Spring Boot 集成 ElasticSearch
1 加入依赖
首先创建一个项目,在项目中加入 ES 相关依赖,具体依赖如下所示:
<dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.1.0</version>
</dependency>
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.1.0</version>
</dependency>
2 创建 ES 配置
在配置文件 application.properties 中配置 ES 的相关参数,具体内容如下:
elasticsearch.host=localhost
elasticsearch.port=9200
elasticsearch.connTimeout=3000
elasticsearch.socketTimeout=5000
elasticsearch.connectionRequestTimeout=500
其中指定了 ES 的 host 和端口以及超时时间的设置,另外我们的 ES 没有添加任何的安全认证,因此 username 和 password 就没有设置。
然后在 config 包下创建 ElasticsearchConfiguration 类,会从配置文件中读取到对应的参数,接着申明一个 initRestClient 方法,返回的是一个 RestHighLevelClient,同时为它添加 @Bean(destroyMethod = “close”) 注解,当 destroy 的时候做一个关闭,这个方法主要是如何初始化并创建一个 RestHighLevelClient。
@Configuration
public class ElasticsearchConfiguration {@Value("${elasticsearch.host}")private String host;@Value("${elasticsearch.port}")private int port;@Value("${elasticsearch.connTimeout}")private int connTimeout;@Value("${elasticsearch.socketTimeout}")private int socketTimeout;@Value("${elasticsearch.connectionRequestTimeout}")private int connectionRequestTimeout;@Bean(destroyMethod = "close", name = "client")public RestHighLevelClient initRestClient() {RestClientBuilder builder = RestClient.builder(new HttpHost(host, port)).setRequestConfigCallback(requestConfigBuilder -> requestConfigBuilder.setConnectTimeout(connTimeout).setSocketTimeout(socketTimeout).setConnectionRequestTimeout(connectionRequestTimeout));return new RestHighLevelClient(builder);}
}3 定义文档实体类
首先在 constant 包下定义常量接口,在接口中定义索引的名字为 user:
public interface Constant {String INDEX = "user";
}
然后在 document 包下创建一个文档实体类:
public class UserDocument {private String id;private String name;private String sex;private Integer age;private String city;// 省略 getter/setter
}
4 ES 基本操作
在这里主要介绍 ES 的索引、文档、搜索相关的简单操作,在 service 包下创建 UserService 类。
4.1 索引操作
在创建索引的时候可以在 CreateIndexRequest 中设置索引名称、分片数、副本数以及 mappings,在这里索引名称为 user,分片数 number_of_shards 为 1,副本数 number_of_replicas 为 0,具体代码如下所示:
public boolean createUserIndex(String index) throws IOException {CreateIndexRequest createIndexRequest = new CreateIndexRequest(index);createIndexRequest.settings(Settings.builder().put("index.number_of_shards", 1).put("index.number_of_replicas", 0));createIndexRequest.mapping("{\n" +" \"properties\": {\n" +" \"city\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"sex\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"age\": {\n" +" \"type\": \"integer\"\n" +" }\n" +" }\n" +"}", XContentType.JSON);CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest, RequestOptions.DEFAULT);return createIndexResponse.isAcknowledged();
}
通过调用该方法,就可以创建一个索引 user,索引信息如下:

关于 ES 的 Mapping会专门出一篇文章进行讲解
4.2 删除索引
在 DeleteIndexRequest 中传入索引名称就可以删除索引,具体代码如下所示:
public Boolean deleteUserIndex(String index) throws IOException {DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(index);AcknowledgedResponse deleteIndexResponse = client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);return deleteIndexResponse.isAcknowledged();
}
介绍完索引的基本操作,下面介绍文档的相关操作:
4.3 文档操作
在这里演示下创建文档、批量创建文档、查看文档、更新文档以及删除文档:
4.3.1 创建文档
创建文档的时候需要在 IndexRequest 中指定索引名称,id 如果不传的话会由 ES 自动生成,然后传入 source,具体代码如下:
public Boolean createUserDocument(UserDocument document) throws Exception {UUID uuid = UUID.randomUUID();document.setId(uuid.toString());IndexRequest indexRequest = new IndexRequest(Constant.INDEX).id(document.getId()).source(JSON.toJSONString(document), XContentType.JSON);IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);return indexResponse.status().equals(RestStatus.OK);
}
下面通过调用这个方法,创建两个文档,具体内容如下:

4.3.2 批量创建文档
在一个 REST 请求中,重新建立网络开销是十分损耗性能的,因此 ES 提供 Bulk API,支持在一次 API 调用中,对不同的索引进行操作,从而减少网络传输开销,提升写入速率。
下面方法是批量创建文档,一个 BulkRequest 里可以添加多个 Request,具体代码如下:
public Boolean bulkCreateUserDocument(List<UserDocument> documents) throws IOException {BulkRequest bulkRequest = new BulkRequest();for (UserDocument document : documents) {String id = UUID.randomUUID().toString();document.setId(id);IndexRequest indexRequest = new IndexRequest(Constant.INDEX).id(id).source(JSON.toJSONString(document), XContentType.JSON);bulkRequest.add(indexRequest);}BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);return bulkResponse.status().equals(RestStatus.OK);
}
下面通过该方法创建些文档,便于下面的搜索演示。
4.3.3 查看文档
查看文档需要在 GetRequest 中传入索引名称和文档 id,具体代码如下所示:
public UserDocument getUserDocument(String id) throws IOException {GetRequest getRequest = new GetRequest(Constant.INDEX, id);GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);UserDocument result = new UserDocument();if (getResponse.isExists()) {String sourceAsString = getResponse.getSourceAsString();result = JSON.parseObject(sourceAsString, UserDocument.class);} else {logger.error("没有找到该 id 的文档");}return result;
}
下面传入文档 id 调用该方法,结果如下所示:
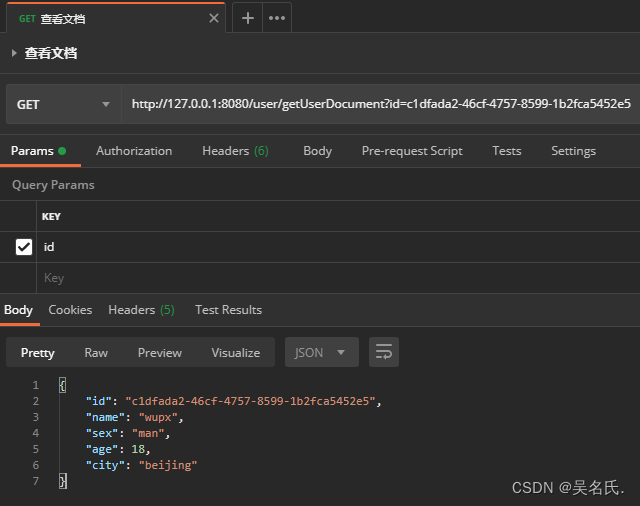
4.3.4 更新文档
更新文档则是先给 UpdateRequest 传入索引名称和文档 id,然后通过传入新的 doc 来进行更新,具体代码如下:
public Boolean updateUserDocument(UserDocument document) throws Exception {UserDocument resultDocument = getUserDocument(document.getId());UpdateRequest updateRequest = new UpdateRequest(Constant.INDEX, resultDocument.getId());updateRequest.doc(JSON.toJSONString(document), XContentType.JSON);UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);return updateResponse.status().equals(RestStatus.OK);
}
下面将文档 id 为 9b8d9897-3352-4ef3-9636-afc6fce43b20 的文档的城市信息改为 handan,调用方法结果如下:
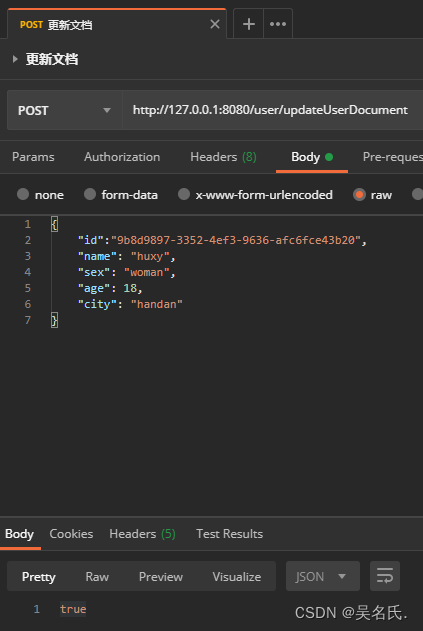
4.3.5 删除文档
删除文档只需要在 DeleteRequest 中传入索引名称和文档 id,然后执行 delete 方法就可以完成文档的删除,具体代码如下:
public String deleteUserDocument(String id) throws Exception {DeleteRequest deleteRequest = new DeleteRequest(Constant.INDEX, id);DeleteResponse response = client.delete(deleteRequest, RequestOptions.DEFAULT);return response.getResult().name();
