机器学习之决策树
决策树:
是一种有监督学习方法,从一系列有特征和标签的数据中总结出决策规则,并采用树状图的结构来呈现规则,用来解决分类和回归问题。
节点:根节点:没有进边,有出边。包含最初的,针对特征的提问中间节点:既有进边也有出边,进边只有一条,出边可以有很多条。都是针对特征的提问。叶子节点:有进边,没有出边,每个叶子节点都是一个类别标签子节点与父节点:在两个相连的节点中,更接近根节点的是父节点,应一个是子节点。
决策树解决的问题:
1、如何从数据中找出最佳节点或者最佳分支?
2、如何让决策树停止生长,防止过拟合?决策树是基于训练集数据构建出来的,如果树长的越大分支越细致,则对训练数据的描述越清楚,但是不一定会很好的用于测试数据中
构建决策树:
根据数据构建很多决策树,再通过贪心算法实现局部最优来达到全局最优结果的算法。
不纯度:某一类标签占有的比例比较大,则说明改标签纯,否则就是不纯,样本呢越纯分配错误的几率越低
用信息熵计算不纯度。
如何用信息熵计算不纯度?先了解下什么叫做信息熵当我们需要判断64组小组比赛的冠军时,我们可以单个单个的猜,最多需要64次才能猜中,但是我们把数据分开,分为1-32和33-64,决断出哪一份会赢,然后再进行拆分,重复六次,最终确定赢得小组,这种代价被称为6比特,信息量得值会随着更多有用信息得出现而降低计算公式:即H(A)=\sum_ip(i)log\frac{1}{p(i)}。信息熵越大,猜对的概率越小,不确定越大,猜对的代价越大信息熵越小,猜对的概率越大,不确定越小,猜对的代价越小
如何衡量决策树里节点(特征)重要性?如何理解特征的重要性?重要性:如果一个节点减少分类的不确定性越明显,则该节点就越重要。使用信息增益衡量特征的重要性
信息增益:在根据某个他则会那个划分数据集之前滞后信息熵发生的变化或者差异叫做信息增益,知道如何计算信息增哟,获得计算增益最高的特征就是最好的选择信息增益作为决策树的划分依据
决策树需要用到的api是:from sklearn.tree import DecisionTreeClassifier 用来分类from sklearn.tree import DecisionTreeRegressor 用来回归
需要用到的对象以及参数:tree = DecisionTreeClassifier(criterion='entropy',random_state=2023)建立对象需要对里面的参数进行设置criterion,设置为'entropy'表示信息熵,默认是基尼系数,random_state自行设置,如果设置完,后面的准确率就不会发生变化,在特征维度比较多时,建议使用
使用决策树
import sklearn.datasets as dataset
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import DecisionTreeRegressor
data = dataset.load_wine()
print(data.keys())
tree = DecisionTreeClassifier(criterion='entropy')
feature = data['data']
target = data['target']
print(feature.shape, target.shape)
x_train, x_test, y_train, y_test = train_test_split(feature, target,train_size=0.8, random_state=2023)
tree.fit(x_train,y_train)
score = tree.score(x_test,y_test)
print(score)
结果:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names'])
(178, 13) (178,)
0.7777777777777778
再次运行:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names'])
(178, 13) (178,)
0.8888888888888888Process finished with exit code 0
我们会发现两次的运行结果不一样。
每次测评分数不一致的原因:
决策树在构建树时,是靠及优化节点来追求一颗最优化的树,每次分支时,用的时一部分特征,选出不纯度相关指标最优作为分支用的节点,每次生成的树都不一样。
相关文章:

机器学习之决策树
决策树: 是一种有监督学习方法,从一系列有特征和标签的数据中总结出决策规则,并采用树状图的结构来呈现规则,用来解决分类和回归问题。 节点:根节点:没有进边,有出边。包含最初的,针…...

