python机器学习——决策树
决策树
# 模块导入
from sklearn.tree import ExtraTreeRegressor as ETR, DecisionTreeRegressor as DTR
ExtraTreeRegressor和DecisionTreeRegressor是scikit-learn库中的两种回归模型,用于拟合和预测连续型目标变量。
决策树是一种基于树结构的机器学习算法,用于解决分类和回归问题。它通过对数据的特征进行一系列判断和分支,逐步将数据集划分成不同的子集,最终得到一个基于特征的树形结构,用于预测新数据的类别或数值。
决策树算法的核心思想是在每个节点上选择最有价值的特征进行划分,使得子节点间的纯度尽可能高,同时保持树的简单性。在分类任务中,纯度通常指子节点中样本所属类别的比例;在回归任务中,纯度通常指子节点中样本目标变量的方差或标准差。
决策树在处理离散型和连续型特征时有不同的处理方式,其中最常见的方法是使用信息增益、信息增益比、基尼指数等指标进行节点划分。对于过拟合问题,可以通过剪枝、随机森林等方法进行处理。
两种树对比
DecisionTreeClassifier和DecisionTreeRegressor是决策树算法的两个变体,用于解决分类和回归问题。它们的主要区别在于所解决的问题类型和输出类型。
- DecisionTreeClassifier(决策树分类器):
- 问题类型:DecisionTreeClassifier用于解决分类问题,即将样本分为不同的类别。
- 输出类型:其输出是一个离散的类别标签,表示样本属于哪个类别。
- DecisionTreeRegressor(决策树回归器):
- 问题类型:DecisionTreeRegressor用于解决回归问题,即预测连续目标变量的值。
- 输出类型:其输出是一个连续的数值,表示预测的目标变量的值。
除了上述区别,DecisionTreeClassifier和DecisionTreeRegressor在算法实现上也有一些略微的差异:
- 分割准则:分类树通常使用基尼系数(Gini index)或熵(entropy)来度量特征的重要性,以选择最佳的分割点。而回归树通常使用平方误差(mean squared error)作为分割准则。
- 剪枝策略:为了防止过拟合,决策树通常需要进行剪枝。对于分类树来说,常用的剪枝策略有预剪枝和后剪枝。对于回归树来说,通常采用贪心策略进行自底向上的剪枝。
总结起来,DecisionTreeClassifier和DecisionTreeRegressor主要区别在于解决的问题类型和输出类型。前者适用于分类问题,输出离散类别标签;后者适用于回归问题,输出连续数值。
决策树中的专业名词
- 节点(Node):表示决策树上的一个数据处理单元,包含一个或多个子节点和一个父节点。
- 根节点(Root Node):表示决策树的起始节点,没有父节点。
- 叶节点(Leaf Node):表示决策树的终止节点,没有子节点。
- 内部节点(Internal Node):表示除根节点和叶节点外的其他节点,拥有一个或多个子节点。
- 特征(Feature):表示决策树划分节点时使用的属性或特征值,可以是离散型或连续型。
- 阈值(Threshold):表示用于划分连续型特征的阈值,通常是根据特征值的中位数或平均值确定的。
- 深度(Depth):表示决策树从根节点到某个节点的路径长度,根节点的深度为0。
- 路径(Path):表示从根节点到叶节点的一条路径,由一系列节点和边组成。
- 分支(Branch):表示从一个节点到其子节点的一条边。
- 剪枝(Pruning):表示对决策树进行修剪,以防止模型过拟合。常用的剪枝方法有预剪枝(
Pre-Pruning)和后剪枝(Post-Pruning)。 - 信息增益(Information Gain):表示在某个节点上划分前后数据集的信息熵差异,用于选择最佳划分特征。
- 基尼指数(
GiniIndex):表示在某个节点上划分前后数据集的基尼系数差异,用于选择最佳划分特征。
DecisionTreeRegressor
导入模块
from sklearn.tree import DecisionTreeRegressor, ExtraTreeRegressor
创建模型对象
dtr = DecisionTreeRegressor(max_depth=None, criterion='mse', splitter='best', random_state=None)
参数说明
max_depth:决策树的最大深度,默认为None,表示不限制深度。criterion:节点划分的标准,可选’mse’(均方误差)或’mae’(平均绝对误差),默认为’mse’。splitter:节点划分的策略,可选’best’(最优划分)或’random’(随机划分),默认为’best’。random_state:随机种子,用于重复实验。
拟合模型
dtr.fit(X,y)
X是一个二维数组或者数据框,其中每一行代表一个样本,每一列表示一个特征
y是目标变量向量,是一个一维数组或列表,其中每个元素表示一个样本的目标值
预测
y_pred_dtr = dtr.predict(X_test)
其中X_test是我们待预测的新特征矩阵
示例代码
数据分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
train_test_split(X, y, test_size=0.2, random_state=42) 是一个常用的函数调用,用于将数据集 X 和对应的目标变量 y 划分为训练集和测试集。具体解释如下:
