数据结构与算法—散列表
目录
散列表
散列函数
散列冲突解决
1、开放寻址法
1.1 线性探测
1.2 二次探测
1.3 双重散列
2、链表法
使用场景
单词查找
散列表与链表的结合使用LRU
散列表总结
散列表实例
散列表
Word 单词拼写功能,如何实现的?散列表(Hash Table)
散列表用的是数组支持按照下标随机访问数据的特性。散列表其实是数组的一种扩展。
用空间换时间
散列表就是用数组支持按照下标随机访问的时候,时间复杂度O(1)的特性。
通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应的下标位置。当查询键值元素时,用散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。
散列函数
Hash(key) key表示元素的键值,hash(key)的值表示经过散列函数计算得到的散列值
散列函数设计的要求
- 散列函数计算得到的散列值是一个非负整数
- 如果key1=key2,hash(key1) = hash(key2)
- 如果key1不等于key2,那hash(key1)不等于hash(key2)
散列冲突无法避免,如著名的MD5,SHA,CRC.而且数组的存储空间有限,也会增大散列冲突的概率。
1、设计散列函数
要点1,散列函数的设计不能太复杂;2、散列函数生成的值要尽可能随机并且均匀分布。
方法:直接寻址法,平方取中法,折叠法,随机数法。
Hash("nice") = (("n" - "a") * 26 * 26 *26 + ("i" - "a")*26 * 26 + ("c" - "a")*26 + ("e"-"a"))
散列冲突解决
1、开放寻址法
如果出现散列冲突,重新探测一个空闲位置,将其插入。
探测方法:
1.1 线性探测
插入:线性探测,存储位置被占用,就从当前位置开始,依次往后查找(尾部结束,接着从头找),直到找到空闲位置为止。
查找:通过散列函数求出要查找元素的键值对应的散列值,然后从数组中下标为散列值的元素和查找的元素。如果相等,找到。如果没有,顺序往后依次查找。如果变量数组中空位置,还没有找到,则说明查找元素并没有在散列列表中。
删除:特殊标记deleted。当线性探测查找的时候,遇到标记为deleted空间。并不是停下来,而且继续探测。
缺点,当插入的数据越来越多,散列冲突的可能性越来越大,空闲位置越来越少,探测时间越久。
1.2 二次探测
与线性探测很像,线性探测每次探测的步长是1,hash(key)+0,hash(key)+1, hash(key)+2
二次探测每次探测的步长变成原来的二次方 hash(key)+0 hash(key)+1^2 hash(key)+2^2
1.3 双重散列
不仅仅要使用一个散列函数,使用一组散列函数hash1(key),hash2(key) ,hash3(key)。函数依次使用,直到找到空闲位置。
不管那种探测方法,当散列表中空闲位置不多的时候,散列冲突的概率会大大提高。一般情况下,尽可能保证散列表中有一定比例的空闲槽位。我们用装载因子来表示空位的多少。
散列表的装载因子 = 填入表中元素个数 / 散列表的长度
装载因子越大,数目空闲位置越少,冲突越多,散列表的性能会下降。
装载因子过大解决方法
动态扩容,降低装载因子
装载因子的阈值设置要权衡时间、空间复杂度。如果内存空间多,对执行效率要求高,可以降低负载因子的阈值;反之,增加负载因子。
动态扩容,可能需要多次。可以将扩容操作穿插在插入操作过程中,分批完成。当装载因子大于阈值后,值申请空间,并不将老的数据搬移到新散列表中。
动态扩容期间的插入操作
当有新数据要插入时,将新数据插入新散列表中,并且从老的散列表中拿出一个数据放入新散列表。每次插入一个数据到散列表。重复上面的过程,老的数据搬移到新散列表中。插入操作的时间不受影响。时间复杂度O(1)
- 优点:散列表中的数据都存储在数组中,可以有效利用CPU缓存,加快查询速度。
- 缺点:删除数据比较麻烦,需要标记已删除的数据
当数据量比较小,装载因子小
2、链表法
在散列表中,每个桶会对应一条链表。所有散列值相同的元素我们都放到相同桶位对应的链表中。
当插入时,只需要通过散列函数计算出对应的散列桶位。
将其插入到对应链表中。时间复杂度O(1)
查找,删除一个元素。计算对应的桶,然后遍历链表查找或删除。复杂度与链表长度k成正比O(k)
- 优点:对内存利用率比较好,需要时申请;对于大装载因子的容忍度更高,只要散列函数的随机值均匀,即使装载因子10,也就是链表的长度变长,查找效率下降,但比顺序表查找快很多。
- 链表的升华,更加高效的散列表;
- 缺点:链表因为要存储指针,对于较小的对象,比较耗内存。链表节点零散分布,不连续,对CPU缓存不友好。
- 使用跳表、红黑树取代链表。即使冲突,在极端情况下,查找时间O(logn)
使用场景
1、单词查找
常用英文单词20万左右。假设单词平均长度是10个字母,占用10字节空间。
- 20万英文单词,大约占用2MB空间。这个大小完全可以放在内存里。
- 当用户输入某个英文单词时,拿用户输入的单词去散列表中查找。如果查到,则说明拼写正确。
2、10万条URL访问日志
如何按照访问次数给URL排序?
- 遍历10万条数据,以URL为key,访问次数为value,存入散列表中。同时记录最大访问的次数K。时间复杂度O(n)
- 如果K不是很大,可以使用桶排序,时间复杂度O(n),如果K很大,(如大于10万),就使用快速排序 O(nlogn)
3、两个字符串数组比较
有两个字符串数组,每个数组有10万条字符串,如何快速找出两个数组中相同的字符串。
- 以第一个字符串构建散列表,key为字符串,value表示出现次数。
- 变量第二个字符串数组,以字符串key在散列表中查找,如果value大于0,则说明存在相同字符串。时间复杂度O(n)
4、散列表与链表的结合使用LRU
借助散列表,可以把LRU缓存淘汰算法的时间复杂度降低为O(1)
- 当需要缓存数据时,先在链表中查找这个数据,没有找到,直接将数据放到链表尾部;如果找到了,就把它移动到链表的尾部。所以单纯的使用链表实现LRU缓存淘汰算法的时间复杂度很高O(n)
