大数据之陌陌聊天数据分析案例
目录
目标需求
数据内容
基于Hive数仓实现需求开发
1.建库建表、加载数据
2.ETL数据清洗
3需求指标统计
目标需求
基于Hadoop和hive实现聊天数据统计分析,构建聊天数据分析报表
1.统计今日总消息量
2.统计今日每小时消息量,发送和接收用户数
3.统计今日各地区发送消息数据量
4.统计今日发送消息和接收消息的用户数
5.统计发送消息最多的top10用户
6.统计接收消息最多的top10用户
7.统计发送人的手机型号分部情况
8.统计发送人的设备操作系统分布情况
数据内容
数据来源:聊天业务系统中导出的2021年11月01日的一天24小时的用户聊天数据,以TSV文本形式存储在文件中
数据大小:两个文件共14万条
列分隔符:制表符‘\t’
数据字典及样列数据:

基于Hive数仓实现需求开发
1.建库建表、加载数据
--------------1、建库---------------------如果数据库已存在就删除
drop database if exists db_msg cascade;
--创建数据库
create database db_msg;
--切换数据库
use db_msg;
--------------2、建表-------------------
--如果表已存在就删除
drop table if exists db_msg.tb_msg_source;
--建表
create table db_msg.tb_msg_source(msg_time string comment "消息发送时间", sender_name string comment "发送人昵称", sender_account string comment "发送人账号", sender_sex string comment "发送人性别", sender_ip string comment "发送人ip地址", sender_os string comment "发送人操作系统", sender_phonetype string comment "发送人手机型号", sender_network string comment "发送人网络类型", sender_gps string comment "发送人的GPS定位", receiver_name string comment "接收人昵称", receiver_ip string comment "接收人IP", receiver_account string comment "接收人账号", receiver_os string comment "接收人操作系统", receiver_phonetype string comment "接收人手机型号", receiver_network string comment "接收人网络类型", receiver_gps string comment "接收人的GPS定位", receiver_sex string comment "接收人性别", msg_type string comment "消息类型", distance string comment "双方距离", message string comment "消息内容"
)
--指定分隔符为制表符
row format delimited fields terminated by '\t';--------------3、加载数据-------------------
--上传数据文件到node1服务器本地文件系统(HS2服务所在机器)
--shell: mkdir -p /root/hivedata--加载数据到表中
load data local inpath '/root/hivedata/data1.tsv' into table db_msg.tb_msg_source;
load data local inpath '/root/hivedata/data2.tsv' into table db_msg.tb_msg_source;--查询表 验证数据文件是否映射成功
select * from tb_msg_source limit 10;--统计行数
select count(*) as cnt from tb_msg_source;
2.ETL数据清洗
--------------4、ETL数据清洗-------------------
--问题1:当前数据中,有一些数据的字段为空,不是合法数据
selectmsg_time,sender_name,sender_gps
from db_msg.tb_msg_source
where length(sender_gps) = 0
limit 10;--问题2:需求中,需要统计每天、每个小时的消息量,但是数据中没有天和小时字段,只有整体时间字段,不好处理
selectmsg_time
from db_msg.tb_msg_source
limit 10;--问题3:需求中,需要对经度和维度构建地区的可视化地图,但是数据中GPS经纬度为一个字段,不好处理
selectsender_gps
from db_msg.tb_msg_source
limit 10;--ETL实现
--如果表已存在就删除
drop table if exists db_msg.tb_msg_etl;
--将Select语句的结果保存到新表中
create table db_msg.tb_msg_etl as
select*,substr(msg_time,0,10) as dayinfo, --获取天substr(msg_time,12,2) as hourinfo, --获取小时split(sender_gps,",")[0] as sender_lng, --提取经度split(sender_gps,",")[1] as sender_lat --提取纬度