X:表示样本特征矩阵,其中每一行代表一个样本,每一列代表一个特征。y:表示目标变量(或标签),是与样本特征矩阵X对应的目标值。test_size=0.2:表示将数据集划分为训练集和测试集时,测试集的大小为全部数据的 20%。random_state=42:表示设置随机数种子为 42,用于控制随机划分的重现性。
该函数会返回划分后的训练集和测试集,以便后续在机器学习模型中使用。具体返回结果会有以下四个元组:
X_train:表示划分后的训练集样本特征。X_test:表示划分后的测试集样本特征。y_train:表示划分后的训练集目标变量。y_test:表示划分后的测试集目标变量。
通过这个函数可以确保训练集和测试集的划分是随机的,并且可以重复该划分过程。同时,通过指定随机数种子,可以使得每次运行时得到相同的划分结果,以保持实验的可重现性。
具体代码
from sklearn.datasets import load_diabetes # 导入糖尿病数据集
from sklearn.model_selection import train_test_split # 将数据划分为训练集和测试集
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error # 计算均方误差# 加载糖尿病数据集
diabetes = load_diabetes()
X, y = diabetes.data, diabetes.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# X_train, X_test, y_train, y_test 分别是 训练集样本特征矩阵 测试集样本特征矩阵 训练集目标向量 测试集目标向量# 创建决策树回归模型dtr = DecisionTreeRegressor(max_depth=5, random_state=42)# 训练模型dtr.fit(X_train, y_train)# 预测测试集y_pred_dtr = dtr.predict(X_test)# 评估模型性能mse = mean_squared_error(y_test, y_pred_dtr)
print("均方误差 (MSE):", mse) # 3600 均方误差较大,需要改进模型
均方误差
均方误差(Mean Squared Error,MSE)是一种常用的回归模型评估指标。它用于衡量模型预测结果与真实值之间的差异程度,具体计算方式如下:
MSE = (1/n) * Σ(yᵢ - ŷᵢ)²
其中,n 是样本数量,yᵢ 是真实值,ŷᵢ 是模型的预测值。
MSE 的计算方法是将每个样本的预测误差平方后求和,再除以样本数量。因为误差被平方,所以 MSE 比较敏感,较大的误差会被放大,而较小的误差则相对较小。
对于 MSE 来说,**数值越小表示模型的预测结果与真实值之间的差异越小,模型的拟合能力越好。**当 **MSE 为0时,表示模型完全拟合了训练数据,但这可能意味着模型过于复杂,存在过拟合的风险。**通常情况下,我们希望选择一个使得 MSE 较小且在训练集和测试集上表现一致的模型。
需要注意的是,MSE 的值与数据集的单位相关,因此无法直接进行跨数据集的比较。在评估模型时,可以将 MSE 与其他模型的 MSE 进行比较,或者将其与问题的背景和要求相结合来进行评估,例如与实际误差的大小进行比较或与领域专家的知识相结合。
模型优化
要修改决策树的参数、进行剪枝以及使用基尼系数进行划分,使得模型更加优化,通常需要使用机器学习库来实现
首先,我们导入所需的库和数据集:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
加载鸢尾花数据集并将其分为训练集和测试集:
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
创建决策树分类器对象,并设置参数:
clf = DecisionTreeClassifier(criterion='gini', max_depth=None, random_state=42)
其中,criterion参数设置了用于划分的准则,这里选择了基尼系数(gini index)。max_depth参数表示树的最大深度,设置为None表示不限制深度。random_state参数用于确定每次运行时的随机性,以便结果可重复。
拟合(训练)决策树分类器:
clf.fit(X_train, y_train)
使用训练好的模型进行预测:
y_pred = clf.predict(X_test)
计算预测的准确率:
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
接下来,我们可以进行剪枝。
首先,我们可以使用预剪枝设置max_depth参数限制树的最大深度:
clf_pruned = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=42)
然后,重复之前的拟合、预测和准确率计算过程:
clf_pruned.fit(X_train, y_train)
y_pred_pruned = clf_pruned.predict(X_test)
accuracy_pruned = accuracy_score(y_test, y_pred_pruned)
print("剪枝后的准确率:", accuracy_pruned)
最后,基于基尼系数的划分是决策树算法的默认选择,所以不需要额外的代码来设置它。
相关文章:

