nn.embedding函数详解(pytorch)
提示:文章附有源码!!!
文章目录
- 前言
- 一、nn.embedding函数解释
- 二、nn.embedding函数使用方法
- 四、模型训练与预测的权重变化探讨
前言
最近发现prompt工程(如sam模型),也有transform的detr模型等都使用了nn.Embedding函数,对points、boxes或learn query进行编码或解码。因此,我想写一篇文章作为记录,本想简单对其 介绍,但写着写着就想把所有与它相关东西作为记录。本文章探讨了nn.Embedding参数、使用方法、模型训练与预测的变化,并附有列子源码作为支撑 ,呈现一个较为完善的理解内容。
一、nn.embedding函数解释
Embedding实际是一个索引表或查找表,它是符合随机初始化生成的正太分布的表,将输入向量化,其结构如下:
nn.Embedding(num_embeddings, embedding_dim)
第1个参数 num_embeddings 就是生成num_embeddings个嵌入向量。
第2个参数 embedding_dim 就是嵌入向量的维度,即用embedding_dim值的维数来表示一个基本单位。
当然,该函数还有很多其它参数,解释如下:
参数源码注释如下:
num_embeddings (int): size of the dictionary of embeddings
embedding_dim (int): the size of each embedding vector
padding_idx (int, optional): If specified, the entries at :attr:`padding_idx` do not contribute to the gradient;therefore, the embedding vector at :attr:`padding_idx` is not updated during training,i.e. it remains as a fixed "pad". For a newly constructed Embedding,the embedding vector at :attr:`padding_idx` will default to all zeros,but can be updated to another value to be used as the padding vector.
max_norm (float, optional): If given, each embedding vector with norm larger than :attr:`max_norm`is renormalized to have norm :attr:`max_norm`.
norm_type (float, optional): The p of the p-norm to compute for the :attr:`max_norm` option. Default ``2``.
scale_grad_by_freq (boolean, optional): If given, this will scale gradients by the inverse of frequency ofthe words in the mini-batch. Default ``False``.
sparse (bool, optional): If ``True``, gradient w.r.t. :attr:`weight` matrix will be a sparse tensor.See Notes for more details regarding sparse gradients.参数中文解释:
num_embeddings (python:int) – 词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999)
embedding_dim (python:int) – 嵌入向量的维度,即用多少维来表示一个符号。
padding_idx (python:int, optional) – 填充id,比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字,这样,网络在遇到填充id时,就不会计算其与其它符号的相关性。(初始化为0)
max_norm (python:float, optional) – 最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化。
norm_type (python:float, optional) – 指定利用什么范数计算,并用于对比max_norm,默认为2范数。
scale_grad_by_freq (boolean, optional) – 根据单词在mini-batch中出现的频率,对梯度进行放缩。默认为False.
sparse (bool, optional) – 若为True,则与权重矩阵相关的梯度转变为稀疏张量
注:该函数服从正太分布,该函数可参与训练,我将在后面做解释。
二、nn.embedding函数使用方法
该函数实际是对词的编码,假如你有2句话,每句话有四个词,那么你想对每个词使用6个维度表达,其代码如下:
import torch.nn as nn
import torch
if __name__ == '__main__':embedding = nn.Embedding(100, 6) # 我设置100个索引,每个使用6个维度表达。input = torch.LongTensor([[1, 2, 4, 5],[4, 3, 2, 3]]) # a batch of 2 samples of 4 indices eache = embedding(input)print('输出尺寸', e.shape)print('输出值:\n',e)weights=embedding.weightprint('embed权重输出值:\n', weights[:6])输出结果:
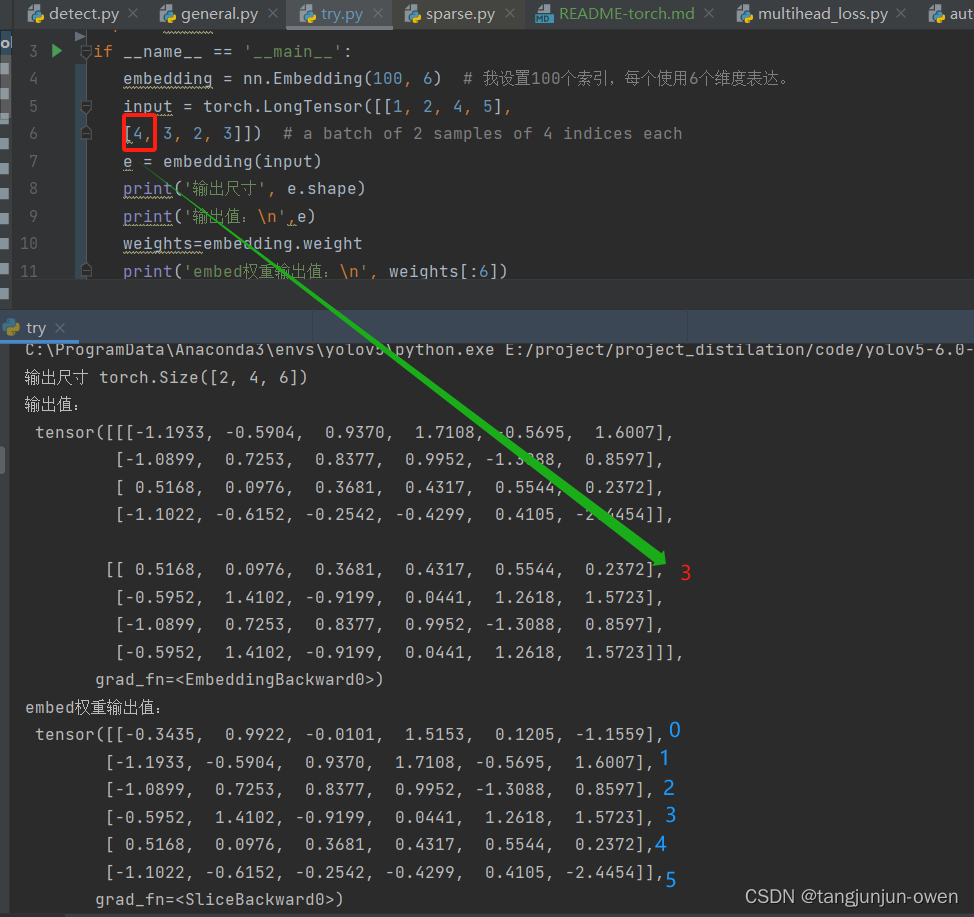
从图上可看出,输入编码是通过索引查找已编号embedding的权重,并将其赋值替换表达。换句话说,nn.Embedding(100, 6)生成正太分布100行6列数据,行必须超过输入句子词语长度,而句子每个词使用整数编码成索引,该索引对应之前embedding行寻找,得到对应行
维度,即可转为表达该词的特征向量。
四、模型训练与预测的权重变化探讨
之前已说过nn.Embedding()在训练过程中会发生变化,但在预测中将不在变化,应该是被训练成最佳词的向量维度表达,也就是说每个词唯一对应索引,被Embedding特征表达训练成最佳特征表达,也可说训练词索引特征表达固定。为探讨此过程,我写了对应示列,如下:
import torch
from torch.nn import Embeddingclass Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.emb = Embedding(5, 3)def forward(self,vec):input = torch.tensor([0, 1, 2, 3, 4])emb_vec1 = self.emb(input)# print(emb_vec1) ### 输出对同一组词汇的编码output = torch.einsum('ik, kj -> ij', emb_vec1, vec)return output
