深度学习(生成式模型)——Classifier Free Guidance Diffusion
文章目录
- 前言
- 推导流程
- 训练流程
- 测试流程
前言
在上一节中,我们总结了Classifier Guidance Diffusion,其有两个弊端,一是需要额外训练一个分类头,引入了额外的训练开销。二是要噪声图像通常难以分类,分类头通常难以学习,影响生成图像的质量。
Classifier Free Guidance Diffusion解决了上述两个弊端,不需要引入额外的分类头即可控制图像的生成。
本节所有符号含义与前文一致,请读者阅读完前三篇博文后在查阅此文。
本文仅总结backbone为DDIM情况下的Classifier Free Guidance Diffusion
推导流程
依据前文可知Classifier Guidance Diffusion的前向过程与反向过程与DDPM一致,且有
q ( x t ∣ x t − 1 , y ) = q ( x t ∣ x t − 1 ) q(x_t|x_{t-1},y)=q(x_t|x_{t-1}) q(xt∣xt−1,y)=q(xt∣xt−1)
则有 q ( x t ∣ x 0 , y ) = q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(x_t|x_{0},y)=q(x_t|x_0)=\mathcal N(x_t;\sqrt{\bar \alpha_t}x_0,(1-\bar\alpha_t)\mathcal I) q(xt∣x0,y)=q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
假设目前有一批基于条件 y y y的样本 x t x_t xt, ϵ ( x t , t , y ) \epsilon(x_t,t,y) ϵ(xt,t,y)服从标准正态分布,则样本 x t x_t xt将满足
x t = α ˉ t x 0 + 1 − α ˉ t ϵ ( x t , t , y ) (1.0) x_t=\sqrt{\bar \alpha_t}x_0+\sqrt{1-\bar\alpha_t}\epsilon(x_t,t,y)\tag{1.0} xt=αˉtx0+1−αˉtϵ(xt,t,y)(1.0)
依据Tweedie方法,我们有
α ˉ t x 0 = x t + ( 1 − α ˉ t ) ∇ x t log p ( x t ∣ y ) \begin{aligned} \sqrt{\bar \alpha_t}x_0=x_t+(1-\bar\alpha_t)\nabla_{x_t}\log p(x_t|y) \end{aligned} αˉtx0=xt+(1−αˉt)∇xtlogp(xt∣y)
进而有
x t = α ˉ t x 0 − ( 1 − α ˉ t ) ∇ x t log p ( x t ∣ y ) (1.1) x_t=\sqrt{\bar \alpha_t}x_0-(1-\bar\alpha_t)\nabla_{x_t}\log p(x_t|y)\tag{1.1} xt=αˉtx0−(1−αˉt)∇xtlogp(xt∣y)(1.1)
结合式1.0与1.1,则有
∇ x t log p ( x t ∣ y ) = − 1 1 − α ˉ t ϵ ( x t , t , y ) (1.2) \nabla_{x_t}\log p(x_t|y)=-\frac{1}{\sqrt{1-\bar\alpha_t}}\epsilon(x_t,t,y)\tag{1.2} ∇xtlogp(xt∣y)=−1−αˉt1ϵ(xt,t,y)(1.2)
依据贝叶斯公式,我们有
log p ( x t ∣ y ) = log p ( y ∣ x t ) + log p ( x t ) − log p ( y ) ∇ x t log p ( y ∣ x t ) = ∇ x t log p ( x t ∣ y ) − ∇ x t log p ( x t ) + ∇ x t log p ( y ) = ∇ x t log p ( x t ∣ y ) − ∇ x t log p ( x t ) = − 1 1 − α ˉ t ϵ ( x t , t , y ) + 1 1 − α ˉ t ϵ ( x t , t ) (1.3) \begin{aligned} \log p(x_t|y)&=\log p(y|x_t)+\log p(x_t)-\log p(y)\\ \nabla_{x_t}\log p(y|x_t)&=\nabla_{x_t}\log p(x_t|y)-\nabla_{x_t}\log p(x_t)+\nabla_{x_t}\log p(y)\\ &=\nabla_{x_t}\log p(x_t|y)-\nabla_{x_t}\log p(x_t)\\ &=-\frac{1}{\sqrt{1-\bar\alpha_t}}\epsilon(x_t,t,y)+\frac{1}{\sqrt{1-\bar\alpha_t}}\epsilon(x_t,t) \end{aligned}\tag{1.3} logp(xt∣y)∇xtlogp(y∣xt)=logp(y∣xt)+logp(xt)−logp(y)=∇xtlogp(xt∣y)−∇xtlogp(xt)+∇xtlogp(y)=∇xtlogp(xt∣y)−∇xtlogp(xt)=−1−αˉt1ϵ(xt,t,y)+1−αˉt1ϵ(xt,t)(1.3)
回顾一下backbone为DDIM的Classifier Guidance Diffusion的采样流程

