Java修仙传之神奇的ES2(巧妙的查询及结果处理篇)
SDL语句查询
查询的基本语法
GET /indexName/_search
{"query": {"查询类型": {"查询条件": "条件值"}}
}根据文档id查询
#查询文档
GET hotel/_doc/36934查询所有
会弹出该索引库下所有文档// 查询所有
GET /indexName/_search
{"query": {"match_all": {}}
}全文检索查询(搜索框)
参与搜索的字段必须是可分词的text类型的字段。
利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:- match_query
- multi_match_query- 对用户搜索的内容做分词,得到词条
- 根据词条去倒排索引库中匹配,得到文档id
- 根据文档id找到文档,返回给用户- 商城的输入框搜索
- 百度输入框搜索
单字段查询(match查询)
GET /indexName/_search
{"query": {"match": {"FIELD": "TEXT"}}
}
多字段查询
备注:字段必须是text类型,可以分词类型!!!!
查找keyword、数值、日期、boolean等会报错!!!
如果放入精确类型的字段,会报错!!!!!
GET /indexName/_search
{"query": {"multi_match": {"query": "TEXT","fields": ["FIELD1", " FIELD12"]}}
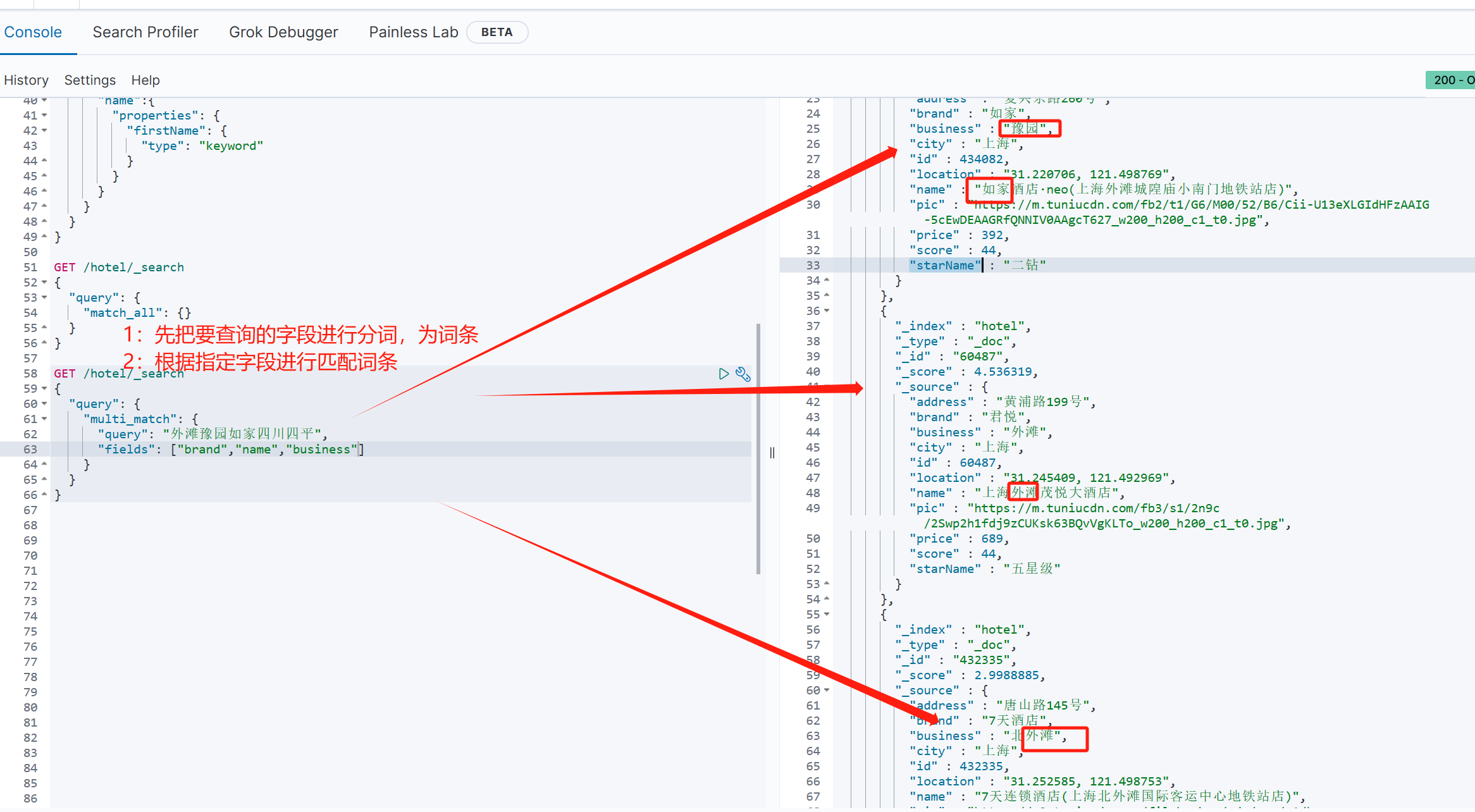
}GET /hotel/_search
{"query": {"multi_match": {"query": "外滩豫园如家四川四平","fields": ["brand","name","business"]}}
}
精准查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段(非text)。所以不会对搜索条件分词。
term查询(精确查询)
查询时,用户输入的内容跟自动值完全匹配时才认为符合条件。
如果输入1234,会完全匹配1234,
123,12345,12,1等都无法匹配到
GET /indexName/_search
{"query": {"term": {"FIELD": {"value": "VALUE"}}}
}# term查询
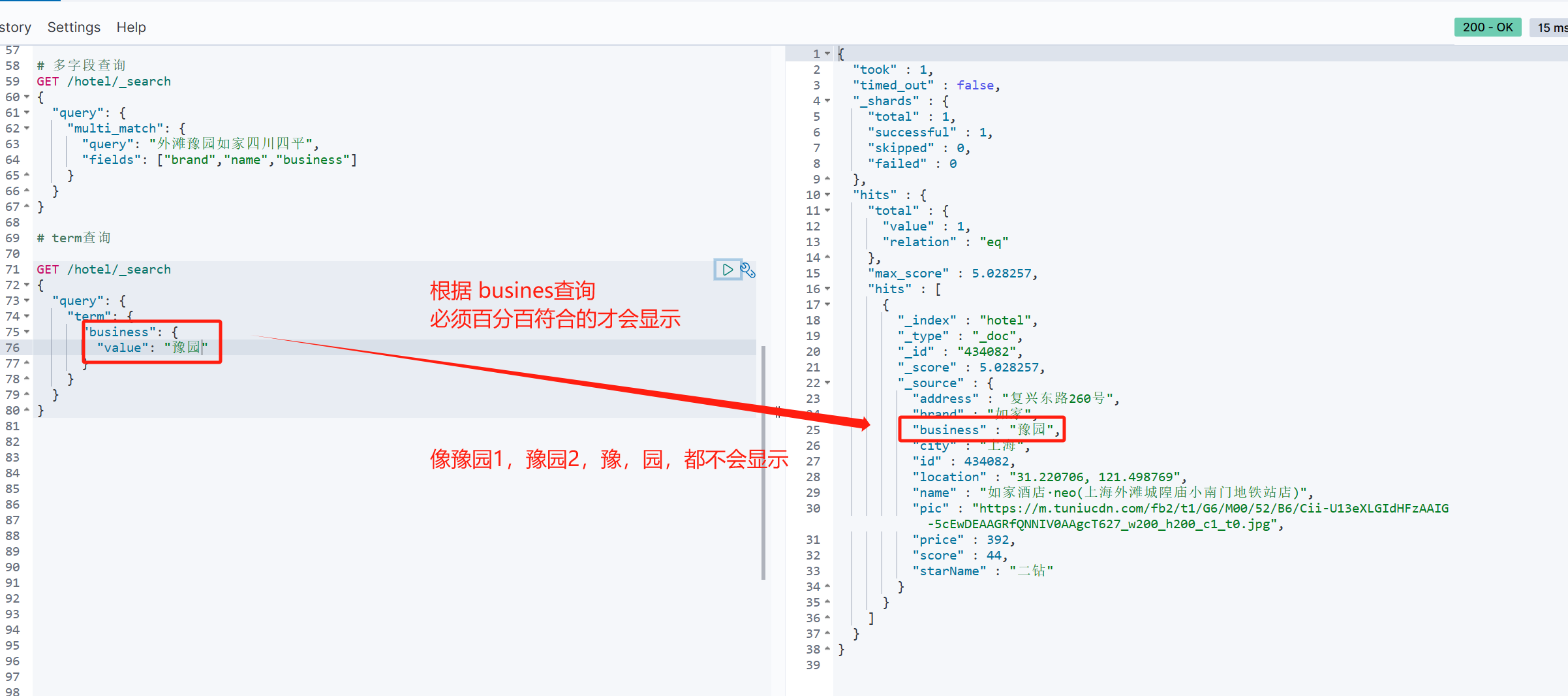
GET /hotel/_search
{"query": {"term": {"business": {"value": "豫园"}}}
}
range查询(范围查询(数值用))
范围查询,一般应用在对数值类型做范围过滤的时候。比如做价格范围过滤。
// range查询
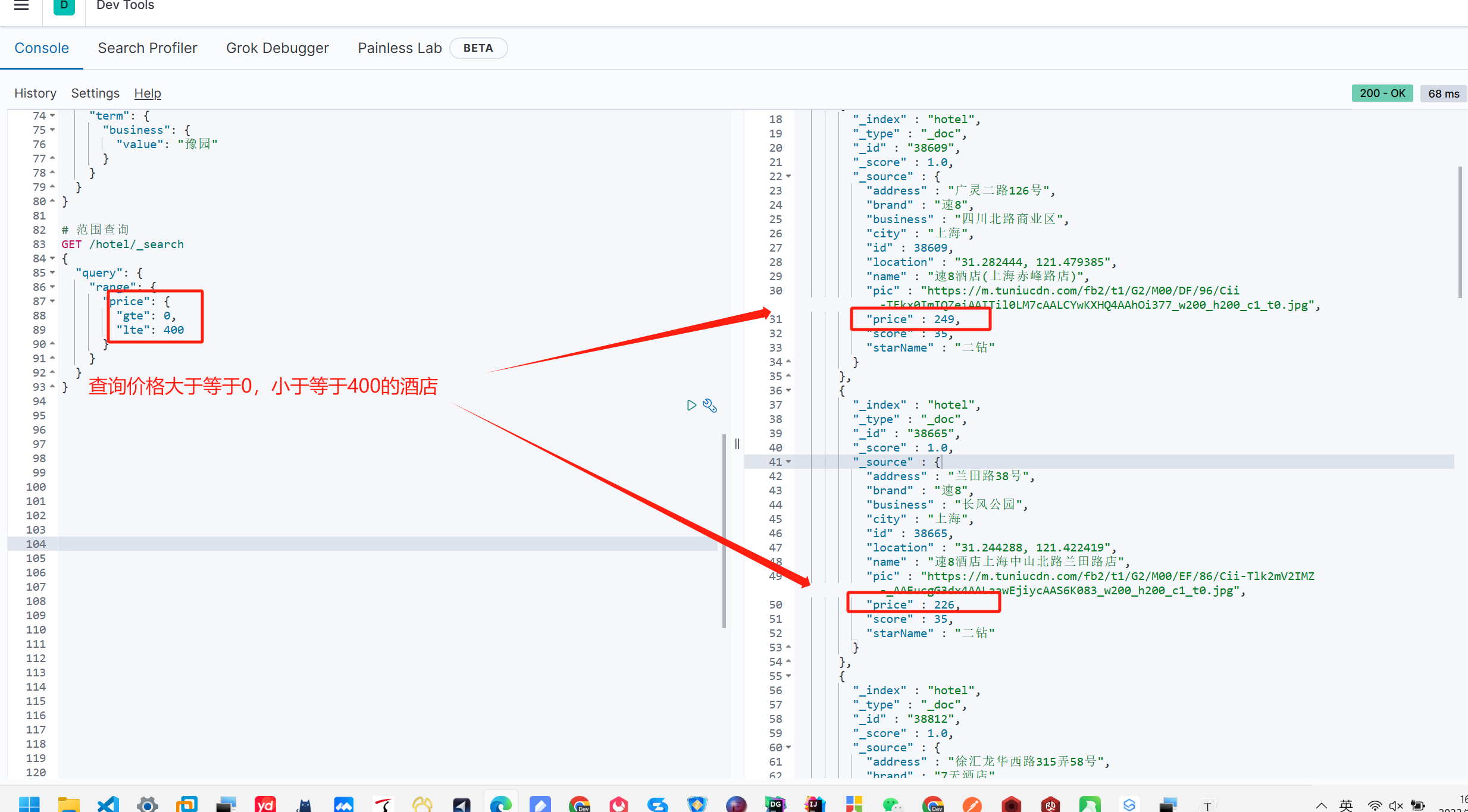
GET /indexName/_search
{"query": {"range": {"FIELD": {"gte": 10, // 这里的gte代表大于等于,gt则代表大于"lte": 20 // lte代表小于等于,lt则代表小于}}}
}
地理坐标查询
所谓的地理坐标查询,其实就是根据经纬度查询
矩形范围查询
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。

