如何基于MLServer构建Python机器学习服务
文章目录
- 前言
- 一、数据集
- 二、训练 Scikit-learn 模型
- 三、基于MLSever构建Scikit-learn服务
- 四、测试模型
- 五、训练 XGBoost 模型
- 六、服务多个模型
- 七、测试多个模型的准确性
- 总结
- 参考
前言
在过去我们训练模型,往往通过编写flask代码或者容器化我们的模型并在docker中运行。这篇文章中,我们将分享如何基于mlserver来搭建Web服务。mlserver是基于 python的推理服务器,可以通过简单的代码实现python web服务,但是它的真正优点在于它是一个为生产环境设计的高性能服务器。

一、数据集
本博客通过使用几个图像模型作为示例,介绍如何使用 MLServer,我们要使用的数据集是Fashion MNIST 数据集。它包含 70,000 张灰度 28x28 像素的服装图像,分为 10 个不同的类别(上衣、连衣裙、外套、裤子等)。
二、训练 Scikit-learn 模型
首先,我们使用scikit-learn框架训练支持向量机 (SVM) 模型。然后我们将模型保存到一个名为Fashion-MNIST.joblib文件中。
import pandas as pd
from sklearn import svm
import time
import joblib#Load Training Data
train = pd.read_csv('../../data/fashion-mnist_train.csv', header=0)
y_train = train['label']
X_train = train.drop(['label'], axis=1)
classifier = svm.SVC(kernel="poly", degree=4, gamma=0.1)#Train Model
start = time.time()
classifier.fit(X_train.values, y_train.values)
end = time.time()
exec_time = end-start
print(f'Execution time: {exec_time} seconds')#Save Model
joblib.dump(classifier, "Fashion-MNIST.joblib")
注意:SVM 算法不是特别适合大型数据集,因为它具有二次性质。根据使用的硬件,本示例中的模型将需要几分钟时间进行训练。
三、基于MLSever构建Scikit-learn服务
好的,所以我们现在有一个保存的模型文件Fashion-MNIST.joblib。让我们来看看我们如何使用 MLServer 来提供服务…
首先,我们需要安装 MLServer。
pip install mlserver
额外的运行时是可选的,但在服务模型时让生活变得非常轻松,我们也会安装 Scikit-Learn 和 XGBoost 的
pip install mlserver-sklearn mlserver-xgboost
你可以在此处找到有关所有推理运行时的详细信息,完成后,我们需要做的就是添加两个配置文件:
- settings.json- 这包含服务器本身的配置。
- model-settings.json- 顾名思义,此文件包含我们要运行的模型的配置。对于我们的settings.json文件,只需定义一个参数就足够了:
{"debug": "true"
}
该model-settings.json文件需要更多信息,因为它需要了解我们尝试服务的模型:
{"name": "fashion-sklearn","implementation": "mlserver_sklearn.SKLearnModel","parameters": {"uri": "./Fashion_MNIST.joblib","version": "v1"}
}
name参数为 MLServer 提供了一个唯一标识符,这在为多个模型提供服务时特别有用(我们稍后会谈到)。定义implementation要使用的预建服务器(如果有),它与用于训练模型的机器学习框架紧密耦合。在我们的例子中,我们使用 scikit-learn 训练了模型,因此我们将使用 MLServer 的 scikit-learn 实现。对于模型,parameters我们只需要提供模型文件的位置以及版本号。
就是这样,两个小配置文件,我们准备好使用以下命令为我们的模型提供服务:
mlserver start .
我们现在已经在本地服务器上运行了我们的模型。它现在已准备好接受通过 HTTP 和 gRPC(分别为默认端口8080和8081)的请求。
四、测试模型
现在我们的模型已经启动并运行了。让我们发送一些请求以查看它的运行情况。
要对我们的模型进行预测,我们需要向以下 URL 发送 POST 请求:
http://localhost:8080/v2/models/<MODEL_NAME>/versions//infer
这意味着要访问我们之前训练的 scikit-learn 模型,我们需要用fashion-sklearn替换MODEL_NAME,用 v1替换VERSION。