- 将散列表与链表一起使用,时间复杂度O(1)
散列表总结
工业级散列表的特性
1,支持快速插入语、删除查找
2、内存占用,不能浪费过多内存;
3、稳定性,极端情况下的退化
实现散列表
1、设计合适的散列函数
2、定义装载因子阈值,并支持动态扩容
3、选择合适的散列冲突解决方法
散列表实例
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
#include <time.h>#define HASH_SHIFT 4
#define HASH_SIZE (1<<HASH_SHIFT)
#define HASH_MASK (HASH_SIZE - 1)struct hash_table{unsigned int used;unsigned long entry[HASH_SIZE];
};void hash_table_reset(struct hash_table *table)
{int i;table->used = 0;for(i = 0;i<HASH_SIZE;i++)table->entry[i] = ~0;
}unsigned int hash_function(unsigned long value)
{return value & HASH_MASK;
}void dump_hash_table(struct hash_table *table)
{int i;for(i = 0;i<HASH_SIZE;i++){if(table->entry[i] == ~0)printf("%2u: ",i);elseprintf("%2u: %2u\n",i,table->entry[i],hash_function(table->entry[i]));}
}void hash_function_test()
{int i;srandom(time(NULL));for(i = 0;i<10;i++){unsigned long val = random();printf("%10u->%2u",val,hash_function(val));}
}unsigned int next_probe(unsigned int pre_key)
{return(pre_key + 1) & HASH_MASK;
}void next_probe_test()
{int i;unsigned int key1,key2;key1 = 0;for(i = 0;i<HASH_SIZE;i++){key2 = next_probe(key1);printf("%2u -> %2u\n",key1,key2);key1 = key2;}
}void hash_table_add(struct hash_table *table,unsigned long value)
{unsigned int key = hash_function(value);if(table->used >= HASH_SIZE)return;while(table->entry[key] != ~0)key = next_probe(key);table->entry[key] = value;table->used++;
}unsigned int hash_table_slot(struct hash_table *table,unsigned long value)
{int i;unsigned int key = hash_function(value);for(i = 0;i<HASH_SIZE;i++){if(table->entry[key] == value || table->entry[key] == ~0)break;key = next_probe(key);}return key;
}bool hash_table_find(struct hash_table *table,unsigned long value)
{return table->entry[hash_table_slot(table,value)] == value;
}void hash_table_del(struct hash_table *table,unsigned long value)
{unsigned int i,k,j;if(!hash_table_find(table,value))return;//findi = j = hash_table_slot(table,value);while(true){table->entry[i] = ~0;do{j = next_probe(j);if(table->entry[j] == ~0)return;k = hash_function(table->entry[j]);}while((i<=j)?(i<k && k<=j) : (i<k || k<=j));table->entry[i] = table->entry[j];i = j;}table->used++;
}void hash_table_add_test()
{struct hash_table table;hash_table_reset(&table);hash_table_add(&table,1234);int ret;ret = hash_table_find(&table,1234);printf("ret res=%d\n",ret);
}void hash_table_del_test()
{struct hash_table table;int i;hash_table_reset(&table);for(i = 0;i<HASH_SIZE;i++)hash_table_add(&table,i);dump_hash_table(&table);hash_table_del(&table,5);dump_hash_table(&table);
}void main()
{//hash_table_add_test();hash_table_del_test();return;
}相关文章:

