Msa类处理多序列比对数据
同源搜索,多序列比对等都是常用的方式,但是有很多的软件可以实现这些同源搜索和多序列比对,但是不同的软件输出的文件格式却是不完全一致,有熟悉的FASTA格式的,也有A2M, A3M,stockholm等格式。
详细介绍:
https://github.com/soedinglab/hh-suite/wiki#multiple-sequence-alignment-formats
A3M格式文件示例:
- 每个序列都以 > 开头的行开始,并包含序列的标识信息。
- 在序列标识行之后,是与该序列相关的比对信息,通常使用字母来表示氨基酸或核酸。‘-’表示缺失,小写字母表示插入。

Stockholm格式文件示例:

import dataclasses
from typing import Sequence, Tuple
import string
import collections# Sequence 表示序列类型,内部的 Sequence[int] 表示整数序列。
# DeletionMatrix 表示一个由整数组成的二维数组。
DeletionMatrix = Sequence[Sequence[int]]### 1. 定义Msa类
# Python中,dataclass 是一个装饰器(Decorator),用于创建称为数据类(data class)的类。
# dataclass 装饰器自动生成一些特殊方法,如 __init__、__repr__、__eq__ 等,
# 减少了编写这些方法的样板代码。
@dataclasses.dataclass(frozen=True)
class Msa:"""Class representing a parsed MSA file."""## 初始化参数sequences: Sequence[str]deletion_matrix: DeletionMatrixdescriptions: Sequence[str]# __post_init__ 是Python数据类(data class)中的特殊方法,# 用于在创建数据类的实例之后进行进一步的初始化操作def __post_init__(self):if not (len(self.sequences) ==len(self.deletion_matrix) ==len(self.descriptions)):raise ValueError('All fields for an MSA must have the same length. 'f'Got {len(self.sequences)} sequences, 'f'{len(self.deletion_matrix)} rows in the deletion matrix and 'f'{len(self.descriptions)} descriptions.')def __len__(self):return len(self.sequences)def truncate(self, max_seqs: int):return Msa(sequences=self.sequences[:max_seqs],deletion_matrix=self.deletion_matrix[:max_seqs],descriptions=self.descriptions[:max_seqs])m_seq = ["AAALLL","AT-LAL","S-ALLI"] # 多序列比对后的数据m_del_matrix = [[0,0,0,0,0,0],[0,0,0,0,0,0],[0,0,0,0,0,0]]m_descriptions = ["seq1","seq2","seq3"]# 实例化
test_msa = Msa(m_seq, m_del_matrix, m_descriptions)
print(test_msa)
print(len(test_msa))
# 去除msa第三条序列
print(test_msa.truncate(2))### 2. 定义函数,解析fasta格式字符串
def parse_fasta(fasta_string: str) -> Tuple[Sequence[str], Sequence[str]]:"""Parses FASTA string and returns list of strings with amino-acid sequences.Arguments:fasta_string: The string contents of a FASTA file.Returns:A tuple of two lists:* A list of sequences.* A list of sequence descriptions taken from the comment lines. In thesame order as the sequences."""sequences = []descriptions = []index = -1for line in fasta_string.splitlines():line = line.strip()if line.startswith('>'):index += 1descriptions.append(line[1:]) # Remove the '>' at the beginning.sequences.append('')continueelif not line:continue # Skip blank lines. sequences[index] += linereturn sequences, descriptionswith open("test_aln.a3m") as f:a3m_string = f.read()
sequences, description = parse_fasta(a3m_string)print(sequences)
print(description)## 多序列比对a3m格式:
## 1. 每个序列都以 > 开头的行开始,并包含序列的标识信息。
## 2.在序列标识行之后,是与该序列相关的比对信息,通常使用字母来表示氨基酸或核酸。
## ‘-’表示缺失,小写字母表示插入。### 3.定义函数,解析a3m格式的msa字符串,生成Msa实例,该函数调用parse_fasta函数
def parse_a3m(a3m_string: str) -> Msa:"""Parses sequences and deletion matrix from a3m format alignment.Args:a3m_string: The string contents of a a3m file. The first sequence in thefile should be the query sequence.Returns:A tuple of:* A list of sequences that have been aligned to the query. Thesemight contain duplicates.* The deletion matrix for the alignment as a list of lists. The elementat `deletion_matrix[i][j]` is the number of residues deleted fromthe aligned sequence i at residue position j.