下面的代码显示了如何导入测试数据,向模型服务器发出请求,然后将结果与实际标签进行比较:
import pandas as pd
import requests#Import test data, grab the first row and corresponding label
test = pd.read_csv('../../data/fashion-mnist_test.csv', header=0)
y_test = test['label'][0:1]
X_test = test.drop(['label'],axis=1)[0:1]#Prediction request parameters
inference_request = {"inputs": [{"name": "predict","shape": X_test.shape,"datatype": "FP64","data": X_test.values.tolist()}]
}
endpoint = "http://localhost:8080/v2/models/fashion-sklearn/versions/v1/infer"#Make request and print response
response = requests.post(endpoint, json=inference_request)
print(response.text)
print(y_test.values)运行test.py上面的代码时,我们从 MLServer 得到以下响应:
{"model_name": "fashion-sklearn","model_version": "v1","id": "31c3fa70-2e56-49b1-bcec-294452dbe73c","parameters": null,"outputs": [{"name": "predict","shape": [1],"datatype": "INT64","parameters": null,"data": [0]}]
}你会注意到 MLServer 已生成一个请求 ID,并自动添加了有关用于满足我们请求的模型和版本的元数据。一旦我们的模型投入生产,捕获这种元数据就非常重要;它允许我们记录每个请求以用于审计和故障排除目的。
你可能还会注意到 MLServer已返回一个数组outputs。在我们的请求中,我们只发送了一行数据,但MLServer也处理批量请求并将它们一起返回。你甚至可以使用一种称为自适应批处理的技术来优化在生产环境中处理多个请求的方式。
在我们上面的示例中,可以找到模型的预测,其中outputs[0].data显示模型已将此样本标记为类别0(值 0 对应于类别t-shirt/top)。该样本的真实标签也是,0所以模型得到了正确的预测!
五、训练 XGBoost 模型
现在我们已经了解了如何使用 MLServer 创建和提供单个模型,让我们来看看我们如何处理在不同框架中训练的多个模型。
我们将使用相同的 Fashion MNIST 数据集,但这次我们将训练XGBoost模型。
import pandas as pd
import xgboost as xgb
import time#Load Training Data
train = pd.read_csv('../../data/fashion-mnist_train.csv', header=0)
y_train = train['label']
X_train = train.drop(['label'], axis=1)
dtrain = xgb.DMatrix(X_train.values, label=y_train.values)#Train Model
params = {'max_depth': 5,'eta': 0.3,'verbosity': 1,'objective': 'multi:softmax','num_class' : 10
}
num_round = 50start = time.time()
bstmodel = xgb.train(params, dtrain, num_round, evals=[(dtrain, 'label')], verbose_eval=10)
end = time.time()
exec_time = end-start
print(f'Execution time: {exec_time} seconds')#Save Model
bstmodel.save_model('Fashion_MNIST.json')
上面用于训练 XGBoost 模型的代码与我们之前用于训练 scikit-learn 模型的代码类似,但这次我们的模型以 XGBoost 兼容格式保存为Fashion_MNIST.json。
六、服务多个模型
MLServer 的一个很酷的事情是它支持多模型服务。这意味着您不必为要部署的每个 ML 模型创建或运行新服务器。使用我们上面构建的模型,我们将使用此功能同时为它们提供服务。