将式1.3代入,且引入一个超参数 w w w,可得
ϵ ^ = ϵ θ ( x t ) − w 1 − α ˉ t ∇ x t log p ( y ∣ x t ) = ϵ θ ( x t ) − w ( ϵ θ ( x t , t ) − ϵ θ ( x t , t , y ) ) = ( 1 − w ) ϵ θ ( x t , t ) + w ϵ θ ( x t , t , y ) (1.4) \begin{aligned} \hat \epsilon &= \epsilon_\theta(x_t)-w\sqrt{1-\bar\alpha_t}\nabla_{x_t}\log p(y|x_t)\\ &=\epsilon_\theta(x_t)-w(\epsilon_\theta(x_t,t)-\epsilon_\theta(x_t,t,y))\\ &=(1-w)\epsilon_\theta(x_t,t)+w\epsilon_\theta(x_t,t,y) \end{aligned}\tag{1.4} ϵ^=ϵθ(xt)−w1−αˉt∇xtlogp(y∣xt)=ϵθ(xt)−w(ϵθ(xt,t)−ϵθ(xt,t,y))=(1−w)ϵθ(xt,t)+wϵθ(xt,t,y)(1.4)
注意到原论文的推导结果为(为了区分,超参数设为 w ^ \hat w w^)
ϵ ^ = ( 1 + w ^ ) ϵ θ ( x t , t , y ) − w ^ ϵ θ ( x t , t ) (1.5) \hat \epsilon = (1+\hat w)\epsilon_\theta(x_t,t,y)-\hat w\epsilon_\theta(x_t,t)\tag{1.5} ϵ^=(1+w^)ϵθ(xt,t,y)−w^ϵθ(xt,t)(1.5)
式1.5和1.4是一致的,均为 ϵ θ ( x t , t , y ) \epsilon_\theta(x_t,t,y) ϵθ(xt,t,y)与 ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵθ(xt,t)的加权和,且权重和为1。
训练流程