def simple_train():model = Model()vec = torch.randn((3, 1))label = torch.Tensor(5, 1).fill_(3)loss_fun = torch.nn.MSELoss()opt = torch.optim.SGD(model.parameters(), lr=0.015)print('初始化emebding参数权重:\n',model.emb.weight)for iter_num in range(100):output = model(vec)loss = loss_fun(output, label)opt.zero_grad()loss.backward(retain_graph=True)opt.step()# print('第{}次迭代emebding参数权重{}:\n'.format(iter_num, model.emb.weight))print('训练后emebding参数权重:\n',model.emb.weight)torch.save(model.state_dict(),'./embeding.pth')return modeldef simple_test():model = Model()ckpt = torch.load('./embeding.pth')model.load_state_dict(ckpt)model=model.eval()vec = torch.randn((3, 1))print('加载emebding参数权重:\n', model.emb.weight)for iter_num in range(100):output = model(vec)print('n次预测后emebding参数权重:\n', model.emb.weight)if __name__ == '__main__':simple_train() # 训练与保存权重simple_test()
结果如下:
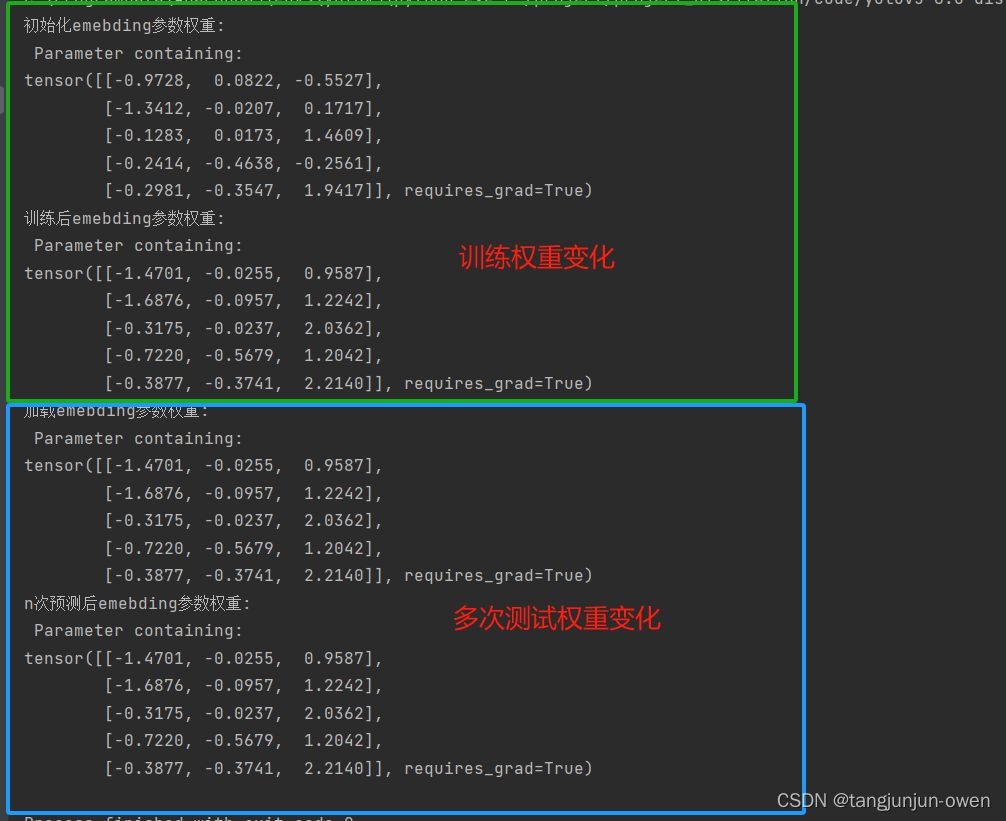
训练代码参考博客:点击这里
相关文章:
nn.embedding函数详解(pytorch)
提示:文章附有源码!!! 文章目录 前言一、nn.embedding函数解释二、nn.embedding函数使用方法四、模型训练与预测的权重变化探讨 前言 最近发现prompt工程(如sam模型),也有transform的detr模型等都使用了nn.Embedding函…...

gitee.com[0: xxx.xx.xxx.xx]: errno=Unknown error
git在提交或拉取代码的时候,遇到以下报错信息: Unable to connect to gitee.com[0: xxx.xx.xxx.xx]: errnoUnknown error 解决问题步骤: 1、找到自己的电脑上的git用户配置文件 文件位置位于:C:\Users\用户名\.gitconfig 比如我…...

bug: https://aip.baidubce.com/oauth/2.0/token报错blocked by CORS policy
还是跟以前一样,我们先看报错点:(注意小编这里是H5解决跨域的,不过解决跨域的原理都差不多) Access to XMLHttpRequest at https://aip.baidubce.com/oauth/2.0/token from origin http://localhost:8000 has been blo…...
简单工厂VS工厂方法
工厂方法模式–制造细节无需知 前面介绍过简单工厂模式,简单工厂模式只是最基本的创建实例相关的设计模式。在真实情况下,有更多复杂的情况需要处理。简单工厂生成实例的类,知道了太多的细节,这就导致这个类很容易出现难维护、灵…...