python机器学习——决策树
决策树 # 模块导入 from sklearn.tree import ExtraTreeRegressor as ETR, DecisionTreeRegressor as DTRExtraTreeRegressor和DecisionTreeRegressor是scikit-learn库中的两种回归模型,用于拟合和预测连续型目标变量。 决策树是一种基于树结构的机器学习算法&…...
) 和 __attribute__((__section__(“*“ “*“)))的使用)
__attribute__((__used__)) 和 __attribute__((__section__(“*“ “*“)))的使用
见:haproxy代码 C语言注册函数和调用函数,便于模块化开发和编程。 #include <stdio.h>#ifdef __APPLE__ #define HA_SECTION(s) __attribute__((__section__("__DATA, " s))) #define HA_SECTION_START(s) __asm("…...
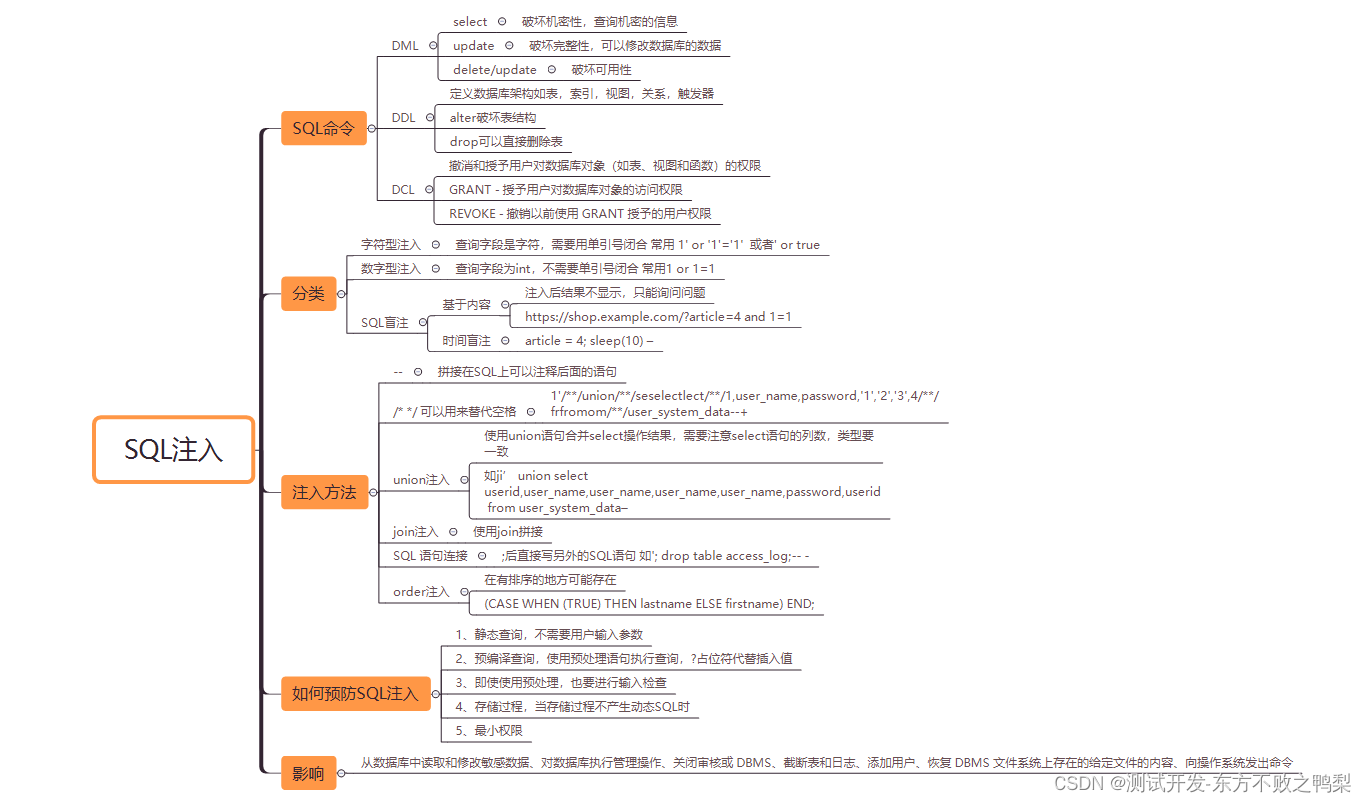
webgoat-(A1)SQL Injection
SQL Injection (intro) SQL 命令主要分为三类: 数据操作语言 (DML)DML 语句可用于请求记录 (SELECT)、添加记录 (INSERT)、删除记录 (DELETE) 和修改现有记录 ÿ…...
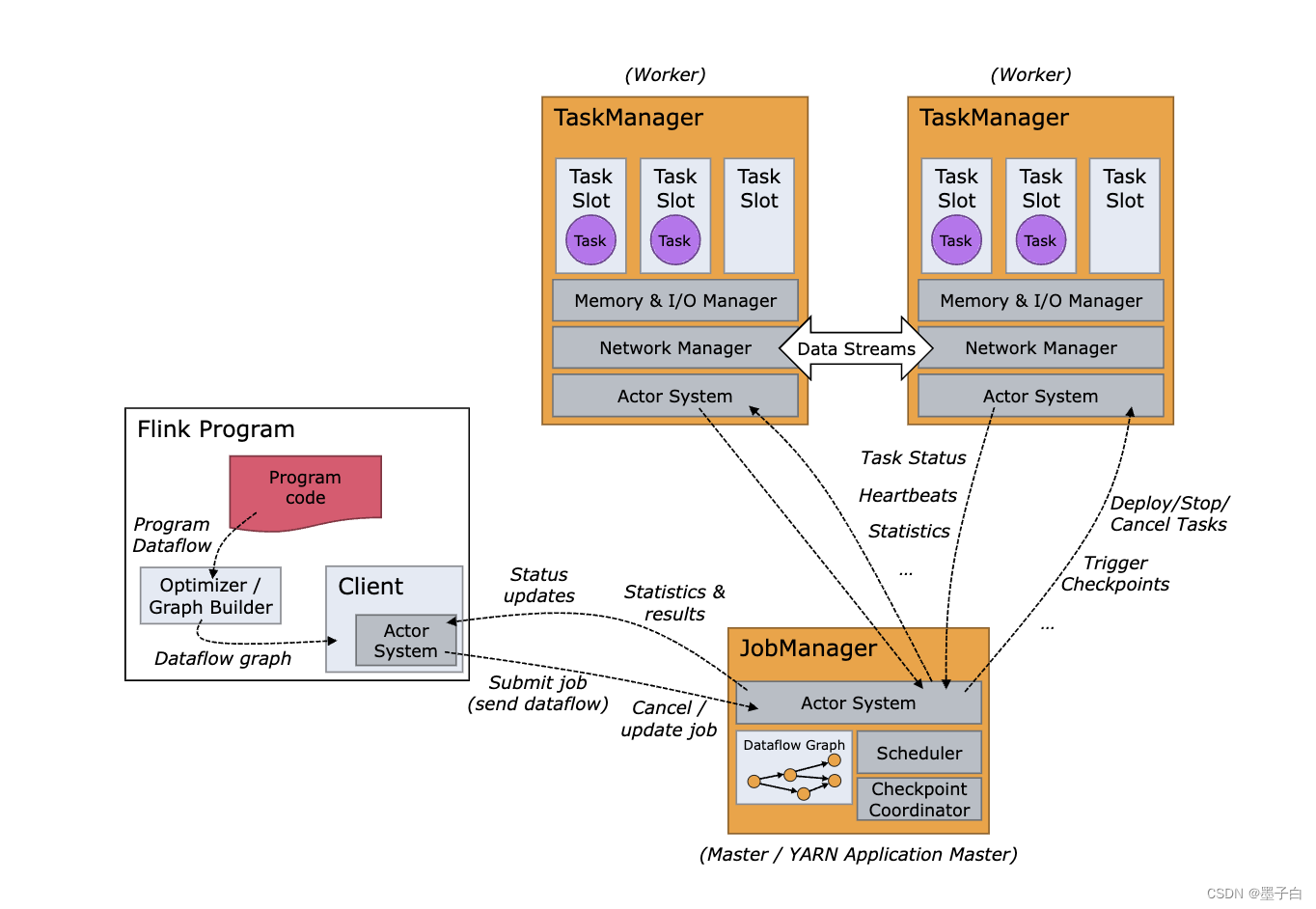
Flink的API分层、架构与组件原理、并行度、任务执行计划
Flink的API分层 Apache Flink的API分为四个层次,每个层次都提供不同的抽象和功能,以满足不同场景下的数据处理需求。下面是这四个层次的具体介绍: CEP API:Flink API 最底层的抽象为有状态实时流处理。其抽象实现是Process Functi…...