依据式1.5,我们需要训练两个神经网络 ϵ θ ( x t , t , y ) \epsilon_\theta(x_t,t,y) ϵθ(xt,t,y)与 ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵθ(xt,t),前者为的输入包含加噪图片 x t x_t xt以及条件 y y y(图像or文字),后者的输入仅包含加噪图像 x t x_t xt。但其实两个神经网络可以共用一个backbone,在训练时,只需要用一定的概率将条件 y y y设置为空即可。
测试流程
Classifier Free Guidance Diffusion的测试流程有两次推断
- 将条件 y y y空置,得到 ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵθ(xt,t)
- 输入条件 y y y,得到 ϵ θ ( x t , t , y ) \epsilon_\theta(x_t,t,y) ϵθ(xt,t,y)
- 利用公式1.5,生成基于条件 y y y的图像
可以看到推断成本多了一倍。
相关文章:
深度学习(生成式模型)——Classifier Free Guidance Diffusion
文章目录 前言推导流程训练流程测试流程 前言 在上一节中,我们总结了Classifier Guidance Diffusion,其有两个弊端,一是需要额外训练一个分类头,引入了额外的训练开销。二是要噪声图像通常难以分类,分类头通常难以学习…...
C语言 每日一题 11.9 day15
数组元素循环右移问题 一个数组A中存有N( > 0)个整数,在不允许使用另外数组的前提下,将每个整数循环向右移M(≥0)个位置,即将A中的数据由(A0A1⋯AN−1)变换为&…...
STM32F103C8T6第三天:pwm、sg90、超声波、距离感应按键开盖震动开盖蜂鸣器
1. 定时器介绍1(317.21) 软件定时(之前的定时方法)(软件延时)缺点:不精确、占用CPU资源 void Delay500ms() //11.0592MHz {unsigned char i, j, k;_nop_();i 4;j 129;k 119;do{do{while (-…...
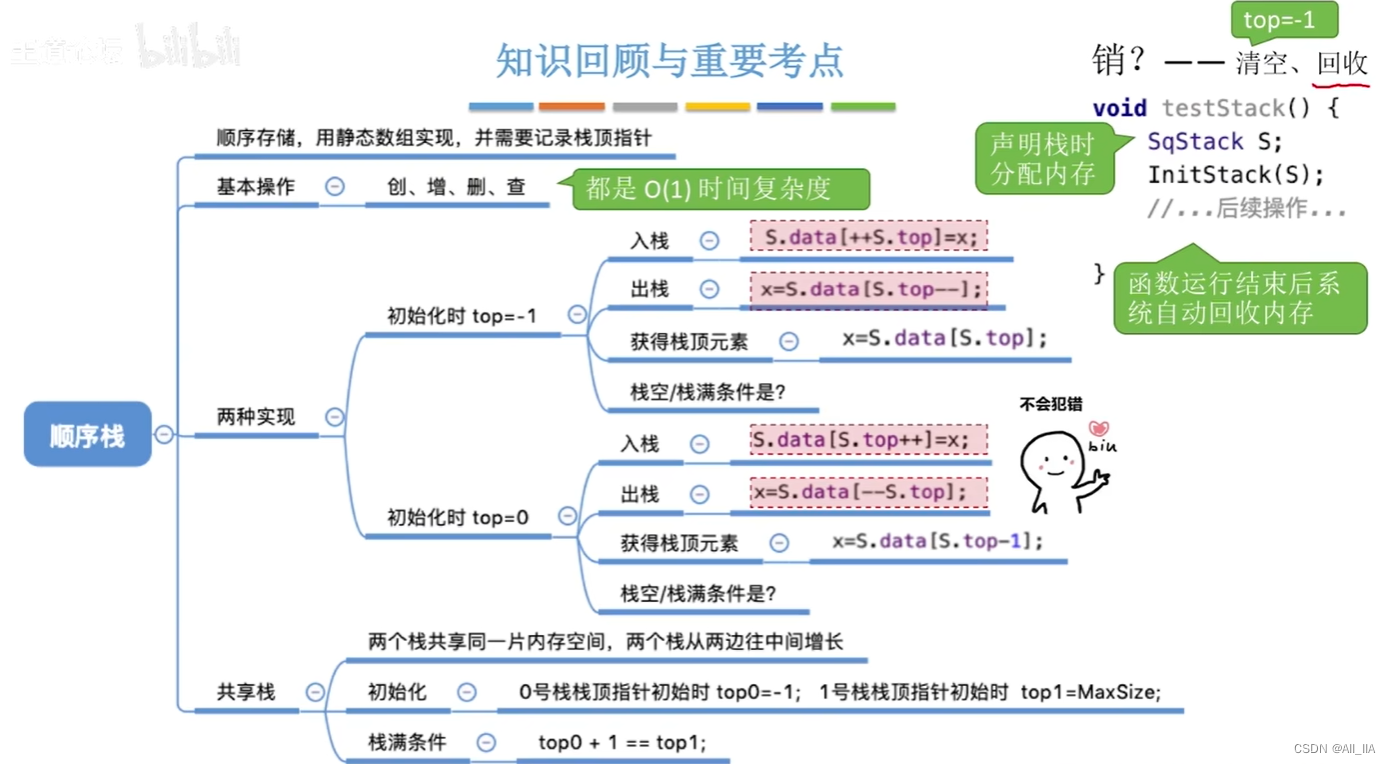
栈的顺序存储实现(C语言)(数据结构与算法)
栈的顺序存储实现通常使用数组来完成。实现方法包括定义一个固定大小的数组,以及一个指向栈顶的指针。当元素入栈时,指针加一并将元素存储在相应位置;当元素出栈时,指针减一并返回相应位置的元素。 1. 顺序栈定义 #define MaxSi…...

