zookeeper本地部署和集群搭建
zookeeper(动物园管理员)是一个广泛应用于分布式服务提供协调服务Apache的开源框架
zookeeper集群特点
- zookeeper集群由一个领导者(Leader)和多个跟随者(Follower)组成。
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所 以Zookeeper适合安装奇数台服务器。
- 全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
- 更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。
- 数据更新原子性,一次数据更新要么成功,要么失败。
- 实时性,在一定时间范围内,Client能读到最新数据。
本地模式安装
zookeeper由Java开发所有要运行zookeeper需要现安装jdk
安装jdk
可以下载免安装版jdk,解压后配置一下环境变量即可
linux下的环境变量配置文件在
/etc/profile然后在该文件下增加如下配置即可
export JAVA_HOME=/usr/java/jdk-21/jdk-21.0.1 // 我自己的jdk目录
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
然后从新加载配置文件,命令为
source /etc/profile 查看Java版本

则表示已成功安装Jdk
安装zookeeper
进入zookeeper官网,找到下载页面,下载-bin.tar.gz版即可,如果没有想要的版本则可以在下载页面的存档连接中找到
Apache ZooKeeper
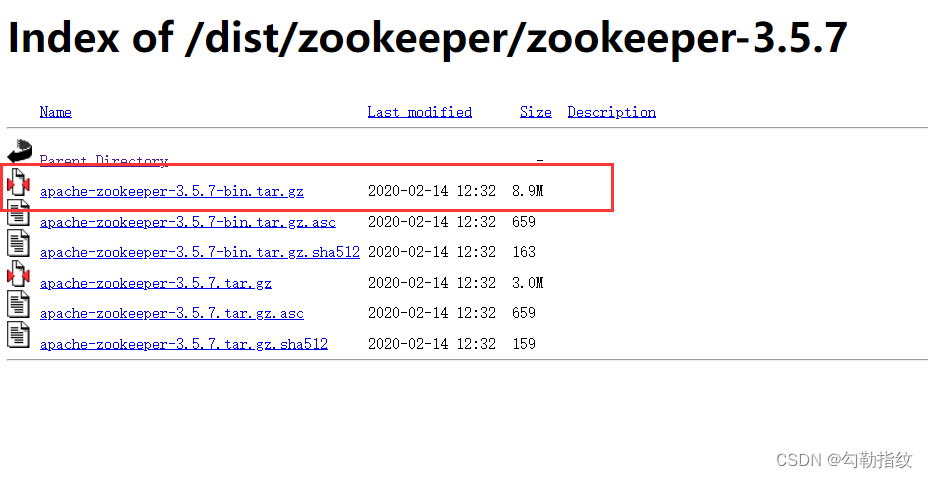
tar -zxvf apache-zookeeper-3.5.7- bin.tar.gz -C /mydata/zookeepermv apache-zookeeper-3.5.7 -bin/ zookeeper-3.5.7配置修改
1、将/mydata/zookeeper/zookeeper-3.5.7/conf这个路径下的 zoo_sample.cfg 修改为 zoo.cfg;
mv zoo_sample.cfg zoo.cfg2、打开 zoo.cfg 文件,修改 dataDir 配置的路径 修改为如下内容(默认的tmp路径是临时路径,一段时间后,linux会自动删除里面的文件,所有不适合正式环境使用)
dataDir=/mydata/zookeeper/zookeeper-3.5.7/data
3、在/mydata/zookeeper/zookeeper-3.5.7/这个目录上创建 data文件夹
操作zookeeper
1、启动 Zookeeper

3、查看状态

4、启动客户端
./zkCli.sh
5、退出客户端:
[zk: localhost:2181(CONNECTED) 0] quit
6、停止 Zookeeper
.bin/zkServer.sh stop
配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
1)tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
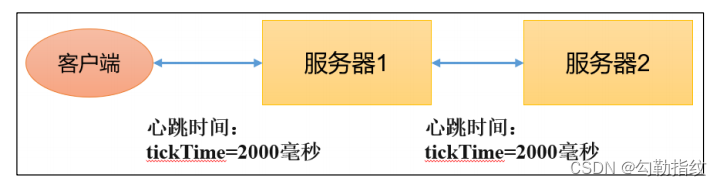

Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量)
3)syncLimit = 5:LF同步通信时限
Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
4)dataDir:保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
zookeeper集群搭建
1)集群规划
(1)修改克隆虚拟机的静态 IP
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="d7919ed1-15af-49fe-9b4e-aad1456eed3d"
DEVICE="ens33"
ONBOOT="yes"IPADDR=192.168.127.100
# wangGuan
GATEWAY=192.168.127.2
# DNS
DNS1=192.168.127.2
(2)查看 Linux 虚拟机的虚拟网络编辑器,编辑->虚拟网络编辑器->VMnet8
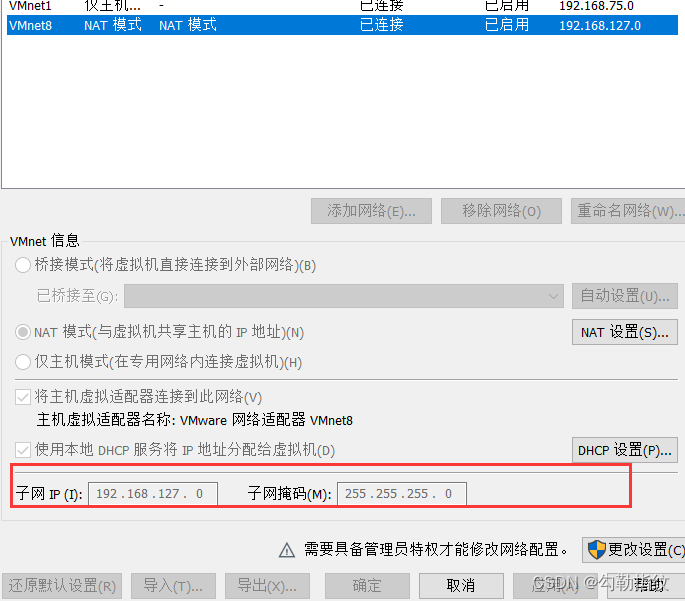
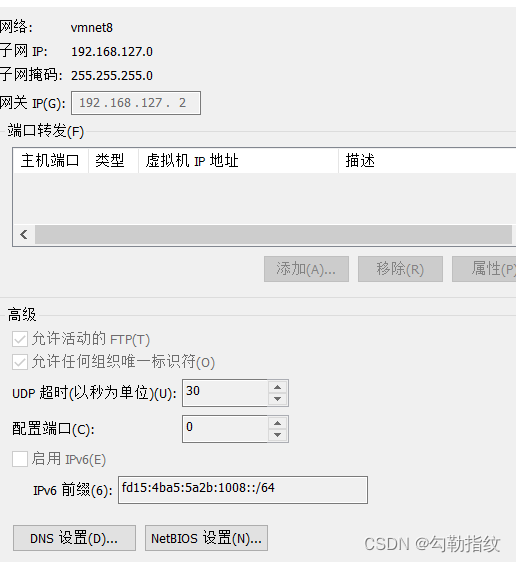
(3)查看 Windows 系统适配器 VMware Network Adapter VMnet8 的 IP 地址