from db_msg.tb_msg_source
--过滤字段为空的数据
where length(sender_gps) > 0 ;--验证ETL结果
selectmsg_time,dayinfo,hourinfo,sender_gps,sender_lng,sender_lat
from db_msg.tb_msg_etl
limit 10;3需求指标统计
--------------5、需求指标统计分析-------------------
--需求:统计今日总消息量
create table if not exists tb_rs_total_msg_cnt
comment "今日消息总量"
as
selectdayinfo,count(*) as total_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo;select * from tb_rs_total_msg_cnt;--结果验证--需求:统计今日每小时消息量、发送和接收用户数
create table if not exists tb_rs_hour_msg_cnt
comment "每小时消息量趋势"
as
selectdayinfo,hourinfo,count(*) as total_msg_cnt,count(distinct sender_account) as sender_usr_cnt,count(distinct receiver_account) as receiver_usr_cnt
from db_msg.tb_msg_etl
group by dayinfo,hourinfo;select * from tb_rs_hour_msg_cnt;--结果验证--需求:统计今日各地区发送消息数据量
create table if not exists tb_rs_loc_cnt
comment "今日各地区发送消息总量"
as
selectdayinfo,sender_gps,cast(sender_lng as double) as longitude,cast(sender_lat as double) as latitude,count(*) as total_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo,sender_gps,sender_lng,sender_lat;select * from tb_rs_loc_cnt; --结果验证--需求:统计今日发送消息和接收消息的用户数
create table if not exists tb_rs_usr_cnt
comment "今日发送消息人数、接受消息人数"
as
selectdayinfo,count(distinct sender_account) as sender_usr_cnt,count(distinct receiver_account) as receiver_usr_cnt
from db_msg.tb_msg_etl
group by dayinfo;select * from tb_rs_usr_cnt; --结果验证--需求:统计今日发送消息最多的Top10用户
create table if not exists tb_rs_susr_top10
comment "发送消息条数最多的Top10用户"
as
selectdayinfo,sender_name as username,count(*) as sender_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo,sender_name
order by sender_msg_cnt desc
limit 10;select * from tb_rs_susr_top10; --结果验证--需求:统计今日接收消息最多的Top10用户
create table if not exists tb_rs_rusr_top10
comment "接受消息条数最多的Top10用户"
as
selectdayinfo,receiver_name as username,count(*) as receiver_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo,receiver_name
order by receiver_msg_cnt desc
limit 10;select * from tb_rs_rusr_top10; --结果验证--需求:统计发送人的手机型号分布情况
create table if not exists tb_rs_sender_phone
comment "发送人的手机型号分布"
as
selectdayinfo,sender_phonetype,count(distinct sender_account) as cnt
from tb_msg_etl
group by dayinfo,sender_phonetype;select * from tb_rs_sender_phone; --结果验证--需求:统计发送人的设备操作系统分布情况
create table if not exists tb_rs_sender_os
comment "发送人的OS分布"
as
selectdayinfo,sender_os,count(distinct sender_account) as cnt
from tb_msg_etl
group by dayinfo,sender_os;select * from tb_rs_sender_os; --结果验证
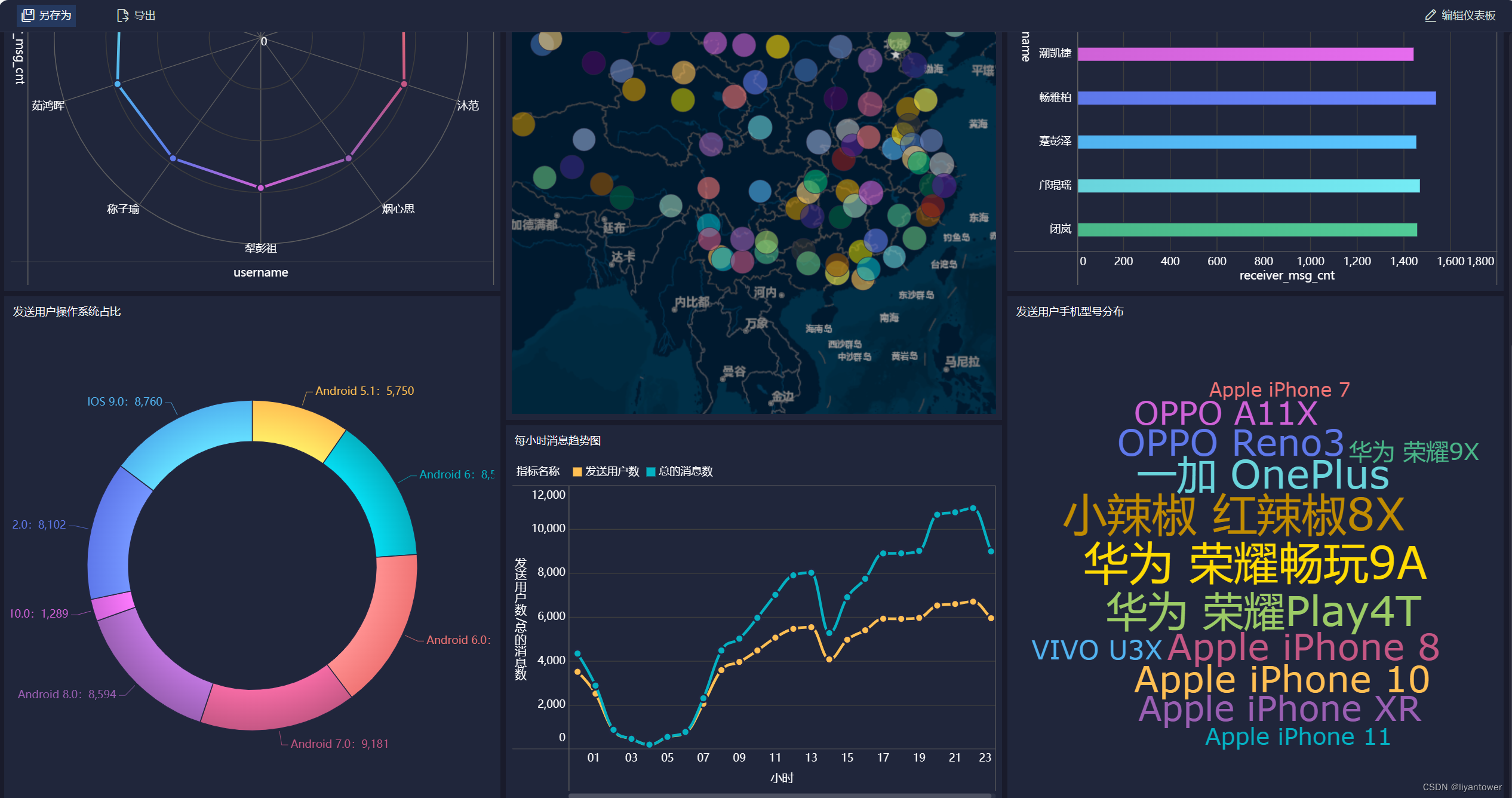
FIneBI可视化报表
构建可视化报表