设计模式 -- 观察者模式
说明 author blog.jellyfishmix.com / JellyfishMIX - githubLICENSE GPL-2.0 定义 观察者模式(Observer Design Pattern) 也被称为发布订阅模式(Publish-Subscribe Design Pattern)。在 GoF 的《设计模式》一书中,它的定义是这样的: Define a one-to-many depe…...

Go RabbitMQ简介 使用
RabbitMQ简介 RabbitMQ 是一个广泛使用的开源消息队列系统,它实现了高级消息队列协议(AMQP)标准,为分布式应用程序提供了强大的消息传递功能。RabbitMQ 是 Erlang 语言编写的,具有高度的可扩展性和可靠性,…...

【面经】Spring框架中用了哪些设计模式
在Spring框架中,主要运用了以下几种设计模式: 工厂模式: Spring beanFactory使用工厂模式在应用程序中管理对象的创建。 通过使用工厂模式,Spring可以将对象的创建与使用分离,降低耦合度。 单例模式: Spr…...
SpringBoot自动配置的原理篇,剖析自动配置原理;实现自定义启动类!附有代码及截图详细讲解
SpringBoot 自动配置 Condition Condition 是在Spring 4.0 增加的条件判断功能,通过这个可以功能可以实现选择性的创建 Bean 操作 思考:SpringBoot是如何知道要创建哪个Bean的?比如SpringBoot是如何知道要创建RedisTemplate的?…...

苹果Ios系统app应用程序开发者如何获取IPA文件签名证书时需要注意什么?
今天呢想和大家介绍介绍苹果App开发者如何获取IPA文件签名证书的步骤和注意事项。对于苹果应用程序开发者而言,获取IPA文件签名证书是发布应用程序至App Store的重要步骤之一。签名证书能够确保应用程序的安全性和可信度,并使其能够在设备上正确运行。 …...
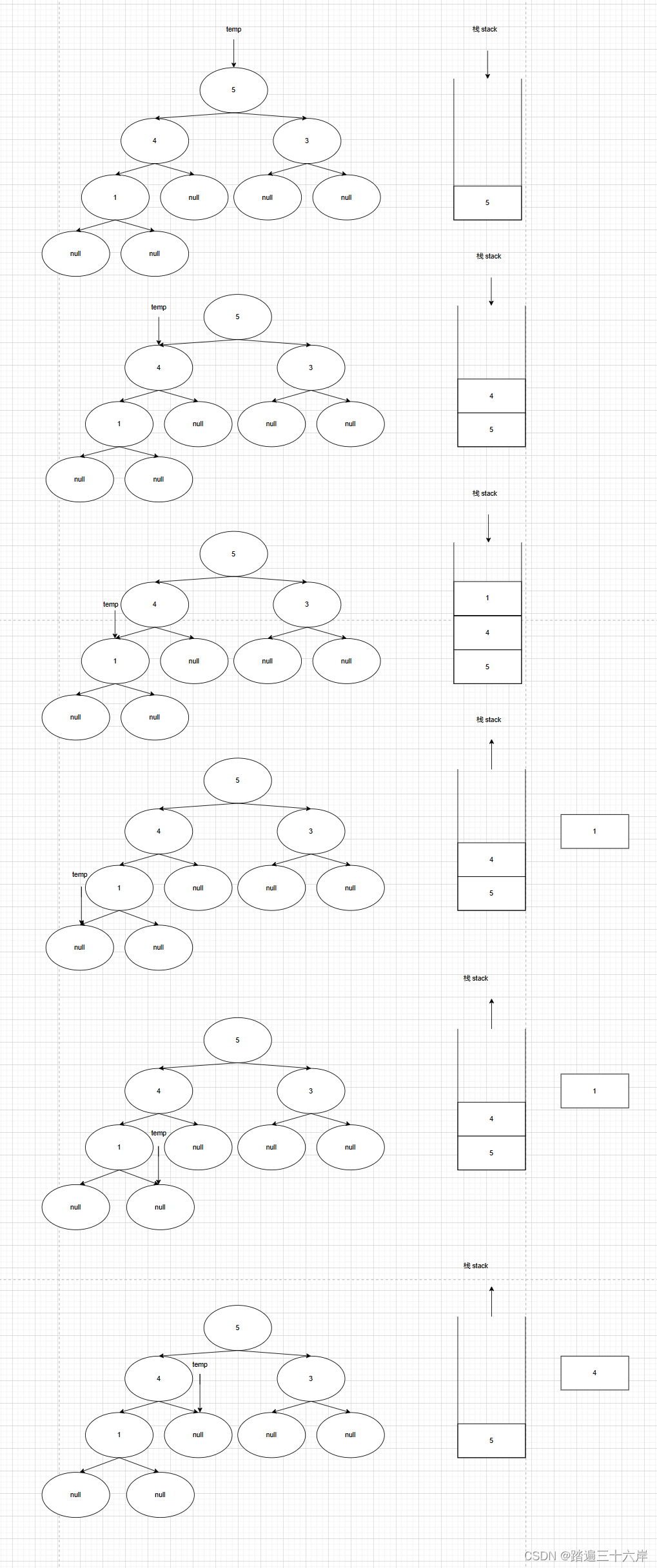
算法通关村第七关-黄金挑战二叉树迭代遍历
大家好我是苏麟 , 今天带来二叉树的迭代遍历 . 二叉树的迭代遍历 前序编列 描述 : 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 题目 : LeetCode 二叉树的前序遍历 : 144. 二叉树的前序遍历 分析 : 前序遍历是中左右,如果还有左子树就一…...
2023-11-Rust
学习方案:Rust程序设计指南 1、变量和可变性 声明变量:let 变量、const 常量 rust 默认变量一旦声明,就不可变(immutable)。当想改变 加 mut(mutable) 。 const 不允许用mut ,只能声明常量,…...

