手把手教你:LLama2原始权重转HF模型

LLama2是meta最新开源的语言大模型,训练数据集2万亿token,上下文长度由llama的2048扩展到4096,可以理解和生成更长的文本,包括7B、13B和70B三个模型,在各种基准集的测试上表现突出,该模型可用于研究和商业用途。
LLama2模型权重和tokenizer下载需要申请访问。
申请链接:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
由于下载的原始LLama2模型权重文件不能直接调用huggingface的transformers库进行使用,如果要使用huggingface transformer训练LLaMA2,需要使用额外的转换脚本。
转换脚本:https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py
现在huggingface上已发布了llama的hf版本,可以直接使用。
现在介绍LLama2模型的原始权重获取和转换脚本。
LLama2模型原始权重获取
在MetaAI申请通过后将会在邮件中提及到PRESIGNED_URL,运行download.sh,按照提示输入即可。
set -eread -p "Enter the URL from email: " PRESIGNED_URL
echo ""
read -p "Enter the list of models to download without spaces (7B,13B,70B,7B-chat,13B-chat,70B-chat), or press Enter for all: " MODEL_SIZE
TARGET_FOLDER="../target/file" # where all files should end up
mkdir -p ${TARGET_FOLDER}if [[ $MODEL_SIZE == "" ]]; thenMODEL_SIZE="7B,13B,70B,7B-chat,13B-chat,70B-chat"
fiecho "Downloading LICENSE and Acceptable Usage Policy"
wget --continue ${PRESIGNED_URL/'*'/"LICENSE"} -O ${TARGET_FOLDER}"/LICENSE"
wget --continue ${PRESIGNED_URL/'*'/"USE_POLICY.md"} -O ${TARGET_FOLDER}"/USE_POLICY.md"echo "Downloading tokenizer"
wget --continue ${PRESIGNED_URL/'*'/"tokenizer.model"} -O ${TARGET_FOLDER}"/tokenizer.model"
wget --continue ${PRESIGNED_URL/'*'/"tokenizer_checklist.chk"} -O ${TARGET_FOLDER}"/tokenizer_checklist.chk"
CPU_ARCH=$(uname -m)if [ "$CPU_ARCH" = "arm64" ]; then(cd ${TARGET_FOLDER} && md5 tokenizer_checklist.chk)else(cd ${TARGET_FOLDER} && md5sum -c tokenizer_checklist.chk)fifor m in ${MODEL_SIZE//,/ }
doif [[ $m == "7B" ]]; thenSHARD=0MODEL_PATH="llama-2-7b"elif [[ $m == "7B-chat" ]]; thenSHARD=0MODEL_PATH="llama-2-7b-chat"elif [[ $m == "13B" ]]; thenSHARD=1MODEL_PATH="llama-2-13b"elif [[ $m == "13B-chat" ]]; thenSHARD=1MODEL_PATH="llama-2-13b-chat"elif [[ $m == "70B" ]]; thenSHARD=7MODEL_PATH="llama-2-70b"elif [[ $m == "70B-chat" ]]; thenSHARD=7MODEL_PATH="llama-2-70b-chat"fiecho "Downloading ${MODEL_PATH}"mkdir -p ${TARGET_FOLDER}"/${MODEL_PATH}"for s in $(seq -f "0%g" 0 ${SHARD})dowget ${PRESIGNED_URL/'*'/"${MODEL_PATH}/consolidated.${s}.pth"} -O ${TARGET_FOLDER}"/${MODEL_PATH}/consolidated.${s}.pth"donewget --continue ${PRESIGNED_URL/'*'/"${MODEL_PATH}/params.json"} -O ${TARGET_FOLDER}"/${MODEL_PATH}/params.json"wget --continue ${PRESIGNED_URL/'*'/"${MODEL_PATH}/checklist.chk"} -O ${TARGET_FOLDER}"/${MODEL_PATH}/checklist.chk"echo "Checking checksums"if [ "$CPU_ARCH" = "arm64" ]; then(cd ${TARGET_FOLDER}"/${MODEL_PATH}" && md5 checklist.chk)else(cd ${TARGET_FOLDER}"/${MODEL_PATH}" && md5sum -c checklist.chk)fi
done
运行download.sh:
sh download.sh
代码注释
# 导入包
import argparse
import gc
import json
import os
import shutil
import warnings
import torch
from transformers import LlamaConfig, LlamaForCausalLM, LlamaTokenizer# 判断LlamaTokenizerFast是否可用,LlamaTokenizerFast可以加速tokenization
try:from transformers import LlamaTokenizerFast
except ImportError as e:warnings.warn(e)warnings.warn("The converted tokenizer will be the `slow` tokenizer. To use the fast, update your `tokenizers` library and re-run the tokenizer conversion")LlamaTokenizerFast = None# 不同版本的LLama模型的分片数目
NUM_SHARDS = {"7B": 1,"7Bf": 1,"13B": 2,"13Bf": 2,"34B": 4,"30B": 4,"65B": 8,"70B": 8,"70Bf": 8,
}# 计算中间层大小,优化计算效率
def compute_intermediate_size(n, ffn_dim_multiplier=1, multiple_of=256):return multiple_of * ((int(ffn_dim_multiplier * int(8 * n / 3)) + multiple_of - 1) // multiple_of)# 读取json文件
def read_json(path):with open(path, "r") as f:return json.load(f)# 写入json文件
