pytorh模型训练、测试
目录
1 导入数据集
2 使用tensorboard展示经过各个层的图片数据
3 完整的模型训练测试流程
使用Gpu训练的两种方式
使用tensorboard显示模型
模型训练测试
L1Loss函数
保存未训练模型或者已经训练完的模型
4 加载训练好的模型进行测试
1 导入数据集
import torch
from torch.utils.data import DataLoader
import torchvision
from torchvision import transforms
import torch.nn as nn
# 准备数据集
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10('./data', train=True, transform=transforms.ToTensor(), download=True)
print("train数据", train_data)
print(f"train_data数据的长度是{len(train_data)}")
train_data = DataLoader(dataset=train_data, batch_size=64, shuffle=True)
print("------------------------------------------")
test_data = torchvision.datasets.CIFAR10('./data', train=False, transform=transforms.ToTensor(), download=True)
print("test数据", test_data)
print(f"test_data数据的长度是{len(test_data)}")
print("第一条数据",test_data[0])
test_data = DataLoader(dataset=test_data, batch_size=64, shuffle=True)train数据 Dataset CIFAR10
Number of datapoints: 50000
Root location: ./data
Split: Train
StandardTransform
Transform: ToTensor()
train_data数据的长度是50000
------------------------------------------
Files already downloaded and verified
test数据 Dataset CIFAR10
Number of datapoints: 10000
Root location: ./data
Split: Test
StandardTransform
Transform: ToTensor()
test_data数据的长度是10000
第一条数据 (tensor([[[0.6196, 0.6235, 0.6471, ..., 0.5373, 0.4941, 0.4549],
[0.5961, 0.5922, 0.6235, ..., 0.5333, 0.4902, 0.4667],
[0.5922, 0.5922, 0.6196, ..., 0.5451, 0.5098, 0.4706],
...,
[0.2667, 0.1647, 0.1216, ..., 0.1490, 0.0510, 0.1569],
[0.2392, 0.1922, 0.1373, ..., 0.1020, 0.1137, 0.0784],
[0.2118, 0.2196, 0.1765, ..., 0.0941, 0.1333, 0.0824]],
[[0.4392, 0.4353, 0.4549, ..., 0.3725, 0.3569, 0.3333],
[0.4392, 0.4314, 0.4471, ..., 0.3725, 0.3569, 0.3451],
[0.4314, 0.4275, 0.4353, ..., 0.3843, 0.3725, 0.3490],
2 使用tensorboard展示经过各个层的图片数据
class convModel(nn.Module):def __init__(self):super(convModel, self).__init__()self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, stride=1, padding=0, bias=True, padding_mode='zeros', kernel_size=3)def forward(self, input_data):return self.conv1(input_data)
write = SummaryWriter('convModel')
model = convModel()
for batch_id, data in enumerate(test_data):write.add_images('原始图片数据展示', data[0], dataformats='NCHW', global_step=batch_id)input_data, label = data[0],data[1]print("batchSize",input_data.size(0))output_data = model(input_data)# 因为经过卷积之后,通道数变为6了,而add_images的源码中要求的通道个数是4个,所以要进行通道变换output_shape_data = torch.reshape(output_data,(-1,3,30,30))write.add_images('经过卷积层之后的图片数据展示', output_shape_data, global_step=batch_id)if batch_id % 300 == 0:print("原始数据的形状", input_data.shape)print("经过卷积层之后的形状", output_data.shape)print("经过形状改变之后", output_shape_data.shape)
write.close()batchSize 64
原始数据的形状 torch.Size([64, 3, 32, 32])
经过卷积层之后的形状 torch.Size([64, 6, 30, 30])
经过形状改变之后 torch.Size([128, 3, 30, 30])
batchSize 64
batchSize 64
batchSize 64
batchSize 64
batchSize 64
batchSize 64
batchSize 64
class maxPoolingModel(nn.Module):def __init__(self):super(maxPoolingModel, self).__init__()self.MaxPool2d = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=False)def forward(self, input_data):return self.MaxPool2d(input_data)
write = SummaryWriter('maxPoolingModel')
model = maxPoolingModel()
for batch_id, data in enumerate(test_data):write.add_images('原始图片数据展示', data[0], dataformats='NCHW', global_step=batch_id)input_data, label = data[0],data[1]output_data = model(input_data)write.add_images('经过池化层之后的图片数据展示', output_data, global_step=batch_id)if batch_id % 300 == 0:print("原始数据的形状", input_data.shape)print("经过池化层之后的形状", output_data.shape)
write.close()原始数据的形状 torch.Size([64, 3, 32, 32])
经过池化层之后的形状 torch.Size([64, 3, 16, 16])
class unLineModel(nn.Module):def __init__(self):super(unLineModel, self).__init__()self.sigmoid = nn.Sigmoid()def forward(self, input_data):return self.sigmoid(input_data)
write = SummaryWriter('unLineModel')
model = unLineModel()
for batch_id, data in enumerate(test_data):write.add_images('原始图片数据展示', data[0], dataformats='NCHW', global_step=batch_id)input_data, label = data[0],data[1]output_data = model(input_data)write.add_images('经过非线性层之后的图片数据展示', output_data, global_step=batch_id)if batch_id % 300 == 0:print("原始数据的形状", input_data.shape)print("经过非线性层之后的形状", output_data.shape)
write.close()原始数据的形状 torch.Size([64, 3, 32, 32])
经过非线性层之后的形状 torch.Size([64, 3, 32, 32])
3 完整的模型训练测试流程
class Model(nn.Module):def __init__(self):super(Model,self).__init__()self.model = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2,stride=1),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2,stride=1),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2,stride=1),nn.MaxPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(in_features=1024, out_features=64),nn.Linear(in_features=64, out_features=10))def forward(self, batch_data):return self.model(batch_data)
# 第一种方式:使用cuda,只需要给模型、损失函数、训练数据、测试数据调用cuda即可,但是这种情况下必须使用if torch.cuda.is_available():判断是否存在cuda,没有的话还是使用cpu,但是没有使用torch.cuda.is_available()判断的话会出错,导致程序无法运行
# 第二种方式:cuda:0 单个显卡
device = torch.device("cuda:0" if torch.cuda.is_available() else 'cpu')
model = Model()
model.to(device=device)
print(model)
batch_data = torch.ones((64,3,32,32)).to(device)
output = model(batch_data)
print("output.shape", output.shape)Model(
(model): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
使用Gpu训练的两种方式
# 第一种方式:使用cuda,只需要给模型、损失函数、训练数据、测试数据调用cuda即可,但是这种情况下必须使用if torch.cuda.is_available():判断是否存在cuda,没有的话还是使用cpu,但是没有使用torch.cuda.is_available()判断的话会出错,导致程序无法运行
# 第二种方式:cuda:0 单个显卡
device = torch.device("cuda:0" if torch.cuda.is_available() else 'cpu'),在这种情况写,只需要将对应的模型、损失函数、训练数据、测试数据使用to调用device上即可
使用tensorboard显示模型