GET hotel/_search
{"query":{"geo_bounding_box":{"location":{"top_left": {"lat": 31.1,"lon": 121.5},"bottom_right":{"lat": 30.9,"lon": 121.7}}}}
}
附近查询
附近查询,也叫做距离查询(geo_distance):查询到指定中心点小于某个距离值的所有文档。

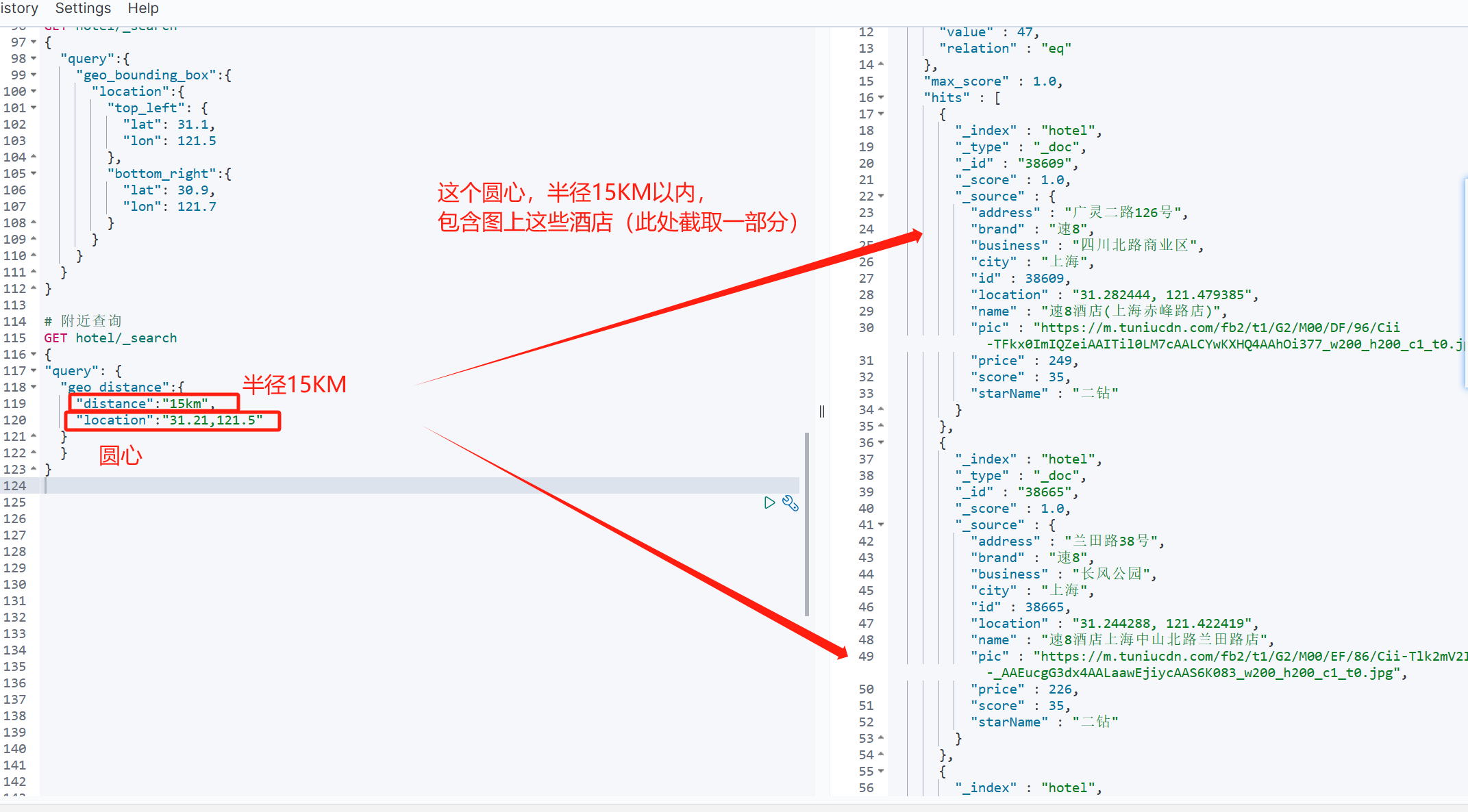
GET /indexName/_search
{"query": {"geo_distance": {"distance": "15km", // 半径"FIELD": "31.21,121.5" // 圆心}}
}
复合查询
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。常见的有两种:
- fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名
- bool query:布尔查询,利用逻辑关系组合多个其它的查询,实现复杂搜索
_scorc算分机制