iOS代码混淆----自动
先大致解释一下“编译"、"反编译": 编译:就是把千千万万行字符串(也叫代码,或者源文件),变成010101010101(机器码,也叫目标代码) 编译过程:预处理-编译-汇编-链接 我的脚本运行在预处理阶段。 反编…...
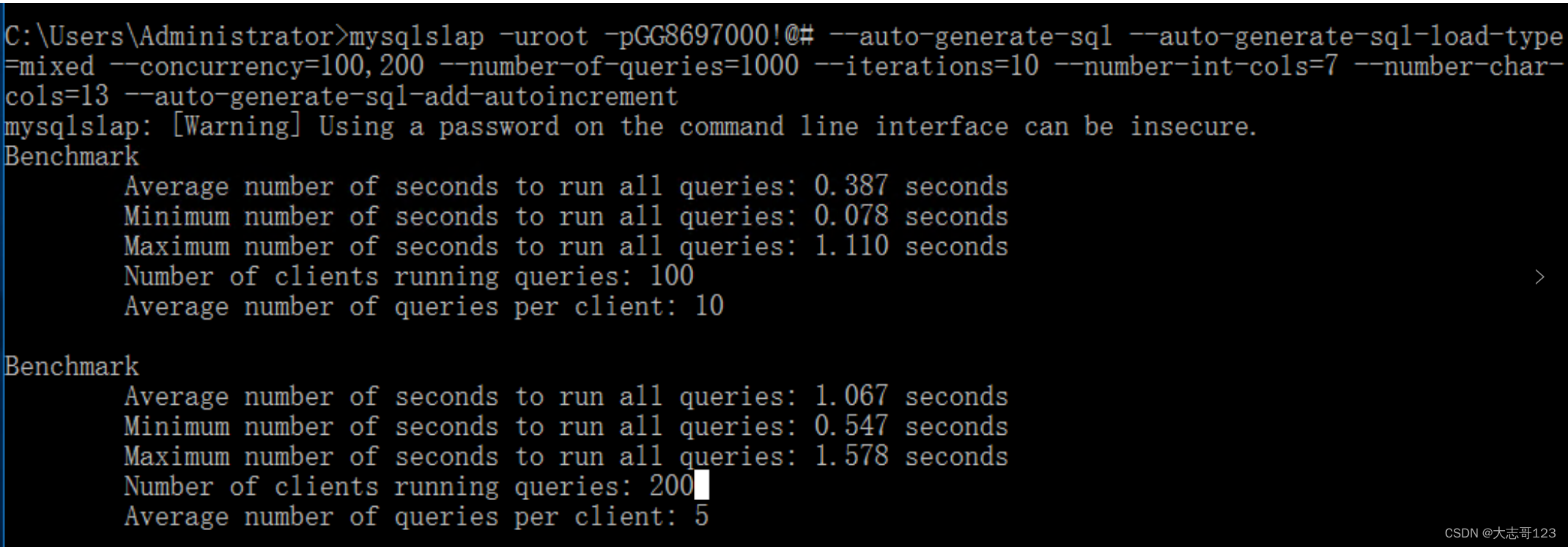
对Mysql和应用微服务做TPS压力测试
1.对Mysql 使用工具:mysqlslap工具 使用命令: mysqlslap -uroot pGG8697000!#--auto generate sql -auto generate sql-load typemixed-concurrency100,200 - number of queries1000-iterations10 - number-int-cols7 - number-charcols13auto genera…...
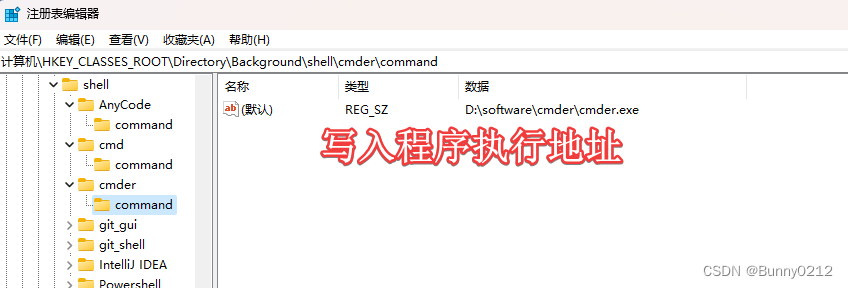
将程序添加至右键菜单
将程序添加至右键菜单 手动导入 如果要将cmder添加至右键菜单。可以通过编写reg注册表方式添加 也可以在路径HKEY_CLASSES_ROOT\Directory\Background\shell中右击添加 创建项commadn 编写reg注册表 [HKEY_CLASSES_ROOT\Directory\Background\shell\cmder]为注册表地址 Wi…...