from torch.utils.tensorboard import SummaryWriter
write = SummaryWriter('model')
write.add_graph(model=model,input_to_model=batch_data)
write.close()模型训练测试
# -------------------------CrossEntropyLoss()维度要求的底层源码-------------------
# Shape:
# - Input: :math:`(N, C)` where `C = number of classes`, or
# :math:`(N, C, d_1, d_2, ..., d_K)` with :math:`K \geq 1`
# in the case of `K`-dimensional loss.
# - Target: :math:`(N)` where each value is :math:`0 \leq \text{targets}[i] \leq C-1`, or
# :math:`(N, d_1, d_2, ..., d_K)` with :math:`K \geq 1` in the case of
# K-dimensional loss.
# - Output: scalar.
# If :attr:`reduction` is ``'none'``, then the same size as the target:
# :math:`(N)`, or
# :math:`(N, d_1, d_2, ..., d_K)` with :math:`K \geq 1` in the case
# of K-dimensional loss.
criteria = nn.CrossEntropyLoss()
criteria.to(device)
nn.L1Loss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
sum_loss_list = []
epoch_list = []
from torch.utils.tensorboard import SummaryWriter
write = SummaryWriter("figure")
total_train_step = 0
total_test_step = 0
for epoch in range(50):ever_epoch_loss_sum = 0.0print("---------------------第 {} 轮训练开始---------------------".format(epoch+1))model.train()for batch_id, data in enumerate(train_data):input_data, input_label = datainput_data = input_data.to(device)input_label = input_label.to(device)output_data = model(input_data)# if batch_id%300 == 0:# print("input_data", input_data.shape) # input_data torch.Size([64, 3, 32, 32])# print("output_data", output_data.shape) # output_data torch.Size([64, 10])# print("input_label", input_label.shape) # input_label torch.Size([64])loss = criteria(output_data, input_label)ever_epoch_loss_sum = ever_epoch_loss_sum + loss.item()loss.backward()optimizer.step()optimizer.zero_grad()if total_train_step % 200 == 0:print("当前总的训练次数:{} ,每一次的Loss:{}".format(total_train_step, loss.item()))write.add_scalar('train_loss', loss.item(), total_train_step)total_train_step = total_train_step + 1sum_loss_list.append(ever_epoch_loss_sum)epoch_list.append(epoch)print("---------------------第 {} 轮测试开始---------------------".format(epoch+1))model.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for batch_id, data in enumerate(test_data):images, label = dataimages = images.to(device)label = label.to(device)output = model(images)loss = criteria(output,label)total_test_loss = total_test_loss + loss.item()accuracy = (output.argmax(1) == label).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss: {}".format(total_test_loss))print("整体数据集上的正确率:{}".format(total_accuracy/len(test_data)))write.add_scalar("test_accuracy",total_accuracy/len(test_data),total_test_step)write.add_scalar('test_loss', total_test_loss, total_test_step)total_test_step = total_test_step + 1torch.save(model,'model_{}.pth'.format(epoch))print("保存第 {} 轮模型".format(epoch+1))
write.close()L1Loss函数
inputs = torch.tensor([1,2,3], dtype=torch.float32)
print("原始数据inputs", inputs)
print("原始数据形状inputs.shape", inputs.shape)
targets = torch.tensor([1,2,5], dtype=torch.float32)
print("目标数据targets", targets)
print("目标数据形状targets.shape", targets.shape)
inputs = torch.reshape(inputs,(1,-1))
print("形状改变数据inputs", inputs)
print("形状改变数据形状inputs.shape", inputs.shape)
targets = torch.reshape(targets,(1,-1))
print("目标数据改变targets", targets)
print("目标数据形状改变targets.shape", targets.shape)
loss = nn.L1Loss()# - Input: :math:`(N, *)` where :math:`*` means, any number of additional# dimensions# - Target: :math:`(N, *)`, same shape as the input
result = loss(inputs, targets)
print(result)原始数据inputs tensor([1., 2., 3.])
原始数据形状inputs.shape torch.Size([3])
目标数据targets tensor([1., 2., 5.])
目标数据形状targets.shape torch.Size([3])
形状改变数据inputs tensor([[1., 2., 3.]])
形状改变数据形状inputs.shape torch.Size([1, 3])
目标数据改变targets tensor([[1., 2., 5.]])
目标数据形状改变targets.shape torch.Size([1, 3])
tensor(0.6667)
保存未训练模型或者已经训练完的模型
# 模型的保存
torch.save(model,'class_model.pth')
# 模型加载,但是这种情况下如果加载的模型和原本的模型没有在同一个文件中,那么需要将原本的模型使用from加载到当前文件中,再使用torch.load
model = torch.load('class_model.pth')
print(model)4 加载训练好的模型进行测试
import torch.nn as nn
import torch
class Model(nn.Module):def __init__(self):super(Model,self).__init__()self.model = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2,stride=1),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2,stride=1),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2,stride=1),nn.MaxPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(in_features=1024, out_features=64),nn.Linear(in_features=64, out_features=10))def forward(self, batch_data):return self.model(batch_data)
load_model = torch.load('G:\python_files\深度学习代码库\model_49.pth') # 加载模型,使用上面的非字典形式保存的模型,这个时候加载的时候必须把原本定义的模型加载到当前文件,然后使用该函数加载。同时需要注意,如果加载的模型原本是在cuda上跑的,这个时候要将模型使用load函数的参数map_location=torch.device('cpu')加载到cpu上,或者也可以将图片的数据放入到gpu上,与原本的模型对应起来
from torchvision import transforms
from PIL import Image
image = Image.open('G:\python_files\深度学习代码库\cats\cat\cat.10.jpg')
trans = transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()])
trans_image_tensor = trans(image)
# 因为上面的模型训练的时候输入是(NCHW),所以将训练完的模型加载进来使用测试的时候必须要将一张图片reshape模型需要的形状,否则就会报错
tensor_shape = torch.reshape(trans_image_tensor,(1,3,32,32)).to(torch.device("cuda:0"))
load_model.eval()
with torch.no_grad():output = load_model(tensor_shape)print(output)注意事项:
load_model = torch.load('G:\python_files\深度学习代码库\model_49.pth') # 加载模型,使用上面的非字典形式保存的模型,这个时候加载的时候必须把原本定义的模型加载到当前文件,然后使用该函数加载。同时需要注意,如果加载的模型原本是在cuda上跑的,这个时候要将模型使用load函数的参数map_location=torch.device('cpu')加载到cpu上,或者也可以将图片的数据放入到gpu上,与原本的模型对应起来# 因为上面的模型训练的时候输入是(NCHW),所以将训练完的模型加载进来使用测试的时候必须要将一张图片reshape模型需要的形状,否则就会报错 tensor_shape = torch.reshape(trans_image_tensor,(1,3,32,32)).to(torch.device("cuda:0"))
相关文章:

