(pytorch进阶之路)Informer
论文:Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (AAAI’21 Best Paper)
看了一下以前的论文学习学习,我也是重应用吧,所以代码部分会比较多,理论部分就一笔带过吧
论文作者也很良心的给出了colab,就大大加快了看源码是怎么实现的速度:https://colab.research.google.com/drive/1_X7O2BkFLvqyCdZzDZvV2MB0aAvYALLC
那么源码主要看什么呢,首先是issue,github的issue里面如果压根就跑不了,那就不用花时间了,如果没太大的错误说明代码没有致命的错误
第二步是看数据,源数据是什么,数据如何预处理
第三步看模型实现,一般就在model文件夹下面,这一步比较简单,重点看创新点部分如何实现的
第四步pth,看看复现结果
文章目录
- 模型框架
- 代码地址
模型框架
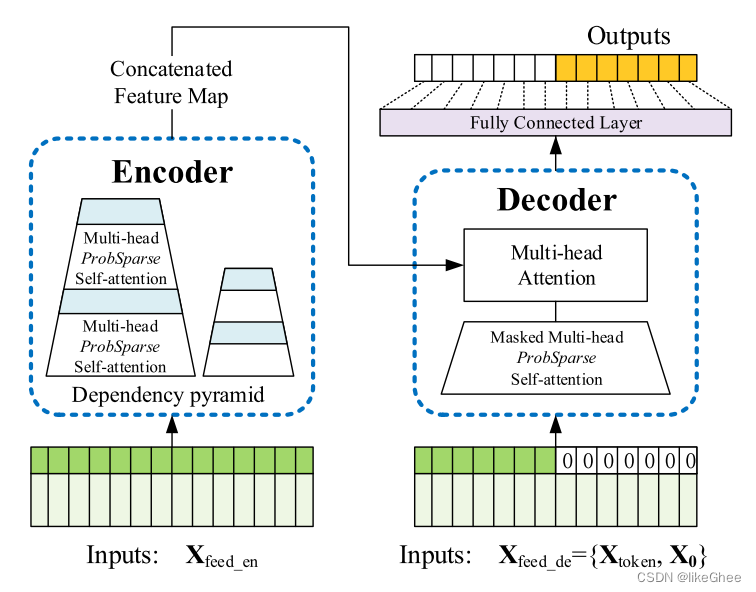
创新点:ProbSparse Attention
主要思想就是用top-k选择最有用的信息
代码地址
https://github.com/zhouhaoyi/Informer2020
下载好代码和数据,仔细阅读Data的说明,我们得知得把数据放到data/ETT文件夹下面
parser部分大致看看什么意思,model,data,root_path,data_path,单卡多卡和num_workers设置一下,结合上下文推测大致的意思,同时github里面提供了数据字典,我们至少需要修改data和data_path参数
由于我是windows上debug的,所以args如果是required=True的话参数需要我们手动填就很麻烦,个人习惯就都改成False先
右键运行成功,那么就可以逐步debug了
main_informer.py运行,逐渐运行到
exp.train(setting)
进入train函数
train_data, train_loader = self._get_data(flag='train')vali_data, vali_loader = self._get_data(flag='val')test_data, test_loader = self._get_data(flag='test')
首先_get_data取数据,进入函数看看,data_dict里面看到了Dataset_Custom,就知道它是可以自定义数据的,后面实例化dataset,实例化dataset再实例化dataloader,数据集做好了
dataset中看看怎么预处理数据的,dataset里面有__read_data__和__getitem__函数,上下文分析__read_data__就是预处理的步骤,因为看到了StandardScaler,里面做了一个标准化
time_features函数对时间维度做特征编码,思想很简单,但是代码写特别复杂
最后构造dataloader
往下走到epoch开始迭代训练数据,到_process_one_batch函数
pred, true = self._process_one_batch(train_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
_process_one_batch进一步处理数据和输入进model,dec_input先全0或者全1进行初始化
然后enc_inputh后面48个和dec_input按dim=1维度进行拼接
dec_input前面的48个就是时序的观测值,我们要预测后面的24个
model输入是96,12的enc_input,enc_mark是96,4时间编码特征
dec_input是72,12,dec_mark是72,4
model 部分
主要是attention模块(其他都比较简单),在model/attn.py,看ProbAttention class,直接看forward函数
首先划分QKV,96个seqlen中选25个(U_part)
重点来了,_prob_QK函数
scores_top, index = self._prob_QK(queries, keys, sample_k=U_part, n_top=u)
进入_prob_QK
首先K扩充了-3的维度,K_expand=(32,8,96,96,64)