}
介绍完文档的基本操作,接下来对搜索进行简单介绍:
4.4 搜索操作
简单的搜索操作需要在 SearchRequest 中设置将要搜索的索引名称(可以设置多个索引名称),然后通过 SearchSourceBuilder 构造搜索源,下面将 TermQueryBuilder 搜索查询传给 searchSourceBuilder,最后将 searchRequest 的搜索源设置为 searchSourceBuilder,执行 search 方法实现通过城市进行搜索,具体代码如下所示:
public List<UserDocument> searchUserByCity(String city) throws Exception {SearchRequest searchRequest = new SearchRequest();searchRequest.indices(Constant.INDEX);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", city);searchSourceBuilder.query(termQueryBuilder);searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);return getSearchResult(searchResponse);
}
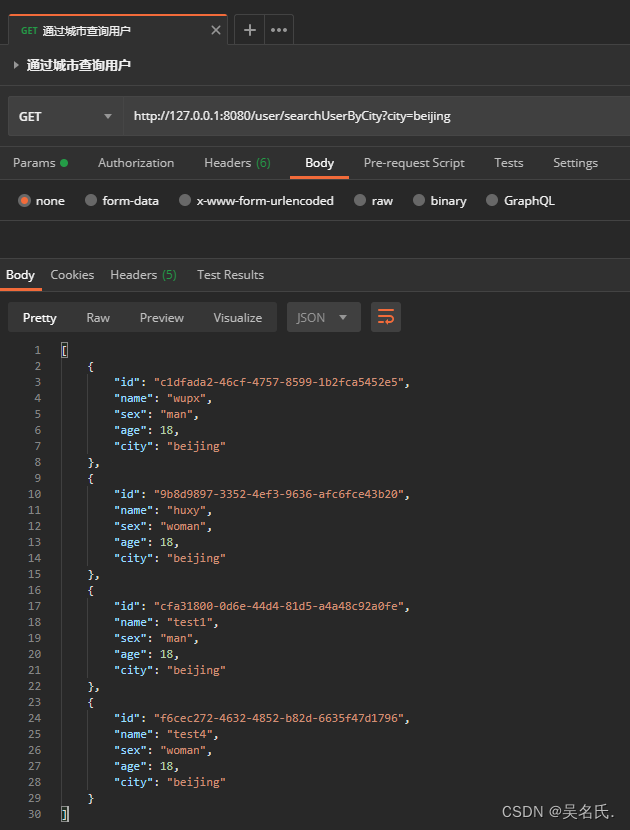
4.4.1 聚合搜索
聚合搜索就是给 searchSourceBuilder 添加聚合搜索,下面方法是通过 TermsAggregationBuilder 构造一个先通过城市就行分类聚合,其中还包括一个子聚合,是对年龄求平均值,然后在获取聚合结果的时候,可以使用通过在构建聚合时的聚合名称获取到聚合结果,具体代码如下所示:
public List<UserCityDTO> aggregationsSearchUser() throws Exception {SearchRequest searchRequest = new SearchRequest(Constant.INDEX);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_city").field("city").subAggregation(AggregationBuilders.avg("average_age").field("age"));searchSourceBuilder.aggregation(aggregation);searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);Aggregations aggregations = searchResponse.getAggregations();Terms byCityAggregation = aggregations.get("by_city");List<UserCityDTO> userCityList = new ArrayList<>();for (Terms.Bucket buck : byCityAggregation.getBuckets()) {UserCityDTO userCityDTO = new UserCityDTO();userCityDTO.setCity(buck.getKeyAsString());userCityDTO.setCount(buck.getDocCount());// 获取子聚合Avg averageBalance = buck.getAggregations().get("average_age");userCityDTO.setAvgAge(averageBalance.getValue());userCityList.add(userCityDTO);}return userCityList;
}
下面是执行该方法的结果:
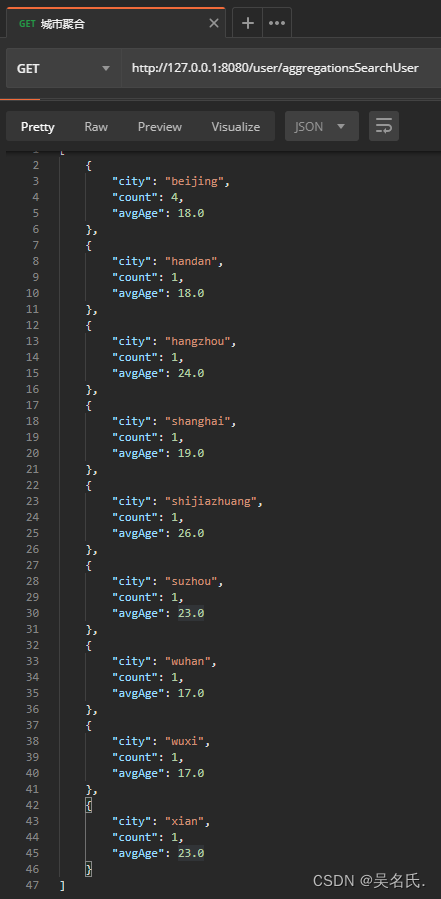
到此为止,ES 的基本操作就简单介绍完了,大家可以多动手试试,不会的可以看下官方文档。
5 总结
本文的完整代码在https://github.com/363153421/springboot-elasticsearch下。
Spring Boot 结合 ES 还是比较简单的,大家可以下载项目源码,自己在本地运行调试这个项目,更好地理解如何在 Spring Boot 中构建基于 ES 的应用。
相关文章:
Spring Boot 集成 ElasticSearch
1 加入依赖 首先创建一个项目,在项目中加入 ES 相关依赖,具体依赖如下所示: <dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.1.0</version&g…...