当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
决定性因素:词条在文档中出现的次数。
比如:10个词条,其中5个是目标词条,得分肯定高了
10个词条,其中1个是目标词条,得分肯定低了


在后来的5.1版本升级中,elasticsearch将算法改进为BM25算法,公式如下:

改进的原因:
早期版本:分数取决于词条出现次数。出现次数越高,得分越高
目前版本:分数取决于词条出现次数。出现次数越高,得分越高,但是会根据算法得到一个上线,不会特别的高算分函数查询

function score 查询中包含四部分内容:- 原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
- 过滤条件:filter部分,符合该条件的文档才会重新算分
- 算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数- weight:函数结果是常量- field_value_factor:以文档中的某个字段值作为函数结果- random_score:以随机数作为函数结果- script_score:自定义算分函数算法
- 运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:- multiply:相乘- replace:用function score替换query score- 其它,例如:sum、avg、max、minfunction score的运行流程如下:- 1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- 2)根据过滤条件,过滤文档
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。因此,其中的关键点是:- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
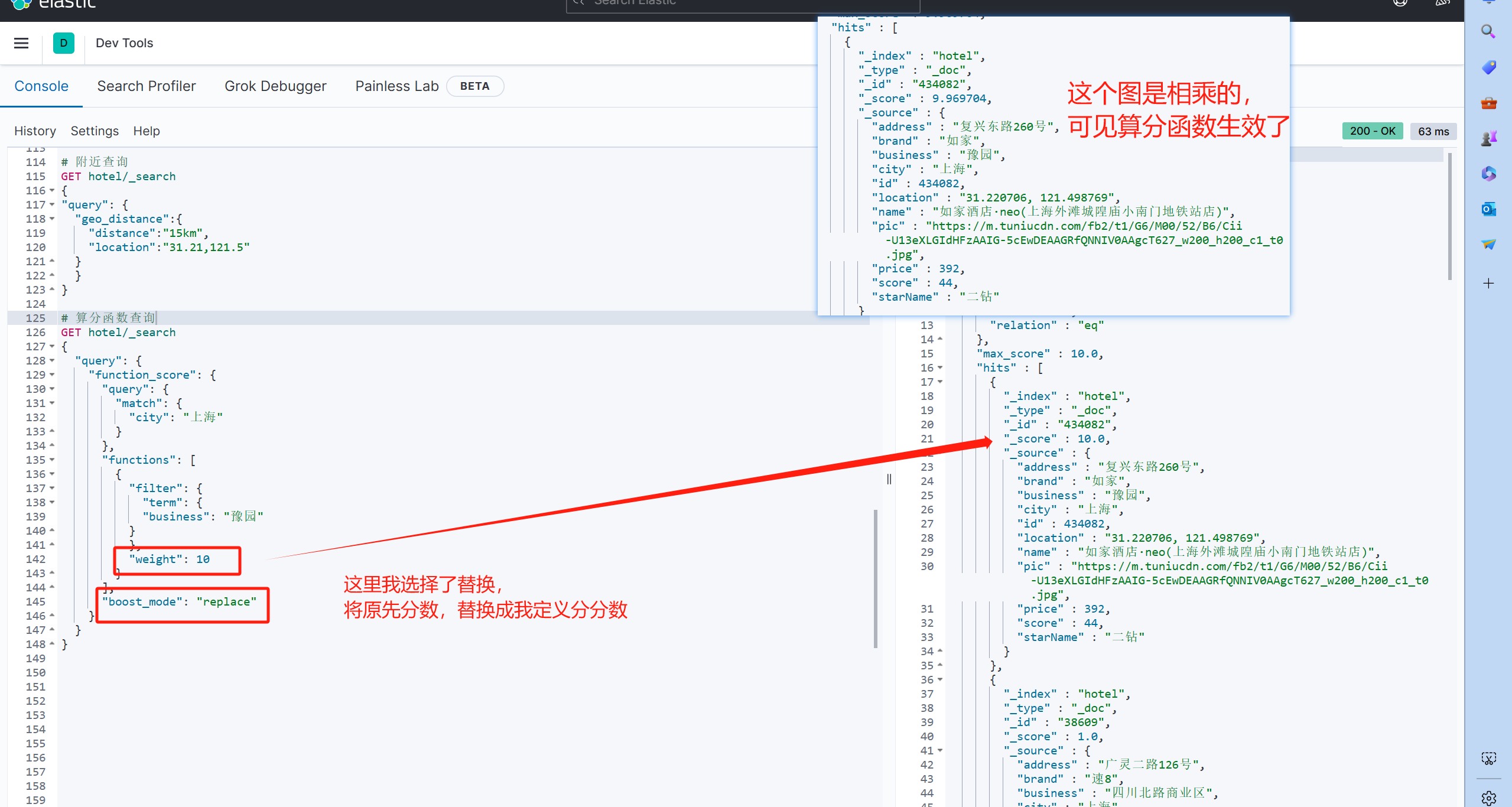
# 算分函数查询
GET hotel/_search
{"query": {"function_score": {"query": {"match": {"city": "上海"}},"functions": [{"filter": {"term": {"business": "豫园"}},"weight": 10}],"boost_mode": "replace"}}
}
布尔查询
(打分的字段越多,查询的性能也越差,所以适当使用filter)
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
- 搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
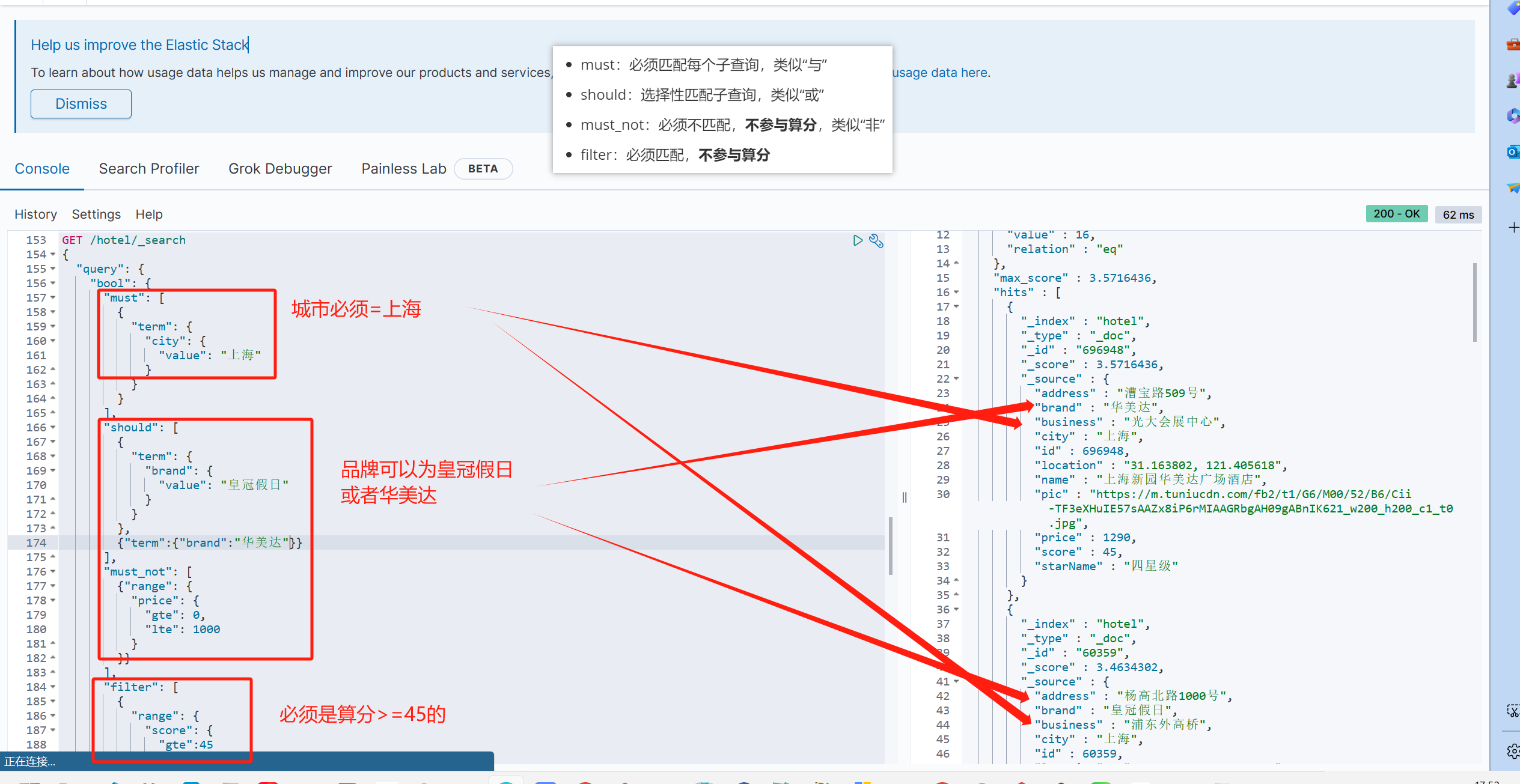
- 其它过滤条件,采用filter查询。不参与算分GET /hotel/_search
{"query": {"bool": {"must": [{"term": {"city": "上海" }}],"should": [{"term": {"brand": "皇冠假日" }},{"term": {"brand": "华美达" }}],"must_not": [{ "range": { "price": { "lte": 500 } }}],"filter": [{ "range": {"score": { "gte": 45 } }}]}}
}
排序
keyword、数值、日期类型好排
text待测试
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"FIELD": "desc" // 排序字段、排序方式ASC、DESC}]
}
分页
基本分页:
基本逻辑:
查询100-110条,共10条数据
1:先读取到100条
2:再往后读10条,到110
3:获取100-110条,这10条数据
当超过10000条,效率无比低下。不支持10000条以上的查询
GET /hotel/_search
{"query": {"match_all": {}},"from": 0, // 分页开始的位置,默认为0"size": 10, // 期望获取的文档总数"sort": [{"price": "asc"}]
}深度分页
问题一:同上
问题二:问题一的扩展版。当集群之后,如果操作集群中的数据,则需要先读取整个集群,再进行操作。
此时每个节点,都会读取大量数据,然后汇总,处理
A节点,读10000条,向下取10条
B节点同理
最后:所有节点的10条汇总,取前N条。执行了多次查询
GET hotel/_search
{"query": {"match": {"all": "外滩如家"}},"size": 3, "search_after": [379, "433576"],"sort": [{"price": {"order": "desc"}},{"id": {"order": "asc"}}]
}search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
核心:基于分页取值
高亮(关键字加标签)
高亮显示的实现分为两步:
- 1)给文档中的所有关键字都添加一个标签,例如<em>标签
- 2)页面给<em>标签编写CSS样式
高亮的核心:关键字加标签
- 高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
- 默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
- 如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
GET /hotel/_search
{"query": {"match": {"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询}},"highlight": {"fields": { // 指定要高亮的字段"FIELD": {"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}
JAVA客户端查询并解析
查询全部matchAllQuery
1:组装查询,发起请求()
1.1:request.source():根据需求点出来需要排序分页还是什么
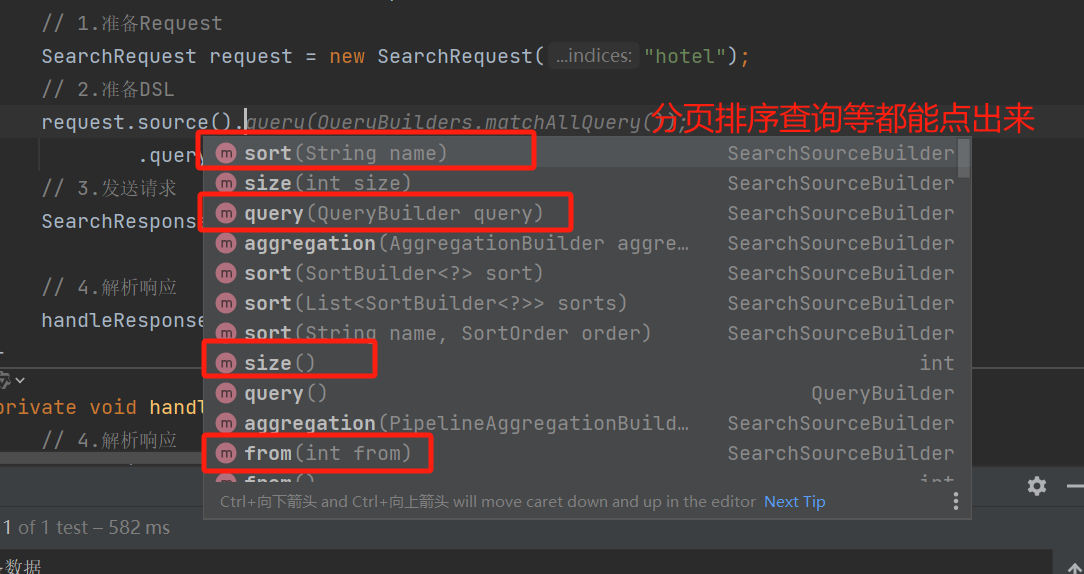
2:根据结构,层层解析
2.1:根据结构解析
2.2:返回数据为json,可以转java类等操作
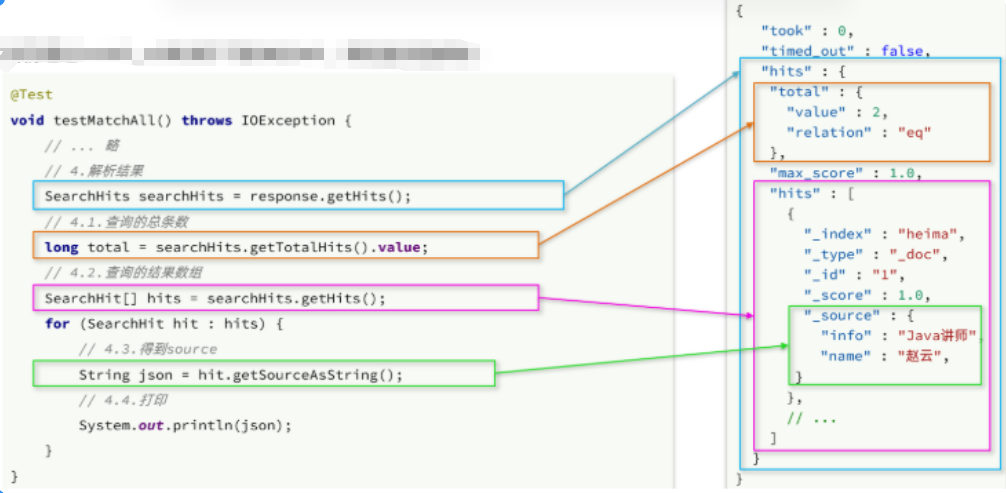
@Test
void testMatchAll() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSLrequest.source().query(QueryBuilders.matchAllQuery());// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}private void handleResponse(SearchResponse response) {// 4.解析响应SearchHits searchHits = response.getHits();// 4.1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 4.2.文档数组SearchHit[] hits = searchHits.getHits();// 4.3.遍历for (SearchHit hit : hits) {// 获取文档sourceString json = hit.getSourceAsString();// 反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println("hotelDoc = " + hotelDoc);}
}match查询
@Testvoid testMatch() throws IOException {SearchRequest request = new SearchRequest("hotel");//单字段查询request.source().query(QueryBuilders.matchQuery("all", "如家"));//多字段查询
// request.source().query(QueryBuilders.multiMatchQuery("外滩", "name","brand","business"));SearchResponse response = client.search(request, RequestOptions.DEFAULT);handleResponse(response);}单字段查询