index_sample随机采样出0~96的96×25的矩阵,K_sample取出(32,8,96,25,64)
Q和K_sample计算内积的到Q_K_sample(32,8,96,25)
Q_K_sample上计算max,选出M_top个max波峰最大的Q,得到Q_reduce(25个Q)
Q_reduce再和96个K做内积
def _prob_QK(self, Q, K, sample_k, n_top): # n_top: c*ln(L_q)# Q [B, H, L, D]B, H, L_K, E = K.shape_, _, L_Q, _ = Q.shape# calculate the sampled Q_KK_expand = K.unsqueeze(-3).expand(B, H, L_Q, L_K, E)index_sample = torch.randint(L_K, (L_Q, sample_k)) # real U = U_part(factor*ln(L_k))*L_qK_sample = K_expand[:, :, torch.arange(L_Q).unsqueeze(1), index_sample, :]Q_K_sample = torch.matmul(Q.unsqueeze(-2), K_sample.transpose(-2, -1)).squeeze(-2)# find the Top_k query with sparisty measurementM = Q_K_sample.max(-1)[0] - torch.div(Q_K_sample.sum(-1), L_K)M_top = M.topk(n_top, sorted=False)[1]# use the reduced Q to calculate Q_KQ_reduce = Q[torch.arange(B)[:, None, None],torch.arange(H)[None, :, None],M_top, :] # factor*ln(L_q)Q_K = torch.matmul(Q_reduce, K.transpose(-2, -1)) # factor*ln(L_q)*L_kreturn Q_K, M_top
_get_initial_context函数显示了如果没有选择到的Q,说明比较平庸,直接用平均V来表示
V_sum = V.mean(dim=-2)
_update_context
只更新25个Q
context_in[torch.arange(B)[:, None, None],torch.arange(H)[None, :, None],index, :]\= torch.matmul(attn, V).type_as(context_in)
attention做完
回到forward,做了一个蒸馏操作,MaxPool1d,stride=2,做个下采样
96len变成48len
ConvLayer((downConv): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,), padding_mode=circular)(norm): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(activation): ELU(alpha=1.0)(maxPool): MaxPool1d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
encoder做完
做decoder,用的模块和encoder一致,还有一个cross attention,都老生常谈,跳过…
相关文章:
(pytorch进阶之路)Informer
论文:Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (AAAI’21 Best Paper) 看了一下以前的论文学习学习,我也是重应用吧,所以代码部分会比较多,理论部分就一笔带过吧 论文作者也很良心的…...
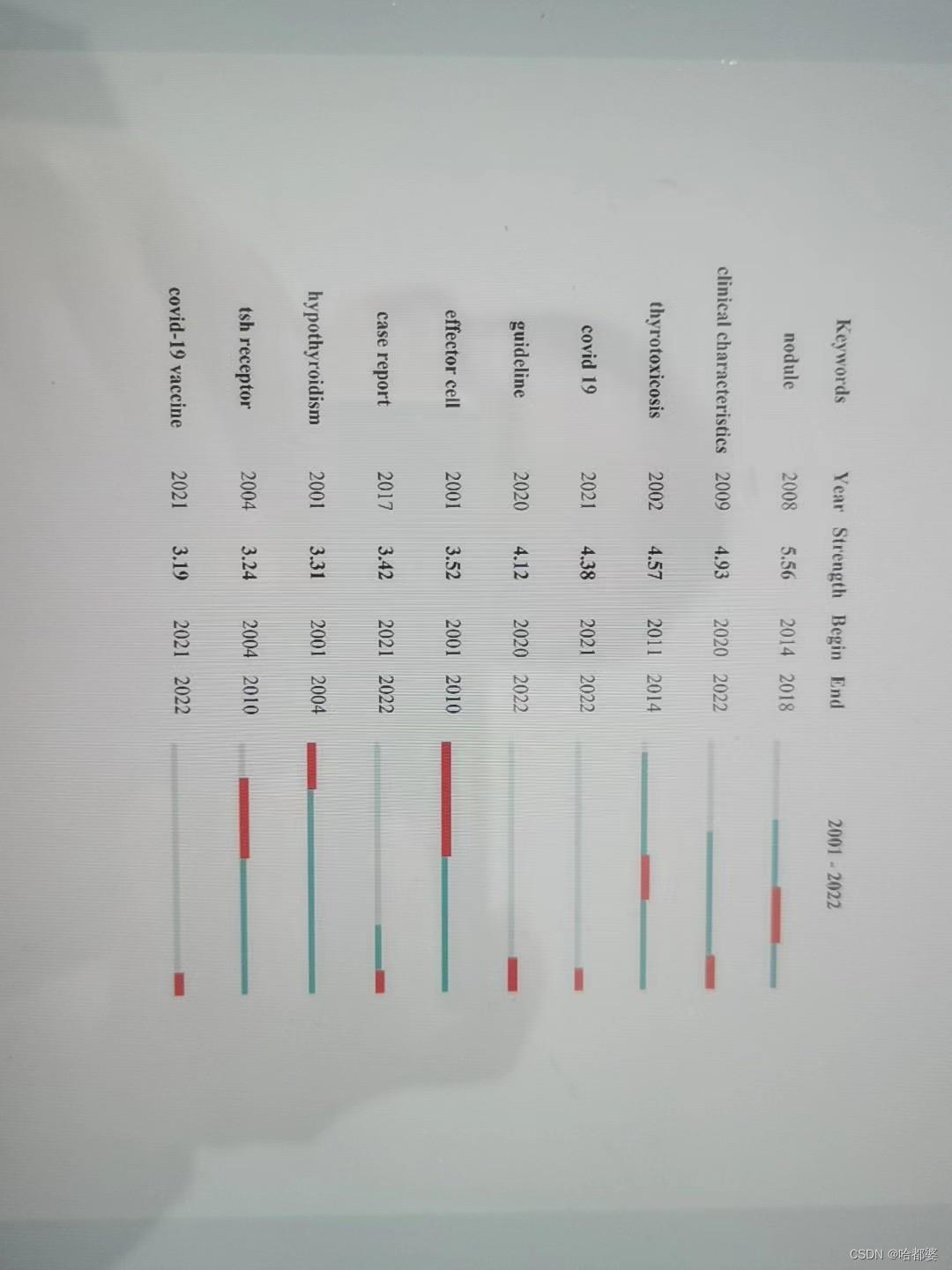
关键词聚类和凸现分析-实战1——亚急性甲状腺炎的
审稿人问题第8页第26行-请指出#是什么意思,并解释为什么亚急性甲状腺炎在这里被列为#8。我认为在搜索亚急性甲状腺炎相关文章时,关键词共现分析应该提供关键词共现的数据。这些结果的实际用途是什么?亚急性甲状腺炎是一种较为罕见但重要的甲状腺疾病&am…...