* A list of descriptions, one per sequence, from the a3m file."""sequences, descriptions = parse_fasta(a3m_string)deletion_matrix = []for msa_sequence in sequences:deletion_vec = []deletion_count = 0for j in msa_sequence:if j.islower():deletion_count += 1else:deletion_vec.append(deletion_count)deletion_count = 0deletion_matrix.append(deletion_vec)# Make the MSA matrix out of aligned (deletion-free) sequences.# string.ascii_lowercase, string模块提供的字符串常量,包含了所有小写字母的 ASCII 字符# str.maketrans 是 Python 字符串方法,用于创建一个字符映射表(translation table),# ''换成''并删除string.ascii_lowercasedeletion_table = str.maketrans('', '', string.ascii_lowercase)# str.translate 使用映射表执行字符转换(删除小写字母)aligned_sequences = [s.translate(deletion_table) for s in sequences]return Msa(sequences=aligned_sequences,deletion_matrix=deletion_matrix,descriptions=descriptions)with open("test_aln.a3m") as f:a3m_string = f.read()msa1 = parse_a3m(a3m_string)
print(msa1)### 4.定义函数, 解析stockholm格式的msa字符串,生成Msa实例
def parse_stockholm(stockholm_string: str) -> Msa:"""Parses sequences and deletion matrix from stockholm format alignment.Args:stockholm_string: The string contents of a stockholm file. The firstsequence in the file should be the query sequence.Returns:A tuple of:* A list of sequences that have been aligned to the query. Thesemight contain duplicates.* The deletion matrix for the alignment as a list of lists. The elementat `deletion_matrix[i][j]` is the number of residues deleted fromthe aligned sequence i at residue position j.* The names of the targets matched, including the jackhmmer subsequencesuffix."""## 有序字典,保持多序列比对中的序列顺序name_to_sequence = collections.OrderedDict()for line in stockholm_string.splitlines():line = line.strip()# 去除空行和注释行if not line or line.startswith(('#', '//')):continuename, sequence = line.split()if name not in name_to_sequence:name_to_sequence[name] = ''name_to_sequence[name] += sequencemsa = []deletion_matrix = []query = ''keep_columns = []for seq_index, sequence in enumerate(name_to_sequence.values()):## 第一行为query序列if seq_index == 0:# Gather the columns with gaps from the queryquery = sequencekeep_columns = [i for i, res in enumerate(query) if res != '-']# Remove the columns with gaps in the query from all sequences.aligned_sequence = ''.join([sequence[c] for c in keep_columns])msa.append(aligned_sequence)# Count the number of deletions w.r.t. query.deletion_vec = []deletion_count = 0# query序列相对于每一个同源序列,氨基酸位置的缺失情况,累加连续缺失for seq_res, query_res in zip(sequence, query): if seq_res != '-' or query_res != '-': if query_res == '-':deletion_count += 1else:deletion_vec.append(deletion_count)deletion_count = 0deletion_matrix.append(deletion_vec)return Msa(sequences=msa,deletion_matrix=deletion_matrix,descriptions=list(name_to_sequence.keys()))with open("test_aln.stockholm") as f:stockholm_string = f.read()
print(stockholm_string)msa2 = parse_stockholm(stockholm_string)
print(msa2)## 注:parse_stockholm 和 parse_a3m 函数生成Msa对象中,
## deletion_matrix中在查询序列deletion位置填上缺失的个数,
## 下一个氨基酸位置的0跳过,所以总长度相等
## 如函数输入msa中第一条序列(query序列)为:“A--CE-H”, 则函数输出的第一条序列为:“ACEH”,
## deletion_matrix的第一个元素为:[0,2,0,1]相关文章:
Msa类处理多序列比对数据
同源搜索,多序列比对等都是常用的方式,但是有很多的软件可以实现这些同源搜索和多序列比对,但是不同的软件输出的文件格式却是不完全一致,有熟悉的FASTA格式的,也有A2M, A3M,stockholm等格式。 详细介绍: …...