多字段查询

精确查询及范围查询
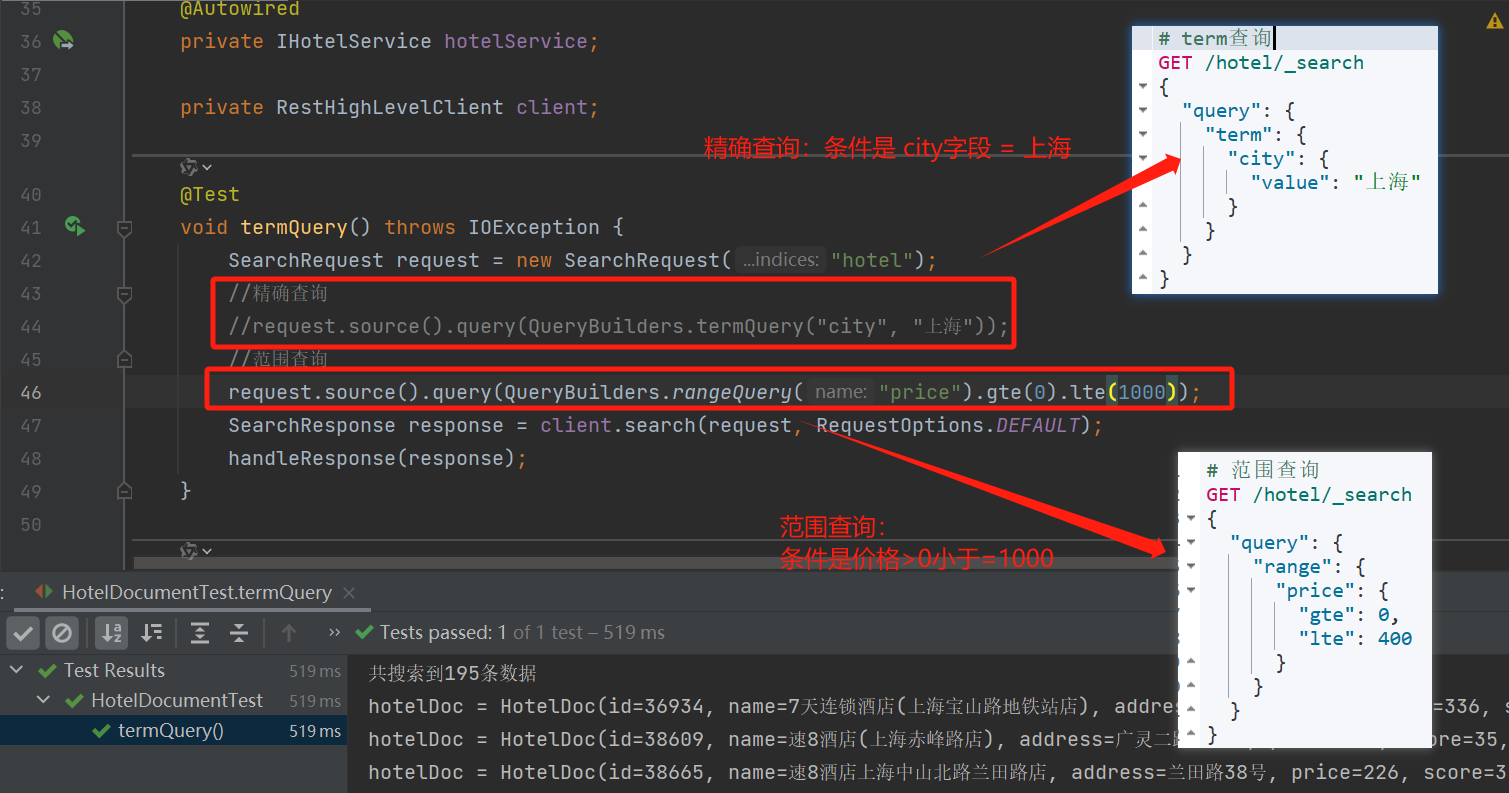
@Testvoid termQuery() throws IOException {SearchRequest request = new SearchRequest("hotel");//精确查询//request.source().query(QueryBuilders.termQuery("city", "上海"));//范围查询request.source().query(QueryBuilders.rangeQuery("price").gte(0).lte(1000));SearchResponse response = client.search(request, RequestOptions.DEFAULT);handleResponse(response);}布尔查询
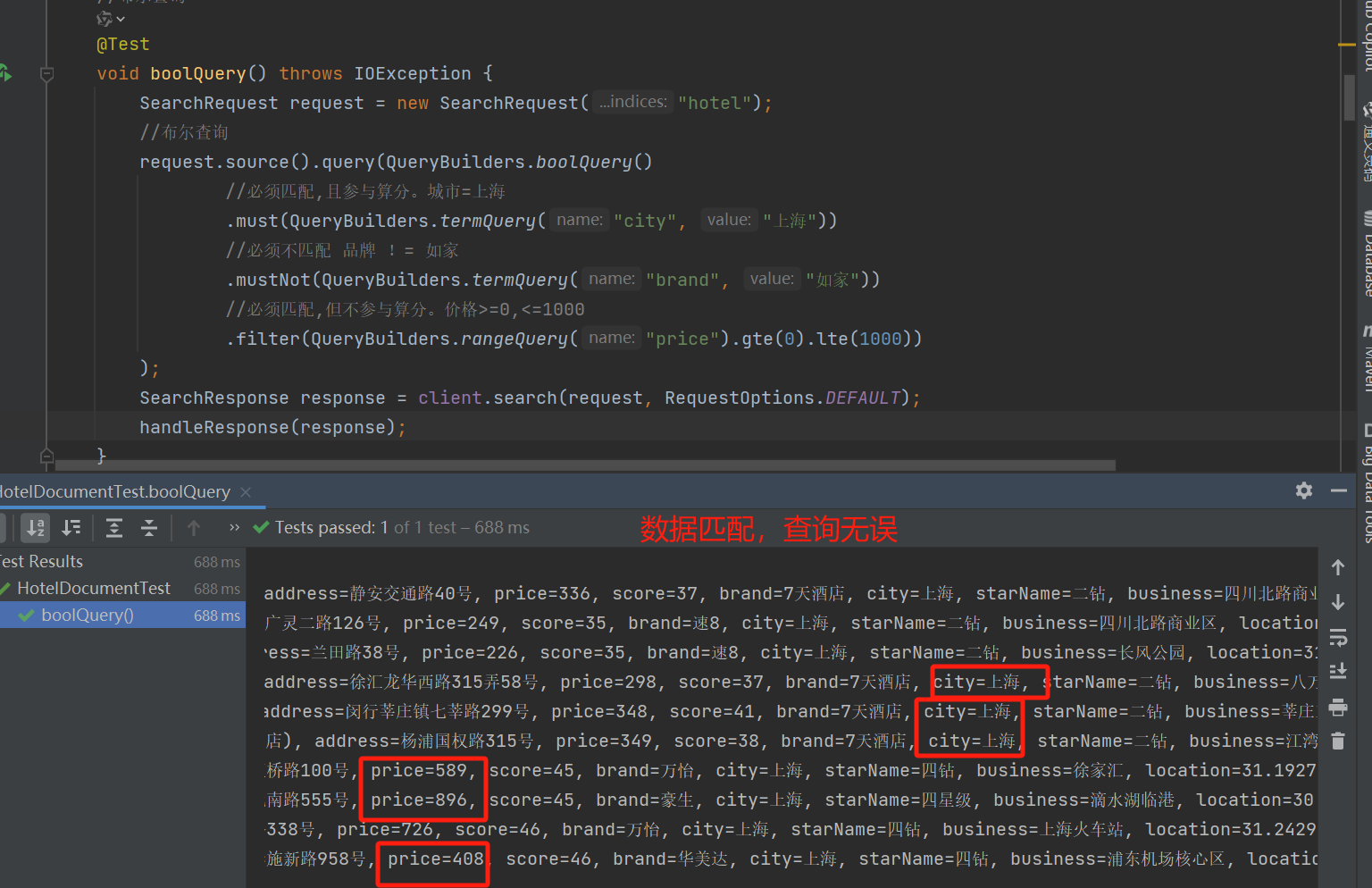
//布尔查询@Testvoid boolQuery() throws IOException {SearchRequest request = new SearchRequest("hotel");//布尔查询request.source().query(QueryBuilders.boolQuery()//必须匹配,且参与算分。城市=上海.must(QueryBuilders.termQuery("city", "上海"))//必须不匹配 品牌 != 如家.mustNot(QueryBuilders.termQuery("brand", "如家"))//必须匹配,但不参与算分。价格>=0,<=1000.filter(QueryBuilders.rangeQuery("price").gte(0).lte(1000)));SearchResponse response = client.search(request, RequestOptions.DEFAULT);handleResponse(response);}分页,排序
@Testvoid sortAndPage() throws IOException {// 页码,每页大小int page = 2, size = 5;//备注:这里什么查询条件都没写,所以会查询出所有数据。