进行 “最佳价格查询器” 的开发
前置条件
public class Shop {private final String name;private final Random random;public Shop(String name) {this.name = name;random = new Random(name.charAt(0) * name.charAt(1) * name.charAt(2));}public double getPrice(String product) {return calculatePrice(product);}private double calculatePrice(String product) {try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}return random.nextDouble() * product.charAt(0) + product.charAt(1);}
}
采用顺序查询所有商店的方式
// 采用顺序查询所有商店的方式
public List<String> findPricesSequential(String product) {return shops.stream().map(shop -> Thread.currentThread().getName() + shop.getName() + "-" + shop.getPrice(product)).collect(Collectors.toList());
}
使用并行流对请求进行并行操作
// 使用并行流对请求进行并行操作
public List<String> findPricesParallel(String product) {return shops.parallelStream().map(shop -> Thread.currentThread().getName() + shop.getName() + "-" + shop.getPrice(product)).collect(Collectors.toList());
}
使用CompletableFuture发起异步请求(使用内部通用线程池)
// 使用CompletableFuture发起异步请求
public List<String> findPricesFuture(String product) {List<CompletableFuture<String>> priceFutures =shops.stream().map(shop -> CompletableFuture.supplyAsync(() -> Thread.currentThread().getName() + shop.getName() + "-" + shop.getPrice(product)))// 内部采用的通用线程池,默认都使用固定数目的线程,具体线程数取决于Runtime.getRuntime().availableProcessors()的返回值。.collect(Collectors.toList());List<String> prices = priceFutures.stream().map(CompletableFuture::join) // 对List中的所有future对象执行join操作,一个接一个地等待它们运行结束.collect(Collectors.toList());return prices;
}
使用CompletableFuture发起异步请求(使用定制的执行器)
CompletableFuture类中的join方法和Future接口中的get有相同的含义,并且也声明在Future接口中,它们唯一的不同是join不会抛出任何检测到的异常。
private final Executor executor = Executors.newFixedThreadPool(shops.size(), ExecuterThreadFactoryBuilder.build("searcher-thread-%d"));// 使用CompletableFuture发起异步请求+使用定制的执行器
public List<String> findPricesFutureCustom(String product) {List<CompletableFuture<String>> priceFutures =shops.stream().map(shop -> CompletableFuture.supplyAsync(() -> Thread.currentThread().getName() + shop.getName() + "-" + shop.getPrice(product), executor)).collect(Collectors.toList());List<String> prices = priceFutures.stream().map(CompletableFuture::join).collect(Collectors.toList());return prices;
}
性能比较
笔者电脑是16线程,所以构造测试数据时16个线程任务是个门槛
private List<Shop> shops = new ArrayList<>();
{for (int i = 0; i < 64; i++) {shops.add(new Shop("LetsSaveBig3" + i));}System.out.println(shops.size());
}StopWatch stopWatch = new StopWatch("性能比较");
execute("sequential", () -> bestPriceFinder.findPricesSequential("myPhone27S"), stopWatch);
execute("parallelStream", () -> bestPriceFinder.findPricesParallel("myPhone27S"), stopWatch);
execute("CompletableFuture", () -> bestPriceFinder.findPricesFuture("myPhone27S"), stopWatch);
execute("CompletableFutureExecuter", () -> bestPriceFinder.findPricesFutureCustom("myPhone27S"), stopWatch);
StopWatchUtils.logStopWatch(stopWatch);private static void execute(String msg, Supplier<List<String>> s, StopWatch stopWatch) {stopWatch.start(msg);System.out.println(s.get());stopWatch.stop();
}
| availableProcessors() = 16 | 4线程任务 | 8线程任务 | 16线程任务 | 20线程任务 | 24线程任务 | 28线程任务 | 32线程任务 | 64线程任务 |
|---|---|---|---|---|---|---|---|---|
| Sequential | 4035 ms | 8057 ms | 16108 ms | 20154 ms | 24131 ms | 28106 ms | 32196 ms | 64325 ms |
| parallelStream | 1005 ms | 1021 ms | 1022 ms | 2022 ms | 2013 ms | 2008 ms | 2012 ms | 4017 ms |
