第三阶段第一章——PySpark实战
学习了这么多python的知识,是时候来搞点真玩意儿了~~
春风得意马蹄疾,一日看尽长安花
o(* ̄︶ ̄*)o
1.前言介绍
(1)什么是spark
Apache Spark是一个开源的分布式计算框架,用于处理大规模数据集的计算任务。它提供了一种高性能、通用、易用的计算引擎,支持数据并行处理、内存计算、迭代计算等多种计算模式,并提供了丰富的API,比如Spark SQL、Spark Streaming、Mlib和Graphx等。Spark的基本单元是弹性分布式数据集(RDD),它是一种可分区、可并行计算的数据结构,可以在多个节点上进行操作。Spark可以运行在多种集群管理器上,包括Hadoop YARN、Apache Mesos和Standalone等。Spark的特点是速度快、易用、灵活、可扩展,已经成为了数据处理和数据科学领域的一个重要工具。

(2)什么是pyspark
PySpark是指Spark的Python API,它是Spark的一部分,可以通过Python语言进行Spark编程。PySpark提供了Python与Spark之间的交互,使Python开发人员能够使用Python语言对Spark进行编程和操作。PySpark可以使用Python进行数据预处理和分析,同时扩展了Python语言的功能,能够同时使用Spark的分布式计算能力,加快了数据处理和分析的速度。与其他编程语言相比,Python在数据处理和科学计算方面有广泛的应用和支持,因此PySpark特别适合处理Python与大规模数据集交互的数据科学项目。

2.基础准备
(1)先下载 pyspark软件包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ pyspark
(2)SparkContext入口对象
初体验代码:
"""演示 """ # 导包 from pyspark import SparkConf, SparkContext# 创建sparkConf对象 conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app") # 基于SparkConf类对象创建SparkContext对象 sc = SparkContext(conf=conf) # 打印PySpark的运行版本 print(sc.version) # 停止SparkContext对象的运行(停止PySpark程序) sc.stop()

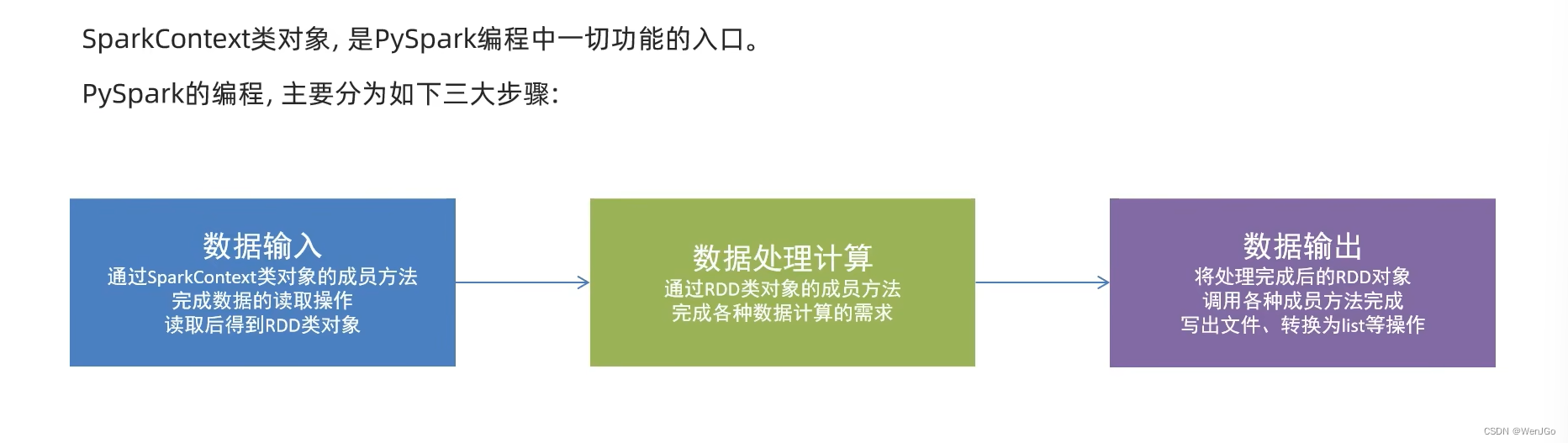
(3)PySpark编程模型
详细过程 ==>>

3.数据输入
(1)RDD对象
数据输入完成之后都会得到一个RDD对象

(2)数据容器转RDD对象
"""演示数据输入 """ from pyspark import SparkConf, SparkContextconf = SparkConf().setMaster("local[*]").setAppName("test_spark") sc = SparkContext(conf=conf)# 通过parallelize方法将Python对象加载到Spark内,成为RDD对象 rdd1 = sc.parallelize([1, 2, 3, 4, 5]) rdd2 = sc.parallelize((1, 2, 3, 4, 5)) rdd3 = sc.parallelize("abcdefg") rdd4 = sc.parallelize({1, 2, 3, 4, 5}) rdd5 = sc.parallelize({"key1": "value1", "key2": "value2"}) # 查看rdd里面的内容需要使用collect()方法 print(rdd1.collect()) print(rdd2.collect()) print(rdd3.collect()) print(rdd4.collect()) print(rdd5.collect())sc.stop()