但是下文分,所以只会取5-10条数据SearchRequest request = new SearchRequest("hotel");//分页 这里是写死的 request.source().from((page - 1) * size).size(size);//排序 升序排序request.source().sort("price", SortOrder.ASC);SearchResponse response = client.search(request, RequestOptions.DEFAULT);handleResponse(response);}handleResponse
private void handleResponse(SearchResponse response) {// 4.解析响应SearchHits searchHits = response.getHits();// 4.1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 4.2.文档数组SearchHit[] hits = searchHits.getHits();// 4.3.遍历for (SearchHit hit : hits) {// 获取文档sourceString json = hit.getSourceAsString();// 反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println("hotelDoc = " + hotelDoc);}}高亮
高亮查询
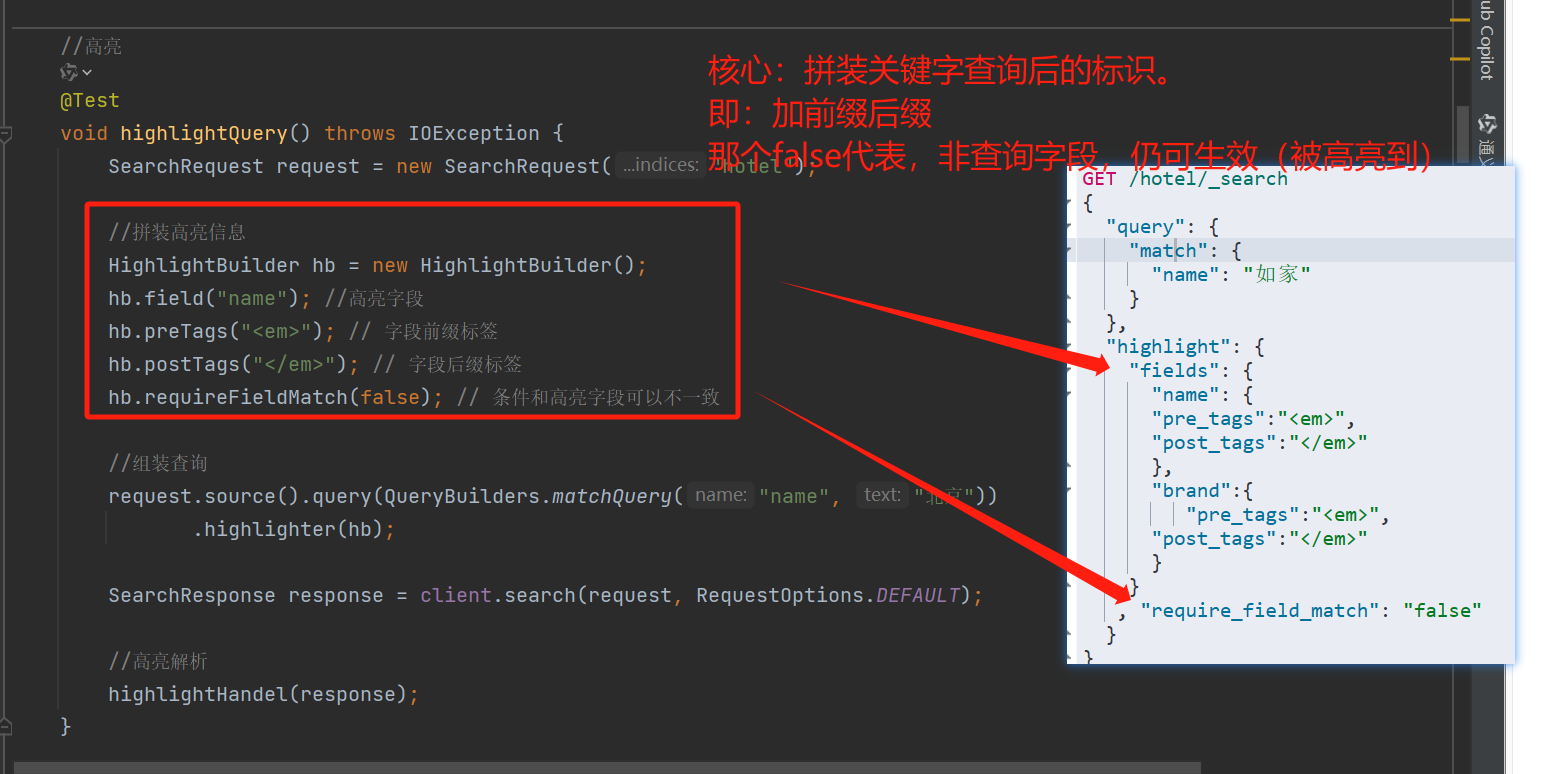
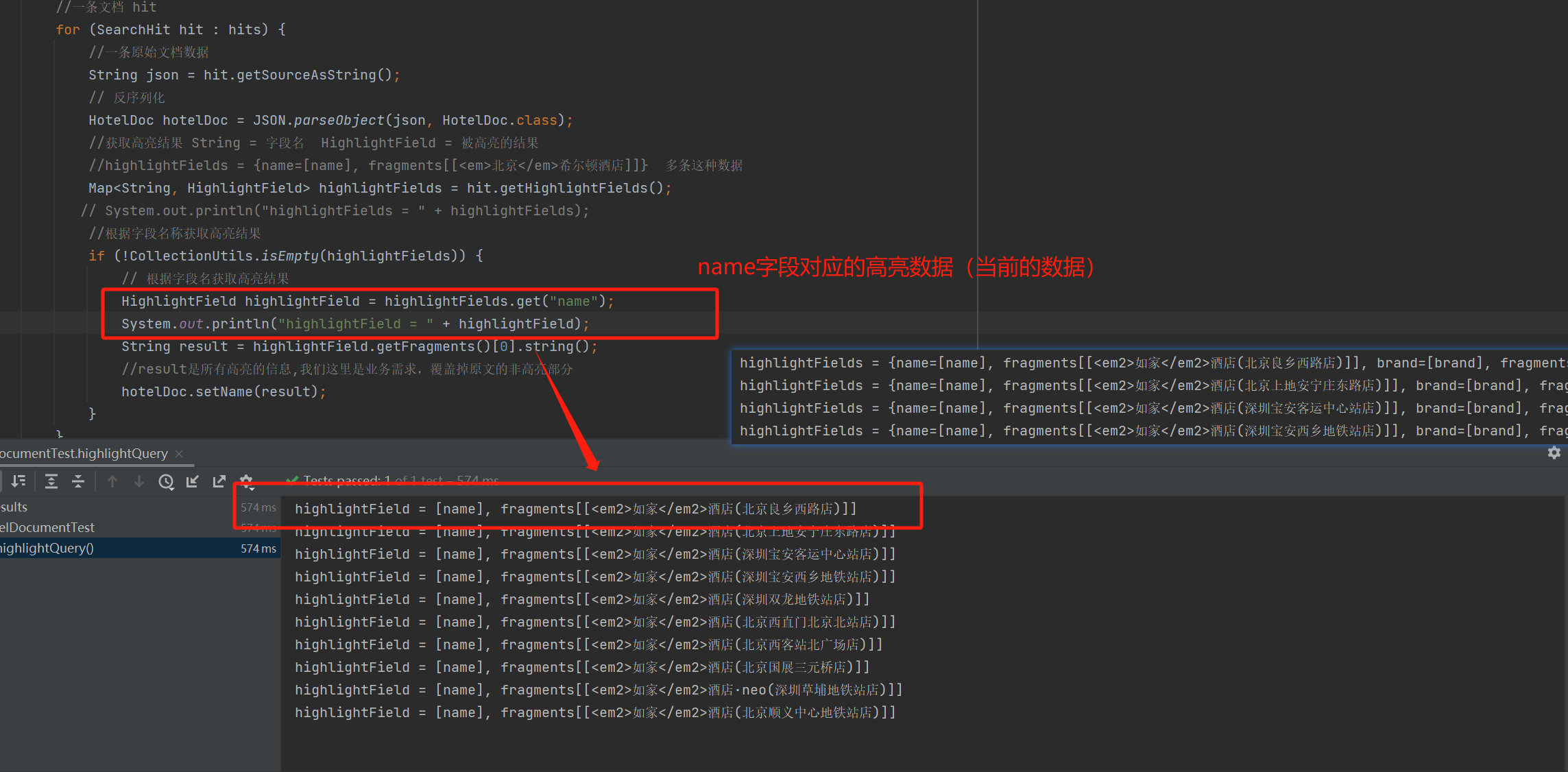
@Testvoid highlightQuery() throws IOException {SearchRequest request = new SearchRequest("hotel");//拼装高亮信息HighlightBuilder hb = new HighlightBuilder();hb.field("name"); //高亮字段hb.preTags("<em>"); // 字段前缀标签hb.postTags("</em>"); // 字段后缀标签hb.requireFieldMatch(false); // 条件和高亮字段可以不一致//组装查询request.source().query(QueryBuilders.matchQuery("name", "北京")).highlighter(hb);SearchResponse response = client.search(request, RequestOptions.DEFAULT);//高亮解析highlightHandel(response);}高亮解析