def write_json(text, path):with open(path, "w") as f:json.dump(text, f)def write_model(model_path, input_base_path, model_size, tokenizer_path=None, safe_serialization=True):# 检查参数文件路径if not os.path.isfile(os.path.join(input_base_path, "params.json")):input_base_path = os.path.join(input_base_path, model_size)# 创建模型临时保存目录os.makedirs(model_path, exist_ok=True)tmp_model_path = os.path.join(model_path, "tmp")os.makedirs(tmp_model_path, exist_ok=True)# 读取参数params = read_json(os.path.join(input_base_path, "params.json"))num_shards = NUM_SHARDS[model_size]n_layers = params["n_layers"]n_heads = params["n_heads"]n_heads_per_shard = n_heads // num_shardsdim = params["dim"]dims_per_head = dim // n_headsbase = params.get("rope_theta", 10000.0)inv_freq = 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))if base > 10000.0:max_position_embeddings = 16384else:max_position_embeddings = 2048# 初始化tokenizertokenizer_class = LlamaTokenizer if LlamaTokenizerFast is None else LlamaTokenizerFastif tokenizer_path is not None:tokenizer = tokenizer_class(tokenizer_path)tokenizer.save_pretrained(model_path)vocab_size = tokenizer.vocab_size if tokenizer_path is not None else 32000# 处理键值对头信息if "n_kv_heads" in params:num_key_value_heads = params["n_kv_heads"] # for GQA / MQAnum_local_key_value_heads = n_heads_per_shard // num_key_value_headskey_value_dim = dim // num_key_value_headselse: # compatibility with other checkpointsnum_key_value_heads = n_headsnum_local_key_value_heads = n_heads_per_shardkey_value_dim = dim# 张量变换def permute(w, n_heads=n_heads, dim1=dim, dim2=dim):return w.view(n_heads, dim1 // n_heads // 2, 2, dim2).transpose(1, 2).reshape(dim1, dim2)print(f"Fetching all parameters from the checkpoint at {input_base_path}.")# 加载权重if num_shards == 1:loaded = torch.load(os.path.join(input_base_path, "consolidated.00.pth"), map_location="cpu")else:loaded = [torch.load(os.path.join(input_base_path, f"consolidated.{i:02d}.pth"), map_location="cpu")for i in range(num_shards)]param_count = 0index_dict = {"weight_map": {}}# 处理每一层的原始权重,并转化为bin文件for layer_i in range(n_layers):filename = f"pytorch_model-{layer_i + 1}-of-{n_layers + 1}.bin"if num_shards == 1:# Unshardedstate_dict = {f"model.layers.{layer_i}.self_attn.q_proj.weight": permute(loaded[f"layers.{layer_i}.attention.wq.weight"]),f"model.layers.{layer_i}.self_attn.k_proj.weight": permute(loaded[f"layers.{layer_i}.attention.wk.weight"]),f"model.layers.{layer_i}.self_attn.v_proj.weight": loaded[f"layers.{layer_i}.attention.wv.weight"],f"model.layers.{layer_i}.self_attn.o_proj.weight": loaded[f"layers.{layer_i}.attention.wo.weight"],f"model.layers.{layer_i}.mlp.gate_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w1.weight"],f"model.layers.{layer_i}.mlp.down_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w2.weight"],f"model.layers.{layer_i}.mlp.up_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w3.weight"],f"model.layers.{layer_i}.input_layernorm.weight": loaded[f"layers.{layer_i}.attention_norm.weight"],f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[f"layers.{layer_i}.ffn_norm.weight"],}else:# Sharded# Note that attention.w{q,k,v,o}, feed_fordward.w[1,2,3], attention_norm.weight and ffn_norm.weight share# the same storage object, saving attention_norm and ffn_norm will save other weights too, which is# redundant as other weights will be stitched from multiple shards. To avoid that, they are cloned.state_dict = {f"model.layers.{layer_i}.input_layernorm.weight": loaded[0][f"layers.{layer_i}.attention_norm.weight"].clone(),f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[0][f"layers.{layer_i}.ffn_norm.weight"].clone(),}state_dict[f"model.layers.{layer_i}.self_attn.q_proj.weight"] = permute(torch.cat([loaded[i][f"layers.{layer_i}.attention.wq.weight"].view(n_heads_per_shard, dims_per_head, dim)for i in range(num_shards)],dim=0,).reshape(dim, dim))state_dict[f"model.layers.{layer_i}.self_attn.k_proj.weight"] = permute(torch.cat([loaded[i][f"layers.{layer_i}.attention.wk.weight"].view(num_local_key_value_heads, dims_per_head, dim)for i in range(num_shards)],dim=0,).reshape(key_value_dim, dim),num_key_value_heads,key_value_dim,dim,)state_dict[f"model.layers.{layer_i}.self_attn.v_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.attention.wv.weight"].view(num_local_key_value_heads, dims_per_head, dim)for i in range(num_shards)],dim=0,).reshape(key_value_dim, dim)state_dict[f"model.layers.{layer_i}.self_attn.o_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.attention.wo.weight"] for i in range(num_shards)], dim=1)state_dict[f"model.layers.