当 MLServer 启动时,它将在目录(和任何子目录)中搜索model-settings.json文件。如果您有多个model-settings.json文件,那么它会自动为所有文件提供服务。
settings.json注意:您仍然只需要根目录中的一个(服务器配置)文件
这是我的目录结构的细分以供参考:
.
├── data
│ ├── fashion-mnist_test.csv
│ └── fashion-mnist_train.csv
├── models
│ ├── sklearn
│ │ ├── Fashion_MNIST.joblib
│ │ ├── model-settings.json
│ │ ├── test.py
│ │ └── train.py
│ └── xgboost
│ ├── Fashion_MNIST.json
│ ├── model-settings.json
│ ├── test.py
│ └── train.py
├── README.md
├── settings.json
└── test_models.py请注意,有两个model-settings.json文件 - 一个用于 scikit-learn 模型,一个用于 XGBoost 模型。
我们现在可以运行mlserver start .,它将开始处理两个模型的请求。
[mlserver] INFO - Loaded model 'fashion-sklearn' succesfully.
[mlserver] INFO - Loaded model 'fashion-xgboost' succesfully.
七、测试多个模型的准确性
现在这两个模型都在 MLServer 上启动并运行,我们可以使用测试集中的样本来验证我们每个模型的准确性。
以下代码向每个模型发送一个批处理请求(包含完整的测试集),然后将收到的预测与真实标签进行比较。在整个测试集上执行此操作可以衡量每个模型的准确性。
import pandas as pd
import requests
import json#Import the test data and split the data from the labels
test = pd.read_csv('./data/fashion-mnist_test.csv', header=0)
y_test = test['label']
X_test = test.drop(['label'],axis=1)#Build the inference request
inference_request = {"inputs": [{"name": "predict","shape": X_test.shape,"datatype": "FP64","data": X_test.values.tolist()}]
}#Send the prediction request to the relevant model, compare responses to training labels and calculate accuracy
def infer(model_name, version):endpoint = f"http://localhost:8080/v2/models/{model_name}/versions/{version}/infer"response = requests.post(endpoint, json=inference_request)#calculate accuracycorrect = 0for i, prediction in enumerate(json.loads(response.text)['outputs'][0]['data']):if y_test[i] == prediction:correct += 1accuracy = correct / len(y_test)print(f'Model Accuracy for {model_name}: {accuracy}')infer("fashion-xgboost", "v1")
infer("fashion-sklearn", "v1")结果表明,XGBoost 模型略优于 SVM scikit-learn 模型:
Model Accuracy for fashion-xgboost: 0.8953
Model Accuracy for fashion-sklearn: 0.864
总结
希望现在你已经了解使用MLServer为模型提供服务是多么容易。
参考
https://dev.to/ukcloudman/serving-python-machine-learning-models-with-ease-37kh
相关文章:
如何基于MLServer构建Python机器学习服务
文章目录前言一、数据集二、训练 Scikit-learn 模型三、基于MLSever构建Scikit-learn服务四、测试模型五、训练 XGBoost 模型六、服务多个模型七、测试多个模型的准确性总结参考前言 在过去我们训练模型,往往通过编写flask代码或者容器化我们的模型并在docker中运行…...