三板斧的使用、全局配置文件、静态文件的配置、orm介绍
三板斧的使用 【1】HttpResponse 返回字符串类型 【2】render 返回html页面,并且在返回给浏览器之前还可以给html页面传值 【3】redirect 重定向页面 视图函数必须返回一个 HttpResponse 对象 def index(request):print(request)# return HttpResponse("r…...
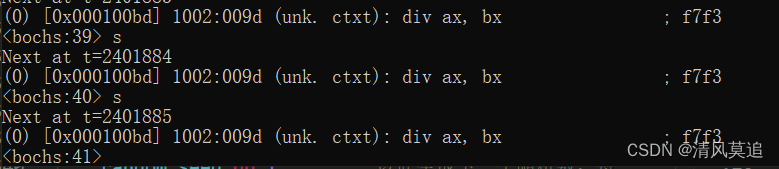
【编程实践】黑框框里的打字小游戏,但是汇编语言
开始: 在学习王爽的《汇编语言》的过程中,我就真切地体会到编程实践对于理解的帮助。起初我没有安装书中的实验环境,看到100页左右就开始感觉无趣、吃力,看了后面忘前面,差点就要放弃这本书的学习。好在我后来还是装好…...
ElasticSearch的集群、节点、索引、分片和副本
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将Elasticsearch里存储文档数据和关系型数据库MySQL存储数据的概念进行一个类比 ES里的Index可以看做一个库,而Types相当于表,Documents则相当…...

std::cout无法打印uint8_t类型的数据
std::cout在处理uint8_t变量类型的时候默认输出字符,刚好数字0-10对应的ascii字符都是不可打印的 解决: 使用static_cast std::cout << static_cast<int>(time) << std::endl;参考文章:https://blog.csdn.net/weixin_459…...
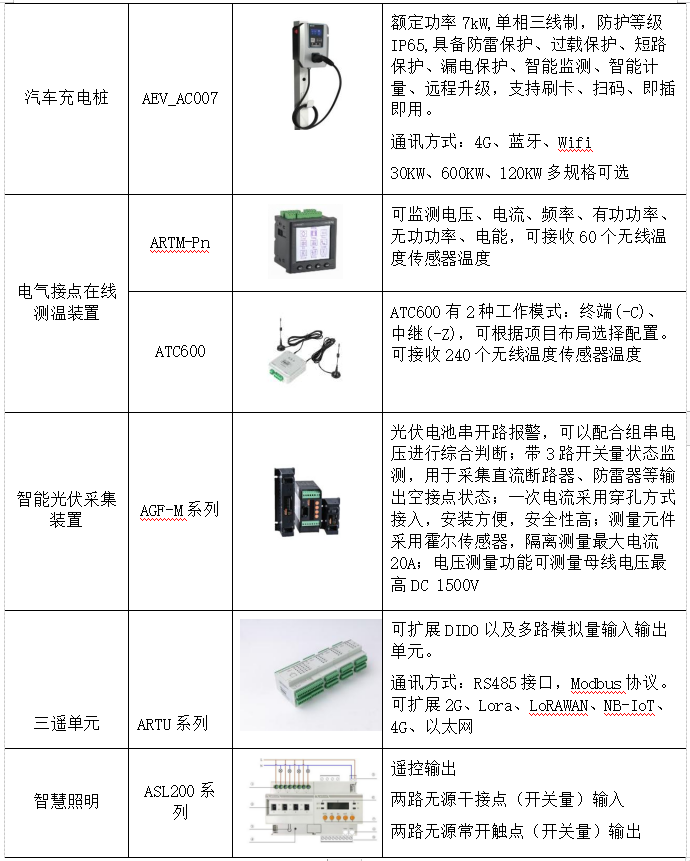
浅谈泛在电力物联网在智能配电系统应用
贾丽丽 安科瑞电气股份有限公司 上海嘉定 201801 摘要:在社会经济和科学技术不断发展中,配电网实现了角色转变,传统的单向供电服务形式已经被双向能流服务形式取代,社会多样化的用电需求也得以有效满足。随着物联网技术的发展&am…...