百度智能云正式上线Python SDK版本并全面开源!
文章目录 1. SDK的优势2. 千帆SDK:快速落地LLM应用3. 如何快速上手千帆SDK3.1 SDK快速启动3.2 SDK进阶指引3.3 通过Langchain接入千帆SDK 4. 开源社区 百度智能云千帆大模型平台再次升级!在原有API基础上,百度智能云正式上线Python SDK&#…...
LeetCode(3)删除有序数组中的重复项【数组/字符串】【简单】
目录 1.题目2.答案3.提交结果截图 链接: 26. 删除有序数组中的重复项 1.题目 给你一个 非严格递增排列 的数组 nums ,请你** 原地** 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保…...

前端视角中的微信登录
目录 引入 流程介绍 具体实现 引入 本文主要讲解网站应用中微信登录的具体流程是怎么样的,以及作为前端开发人员在这整个流程中的主要任务是什么。 如果想要实现微信登录的功能,需要开发人员到微信开放平台注册相应的账号,进行注册应用&am…...

Python 中使用 Selenium 隐式等待
selenium 包用于使用 Python 脚本进行自动化和测试。 我们可以使用它来访问网页中的各个元素并使用它们。 该包中有许多方法可用于根据不同属性检索元素。 加载页面时,会动态检索一些元素。 与其他元素相比,这些元素的加载速度可能不同。 Python 中使用…...
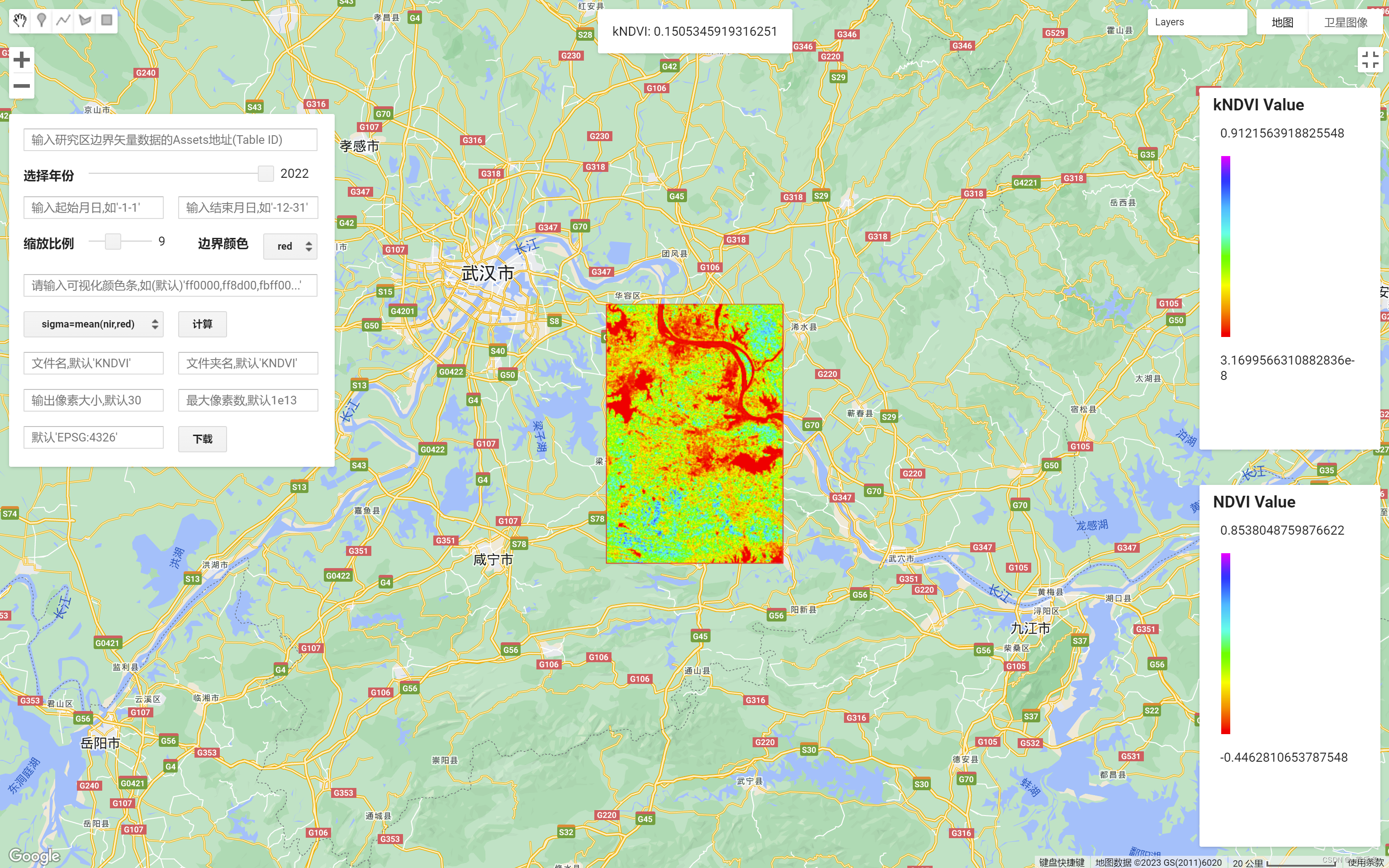
GEE:基于 Landsat 计算的 kNDVI 应用 APP
作者:CSDN @ _养乐多_ 本文记录了在Google Earth Engine(GEE)平台中,使用 Landsat 遥感数据计算 kNDVI 的应用 APP 链接,并介绍该 APP 的使用方法和步骤。该APP可以为用户展示 NDVI 和 kNDVI 的遥感影像,进行对比分析。该 APP 在 Google Earth Engine(GEE)平台中实现。…...