二叉树——二叉搜索树中的众数
二叉搜索树中的众数 链接 给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。 如果树中有不止一个众数,可以按 任意顺序 返回。 假定…...
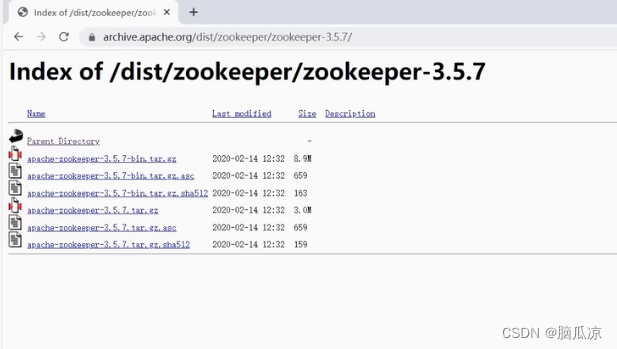
安装_配置参数解读_集群安装配置_启动选举_搭建启停脚本---大数据之ZooKeeper工作笔记004
这里首先下载zookeeper安装包,可以看到官网地址 找到download 点击下载 找到老一点的,我们找3.5.7 in the archive 点击 然后这里找到3.5.7这一个 然后下载这个-bin.tar.gz这个...
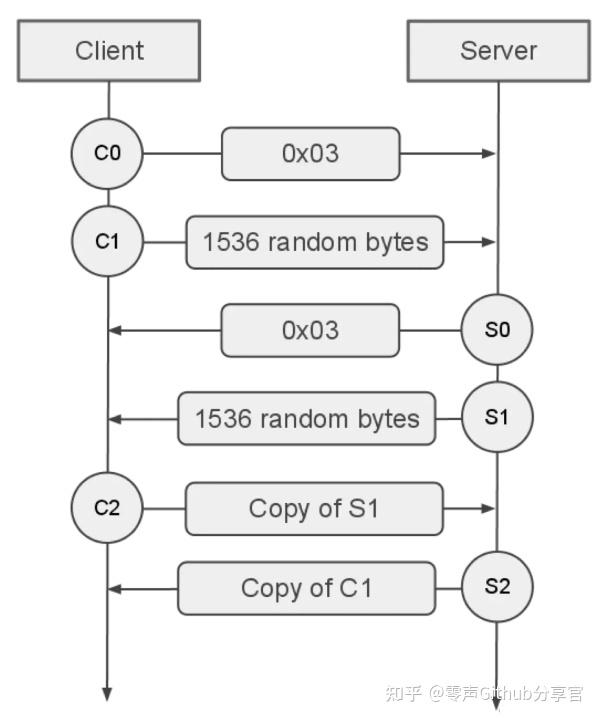
RTMP的工作原理及优缺点
一.什么是RTMP?RTMP(Real-Time Messaging Protocol,实时消息传输协议)是一种用于低延迟、实时音视频和数据传输的双向互联网通信协议,由Macromedia(后被Adobe收购)开发。RTMP的工作原理是&#…...