| CompletableFuture | 1008 ms | 1019 ms | 2022 ms | 2027 ms | 2016 ms | 2006 ms | 3017 ms | 5043 ms |
| CompletableFutureExecuter | 1012 ms | 1007 ms | 1019 ms | 1023 ms | 1019 | 1012 ms | 1020 ms | 1025 ms |
线程池如何选择合适的线程数目
线程池中线程的数目取决于你预计你的应用需要处理的负荷,但是你该如何选择合适的线程数目呢?
如果线程池中线程的数量过多,最终它们会竞争稀缺的处理器和内存资源,浪费大量的时间在上下文切换上。
如果线程的数目过少,处理器的一些核可能就无法充分利用。
《Java并发编程实战》作者 Brian Goetz 建议,线程池大小与处理器的利用率之比可以使用下面的公式进行估算:
N(threads) = N(CPU) * U(CPU) * (1 + W/C)
其中:
·N(CPU)是处理器的核的数目,可以通过Runtime.getRuntime().availableProcessors()得到
·U(CPU)是期望的CPU利用率(该值应该介于0和1之间)
·W/C是等待时间与计算时间的比率
公式理解:
C / (C+W) = N(CPU) * U(CPU) / N(threads) → 计算时间占比 = 有效CPU在线程数中的占比
线程极限阈值数计算
你的应用99%的时间都在等待商店的响应,所以估算出的W/C比率为100。且CPU利用率是100%,则根据公式极限阈值为16*1*100=1600 ,即创建一个拥有1600个线程的线程池。
你的应用99%的时间都在等待商店的响应,所以估算出的W/C比率为100。这意味着如果你期望的CPU利用率是100%,你需要创建一个拥有1600个线程的线程池。实际操作中,如果你创建的线程数比商店的数目更多,反而是一种浪费,因为这样做之后,你线程池中的有些线程根本没有机会被使用。出于这种考虑,我们建议你将执行器使用的线程数,与你需要查询的商店数目设定为同一个值,这样每个商店都应该对应一个服务线程。不过,为了避免发生由于商店的数目过多导致服务器超负荷而崩溃,你还是需要设置一个上限,比如100个线程。代码清单如下所示。
private final Executor executor = Executors.newFixedThreadPool(Math.min(shops.size(), 100), ExecuterThreadFactoryBuilder.build("searcher-thread-%d"));public List<String> findPricesFutureCustom(String product) {List<CompletableFuture<String>> priceFutures =shops.stream().map(shop -> CompletableFuture.supplyAsync(() -> Thread.currentThread().getName() + "-" + shop.getName() + "-" + shop.getPrice(product), executor)).collect(Collectors.toList());List<String> prices = priceFutures.stream().map(CompletableFuture::join).collect(Collectors.toList());return prices;
}
| Processors=16 | 4线程任务(ms) | 8 | 16 | 20 | 24 | 28 | 32 | 64 | 100 | 500 | 1000 | 1600 | 3200 | 4000 | 8000 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sequential | 4035 | 8057 | 16108 | 20154 | 24131 | 28106 | 32196 | 64325 | |||||||
| parallelStream | 1005 | 1021 | 1022 | 2022 | 2013 | 2008 | 2012 | 4017 | 7110 | 32240 | |||||
| CompletableFuture | 1008 | 1019 | 2022 | 2027 | 2016 | 2006 | 3017 | 5043 | 7058 | 34177 | |||||
| newFixedThreadPool shops.size() | 1012 | 1007 | 1019 | 1023 | 1019 | 1012 | 1020 | 1025 | 1029 | 1081 | 1365 | 1330 | 2407 | 1662 | 3129 |
| newFixedThreadPool min(shops.size(),100) | 1093 | 1043 | 5116 | 10192 | 32434 | 80658 |
public static ThreadFactory build(String nameFormat) {return new ThreadFactoryBuilder().setDaemon(true).setNameFormat(nameFormat).build();
}
注意,当前创建的是一个由守护线程构成的线程池。Java程序无法终止或者退出一个正在运行中的线程,所以最后剩下的那个线程会由于一直等待无法发生的事件而引发问题。如果将线程标记为守护进程,意味着程序退出时它也会被回收。这二者之间没有性能上的差异。
综上比较可知,CompletableFuture + Executer方式最高效。一般而言,这种状态会一直持续,直到商店的数目达到我们之前计算的 阈值 1600。这个例子证明了要创建更适合你的应用特性的执行器,利用CompletableFutures向其提交任务执行是个不错的主意。处理需大量使用异步操作的情况时,这几乎是最有效的策略。
并行——使用流还是CompletableFutures?
目前为止,你已经知道对集合进行并行计算有两种方式:要么将其转化为并行流,利用map这样的操作开展工作,要么枚举出集合中的每一个元素,创建新的线程,在CompletableFuture内对其进行操作。后者提供了更多的灵活性,你可以调整线程池的大小,而这能帮助你确保整体的计算不会因为线程都在等待I/O而发生阻塞。
我们对使用这些API的建议如下。
1、如果你进行的是计算密集型的操作,并且没有I/O,那么推荐使用Stream接口,因为实现简单,同时效率也可能是最高的(如果所有的线程都是计算密集型的,那就没有必要创建比处理器核数更多的线程)。
2、如果你并行的工作单元还涉及等待I/O的操作(包括网络连接等待),那么使用CompletableFuture灵活性更好,你可以像前文讨论的那样,依据等待/计算,或者W/C的比率设定需要使用的线程数。这种情况不使用并行流的另一个原因是,处理流的流水线中如果发生I/O等待,流的延迟特性会让我们很难判断到底什么时候触发了等待。
参考
《Java8 实战》第11章 CompletableFuture:组合式异步编程
相关文章:
进行 “最佳价格查询器” 的开发
前置条件 public class Shop {private final String name;private final Random random;public Shop(String name) {this.name name;random new Random(name.charAt(0) * name.charAt(1) * name.charAt(2));}public double getPrice(String product) {return calculatePrice…...