聊聊logback的UNDEFINED_PROPERTY
序 本文主要研究一下logback的UNDEFINED_PROPERTY substVars ch/qos/logback/core/util/OptionHelper.java public static String substVars(String input, PropertyContainer pc0, PropertyContainer pc1) {try {return NodeToStringTransformer.substituteVariable(input,…...
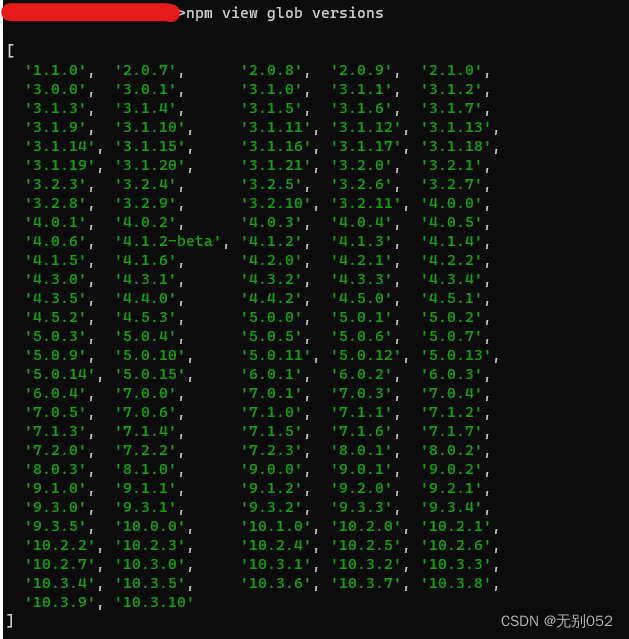
记一次pdjs时安装glob出现,npm ERR! code ETARGET和npm ERR! code ELIFECYCLE
如往常一样,我使用pdjs来编译proto文件,但出现了以下报错: 大致就是pdjs的util在尝试执行npm install glob^7.2.1 escodegen^1.13.0时出错了 尝试手动执行安装,escodegen被正确安装,但glob^7.2.1出错 npm ERR! code E…...
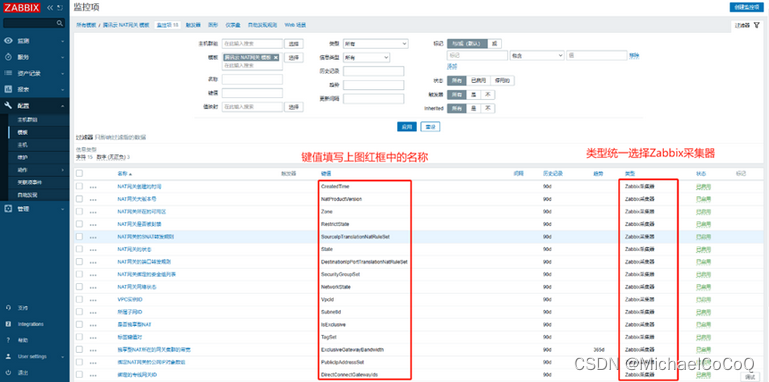
Zabbix如何监控腾讯云NAT网关
1、NAT网关介绍 NAT 网关(NAT Gateway)是一种支持 IP 地址转换服务,提供网络地址转换能力,主要包括SNAT(Source Network Address Translation,源网络地址转换)和DNAT(Destination N…...

SpringBoot案例(数据层、业务层、表现层)
1.创建项目 2.选择坐标 3.添加坐标 说明:为了便于开发,引入了lombak坐标。 <!--添加mybatis-plus坐标--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><ver…...

交叉编译程序:以 freetype 为例
1 程序运行的一些基础知识 1.1 编译程序时去哪找头文件? 系统目录:就是交叉编译工具链里的某个 include 目录;也可以自己指定:编译时用 “ -I dir ” 选项指定。 1.2 链接时去哪找库文件? 系统目录&#…...

spring-cloud-starter-dubbo不设置心跳间隔导致生产者重启no Provider问题记录
版本 spring-cloud-starter-dubbo-2.2.4.RELEASE 问题描述 生产者重启后,正常注册到注册中心,但是消费者调用接口是no provider,偶现,频繁出现 解决办法 先说原因和解决办法,有兴趣可以看下问题的排查过程。 原因…...

【数据结构】败者树的建树与比较过程
文章目录 前置知识归并段 建树过程比较过程疑问为什么比较次数减少了?如果某个归并段的元素一直获胜,没有元素了怎么办?处理方法 1处理方法 2 前置知识 归并段 外部排序算法通常用于处理大规模数据,其中数据量远超过计算机内存的…...

