11.7加减计数器,可置位~,数字钟分秒,串转并,串累加转并,24位串并128,流水乘法器,一些乘法器
信号发生器

方波,就是一段时间内都输出相同的信号

锯齿波就是递增
![]()
三角波就是先增后减

加减计数器
当mode为1则加,Mode为0则减;只要为0就输出zero

这样会出问题,因为要求是十进制,但是这里并没有考虑到9之后怎么办,所以就会使number输出超过9,应该额外要添加十进制的边缘判断,即mode为1,要加的时候也要判断一下是不是要继续加,而不是直接加

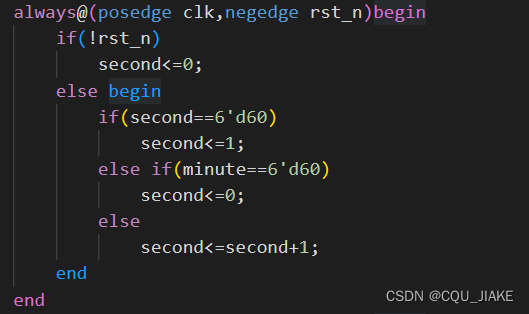
简易秒表
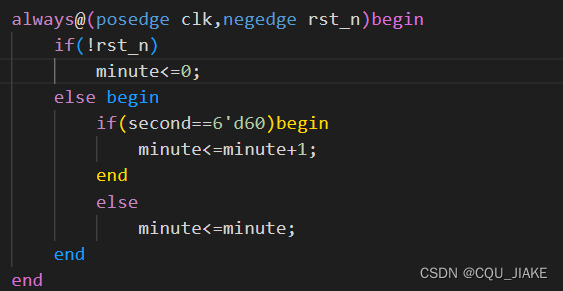
输出端口second为1~60,到60时,minute+1,分到60时,停止计数
秒的确定
分的确定
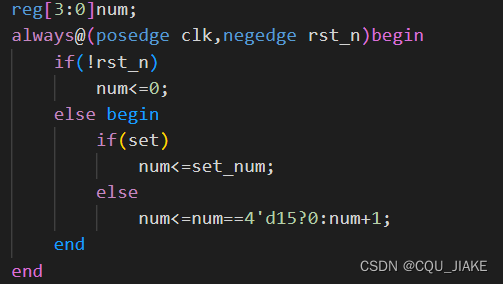
可置位计数器
就是有置位信号时,把当前数字置为要置的数字
然后要确定是十六进制
额外逻辑
串转并
输入端输入单位信号,累积到6个后,输出一个六位的信号

reg [5:0] data_reg;reg [2:0] data_cnt;always @(posedge clk or negedge rst_n ) beginif(!rst_n)ready_a <= 'd0;elseready_a <= 1'd1;endalways @(posedge clk or negedge rst_n ) beginif(!rst_n)data_cnt <= 'd0;else if(valid_a && ready_a)data_cnt <= (data_cnt == 3'd5) ? 'd0 : (data_cnt + 1'd1);endalways @(posedge clk or negedge rst_n ) beginif(!rst_n)data_reg <= 'd0;else if(valid_a && ready_a)data_reg <= {data_a, data_reg[5:1]};endalways @(posedge clk or negedge rst_n ) beginif(!rst_n)beginvalid_b <= 'd0;data_b <= 'd0;endelse if(data_cnt == 3'd5)beginvalid_b <= 1'd1;data_b <= {data_a, data_reg[5:1]};endelsevalid_b <= 'd0;end
数据累加输出
当接受到4个输入数据后,输出一个这四个数据的累加结果

`timescale 1ns/1nsmodule valid_ready(input clk , input rst_n ,input [7:0] data_in ,input valid_a ,input ready_b ,output ready_a ,output reg valid_b ,output reg [9:0] data_out
);
reg [1:0] data_cnt;assign ready_a = !valid_b | ready_b;always @(posedge clk or negedge rst_n ) beginif(!rst_n) data_cnt <= 'd0;else if(valid_a && ready_a)data_cnt <= (data_cnt == 2'd3) ? 'd0 : (data_cnt + 1'd1);
end
always @(posedge clk or negedge rst_n ) beginif(!rst_n) valid_b <= 'd0;else if(data_cnt == 2'd3 && valid_a && ready_a)valid_b <= 1'd1;else if(valid_b && ready_b)valid_b <= 1'd0;
endalways @(posedge clk or negedge rst_n ) beginif(!rst_n) data_out <= 'd0;else if(ready_b && valid_a && ready_a && (data_cnt == 2'd0))data_out <= data_in;else if(valid_a && ready_a)data_out <= data_out + data_in;endendmodule非阻塞赋值,就是把次态给现态,就是说右侧的是次态,但是现在还不用,是下个状态的情况,那么条件判断里就是导致其进入下个状态的条件
非整数倍数据位宽转换24to128
数据位宽转换,24位转128位,先到的数据为高位
也是串转并的一种,只不过最后的时候是只要一部分
思路都是,先判断输入的有效性,有效时,就对数据暂存器做出改变;对于输出时,如果可以输出了,即让输出,就输出,没有使能,就不输出,依然暂存。
24和128的最小公倍数为384,所以每到384的时候,就是对齐了一次,即完成一次周期
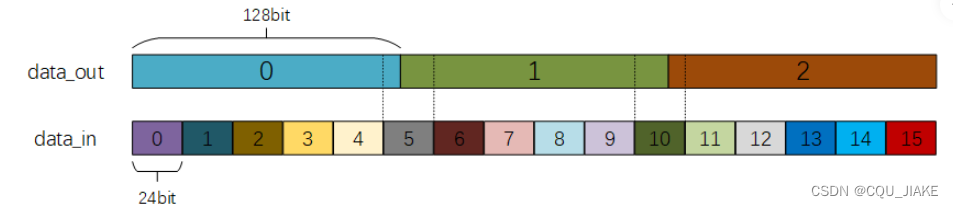
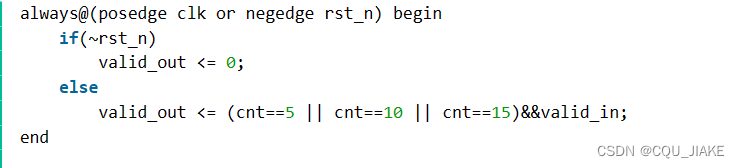
所以每当cnt到5,10,15时,就需要输出一次,并拉高valid_out一个周期