Transformer:开源机器学习项目,上千种预训练模型 | 开源日报 No.66
huggingface/transformers Stars: 113.5k License: Apache-2.0 这个项目是一个名为 Transformers 的开源机器学习项目,它提供了数千种预训练模型,用于在文本、视觉和音频等不同领域执行任务。该项目主要功能包括: 文本处理:支持…...
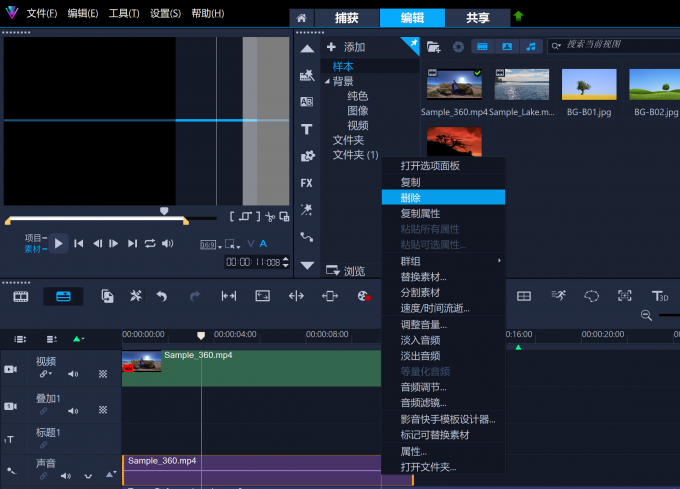
Corel VideoStudio 会声会影2024剪辑中间的视频怎么删 剪辑中音乐太长怎么办
我很喜欢视频剪辑软件Corel VideoStudio 会声会影2024,因为它使用起来很有趣。它很容易使用,但仍然给你很多功能和力量。视频剪辑软件Corel VideoStudio 会声会影2023让我与世界分享我的想法!“这个产品的功能非常多,我几乎没有触…...