ChatGPT如何管理对话历史?
问题 由于现在开始大量使用ChatGPT对话功能,认识到他在提供启发方面具有一定价值。比如昨天我问他关于一个微习惯的想法,回答的内容还是很实在,而且能够通过他的表达理解自己的问题涉及到的领域是什么。 此外,ChatGPT能够总结对话…...
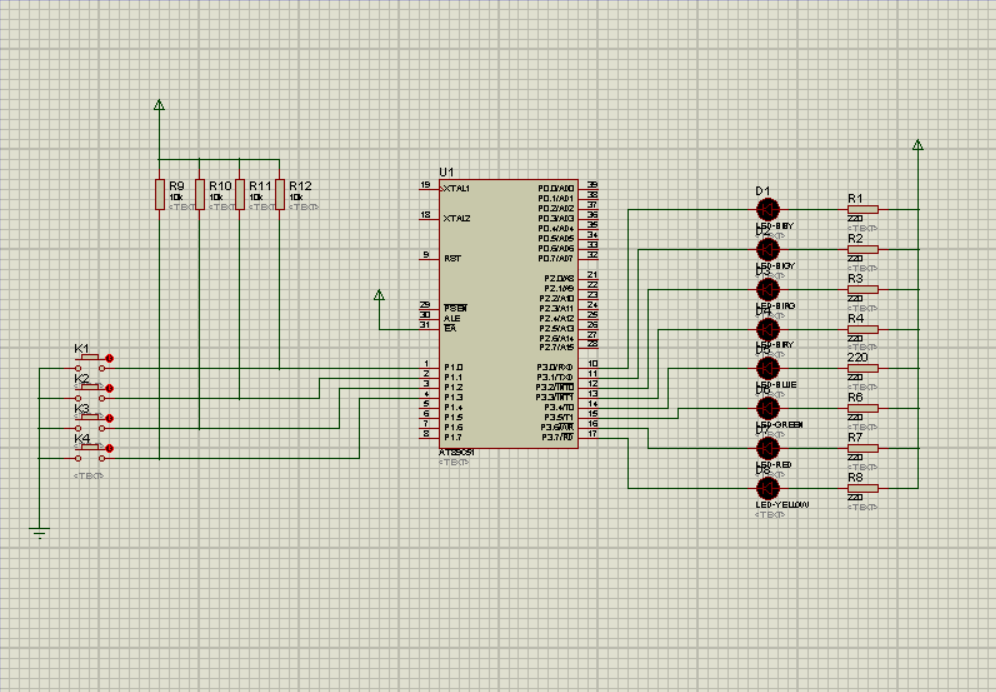
独立键盘接口设计(Keil+Proteus)
前言 软件的操作参考这篇博客。 LED数码管的静态显示与动态显示(KeilProteus)-CSDN博客https://blog.csdn.net/weixin_64066303/article/details/134101256?spm1001.2014.3001.5501实验:用4个独立按键控制8个LED指示灯。 按下k1键&#x…...
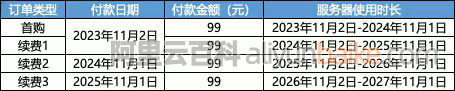
阿里云99元服务器2核2G3M带宽_4年396元_新老用户同享
阿里云99元服务器新老用户同享活动 aliyunfuwuqi.com/go/aliyun 首先要在2023年11月1日去阿里云活动页下单新购这个套餐,享受99元包1年。同天再续费1年又享受了99元包1年;等到明年2024年11月1日之后,又可以以99元续1年;最后等到20…...

数据库实验:SQL的数据控制
目录 数据控制实验目的实验内容实验要求实验过程实验内容提纲实验过程 数据控制 数据控制SQL语句(DCL)是一类可对用户数据访问权进行控制的操作语句,可以控制特定用户或角色对数据表、视图、存储过程、触发器等数据对象的访问权限。主要有GRANT、REVOKE、DENY语句操…...
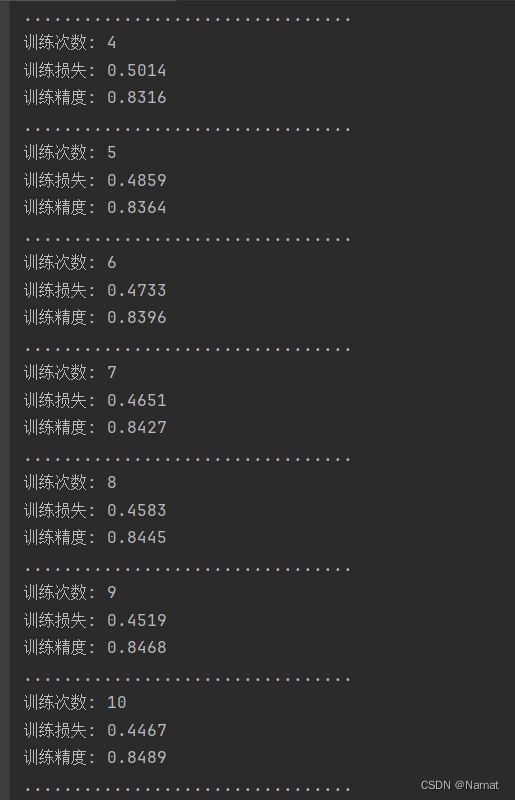
深度学习_10_softmax_实战
由于网上代码的画图功能是基于jupyter记事本,而我用的是pycham,这导致画图代码不兼容pycharm,所以删去部分代码,以便能更好的在pycharm上运行 完整代码: import torch from d2l import torch as d2l"创建训练集&创建检测集合"…...