(4)保证 Linux 系统 ifcfg-ens33 文件中 IP 地址、虚拟网络编辑器地址和 Windows 系统 VM8 网络 IP 地址在同一网段。
2)修改克隆机主机名,以下以 hadoop100 举例说明
(1)修改主机名称
vim /etc/hostnamehadoop102
(2)配置 Linux 克隆机主机名称映射 hosts 文件,打开/etc/host
[root@hadoop100 ~]# vim /etc/hosts
192.168.127.100 hadoop100
192.168.127.101 hadoop101
192.168.127.102 hadoop102
192.168.127.103 hadoop103
192.168.127.104 hadoop104
192.168.127.105 hadoop105
192.168.127.106 hadoop106
192.168.127.107 hadoop107
192.168.127.108 hadoop108
192.168.127.132 qingmangmall
3)重启克隆机 hadoop100
[root@hadoop100 ~]# reboot
4)修改 windows 的主机映射文件(hosts 文件)
- (a)进入 C:\Windows\System32\drivers\etc 路径
- (b)打开 hosts 文件并添加如下内容,然后保存
192.168.127.100 hadoop100
192.168.127.101 hadoop101
192.168.127.102 hadoop102
192.168.127.103 hadoop103
192.168.127.104 hadoop104
192.168.127.105 hadoop105
192.168.127.106 hadoop106
192.168.127.107 hadoop107
192.168.127.108 hadoop108
192.168.127.132 qingmangmall
3)集群分发
将zookeeper分发给其他服务
[user@hadoop102 ~]$ sudo chown user:user -R /mydata
[user@ hadoop102 ~]$ scp -r /mydata/zookeeper user@hadoop103:/mydata
100
scp -r /mydata/zookeeper/zookeeper-3.5.7/data user@hadoop103:/mydata/zookeeper/zookeeper-3.5.7
配置zoo.cfg文件
[user@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
[user@hadoop102 conf]$ vim zoo.cfg
dataDir=/opt/module/zookeeper-3.5.7/zkData
#######################cluster##########################server.100=hadoop100:2888:3888server.103=hadoop103:2888:3888server.132=qingmangmall:2888:3888
集群操作
[user@hadoop100 zookeeper-3.5.7]$ bin/zkServer.sh start[user@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start[user@qingmangmall zookeeper-3.5.7]$ bin/zkServer.sh start
[user@hadoop100 zookeeper-3.5.7]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfgMode: follower[user@hadoop103 zookeeper-3.5.7]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfgMode: leader[user@qingmangmall zookeeper-3.5.7]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfgMode: follower
附录
1)创建用户 并设置文件所属组
[root@hadoop100 ~]# useradd user[root@hadoop100 ~]# passwd user
[root@hadoop100 ~]# vim /etc/sudoers
## Allow root to run any commands anywhereroot ALL=(ALL) ALL## Allows people in group wheel to run all commands% wheel ALL=(ALL) ALLuser ALL=(ALL) NOPASSWD:ALL
mkdir /mydata
[root@hadoop100 ~]# chown user:user /mydata
2)scp(secure copy)安全拷贝
3)rsync 远程同步工具
相关文章:
zookeeper本地部署和集群搭建
zookeeper(动物园管理员)是一个广泛应用于分布式服务提供协调服务Apache的开源框架 Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它 负责存储和管理大家都关心的数据 ,然 后 接受观察…...
工程师)
优橙内推甘肃专场——5G网络优化(中高级)工程师
内推公司1:上海井胜通讯技术有限公司 内推公司2:西安长河通讯有限责任公司 内推公司3:沈阳电信工程局 上海井胜通讯技术有限公司 公司成立于2002年,是一家专业移动通信技术服务公司。2008年之前是香港一家大型流动通讯运营公司…...
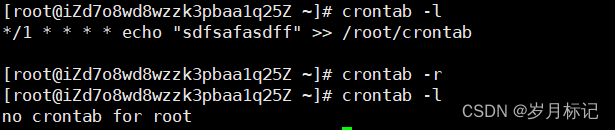
crontab 定时任务
1.查看 crond 是否开启 systemctl status crond 2.设置 crontab 定时任务 基本语法 #基本语法 crontab [选项] 查看定时任务 #查看定时任务 crontab -l 编辑定时任务 #编辑定时任务 crontab -e 案例实操 */1 * * * * echo "hello,world" >> /root/hel…...
【入门Flink】- 03Flink部署
集群角色 Flik提交作业和执行任务,需要几个关键组件: 客户端(Client):代码由客户端获取并做转换,之后提交给JobManger JobManager:就是Fink集群里的“管事人”,对作业进行中央调度管理;而它获…...

DockerFile常用保留字指令及知识点合集
目录 DockerFile加深理解: DockerFile常用保留字指令 保留字: RUN:容器构建时需要运行的命令 COPY:类似ADD,拷贝文件和目录到镜像中。 将从构建上下文目录中 <源路径> 的文件/目录复制到新的一层的镜像内的 …...

怎么批量删除文件名中的空格?
怎么批量删除文件名中的空格?当我们整理文件的时候发现文件名里面有一些空格,如果空格较多,可能会造成文件名特别的长,我们一般会随手对文件进行重命名,然后将文件名中的空格删除掉,这项操作非常的简单方便…...

回顾十大数据恢复软件,帮助用于恢复丢失的文件!
您是否因丢失计算机上的重要文件而感到恐慌?你不是一个人!数据丢失是许多人面临的严重问题,但幸运的是,有许多解决方案可以恢复数据。 在本文中,我将回顾十大数据恢复软件,以帮助您恢复丢失的文件…...

【Linux】多路IO复用技术②——poll详解如何使用poll模型实现简易的一对多服务器(附图解与代码实现)
在阅读本篇博客之前,建议大家先去看一下我之前写的这篇博客,否则你很可能会一头雾水 【Linux】多路IO复用技术①——select详解&如何使用select模型在本地主机实现简易的一对多服务器(附图解与代码实现)http://t.csdnimg.cn/…...