简单的输入信号计数器,表示已经输入了几个24位的信号
数据暂存器,每当输入有效时,将数据从低位移入,注意是低位,而且是要在输入有效时操作
输出使能
需要注意的是,非阻塞是使的关系,即这个clk里收到了信号,但是并不在这个周期里即时发生改变,而是在下个clk里再发生改变,也就使得逻辑上同步的输入输出,不是在同一个周期上发生,而是先有输入,才有下个周期对应的输出,每个周期输出的都是上个周期的结果。当下输入的数据,在下个周期出结果
但在赋值时,由于是非阻塞,所以也是在给次态赋值,所以这个周期里干的事,都不是这个周期里的,而是去确定下个周期的,这个周期里的事都在上个周期里确定了;也就是说此时的条件都是下个周期的,而不是当下的。
所以写的时候,就不要想的是串行。而是想写的是一个一个模块,根据不同的输入给出不同的输出
就是注意![]()
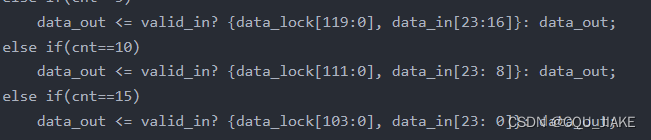
先到的数据在高位,满的时候,先从高位出去,即FIFO。只是截取高位的时候,是从暂存器的低位开始截取的,也就是说,还是先进的最高位先出去;然后输出的时候,是先尝试输出再寄存,因为寄存的时候不管截不截取,它就是全部存进去。但是输出的时候,要判断并截取一部分新的
valid_in是判断当前的输出是不是有效,如果无效,即使输入了,要发生一些改变时,也不会
之前担心的是,如果能输出的时候,先在暂存器里输入了一遍,结果又在输入里输入了一遍
但实际上,这就是为什么要用非阻塞而不是阻塞。即各个模块都是并行的,都是并行的,即在这个时钟刻里,用的都是上个时间里的数值,而且不会发生改变。用非阻塞可以不用考虑这样的先后问题,如果是阻塞,就必须先尝试输出,才能暂存
用阻塞也会出问题,出时序问题,马丹
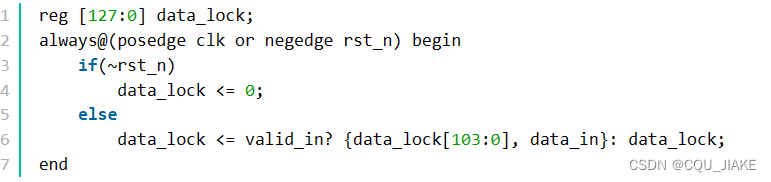
`timescale 1ns/1nsmodule width_24to128(input clk , input rst_n ,input valid_in ,input [23:0] data_in ,output reg valid_out ,output reg [127:0] data_out
);reg [3:0] cnt;reg [127:0] data_lock;always@(posedge clk or negedge rst_n) beginif(~rst_n)cnt <= 0;elsecnt <= ~valid_in? cnt:cnt+1;endalways@(posedge clk or negedge rst_n) beginif(~rst_n)valid_out <= 0;elsevalid_out <= (cnt==5 || cnt==10 || cnt==15)&&valid_in;endalways@(posedge clk or negedge rst_n) beginif(~rst_n)data_lock <= 0;elsedata_lock <= valid_in? {data_lock[103:0], data_in}: data_lock;endalways@(posedge clk or negedge rst_n) beginif(~rst_n)data_out <= 0;else if(cnt==5)data_out <= valid_in? {data_lock[119:0], data_in[23:16]}: data_out;else if(cnt==10)data_out <= valid_in? {data_lock[111:0], data_in[23: 8]}: data_out;else if(cnt==15)data_out <= valid_in? {data_lock[103:0], data_in[23: 0]}: data_out;elsedata_out <= data_out;end
endmodule
流水线乘法器