数据结构与算法—散列表
目录 散列表 散列函数 散列冲突解决 1、开放寻址法 1.1 线性探测 1.2 二次探测 1.3 双重散列 2、链表法 使用场景 单词查找 散列表与链表的结合使用LRU 散列表总结 散列表实例 散列表 Word 单词拼写功能,如何实现的?散列表(Has…...

计算机网络笔记、面试八股(一)—— TCP/IP网络模型
本章目录1. TCP/IP网络模型1.1 应用层1.1.1 应用层作用1.1.2 应用层有哪些常用协议1.2 运输层1.2.1 TCP与UDP的区别1.2.2 分块传输1.2.3 端口1.3 网络层1.3.1 IP报文1.3.2 IP地址1.3.3 网络号和主机号的获得1.3.4 子网掩码的获得1.3.5 路由1.3.6 IP地址与MAC地址的区别1.3.7 AR…...
:国际化)
Servlet笔记(18):国际化
三个概念 国际化: 意义着一个网站提供不同版本的翻译成访问者的语言或国籍的内容。本地化: 意味着向网站添加资源,以使其适应特定的地理或文化区域。区域设置: 针对某个国家的某个地区的设置。 Servlet可以根据请求者的区域设置…...

kibana搭建(windowslinux)
1.说明 搭建kibana方便查询es库,本文分别对windows和linux版本进行安装,因为es集群版本是7.4.1,所以配套的kibana也是选择相同版本 2.下载 https://artifacts.elastic.co/downloads/kibana/kibana-7.4.1-windows-x86_64.zip https://artifact…...
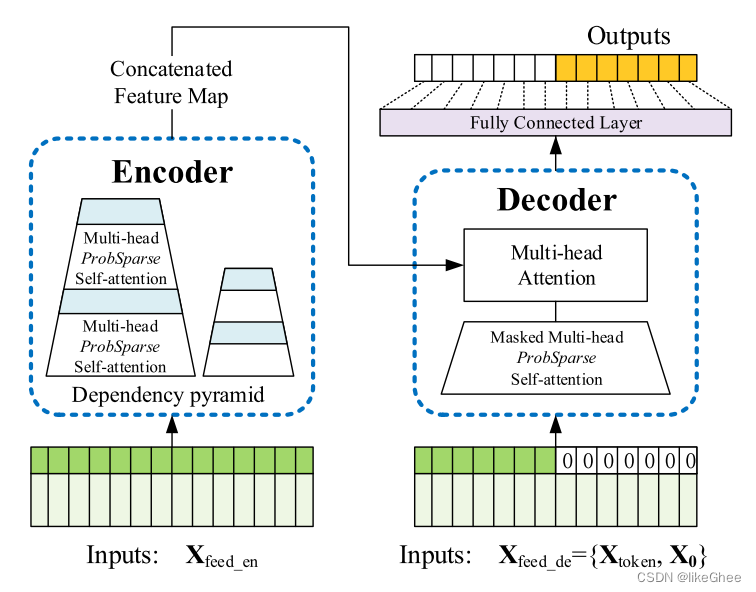
(pytorch进阶之路)Informer
论文:Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (AAAI’21 Best Paper) 看了一下以前的论文学习学习,我也是重应用吧,所以代码部分会比较多,理论部分就一笔带过吧 论文作者也很良心的…...
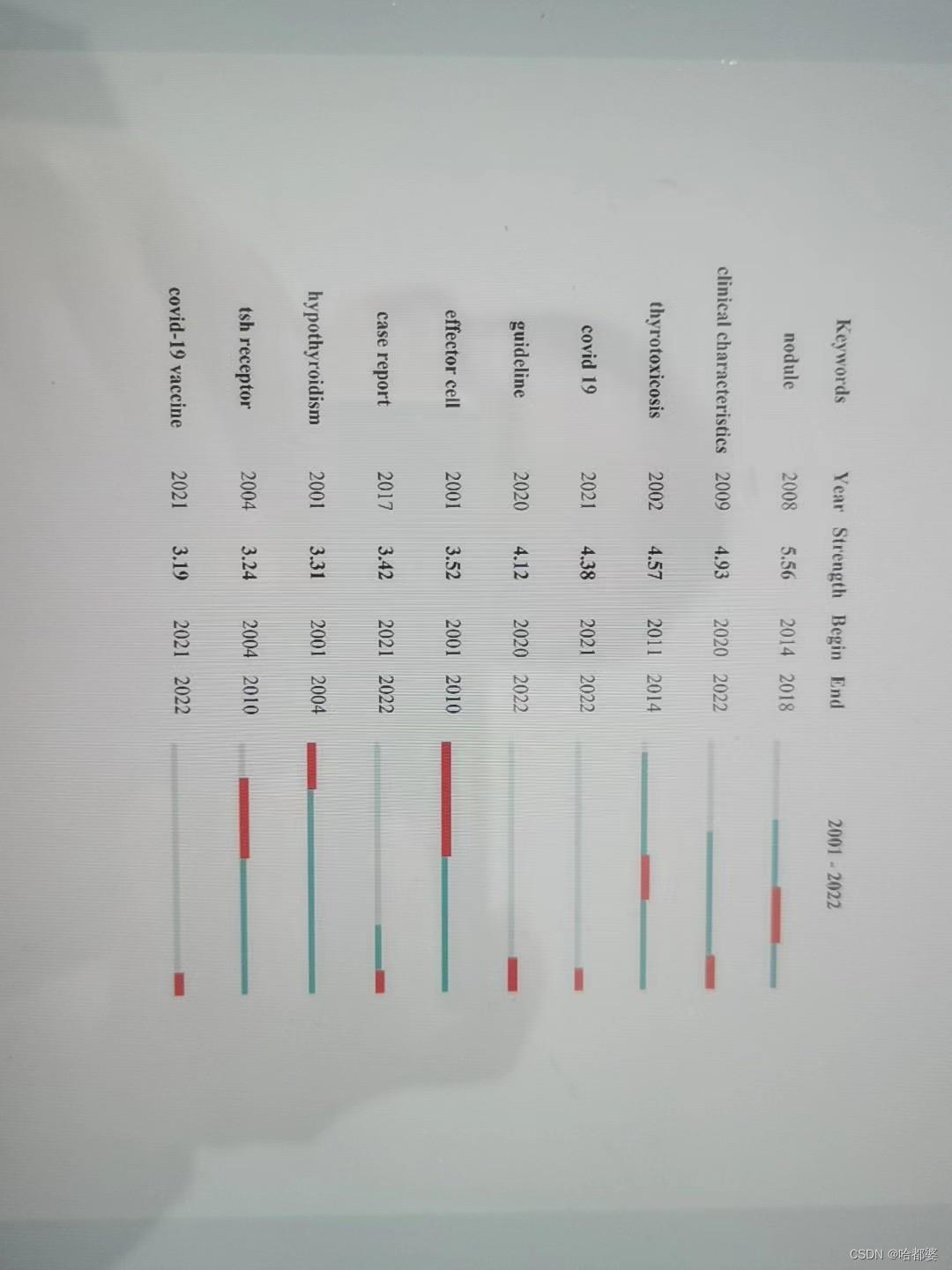
关键词聚类和凸现分析-实战1——亚急性甲状腺炎的
审稿人问题第8页第26行-请指出#是什么意思,并解释为什么亚急性甲状腺炎在这里被列为#8。我认为在搜索亚急性甲状腺炎相关文章时,关键词共现分析应该提供关键词共现的数据。这些结果的实际用途是什么?亚急性甲状腺炎是一种较为罕见但重要的甲状腺疾病&am…...

