类型的命令 lpush lpushx rpush lrange lpop rpop lindex linsert llen lrem ltrim lset 阻塞命令 阻塞命令的使用场景 1.针对一个非空的列表进行操作 2.针对一个空的列表进行操作 3.针对多个key进行操作. 内部编码 lisi类型的应用场景 存储(班级…...
3D模型格式转换工具HOOPS Exchange:如何将3D PDF转换为STEP格式?
3D CAD数据在制造、工程和设计等各个领域都扮演着重要的角色。为了促进不同软件应用程序之间的协作和互操作性,它通常以不同的格式进行交换。 HOOPS Exchange是一个强大的软件开发工具包,提供了处理和将3D CAD数据从一种格式转换为另一种格式的解决方案…...
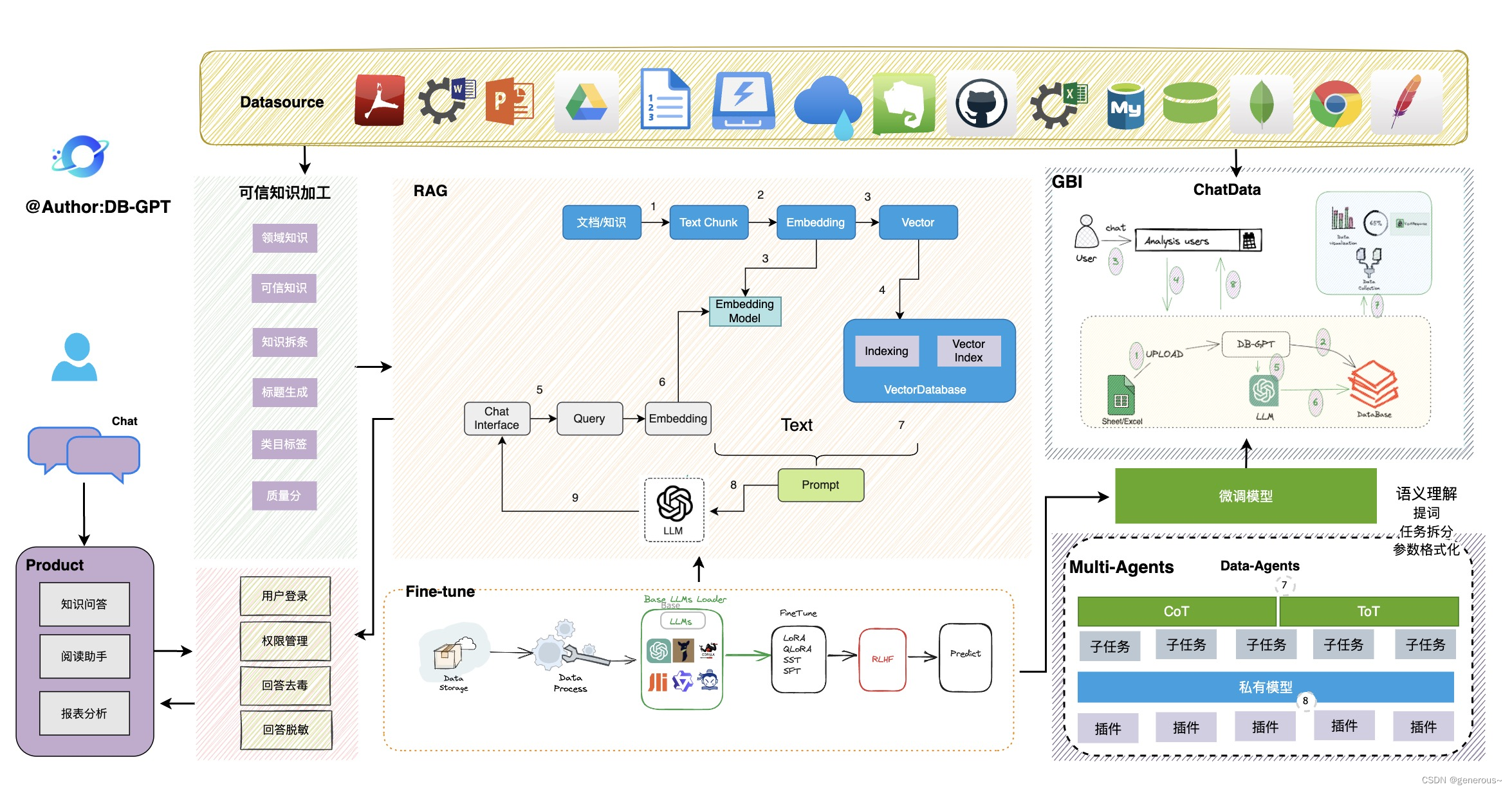
DB-GPT介绍
DB-GPT介绍 引言DB-GPT项目简介DB-GPT架构关键特性私域问答&数据处理多数据源&可视化自动化微调Multi-Agents&Plugins多模型支持与管理隐私安全支持数据源 子模块DB-GPT-Hub微调参考文献 引言 随着数据量的不断增长和数据分析的需求日益增多,将自然语言…...