Brain Teaser概率类 - 三局两胜制
问题 三局两胜制比赛,两局结束还是三局结束的概率大? 解答 假设每局比赛的结果是独立同分布的,且遵循伯努利分布,其中一方的胜率为p,另一方为1-p. 则两局结束的概率是 p 2 ( 1 − p ) 2 ≥ 0.5 p^2 (1-p)^2 \geq …...

在现实生活中传感器GV-H130/GV-21的使用
今天,收获了传感器GV-H130/GV-21,调试探头的用法,下面就来看看吧!如有不妥欢迎指正!!!! 目录 传感器GV-H130/GV-21外观 传感器调试探头 探头与必要准备工作 传感器数值更改调试 …...

海康Visionmaster-全局脚本:通过通讯触发快速匹配 模块换型的方法
如何实现根据通讯信号切换快速匹配的模型文件并触发流程执行? 1.动态切换模板需在全局脚本中调用相关接口实现,可以在全局脚本的通讯数据接收回调中实现代码逻辑,代码如下。 C# using System; using VM.GlobalScript.Methods; using System.…...

什么是闭包
闭包是指函数在定义时可以访问其词法作用域的能力,即使函数在定义之后被传递到了其他地方执行。它包含了两个主要的特性:函数内部可以访问外部函数作用域中的变量,而这些变量在函数执行完毕后依然保持在内存中。 具体来说,闭包的…...
)
sql6(Leetcode1387使用唯一标识码替换员工ID)
1112-2 代码: INNER JOIN 如果表中有至少一个匹配,则返回行 LEFT JOIN 即使右表中没有匹配,也从左表返回所有的行(LEFT为基准 RIGHT JOIN 即使左表中没有匹配,也从右表返回所有的行 # Write your MySQL query st…...

qt-C++笔记之Qt中的时间与定时器
qt-C笔记之Qt中的时间与定时器 code review! 文章目录 qt-C笔记之Qt中的时间与定时器一.Qt中的日期时间数据1.1.QTime:获取当前时间1.2.QDate:获取当前日期1.3.QDateTime:获取当前日期和时间1.4.QTime类详解1.5.QDate类详解1.6..QDateTime类…...