使用VSCODE链接Anaconda
打代码还是在VSCODE里得劲 所以得想个办法在VSCODE里运行py文件 一开始在插件商店寻找插件 但是没有发现什么有效果的 幸运的是VSCODE支持自己选择Python的编译器 打开VSCODE 按住CtrlShiftP 输入Select Interpreter 如果电脑已经安装上了Python的环境 VSCODE会默认选择普通…...
Mysql数据库 9.SQL语言 查询语句 连接查询、子查询
连接查询 通过查询多张表,用连接查询进行多表联合查询 关键字:inner join 内连接 left join 左连接 right join 右连接 数据准备 创建新的数据库:create database 数据库名; create database db_test2; 使用数据库:use 数据…...
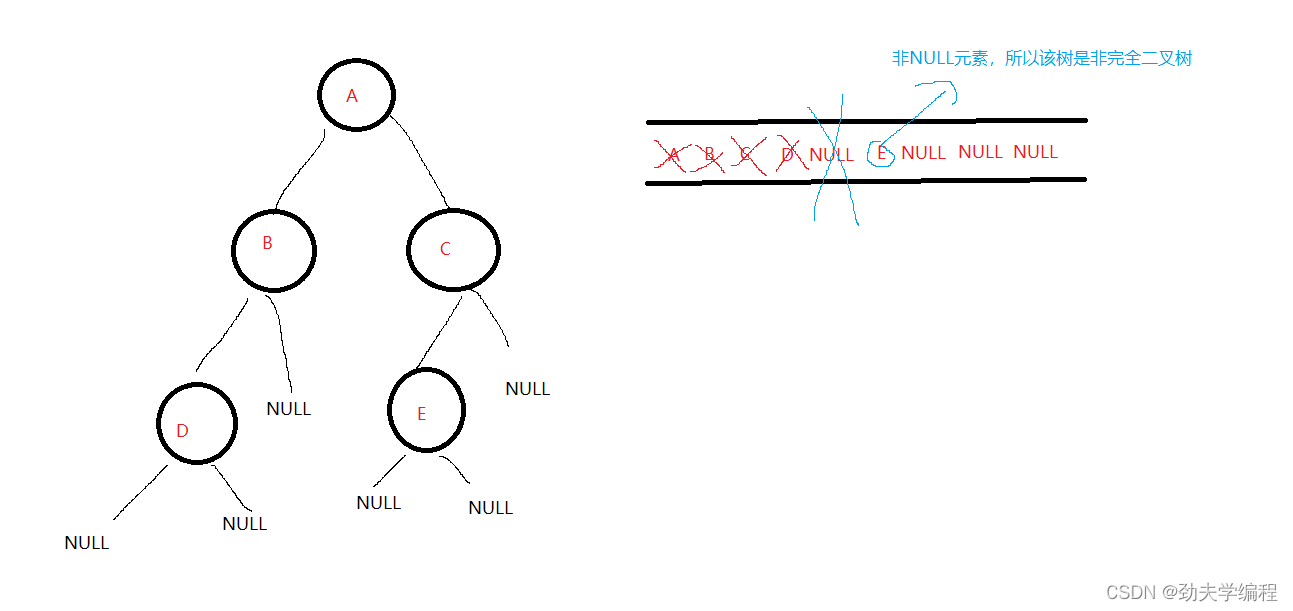
二叉树按二叉链表形式存储,试编写一个判别给定二叉树是否是完全二叉树的算法
完全二叉树:就是每层横着划过去是连起来的,中间不会断开 比如下面的左图就是完全二叉树 再比如下面的右图就是非完全二叉树 那我们可以采用层序遍历的方法,借助一个辅助队列 当辅助队列不空的时候,出队头元素,入队头…...