(3)读取文件转化为RDD对象
代码示例
# 用过textFile方法,读取文件数据加载到Spark内,成为RDD对象 from pyspark import SparkConf, SparkContextconf = SparkConf().setMaster("local[*]").setAppName("test_spark") sc = SparkContext(conf=conf)rdd_file = sc.textFile("D:\\IOText\\b.txt") print(rdd_file.collect())sc.stop()

4.数据计算
pyspark是通过RDD对象内丰富的:成员方法(算子)
(1)map方法
功能:将RDD的数据一条条处理(处理的逻辑 基于map算子中接收的处理函数),返回新的RDD
语法:
代码示例
"""演示map方法 """ from pyspark import SparkConf, SparkContext import os #配置环境变量 os.environ['PYSPARK_PYTHON'] = "D:\\Python310\\dev\\python\\python3.10.4\\python.exe"conf = SparkConf().setMaster("local[*]").setAppName("map_test") sc = SparkContext(conf=conf)# 准备RDD rdd = sc.parallelize([1, 2, 3, 4, 5])# 通过map方法将全部数据都乘以10 # (T) -> U def func(data):return data * 10rdd2 = rdd.map(func) print(rdd2.collect())# 链式调用,快速解决 rdd3 = rdd.map(lambda e: e * 100).map(lambda e: e + 6) print(rdd3.collect())

(2)flatMap方法
和map差不多,多了一个消除嵌套的效果
功能:对rdd执行map操作,然后进行解除嵌套
代码示例
"""演示 flatmap 方法 """ from pyspark import SparkConf, SparkContext import os# 配置环境变量 os.environ['PYSPARK_PYTHON'] = "D:\\Python310\\dev\\python\\python3.10.4\\python.exe"conf = SparkConf().setMaster("local[*]").setAppName("flatmap_test") sc = SparkContext(conf=conf)# 准备一个RDD rdd = sc.parallelize(["a b c", "e f g", "uuu ggg"]) rdd2 = rdd.flatMap(lambda x: x.split(" ")) print(rdd2.collect())

(3)reduceByKey方法
功能:自动分组,组内聚合

代码示例
"""演示 reduceByKey 方法
"""
from pyspark import SparkConf, SparkContext
import os# 配置环境变量
os.environ['PYSPARK_PYTHON'] = "D:\\Python310\\dev\\python\\python3.10.4\\python.exe"conf = SparkConf().setMaster("local[*]").setAppName("reduceByKey_test")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([('男', 99), ('男', 88), ('女', 99), ('女', 66)])
# 求男生和呃女生两个组的成绩之和
rdd1 = rdd.reduceByKey(lambda a, b: a + b)
print(rdd1.collect())(4)练习案例1
目标,统计文件内出现单词的数量.
代码示例:
"""读取文件,统计文件内,单词出现的数量 """from pyspark import SparkConf, SparkContext import osos.environ['PYSPARK_PYTHON'] = "D:\\Python310\\dev\\python\\python3.10.4\\python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_1") sc = SparkContext(conf=conf)# 读取文件 file_rdd = sc.textFile("D:\\IOText\\b.txt")# 取出所有的单词 words = file_rdd.flatMap(lambda line: line.split(' ')) print(words.collect()) # 将其转化为map类型,value设置为1,方便在之后分组统计 word_one = words.map(lambda w: (w, 1)) # 分组求和 res = word_one.reduceByKey(lambda a, b: a + b)print(res.collect())我的文件数据是
word1
word2 word2
word3 word3 word3
word4 word4 word4 word4
(5)filter方法
功能:过滤想要的数据进行保留
filter返回值为TRUE则保留,不然会被过滤语法:
代码示例:
"""filter方法演示 """ from pyspark import SparkConf, SparkContext import osos.environ['PYSPARK_PYTHON'] = "D:\\Python310\\dev\\python\\python3.10.4\\python.exe"conf = SparkConf().setMaster("local[*]").setAppName("filter_test") sc = SparkContext(conf=conf)# 准备一个RDD rdd = sc.parallelize([1, 2, 3, 4, 5]) # filter返回值为TRUE则保留,不然会被过滤 rdd2 = rdd.filter(lambda e: e % 2 == 0) print(rdd2.collect())