【C++】复杂的多继承及其缺陷(菱形继承)
本篇要分享的内容是C中多继承的缺陷:菱形继承。 以下为本篇目录 目录 1.多继承的缺陷与解决方法 2.虚继承的底层原理 3.虚继承底层原理的设计原因 1.多继承的缺陷与解决方法 首先观察下面的图片判断它是否为多继承 这实际上是一个单继承,单继承的特…...

esp32-rust-no_std-examples-blinky
什么是裸机环境? 裸机环境是指没有可供使用的操作系统环境。当编译的 Rust 程序拥有 no_std 属性时,该程序无权访问上述 std 章节中提到的某些特定功能。尽管仍支持使用配网或引入复杂数据结构等功能,但实现方式将会更加复杂。 no_std…...

GitHub上的开源工业软件
github上看到一个中国人做的流体力学开源介绍,太牛了! https://github.com/clatterrr/FluidSimulationTutorialsUnity 先分析一下工业仿真软件赛道 工业仿真软件的赛道和产品主要功能如下: 1. 工艺仿真赛道: - 工厂布局优化&am…...
Centos7安装配置中文输入法
Centos7安装配置中文输入法 在安装CentOS时,我们为了方便使用,语言选择了中文,但是我们发现,在Linux命令行或者是浏览器中输入时,我们只能输入英文,无法输入汉字。 来,跟随脚步,设…...

【OJ比赛日历】快周末了,不来一场比赛吗? #11.11-11.17 #12场
CompHub[1] 实时聚合多平台的数据类(Kaggle、天池…)和OJ类(Leetcode、牛客…)比赛。本账号会推送最新的比赛消息,欢迎关注! 以下信息仅供参考,以比赛官网为准 目录 2023-11-11(周六) #5场比赛2023-11-12…...

提取当前文件夹下多文件夹中的数据
提取当前文件夹下多文件夹中的数据 1.实现步骤 现在D:\临时\图库 这个文件夹下有多个文件夹,现在需要将多个文件夹中的文件全部移动到D:\临时\图库下; $sourcePath "D:\临时\图库" $targetPath "D:\临时\图库"Get-ChildItem -Path $sourcePath -File …...