GlobalMapper---dem生成均匀分布的网格,或者均匀分布的点高程点
1打开DEM数据。点击工具栏上的Open Data File(s)按钮,打开DEM数据 2点击【Create Grid】按钮 3生成点 4导出格式xyz 5南方cass展点 6过滤抽稀...

k8s系列文章一:安装指南
前言 k8s是docker的升级版,可用于docker集群配置管理微服务 一、更新ubuntu系统版本 sudo apt update sudo apt upgrade二、添加GPG密钥(阿里源) 尽管我不知道gpg是个什么东西,反正跟着做就完了 curl https://mirrors.aliyun.com/kubernetes/apt/do…...

Pod 进阶
目录 1、资源限制 1.1 官网示例 1.2 CPU 资源单位 1.3 内存 资源单位 2、健康检查:又称为探针(Probe) 2.1 探针的三种规则 2.2 Probe支持三种检查方法 2.3 官网示例 3、扩展 pod的状态 3.1 Container生命周期 1、资源限制 当定义…...
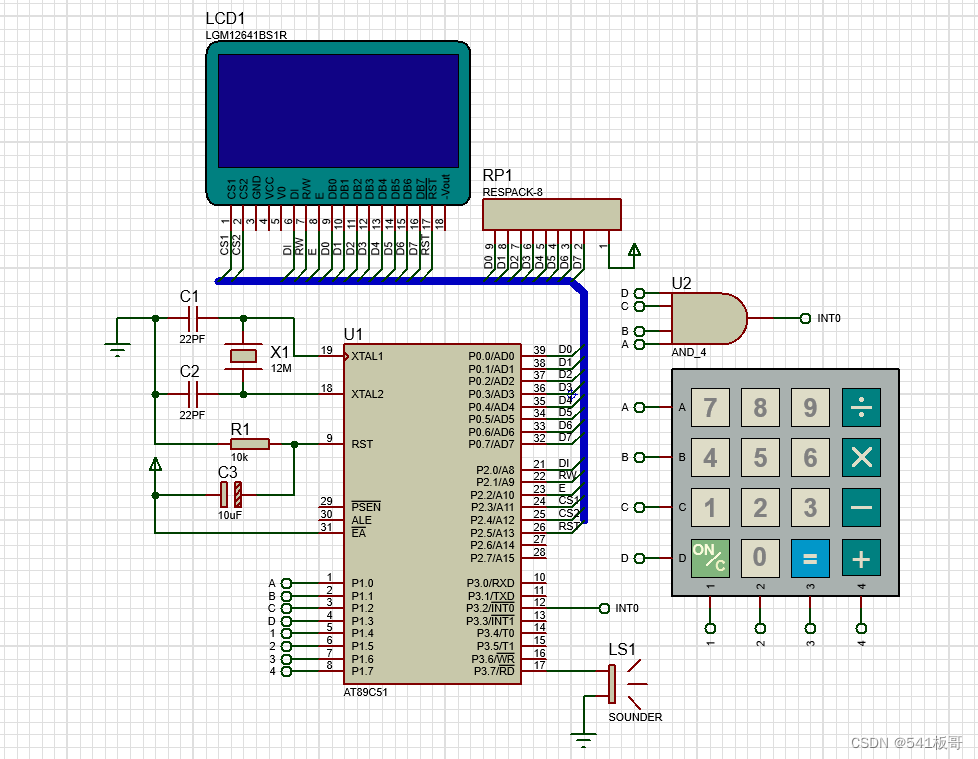
Proteus仿真--12864LCD显示计算器键盘按键实验(仿真文件+程序)
本文主要介绍基于51单片机的12864LCD液晶显示电话拨号键盘按键实验(完整仿真源文件及代码见文末链接) 仿真图如下 本设计主要介绍计算器键盘仿真,按键按下后在12864液晶上显示对应按键键值 仿真运行视频 Proteus仿真--12864LCD显示计算器…...