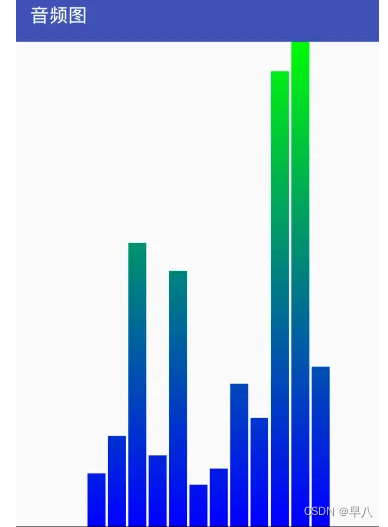
Android自定义控件
目录 Android自定义控件一、对现有控件进行扩展二、创建复合控件1 定义属性2 组合控件3 引用UI模板 三、重写View来实现全新控件1 弧线展示图1.1 具体步骤: 2 音频条形图2.1 具体步骤 四、补充:自定义ViewGroup Android自定义控件 ref: Android自定义控件…...

Java 中的 Cloneable 接口和深拷贝
引言: 在 Java 中,深拷贝是一种常见的需求,它可以创建一个对象的完全独立副本。Cloneable 接口提供了一种标记机制,用于指示一个类实例可以被复制。本文将详细介绍 Java 中的 Cloneable 接口和深拷贝的相关知识࿰…...
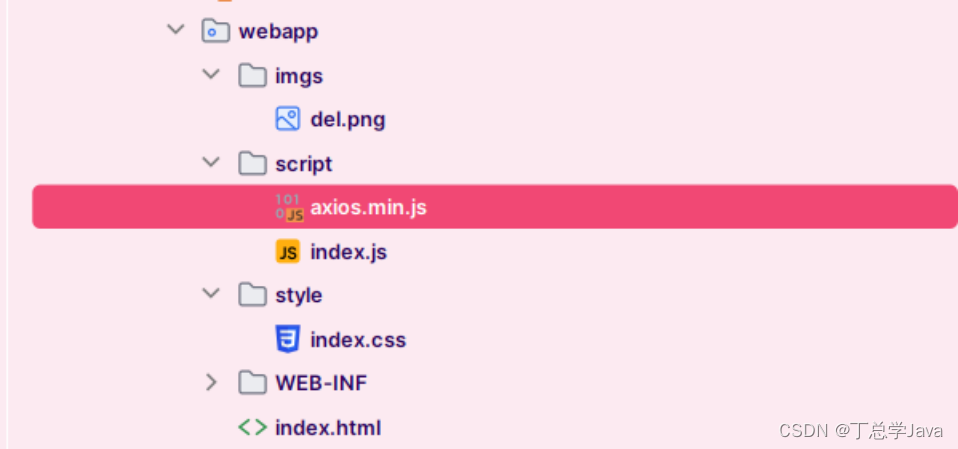
项目实战:通过axios加载水果库存系统的首页数据