深度学习(生成式模型)——Classifier Free Guidance Diffusion
文章目录 前言推导流程训练流程测试流程 前言 在上一节中,我们总结了Classifier Guidance Diffusion,其有两个弊端,一是需要额外训练一个分类头,引入了额外的训练开销。二是要噪声图像通常难以分类,分类头通常难以学习…...
C语言 每日一题 11.9 day15
数组元素循环右移问题 一个数组A中存有N( > 0)个整数,在不允许使用另外数组的前提下,将每个整数循环向右移M(≥0)个位置,即将A中的数据由(A0A1⋯AN−1)变换为&…...
STM32F103C8T6第三天:pwm、sg90、超声波、距离感应按键开盖震动开盖蜂鸣器
1. 定时器介绍1(317.21) 软件定时(之前的定时方法)(软件延时)缺点:不精确、占用CPU资源 void Delay500ms() //11.0592MHz {unsigned char i, j, k;_nop_();i 4;j 129;k 119;do{do{while (-…...
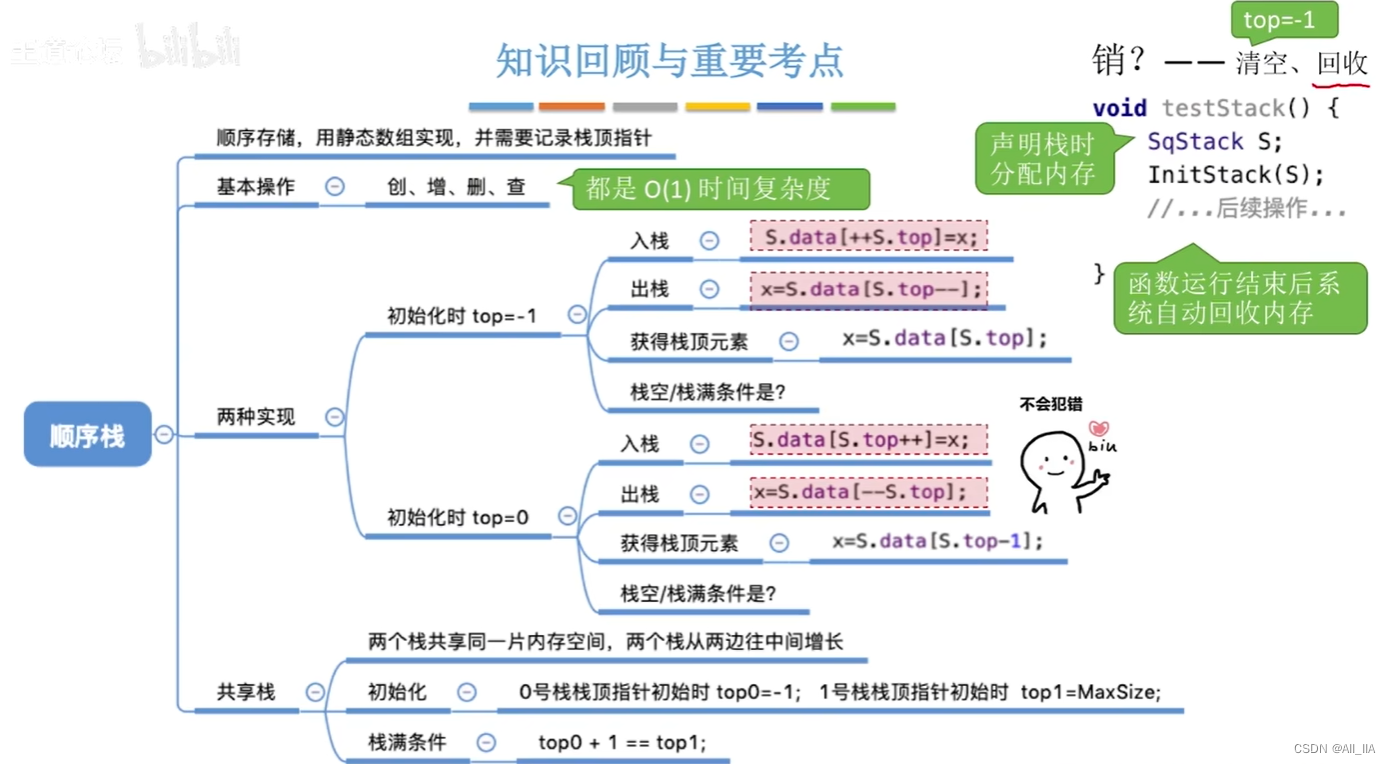
栈的顺序存储实现(C语言)(数据结构与算法)
栈的顺序存储实现通常使用数组来完成。实现方法包括定义一个固定大小的数组,以及一个指向栈顶的指针。当元素入栈时,指针加一并将元素存储在相应位置;当元素出栈时,指针减一并返回相应位置的元素。 1. 顺序栈定义 #define MaxSi…...

设计模式 -- 观察者模式
说明 author blog.jellyfishmix.com / JellyfishMIX - githubLICENSE GPL-2.0 定义 观察者模式(Observer Design Pattern) 也被称为发布订阅模式(Publish-Subscribe Design Pattern)。在 GoF 的《设计模式》一书中,它的定义是这样的: Define a one-to-many depe…...

Go RabbitMQ简介 使用
RabbitMQ简介 RabbitMQ 是一个广泛使用的开源消息队列系统,它实现了高级消息队列协议(AMQP)标准,为分布式应用程序提供了强大的消息传递功能。RabbitMQ 是 Erlang 语言编写的,具有高度的可扩展性和可靠性,…...