Spring 缓存注解
Spring Cache 框架给我们提供了 Cacheable 注解用于缓存方法返回内容。但是 Cacheable 注解不能定义缓存有效期。这样的话在一些需要自定义缓存有效期的场景就不太实用。 按照 Spring Cache 框架给我们提供的 RedisCacheManager 实现,只能在全局设置缓存有效期。这…...

微信小程序前端开发
目录 前言: 1. 框架选择和项目搭建 2. 小程序页面开发 3. 数据通信和接口调用 4. 性能优化和调试技巧 5. 小程序发布和上线 前言: 当谈到微信小程序前端开发时,我们指的是使用微信小程序框架进行开发的一种方式。在本文中,我…...

C# OpenCvSharp DNN HybridNets 同时处理车辆检测、可驾驶区域分割、车道线分割
效果 项目 代码 using OpenCvSharp; using OpenCvSharp.Dnn; using System; using System.Collections.Generic; using System.Drawing; using System.IO; using System.Linq; using System.Numerics; using System.Text; using System.Windows.Forms;namespace OpenCvSharp_D…...
无需开发,精臣云可轻松连接用户运营、广告推广等行业应用
精臣智慧标识科技有限公司简介 武汉精臣智慧标识科技有限公司,是国内便携式标签打印机创新品牌和实物管理解决方案服务商。在物品标签还处在繁琐的PC打印时代,精臣公司便创造性地从智能便携角度出发,顺应移动互联时代趋势,推出了…...