基于SpringBoot+Vue的博物馆管理系统
基于springbootvue的博物馆信息管理系统的设计与实现~ 开发语言:Java数据库:MySQL技术:SpringBootMyBatisVue工具:IDEA/Ecilpse、Navicat、Maven 系统展示 主页 登录界面 管理员界面 用户界面 摘要 基于SpringBoot和Vue的博物馆…...
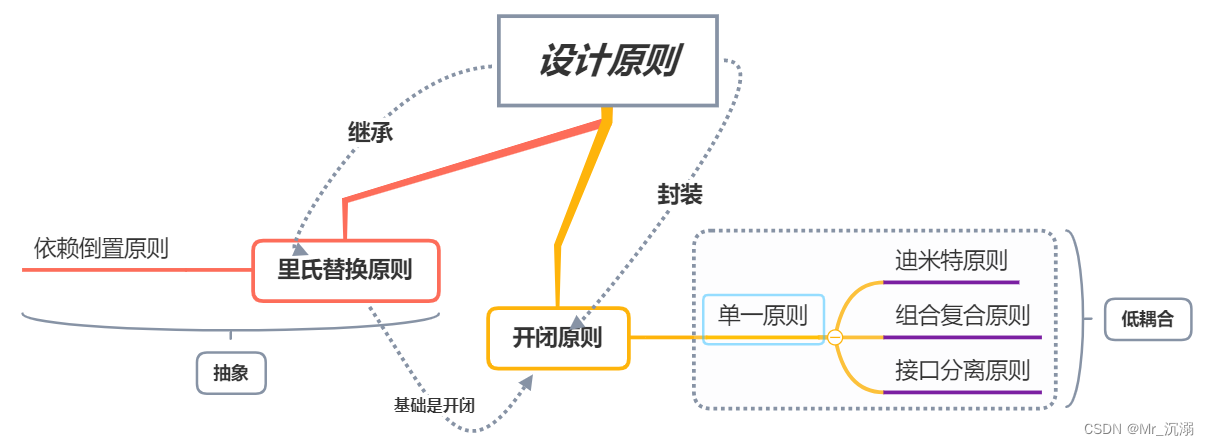
软件开发中常见的设计原则
软件开发中常见的设计原则 1. 单一责任原则2. 开放封闭原则3. 里氏替换原则4. 接口分离原则5. 依赖倒置原则6. 迪米特法则7. 合成复用原则8. 共同封闭原则9. 稳定抽象原则10. 稳定依赖原则 简写全拼中文翻译SRPThe Single Responsibility Principle单一责任原则OCPThe Open Clo…...

Linux安装ffmpeg并截取图片和视频的缩略图使用
Linux安装ffmpeg并截取图片和视频的缩略图使用 官方下载地址: http://www.ffmpeg.org/download.html#releases 我这里使用版本: ffmpeg_3.2_repo.tar.gz 可以百度网盘分享给大家 安装的环境为 Centos 64位操作系统 安装时须为 root 用户进行操作 #解压 tar -zxvf ffmpeg_3…...
)
第三章:人工智能深度学习教程-基础神经网络(第一节-ANN 和 BNN 的区别)
你有没有想过建造大脑之类的东西是什么感觉,这些东西是如何工作的,或者它们的作用是什么?让我们看看节点如何与神经元通信,以及人工神经网络和生物神经网络之间有什么区别。 1.人工神经网络:人工神经网络(…...