1、创建静态页面 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><link rel"stylesheet" href"style/index.css"><script src"script/axios.mi…...
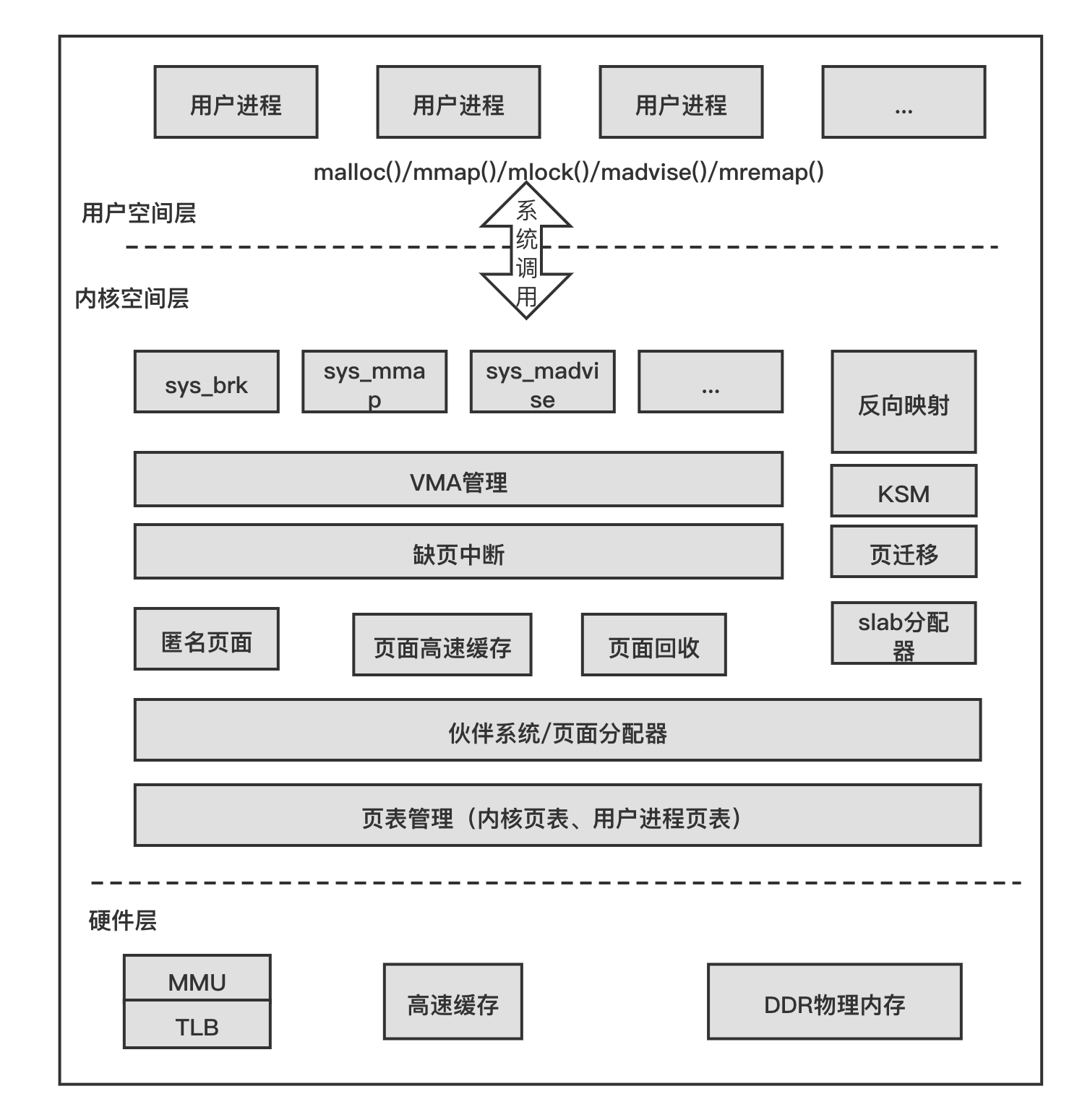
RK3568平台 内存的基本概念
一.Linux的Page Cache page cache,又称pcache,其中文名称为页高速缓冲存储器,简称页高缓。page cache的大小为一页,通常为4K。在linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访…...
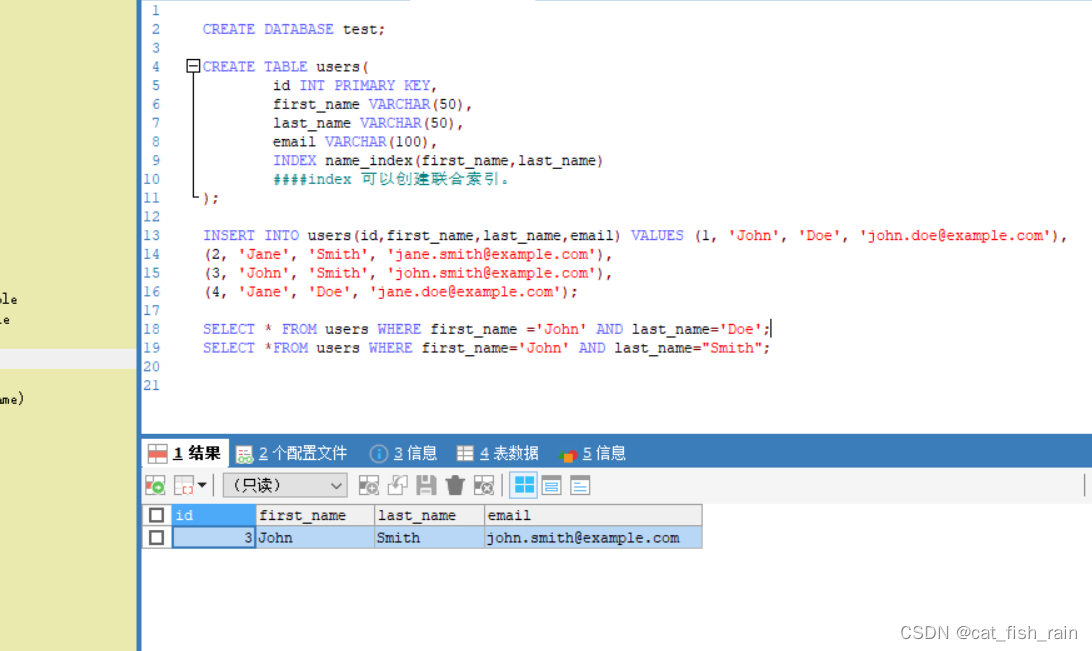
mysql联合索引和最左匹配问题。
1引言: 如果频繁地使⽤相同的⼏个字段查询,就可以考虑建⽴这⼏个字段的联合索引来提⾼查询效率。⽐如对 于联合索引 test_col1_col2_col3,实际建⽴了 (col1)、(col1, col2)、(col, col2, col3) 三个索引。联合 索引的主要优势是减少结果集数量…...

