Flink—— Data Source 介绍
Data Source 简介
Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来,Flink 就能够一直计算下去,这个 Data Sources 就是数据的来源地。
Flink 中你可以使用 StreamExecutionEnvironment.addSource(sourceFunction) 来为你的程序添加数据来源。
Flink 已经提供了若干实现好了的 source functions,当然你也可以通过实现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source。
Flink Data Source分类
Flink的数据源可以根据数据的来源和特性进行分类。以下是常见的Flink数据源分类:
集合数据源
集合数据源(Collection Data Source):集合数据源指的是将本地的集合或数组作为输入数据的数据源。在Flink中,可以使用fromCollection、fromElements等方法将Java或Scala中的集合数据转化为数据流进行处理。
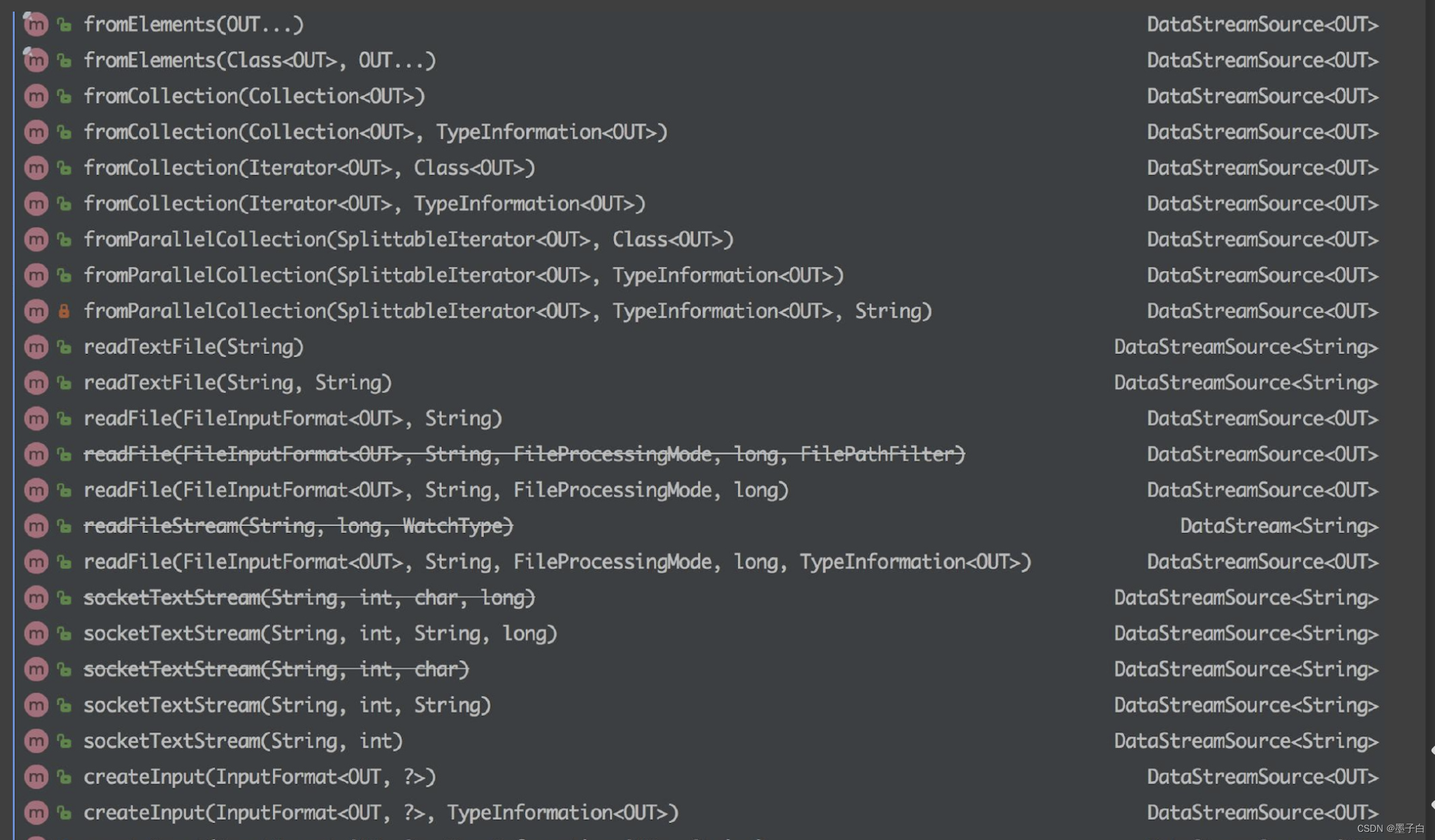
1、fromCollection(Collection) - 从 Java 的 Java.util.Collection 创建数据流。集合中的所有元素类型必须相同。
2、fromCollection(Iterator, Class) - 从一个迭代器中创建数据流。Class 指定了该迭代器返回元素的类型。
3、fromElements(T …) - 从给定的对象序列中创建数据流。所有对象类型必须相同。
4、fromParallelCollection(SplittableIterator, Class) - 从一个迭代器中创建并行数据流。Class 指定了该迭代器返回元素的类型。
5、generateSequence(from, to) - 创建一个生成指定区间范围内的数字序列的并行数据流。
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import java.util.Arrays;
import java.util.List;public class CollectionDataSourceExample {public static void main(String[] args) throws Exception {final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 创建一个包含整数的集合List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);// 将集合转化为Flink的DataSetDataSet<Integer> dataset = env.fromCollection(data);// 打印数据集中的元素dataset.print();}
}
关于使用集合数据源的注意事项:
-
数据规模:集合数据源适用于小规模数据集。确保你的数据集在内存中能够合理存放,不至于导致内存溢出。
-
内存消耗:集合数据源会将所有数据存储在内存中,因此需要谨慎处理大型数据集,避免对内存资源造成过大压力。
-
并行度设置:在集群环境下,可以通过设置并行度来充分利用集群资源,提高作业的执行效率。
-
调试和测试:集合数据源非常适合用于本地调试和测试,可以快速验证处理逻辑并观察输出结果。
使用集合数据源时需要注意这些方面,以确保作业能够稳定运行并获得良好的性能表现。
文件数据源
文件数据源(File Data Source):文件数据源用于从文件系统中读取数据,可以是本地文件系统或分布式文件系统(如HDFS)。Flink提供了readTextFile、readCsvFile等方法来支持常见文件格式的数据读取。
1、readTextFile(path) - 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回。
2、readFile(fileInputFormat, path) - 根据指定的文件输入格式读取文件(一次)。