pytorh模型训练、测试
目录 1 导入数据集 2 使用tensorboard展示经过各个层的图片数据 3 完整的模型训练测试流程 使用Gpu训练的两种方式 使用tensorboard显示模型 模型训练测试 L1Loss函数 保存未训练模型或者已经训练完的模型 4 加载训练好的模型进行测试 1 导入数据集 import torch from torch.u…...
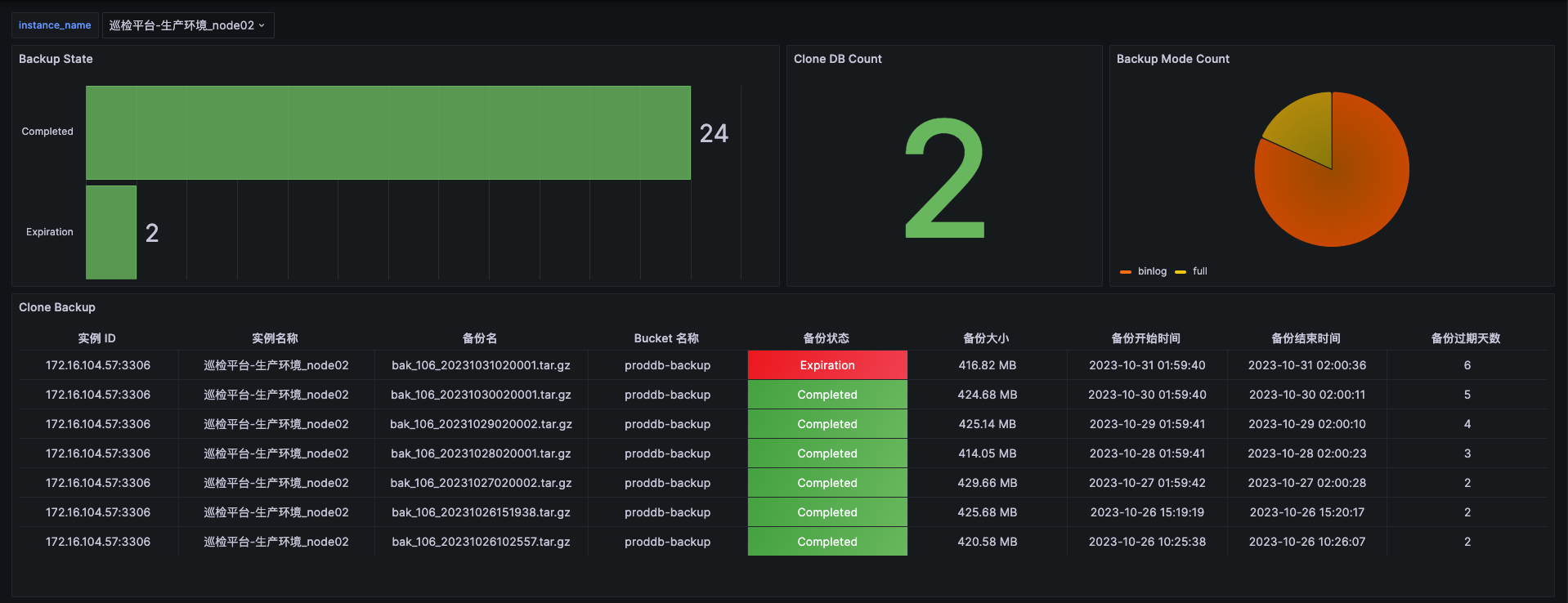
MySQL 8.0 Clone Plugin 详解
文章目录 前言1. 克隆插件安装2. 克隆插件的使用2.1 本地克隆2.2 远程克隆 3. 克隆任务监控4. 克隆插件实现4.1 Init 阶段4.2 File Copy4.3 Page Copy4.4 Redo Copy4.5 Done 5. 克隆插件的限制6. 克隆插件与 Xtrabackup 的异同7. 克隆插件相关参数 后记 前言 克隆插件…...