9.1 IGMPv1实验
9.4.1 IGMPv1 实验目的 熟悉IGMPv1的应用场景掌握IGMPv1的配置方法实验拓扑 实验拓扑如图9-7所示: 图9-7:IGMPv1 实验步骤 (1)配置IP地址 MCS1的配置 MCS1的IP地址配置如图9-8所示: 图9-8:MCS1的配置 …...

软考高级系统分析师系列论文之十:论实时控制系统与企业信息系统的集成在通信业应用
软考高级系统分析师系列论文之十:论实时控制系统与企业信息系统的集成在通信业应用 一、摘要二、正文三、总结一、摘要 近年来,在应用需求的强大驱动下,我国通信业有了长足的进步。现有通信行业中的许多企业单位,如电信公司或移动集团,其信息系统的主要特征之一是对线路的…...
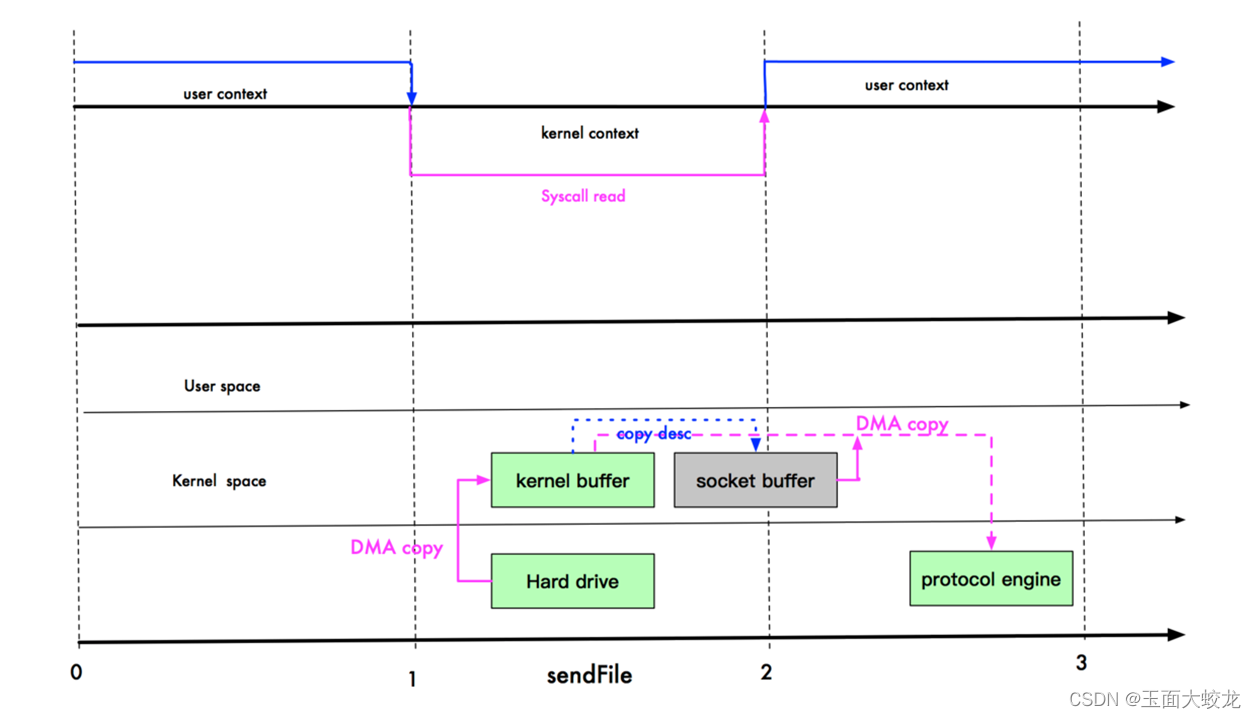
NIO与零拷贝
目录 一、零拷贝的基本介绍 二、传统IO数据读写的劣势 三、mmap优化 四、sendFile优化 五、 mmap 和 sendFile 的区别 六、零拷贝实战 6.1 传统IO 6.2 NIO中的零拷贝 6.3 运行结果 一、零拷贝的基本介绍 零拷贝是网络编程的关键,很多性能优化都离不开。 在…...
)
【PAT甲级题解记录】1151 LCA in a Binary Tree (30 分)
【PAT甲级题解记录】1151 LCA in a Binary Tree (30 分) 前言 Problem:1151 LCA in a Binary Tree (30 分) Tags:树的遍历 并查集 LCA Difficulty:剧情模式 想流点汗 想流点血 死而无憾 Address:1151 LCA in a Binary Tree (30 分…...

Android 获取手机语言环境 区分简体和繁体,香港,澳门,台湾繁体
安卓和IOS 系统语言都是准守:ISO 639 ISO 代码表IOS:plus.os.language ios正常,安卓下简体和繁体语言,都是zh安卓获取系统语言方法:Locale.getDefault().language手机切换到繁体(台湾,香港&…...