高防CDN与高防服务器:为什么高防服务器不能完全代替高防CDN
在当今的数字化时代,网络安全已经成为企业不容忽视的关键问题。面对不断增长的网络威胁和攻击,许多企业采取了高防措施以保护其网络和在线资产。然而,高防服务器和高防CDN是两种不同的安全解决方案,各自有其优势和局限性。在本文中…...
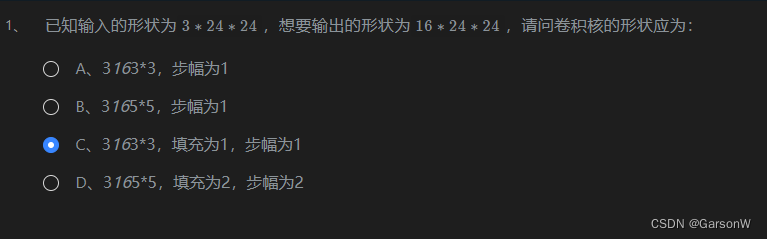
关于卷积神经网络的多通道
多通道输入 当输入的数据包含多个通道时,我们需要构造一个与输入通道数相同通道数的卷积核,从而能够和输入数据做卷积运算。 假设输入的形状为n∗n,通道数为ci,卷积核的形状为f∗f,此时,每一个输入通道都…...

19、Flink 的Table API 和 SQL 中的内置函数及示例(1)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

<a>标签的download属性部分浏览器无法自动识别文件后缀
问题 最近开发中遇到的问题,文件名中含有点和逗号字符,当使用a标签的download属性下载内容时,如果不指定后缀,部分浏览器无法自动识别文件后缀。如下图所示: 定义用法 download 属性定义了下载链接的地址。 href 属性…...

前端图片压缩上传,减少等待时间!优化用户体检
添加图片注释,不超过 140 字(可选) 这里有两张图片,它们表面看上去是一模一样的,但实际上各自所占用的内存大小相差了180倍。 添加图片注释,不超过 140 字(可选) 添加图片注释&…...