掌握未来技术趋势:深度学习与量子计算的融合
掌握未来技术趋势:深度学习与量子计算的融合 摘要:本博客将探讨深度学习与量子计算融合的未来趋势,分析这两大技术领域结合带来的潜力和挑战。通过具体案例和技术细节,我们将一睹这两大技术在人工智能、药物研发和金融科技等领域…...

京东数据分析:2023年9月京东笔记本电脑行业品牌销售排行榜
鲸参谋监测的京东平台9月份笔记本电脑市场销售数据已出炉! 9月份,笔记本电脑市场整体销售下滑。鲸参谋数据显示,今年9月份,京东平台上笔记本电脑的销量将近59万,环比下滑约21%,同比下滑约40%;销…...
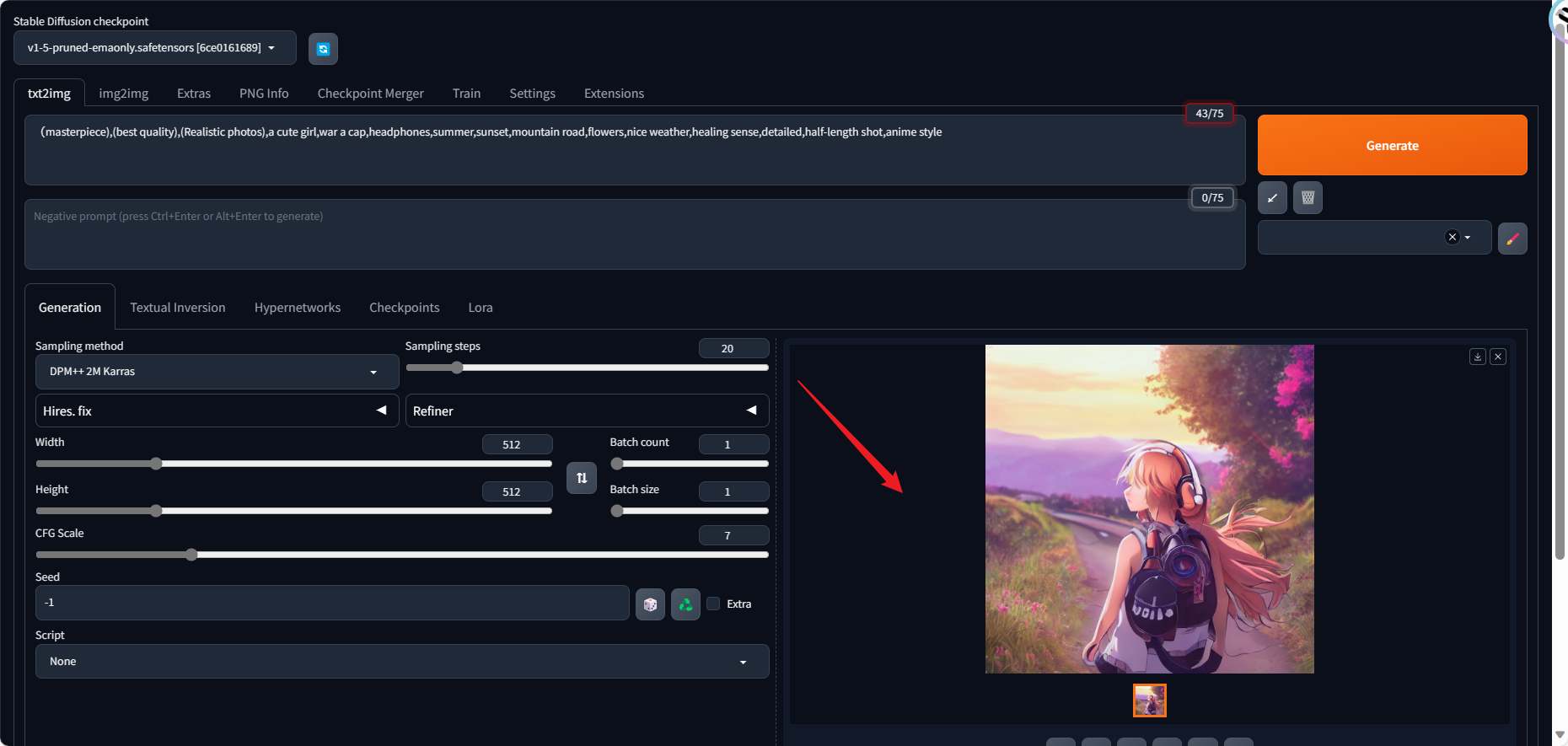
3 任务3 使用趋动云部署自己的stable-diffusion
使用趋动云部署自己的stable-diffusion 1 创建项目:2 初始化开发环境实例3 部署模型4 模型测试 1 创建项目: 1.进入趋动云用户工作台,选择:当前空间,请确保当前所在空间是注册时系统自动生成的空间。 a.非系统自动生成…...