相关文章:
大数据之陌陌聊天数据分析案例
目录 目标需求 数据内容 基于Hive数仓实现需求开发 1.建库建表、加载数据 2.ETL数据清洗 3需求指标统计 目标需求 基于Hadoop和hive实现聊天数据统计分析,构建聊天数据分析报表 1.统计今日总消息量 2.统计今日每小时消息量,发送和接收用户数 3.…...

03 贝尔曼公式
贝尔曼公式 前言1、Motivating examples2、state value3、Bellman equation:Derivation4、Bellman equation:Matrix-vector form4、Bellman equation:Solve the state value5、Action value 前言 本文来自西湖大学赵世钰老师的B站视频。本节课主要介绍贝尔曼公式。 本节课概要…...

学习视频剪辑:批量添加srt字幕,让视频更生动
随着社交媒体的普及,视频制作变得越来越重要。无论是记录生活,还是分享知识,视频都是一个非常有力的工具。但是,如何让您的视频更生动、更吸引人呢?通过学习视频剪辑,您可以使您的视频更具有吸引力。而在这…...
Windows桌面便签工具推荐使用哪一款?
电脑桌面上张贴便利贴可以将近期需要完成的工作计划逐一添加到便利贴中,电脑桌面悬挂便利贴工具可以督促日常各项事务的完成。当前可悬挂在电脑桌面上的便利贴工具是比较多的,其中桌面小工具便签软件敬业签可满足各行业的办公需求。 建议大家在Windows桌…...
)
【微信小程序】自定义组件(二)
自定义组件 纯数据字段1、什么是纯数据字段2、使用规则 组件的生命周期1、组件全部的生命周期函数2、组件主要的生命周期函数3、lifetimes节点 组件所在页面的生命周期1、什么是组件所在页面的生命周期2、 pageLifetimes节点3、生成随机的颜色值 纯数据字段 1、什么是纯数据字…...

llinux的更目录下的文件作用和举例
Linux是一种开源的操作系统,其文件系统采用了一种层次化的结构。在Linux文件系统中,最顶层的目录被称为根目录,也就是“/”(斜杠)。在根目录下,有很多文件和目录,它们各自有着不同的作用。本文将…...