第三阶段第一章——PySpark实战
学习了这么多python的知识,是时候来搞点真玩意儿了~~ 春风得意马蹄疾,一日看尽长安花 o(* ̄︶ ̄*)o 1.前言介绍 (1)什么是spark Apache Spark是一个开源的分布式计算框架,用于处理大规模数据集的…...
Python数据容器(字符串)
字符串 1.字符串 字符串也是数据容器的一种,字符串是字符的容器,一个字符串可以存放任意数量的字符。 2.字符串的下标索引 从前向后,下标从0开始从后向前,下标从-1开始 # 通过下标索引获取特定位置的字符 name python print(na…...
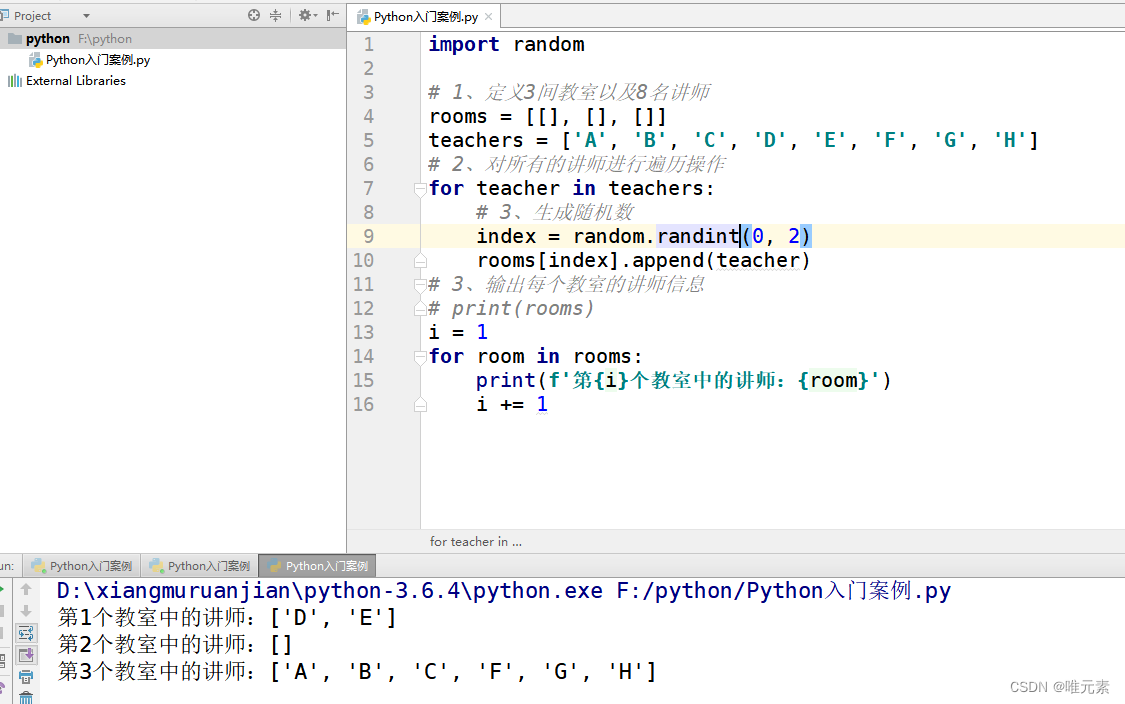
Python---练习:把8名讲师随机分配到3个教室
案例:把8名讲师随机分配到3个教室 列表嵌套:有3个教室[[],[],[]],8名讲师[A,B,C,D,E,F,G,H],将8名讲师随机分配到3个教室中。 分析: 思考1:我们第一间教室、第二间教室、第三间教室,怎么表示…...
python+requests接口自动化测试
原来的web页面功能测试转变成接口测试,之前大多都是手工进行,利用postman和jmeter进行的接口测试,后来,组内有人讲原先web自动化的测试框架移驾成接口的自动化框架,使用的是java语言,但对于一个学java&…...
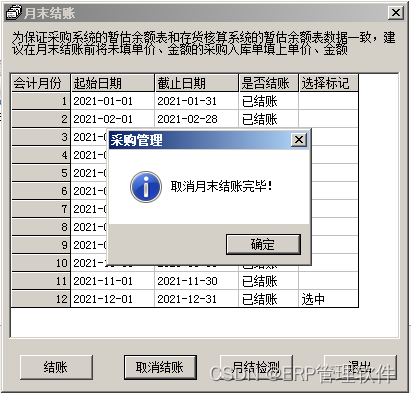
【T3】畅捷通T3采购管理模块反结账,提示:本年数据已经结转,不能取消结账。
【问题描述】 使用畅捷通T3软件过程中, 针对以前年度进行反结账过程中,遇到采购管理模块取消12月份结账, 提示:本年数据已经结转,不能取消结账。 【分析需求】 按正常逻辑,需要清空新年度数据,…...