C语言 memset
C语言memset函数详解_C 语言_脚本之家 (jb51.net) 注意是按照字节赋值的。int型变量,当赋值0时,是没有问题的,但是赋值1,却按照每个字节都赋值1,最终结果错误。 怎么解决呢? 不能使用memset么࿱…...

Windows安装svn命令
1、svn命令下载地址 https://www.visualsvn.com/downloads/; 2、安装svn命令 3、测试svn命令是否安装成功...

vr航天探索科普展vr航天科普亲子嘉年华
随着生活水平的提高,人们的体验事物也在变多,学习方面也越来越多元化。现在我国的航天技术也在快速的发展,在宇宙太空中有我们的一席之位。航天大发展离不开每个航天人的努力。现在很多的人从娃娃做起,让他们更早的体验和了解外太…...

双11“万亿交易额”背后,浪潮信息助力银行扛住交易洪流
双十一,不仅是网络购物的狂欢,更是中国支付清算业务的大考。 举目望去,双十一的台前幕后可谓是“不一样的精彩”。一方面台前的主角是消费者,全球超200个国家和地区的人们捧着手机、电脑,在阿里、京东、抖音、拼多多等…...

geoserver发布同一字段的多值渲染
Geoserver之同一字段的多值渲染 有时候我们需要对一个shp的某一字段值中的不同值进行区分展示,但是一般的渲染都是按照统一图层展示的,因此为了更好的效果,我们选择使用uDig等工具处理。 文章目录 Geoserver之同一字段的多值渲染前言一共是分…...