一文搞懂Python时间序列
Python时间序列1. datetime模块1.1 datetime对象1.2 字符串和datatime的相互转换2. 时间序列基础3. 重采样及频率转换4. 时间序列可视化5. 窗口函数5.1 移动窗口函数5.2 指数加权函数5.3 二元移动窗口函数时间序列(Time Series)是一种重要的结构化数据形…...
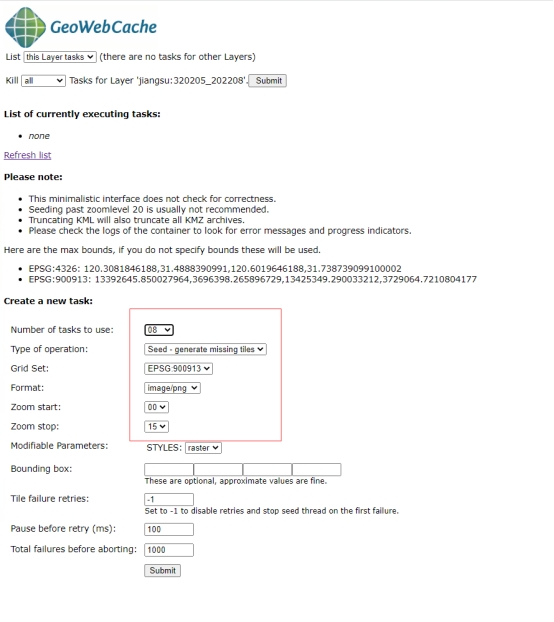
GeoServer发布数据进阶
GeoServer发布数据进阶 GeoServer介绍 GeoServer是用于共享地理空间数据的开源服务器。 它专为交互操作性而设计,使用开放标准发布来自任何主要空间数据源的数据。 GeoServer实现了行业标准的 OGC 协议,例如网络要素服务 (WFS)…...
Docker离线部署
Docker离线部署 目录 1、需求说明 2、下载docker安装包 3、上传docker安装包 4、解压docker安装包 5、解压的docker文件夹全部移动至/usr/bin目录 6、将docker注册为系统服务 7、重启生效 8、设置开机自启 9、查看docker版本信息 1、需求说明 大部份公司为了服务安全…...
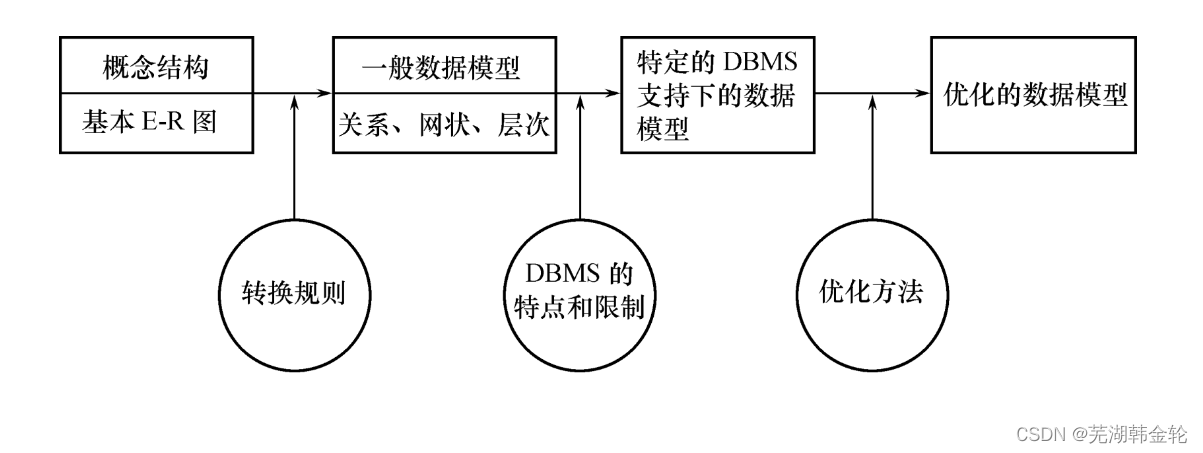
《数据库系统概论》学习笔记——第七章 数据库设计
教材为数据库系统概论第五版(王珊) 这一章概念比较多。最重点就是7.4节。 7.1 数据库设计概述 数据库设计定义: 数据库设计是指对于一个给定的应用环境,构造(设计)优化的数据库逻辑模式和物理结构&#x…...