Java,面向对象,内部类
内部类的定义: 将一个类A定义在另一个类B里面,里面的那个类A就称为内部类(InnerClass),类B则称为外部类(OuterClass)。 内部类的使用场景: 类A只在类B中使用,便可以使用内部类的方法…...

唯一ID如何生成,介绍一下目前技术领域最常使用的几种方法
纵使十面大山,又如何,无妨… 概述 唯一ID(Unique Identifier)是在计算机科学和信息技术领域中用于标识某个实体或数据的唯一标识符。生成唯一ID的方法可以根据具体需求和应用场景的不同而有所不同。以下是一些目前技术领域中常用…...
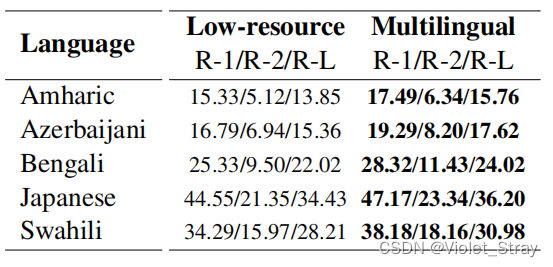
【翻译】XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages
摘要 当代的关于抽象文本摘要的研究主要集中在高资源语言,比如英语,这主要是因为低/中资源语言的数据集有限。在这项工作中,我们提出了XL-Sum,这是一个包含100万篇专业注释的文章摘要对的综合多样数据集,从BBC中提取&…...
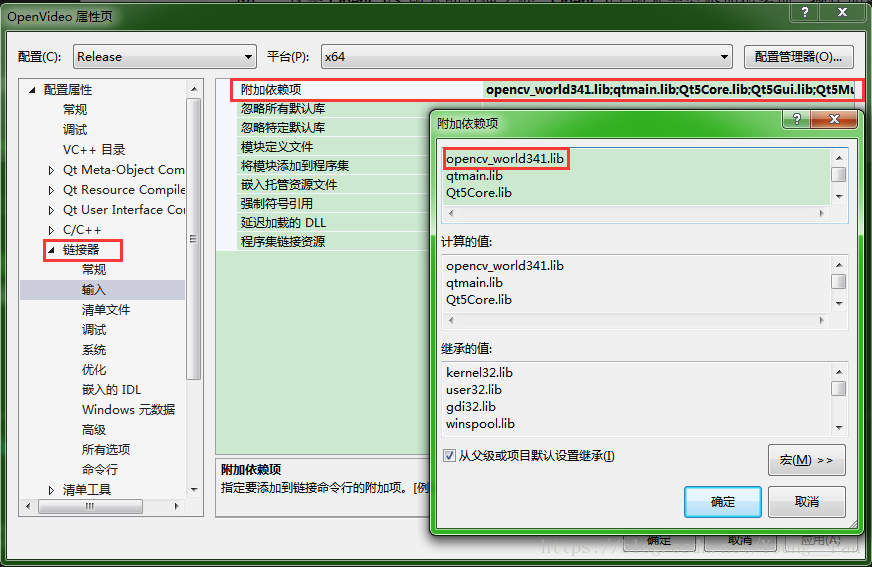
配置OpenCV
Open CV中包含很多图像处理的算法,因此学会正确使用Open CV也是人脸识别研究的一项重要工作。在 VS2017中应用Open CV,需要进行手动配置,下面给出在VS2017中配置Open CV的详细步骤。 1.下载并安装OpenCV3.4.1与VS2017的软件。 2.配置Open CV环…...