{layer_i}.mlp.gate_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.feed_forward.w1.weight"] for i in range(num_shards)], dim=0)state_dict[f"model.layers.{layer_i}.mlp.down_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.feed_forward.w2.weight"] for i in range(num_shards)], dim=1)state_dict[f"model.layers.{layer_i}.mlp.up_proj.weight"] = torch.cat([loaded[i][f"layers.{layer_i}.feed_forward.w3.weight"] for i in range(num_shards)], dim=0)state_dict[f"model.layers.{layer_i}.self_attn.rotary_emb.inv_freq"] = inv_freqfor k, v in state_dict.items():index_dict["weight_map"][k] = filenameparam_count += v.numel()torch.save(state_dict, os.path.join(tmp_model_path, filename))# 处理最后一层权重,并保存filename = f"pytorch_model-{n_layers + 1}-of-{n_layers + 1}.bin"if num_shards == 1:state_dict = {"model.embed_tokens.weight": loaded["tok_embeddings.weight"],"model.norm.weight": loaded["norm.weight"],"lm_head.weight": loaded["output.weight"],}else:state_dict = {"model.norm.weight": loaded[0]["norm.weight"],"model.embed_tokens.weight": torch.cat([loaded[i]["tok_embeddings.weight"] for i in range(num_shards)], dim=1),"lm_head.weight": torch.cat([loaded[i]["output.weight"] for i in range(num_shards)], dim=0),}for k, v in state_dict.items():index_dict["weight_map"][k] = filenameparam_count += v.numel()torch.save(state_dict, os.path.join(tmp_model_path, filename))# 写入配置文件index_dict["metadata"] = {"total_size": param_count * 2}write_json(index_dict, os.path.join(tmp_model_path, "pytorch_model.bin.index.json"))ffn_dim_multiplier = params["ffn_dim_multiplier"] if "ffn_dim_multiplier" in params else 1multiple_of = params["multiple_of"] if "multiple_of" in params else 256config = LlamaConfig(hidden_size=dim,intermediate_size=compute_intermediate_size(dim, ffn_dim_multiplier, multiple_of),num_attention_heads=params["n_heads"],num_hidden_layers=params["n_layers"],rms_norm_eps=params["norm_eps"],num_key_value_heads=num_key_value_heads,vocab_size=vocab_size,rope_theta=base,max_position_embeddings=max_position_embeddings,)config.save_pretrained(tmp_model_path)# 释放内存空间,以便正确加载模型del state_dictdel loadedgc.collect()print("Loading the checkpoint in a Llama model.")# 从临时文件中加载模型model = LlamaForCausalLM.from_pretrained(tmp_model_path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True)# 避免将此作为配置的一部分保存del model.config._name_or_pathmodel.config.torch_dtype = torch.float16print("Saving in the Transformers format.")# 保存LLama模型到指定的路径model.save_pretrained(model_path, safe_serialization=safe_serialization)# 删除临时文件中的所有内容shutil.rmtree(tmp_model_path)# 保存tokenizer
def write_tokenizer(tokenizer_path, input_tokenizer_path):# Initialize the tokenizer based on the `spm` modeltokenizer_class = LlamaTokenizer if LlamaTokenizerFast is None else LlamaTokenizerFastprint(f"Saving a {tokenizer_class.__name__} to {tokenizer_path}.")tokenizer = tokenizer_class(input_tokenizer_path)tokenizer.save_pretrained(tokenizer_path)def main():# 参数处理parser = argparse.ArgumentParser()parser.add_argument("--input_dir",help="Location of LLaMA weights, which contains tokenizer.model and model folders",)parser.add_argument("--model_size",choices=["7B", "7Bf", "13B", "13Bf", "30B", "34B", "65B", "70B", "70Bf", "tokenizer_only"],help="'f' models correspond to the finetuned versions, and are specific to the Llama2 official release. For more details on Llama2, checkout the original repo: https://huggingface.co/meta-llama",)parser.add_argument("--output_dir",help="Location to write HF model and tokenizer",)parser.add_argument("--safe_serialization", type=bool, help="Whether or not to save using `safetensors`.")args = parser.parse_args()spm_path = os.path.join(args.input_dir, "tokenizer.model")# 判断转换的对象if args.model_size != "tokenizer_only":write_model(model_path=args.output_dir,input_base_path=args.input_dir,model_size=args.model_size,safe_serialization=args.safe_serialization,tokenizer_path=spm_path,)else:write_tokenizer(args.output_dir, spm_path)if __name__ == "__main__":main()
脚本运行
python convert_llama_weights_to_hf.py --input_dir raw-llama2-7b --output_dir llama2_7b_hf
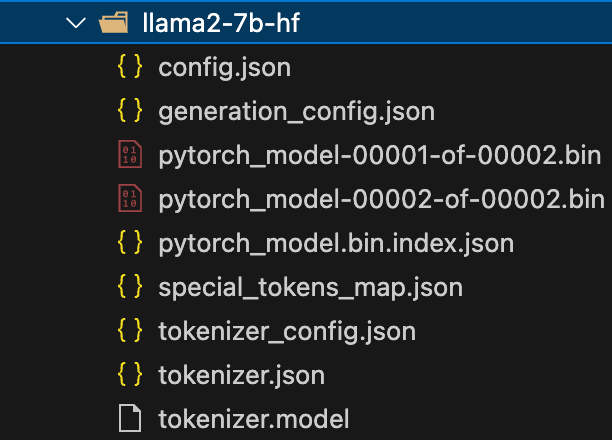
raw-llama2-7b文件夹内容:

llama2_7b_hf转换文件内容:
相关文章:
手把手教你:LLama2原始权重转HF模型
LLama2是meta最新开源的语言大模型,训练数据集2万亿token,上下文长度由llama的2048扩展到4096,可以理解和生成更长的文本,包括7B、13B和70B三个模型,在各种基准集的测试上表现突出,该模型可用于研究和商业用…...
后入能先出,一文搞懂栈
目录 什么是栈数组实现链表实现栈能这么玩总结 什么是栈 栈在我们日常编码中遇到的非常多,很多人对栈的接触可能仅仅局限在 递归使用的栈 和 StackOverflowException,栈是一种后进先出的数据结构(可以想象生化金字塔的牢房和生化角斗场的狗洞)。 栈&…...
京东API接口的应用场景:商品信息查询,商品详情获取
京东API接口的应用场景涵盖了电商业务的各个方面,通过API的方式,开发者可以方便地获取京东平台上的商品信息、用户信息、订单信息等,进而进行个性化的应用开发。以下是几个典型的应用场景: 商品信息查询:通过京东API接…...

微信小程序使用iconfont坑
下载解压 font-face {font-family: "iconfont"; /* Project id 4322044 */src: url(iconfont.woff2?t1699515502419) format(woff2),url(iconfont.woff?t1699515502419) format(woff),url(iconfont.ttf?t1699515502419) format(truetype); }.iconfont {font-famil…...