流水线
就是采用乘法竖式的思想,将乘法转化加法,最高位为n,则就有n个加法数
用循环简化代码

`timescale 1ns/1nsmodule multi_pipe#(parameter size = 4
)(input clk , input rst_n ,input [size-1:0] mul_a ,input [size-1:0] mul_b ,output reg [size*2-1:0] mul_out
);
wire [2*size-1 : 0] a,b;
reg [2*size-1 : 0]temp0,temp1,temp2,temp3;
assign a=mul_a;
assign b=mul_b;
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
temp0<=0;
temp1<=0;
temp2<=0;
temp3<=0;
end
else
begin
temp0 <= b[0] ? a : 0;
temp1<= b[1] ? a<<1 : 0;
temp2<= b[2] ? a<<2 : 0;
temp3<= b[3] ? a<<3 : 0;
end
end
always @ (posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
mul_out=0;
end
else
begin
mul_out=temp0+temp1+temp2+temp3;
endend
endmodule
`timescale 1ns/1nsmodule multi_pipe#(parameter size = 4
)(input clk , input rst_n ,input [size-1:0] mul_a ,input [size-1:0] mul_b ,output reg [size*2-1:0] mul_out
);//parameter parameter N = size * 2;//definationwire [N - 1 : 0] temp [0 : 3];reg [N - 1 : 0] adder_0;reg [N - 1 : 0] adder_1;//output genvar i;generatefor(i = 0; i < 4; i = i + 1)begin : loopassign temp[i] = mul_b[i] ? mul_a << i : 'd0;endendgeneratealways@(posedge clk or negedge rst_n)beginif(!rst_n) adder_0 <= 'd0;else adder_0 <= temp[0] + temp[1];endalways@(posedge clk or negedge rst_n)beginif(!rst_n) adder_1 <= 'd0;else adder_1 <= temp[2] + temp[3];endalways@(posedge clk or negedge rst_n)beginif(!rst_n) mul_out <= 'd0;else mul_out <= adder_0 + adder_1;end
endmodule

就是说,一个数位数是否为1,决定另一个数是否为拓位后的数还是0
状态图实现任意位乘法
2个32位整数相乘,实际上是进行了32次加法操作

流程图中,x因为需要左移,所以32位长度的x应该用一个64位寄存器来存储,这样才能保证x左移后不会发生高位丧失。
取绝对值操作
首先是获取符号位,然后根据符号位去决定对应的操作
如果是正数,就直接赋值;不然,就先取反再+1

输入为mult_begin,拉高后乘法再开始,直到运算结束,或者人为拉低
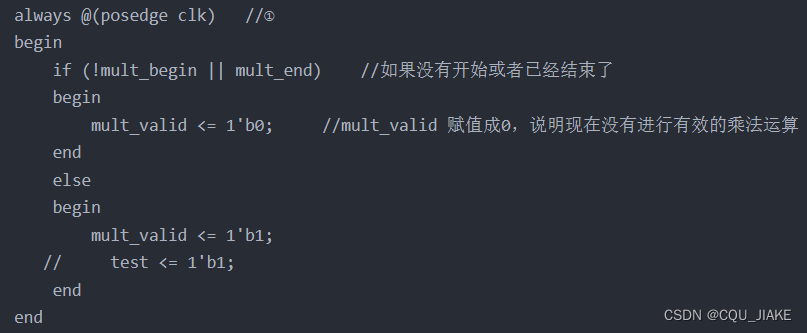
需要注意的是,右移y,那么每次都是去掉y的最低位,然后需要在最高位补0,即整体往右移动一位;这个块就是实现每次都右移一位y

这个是左移x,不会丢位,因为最多移32次,最多就是到最高位

然后这个是判断加数,如果此时y的最低位是1,那么就加;不然,就不加为0;

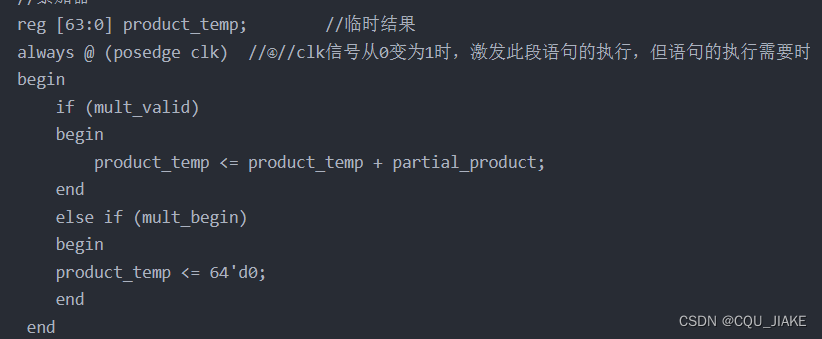
符号位确定

循环实现
相同的思路,第二种就是用for循环简化了代码


采用移位寄存器同样可以实现,上面那个是每次都计算,都是从头开始移位i次,采用移位寄存器后就是不断复用上一次的结果,只移位一次就可以,而不是每次都移位i次
用i,i就代表移位的次数,可以简便的读取到第i位,以及左移i位的结果
流水线是每次都加两个新的,

仿真文件
`timescale 1ns / 1psmodule tb;// Inputsreg clk;reg mult_begin;reg [31:0] mult_op1;reg [31:0] mult_op2;// Outputswire [63:0] product;wire mult_end;// Instantiate the Unit Under Test (UUT)multiply uut (.clk(clk), .mult_begin(mult_begin), .mult_op1(mult_op1), .mult_op2(mult_op2), .product(product), .mult_end(mult_end));initial begin// Initialize Inputsclk = 0;mult_begin = 0;mult_op1 = 0;mult_op2 = 0;// Wait 100 ns for global reset to finish#100;mult_begin = 1;mult_op1 = 32'H00001111;mult_op2 = 32'H00001111;#400;mult_begin = 0;#500;mult_begin = 1;mult_op1 = 32'H00001111;mult_op2 = 32'H00002222;#400;mult_begin = 0;#500;mult_begin = 1;mult_op1 = 32'H00000002;mult_op2 = 32'HFFFFFFFF;#400;mult_begin = 0;#500;mult_begin = 1;mult_op1 = 32'H00000002;mult_op2 = 32'H80000000;#400;mult_begin = 0;// Add stimulus hereendalways #5 clk = ~clk;
endmodule一些细节
这是两者的位数关系
非流水线设计就是每次乘法运算只输出一个结果
相关文章:
11.7加减计数器,可置位~,数字钟分秒,串转并,串累加转并,24位串并128,流水乘法器,一些乘法器
信号发生器 方波,就是一段时间内都输出相同的信号 锯齿波就是递增 三角波就是先增后减 加减计数器 当mode为1则加,Mode为0则减;只要为0就输出zero 这样会出问题,因为要求是十进制,但是这里并没有考虑到9之后怎么办&a…...