【面经】Spring框架中用了哪些设计模式
在Spring框架中,主要运用了以下几种设计模式: 工厂模式: Spring beanFactory使用工厂模式在应用程序中管理对象的创建。 通过使用工厂模式,Spring可以将对象的创建与使用分离,降低耦合度。 单例模式: Spr…...

第14篇:Power Query 高级数据处理
第14篇:Power Query 高级数据处理 1. Power Query 核心概念 1.1 M 语言基础 Power Query 使用 M 语言进行数据转换: // 基本语法结构 let步骤1 操作1,步骤2 操作2,结果 最终输出 in结果1.2 查询步骤链 源数据↓ 引用类型转换↓ 删除列↓ 筛选行↓ 分组…...

【VSCode工业级调试适配指南】:20年嵌入式老兵亲授5大硬核配置技巧,让JTAG/SWD调试效率提升300%
更多请点击: https://intelliparadigm.com 第一章:VSCode工业级调试适配的底层逻辑与演进路径 VSCode 的调试能力并非基于独立运行的调试器,而是通过标准化协议与外部调试后端协同工作。其核心是 Debug Adapter Protocol(DAP&…...

PyCharm专业版用户看过来:不用Anaconda,如何用内置工具创建和管理Python虚拟环境?
PyCharm专业版虚拟环境管理全指南:告别Anaconda的轻量化方案 每次启动Anaconda Navigator时那个缓慢的加载进度条,是否让你怀念PyCharm流畅的启动体验?作为PyCharm专业版用户,你可能还没意识到自己手中已经握有一把环境管理的瑞士…...

如何安全备份安卓短信和通话记录:SMS Backup+ 的完整指南
如何安全备份安卓短信和通话记录:SMS Backup 的完整指南 【免费下载链接】sms-backup-plus Backup Android SMS, MMS and call log to Gmail / Gcal / IMAP 项目地址: https://gitcode.com/gh_mirrors/sms/sms-backup-plus 您是否曾担心手机丢失或损坏时&…...

ABAP 与七伤拳
我每次在项目里看到某些 ABAP 写法,脑子里都会蹦出《倚天屠龙记》里的七伤拳。原因不神秘,这门功夫最扎人的地方,不只是威力大,而是练功和出拳的代价会先落回自己身上。公开资料里对七伤拳的描述很一致,它被概括为一门先伤己后伤人的拳法,内力不够、根基不稳时,强行修炼…...

告别复杂CSS:spin.js如何用现代工具链简化加载动画开发
告别复杂CSS:spin.js如何用现代工具链简化加载动画开发 【免费下载链接】spin.js A spinning activity indicator 项目地址: https://gitcode.com/gh_mirrors/sp/spin.js 在现代Web开发中,加载动画是提升用户体验的关键元素,但传统CSS…...

终极指南:使用GPG确保Buildah镜像完整性的完整步骤
终极指南:使用GPG确保Buildah镜像完整性的完整步骤 【免费下载链接】buildah A tool that facilitates building OCI images. 项目地址: https://gitcode.com/gh_mirrors/bu/buildah Buildah是一个轻量级工具,用于构建OCI(开放容器倡议…...

以线性代数的行列式理解数学应用备忘
线性代数 是什么?12 AI Logo DeepSeek-V3.2 04-24 02:37 线性代数是高等学校各专业学生的一门必修的基础理论课,主要阐述代数学中线性关系的经典理论。它广泛应用于科学技术的各个领域,是学生学习后继课程以及从事科学研究、工程技术与管理工…...

AgentHeroes:AI角色生成与内容自动化工作流平台全解析
1. 项目概述与核心价值最近在折腾AI内容生成的朋友,应该都遇到过类似的痛点:好不容易用Stable Diffusion或者Midjourney跑出一个满意的角色形象,想让它动起来、甚至批量生成内容发布到社交媒体,却发现每一步都卡在不同的工具和平台…...

BERT模型解析:原理、变种与实践指南
1. BERT模型基础解析BERT(Bidirectional Encoder Representations from Transformers)是2018年由Google推出的基于Transformer架构的自然语言处理模型。与传统的单向语言模型不同,BERT采用双向训练机制,使其能够同时利用上下文信息…...