Ionic header content footer toolbar UI实例
1 ionic的button图标 <ion-header [translucent]"true"><ion-toolbar><ion-buttons slot"start"><ion-back-button default-href"/tabs/tab1" text"back" icon"caret-back"></ion-back-button&…...
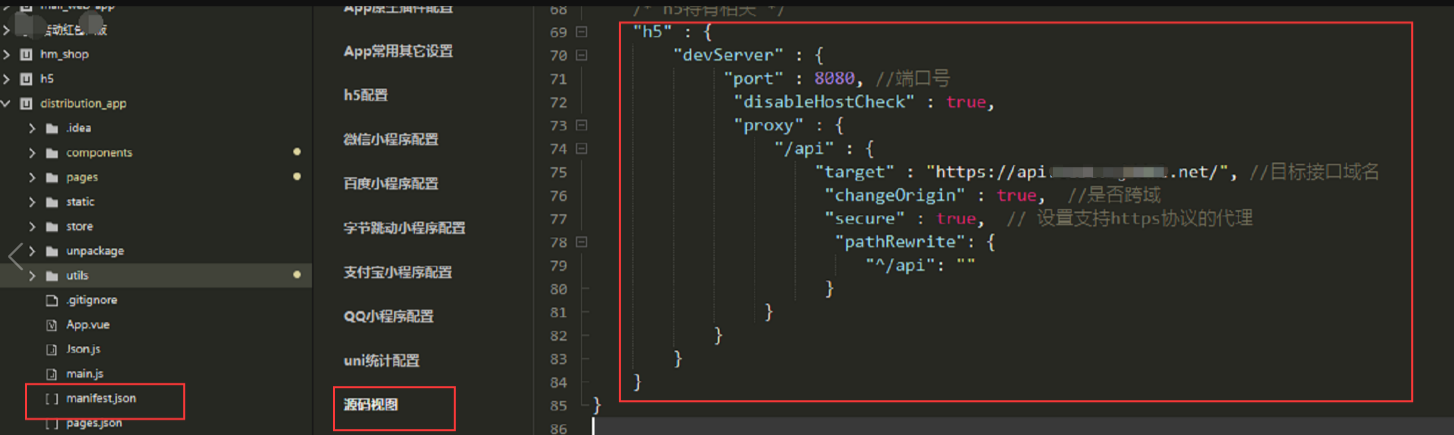
uniapp 解决H5跨域的问题
uniapp 解决h5跨域问题 manifest.json manifest.json文件中,点击“源码视图”,在此对象的最后添加以下代码: "h5" : {"devServer" : {"port" : 8080, //端口号"disableHostCheck" : true,"proxy" :…...
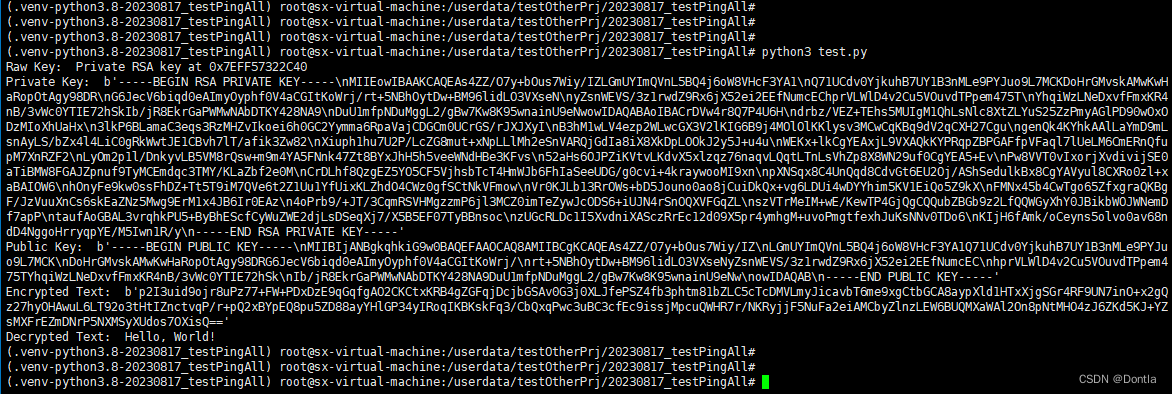
对称加密(symmetric encryption)和非对称加密(Asymmetric Encryption)(密钥、公钥加密、私钥解密)AES、RSA
文章目录 对称加密与非对称加密对称加密1.1 定义1.2 工作原理1.3 场景分析1.4 算法示例(以AES为例)1.5 对称加密的优点与缺点优点缺点 非对称加密2.1 定义2.2 工作原理注意:每次生成的RSA密钥对都会不一样 2.3 场景分析2.4 算法示例ÿ…...
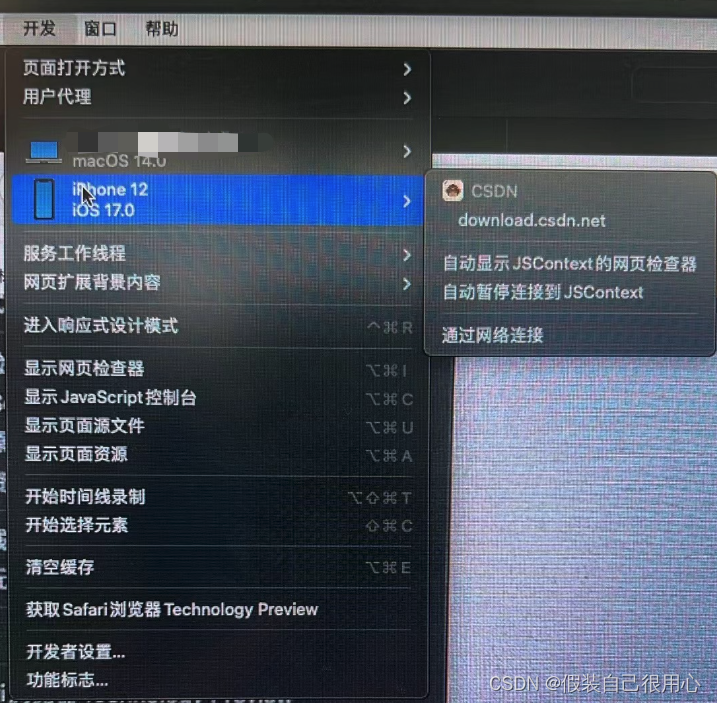
iOS 16.4 之后真机与模拟器无法使用Safari调试H5页面问题
背景 iOS 16.4之后用真机调试H5时候发现,Safari中开发模块下面无法调试页面 解决方案 在WKWebView中设置以下代码解决 if (available(iOS 16.4, *)) {[_webView setInspectable:YES];}然后再次调试就可以了...
野火霸天虎 STM32F407 学习笔记_3 尝试寄存器映射方式点亮 LED 灯
新建工程 寄存器方式 要命啊,一看名字我就不想试。寄存器新建不得麻烦死。 哎算了为了学习原理,干了。 我们尝试自己写一个寄存器的库函数来引用。 首先我们需要引用 st 官方启动文件 stmf4xx.s,具体用途后面章节再展开讲解。然后我们自…...