软考 系统架构设计师之考试感悟
今天是2023年11月4号,是软考系统架构设计师考试的正日子。考了一天,身心俱疲,但更多的是暮鼓晨钟般的教训和感悟。下边将今天的感悟写在这里,以资自己及后来者借鉴。 我是从今年7月底8月初开始看教材 ——《系统架构设计师教程》…...
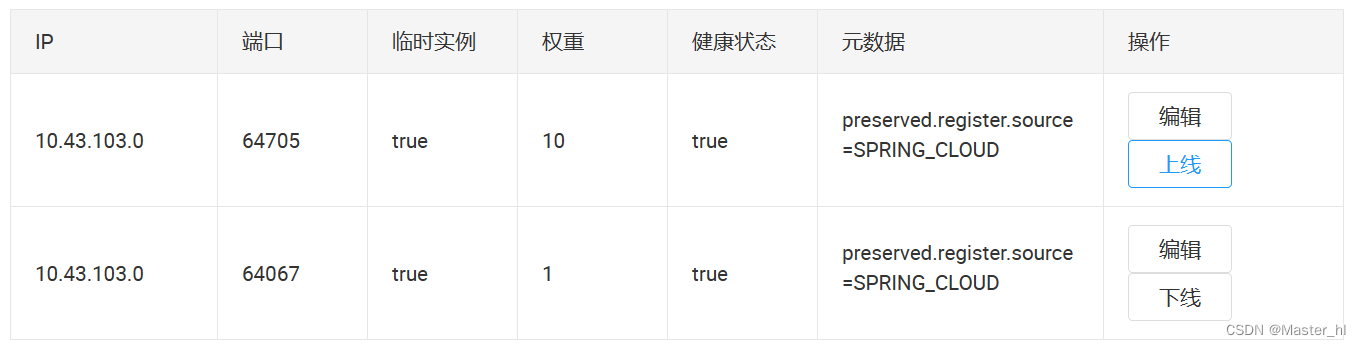
深入Spring Cloud LoadBalancer:策略全解析与缓存机制
目录 1. 什么是 LoadBalancer ? 2. 负载均衡策略的分类 2.1 常见的负载均衡策略 3. 为什么要学习 Spring Cloud Balancer ? 4. Spring Cloud LoadBalancer 内置的两种负载均衡策略 4.1 轮询负载均衡策略(默认的) 4.2 随机负…...
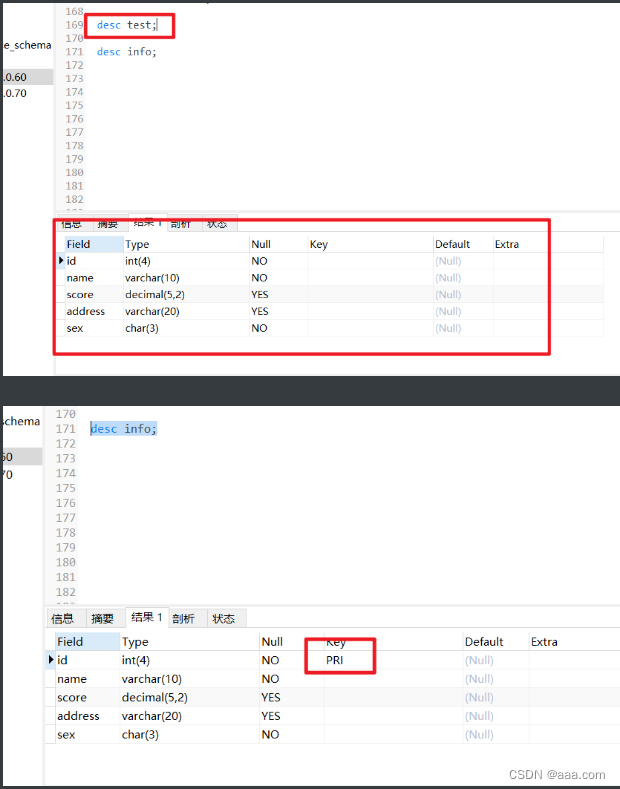
MySQL的高阶语句
前言 数据库是用来存储数据,更新,查询数据的工具,而查询数据是一个数据库最为核心的功能,数据库是用来承载信息,而信息是用来分析和查看的。所以掌握更为精细化的查询方式是很有必要的。本文将围绕数据的高级查询语句展…...
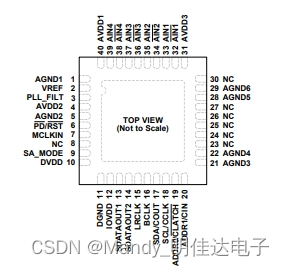
适合汽车音频系统的ADAU1977WBCPZ、ADAU1978WBCPZ、ADAU1979WBCPZ四通道 ADC,24-bit,音频