线性代数(五) | 矩阵对角化 特征值 特征向量
文章目录 1 矩阵的特征值和特征向量究竟是什么?2 求特征值和特征向量3 特征值和特征向量的应用4 矩阵的对角化 1 矩阵的特征值和特征向量究竟是什么? 矩阵实际上是一种变换,是一种旋转伸缩变换(方阵) 不是方阵的话还有可能是一种…...

读书笔记:彼得·德鲁克《认识管理》第12章 服务机构的绩效管理
一、章节内容概述 要提高服务机构和服务部门的绩效水平,需要的不是天才,相反,首先需要的是清晰的目标和任务,其次是把资源集中用于优先事项,再次需要明确的成果衡量标准,最后需要系统性地抛弃过时的目标和…...

基于FPGA的模板匹配红外目标跟踪算法设计
为什么要写这篇文章 我写这篇文章的原因是一天在B站看到了一个大神发的视频是关于跟踪一个无人机的,看到作者跟网友的回复说是用的图像匹配算法,我就在网上搜索相关资料,最终找到一篇文献。文献中对该算法的评价很高,满足制导系统…...
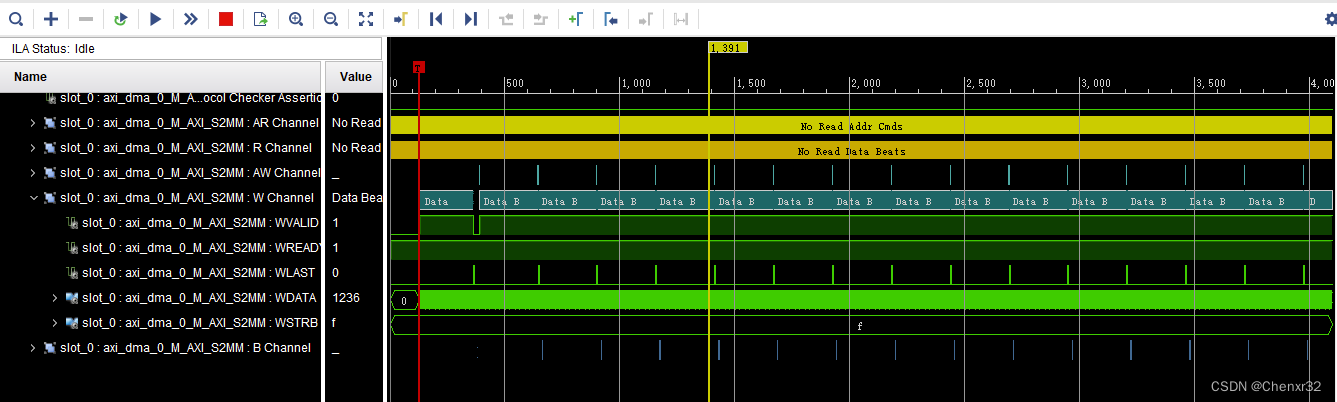
ZYNQ通过AXI DMA实现PL发送连续大量数据到PS DDR
硬件:ZYNQ7100 软件:Vivado 2017.4、Xilinx SDK 2017.4 ZYNQ PL 和 PS 的通信方式有 AXI GPIO、BRAM、DDR等。对于数据量较少、地址不连续、长度规则的情况,BROM 比较适用。而对于传输速度要求高、数据量大、地址连续的情况,比…...