3、readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和读取路径读取文件。根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;public class FileDataSourceExample {public static void main(String[] args) throws Exception {final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 从文件创建数据集String filePath = "path/to/your/file.txt";DataSet<String> text = env.readTextFile(filePath);// 打印文件中的内容text.print();}
}
关于使用文件数据源的注意事项:
-
文件路径:确保提供的文件路径是正确的,可以是本地文件系统路径,也可以是HDFS路径或其他支持的文件系统路径。
-
文件格式:Flink支持多种文件格式,包括文本文件、CSV文件、Parquet文件等。根据实际情况选择合适的文件格式进行读取。
-
并行度设置:在集群环境下,可以通过设置并行度来充分利用集群资源,提高文件读取的并行处理能力。
-
文件分区:对于大型文件,可以考虑文件分区和并行读取,以加速数据的加载和处理过程。
-
文件读取性能:尽量避免频繁的小文件读取操作,因为这会增加文件系统的负担并降低整体性能。
使用文件数据源时需要注意以上方面,以确保能够有效地读取文件数据,并且提高作业的执行效率。
Socket数据源
Socket数据源(Socket Data Source):Socket数据源允许通过网络套接字接收数据,通常用于测试和演示目的。Flink可以使用socketTextStream方法从TCP socket接收数据流。
socketTextStream(String hostname, int port) - 从 socket 读取。元素可以用分隔符切分。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class SocketDataSourceExample {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 从socket创建数据流String hostname = "localhost";int port = 9999;env.socketTextStream(hostname, port).print();// 执行作业env.execute("Socket Data Source Example");}
}
关于使用Socket数据源的注意事项:
-
主机和端口:确保指定的主机和端口是正确的,并且能够与数据源通信。
-
网络延迟:由于Socket数据源涉及网络通信,因此可能受到网络延迟的影响。需要考虑网络性能对作业整体性能的影响。
-
并行度设置:可以通过设置并行度来充分利用集群资源,提高数据流处理的并行能力。
-
数据格式:需要确保从Socket接收到的数据能够被正确解析和处理,例如按行读取文本数据等。
-
容错机制:在使用Socket数据源时,需要考虑作业的容错机制,以确保在发生故障或数据丢失时能够正确处理和恢复。
使用Socket数据源时需要注意以上方面,以确保能够有效地接收数据并提高作业的执行效率。
自定义数据源
自定义数据源(Custom Data Source):除了上述内置的数据源外,Flink还支持自定义数据源。用户可以实现自己的SourceFunction接口来定义特定的数据生成逻辑,例如从消息队列、数据库、传感器等实时数据源中读取数据。
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;public class CustomDataSource extends RichParallelSourceFunction<String> {private boolean running = true;@Overridepublic void run(SourceContext<String> ctx) throws Exception {while (running) {// 生成数据String data = generateData();// 发射数据ctx.collect(data);// 控制数据生成频率Thread.sleep(1000);}}@Overridepublic void cancel() {running = false;}private String generateData() {// 实现自定义的数据生成逻辑return "some data";}