CSS 滚动捕获 Scroll Snap
CSS 滚动捕获 Scroll Snap CSS 滚动捕获允许开发者通过声明一些位置(或叫作捕获位置)来创建精准控制的滚动体验. 通常来说轮播图就是这种体验的例子, 在轮播图中, 用户只能停在图 A 或者图 B, 而不能停在 A 和 B 的中间. 比如平时用淘宝或小红书, 当你上滑到下一个推荐内容时…...

【带头学C++】----- 三、指针章 ---- 3.9 数组作为函数的参数
当数组作为函数参数时,有几种常见的方式可以传递数组给函数: 数组作为指针传递: 数组名在函数调用时会自动转换为指向数组第一个元素的指针。通过指针可以访问数组元素,但无法获取数组的大小。在函数中修改指针指向的值会影响原始…...
完美处理 Android App 的 apk 输出路径与文件名
实现代码 buildTypes {// ...applicationVariants.all {variant ->variant.outputs.all {Calendar calendar Calendar.getInstance(Locale.CHINA);def buildDate String.format(Locale.CHINA, "%04d%02d%02d", calendar.get(Calendar.YEAR), calendar.get(Cale…...

【技术干货】开源库 Com.Gitusme.Net.Extensiones.Core 的使用
目录 1、项目介绍 2、为项目添加依赖 3、代码中导入命名空间 4、代码中使用 示例 1:string转换 示例 2:object转换 1、项目介绍 Com.Gitusme.Net.Extensiones.Core是一个.Net扩展库。当前最新版本1.0.4,提供了常见类型转换,…...
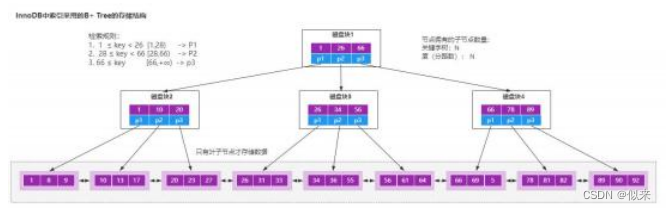
大厂面试题-b树和b+树的理解
为了更清晰的解答这个问题,从三个方面来回答: a.了解二叉树、AVL树、B树的概念 b.B树和B树的应用场景 1.B树是一种多路平衡查找树,为了更形象的理解,我们来看这张图。 二叉树,每个节点支持两个分支的树结构ÿ…...
NeRF-SLAM部署运行(3060Ti)
记录在部署运行期间遇到的一些问题,分享给大家~ 一、环境 RTX 3060 Ti、8G显存、Ubuntu18.04 二、部署 1. 下载代码 git clone https://github.com/jrpowers/NeRF-SLAM.git --recurse-submodules git submodule update --init --recursive cd thirdparty/insta…...
零基础编程入门教程软件推荐,零基础编程自学
零基础编程入门教程软件推荐,零基础编程自学 给大家分享一款中文编程工具,零基础轻松学编程,不需英语基础,编程工具可下载。 这款工具不但可以连接部分硬件,而且可以开发大型的软件,象如图这个实例就是用…...

Amazon EC2 安全可调用的云虚拟主机服务器
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! Amazon EC2 打造全新的科技链 Amazon Elastic Compute Cloud(Amazon EC2)提供最广泛、最深入的计算平台,拥有超过 500 个实例&…...

HTTP/HTTPS、SSL/TLS、WS/WSS 都是什么?
有同学问我,HTTP/HTTPS、SSL/TLS、WS/WSS 这都是些什么?那我们就先从概念说起: HTTP 是超文本传输协议,信息是通过明文传输。HTTPS 是在 HTTP 的基础上信息通过加密后再传输。SSL 是实现 HTTPS 信息传输加密的算法。TLS 是 SSL 的…...

软考之系统安全理论基础+例题
系统安全 系统安全性分析与设计 作为全方位的、整体的系统安全防范体系也是分层次的,不同层次反映了不同的安全问题,根据网络的应用现状情况和结构,可以将安全防范体系的层次划分为 物理层安全系统层安全网络层安全应用层安全安全管理。 …...

棱镜七彩亮相工控中国大会,以软件供应链安全助力新型工业化高质量发展
2023年11月1日-3日,2023第三届工控中国大会在苏州国际会议中心举办,本届大会由中国电子信息产业发展研究院、中国工业经济联合会、国家智能制造专家委员会、国家产业基础专家委员会、江苏省工业和信息化厅、江苏省国有资产监督管理委员会、苏州市人民政府…...