二叉树——二叉搜索树中的众数
二叉搜索树中的众数 链接 给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。 如果树中有不止一个众数,可以按 任意顺序 返回。 假定…...
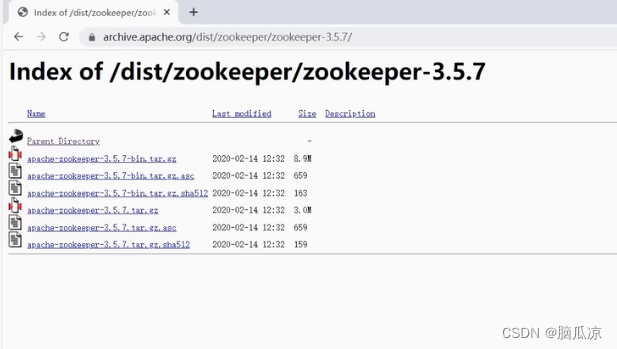
安装_配置参数解读_集群安装配置_启动选举_搭建启停脚本---大数据之ZooKeeper工作笔记004
这里首先下载zookeeper安装包,可以看到官网地址 找到download 点击下载 找到老一点的,我们找3.5.7 in the archive 点击 然后这里找到3.5.7这一个 然后下载这个-bin.tar.gz这个...
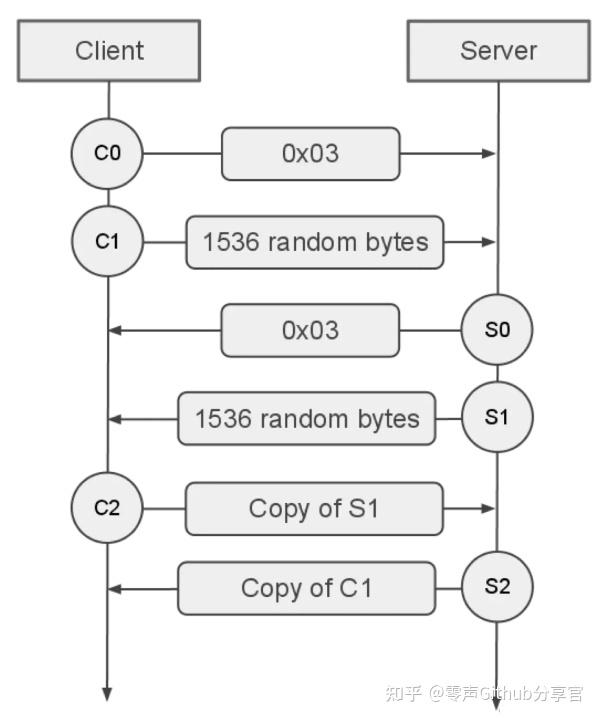
RTMP的工作原理及优缺点
一.什么是RTMP?RTMP(Real-Time Messaging Protocol,实时消息传输协议)是一种用于低延迟、实时音视频和数据传输的双向互联网通信协议,由Macromedia(后被Adobe收购)开发。RTMP的工作原理是&#…...

【数据结构与算法】——第八章:排序
文章目录1、基本概念1.1 什么是排序1.2 排序算法的稳定性1.3 排序算法的分类1.4 内排序的方法2、插入排序2.1 直接插入排序2.2 直接插入排序2.3 希尔排序3、交换排序3.1 冒泡排序3.2 快速排序4、选择排序4.1 简单选择排序4.2 树形选择排序4.3 堆排序4.4 二路归并排序5、基数排序…...