}
在这个示例中,我们创建了一个名为CustomDataSource的类,它继承自RichParallelSourceFunction并指定了数据类型为String。在run方法中,我们使用一个循环来生成数据并通过collect方法将数据发射出去。在cancel方法中,我们设置了一个标志位来控制数据源的运行状态。
关于使用自定义数据源的注意事项:
-
并行度设置:根据数据源的性质和数据量合理地设置并行度,以充分利用集群资源。
-
数据生成频率:确保数据生成的频率和速度能够适应作业的处理能力,避免数据源产生过快导致作业无法及时处理。
-
容错机制:在自定义数据源中,需要考虑作业的容错机制,例如在发生故障时如何正确处理和恢复。
-
数据格式:确保从自定义数据源产生的数据能够被正确解析和处理,符合作业的输入要求。
-
资源管理:需要确保自定义数据源的资源占用和生命周期管理,避免资源泄露或过度占用资源。
使用自定义数据源时需要考虑以上方面,并确保能够有效地产生数据并提高作业的执行效率。
Apache Kafka数据源
Apache Kafka数据源(Kafka Data Source):作为流数据处理框架,Flink对Kafka提供了良好的集成支持。可以使用addSource方法结合Flink的Kafka Connector来从Kafka主题中读取数据。
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class KafkaDataSourceExample {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// Kafka配置Properties properties = new Properties();properties.setProperty("bootstrap.servers", "localhost:9092");properties.setProperty("group.id", "flink-consumer-group");// 创建Kafka数据流FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("my-topic", new SimpleStringSchema(), properties);DataStream<String> kafkaDataStream = env.addSource(kafkaConsumer);kafkaDataStream.print();// 执行作业env.execute("Kafka Data Source Example");}
}
在这个示例中,我们首先创建了一个StreamExecutionEnvironment对象,然后设置Kafka的连接配置,包括bootstrap servers和consumer group id等。接下来,我们创建了一个FlinkKafkaConsumer对象,指定了要消费的topic以及数据的序列化方式,并将其添加到流处理环境中。最后,我们通过调用print方法来打印数据流中的内容,并通过execute方法启动作业并执行。
关于使用Kafka数据源的注意事项:
-
Kafka配置:确保指定的Kafka配置正确,并能够与Kafka集群进行通信。
-
序列化方式:根据实际情况选择合适的数据序列化方式,例如SimpleStringSchema、JSON、Avro等。
-
并行度设置:可以通过设置并行度来充分利用集群资源,提高数据流处理的并行能力。
-
数据消费策略:需要考虑消费数据的策略,如是否从最新/最旧的数据开始消费,以及如何处理消费过程中的偏移量。
-
容错机制:在使用Kafka数据源时,需要考虑作业的容错机制,以确保在发生故障或数据丢失时能够正确处理和恢复。
使用Kafka数据源时需要注意以上方面,以确保能够有效地消费Kafka中的数据并提高作业的执行效率。
Apache Pulsar数据源
Apache Pulsar数据源(Pulsar Data Source):类似于Kafka,Flink也集成了对Pulsar的支持,可以直接从Pulsar主题中读取数据。