【模型推理优化学习笔记】CUDA加速矩阵乘计算
矩阵乘可以利用gpu多线程并行的特点进行加速计算,但是传统简单的方法需要多次读取数据到寄存器中,增加耗时,因此利用gpu的共享内存可以被一个block内的所有线程访问到的特性,结合tiling技术进行加速计算。 理论部分不解释了&#…...
第三届 “鹏城杯”(初赛)
第三届 “鹏城杯”(初赛) WEB Web-web1 反序列化tostring打Hack类 Payload:O%3A1%3A%22H%22%3A1%3A%7Bs%3A8%3A%22username%22%3BO%3A6%3A%22Hacker%22%3A2%3A%7Bs%3A11%3A%22%00Hacker%00exp%22%3BN%3Bs%3A11%3A%22%00Hacker%00cmd%22%3BN%3B%7D%7D…...

React Hooks为什么要在顶层使用?
为什么必须在函数顶层使用hooks? 使用过 hooks 的小伙伴应该都会发现,hooks只能在函数式组件的顶层使用,不能在循环,条件或嵌套函数中调用 Hook。 为什么呢? 查阅了很多答案,总结如下: hook…...
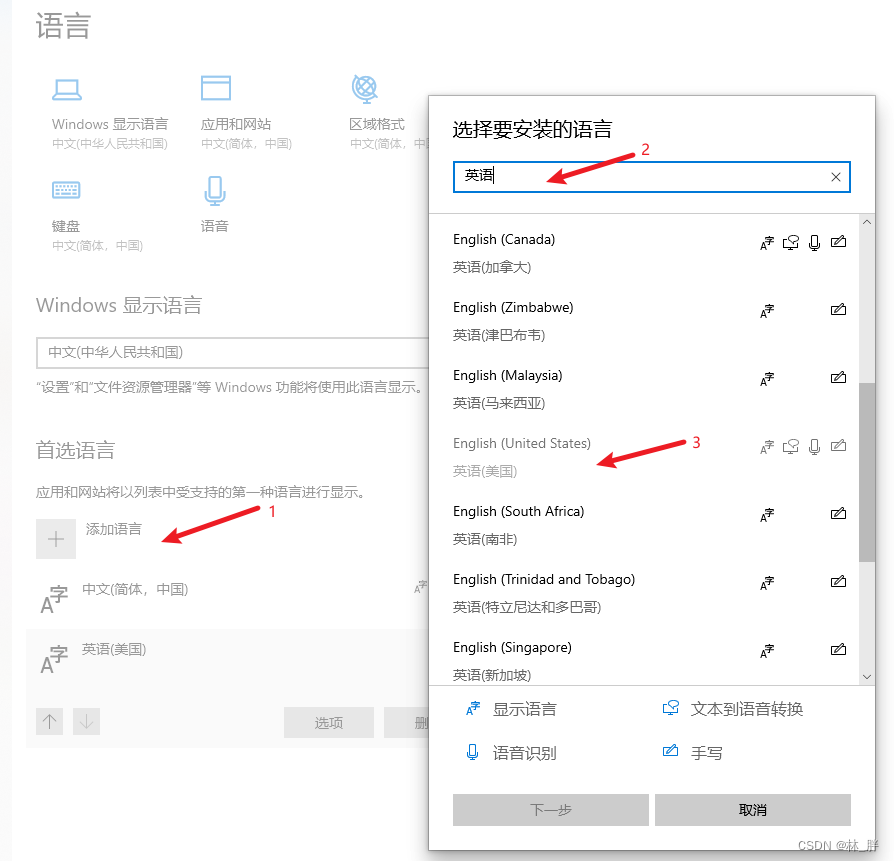
Vscode Vim自动切换
在VsCode里安装了Vim插件,由于Vim插件存在Normal和Insert两种模式,会需要经常性的按shift切换中英文,太过麻烦,本文介绍一下如何通过im-select来解决。 首先先确保自己的电脑里装有英文语言包,win10系统下可以使用Win…...