全球发布|首个AI视角下的生态系统架构解读—《生态系统架构--人工智能时代从业者的新思维》重磅亮相!
点击可免费注册下载 👇 人工智能时代的企业架构师必读系列 《生态系统架构--人工智能时代从业者的新思维》 Philip Tetlow、Neal Fishman、Paul Homan、Rahul著 The Open Group Press 2023年11月出版 这本书可以很好地帮助全球架构师使用人工智能来构建、开发和…...

解决torch.hub.load加载网络模型异常
1 torch.hub.load 加载网络模型错误 通过网络使用torch.hub.load加载模型代码如下: self.model torch.hub.load("facebookresearch/dinov2", dinov2_vits14, sourcegithub).to(self.device) 运行网上的项目,经常会卡住或者超时,…...
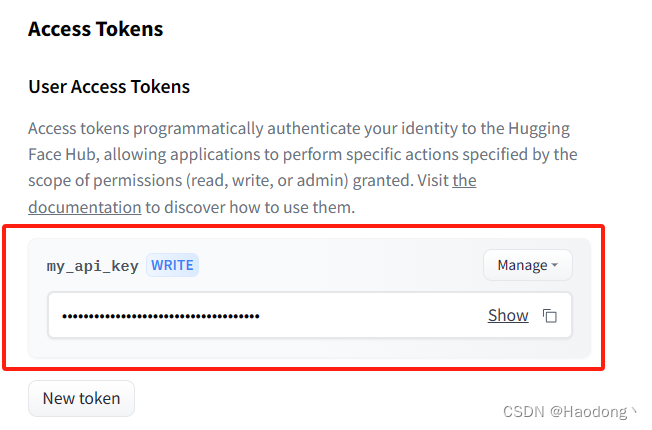
如何获取HuggingFace的Access Token;如何获取HuggingFace的API Key
Access Token通过编程方式向 HuggingFace 验证您的身份,允许应用程序执行由授予的权限范围(读取、写入或管理)指定的特定操作。您可以通过以下步骤获取: 1.首先,你需要注册一个 Hugging Face 账号。如果你已经有了账号…...

How to resolve jre-openjdk and jre-openjdk-headless conflicts?
2023-11-05 Archlinux 执行 pacman -Syu 显示 failed to prepare transaction;jre-openjdk and jre-openjdk-headless conflicts 解决 archlinux sudo pacman -Sy jdk-openjdk...

setTimeout和setImmediate以及process.nextTick的区别?
目录 前言 setTimeout 特性和用法 setImmediate 特性和用法 process.nextTick 特性和用法 区别和示例 总结 在Node.js中,setTimeout、setImmediate和process.nextTick是用于调度异步操作的三种不同机制。它们之间的区别在于事件循环中的执行顺序和优先级。…...

read 方法为什么返回 int 类型
在Java的输入流(InputStream)中,read方法返回int类型的值的原因是为了提供更多的信息和灵活性。虽然这可能看起来有些不直观,但有一些合理的考虑和用途,主要包括以下几点: EOF标志:read方法返回…...

在二维矩阵/数组中查找元素 Leetcode74, Leetcode240
这一类题型中二维数组的元素取值有序变化,因此可以用二分查找法。我们一起来看一下。 一、Leetcode 74 Leetcode 74. 搜索二维矩阵 这道题要在一个二维矩阵中查找元素。该二维矩阵有如下特点: 每行元素 从左到右 按非递减顺序排列。每行的第一个元素 …...