在linux中web服务器的搭建与配置
以下涉及到的linux命令大全查阅 https://www.runoob.com/linux/linux-command-manual.htmlvim命令查阅 https://www.runoob.com/linux/linux-vim.htmlscp命令https://www.runoob.com/linux/linux-comm-scp.html首先要有一个请求的服务地址用ssh 进入到linux系统中ssh 请求的服务…...
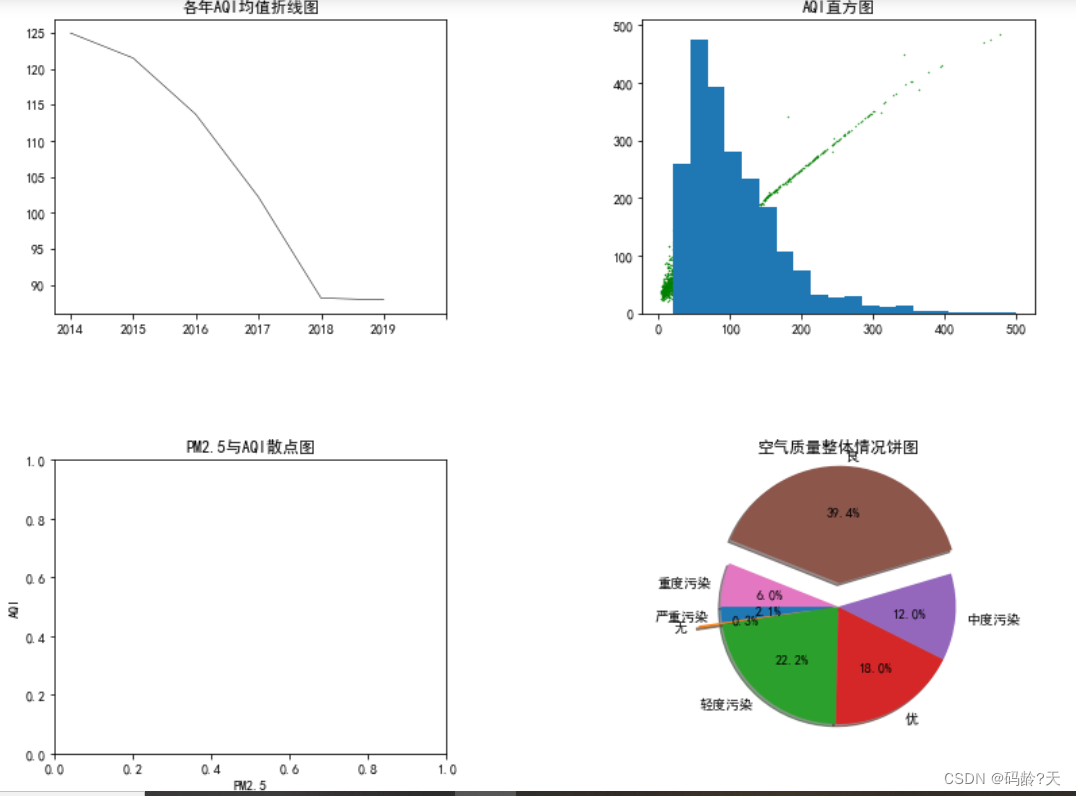
《Python机器学习》基础代码2
👂 逝年 - 夏小虎 - 单曲 - 网易云音乐 目录 👊Matplotlib综合应用:空气质量监测数据的图形化展示 🌼1,AQI时序变化特点 🌼2,AQI分布特征 相关性分析 🌼3,优化图形…...

如何基于MLServer构建Python机器学习服务
文章目录前言一、数据集二、训练 Scikit-learn 模型三、基于MLSever构建Scikit-learn服务四、测试模型五、训练 XGBoost 模型六、服务多个模型七、测试多个模型的准确性总结参考前言 在过去我们训练模型,往往通过编写flask代码或者容器化我们的模型并在docker中运行…...

9.1 IGMPv1实验
9.4.1 IGMPv1 实验目的 熟悉IGMPv1的应用场景掌握IGMPv1的配置方法实验拓扑 实验拓扑如图9-7所示: 图9-7:IGMPv1 实验步骤 (1)配置IP地址 MCS1的配置 MCS1的IP地址配置如图9-8所示: 图9-8:MCS1的配置 …...