C语言初学1:详解#include <stdio.h>
一、概念 #include <stdio.h> 称为编译预处理命令,它在告诉C编译器在编译时包含stdio.h文件,如果在代码中,调用了这个头文件中的函数或者宏定义,则需引用该头文件。 二、作用 stdio.h是c语言中的标准输入输出的头文件&am…...
5 Tensorflow图像识别(下)模型构建
上一篇:4 Tensorflow图像识别模型——数据预处理-CSDN博客 1、数据集标签 上一篇介绍了图像识别的数据预处理,下面是完整的代码: import os import tensorflow as tf# 获取训练集和验证集目录 train_dir os.path.join(cats_and_dogs_filter…...
OpenCV 图像复制和图像区域读写
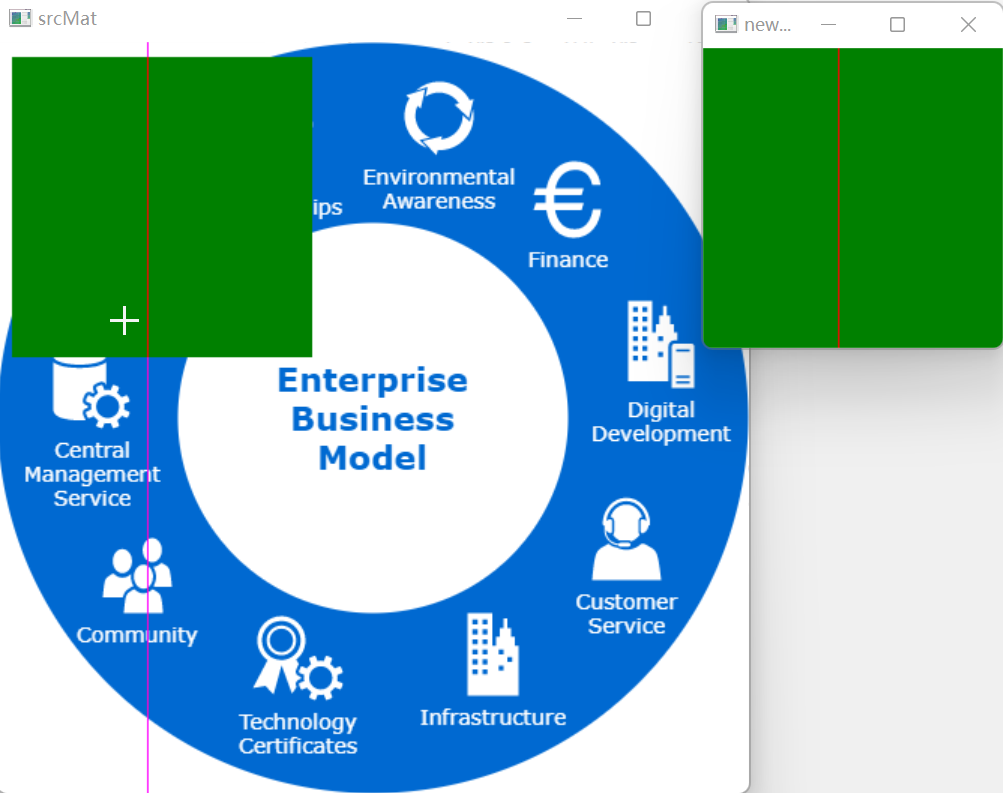
图像复制 共享数据, 使用 new Mat(srcMat, ...) 和 newMatsrcMat 生成新的Mat都和原Mat共享数据, 也就是说如果修改某一Mat,其他Mat也会随之改变复制全新的Mat, 使用CopyTo() 和 Clone() 方法将生成一个全新的Mat, 新Mat和原Mat不共享数据. 图像区域和点的读写 区域读取: 通过s…...
【分布式事务】初步探索分布式事务的概率和理论,初识分布式事的解决方案 Seata,TC 服务的部署以及微服务集成 Seata
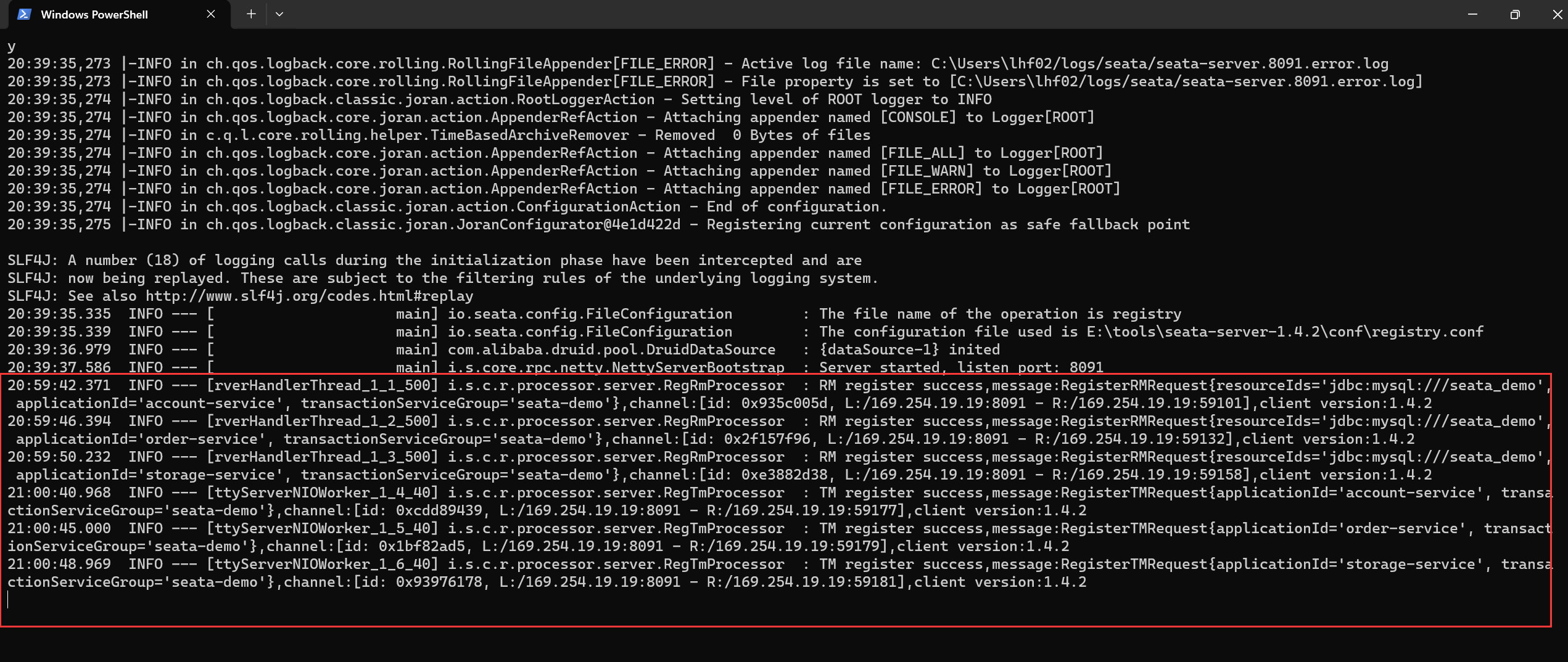
文章目录 一、分布式服务案例1.1 分布式服务 demo1.2 演示分布式事务问题 二、分布式事务的概念和理论2.1 什么是分布式事务2.2 CAP 定理2.3 BASE 理论2.4 分布式事务模型 三、分布式事务解决方案 —— Seata3.1 什么是 Seata3.2 Seata 的架构3.3 Seata 的四种分布式事务解决方…...
es6过滤对象里面指定的不要的值filter过滤
//过滤出需要的值this.dataItemTypeSelectOption response.data.filter(ele > ele.dictValue tree||ele.dictValue float4);//过滤不需要的值this.dataItemTypeSelectOption response.data.filter((item) > {return item.dictValue ! "float4"&&it…...