【Datawhale图机器学习】半监督节点分类:标签传播和消息传递
半监督节点分类:标签传播和消息传递 半监督节点分类问题的常见解决方法: 特征工程图嵌入表示学习标签传播图神经网络 基于“物以类聚,人以群分”的Homophily假设,讲解了Label Propagation、Relational Classificationÿ…...
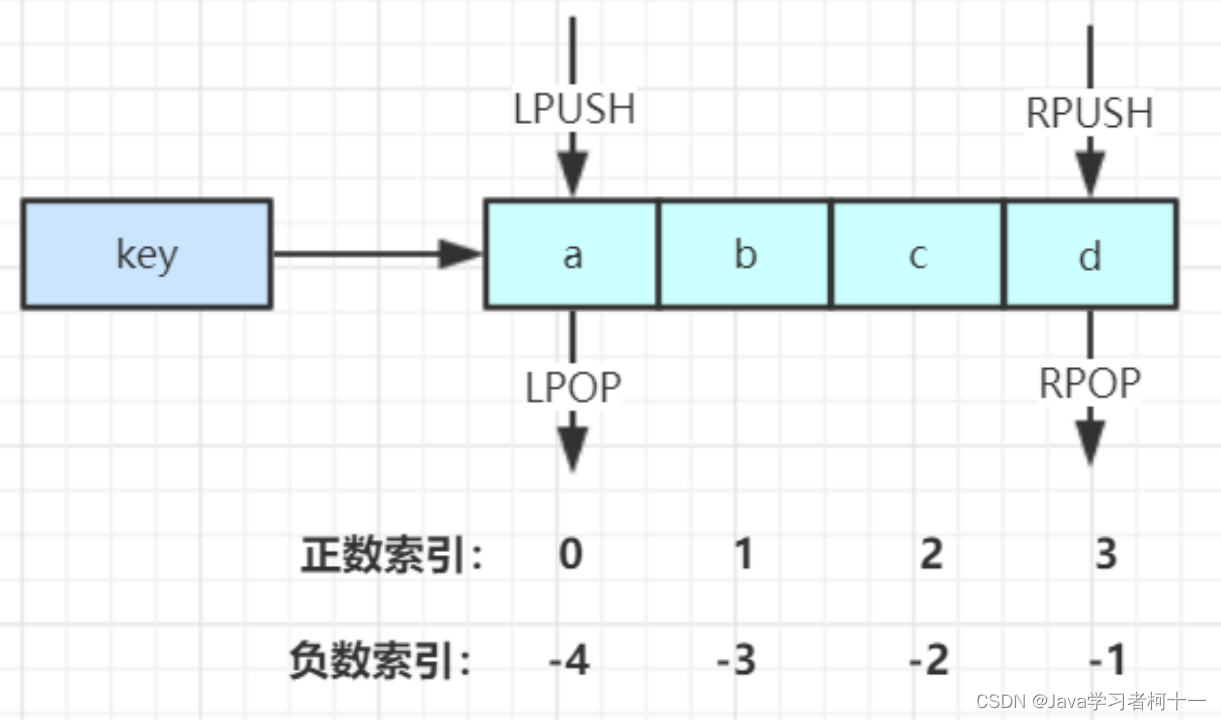
【分布式缓存学习篇】Redis数据结构
一、Redis的数据结构 二、String 数据结构 2.1 字符串常用操作 //存入字符串键值对 SET key value //批量存储字符串键值对 MSET key value [key value ...] //存入一个不存在的字符串键值对 SETNX key value //获取一个字符串键值 GET ke…...

【跟着ChatGPT学深度学习】ChatGPT带我入门NLP
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...

RGB888与RGB565颜色
颜色名称RGB888原色RGB565还原色英RGB888[Hex]RGB888_R[Hex]RGB888_G[Hex]RGB888_B[Hex]RGB565[Hex]RGB565_R[Hex]RGB565_G[Hex]RGB565_B[Hex]黑色Black0x0000000000000x0000000昏灰Dimgray0x6969696969690x6B4DD1AD灰色Gray0x8080808080800x8410102010暗灰Dark Gray0xA9A9A9A9…...