最新Cocos Creator 3.x 如何动态修改3D物体的透明度
Cocos Creator 3.x 的2D UI有个组件UIOpacity组件可以动态修改UI的透明度,非常方便。很多同学想3D物体上也有一个这样的组件来动态的控制与修改3D物体的透明度。今天基于Cocos Creator 3.8 来实现一个可以动态修改3D物体透明度的组件Opacity3D。 对啦!这里有个游戏…...
golang 2018,go 1.19安装Gin
GOPROXYhttps://mirrors.aliyun.com/goproxy/ 一致提示URL不能有点,给我整郁闷了,换了这个地址好了 但是一致提示zip的包问题,最后还是不行又换回七牛 NEWBEE! [GIN-debug] Environment variable PORT is undefined. Using por…...

常用的三角函数公式
sin 2 x cos 2 x 1 \sin ^2 x \cos ^2 x 1 sin2xcos2x1 tan x sin x cos x \tan x \dfrac{\sin x}{\cos x} tanxcosxsinx cot x 1 tan x cos x sin x \cot x \dfrac{1}{\tan x}\dfrac{\cos x}{\sin x} cotxtanx1sinxcosx sec …...

【MySQL】一文学会所有MySQL基础知识以及基本面试题
文章目录 前言 目录 文章目录 前言 一、主流数据库以及如何登陆数据库 二、常用命令使用 三、SQL分类 3.1 存储引擎 四、创建数据库如何设置编码等问题 4.1操纵数据库 4.2操纵表 五、数据类型 六、表的约束 七、基本查询 八、函数 九、复合查询 十、表的内连和外连 十一、索引…...