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.pulsar.FlinkPulsarSource;
import org.apache.pulsar.client.api.Schema;
import org.apache.pulsar.client.api.PulsarClientException;public class PulsarDataSourceExample {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();String serviceUrl = "pulsar://localhost:6650";String topic = "my-topic";FlinkPulsarSource<String> pulsarSource = new FlinkPulsarSource<>(serviceUrl,topic,Schema.STRING);DataStream<String> pulsarDataStream = env.addSource(pulsarSource);pulsarDataStream.print();env.execute("Pulsar Data Source Example");}
}
在这个示例中,我们首先创建了一个StreamExecutionEnvironment对象,然后指定了Pulsar的连接信息和要消费的topic。接下来,我们创建了一个FlinkPulsarSource对象,并指定了Pulsar的serviceUrl、topic以及数据的Schema,并将其添加到流处理环境中。最后,我们通过调用print方法来打印数据流中的内容,并通过execute方法启动作业并执行。
关于使用Pulsar数据源的注意事项:
-
Pulsar连接配置:确保指定的Pulsar连接信息正确,并能够与Pulsar集群进行通信。
-
Schema设置:根据实际情况选择合适的数据Schema,例如STRING、JSON、AVRO等。
-
并行度设置:可以通过设置并行度来充分利用集群资源,提高数据流处理的并行能力。
-
数据消费策略:需要考虑消费数据的策略,如是否从最新/最旧的数据开始消费,以及如何处理消费过程中的偏移量。
-
容错机制:在使用Pulsar数据源时,需要考虑作业的容错机制,以确保在发生故障或数据丢失时能够正确处理和恢复。
使用Pulsar数据源时需要注意以上方面,以确保能够有效地消费Pulsar中的数据并提高作业的执行效率。
这些不同类型的数据源为Flink应用程序提供了灵活的数据接入方式,使得Flink可以轻松地处理不同来源和格式的数据。根据具体的业务需求和场景特点,可以选择合适的数据源类型来构建流处理和批处理应用程序。
更多消息资讯,请访问昂焱数据(https://www.ayshuju.com)
相关文章:
Flink—— Data Source 介绍
Data Source 简介 Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来ÿ…...
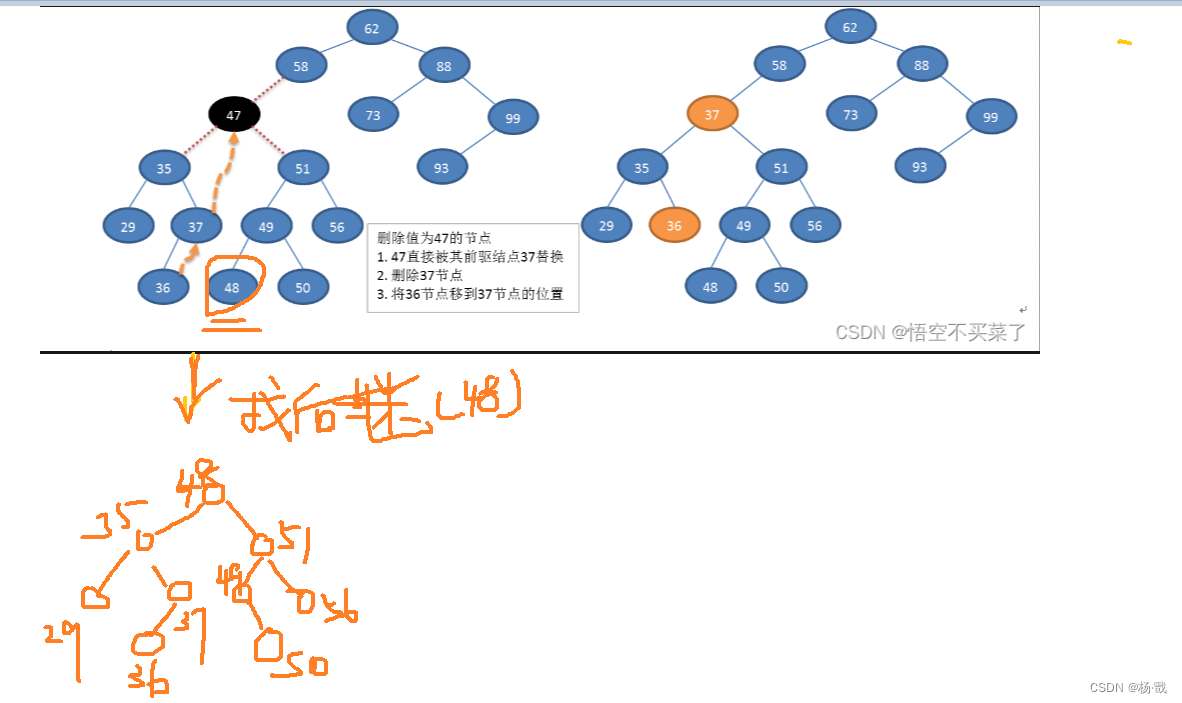
树之二叉排序树(二叉搜索树)
什么是排序树 说一下普通二叉树可不是左小右大的 插入的新节点是以叶子形式进行插入的 二叉排序树的中序遍历结果是一个升序的序列 下面是两个典型的二叉排序树 二叉排序树的操作 构造树的过程即是对无序序列进行排序的过程。 存储结构 通常采用二叉链表作为存储结构 不能 …...
管易云与电商平台的无代码集成:实现API连接与用户运营
管易云简介及其与电商平台的合作 金蝶管易云是金蝶集团旗下以电商为核心业务的子公司,是国内最早的电商ERP服务商之一,总部在上海,与淘宝、天猫、 京东、拼多多、抖音等300多家主流电商平台建立合作关系,同时管易云是互联网平台首…...
)
ElementUI的el-upload上传组件与表单一起提交遇到的各种问题以及解决办法(超详细,每个步骤都有详细解读)
背景: 使用ruoyi-vue进行2次开发,需要实现表单与文件上传一起提交,并且文件上传有4个,且文件校验很复杂,因此ruoyi-vue集成的上传组件FileUpload调试几天后发现真不太适用,最终选择element UI原生组件el-upload(FileUpload也是基于el-upload实现的),要实现表单与文件同…...