Docker从入门到上天系列第二篇:传统虚拟机和容器的对比以及Docker的作用以及所解决的问题
大神推荐:作者有幸结识技术大神孙哥为好友获益匪浅,现在把孙哥作为朋友分享给大家。 孙哥链接:孙哥个人主页 作者简介:一个颜值99分,只比孙哥差一点的程序员。 本专栏简介:话不多说,让我们一起干翻Docker 本文章简介:话不多说,让我们讲清楚首先讲清楚Docker是什么 文章…...

共话医疗数据安全,美创科技@2023南湖HIT论坛,11月11日见
11月11日浙江嘉兴 2023南湖HIT论坛 如约而来 深入数据驱动运营管理、运营数据中心建设、数据治理和数据安全、数据资产“入表”等热点、前沿话题 医疗数据安全、数字化转型深耕者—— 美创科技再次深入参与 全新发布:医疗数据安全白皮书 深度探讨:数字…...

乐园要吸引儿童还是家长?万达宝贝王2000万会员的求精之路
2023年6月,万达宝贝王正式迈入“400店时代”。 万达宝贝王在全国200多座城市,以游乐设施、主题活动、成长课程服务10亿多用户,拥有2000多万名会员,是真正的国内儿童乐园领跑者。 当流量时代变成“留量”时代,用户增长…...

ps人像怎么做渐隐的效果?
photoshop怎么制作人像渐隐的图片效果?渐隐效果需要使用渐变来实现,下面我们就来看看详细的教程。 首先,我们打开Photoshop,点击屏幕框选的【打开】,打开一张背景图片。 下面,我们点击左上角【文件】——【…...

为什么IN操作符一般比OR操作符清单执行更快
IN操作符一般比OR操作符清单执行更快的主要原因有以下几点: 查询优化:数据库管理系统通常会针对IN操作符进行更好的查询优化。它可以使用哈希表或二叉搜索树等数据结构来更快地查找匹配的值,从而减少了搜索时间。而OR操作符需要逐个比较每个条…...
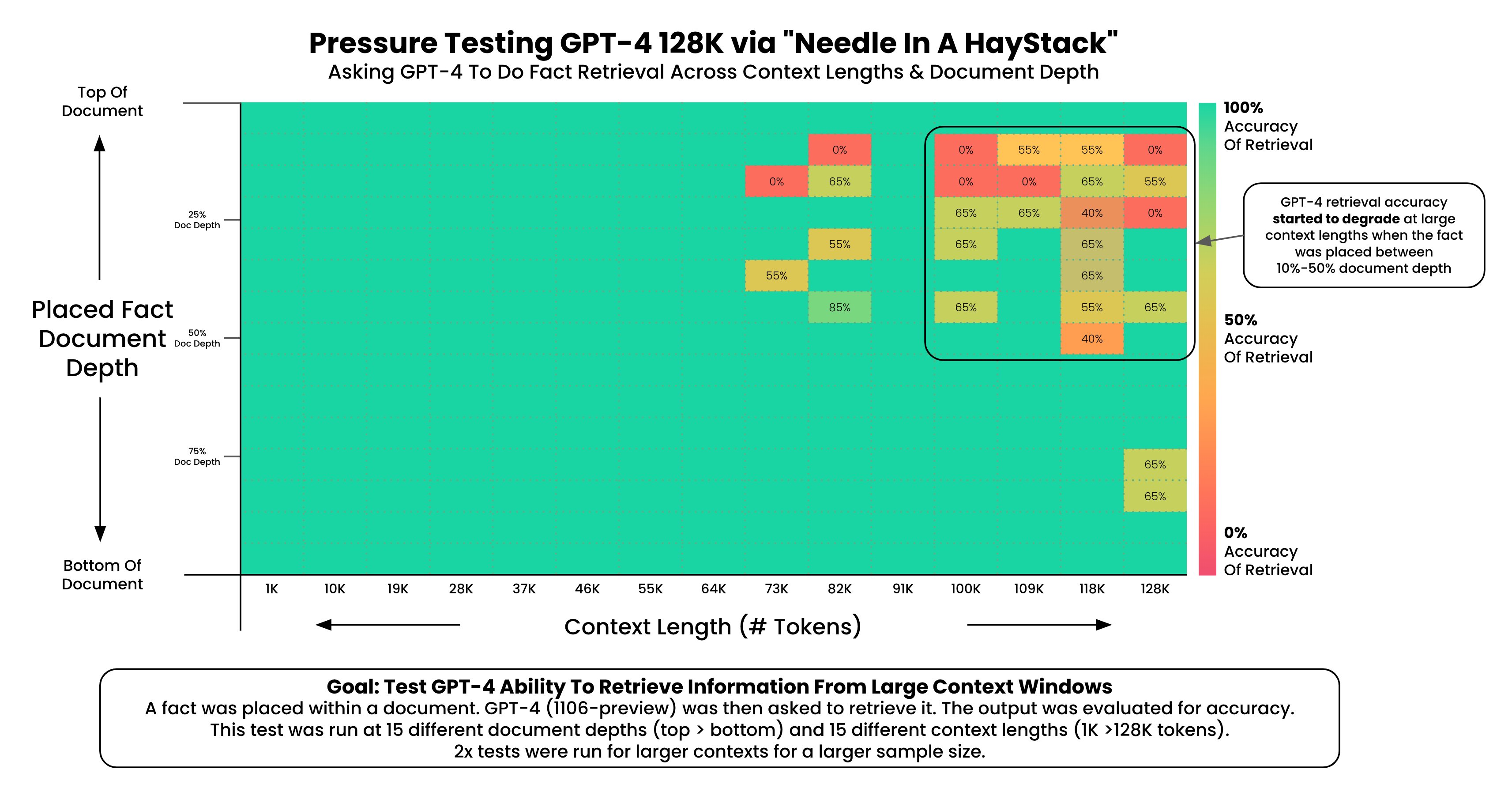
GPT-4-Turbo的128K长度上下文性能如何?超过73K Tokens的数据支持依然不太好!
本文原文来自DataLearnerAI官方网站:GPT-4-Turbo的128K长度上下文性能如何?超过73K Tokens的数据支持依然不太好! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051699526438975 GPT-4 Turbo是OpenAI最新发布的号称…...
osg之黑夜背景地月系显示
目录 效果 代码 效果 代码 /** * Lights test. This application is for testing the LightSource support in osgEarth. * 灯光测试。此应用程序用于测试osgEarth中的光源支持。 */ #include "stdafx.h" #include <osgViewer/Viewer> #include <osgEarth/N…...