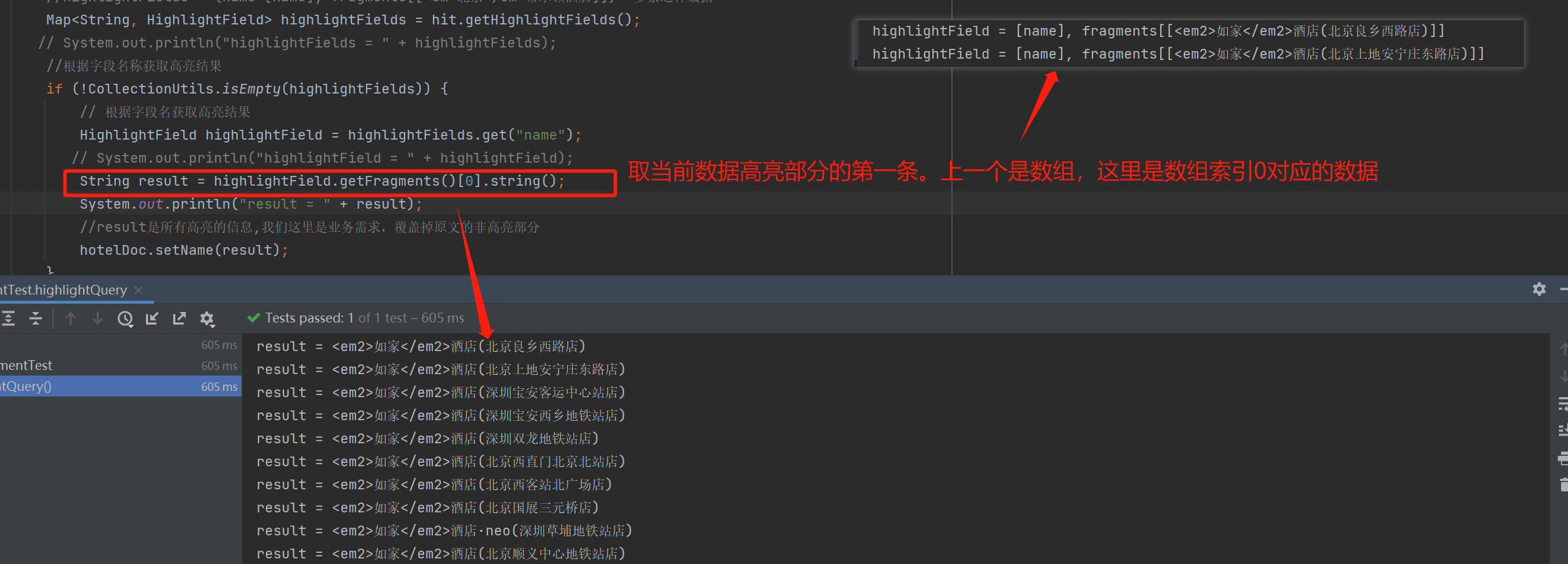
private void highlightHandel(SearchResponse response) {// 4.解析响应SearchHits searchHits = response.getHits();//获取总条数Long total = searchHits.getTotalHits().value;//文档数组SearchHit[] hits = searchHits.getHits();//一条文档 hitfor (SearchHit hit : hits) {//一条原始文档数据String json = hit.getSourceAsString();// 反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);//获取高亮结果 String = 字段名 HighlightField = 被高亮的结果//highlightFields = {name=[name], fragments[[<em>北京</em>希尔顿酒店]]} 多条这种数据Map<String, HighlightField> highlightFields = hit.getHighlightFields();//根据字段名称获取高亮结果if (!CollectionUtils.isEmpty(highlightFields)) {// 根据字段名获取高亮结果HighlightField highlightField = highlightFields.get("name");String result = highlightField.getFragments()[0].string();//result是所有高亮的信息,我们这里是业务需求,覆盖掉原文的非高亮部分hotelDoc.setName(result);}}}详细解释:

相关文章:
Java修仙传之神奇的ES2(巧妙的查询及结果处理篇)
SDL语句查询 查询的基本语法 GET /indexName/_search {"query": {"查询类型": {"查询条件": "条件值"}} } 根据文档id查询 #查询文档 GET hotel/_doc/36934 查询所有 会弹出该索引库下所有文档// 查询所有 GET /indexName/_searc…...

架构设计的课程资料
架构设计课 枫叶云笔记...

数据结构与算法C语言版学习笔记(5)-串,匹配算法、KMP算法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、串的定义二、串的存储结构1.顺序结构2.链式结构 三、串的朴素的模式匹配算法(暴力匹配算法)1.背景2.假设我们要从下面的主串 S"…...

新版HI3559AV100开发注意事项
新版HI3559AV100开发注意事项 一、在Hi3559A上使用openCV VideoCapture开启.mp4影像档, isOpened一直得到false 在Hi3559A上已经cross compile ffmepg 4.1openCV 3.4.4 但使用openCV VideoCapture开启.mp4影像档, isOpened一直得到false 请问要如何知道是什么原因无法开启影像…...
Django(一、简介,安装与使用)
文章目录 一、Django引入1.web应用程序什么是web?web引用程序的优点web应用程序的缺点什么是web框架 2.纯手写web框架1.web框架的本质2.HTTP协议的特性:3.编写基于wsgire模块搭建web框架代码封装优化代码封装 二、Django框架的学习1.Python中的主流框架2…...
【Linux C IO多路复用】多用户聊天系统
目录 Server-Client mutiplexingServer mutiplexingClient mutiplexing Server-Client 在Linux系统中,IO多路复用是一种机制,它允许一个进程能够监视多个文件描述符(sockets、pipes等)的可读、可写和异常等事件。这样…...
JSON——数组语法
一段JSON可能是以 ”{“ 开头 也可能仅包含一段JSON数组 如下 [ { "name" : "hello,world"}, {"name" : "SB JSON”}, {“name” : "SB互联网房地产CNM“}, ] 瞧,蛋疼不...CJSON过来还是得搜下网…...

运营商大数据精准获客:我们提供精准客源渠道的最大资源体?
运营商大数据精准营销 谈起精准获客,竞争对手永远是为我们提供精准客源渠道的最大资源体! 最新的获客方式,就是从竞争对手的手中把他们的精准客户资源变为自己的。 今年最火的运营商大数据精准营销是拒绝传统营销方式的烧钱推广࿰…...
表象变换与矩阵元
表象变换 一维粒子哈密顿量 表象中的矩阵元 态的表象变换 不难证明 算符的表象变换 坐标表象 Non-denumerable basis...

vue乾坤微前端项目
1、主应用 安装乾坤 npm i qiankun -S 注册微应用并启动: import { registerMicroApps, start } from qiankun;//设置两个微应用 registerMicroApps([{name: vue1, //要跟package.json中的name保持一致entry: //localhost:8081, //本地就这么写container: #cont…...
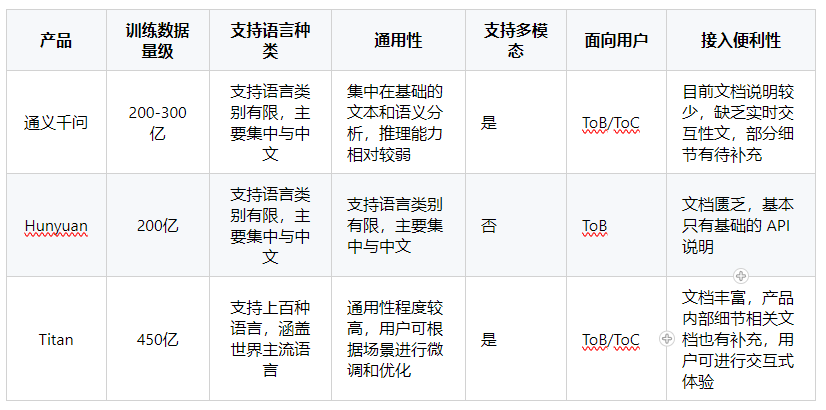
大语言模型比武
今年随着 ChatGPT 的流行,并在各个领域有一定程度生产级别的应用。国内外也掀起了一股大语言模型浪潮,各大厂商都推出了自己的大语言模型,阿里推出了 通义千问,腾讯推出了 Hunyuan,亚马逊云推出了 Titan,大…...

王道数据结构第五章二叉树的遍历第13题
目录 解题思路 宏定义 二叉树定义 栈定义 实现函数 测试代码 测试结果...

微服务的发展历程的详细说明及每个阶段主流的架构和组件
微服务的发展历程的详细说明及每个阶段主流的架构和组件如下: 一、微服务的发展历程: 起始阶段:这个阶段主要是面向服务的架构(SOA)的兴起。此时,企业开始尝试将单体应用拆分为多个服务,但此时…...
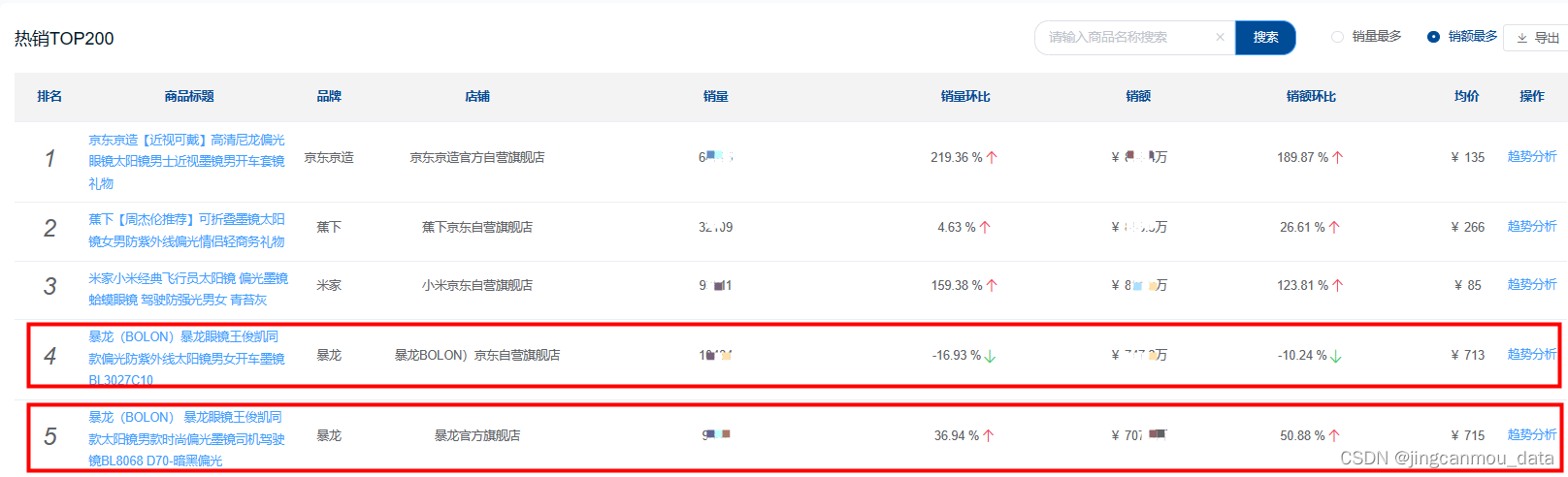
2023年眼镜行业分析(京东眼镜销量数据分析):市场规模同比增长26%,消费需求持续释放
随着我国经济的不断发展,电子产品不断普及,低龄及老龄人口的用眼场景不断增多,不同年龄阶段的人群有不同的视力问题,因此,视力问题人口基数也随之不断加大,由此佩戴眼镜的人群也不断增多。 同时,…...
基础课26——业务流程分析方法论
基础课25中我们提到业务流程分析方法包括以下几种: 价值链分析法:主要是找出或设计出哪些业务能够使得客户满意,实现客户价值最大化的业务流程。要进行价值链分析的时候可以从企业具体的活动进行细分,细分的具体方面可以从生产指…...