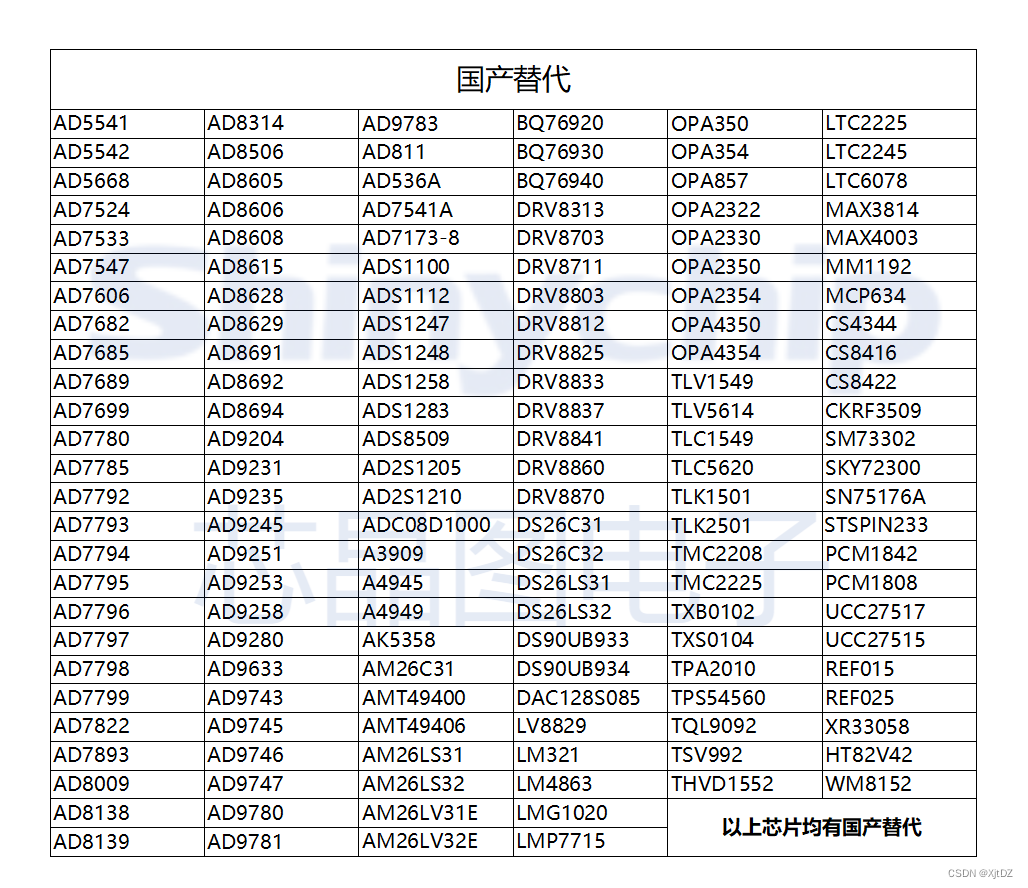
MS35657步进电机驱动器可兼容DRV8824
MS35657 是一款双通道 DMOS 全桥驱动器,可以驱动一个步进电机或者两个直流电机。可兼容DRV8824(功能基本一致,管脚不兼容)。每个全桥的驱动电流在 24V 电源下可以工作到 1.4A。MS35657 集成了固定关断时间的 PWM 电流校正器&#…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

2026长沙智能家居品牌实测,这些本地老牌值得选
2026年,长沙的智能家居市场已经从“概念热”转向“落地战”。我走访了长沙多个本地服务商,实测了不同品牌在别墅、酒店、大平层等场景的真实表现。今天,结合数据与案例,分享几个值得关注的本地品牌,尤其是深耕8年以上的…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对?
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...
)
Frida无Root Hook PC微信小程序源码(Electron+Chromium)
1. 这不是“破解”,而是一次对微信小程序运行机制的逆向观察 你有没有试过,在PC版微信里点开一个小程序,想看看它背后是怎么写的?比如某个电商小程序的优惠券逻辑、某个工具类小程序的数据渲染方式,甚至只是单纯好奇—…...