用于强化学习的置换不变神经网络
一、介绍 如果强化学习代理提供的输入在训练中未明确定义,则通常表现不佳。一种新方法使 RL 代理能够正常运行,即使受到损坏、不完整或混乱的输入的影响也是如此。 “大脑能够使用来自皮肤的信息,就好像它来自眼睛一样。我们不是用眼睛看&…...

穿越机电调协议进化史:从PWM到DShot1200的性能对比实测
穿越机电调协议进化史:从PWM到DShot1200的性能对比实测 第一次接触穿越机时,最让我困惑的就是电调协议的选择。PWM、OneShot、DShot这些名词听起来像天书,直到亲眼看到不同协议在示波器上的波形差异,才真正理解它们对飞行性能的影…...

解密Claude Code工具链:从Bash到WebSearch的18种武器使用指南
Claude Code工具链深度解析:从基础操作到智能协同的18种核心能力 在当今快速发展的AI辅助编程领域,Claude Code以其独特的工具链设计和安全优先的理念脱颖而出。这套工具系统不仅仅是简单的命令集合,而是一个经过精心设计的智能协作框架&…...
)
别再瞎选启动盘格式了!用Rufus烧录Windows安装盘时,MBR和GPT到底怎么选?(附DiskGenius查看方法)
启动盘格式选择指南:MBR与GPT的终极决策逻辑 每次用Rufus制作Windows安装盘时,面对MBR和GPT两个选项,你是不是总在纠结该选哪个?这就像站在分叉路口,生怕选错方向耽误一整天。其实答案藏在你的硬件配置和使用场景里——…...

AI Agent的感知世界:多模态输入处理
AI Agent的感知世界:多模态输入处理 关键词: AI Agent、多模态感知、多模态融合、深度学习、Transformer架构、计算机视觉、自然语言处理 摘要 本文深入探讨AI Agent如何通过多模态输入处理构建对世界的全面感知。我们将从第一性原理出发,分析多模态感知的理论基础,详细解…...
)
滴水逆向 Day05:函数嵌套调用的内存布局(图文版)
0基础小白学逆向记录贴,一起来学逆向。https://mp.weixin.qq.com/s/EPDY6i2-R-WQI101KTJvtg 一、核心目标:搞懂一个函数调用另一个函数时,栈空间是怎么变化的、参数怎么传递、返回值怎么回来、ebp/esp 到底在干什么。 二、示例代码࿰…...
线下活动记录)
Google BwA 杭州场(Gemma 4 专题全国首发)线下活动记录
今天参加了Google BwA 杭州场(Gemma 4 专题全国首发)线下活动,感觉挺有意思的。这篇文章简单总结一下活动的主要内容。 关于MoE模型 本地大模型的一大问题就是运行速度慢。会上说的让我比较印象深刻的一个点就是,Gemma 4有多个版…...

王杨安企cms:批量3000个游戏下载指定链接导入方法!
我只做游戏下载站和其他管道项目,今天就简单讲解一下如何用安企cms下载站模板,批量导入几千个游戏指定下载链接!其他老站长一般都是用api接口,但是接口对于入门的新手有难度,我也是入门级的新手,所以只说入…...

极客卸载工具深度解析:6.69MB的绿色卸载神器为何备受推崇
Windows系统长期面临软件卸载不彻底的问题。 系统自带的卸载功能往往无法清除残留文件和注册表项。 这些残留数据日积月累,会严重影响系统运行效率。 极客卸载工具正是为解决这一痛点而生。 极客卸载采用绿色单文件设计模式。 整个程序解压后仅有6.69MB的体积。 这…...

PoeCharm:10个技巧让你成为流放之路角色构建大师
PoeCharm:10个技巧让你成为流放之路角色构建大师 【免费下载链接】PoeCharm Path of Building Chinese version 项目地址: https://gitcode.com/gh_mirrors/po/PoeCharm 当你在流放之路中面对复杂的角色构建时,是否曾因语言障碍而错过最佳装备组合…...

【量化实战】解码期权PCR:从情绪指标到稳健策略的构建与优化
1. 期权PCR指标的本质与市场情绪解码 第一次接触期权PCR指标时,我和大多数新手一样困惑——这个看似简单的比值背后,到底藏着什么市场秘密?经过多年实战,我发现它就像市场的"心电图",能实时反映投资者的集体…...