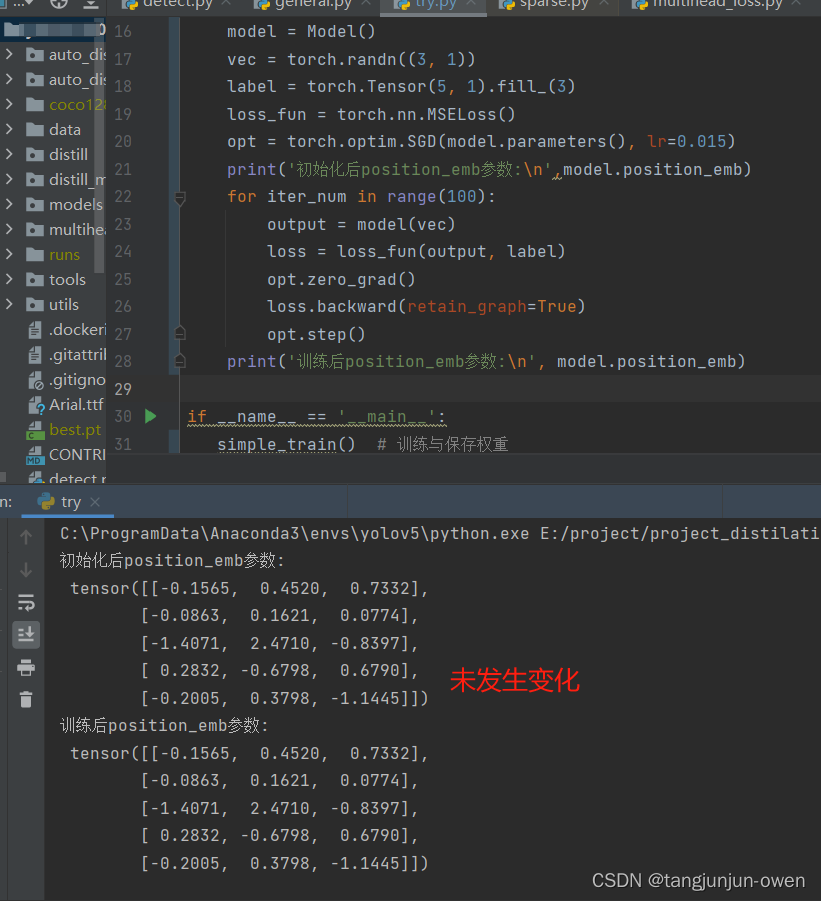
self.register_buffer方法使用解析(pytorch)
self.register_buffer就是pytorch框架用来保存不更新参数的方法。 列子如下: self.register_buffer("position_emb", torch.randn((5, 3)))第一个参数position_emb传入一个字符串,表示这组参数的名字,第二个就是tensor形式的参数…...
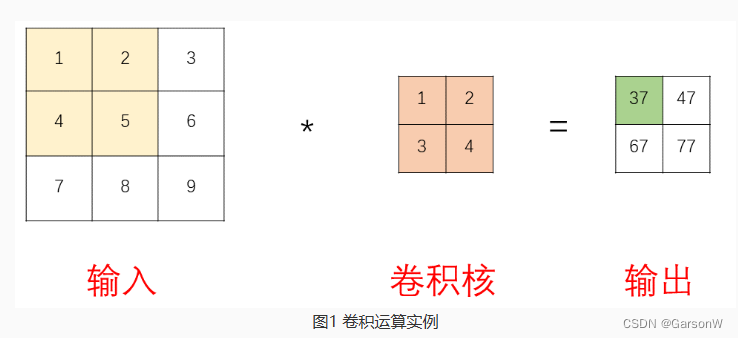
关于卷积神经网络中如何计算卷积核大小(kernels)
首先需要说明的一点是,虽然卷积层得名于卷积( convolution )运算,但我们通常在卷积层中使用更加直观的计算方式,叫做互相关( cross-correlation )运算。 也就是说,其实我们现在在这里…...
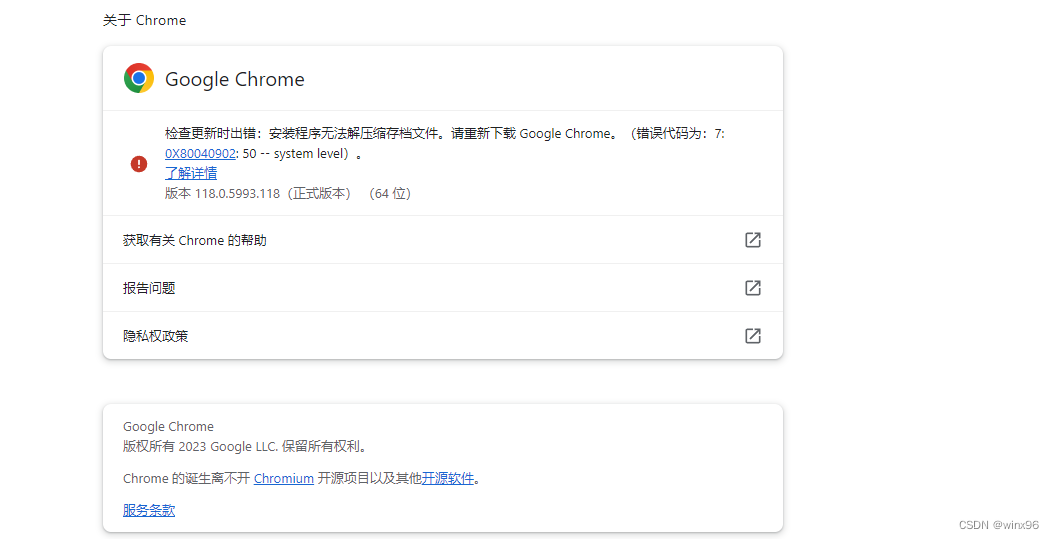
python使用selenium做自动化,最新版Chrome与chromedriver不兼容
目前Chrome版本是118.0.5993.118 下方是版本对应的下载地址: chrome版本118: https://download.csdn.net/download/qq_35845339/88510476 chrome版本119: chromedriverlinux64https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testin…...