一、ADAU1977WBCPZ 集成诊断功能的四通道ADC,音频 24 b 192k IC,SPI 40LFCSP ADAU1977集成4个高性能模数转换器(ADC),其直接耦合输入具有10 V rms性能。该ADC采用多位Σ-Δ架构,其连续时间前端能够实现低EMI性能。它可以直接连接…...
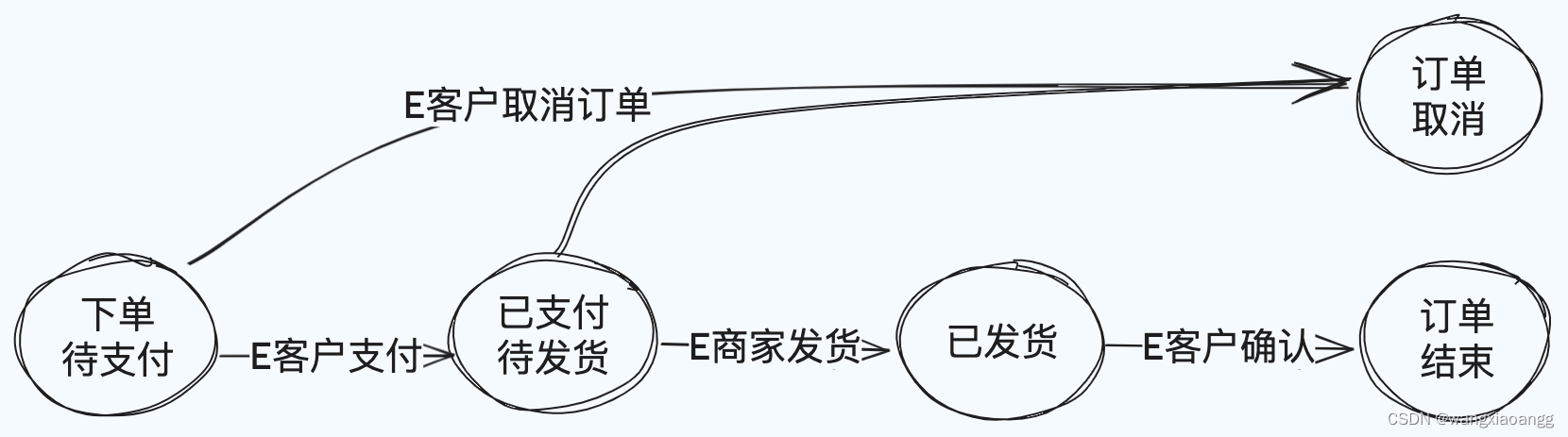
设计模式-状态模式 golang实现
一 什么是有限状态机 有限状态机,英⽂翻译是 Finite State Machine,缩写为 FSM,简称为状态机。 状态机不是指一台实际机器,而是指一个数学模型。说白了,一般就是指一张状态转换图。 已订单交易为例: 1.…...
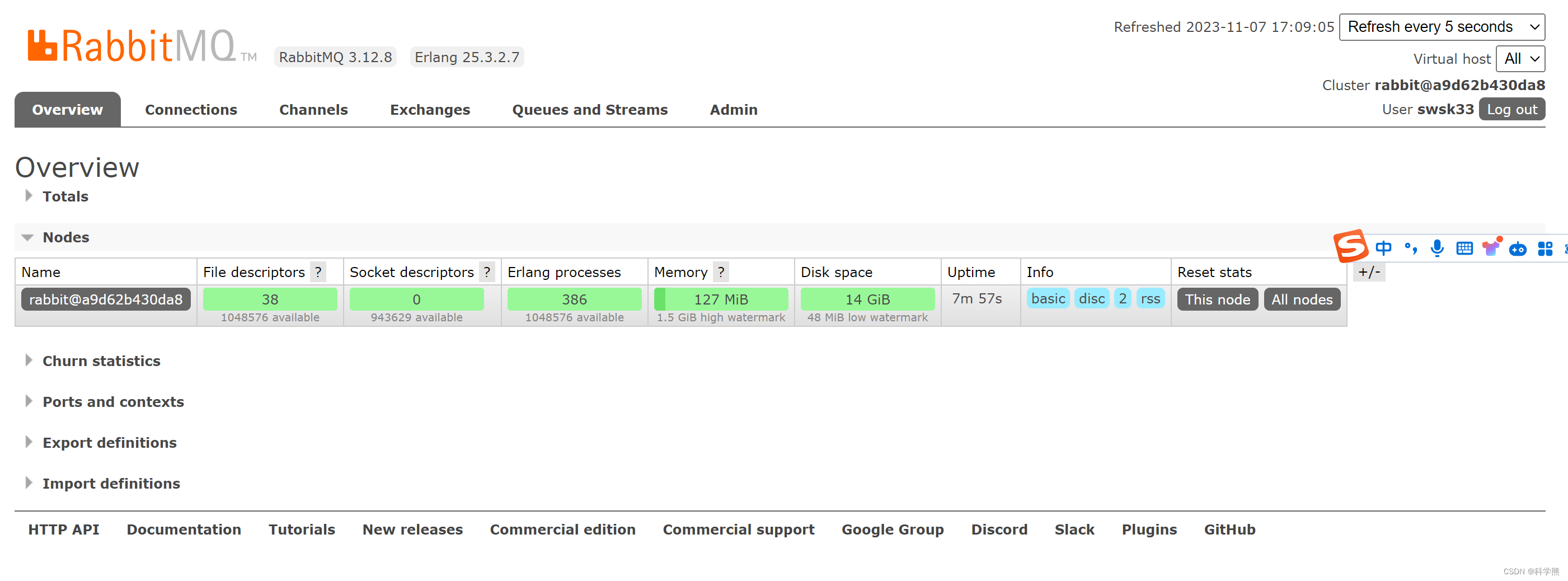
通过docker快速部署RabbitMq
查询镜像: docker search rabbitmq拉去RabbitMq镜像: docker pull rabbitmq:management创建数据卷: docker volume create rabbitmq-home运行容器: docker run -id --namerabbitmq -v rabbitmq-home:/var/lib/rabbitmq -p 156…...