常见的域名后缀有哪些?不同域名后缀的含义是什么?
域名发展至今,已演变出各种各样的域名后缀,导致很多网站管理人员在注册域名时不知该如何选择。下面,中科三方针对常见域名后缀种类,以及不同域名后缀的含义做下简单介绍。 什么是域名后缀? 域名是由一串由点分隔开的…...
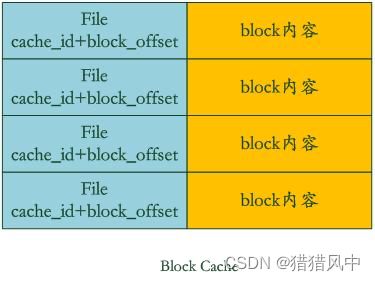
LevelDB架构介绍以及读、写和压缩流程
LevelDB 基本介绍 是一个key/value存储,key值根据用户指定的comparator排序。 特性 keys 和 values 是任意的字节数组。数据按 key 值排序存储。调用者可以提供一个自定义的比较函数来重写排序顺序。提供基本的 Put(key,value),Get(key),…...

华为OD机试模拟题 用 C++ 实现 - 快递货车(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 最多获得的短信条数(2023.Q1)) 文章目录 最近更新的博客使用说明快递货车题目输入输出示例一输入输出Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为 OD 清单…...
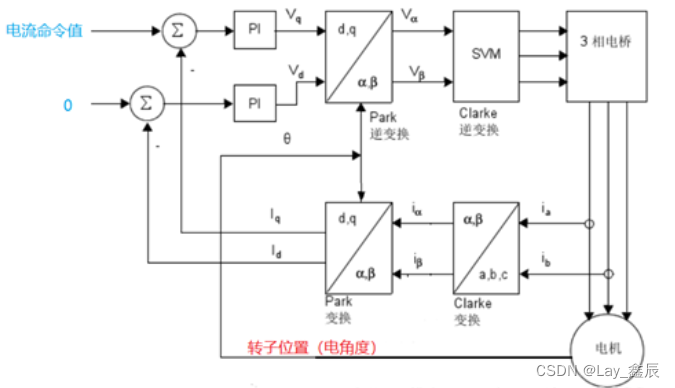
伺服三环控制深层原理解析
我们平时使用的工业伺服,通常是成套伺服,即驱动器和电机型号存在配对关系。 但有些时候,我们要用电机定转子和编码器制作非成套电机,这种时候,我们需要对驱动器进行各种设置才能驱动电机。 此篇文章将通过介绍伺服控制的三环控制原理入手来说明我们调试非成套伺服时需要…...
)
Cornerstone完整的基于 Web 的医学成像平台(一)
1.简介 Cornerstone是一个开源的基于Web的医学成像平台,它提供了一个易于使用的界面,可以用于加载、显示和处理医学图像。Cornerstone可以用于许多医学图像处理应用程序,例如计算机断层扫描(CT)、磁共振成像ÿ…...
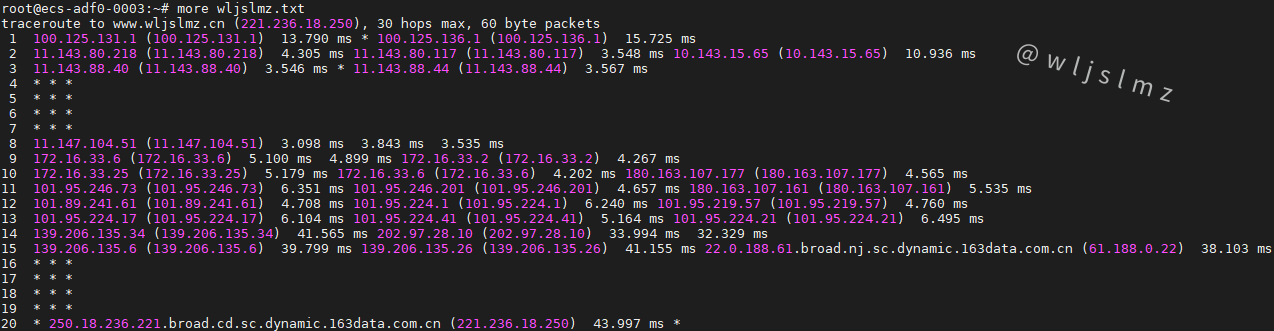
老板让我在Linux中使用traceroute排查服务器网络问题,幸好我收藏了这篇文章!
一、前言 作为网络工程师或者运维工程师,traceroute命令不会陌生,它的作用类似于ping命令,用于诊断网络的连通性,不过traceroute命令输出的命令会比ping命令丰富的多,可以跟踪从源系统到目标系统的路径。 很多工程师…...