1-时间复杂度和空间复杂度
为了找到最适合当前问题而估量“算法”的评价s 时间复杂度空间复杂度执行效率:根据算法编写出的程序,执行时间越短,效率就越高占用的内存空间:不同算法编写出的程序,执行时占用的内存空间也不相同。如果实际场景中仅能…...

EtherCAT主站SOEM -- 3 -- SOEM之ethercatconfig.h/c文件解析
EtherCAT主站SOEM -- 3 -- SOEM之ethercatconfig.h/c文件解析 一 ethercatconfig.h/c文件功能预览:二 ethercatconfig.h/c 中主要函数的作用:2.1.1 ec_config_init(uint8 usetable) 和 ecx_config_init(ecx_contextt *context, uint8 usetable)ÿ…...

洗地机哪个品牌好?家用洗地机选购攻略
随着家用洗地机的普及和市场的广泛认可,进入洗地机行业的制造商也越来越多。在面对众多洗地机品牌时,消费者常常感到困惑,不知道如何选择。面对众多选择,选择有良好保障的知名洗地机品牌是明智之举。知名品牌在质量、售后服务等方…...
Java数组的定义与常用使用方法
目录 一.什么是数组 二.数组的创建及初始化 数组的创建 数组的初始化 动态初始化: 静态初始化: 【注意】 三.数组的使用 数组中元素访问 遍历数组 四.数组作为方法的参数 参数传基本数据类型 参数传数组类型(引用数据类型) 作为方法的返回…...
[计算机网络]认识“协议”
认识“协议” 文章目录 认识“协议”序列化和反序列化网络计算器引入Sock类设计协议编写服务端类启动服务端编写客户端类启动客户端程序测试 序列化和反序列化 在网络体系结构中,应用层的应用程序会产生数据,这个数据往往不是简单的一段字符串数据&…...

Angular Signal Forms:以状态为先,革新表单验证、UI 更新与状态管理
Angular Signal Forms:为表单管理引入以状态为先的模型表单通常是前端应用中状态最复杂的部分,负责捕获用户输入、运行验证逻辑、跟踪交互状态,并协调更改在 UI 中传播。随着表单规模增大,保持内容同步所需代码量会迅速增加。Angu…...

《最终的数据解读指南》
原文:towardsdatascience.com/the-ultimate-guide-to-making-sense-of-data-aaa121db1119?sourcecollection_archive---------0-----------------------#2024-06-04 来自 Uber、Meta 和高速成长初创公司的 10 年经验教训 https://medium.com/twalbaum?sourcepost…...
基于 PyTorch 的 TransU-Net 模型进行不同城市建筑物的精准提取 来继续遥感图像语义分割
基于 PyTorch 的 TransU-Net 模型进行不同城市建筑物的精准提取 来继续遥感图像语义分割 遥感图像语义分割,遥感建筑物数据集,基于Pytorch框架,针对不同城市建筑物精准提取。 遥感图像中包含丰富的地理空间信息,从遥感图像中了…...

不止于指路,智慧导览如何重构公共空间价值
在过去很长一段时间里,公共空间的价值被简单地等同于功能性。一个公园只要有绿化和座椅,一个商场只要有商铺和电梯,一个政务大厅只要有窗口和座位,就被认为是合格的公共空间。然而,随着人们生活水平的提高和消费观念的…...
终极免费实时屏幕翻译工具:Translumo完全使用指南
终极免费实时屏幕翻译工具:Translumo完全使用指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾经因…...