20231106_抽象类abstract
抽象类abstract 关键字 abstract运用抽象类抽象方法:修饰抽象类中的某个方法,强制子类重写该方法 归纳 关键字 abstract 对于子类必须要实现特定方法,当时父类无法明确时,可定义为抽象类及抽象方法 不合理: 动物吃东西是基础,在这里写吃的方法过于简单,信息没有实际意义; 怎…...

yolov5 obb旋转框 tensorrt部署
文章目录 1.生成engine文件2.检测图像3.代码yolov5-obb tensorRT部署代码结合王新宇和fish-kong两者的代码,可以多batch批量检测旋转框 yolov5旋转框检测: https://blog.csdn.net/qq_42754919/article/details/134145174 1.生成engine文件 首先需要将pt文件转换成wts文件,…...
http中的Content-Type类型
浏览器的Content-Type 最近在做web端下载的时候需要给前端返回一个二进制的流,需要在请求头中设置一个 writer.Header().Set("Content-Type", "application/octet-stream")那么http中的Content-Type有具体有哪些呢?他们具体的使用场…...
【C语法学习】17 - fwrite()函数
文章目录 1 函数原型2 参数3 返回值4 示例 1 函数原型 fwrite():将ptr指向的内存空间中储存的数据块写入与指定流stream相关联的二进制文件中,函数原型如下: size_t fwrite(const void *ptr, size_t size, size_t count, FILE *stream)2 参…...
)
CWE(Common Weakness Enumeration,通用缺陷枚举)
参考链接:https://cwe.mitre.org/ CWE(Common Weakness Enumeration,通用缺陷枚举)和CVE(Common Vulnerabilities & Exposures,通用漏洞和风险)都是在计算机软件安全领域中非常重要的公开数…...

华为政企视频会议产品集
产品类型产品型号产品说明 maintainProductCloudMCU基础版-ARM华为CloudMCU是为面向云化需求而推出的功能强大的企业云通信融合媒体平台。融合视频、音频和数据等多种媒体内容,接入从会议室到个人PC、手机等设备,实现统一无缝的沟通协作。maintainProduc…...

IntelliJ IDEA 2022创建Maven项目
IntelliJ IDEA 2022创建Maven项目 点击New Project 配置一下下 (1). 选择Maven Archetype (2). 输入Name就是你的项目名称 (3). 输入Location是你的项目保存目录 (4). 选择JDK (5). 选择Catalog一般默认选择Internal即可 在Archetype这里我们选择一个模板来创建Maven项目 …...

有限域的Fast Multiplication和Modular Reduction算法实现
1. 引言 关于有限域的基础知识,可参考: RISC Zero团队2022年11月视频 Intro to Finite Fields: RISC Zero Study Club 有限域几乎是密码学中所有数学的基础。 ZKP证明系统中的所有运算都是基于有限域的: 使用布尔运算的数字电路…...

第八章:security testing
文章目录 Security Testingbuffer overflow 的例子Fuzzing 测试Random Testing好处坏处Mutation-based Fuzzing好处坏处Generation-based Fuzzing好处坏处Memory DebuggerUndefined Behaviors (未定义行为)Security Testing 渗透测试(或称为pentesting)是指攻击软件以寻找安…...

Linux系统下一些配置建议整理
1. 【推荐】高并发服务器建议调小 TCP 协议的 time_wait 超时时间。 说明:操作系统默认 240 秒后,才会关闭处于 time_wait 状态的连接,在高并发访问下,服 务器端会因为处于 time_wait 的连接数太多,可能无法建立新的…...