软考高级系统分析师系列论文之十:论实时控制系统与企业信息系统的集成在通信业应用
软考高级系统分析师系列论文之十:论实时控制系统与企业信息系统的集成在通信业应用 一、摘要二、正文三、总结一、摘要 近年来,在应用需求的强大驱动下,我国通信业有了长足的进步。现有通信行业中的许多企业单位,如电信公司或移动集团,其信息系统的主要特征之一是对线路的…...
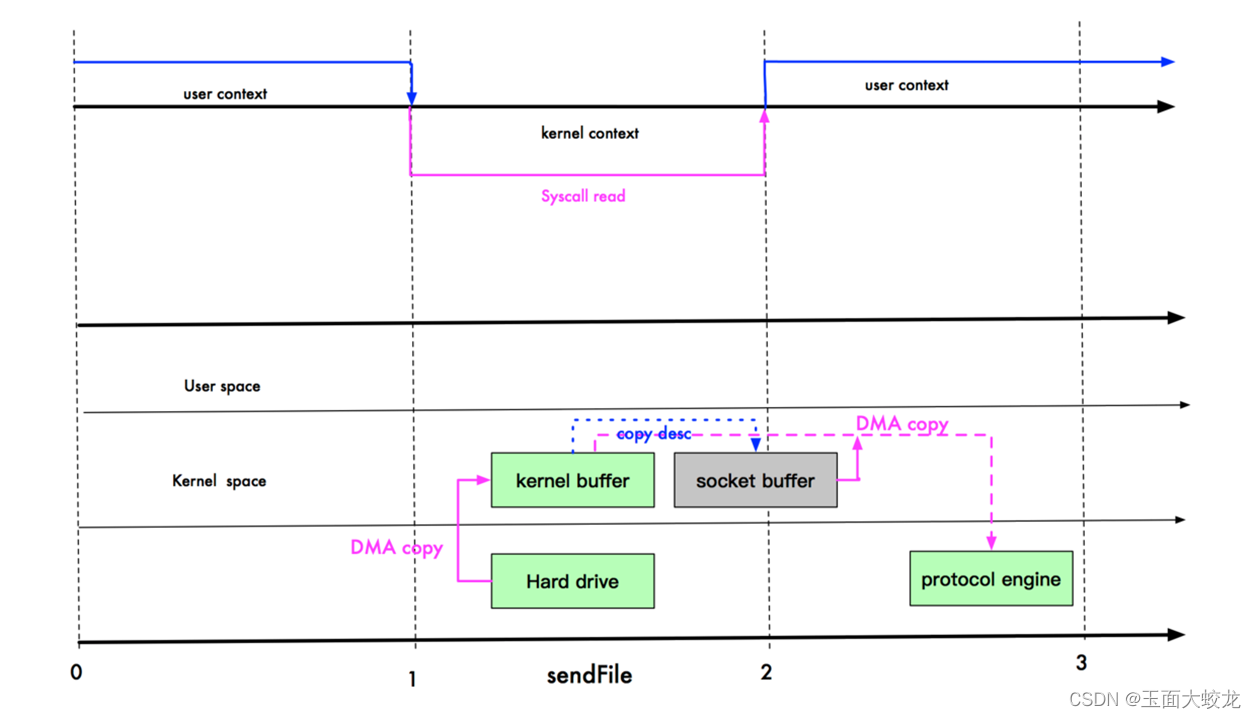
NIO与零拷贝
目录 一、零拷贝的基本介绍 二、传统IO数据读写的劣势 三、mmap优化 四、sendFile优化 五、 mmap 和 sendFile 的区别 六、零拷贝实战 6.1 传统IO 6.2 NIO中的零拷贝 6.3 运行结果 一、零拷贝的基本介绍 零拷贝是网络编程的关键,很多性能优化都离不开。 在…...
)
【PAT甲级题解记录】1151 LCA in a Binary Tree (30 分)
【PAT甲级题解记录】1151 LCA in a Binary Tree (30 分) 前言 Problem:1151 LCA in a Binary Tree (30 分) Tags:树的遍历 并查集 LCA Difficulty:剧情模式 想流点汗 想流点血 死而无憾 Address:1151 LCA in a Binary Tree (30 分…...

Android 获取手机语言环境 区分简体和繁体,香港,澳门,台湾繁体
安卓和IOS 系统语言都是准守:ISO 639 ISO 代码表IOS:plus.os.language ios正常,安卓下简体和繁体语言,都是zh安卓获取系统语言方法:Locale.getDefault().language手机切换到繁体(台湾,香港&…...