数据结构初阶---复杂度的OJ例题
复杂度的OJ例题 一、消失的数字1.思路一2.思路二3.思路三 二、旋转数组1.思路一2.思路二3.思路三 一、消失的数字 数组nums包含从0到n的所有整数,但其中缺了一个。请编写代码找出那个缺失的整数。你有办法在O(N)时间内完成吗? 链接:力扣&…...

Prometheus|云原生|grafana的admin用户密码重置备忘记录
很久很久以前部署的一个Prometheus套装里的grafana密码给忘记了,回忆总是很痛苦,因此还是在这里简单的记录一下,下次就不需要满世界反翻找了。 一, 改库重置密码为admin grafana密码存放在哪里的? 必须说明一下&am…...

[hive]中的字段的数据类型有哪些
Hive中提供了多种数据类型用于定义表的字段。以下是Hive中常见的数据类型: 布尔类型(Boolean):用于表示true或false。 字符串类型(String):用于表示文本字符串。 整数类型(Intege…...
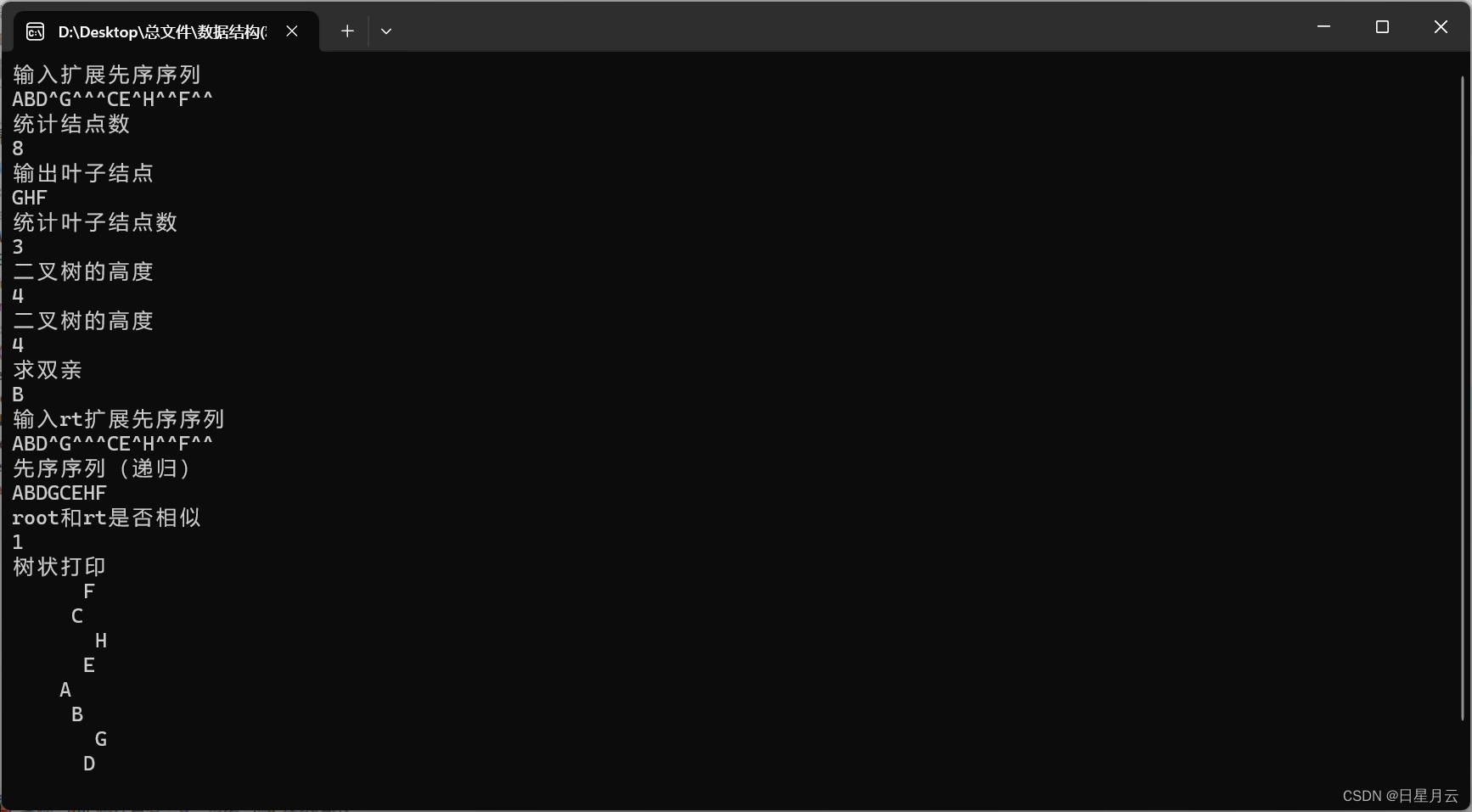
第六章 树【数据结构和算法】【精致版】
第六章 树【数据结构和算法】【精致版】 前言版权第六章 树6.1 应用实例6.2 树的概念6.2.1树的定义与表示6.2.2 树的基本术语6.2.3树的抽象数据类型定义 6.3 二叉树6.3.1二叉树的定义6.3.2 二叉树的性质6.3.3 二叉树的存储 6.4 二叉树的遍历6.4.1 二叉树的遍历及递归实现**1-二…...