【launch文件中如何启动gdb调试单个节点多个节点】
文章目录 调试多个节点在ROS中,如果需要用gdb调试节点,你可以在.launch文件中添加相关的参数。以下是一个例子,展示如何为一个节点启动gdb调试: <launch><node pkg="your_package" type="your_node...
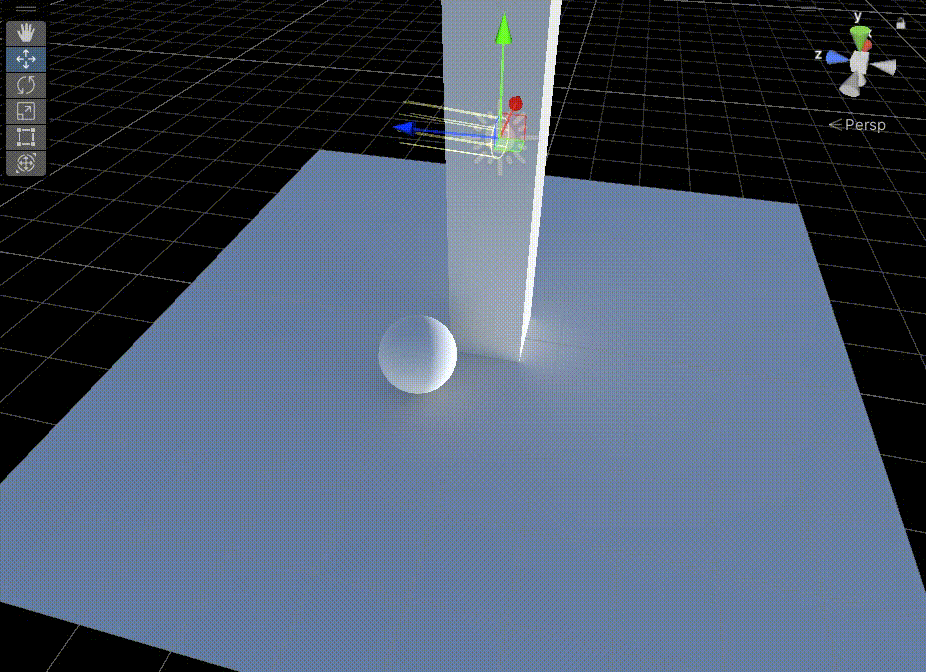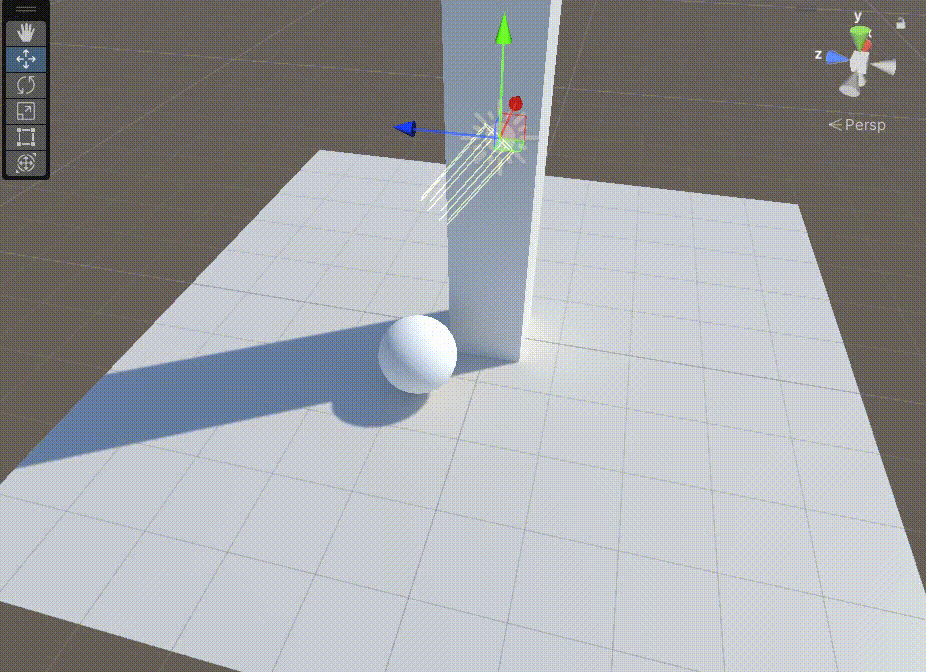