【数据结构与算法】——第八章:排序
文章目录1、基本概念1.1 什么是排序1.2 排序算法的稳定性1.3 排序算法的分类1.4 内排序的方法2、插入排序2.1 直接插入排序2.2 直接插入排序2.3 希尔排序3、交换排序3.1 冒泡排序3.2 快速排序4、选择排序4.1 简单选择排序4.2 树形选择排序4.3 堆排序4.4 二路归并排序5、基数排序…...

在linux中web服务器的搭建与配置
以下涉及到的linux命令大全查阅 https://www.runoob.com/linux/linux-command-manual.htmlvim命令查阅 https://www.runoob.com/linux/linux-vim.htmlscp命令https://www.runoob.com/linux/linux-comm-scp.html首先要有一个请求的服务地址用ssh 进入到linux系统中ssh 请求的服务…...
《Python机器学习》基础代码2
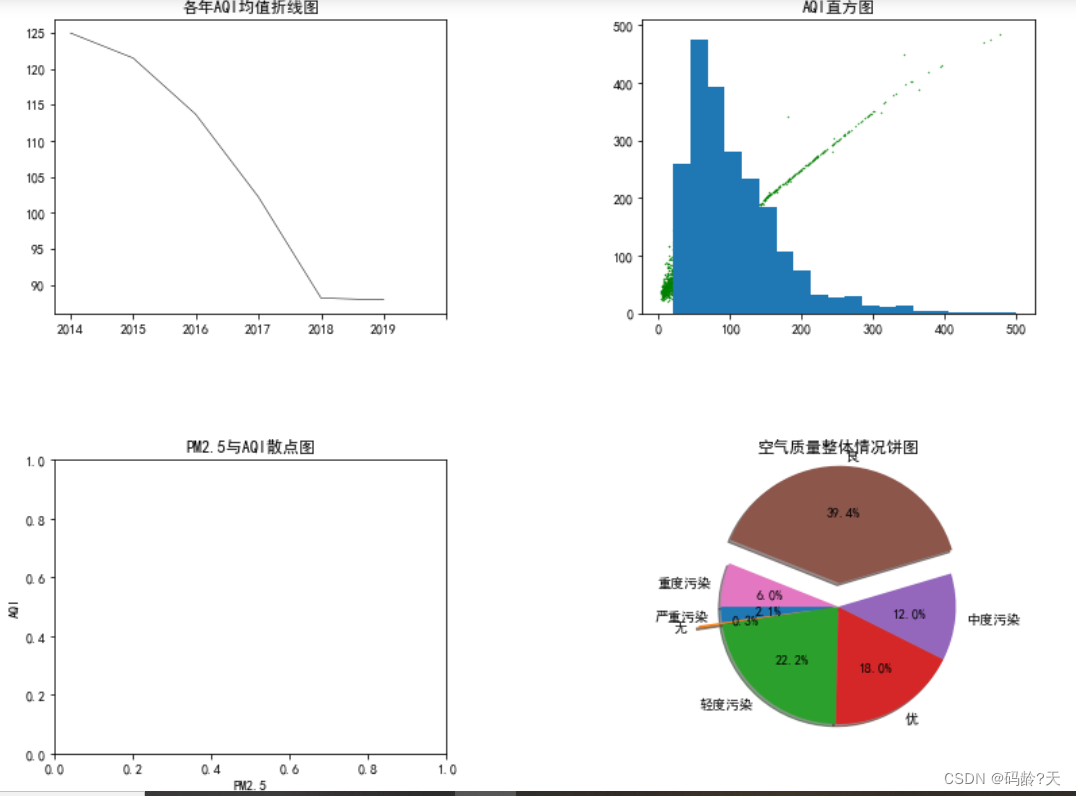
👂 逝年 - 夏小虎 - 单曲 - 网易云音乐 目录 👊Matplotlib综合应用:空气质量监测数据的图形化展示 🌼1,AQI时序变化特点 🌼2,AQI分布特征 相关性分析 🌼3,优化图形…...