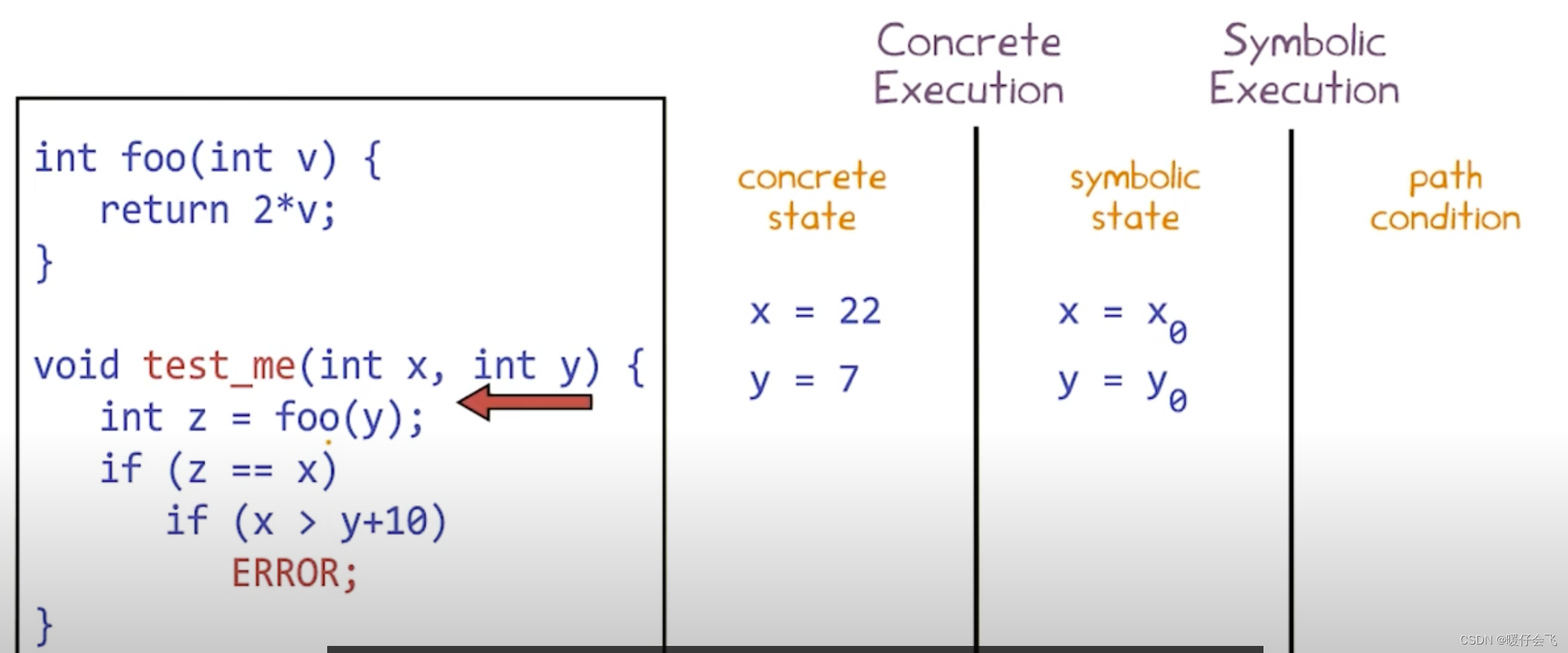
第九章:Dynamic Symbolic Execution
文章目录 Dynamic Symbolic Executionoverviewmotivationdynamic symbolic execution常用的其他技术对比Random Testingsymbolic executionCombined static and symbolic - Dynamic Execution (DSE)step1: 初始化两个具体的值 x,ystep2: 根据定义得出 z 的 concrete value 和 s…...
在搜索引擎中屏蔽csdn
csdn是一个很好的技术博客,里面信息很丰富,我也喜欢在csdn上做技术笔记。 但是CSDN体量太大,文章质量良莠不齐。当在搜索引擎搜索技术问题时,搜索结果中CSDN的内容占比太多,导致难以从其他优秀的博客平台中获取信息。因…...
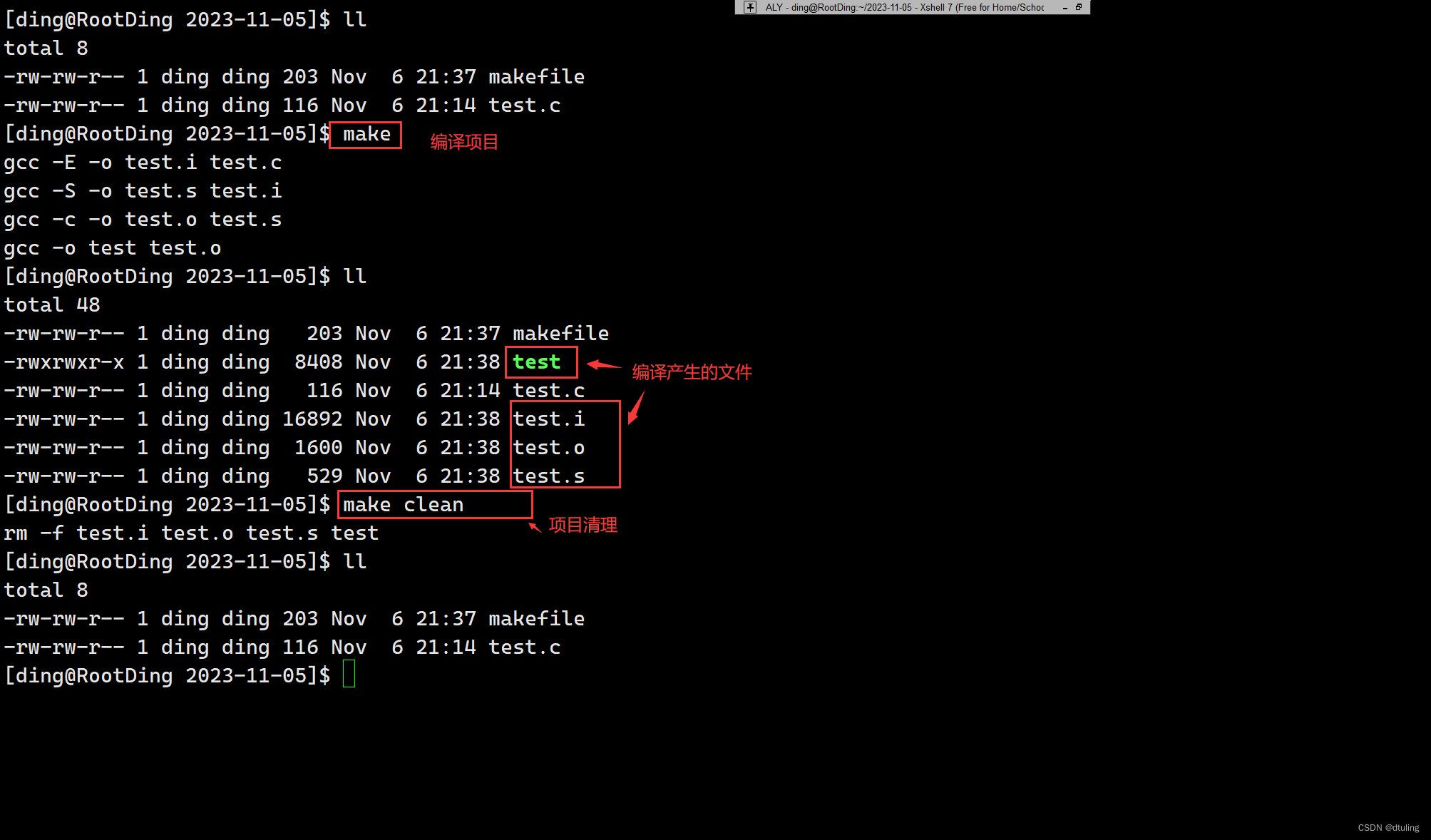
Linux开发工具的使用(vim、gcc/g++ 、make/makefile)
文章目录 一 :vim1:vim基本概念2:vim的常用三种模式3:vim三种模式的相互转换4:vim命令模式下的命令集- 移动光标-删除文字-剪切/删除-复制-替换-撤销和恢复-跳转至指定行 5:vim底行模式下的命令集 二:gcc/g1:gcc/g的作用2:gcc/g的语法3:预处理4:编译5:汇编6:链接7:函…...