python flask_restful “message“: “Failed to decode JSON object: None“
1、问题表现 "message": "Failed to decode JSON object: None"2、出现的原因 Werkzeug 版本过高 3、解决方案 pip install Werkzeug2.0解决效果 可以正常显示json数据了 {"message": {"rate": "参数错误"} }...
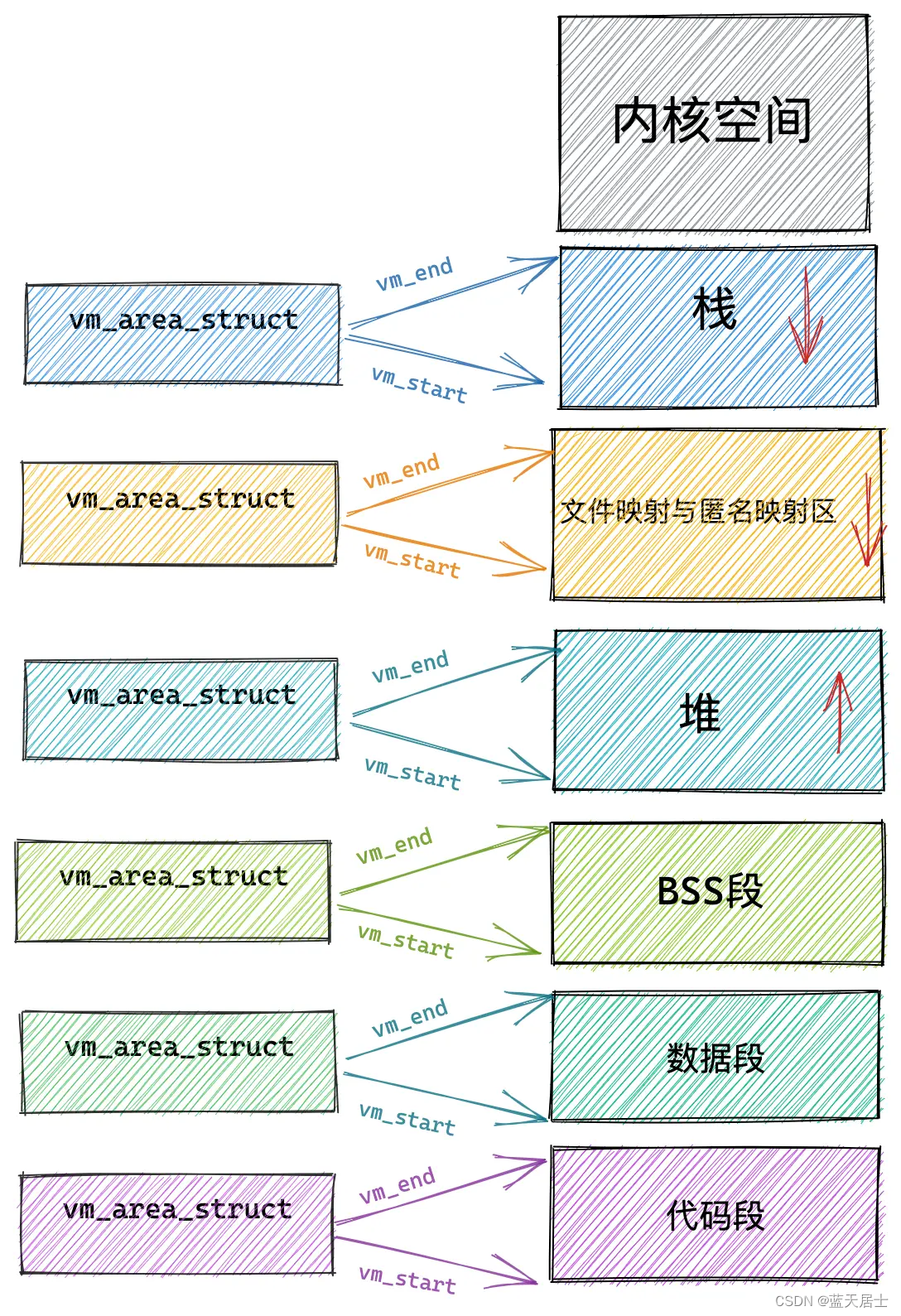
Linux内核有什么之内存管理子系统有什么第六回 —— 小内存分配(4)
接前一篇文章:Linux内核有什么之内存管理子系统有什么第五回 —— 小内存分配(3) 本文内容参考: linux进程虚拟地址空间 《趣谈Linux操作系统 核心原理篇:第四部分 内存管理—— 刘超》 特此致谢! 二、小…...
)
【OpenHarmony内核】Harmony内核之线程操作函数(二)
文章目录 前言一、获取线程优先级二、转交控制运行权三、挂起线程3.1 线程的挂起是什么意思?3.2 函数介绍四、恢复线程五、分离指定的线程5.1 分离线程是什么意思5.2 函数介绍六、等待线程终止运行七、终止当前线程的运行八、终止指定线程的运行九、获取活跃线程数总结前言 O…...