pam_radius库的使用
一. 前言 我们知道,linux pam库是一系列的库,用于处理一些应用程序的认证工作,比如login程序。但是默认的pam库只是用于本地认证,也就是认证的用户名和密码存储在本机上。如果需要远程认证,比如向radius服务器认证&…...

qt6:无法使用setFontColor
问题描述 跟着C开发指南视频学习,但是发现无论是直接使用ui设计,还是纯代码都无法实现变更字体颜色的功能。图中显示,点击颜色控件后,文本框的文字加粗、下划线、斜体等才能设置,但是无法变更颜色。 此文提醒qt sty…...
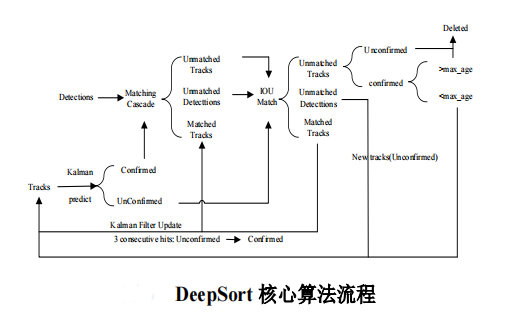
竞赛 深度学习疫情社交安全距离检测算法 - python opencv cnn
文章目录 0 前言1 课题背景2 实现效果3 相关技术3.1 YOLOV43.2 基于 DeepSort 算法的行人跟踪 4 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习疫情社交安全距离检测算法 ** 该项目较为新颖,适合作为竞赛…...
无声的世界,精神科用药并结合临床的一些分析及笔记(十)
目录 回 “ 家 ” 克服恐惧 奥沙西泮 除夕 酒与药 警告 离别 回 “ 家 ” 她的锥切手术进行的很顺利,按计划继续返回安定医院调节心理状态,病友们都盼着我们回“家”。当我俩跨入病区,大家都涌过来帮我们大包小包的拎着行李࿰…...

构建强大的Web应用之Django详解
引言: Django是一个功能强大且灵活的Python Web框架,它提供了一套完整的工具和功能,帮助开发者快速构建高效的Web应用。本篇文章将带您逐步了解Django的基本概念和使用方法,并通过实际的代码案例,帮助您从零开始构建自…...

Linux 之搭建 arm 的 qemu 模拟器
目录 1. Linux 之搭建 arm 的 qemu 模拟器 1. Linux 之搭建 arm 的 qemu 模拟器 OS: kali 1. 安装交叉编译工具、GDB 和 QEMU # sudo apt-get install qemu debootstrap qemu-user-static # sudo apt-get install qemu-system-arm # sudo apt-get install gdb-multiarch //支持…...

uinapp微信小程序隐私政策授权
🚀 隐私弹窗效果图: 1、启用隐私相关功能在manifest.json文件中配置 usePrivacyCheck: true "mp-weixin" : {"__usePrivacyCheck__" : true, },2、创建组件 <template><view><!-- 隐私政策弹窗 --><uni-popu…...

使用Java工作流简单介绍
本人详解 作者:王文峰,参加过 CSDN 2020年度博客之星,《Java王大师王天师》 公众号:JAVA开发王大师,专注于天道酬勤的 Java 开发问题中国国学、传统文化和代码爱好者的程序人生,期待你的关注和支持!本人外号:神秘小峯 山峯 转载说明:务必注明来源(注明:作者:王文峰…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

Visual Paradigm 17.0 团队协作新功能实测:手把手教你用项目模板和文件夹管理提效
Visual Paradigm 17.0 团队协作实战指南:从模板配置到文件夹管理的高效工作流在敏捷开发团队中,项目启动速度和资产管理的规范性往往直接影响整体效率。Visual Paradigm 17.0针对这一痛点推出的团队协作增强功能,特别是服务器端项目模板和文件…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南
pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download pan-baidu-download是一款基于Python开发的百度网盘命令行下载…...

从RD、CS到WK:一文讲透SAR主流成像算法的演进与选型实战
从RD、CS到WK:SAR成像算法选型实战指南 当无人机掠过灾区上空,或卫星扫描地球表面时,合成孔径雷达(SAR)正通过电磁波穿透云层和黑暗,将地面信息转化为高分辨率图像。而决定图像质量的关键,在于工…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...