SenseVoice WebUI镜像体验:上传音频秒获文字+表情标签,小白也能玩转
SenseVoice WebUI镜像体验:上传音频秒获文字表情标签,小白也能玩转 1. 快速了解SenseVoice WebUI SenseVoice WebUI是一个开箱即用的语音识别工具,它能将你上传的音频文件快速转换成文字,并自动标注说话人的情感状态和音频中的特…...

基于 stm32 智能水壶的设计与实现
收藏关注不迷路!! 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多…...

DAMOYOLO模型一键部署教程:基于Ubuntu20.04与Docker环境
DAMOYOLO模型一键部署教程:基于Ubuntu20.04与Docker环境 想试试最新的目标检测模型,但被复杂的依赖和配置搞得头大?别担心,今天咱们就来聊聊怎么用最简单的方式,在Ubuntu 20.04上把DAMOYOLO模型跑起来。整个过程就像搭…...

收藏 | 传统程序员转型AI Agent工程师:未来最值钱的程序员是这类人
文章探讨了传统程序员在AI时代面临的转型问题,提出AI Agent工程师是未来趋势。文章指出,AI Agent工程师的核心能力并非模型本身,而是构建稳定自动化系统的系统工程能力,包括工具编排、状态管理、权限控制等。文章建议传统程序员通…...

Sammy.js项目实战:从零搭建完整的单页应用架构终极指南
Sammy.js项目实战:从零搭建完整的单页应用架构终极指南 【免费下载链接】sammy Sammy is a tiny javascript framework built on top of jQuery, Its RESTful Evented Javascript. 项目地址: https://gitcode.com/gh_mirrors/sa/sammy Sammy.js是一个轻量级的…...
)
保姆级教程:用ArduPilot给无人车/船配置避障(附MR72雷达、TFmini Plus参数)
保姆级教程:用ArduPilot为无人车/船配置毫米波与激光雷达避障系统 当你的无人车在野外自动巡航时突然检测到前方障碍物,是紧急刹车还是智能绕行?水面无人船在夜间航行如何避开漂浮物?本文将手把手带你完成从硬件选型到参数调优的全…...
Pixel Aurora Engine真实作品:支持物理位移反馈的UI交互+生成图联动演示
Pixel Aurora Engine真实作品:支持物理位移反馈的UI交互生成图联动演示 1. 像素极光创意引擎介绍 Pixel Aurora Engine(像素极光引擎)是一款融合AI生成技术与复古游戏美学的创意工具。这款"虚拟游戏机"采用8-bit像素风格界面&…...

OpenClaw对话式编程:Qwen3-4B模型解释代码与生成示例
OpenClaw对话式编程:Qwen3-4B模型解释代码与生成示例 1. 为什么需要对话式编程? 作为一名长期与代码打交道的开发者,我经常遇到这样的困境:面对一段复杂代码时,需要反复查阅文档;学习新框架时,…...
Pixel Aurora Engine应用场景:独立开发者低成本构建像素IP资产库
Pixel Aurora Engine应用场景:独立开发者低成本构建像素IP资产库 1. 像素艺术创作新纪元 在游戏开发领域,像素艺术始终保持着独特的魅力。从早期的《超级马里奥》到现代的《星露谷物语》,像素风格游戏凭借其怀旧感和艺术表现力,…...

OpenClaw自动化周报:Qwen3.5-9B解读工作截图生成总结
OpenClaw自动化周报:Qwen3.5-9B解读工作截图生成总结 1. 为什么需要自动化周报 每周五下午,我都会陷入一种"周报焦虑"——电脑桌面上堆满了会议截图、临时记录的txt文件、微信里的零散对话。手动整理这些碎片信息需要3-4个小时,常…...