算法进阶指南图论 通信线路
通信线路 思路:我们考虑需要升级的那条电缆的花费,若其花费为 w ,那么从 1 到 n 的路径上,至多存在 k 条路径的价值大于 w ,这具有一定的单调性,当花费 w 越大,我们路径上价值大于 w 的花费会越…...
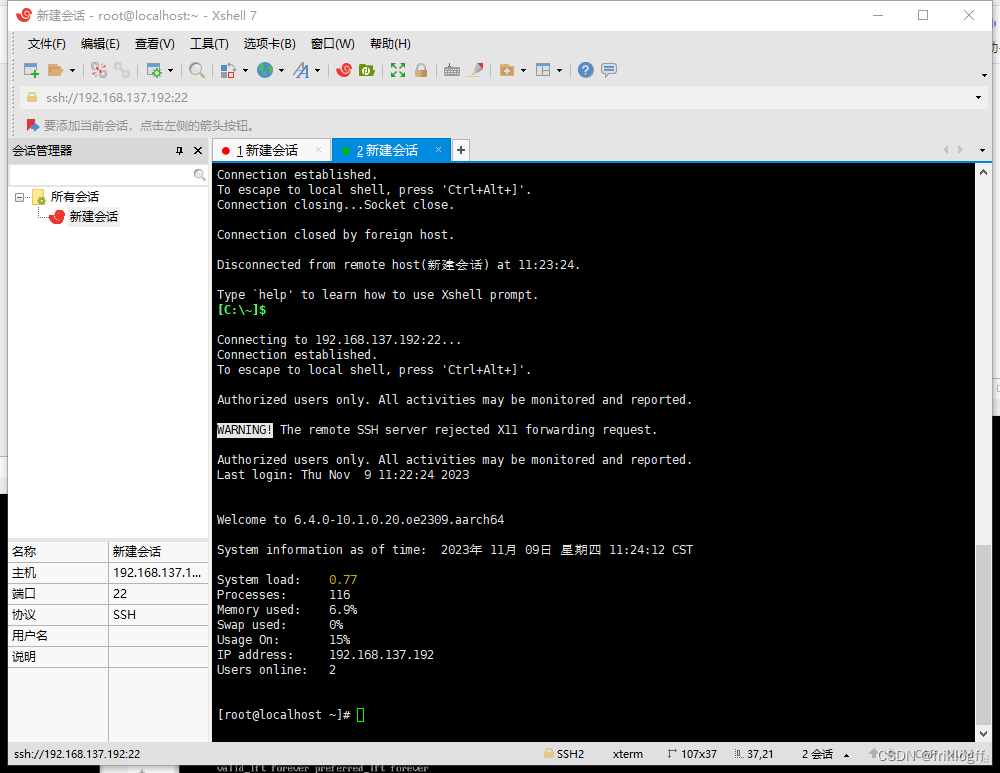
【QEMU-tap-windows-Xshell】QEMU 创建 aarch64虚拟机(附有QEMU免费资源)
“从零开始:在Windows上创建aarch64(ARM64)虚拟机” 前言 aarch64(ARM64)架构是一种现代的、基于 ARM 技术的计算架构,具有诸多优点,如低功耗、高性能和广泛应用等。为了在 Windows 平台上体验…...

strtok函数详解:字符串【分割】的利器
目录 一,strtok函数简介 二,strtok函数的用法 三,strtok函数的注意事项 一,strtok函数简介 strtok函数可以帮助我们将一个字符串按照指定的分隔符进行分割,从而得到我们想要的子字符串。 🍂函数头文件&am…...

winui3开发笔记(二)自定义标题栏
参考文章链接:https://www.programminghunter.com/article/46392310600/ 注意事项 获取 AppWindowTitleBar 的实例并设置其颜色属性时,InitializeTitleBar(AppWindow.TitleBar);,只适用于Windows App SDK 1.2及以上,所以如果用w…...