持续交付-Jenkinsfile 语法
实现 Pipeline 功能的脚本语言叫做 Jenkinsfile,由 Groovy 语言实现。Jenkinsfile 一般是放在项目根目录,随项目一起受源代码管理软件控制,无需像创建"自由风格"项目一样,每次可能需要拷贝很多设置到新项目,…...
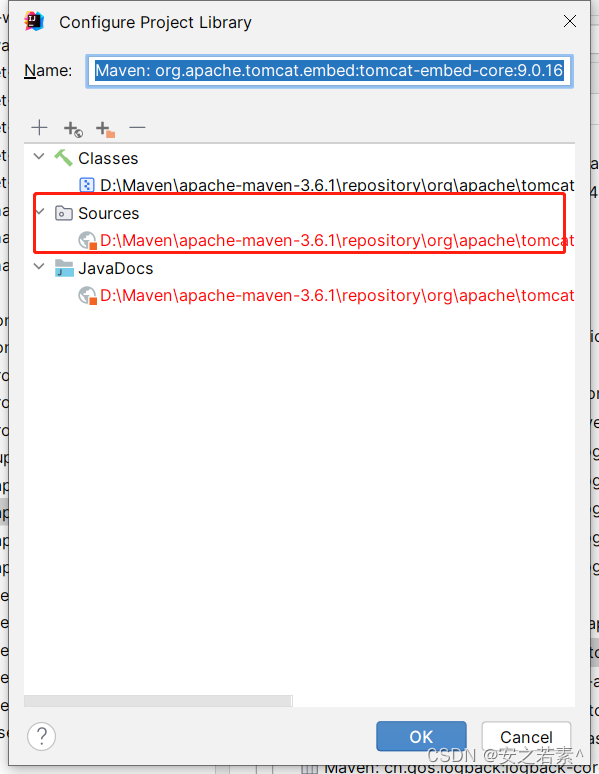
IDEA重新choose source
大概现状是这样:之前有个工程,依赖了别的模块基础包,但当时并没有依赖包的源码工程,因此,通过鼠标左键点进去,看到的是jar包里的class文件,注释什么的都去掉了的,不好看。后面有这个…...
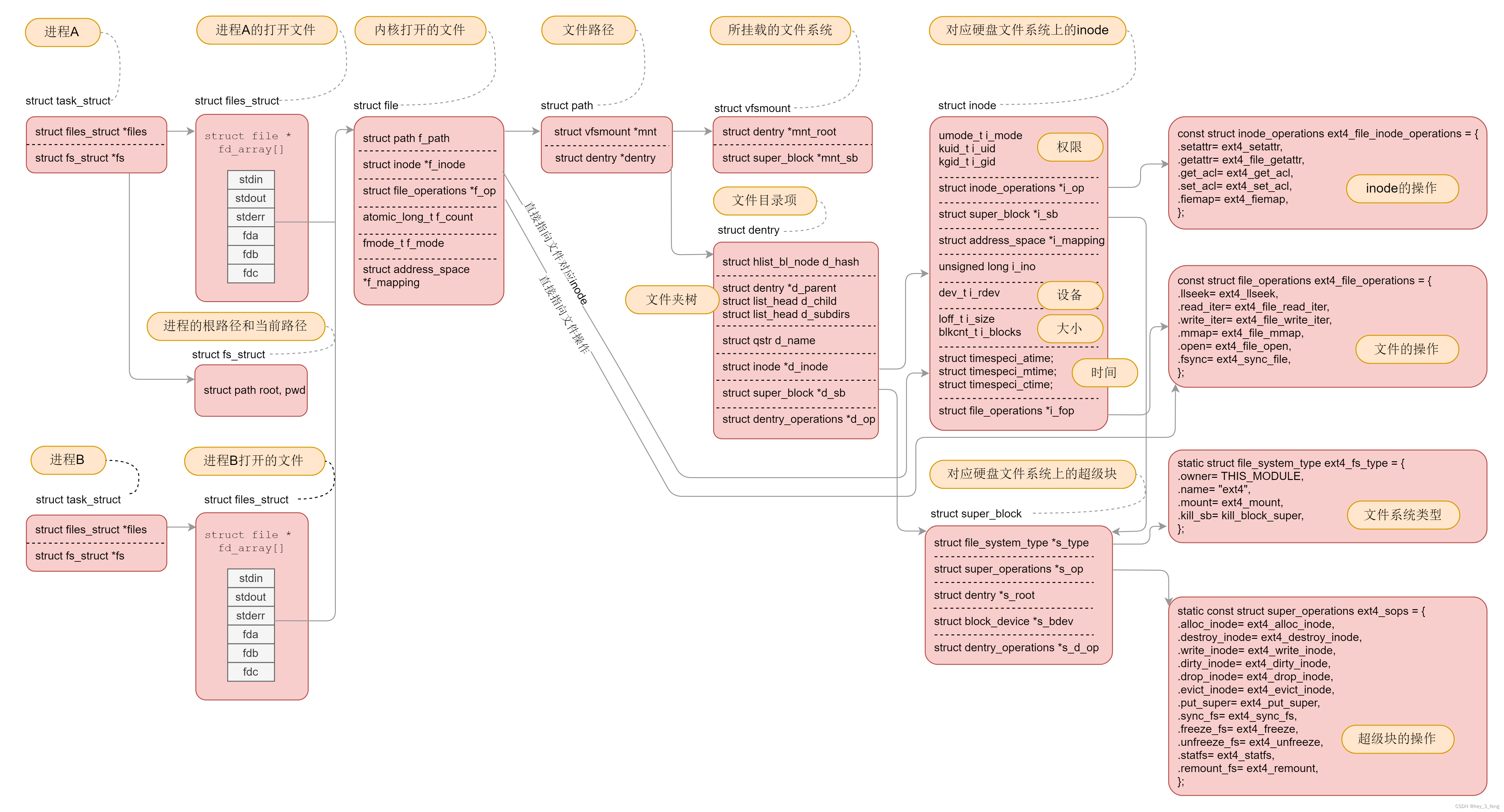
解析虚拟文件系统的调用
Linux 可以支持多达数十种不同的文件系统。它们的实现各不相同,因此 Linux 内核向用户空间提供了虚拟文件系统这个统一的接口,来对文件系统进行操作。它提供了常见的文件系统对象模型,例如 inode、directory entry、mount 等,以及…...