已解决:云原生领域的超时挂载Bug — Kubernetes深度剖析
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

Excel打开密码怎么取消?两种方法教你快速移除工作簿密码
为了确保重要数据的安全,我们经常会为Excel文件设置打开密码。但当文件需要分享给同事,或者自己觉得每次输入密码太麻烦时,又该如何取消这个密码呢?本文将详细介绍两种简单有效的取消Excel打开密码的方法,并解答一个常…...

终极macOS窗口置顶工具:Topit完整指南,让你的多任务效率提升300%
终极macOS窗口置顶工具:Topit完整指南,让你的多任务效率提升300% 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否经常在Mac上工作…...

3分钟搞定ESP8266固件烧录:NodeMCU PyFlasher终极指南
3分钟搞定ESP8266固件烧录:NodeMCU PyFlasher终极指南 【免费下载链接】nodemcu-pyflasher Self-contained NodeMCU flasher with GUI based on esptool.py and wxPython. 项目地址: https://gitcode.com/gh_mirrors/no/nodemcu-pyflasher 还在为ESP8266固件…...

AI短剧制作工具源码部署教程,从环境搭建到SAAS多开
温馨提示:文末有资源获取方式随着AI生成技术的快速迭代,短剧创作的门槛正在急剧下降。最近有不少朋友咨询如何搭建一套属于自己的AI短剧创作平台,今天就简单记录一下从环境准备到SAAS多开的完整过程。源码获取方式在源码闪购网。一、环境准备…...

Python常用函数及常用库整理笔记
文件操作文件夹/目录import os1、os.path.exists(path) 判断一个文件/目录是否存在,只要存在相匹配的文件或目录就返回True,因此当目录与文件同名时可能报错2、os.path.isdir(fname) 判断目录是否存在,必须是目录才返回True3、os.makedirs(pa…...

别再傻傻分不清了!Python数据生成三剑客:linspace、arange、range到底怎么选?
Python数据生成三剑客:linspace、arange、range的黄金选择法则 第一次接触Python科学计算时,我也曾被这三个函数搞得晕头转向——明明看起来都能生成数字序列,为什么要有三个?直到在真实项目中踩过几次坑,才明白它们的…...

终极指南:掌握pyenv-virtualenv与Pyenv无缝集成的10个技巧
终极指南:掌握pyenv-virtualenv与Pyenv无缝集成的10个技巧 【免费下载链接】pyenv-virtualenv a pyenv plugin to manage virtualenv (a.k.a. python-virtualenv) 项目地址: https://gitcode.com/gh_mirrors/py/pyenv-virtualenv pyenv-virtualenv是一个Pyen…...
输出)

2.6万亿天量成交却跌破4100点!A股这波“性能调优”,咱们程序员该怎么看懂?
大家好,我是Kyle,今天收盘估计不少持仓的兄弟跟我一样,看着K线的波动,心跳频率都跟着大盘震荡走了——这行情,简直比线上服务高峰期的QPS波动还刺激。先给大家上最新的“生产环境数据”:今天两市成交量干到…...

Halcon 3D视觉标定避坑指南:从点云模型创建到`calibrate_hand_eye`,我踩过的雷你别再踩
Halcon 3D视觉标定避坑指南:从点云模型创建到calibrate_hand_eye实战解析 在工业自动化领域,3D视觉引导的机器人作业已成为智能制造的核心技术之一。Halcon作为机器视觉领域的标杆软件,其3D手眼标定功能(eye-to-hand)被…...