2026企业网盘怎么选?十大产品深度测评:从合规到协作一次讲清
企业网盘已经不只是“存文件”这么简单了。2026年,远程办公常态化、数据合规持续收紧、企业开始把“文件”当作数字资产来治理——网盘也从“云端U盘”进化为企业数字资产管理的底座。 过去选网盘,很多企业只看容量和价格;现在真正拉开差距的…...

网易云音乐无损FLAC下载工具:轻松获取专业级音乐资源
网易云音乐无损FLAC下载工具:轻松获取专业级音乐资源 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 还在为在线音乐平台的音质限制而烦恼…...

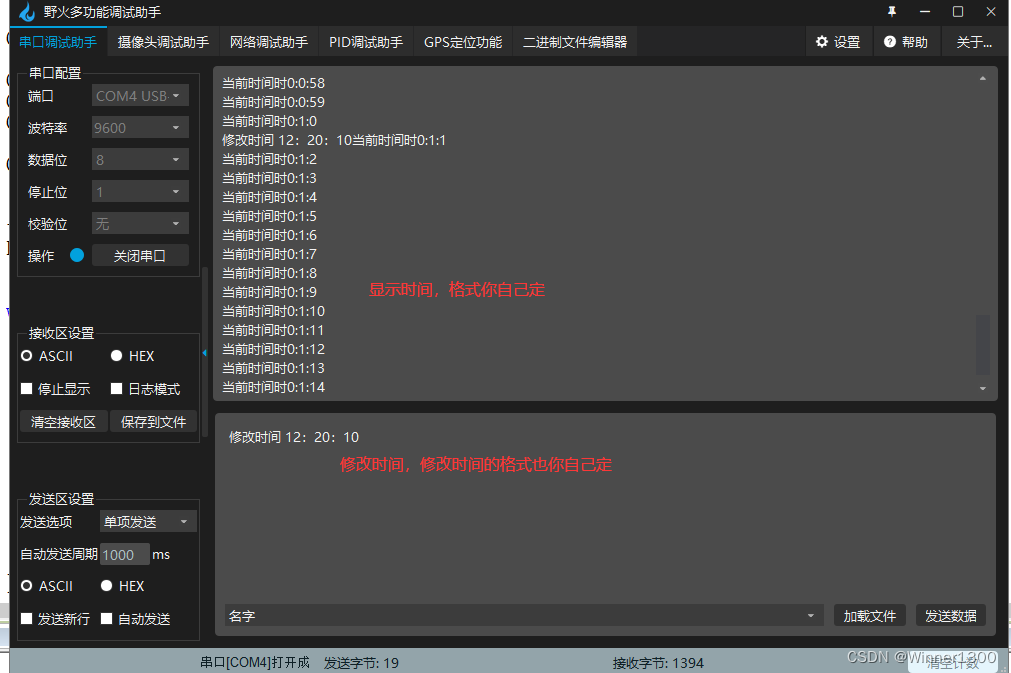
PyQt5串口上位机开发指南:从环境搭建到数据可视化实战
1. 项目概述与核心价值最近在做一个嵌入式项目,调试阶段需要频繁地和下位机进行数据交互。每次改个参数、读个状态,都得打开串口调试助手,手动输入十六进制命令,再盯着返回的数据一个个换算,效率低不说,还容…...

3分钟搞定百度网盘提取码:新手也能快速上手的终极解决方案
3分钟搞定百度网盘提取码:新手也能快速上手的终极解决方案 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否经常遇到这样的烦恼:朋友分享的百度网盘链接明明就在眼前,却因为缺少那个关…...

告别数据锁定:用youdaonote-pull实现有道云笔记的本地化自由
告别数据锁定:用youdaonote-pull实现有道云笔记的本地化自由 【免费下载链接】youdaonote-pull 📝 一个一键导出 / 备份「有道云笔记」所有笔记的 Python 脚本。 A Python script to export/backup all the notes of the "Youdao Note". 项目…...