MapReduce 读写数据库
MapReduce 读写数据库 经常听到小伙伴吐槽 MapReduce 计算的结果无法直接写入数据库, 实际上 MapReduce 是有操作数据库实现的 本案例代码将实现 MapReduce 数据库读写操作和将数据表中数据复制到另外一张数据表中 准备数据表 create database htu; use htu; creat…...
)
设计模式 -- 状态模式(State Pattern)
状态模式:类的行为基于它的状态改变 属于行为型模式,创建表示各种状态的对象和一个行为随着状态对象改变而改变的 context 对象。在代码中包含大量与对象状态有关的条件语句可以通过此模式将各种具体的状态类抽象出来 介绍 意图:允许对象在…...

qt quick发布程序启动失败
qt quick/qml 程序发布之后,程序启动不了 经过探究测试,程序启动的不了的情况下是因为有dll没有添加。在release文件夹下进行发布操作(不单独复制xx.exe拿出来),再次点击IDE的RUN按钮,则会提示有Moudle没有…...

nginx反向代理报错合集
本文汇集了最近在使用nginx反向代理过程中遇到的一系列错误及其解决办法。 1缺乏支持项导致nginx配置错误 在利用sudo ./configure --with-http_ssl_module --with-http_stub_status_module进行配置时,往往会遇到以下类型的错误 error: the HTTP rewrite module …...

【Linux精讲系列】——vim详解
作者主页 📚lovewold少个r博客主页 ⚠️本文重点:c入门第一个程序和基本知识讲解 👉【C-C入门系列专栏】:博客文章专栏传送门 😄每日一言:宁静是一片强大而治愈的神奇海洋! 目录 目录 作者…...

基于LangGraph与Gemini构建具备规划-执行-反思能力的智能研究助手
1. 项目概述:一个能“思考”的智能研究助手如果你正在寻找一个能帮你自动完成复杂网络研究、并给出有据可查答案的智能应用,那么这个基于 Google Gemini 和 LangGraph 构建的全栈项目,绝对值得你花时间深入探索。它不仅仅是一个简单的聊天机器…...

如何快速上手Minecraft PCL启动器:10个简单步骤打造你的游戏世界
如何快速上手Minecraft PCL启动器:10个简单步骤打造你的游戏世界 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 想要轻松畅玩Minecraft却为复杂的启动和模组管…...
)
MCP低代码平台集成调试失效全解(含官方未公开的Debug Mode激活密钥)
更多请点击: https://intelliparadigm.com 第一章:MCP低代码平台集成调试失效全解(含官方未公开的Debug Mode激活密钥) 当MCP(Model-Code-Platform)低代码平台在跨系统集成场景中出现调试断点不触发、日志…...

3种简单方法彻底解决Navicat试用期问题:免费无限重置方案
3种简单方法彻底解决Navicat试用期问题:免费无限重置方案 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 还在为N…...

在Windows上解锁苹果触控板的原生体验:mac-precision-touchpad完全指南
在Windows上解锁苹果触控板的原生体验:mac-precision-touchpad完全指南 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/ma/mac-preci…...

Windows触控板终极方案:mac-precision-touchpad驱动完整指南深度解析
Windows触控板终极方案:mac-precision-touchpad驱动完整指南深度解析 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/ma/mac-precisi…...

如何用Ryujinx在电脑上畅玩Switch游戏:从零开始的终极指南
如何用Ryujinx在电脑上畅玩Switch游戏:从零开始的终极指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 想在电脑上体验《塞尔达传说:旷野之息》或《超级马里…...

别再只重启服务了!深入RabbitMQ客户端源码,看懂AmqpIOException到底怎么来的
从Socket到异常栈:解码RabbitMQ客户端IO异常的底层真相 当监控系统第17次报警显示AmqpIOException时,团队里的中级工程师小王习惯性地执行了服务重启。这个动作就像按下老式电视机的雪花屏,短暂恢复后总会再次出现。我们是否思考过࿱…...
)
保姆级教程:在AutoSar CP架构下为CAN报文配置SecOC(基于Davinci Configurator)
实战指南:基于Davinci Configurator的AutoSar CP架构SecOC配置全解析 在汽车电子领域,信息安全已成为功能安全之外的另一大核心诉求。随着车载网络攻击面不断扩大,传统CAN总线"裸奔"式的通信方式正面临严峻挑战。作为AutoSar标准中…...

LSTM序列预测模型详解与应用实践
1. 序列预测与循环神经网络基础序列预测是机器学习中一个极具挑战性的领域,它要求模型能够理解并预测数据点之间的时序关系。想象一下,你正在观看一部悬疑电影,随着剧情推进,你不断根据之前的线索猜测接下来会发生什么——这正是序…...