如何基于MLServer构建Python机器学习服务
文章目录前言一、数据集二、训练 Scikit-learn 模型三、基于MLSever构建Scikit-learn服务四、测试模型五、训练 XGBoost 模型六、服务多个模型七、测试多个模型的准确性总结参考前言 在过去我们训练模型,往往通过编写flask代码或者容器化我们的模型并在docker中运行…...

9.1 IGMPv1实验
9.4.1 IGMPv1 实验目的 熟悉IGMPv1的应用场景掌握IGMPv1的配置方法实验拓扑 实验拓扑如图9-7所示: 图9-7:IGMPv1 实验步骤 (1)配置IP地址 MCS1的配置 MCS1的IP地址配置如图9-8所示: 图9-8:MCS1的配置 …...

软考高级系统分析师系列论文之十:论实时控制系统与企业信息系统的集成在通信业应用
软考高级系统分析师系列论文之十:论实时控制系统与企业信息系统的集成在通信业应用 一、摘要二、正文三、总结一、摘要 近年来,在应用需求的强大驱动下,我国通信业有了长足的进步。现有通信行业中的许多企业单位,如电信公司或移动集团,其信息系统的主要特征之一是对线路的…...
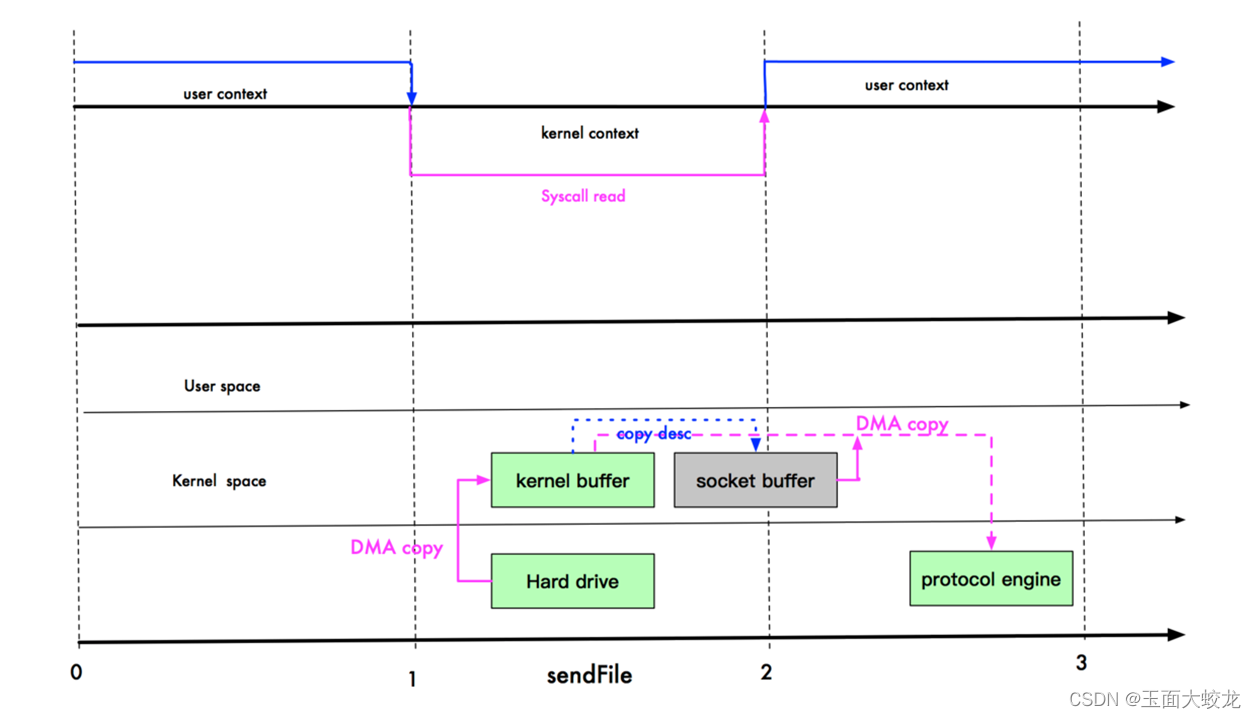
NIO与零拷贝
目录 一、零拷贝的基本介绍 二、传统IO数据读写的劣势 三、mmap优化 四、sendFile优化 五、 mmap 和 sendFile 的区别 六、零拷贝实战 6.1 传统IO 6.2 NIO中的零拷贝 6.3 运行结果 一、零拷贝的基本介绍 零拷贝是网络编程的关键,很多性能优化都离不开。 在…...
)
【PAT甲级题解记录】1151 LCA in a Binary Tree (30 分)
【PAT甲级题解记录】1151 LCA in a Binary Tree (30 分) 前言 Problem:1151 LCA in a Binary Tree (30 分) Tags:树的遍历 并查集 LCA Difficulty:剧情模式 想流点汗 想流点血 死而无憾 Address:1151 LCA in a Binary Tree (30 分…...