Spring Boot 配置文件中的中文读取出来是乱码,或者是问号
在调试阿里短信时候,遇到读取配置文件乱码导致标签名无法正常使用,而可能有两个原因导致这个问题,一个是配置文件编码方式不是UTF-8的,另一个是Spring http使用的编码不是UTF-8。 1、第一步,将配置文件的编码方式改为U…...

【系统架构设计】架构核心知识: 3.8 ADL和产品线
目录 一 ADL 二 产品线 1 产品线 2 过程模型 3 软件产品线的建立方式...

imagettftext(): Could not find/open font 解决办法
问题:Captcha验证码不能正常显示,是因为使用GD库imagettftext()函数时,报“Warning: imagettftext(): Could not find/open font in ”警告 。 网上的解决方法: 将font路径的相对路径 转成 绝对路径即可 $fontfile "./fonts/*.ttf&q…...
)
P1853 投资的最大效益(DP背包)
投资的最大效益 题目背景 约翰先生获得了一大笔遗产,他暂时还用不上这一笔钱,他决定进行投资以获得更大的效益。银行工作人员向他提供了多种债券,每一种债券都能在固定的投资后,提供稳定的年利息。当然,每一种债券的…...

避坑指南:Informer模型更换自定义数据集时,90%新手会忽略的5个关键参数
Informer模型自定义数据集避坑指南:5个关键参数详解与实战调优 第一次尝试将Informer模型应用到自己的数据集上时,我盯着屏幕上那一串令人绝望的报错信息发呆了整整半小时。明明已经按照官方示例修改了数据路径和基本参数,为什么模型要么无法…...
)
51单片机入门-直流电机(十五)
目录:1.直流电机驱动(PWM)2.LED呼吸灯&直流电机调速1.直流电机驱动(PWM)让他转的快一些让他转2us停1us2.LED呼吸灯&直流电机调速点亮一个LED:在循环里:点亮熄灭显示暗一些:让…...

万兴剧厂AI漫剧APP2025推荐,打造个性化漫剧体验
万兴剧厂AI漫剧APP2025推荐,打造个性化漫剧体验在当今数字化娱乐的浪潮中,漫剧以其独特的表现形式和丰富的内容吸引了众多用户。据《2025中国数字娱乐行业发展报告》显示,2025年漫剧市场规模持续增长,用户对于优质漫剧的需求也日益…...

Kodi中文插件库终极指南:3分钟打造你的智能家庭影院
Kodi中文插件库终极指南:3分钟打造你的智能家庭影院 【免费下载链接】xbmc-addons-chinese Addon scripts, plugins, and skins for XBMC Media Center. Special for chinese laguage. 项目地址: https://gitcode.com/gh_mirrors/xb/xbmc-addons-chinese 还在…...

无人机飞控实战:四元数微分方程在PX4中的实现与调参技巧
无人机飞控实战:四元数微分方程在PX4中的实现与调参技巧 当无人机在复杂环境中执行高速机动时,传统欧拉角描述姿态会出现万向节锁死现象。去年调试一台行业级六旋翼时,就曾遇到俯仰角接近90时控制器突然发散的情况——这正是欧拉角奇异点的典…...

intv_ai_mk11作品分享:会议纪要提炼、政策白话解读、技术术语通俗化实例
intv_ai_mk11作品分享:会议纪要提炼、政策白话解读、技术术语通俗化实例 1. 模型简介与核心能力 intv_ai_mk11是一款基于Llama架构的中等规模文本生成模型,特别擅长处理各类文本转换和解释任务。这个开箱即用的解决方案已经完成本地部署,用…...
)
ESP32-S3玩转微雪2.8寸触摸屏:从零到LVGL的保姆级避坑指南(ESP-IDF 5.3)
ESP32-S3与微雪2.8寸触摸屏深度适配:LVGL全流程实战手册 刚拿到微雪2.8寸触摸屏开发板的开发者,往往既兴奋又忐忑——这块搭载ESP32-S3芯片、配备8M PSRAM的硬件平台,理论上能流畅运行LVGL图形库,但实际开发中总会遇到各种"坑…...

LuckyLilliaBot架构解析:NTQQ OneBot API插件的深度技术实现指南
LuckyLilliaBot架构解析:NTQQ OneBot API插件的深度技术实现指南 【免费下载链接】LuckyLilliaBot NTQQ的OneBot API插件 项目地址: https://gitcode.com/gh_mirrors/li/LuckyLilliaBot LuckyLilliaBot是一款基于OneBot 11协议的开源QQ机器人框架,…...

如何正确计算 CSV 文件中每行学生成绩的平均值
本文详解 python 中使用 csv 模块处理学生成绩数据时常见的累积错误,并提供结构清晰、健壮可靠的解决方案,重点解决因变量作用域不当导致的平均值计算失真问题。在使用 Python 的 csv 模块逐行读取学生成绩文件(如 "students.csv"&…...

SuGaR与NeRF对比分析:为什么高斯泼溅是未来趋势
SuGaR与NeRF对比分析:为什么高斯泼溅是未来趋势 【免费下载链接】SuGaR [CVPR 2024] Official PyTorch implementation of SuGaR: Surface-Aligned Gaussian Splatting for Efficient 3D Mesh Reconstruction and High-Quality Mesh Rendering 项目地址: https://…...