二十五、W5100S/W5500+RP2040树莓派Pico<Modebus TCP Server示例>
文章目录 1 前言2 简介2 .1 什么是Modbus TCP?2.2 Modbus TCP指令介绍2.3 请求数据过程2.4 Modbus TCP协议优点2.5 Modbus TCP应用场景 3 WIZnet以太网芯片4 Modbus TCP示例概述以及使用4.1 流程图4.2 准备工作核心4.3 连接方式4.4 主要代码概述4.5 结果演示 5 注意…...

Android画个圆点状态灯
1、创建一个 XML 文件在 res/drawable 目录下(默认为黑色) <?xml version"1.0" encoding"utf-8"?> <shape xmlns:android"http://schemas.android.com/apk/res/android"android:shape"oval"><…...

高性能网络编程 - 解读3种线程模型
文章目录 Pre线程模型1:传统阻塞 I/O 服务模型线程模型2:Reactor 模式Reactor 模式的基本设计思想Reactor 模式中的关键组成3种典型实现单 Reactor 单线程单 Reactor 多线程主从 Reactor 多线程 小结 线程模型3:Proactor 模型 Pre 高性能网络…...
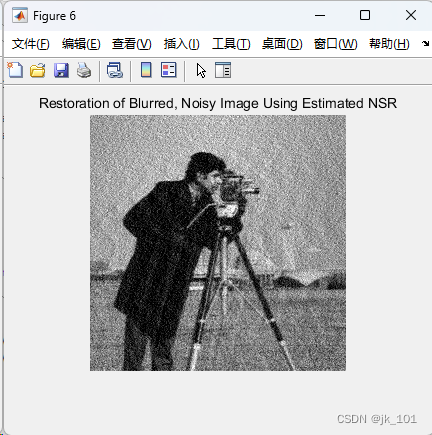
MATLAB中deconvwnr函数用法
目录 语法 说明 示例 使用 Wiener 滤波对图像进行去模糊处理 deconvwnr函数的功能是使用 Wiener 滤波对图像进行去模糊处理。 语法 J deconvwnr(I,psf,nsr) J deconvwnr(I,psf,ncorr,icorr) J deconvwnr(I,psf) 说明 J deconvwnr(I,psf,nsr) 使用 Wiener 滤波算法对…...