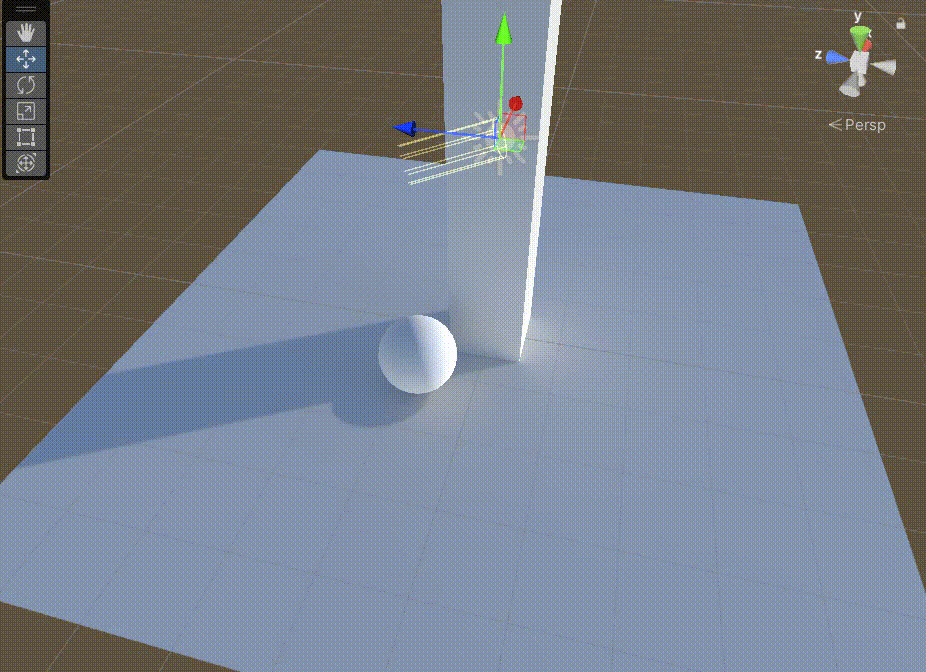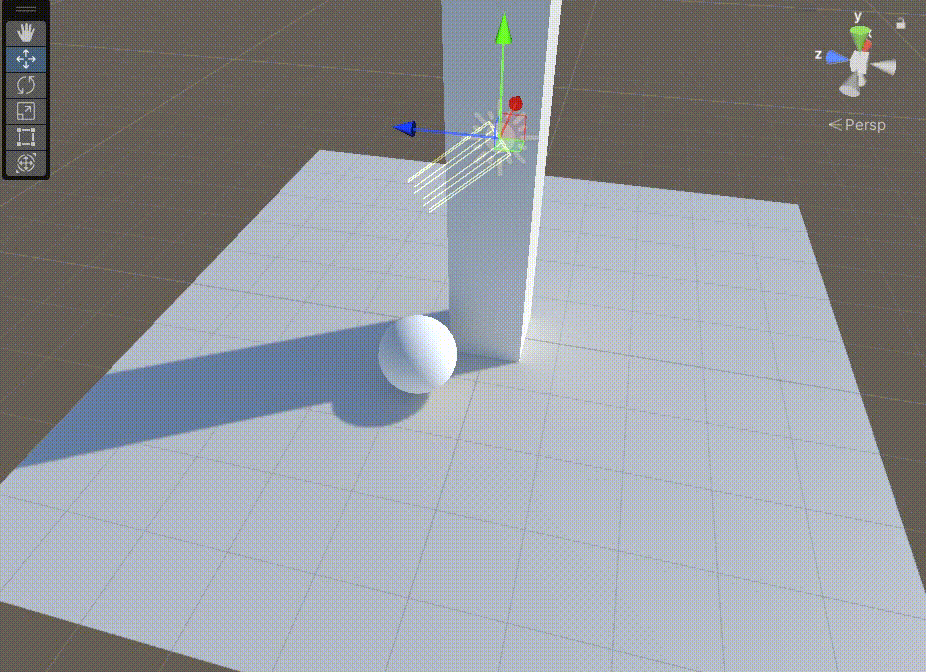
Unity中Shader的GI的直接光实现
文章目录 前言一、在上一篇文章中,得到GI相关数据后,需要对其进行Lambert光照模型计算二、在准备好上面步骤后,我们需要准备缺少的数据1、准备上图中的 s.Normal2、准备上图中的 s.Albedo 前言 Unity中Shader的GI的直接光实现,基…...