Android 获取手机语言环境 区分简体和繁体,香港,澳门,台湾繁体
安卓和IOS 系统语言都是准守:ISO 639 ISO 代码表IOS:plus.os.language ios正常,安卓下简体和繁体语言,都是zh安卓获取系统语言方法:Locale.getDefault().language手机切换到繁体(台湾,香港&…...

一文搞懂Python时间序列
Python时间序列1. datetime模块1.1 datetime对象1.2 字符串和datatime的相互转换2. 时间序列基础3. 重采样及频率转换4. 时间序列可视化5. 窗口函数5.1 移动窗口函数5.2 指数加权函数5.3 二元移动窗口函数时间序列(Time Series)是一种重要的结构化数据形…...
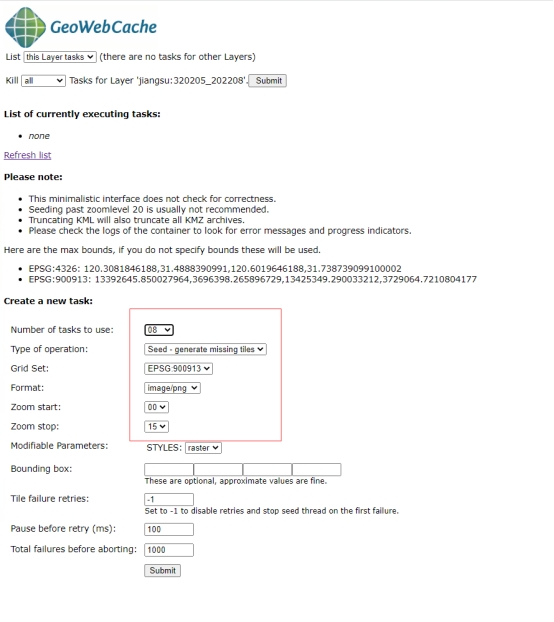
GeoServer发布数据进阶
GeoServer发布数据进阶 GeoServer介绍 GeoServer是用于共享地理空间数据的开源服务器。 它专为交互操作性而设计,使用开放标准发布来自任何主要空间数据源的数据。 GeoServer实现了行业标准的 OGC 协议,例如网络要素服务 (WFS)…...
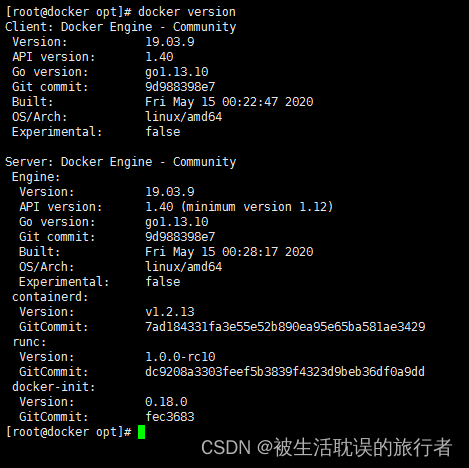
Docker离线部署
Docker离线部署 目录 1、需求说明 2、下载docker安装包 3、上传docker安装包 4、解压docker安装包 5、解压的docker文件夹全部移动至/usr/bin目录 6、将docker注册为系统服务 7、重启生效 8、设置开机自启 9、查看docker版本信息 1、需求说明 大部份公司为了服务安全…...
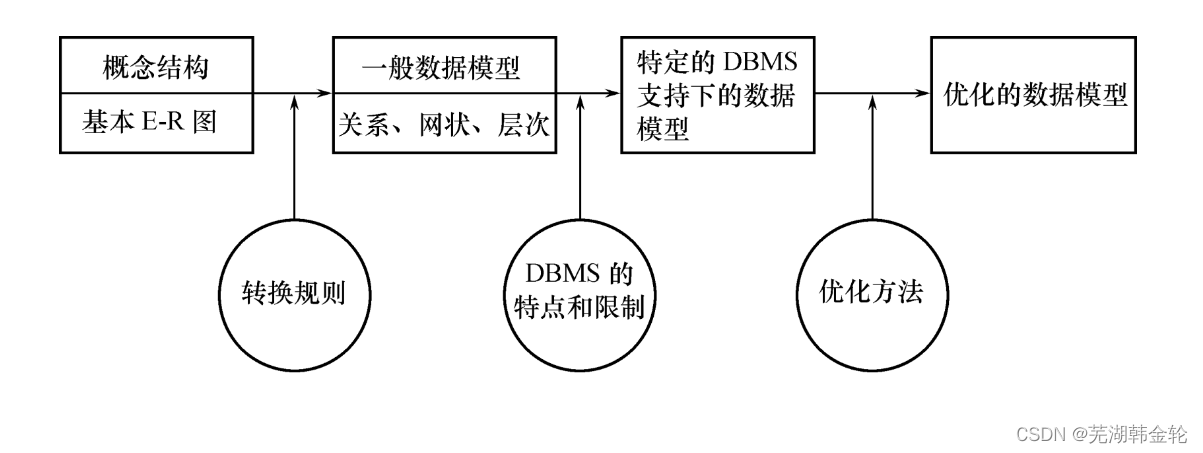
《数据库系统概论》学习笔记——第七章 数据库设计
教材为数据库系统概论第五版(王珊) 这一章概念比较多。最重点就是7.4节。 7.1 数据库设计概述 数据库设计定义: 数据库设计是指对于一个给定的应用环境,构造(设计)优化的数据库逻辑模式和物理结构&#x…...