一文搞懂Python时间序列
Python时间序列1. datetime模块1.1 datetime对象1.2 字符串和datatime的相互转换2. 时间序列基础3. 重采样及频率转换4. 时间序列可视化5. 窗口函数5.1 移动窗口函数5.2 指数加权函数5.3 二元移动窗口函数时间序列(Time Series)是一种重要的结构化数据形…...
GeoServer发布数据进阶
GeoServer发布数据进阶 GeoServer介绍 GeoServer是用于共享地理空间数据的开源服务器。 它专为交互操作性而设计,使用开放标准发布来自任何主要空间数据源的数据。 GeoServer实现了行业标准的 OGC 协议,例如网络要素服务 (WFS)…...

FireRedASR Pro模型架构浅析:从卷积神经网络到端到端设计
FireRedASR Pro模型架构浅析:从卷积神经网络到端到端设计 最近在语音识别圈子里,FireRedASR Pro这个名字被提到的次数越来越多了。不少朋友都在问,这个模型到底有什么特别之处,为什么大家都在讨论它。其实,它的核心魅…...
)
ArcMap地图数字化实战:从加载地形图到保存成果的完整流程(附常见问题解决)
ArcMap地图数字化实战:从加载地形图到保存成果的完整流程(附常见问题解决) 在GIS领域,地图数字化是将纸质地图或图像转换为计算机可识别和处理的数字格式的基础工作。这项技能不仅是GIS专业学生的必修课,也是城市规划、…...

GraphRAG实战指南:12种技术对比,教你如何选择最适合的图结构RAG方案
GraphRAG技术选型实战:12种方案深度解析与场景适配指南 当传统RAG在简单问答场景中表现尚可时,面对需要多跳推理、深度上下文关联的复杂任务,GraphRAG正展现出独特优势。本文将从工程实践角度,拆解12种主流GraphRAG技术的核心差异…...

影墨·今颜小红书模型与Claude Code的协同编程应用设想
影墨今颜小红书模型与Claude Code的协同编程应用设想 最近在琢磨一个挺有意思的组合:让擅长生成代码的Claude Code和专门为小红书内容优化的影墨今颜模型一起干活。听起来有点跨界,但仔细想想,这俩搭档起来,说不定能解决不少实际…...

5G NR随机接入实战:手把手教你理解并排查MSG3发送失败的那些坑
5G NR随机接入实战:MSG3发送失败全场景排查指南 当5G终端尝试接入网络时,随机接入过程中的MSG3发送失败是最常见的"拦路虎"之一。作为网络优化的关键指标,MSG3失败直接影响用户体验和网络KPI。本文将带您深入协议栈底层,…...

JPEXS Free Flash Decompiler社区大使选拔流程:申请与评审完全指南
JPEXS Free Flash Decompiler社区大使选拔流程:申请与评审完全指南 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler JPEXS Free Flash Decompiler是一款功能强大的Flash反编译…...

HP-Socket技术债务管理成熟度提升计划:行动项与时间表
HP-Socket技术债务管理成熟度提升计划:行动项与时间表 【免费下载链接】HP-Socket High Performance TCP/UDP/HTTP Communication Component 项目地址: https://gitcode.com/gh_mirrors/hp/HP-Socket HP-Socket作为高性能TCP/UDP/HTTP通信组件,随…...

RCLAMP0542T.TCT静电保护TVS 二极管阵列 SEMTECH 电子元器件IC 芯片
RCLAMP0542T.TCT 是由 SEMTECH 公司推出的一款超低电容、双通道ESD(静电放电)保护 TVS 二极管阵列,具备0.45pF 超低电容、5A 浪涌承受能力和超小型 SLP1610P4T 封装,专为高速数据接口设计,广泛应用于通信设备、消…...

STM32HAL库项目实战:我把W5500和MQTTClient库‘缝’起来,实现了阿里云OTA升级前传
STM32HAL库与W5500深度整合:从MQTT云连接到OTA升级的工程实践 在嵌入式设备智能化浪潮中,远程固件升级(OTA)已成为工业设备的标配功能。本文将揭示如何基于STM32HAL库和W5500以太网芯片构建可靠的云连接通道,为后续OTA升级打下坚实基础。不同…...

Elasticsearch踩坑记录:scaled_float字段查询结果和你想的不一样?
Elasticsearch中的scaled_float:为什么你的查询结果总是不准确? 刚接触Elasticsearch的开发者经常会遇到一个令人困惑的现象:明明存储的是精确的浮点数,查询时却返回了意料之外的结果。这背后往往与scaled_float字段类型的特殊处理…...