数据可视化:动态柱状图
终于来到最后一个数据可视化的文章拿啦~~~ 在这里学习如何绘制动态柱状图 我先整个活 (๑′ᴗ‵๑)I Lᵒᵛᵉᵧₒᵤ❤ 什么是pyecharts? 答: Python的Pyecharts软件包。它是一个用于Python数据可视化和图表绘制的库,可用于制作…...

【Epic认证级适配流程】:UE6.5.0–6.5.3全版本C++27支持矩阵,含3大禁用扩展、2个ABI断裂风险点与1份可审计迁移Checklist
第一章:Epic认证级C27适配的合规性基准与目标定义Epic Games官方于2024年Q3发布的《Unreal Engine 5.5 C Language Compliance Framework》首次将C27草案核心特性纳入引擎构建工具链的强制验证范围。本章确立的合规性基准并非仅面向语法兼容,而是聚焦于A…...
:如何进行数据整理(下),分类变量如何设置对照组?设置值标签?)
Zstats高级版教程(3):如何进行数据整理(下),分类变量如何设置对照组?设置值标签?
本篇是风暴统计平台教程系列的第三章,将详细说明如何使用数据整理模块,节省后续分析的时间。因为涉及内容比较多,分为上中下三篇,此为下篇。前两篇数据整理教程分别向大家详细介绍了数据整理模块的定量数据转分类、计算新变量、变…...
)
C++高频交易内存池性能跃迁指南(从42μs到1.7μs的97.6%时延压缩路径)
第一章:C高频交易内存池性能跃迁全景图在毫秒乃至微秒级竞争的高频交易系统中,动态内存分配已成为关键性能瓶颈。标准 malloc 与 new 操作引入的锁争用、TLB抖动及堆碎片问题,直接导致订单延迟波动增大、吞吐量不可预测。现代低延迟内存池通过…...

SecGPT-14B模型蒸馏:打造轻量级OpenClaw安全助手
SecGPT-14B模型蒸馏:打造轻量级OpenClaw安全助手 1. 为什么需要轻量级安全助手? 去年在为一个金融客户部署自动化安全监控系统时,我遇到了一个典型困境:他们的边缘设备只能提供4GB内存和2核CPU的算力,但SecGPT-14B这…...

golang.org/x/net WebSocket开发完全手册:实现实时双向通信
golang.org/x/net WebSocket开发完全手册:实现实时双向通信 【免费下载链接】net [mirror] Go supplementary network libraries 项目地址: https://gitcode.com/gh_mirrors/ne/net 在现代Web应用开发中,实时双向通信已成为提升用户体验的关键技术…...

OpenClaw配置文件详解:Qwen3.5-9B高级参数调优手册
OpenClaw配置文件详解:Qwen3.5-9B高级参数调优手册 1. 为什么需要手动调优OpenClaw配置 上周我尝试用OpenClaw自动处理一批技术文档的归档工作,发现同样的任务在不同时段完成速度差异巨大。有时30分钟就能搞定,有时却要卡顿近2小时。这促使…...

Android开发者的USB摄像头避坑指南:从设备枚举到SurfaceView预览的完整流程
Android开发者实战:USB摄像头集成全流程与疑难解析 去年接手一个医疗设备项目时,我需要在Android平板上接入工业级USB摄像头。本以为三天能搞定,结果光是解决画面拉伸问题就耗了一周。这份踩坑经验总结,将带你系统掌握从设备枚举到…...

OpenClaw与千问3.5-35B-A3B-FP8低成本方案:自建模型接口替代OpenAI高价调用
OpenClaw与千问3.5-35B-A3B-FP8低成本方案:自建模型接口替代OpenAI高价调用 1. 为什么需要替代OpenAI高价调用 去年冬天的一个深夜,我盯着OpenAI API账单上那个刺眼的数字——$127.83,这只是一个月的测试费用。当时我正在用OpenClaw做一个自…...

电力系统稳定器与静态无功补偿器联合提升暂态稳定性Simulink仿真模型研究
使用电力系统稳定器(PSS)和静态无功补偿器(SVC)提高暂态稳定性的simulink仿真模型电力系统这玩意儿最怕的就是突然来个大扰动,比如短路故障或者大负荷切换。这时候发电机的功角曲线要是收不住,分分钟全网停…...

深入解析pysim中的eUICC ISD-R命令:从基础操作到高级应用
1. eUICC ISD-R命令基础入门 第一次接触eUICC ISD-R命令时,我完全被那些专业术语搞晕了。经过几个项目的实战,我发现这些命令其实就像智能手机上的应用商店操作——只不过管理的是SIM卡上的应用。eUICC(嵌入式通用集成电路卡)是现…...