【Datawhale图机器学习】半监督节点分类:标签传播和消息传递
半监督节点分类:标签传播和消息传递 半监督节点分类问题的常见解决方法: 特征工程图嵌入表示学习标签传播图神经网络 基于“物以类聚,人以群分”的Homophily假设,讲解了Label Propagation、Relational Classificationÿ…...
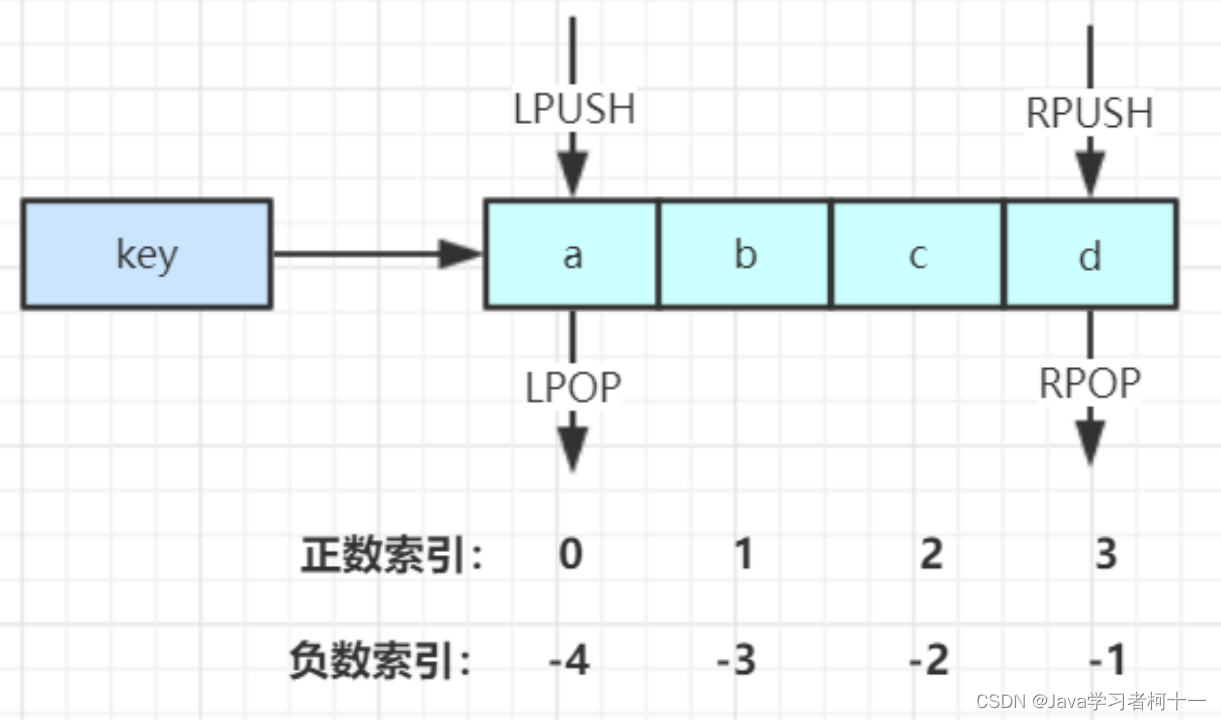
【分布式缓存学习篇】Redis数据结构
一、Redis的数据结构 二、String 数据结构 2.1 字符串常用操作 //存入字符串键值对 SET key value //批量存储字符串键值对 MSET key value [key value ...] //存入一个不存在的字符串键值对 SETNX key value //获取一个字符串键值 GET ke…...