上传论文给降AI工具会被拿去训练吗?嘎嘎降AI自研引擎不用你数据!
上传论文给降AI工具会被拿去训练吗?嘎嘎降AI自研引擎不用你数据! 把毕业论文上传给陌生工具时你心里在想什么 写论文的同学决定买降 AI 工具时,几乎都会犹豫一件事——把整篇毕业论文上传给一个陌生工具,安全吗? 具体担…...

capl发送错误帧
on key a{output(errorframe);}on errorframe{write("错误帧通道 %d.",this.can);}...

量子优化算法与经典算法在Max-Cut问题中的性能对比
1. 量子优化算法与Max-Cut问题概述 Max-Cut问题是图论中一个经典的NP难组合优化问题,其目标是将给定无向图的顶点划分为两个互不相交的子集,使得连接这两个子集的边权重之和最大。这个问题在统计物理、电路设计和网络聚类等领域有广泛应用背景。随着量子…...

Dev-GPT部署指南:简单三步将你的微服务推向Jina云平台
Dev-GPT部署指南:简单三步将你的微服务推向Jina云平台 【免费下载链接】dev-gpt Your Virtual Development Team 项目地址: https://gitcode.com/gh_mirrors/de/dev-gpt Dev-GPT是一款强大的虚拟开发团队工具,能够帮助开发者快速构建和部署微服务…...

ARM缓存控制器架构解析与性能优化实践
1. ARM缓存控制器架构概述 在现代处理器设计中,缓存控制器作为CPU与主存之间的关键桥梁,其设计优劣直接影响系统整体性能。ARM架构的缓存控制器采用分层设计理念,通过数据RAM、标签RAM和脏RAM三大核心组件的协同工作,实现了高效的…...

WinRAR分卷压缩 vs 7-Zip分卷压缩:哪个更适合你?一次讲清区别、选型和实操
WinRAR分卷压缩 vs 7-Zip分卷压缩:深度对比与场景化选型指南 在数字文件传输与存储的日常场景中,大文件处理始终是个绕不开的痛点。无论是设计师需要发送PSD源文件给客户,还是开发人员要共享虚拟机镜像,当文件体积突破邮箱附件限…...

ChatTTS开源对话式语音合成:情感控制与实战部署指南
1. 项目概述:从文本到语音的“情感”革命最近在语音合成圈子里,一个名为ChatTTS的项目热度持续攀升。作为一个长期关注语音技术发展的从业者,我最初也被它“高质量、多语言、可控性强”的描述所吸引。但真正上手后才发现,这个项目…...

GPT宏系统开发指南:从提示词模板到RAG知识库的自动化实践
1. 项目概述:一个让GPT“记住”并“执行”的自动化利器如果你经常和GPT打交道,无论是ChatGPT的Web界面,还是通过API调用,肯定都遇到过这样的烦恼:每次对话,你都得把那些重复的、固定的指令或背景信息再敲一…...

边缘计算能效革命:从架构革新到产业落地的破局之路
1. 边缘计算的核心矛盾:智能需求与能源瓶颈的碰撞在过去的几年里,我亲眼见证了计算范式的一次深刻迁徙:从集中式的云端,正不可逆转地向着物理世界的每一个角落——也就是我们常说的“边缘”——扩散。驱动这股浪潮的,是…...

终极指南:3分钟实现GitHub全界面中文化,彻底消除语言障碍
终极指南:3分钟实现GitHub全界面中文化,彻底消除语言障碍 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese GitH…...