赛宁网安入选国家工业信息安全漏洞库(CICSVD)2023年度技术组成员单
近日,由国家工业信息安全发展研究中心、工业信息安全产业发展联盟主办的“2023工业信息安全大会”在北京成功举行。 会上,国家工业信息安全发展研究中心对为国家工业信息安全漏洞库(CICSVD)提供技术支持的单位授牌表彰。北京赛宁…...

Git系列之Git集成开发工具及git扩展使用
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是君易--鑨,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的博客专栏《Git实战开发》。🎯🎯 &a…...

selenium headless 无头模式慢
selenium设置headlessTrue发现非常慢,headlessFalse要快很多。 最后测试发现升级到selenium最新版本,selenium4.15.2。设置--headlessnew,解决了,速度正常了。 新版selenium有了两种headless模式,参见:He…...
快速修复因相机断电导致视频文件打不开的问题
3-5 本文主要解决因相机突然断电导致拍摄的视频文件打不开的问题。 在日常工作中,有时候需要使用相机拍摄视频,比如现在有不少短视频拍摄的需求,如果因电池突然断电的原因,导致拍出来的视频播放不了,这时候就容易出大…...

Ceph 笔记, ssh写入缓存
硬件建议 — Ceph 文档 写入缓存 企业级 SSD 和 HDD 通常包括断电保护功能,包括 在运行时断电时确保数据耐久性,以及 使用多级缓存来加快直接或同步写入速度。这些设备 可以在两种缓存模式之间切换 -- 刷新到的易失性缓存 具有 fsync 的持久性媒体&a…...
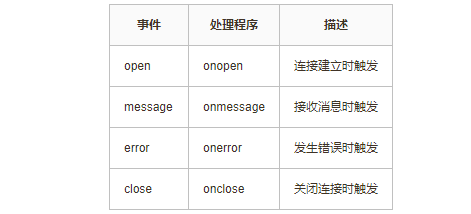
WebSocket魔法师:打造实时应用的无限可能
1、背景 在开发一些前端页面的时候,总是能接收到这样的需求:如何保持页面并实现自动更新数据呢?以往的常规做法,是前端使用定时轮询后端接口,获取响应后重新渲染前端页面,这种做法虽然能达到类似的效果&…...
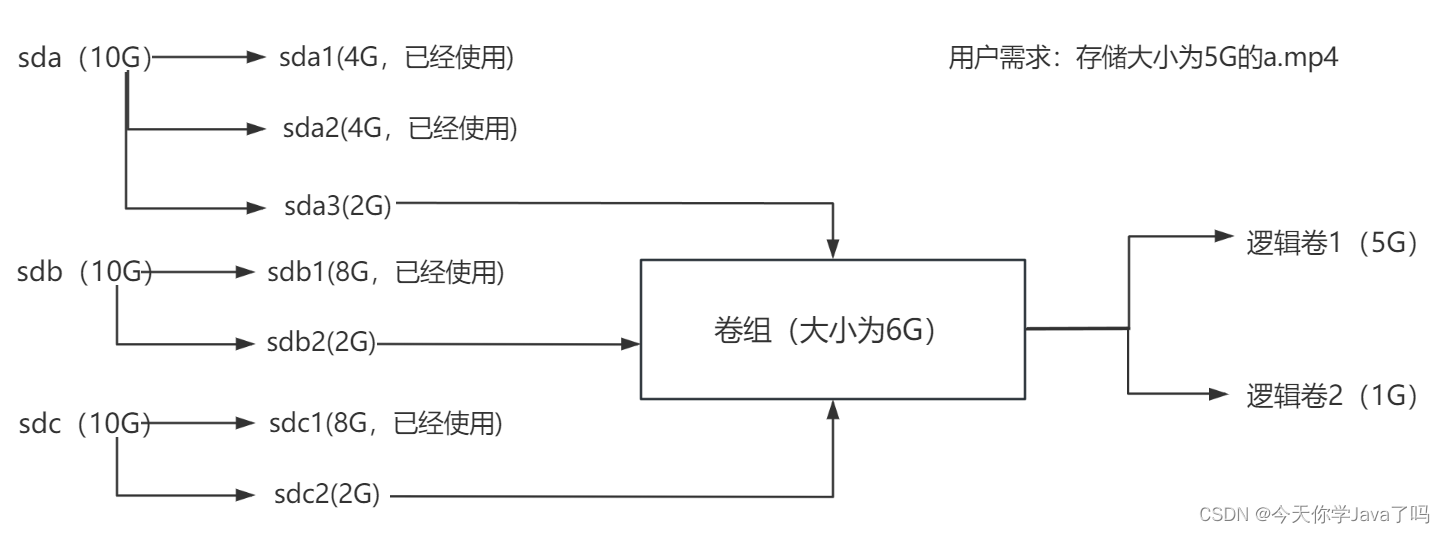
网络运维Day06-补充
文章目录 RAID磁盘阵列RAID0条带模式RAID1镜像模式RAID5高性价比模式RAID01RAID10 逻辑卷一块磁盘的使用流程逻辑卷的使用流程 制作逻辑卷步骤一:添加硬盘步骤二:分区规划步骤三:制作物理卷步骤四:制作卷组步骤五:制作…...
)
openssl+SM2开发实例一(含源码)
一、SM2算法介绍 SM2(国密算法2) 是中国国家密码管理局(CNCA)颁布的椭圆曲线密码算法标准,属于非对称加密算法。它基于椭圆曲线离散对数问题,提供了安全可靠的数字签名、密钥交换和公钥加密等功能。SM2被设…...
操作系统 | 编写内核
🌈个人主页:Sarapines Programmer🔥 系列专栏:《操作系统实验室》🔖少年有梦不应止于心动,更要付诸行动。 目录结构 1. 操作系统实验之编写内核 1.1 实验目的 1.2 实验内容 1.3 实验步骤 1.4 实验过程 …...