【数字图像处理-TUST】实验二-图像噪声生成与滤波降噪
一,题目 读入一幅图像使用两种以上的方法向图像中分别添加噪声输出一幅二值图像,背景为黑色,噪声区域为白色使用三种滤波方法对上述添加了噪声的图像进行降噪处理输出降噪处理后的结果图像 二,实验原理 采用了两种方法添加了噪…...
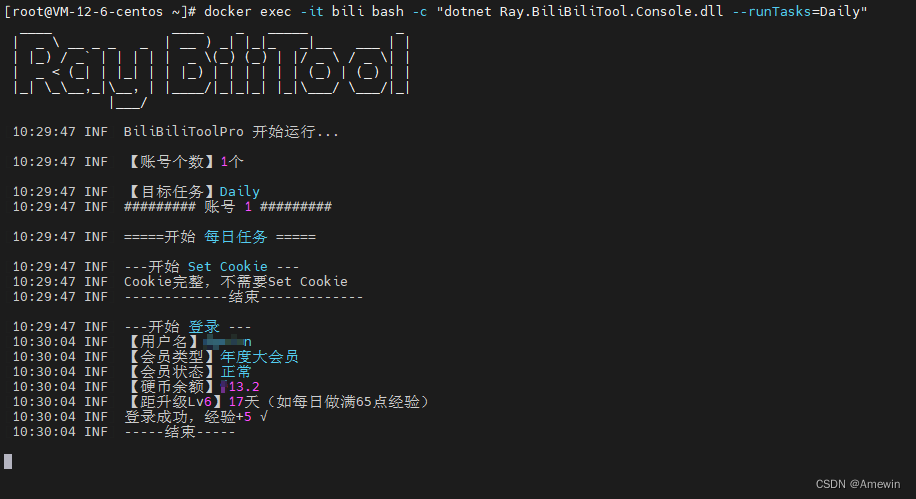
bilibili快速升满级(使用Docker 容器脚本)
部署bilibili升级运行容器脚本 docker run --name"bili" -v /bili/Logs:/app/Logs -e Ray_DailyTaskConfig__Cron"30 9 * * *" -e Ray_LiveLotteryTaskConfig__Cron"40 9 * * *" -e Ray_UnfollowBatchedTaskConfig__Cron"…...
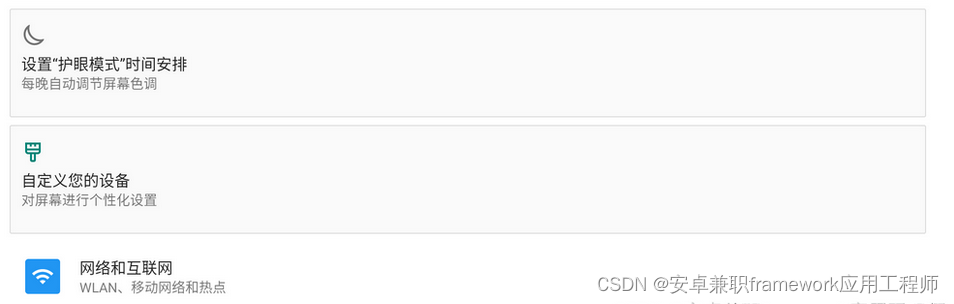
Android 13.0 Settings主页面去掉FocusRecyclerView相关功能
1.前言 在13.0的系统rom产品定制化开发中,在系统Settings主页面的主菜单中,在测试某些功能的时候,比如开启护眼模式和改变系统密度会在主菜单第一项的网络菜单头部增加 自定义您的设备和设置护眼模式时间安排 等等相关的设置模块 这对于菜单布局显示相当不美观,所以根据系…...

Python(四)字符串
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…...

WPF中ElementName与RelativeSource绑定的局限性以及对策
完全来源于十月的寒流,感谢大佬讲解 <Window x:Class"Test_01.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml"xmlns:d"http://schem…...

智能体开发框架深度解析:从模块化设计到工程实践
1. 项目概述:从代码仓库到智能体开发框架的深度解构最近在GitHub上看到一个名为wshobson/agents的仓库,热度不低。乍一看标题“agents”,很容易让人联想到当下火热的AI智能体(Agent)领域。但作为一个在软件开发和AI应用…...

Bebas Neue:开源几何无衬线字体在现代化设计中的技术架构与应用实践
Bebas Neue:开源几何无衬线字体在现代化设计中的技术架构与应用实践 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue Bebas Neue是一款基于SIL Open Font License v1.1许可证的免费开源显示字体&#…...

告别“唯大厂论”:全球财富 500 强实体企业 IT 核心岗位的隐形红利
在当前的留学生家庭中,关于计算机科学(CS)与工程类专业的就业规划,往往笼罩着一种高度趋同的“名企焦虑”。许多家长和学生将目光死死锁定在硅谷的科技巨头或少数几家头部互联网大厂上。为了挤进这些竞争白热化的窄门,…...

2025届必备的AI学术助手横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek DeepSeek身为人工智能写作工具,能对学术论文撰写流程予以有效支撑,于…...
)
MCP 2026调度策略迁移避坑指南,12个生产环境血泪案例(含某TOP3云厂商未公开故障复盘)
更多请点击: https://intelliparadigm.com 第一章:MCP 2026调度策略迁移的底层逻辑与演进全景 MCP(Multi-Cluster Policy)2026调度策略并非简单配置升级,而是面向异构算力联邦、跨云服务网格与实时SLA保障的范式重构。…...

WPS-Zotero集成方案:跨平台科研写作工作流优化
WPS-Zotero集成方案:跨平台科研写作工作流优化 【免费下载链接】WPS-Zotero An add-on for WPS Writer to integrate with Zotero. 项目地址: https://gitcode.com/gh_mirrors/wp/WPS-Zotero WPS-Zotero插件为科研工作者提供了跨平台文献管理集成方案&#x…...

SuperDesign:IDE内AI设计助手,自然语言生成UI与代码
1. 项目概述:当AI设计助手住进你的代码编辑器如果你和我一样,是个对UI设计有点“手残”但又有完美主义倾向的开发者,那今天聊的这个工具,你可能会觉得相见恨晚。它就是SuperDesign,一个直接运行在你IDE(比如…...

高层次综合设计流程
一、高层次设计流程 1.高层次综合的基本介绍和说明 2.C语言验证 3.接口的综合 4.任意精度类型 5.设计的分析和优化 6.RTL验证 7.hls的ip core的集成 8.在zynq的soc中使用hls ip core 9.在microblaze中使用hls ip core二、ug871中内容 1.设计流程 2.接口综合 3.优化方法 包括工程…...

图记忆技术解析:构建能联想与推理的AI记忆系统
1. 项目概述:当图神经网络遇上记忆增强如果你在构建一个复杂的问答系统、一个需要长期追踪用户行为的推荐引擎,或者一个能理解多轮对话的智能体,你可能会遇到一个共同的瓶颈:模型如何记住并利用那些跨越时间、分散在不同对话或文档…...

2026年权威发布:AI搜索优化源头服务商深度测评,杭州7大GEO优化解决方案避坑指南
在2026年的今天,AI搜索已成为企业获取精准流量、建立用户心智的首要入口。传统搜索引擎优化(SEO)的逻辑正在被生成式引擎优化(GEO)快速迭代,其核心从“匹配关键词”转向“成为标准答案”。面对这一剧变&…...