多项式逻辑回归原理与Python实践指南
1. 多项式逻辑回归概述逻辑回归是机器学习中最基础也最常用的分类算法之一。标准的逻辑回归(二项逻辑回归)适用于二分类问题,通过Sigmoid函数将线性回归的输出映射到(0,1)区间,表示样本属于正类的概率。但在实际应用中,…...

WinUtil终极指南:5分钟掌握Windows系统优化与批量安装工具
WinUtil终极指南:5分钟掌握Windows系统优化与批量安装工具 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 还在为Windows系统卡顿…...

【无人机三维路径规划】基于动物迁徙算法AMO实现复杂地形无人机避障三维航迹规划附Matlab代码
🔥 内容介绍摘要无人机三维路径规划在复杂地形环境中面临着避障和全局最优解搜索的双重挑战。本文提出了一种基于动物迁徙算法(AMO)的无人机三维避障路径规划方法。该方法利用AMO算法的全局搜索能力和局部寻优能力,有效地解决了复…...

OpenPLC Editor:免费开源的工业自动化编程终极指南 [特殊字符]
OpenPLC Editor:免费开源的工业自动化编程终极指南 🚀 【免费下载链接】OpenPLC_Editor 项目地址: https://gitcode.com/gh_mirrors/ope/OpenPLC_Editor 你是否曾为高昂的PLC编程软件授权费用而烦恼?是否想寻找一款功能强大、完全免费…...

Kohya_SS稳定扩散训练器:5个步骤掌握AI模型个性化训练
Kohya_SS稳定扩散训练器:5个步骤掌握AI模型个性化训练 【免费下载链接】kohya_ss 项目地址: https://gitcode.com/GitHub_Trending/ko/kohya_ss Kohya_SS是一款功能强大的稳定扩散模型训练工具,专为AI艺术创作者和开发者设计,提供了从…...

Mermaid Live Editor终极指南:免费在线图表编辑器快速上手教程
Mermaid Live Editor终极指南:免费在线图表编辑器快速上手教程 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-liv…...

慧科讯业:2026年北京车展前瞻报告
行业背景政策:汽车政策从补贴转向内需 技术双轮驱动,L3 自动驾驶准入标准 2026 年落地,新能源车购置税减半至 2027 年。消费:购车群体年轻化,26-35 岁占比 42.3%,智能化成核心标配,决策更理性。…...

告别本地跑不动:用AutoDL廉价GPU服务器训练YOLOv8模型的完整开销与效率对比
告别本地跑不动:用AutoDL廉价GPU服务器训练YOLOv8模型的完整开销与效率对比 作为一名长期在本地GTX 1060显卡上挣扎的计算机视觉开发者,每次看到YOLOv8论文中那些令人心动的性能指标时,总会被现实中的显存不足警告和漫长的训练时间打回原形。…...

MAA明日方舟助手:基于图像识别技术的游戏自动化解决方案
MAA明日方舟助手:基于图像识别技术的游戏自动化解决方案 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://g…...

MemOS:基于持久化内存的瞬时启动操作系统架构探索
1. 项目概述:当内存成为操作系统最近在社区里看到一个挺有意思的项目,叫 MemTensor/MemOS。光看名字,你可能会有点懵,这到底是啥?是内存数据库?还是某种新的内存管理框架?其实,它比这…...