JAVA进程和线程
哈喽~大家好呀,这篇来看看JAVA进程和线程。 🥇个人主页:个人主页 🥈 系列专栏:【日常学习上的分享】 🥉与这篇相关的文章: Redis快速入…...

日志配置陷阱:Telegraf Windows版本兼容性问题深度解析
日志配置陷阱:Telegraf Windows版本兼容性问题深度解析 Windows系统管理员常面临日志采集配置升级后服务无法启动的困境。Telegraf作为InfluxData开源的指标收集代理(Agent),其Windows版本在日志配置变更时可能引发兼容性问题。本…...

Slim模板终极部署指南:从开发到生产的完整流程
Slim模板终极部署指南:从开发到生产的完整流程 【免费下载链接】slim Slim is a template language whose goal is to reduce the syntax to the essential parts without becoming cryptic. 项目地址: https://gitcode.com/gh_mirrors/sli/slim Slim模板语言…...

百考通:一站式计算机与工程类项目学习与精准开发平台
在信息技术高速发展的今天,无论是高校学生、编程爱好者还是行业从业者,都面临着项目实践资源分散、学习路径不清晰、开发效率低下的困境。百考通(https://www.baikaotongai.com) 应运而生,以一站式项目资源聚合平台的姿…...

OpenClaw浏览器自动化:千问3.5-27B驱动智能检索与内容聚合
OpenClaw浏览器自动化:千问3.5-27B驱动智能检索与内容聚合 1. 为什么需要浏览器自动化助手 作为一个经常需要做市场调研的技术人,我过去总是陷入这样的循环:打开十几个浏览器标签页,在不同平台间反复切换,手动复制粘…...

WebPlotDigitizer终极指南:从科研图表到结构化数据的完整解决方案
WebPlotDigitizer终极指南:从科研图表到结构化数据的完整解决方案 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigitizer 在科研和…...

第 6 次执行后,PostgreSQL 执行计划为何突变?
引言 在 PostgreSQL 中,预处理语句通常用于提升性能并防止 SQL 注入。但一个不易察觉的行为是:查询规划器会在执行达到特定次数后自动改变执行计划。 这种变化往往令人困惑——SQL 本身未发生变化,执行计划却突然发生切换,有时甚至…...

开发环境配置实战:通过Anaconda Prompt高效管理虚拟环境与Jupyter内核
1. 为什么需要Anaconda Prompt管理虚拟环境 作为数据科学领域的开发者,我经历过无数次Python环境混乱带来的痛苦。记得有一次在交付项目前,突然发现本地运行的模型在服务器上完全无法复现,排查了半天才发现是numpy版本不兼容的问题。这种经历…...

数据科学家稳健统计系列第一部分:稳健的中心趋势度量以及...
原文:towardsdatascience.com/robust-statistics-for-data-scientists-part-1-resilient-measures-of-central-tendency-and-67e5a60b8bf1 https://github.com/OpenDocCN/towardsdatascience-blog-zh-2024/raw/master/docs/img/cf43c75d8b50af4d9c13df54abeccde8.pn…...

基于Matlab的多自由度轴承静刚度计算之旅
基于Matlab的多自由度轴承静刚度计算 因分析静态下刚度结果,仅考虑重力作用,未考虑离心力的作用 深沟球轴承和圆锥轴承基本参数包括滚珠数量、滚珠直径、中称直径、曲率和材料参数 程序已调通,可直接运行在机械工程领域,深入了解轴…...

短视频 SEO 优化能给企业带来什么好处_短视频 SEO 如何优化视频标题和描述
短视频 SEO 优化能给企业带来什么好处_短视频 SEO 如何优化视频标题和描述 在当今数字化时代,短视频平台已经成为了企业营销和品牌推广的重要渠道。短视频的传播范围和影响力远不止于视频内容本身,背后的搜索引擎优化(SEO)策略同…...