中年人最贵的错觉,是靠“闭眼许愿”去赌一个残酷的未来
周四下班,北京下了场雨。我刚出地铁14号线,就被老同事大杨拽去了旁边的一家小饭馆。大杨今年39,在一家传统IT企业干了八年客户总监,背着大兴一套房的上万块月供,家里还有个刚上小学的吞金兽。几杯扎啤下肚,…...

如何通过smol-macros获得Rust异步编程的终极快速编译优势
如何通过smol-macros获得Rust异步编程的终极快速编译优势 【免费下载链接】smol A small and fast async runtime for Rust 项目地址: https://gitcode.com/gh_mirrors/smo/smol smol是一个轻量级且高效的Rust异步运行时,专为追求极致性能和快速编译的开发者…...

开启MySQL8的密码策略组件validate_password
一、validate_password组件安装配置1. 安装组件INSTALL COMPONENT file://component_validate_password;安装后,密码策略立即生效,但仅影响后续操作(如新建用户或修改密码)。2. 卸载组件UNINSTALL COMPONENT file://component_val…...

DAMO-YOLO手机检测结果结构化解析:JSON输出格式与数据库存储设计
DAMO-YOLO手机检测结果结构化解析:JSON输出格式与数据库存储设计 1. 引言:从检测框到结构化数据 当你运行一个手机检测模型,看到屏幕上出现一个个红色的方框时,你可能在想:这些检测结果怎么用起来?怎么保…...

SDMatte效果深度评测:复杂人像与发丝级抠图的惊艳表现
SDMatte效果深度评测:复杂人像与发丝级抠图的惊艳表现 1. 开篇:重新定义图像抠图标准 当你在电商平台看到完美无瑕的商品展示图,或者在电影中看到主角与虚拟场景无缝融合时,背后都离不开一项关键技术——图像抠图。传统抠图工具…...
)
WSL 极速部署 llama.cpp:三步搞定 CPU、GPU 本地运行大模型(CUDA 加速)
摘要: 想在 Windows 下本地跑大模型,又不想搞双系统?WSL llama.cpp 是最轻量、高效的选择。本文将带你一步步完成环境配置、源码编译(可选 NVIDIA GPU 加速),并下载模型直接运行。无需复杂依赖,…...

npx:Node.js生态中的敏捷执行器,如何革新命令行工具的使用体验?
1. 为什么我们需要npx? 如果你用过Node.js,肯定对npm不陌生。作为Node.js的包管理器,npm让我们能够轻松安装和管理各种JavaScript库和工具。但不知道你有没有遇到过这样的烦恼:每次想用某个命令行工具,都得先全局安装它…...

python devspace
# 聊聊Python DevSpace:一个让开发环境更清爽的工具 最近在项目里折腾环境配置,又遇到了老问题。不同的项目依赖不同的Python版本,不同的库版本,有时候甚至需要不同的系统环境。虚拟环境能解决一部分问题,但涉及到系统…...

如何快速融入Kolors开源社区:完整贡献指南与技术支持体系
如何快速融入Kolors开源社区:完整贡献指南与技术支持体系 【免费下载链接】Kolors Kolors Team 项目地址: https://gitcode.com/gh_mirrors/ko/Kolors Kolors是由快手Kolors团队开发的大规模文本到图像生成模型,基于潜在扩散技术,在数…...

react-native-shared-element 跨平台适配指南:iOS、Android 和 Web 的实现差异
react-native-shared-element 跨平台适配指南:iOS、Android 和 Web 的实现差异 【免费下载链接】react-native-shared-element Native shared element transition "primitives" for react-native 💫 项目地址: https://gitcode.com/gh_mirro…...