SDMatte惊艳效果展示:高清透明PNG在海报/PPT/详情页真实复用案例
SDMatte惊艳效果展示:高清透明PNG在海报/PPT/详情页真实复用案例 1. 为什么你需要关注SDMatte 在日常设计工作中,抠图可能是最耗时但又必不可少的环节。无论是制作电商详情页、设计海报还是准备PPT素材,一个高质量的透明背景图片往往能大幅…...

基于springboot的旅游景点门票信息系统设计与实现-vue
目录 技术栈选择系统模块划分数据库设计接口设计规范前端实现要点安全措施部署方案开发流程测试计划扩展功能预留 项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作 技术栈选择 后端采用Spring Boot框架,提供RESTful…...

致开发者:别再重复造轮子,这个开源商城系统让你把时间花在刀刃上
作为开发者,你是否厌倦了每次新项目都要从零搭建电商后台?商品、订单、会员、营销……这些基础模块耗费了你多少宝贵的创造力?今天,我们想和你聊聊一个能让你“拿来即用,改也不难”的解决方案——CRMEB开源商城系统。它…...

Ostrakon-VL-8B模型剪枝与量化入门:降低部署资源消耗
Ostrakon-VL-8B模型剪枝与量化入门:降低部署资源消耗 想让大模型在普通电脑上跑起来?这听起来像是个遥不可及的梦想,尤其是对于Ostrakon-VL-8B这种参数规模不小的视觉语言模型。它功能强大,但随之而来的就是对GPU显存和算力的高要…...

HP-Socket创新项目原型迭代记录:变更、原因与效果
HP-Socket创新项目原型迭代记录:变更、原因与效果 【免费下载链接】HP-Socket High Performance TCP/UDP/HTTP Communication Component 项目地址: https://gitcode.com/gh_mirrors/hp/HP-Socket HP-Socket作为一款高性能TCP/UDP/HTTP通信组件,其…...

OpenClaw安全实践:私有化Qwen3-VL:30B保障敏感数据不出境
OpenClaw安全实践:私有化Qwen3-VL:30B保障敏感数据不出境 1. 为什么我们需要私有化部署 去年处理一份法律合同时,我犯了一个至今心有余悸的错误——把客户保密协议上传到某公有云AI进行条款分析。虽然及时删除了文件,但那种"数据已脱离…...

Phi-4-Reasoning-Vision智能助手:医疗影像图文问答系统构建实践
Phi-4-Reasoning-Vision智能助手:医疗影像图文问答系统构建实践 1. 项目概述 Phi-4-Reasoning-Vision是一款基于微软Phi-4-reasoning-vision-15B多模态大模型开发的高性能推理工具,专为医疗影像分析场景优化。该系统能够理解医学影像内容并回答专业问题…...
5大理由让你立即选择Argos Translate:开源离线翻译的终极解决方案
5大理由让你立即选择Argos Translate:开源离线翻译的终极解决方案 【免费下载链接】argos-translate Open-source offline translation library written in Python 项目地址: https://gitcode.com/GitHub_Trending/ar/argos-translate Argos Translate是一款…...

什么时候会触发FullGC
面试 1、老年代空间不足。应该让对象在年轻代多存活一段时间,不要创建过大的对象及数组。 2、元空间满了。说明此时,系统中要加载的类、反射的类和调用的方法较多。 3、MinorGC执行后晋升到老年代的平均大小大于老年代的剩余空间。...

Android NDK开发从入门到实战:解锁应用性能的终极武器
引言 在Android应用开发领域,Java和Kotlin凭借其简洁的语法和强大的框架支持,成为了绝大多数开发者的首选。然而,当面对高性能计算、游戏引擎集成、硬件加速访问或核心算法保护等场景时,纯Java层的实现往往显得力不从心。这时&…...