MySQL(10):创建和管理表
基础知识 在 MySQL 中,一个完整的数据存储过程总共有 4 步,分别是:创建数据库、确认字段、创建数据表、插入数据。 要先创建一个数据库,而不是直接创建数据表:从系统架构的层次上看,MySQL 数据库系统从大到…...

Python赋值给另一个变量且不改变原变量
Python赋值给另一个变量且不改变原变量 在Python中,如果你想将一个变量的值赋给另一个变量,同时保持原变量不变,你可以使用复制(copy)而不是引用(reference)。Python中的变量通常是通过引用&…...
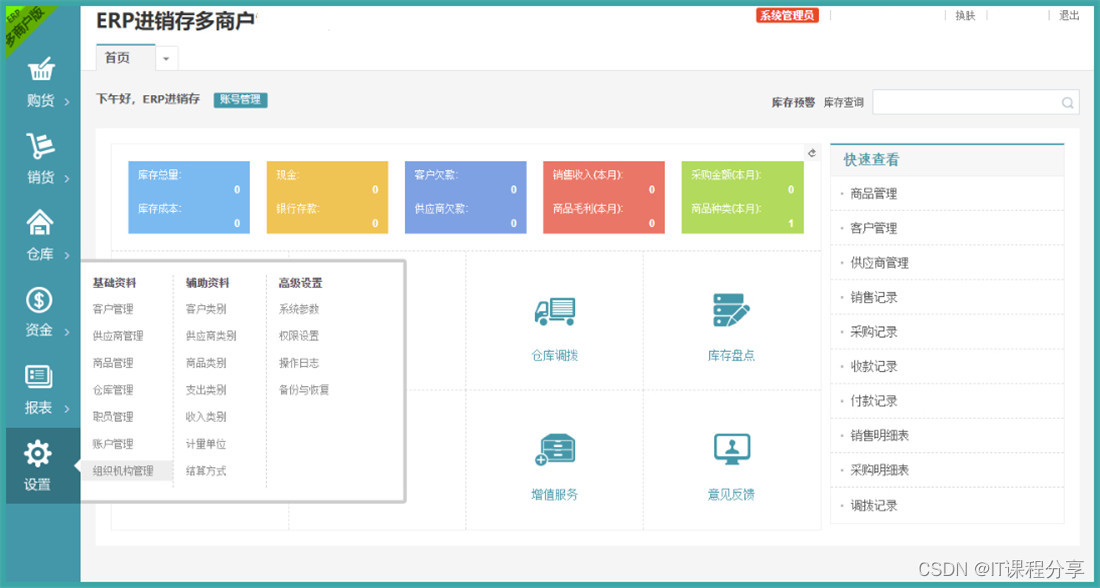
PHP进销存ERP系统源码
PHP进销存ERP系统源码 系统介绍: 扫描入库库存预警仓库管理商品管理供应商管理。 1、电脑端手机端,手机实时共享,手机端一目了然。 2、多商户Saas营销版 无限开商户,用户前端自行注册,后台管理员审核开通 3、管理…...
)
npm i 报错:Cannot read properties of null (reading ‘refs‘)
问题: 旧项目要更改东西,重新部署上线的时候,发现页面显示有异常。当时在开发环境是没有问题的。后经排查是一个引入swiper的页面报错了,只要注释掉swiper插件,就没问题了,但这肯定是不行的。 原因: npm和…...
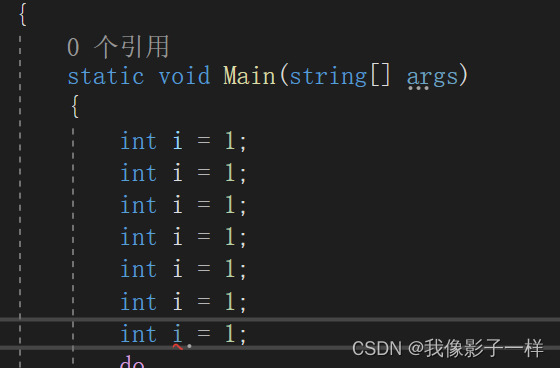
C#学习中关于Visual Studio中ctrl+D快捷键(快速复制当前行)失效的解决办法
1、进入VisualStudio主界面点击工具——>再点击选项 2、进入选项界面后点击环境——>再点击键盘,我们可用看到右边的界面的映射方案是VisualC#2005 3、 最后点击下拉框,选择默认值,点击之后确定即可恢复ctrlD的快捷键功能 4、此时可以正…...

银河E8,吉利版Model 3:5米大车身、45寸大屏、首批8295座舱芯
作者 | Amy 编辑 | 德新 吉利银河E8在曝光后多次引爆热搜,李书福更是赞誉有加,称其为「买了就直接享受」。这款备受瞩目的车型于 10月30日晚首次亮相。 虽然新车外观在今年上海车展上早已曝光,但这次的发布会却带来了不少惊喜。新车架构以及…...

技术分享 | 被测项目需求你理解到位了么?
需求分析是开始测试工作的第一步,产品会先产出一个需求文档,然后会组织需求宣讲,在需求宣讲中分析需求中是否存在问题,然后宣讲结束后,通过需求文档分析测试点并且预估排期。所以对于需求的理解非常重要。 需求文档 …...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

深度解析:JetBrains IDE试用期重置机制的技术实现
深度解析:JetBrains IDE试用期重置机制的技术实现 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 在软件开发工作流中,JetBrains IDE试用期管理是一个常见的技术挑战,尤其是在多…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...

终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题
终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也经历过这样的…...

API渗透测试:契约驱动的协议/语义/架构三层攻防
1. 为什么“API渗透测试”不是Web渗透的简单延伸?很多人刚接触API安全时,第一反应是:“不就是把Burp Suite抓到的HTTP请求换个参数发一发?跟测网页表单差不多。”我2018年第一次接手某金融类SaaS平台的API安全评估时,也…...

概率论:常见分布的期望与方差、中心极限定理、切比雪夫不等式
目录 一、0、1分布 二、二项分布 三、泊松分布 四、均匀分布 五、指数分布 六、正态分布 七、中心极限定理及其应用 (1)中心极限定理的定义 (2)使用示例 八、切比雪夫不等式 (1)切比雪夫不…...

终极艾尔登法环存档迁移指南:3分钟学会角色无损转移
终极艾尔登法环存档迁移指南:3分钟学会角色无损转移 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档迁移而烦恼吗?当游戏版本更新后,你辛辛苦苦培…...

FModel完整部署指南:UE5资源提取与逆向解析实战
1. 为什么FModel不是“另一个UE资源查看器”,而是虚幻项目逆向分析的起点FModel虚幻引擎资源提取工具完整部署指南——这标题里藏着三个被多数人忽略的关键信号:“FModel”不是泛指,“虚幻引擎”特指UE4/UE5原生资产体系,“完整部…...

思源宋体完全免费商用指南:7种字重中文开源字体终极教程
思源宋体完全免费商用指南:7种字重中文开源字体终极教程 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 想要为你的中文设计项目找到一款既专业又完全免费的高质量字体吗&a…...