(6)distinct方法
功能:对RDD数据进行去重,返回新的RDD
语法:
rdd.distinct( ) # 这里无需传参
代码示例:
"""distinct方法演示
"""
from pyspark import SparkConf, SparkContext
import osos.environ['PYSPARK_PYTHON'] = "D:\\Python310\\dev\\python\\python3.10.4\\python.exe"conf = SparkConf().setMaster("local[*]").setAppName("filter_test")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([1, 1, 2, 2, 2, 3, 4, 5])
# filter返回值为TRUE则保留,不然会被过滤
rdd2 = rdd.distinct()
print(rdd2.collect())
(7)sortBy方法
功能:对RDD数据进行排序,基于你指定的排序依据
语法:
"""sortBy方法演示 """ from pyspark import SparkConf, SparkContext import osos.environ['PYSPARK_PYTHON'] = "D:\\Python310\\dev\\python\\python3.10.4\\python.exe"conf = SparkConf().setMaster("local[*]").setAppName("filter_test") sc = SparkContext(conf=conf)# 读取文件 file_rdd = sc.textFile("D:\\IOText\\b.txt")# 取出所有的单词 words = file_rdd.flatMap(lambda line: line.split(' ')) # print(words.collect()) # 将其转化为map类型,value设置为1,方便在之后分组统计 word_one = words.map(lambda w: (w, 1)) # 分组求和 res = word_one.reduceByKey(lambda a, b: a + b) # print(res.collect()) # 按照出现次数从小到大排序 final_rdd = res.sortBy(lambda x: x[1], ascending=True, numPartitions=1) print(final_rdd.collect())

(8)练习案例2
需要的数据已经上传到博客
三个需求:
# TODO 需求一:城市销售额排名# TODO 需求2:全部城市有哪些商品类别在售卖# TODO 需求3:北京市有哪些商品类别在售卖"""sortBy方法演示 """ from pyspark import SparkConf, SparkContext import json import osos.environ['PYSPARK_PYTHON'] = "D:\\Python310\\dev\\python\\python3.10.4\\python.exe"conf = SparkConf().setMaster("local[*]").setAppName("filter_test") sc = SparkContext(conf=conf)# TODO 需求一:城市销售额排名 # 1.1 读取文件 file_rdd = sc.textFile("D:\\IOText\\orders.txt") # 1.2 取出一个个JSON字符串 json_str_rdd = file_rdd.flatMap(lambda x: x.split("|")) # 1.3 取出城市和销售额数据 dict_rdd = json_str_rdd.map(lambda x: json.loads(x)) # print(dict_rdd.collect()) # 1.4 取出城市和销售额数据 city_with_money_rdd = dict_rdd.map(lambda x: (x['areaName'], int(x['money']))) # 1.5 按城市分组按销售额聚合 city_result_rdd = city_with_money_rdd.reduceByKey(lambda a, b: a + b) # 1.6 按销售额聚合结果进行排序 result_rdd_1 = city_result_rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1) print("需求1的结果:", result_rdd_1.collect())# TODO 需求2:全部城市有哪些商品类别在售卖 # 同时记得去重 category_rdd = dict_rdd.map(lambda x: x['category']).distinct() print("需求2的结果:", category_rdd.collect())# TODO 需求3:北京市有哪些商品类别在售卖 # 3.1 只要北京市的数据 rdd_beijing = dict_rdd.filter(lambda x: x["areaName"] == "北京") # 3.2 取出全部商品类别并且去重 result_rdd_3 = rdd_beijing.map(lambda x: x['category']).distinct() print("需求3的结果:", result_rdd_3.collect())
5.数据输出
(1)输出为Python对象:collect算子
功能:将RDD各个分区内的数据,统一手机到Driver中,形成一个List对象
用法:
rdd.collect( ) # 返回值是一个list
(2)输出为Python对象:reduce算子
功能:对RDD数据集按照你传入的逻辑进行聚合
语法:

(3)输出为Python对象:take算子
功能:取RDD的前N个元素,组合成list返回给你
语法:

(4)输出为Python对象:count算子
功能:计算RDD有多少条数据,返回值是一个数字
语法:

(5)上述1-4算子代码示例
"""collect算子
"""from pyspark import SparkConf, SparkContext
import osos.environ['PYSPARK_PYTHON'] = "D:\\Python310\\dev\\python\\python3.10.4\\python.exe"conf = SparkConf().setMaster("local[*]").setAppName("filter_test")
sc = SparkContext(conf=conf)# 准备RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])# collect算子,输出RDD为list对象
rdd_list: list = rdd.collect()
print(type(rdd_list))
print(rdd_list)# reduce算子,对RDD进行两两聚合
num = rdd.reduce(lambda a, b: a + b)
print(num)# take算子,取出RDD前N个元素,组成list返回
take_list_3 = rdd.take(3)
print(take_list_3)# count算子,统计rdd内有多少条数据,返回值为数字
num_count = rdd.count()
print(f"有{num_count}个元素")
(6)输出到文件中:saveAsTextFile算子
功能:将RDD的数据写入文本文件中
支持 本地写出,hdfs等文件系统
语法:

注意事项:

代码示例:
"""saveAsTextFile
"""from pyspark import SparkConf, SparkContext
import osos.environ['PYSPARK_PYTHON'] = "D:\\Python310\\dev\\python\\python3.10.4\\python.exe"
os.environ['HADOOP_HOME'] = "D:\\CodeSoft\\Hadoop\\hadoop-3.0.0"conf = SparkConf().setMaster("local[*]").setAppName("filter_test")
sc = SparkContext(conf=conf)# 准备RDD1
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
# 准备RDD2
rdd2 = sc.parallelize([("hello", 3), ("spark", 5), ("java", 7)])
# 准备RDD3
rdd3 = sc.parallelize([[1, 3, 5], [6, 7, 9], [11, 13, 11]])# 输出到文件之中
rdd1.saveAsTextFile("D:\\IOText\\saveAsTextFile测试1")
rdd2.saveAsTextFile("D:\\IOText\\saveAsTextFile测试2")
rdd3.saveAsTextFile("D:\\IOText\\saveAsTextFile测试3")上述方法会使文件内有对应你CPU核心数量的分区
修改RDD分区为1个
方式一:SparkConf对象设置属性为全局并行度为1

方式二:创建RDD的时候设置(parallelize方法传入numSlices的参数为1)

6.综合案例
搜索引擎日志分析

实现代码:
"""综合案例
"""from pyspark import SparkConf, SparkContext
import os
import jsonos.environ['PYSPARK_PYTHON'] = "D:\\Python310\\dev\\python\\python3.10.4\\python.exe"
os.environ['HADOOP_HOME'] = "D:\\CodeSoft\\Hadoop\\hadoop-3.0.0"conf = SparkConf().setMaster("local[*]").setAppName("filter_test")
conf.set("spark.default.parallelism", "1")
conf.set("spark.default.parallelism", "1")
sc = SparkContext(conf=conf)# 读取文件转换成RDD
file_rdd = sc.textFile("D:\\IOText\\search_log.txt")# TODO 需求一:热门搜索时间段Top3(小时精度)
# 1.1 取出全部的时间并且转换为小时
# 1.2 转换为(小时,1)的二元组
# 1.3 key分组聚合value
# 1.4 排序(降序)
# 1.5 取前三
res1 = (file_rdd.map(lambda x: (x.split("\t")[0][:2], 1)).reduceByKey(lambda a, b: a + b).sortBy(lambda x: x[1], ascending=False, numPartitions=1).take(3))
print(f"需求一的结果:{res1}")# TODO 需求二:热门搜索词Top3
# 2.1 取出全部的搜索词
# 2.2 (词,1)二元组
# 2.3 分组聚合
# 2.4 排序
# 2.5 top3
res2 = (file_rdd.map(lambda x: (x.split("\t")[2], 1)).reduceByKey(lambda a, b: a + b).sortBy(lambda x: x[1], ascending=False, numPartitions=1).take(3))
print(f"需求二的结果:{res2}")# TODO 需求三:统计黑马程序员关键字在什么时间段被搜索的最多
# 3.1 过滤内容,只保留黑马程序员关键词
# 3.2 转换为(小时,1)的二元组
# 3.3 分组聚合
# 3.4 排序
# 3.5 取前一
res3 = (file_rdd.map(lambda x: x.split("\t")).filter(lambda x: x[2] == "黑马程序员").map(lambda x: (x[0][:2], 1)).reduceByKey(lambda a, b: a + b).sortBy(lambda x: x[1], ascending=False, numPartitions=1).take(1))
print(f"需求三的结果:{res3}")# TODO 需求四:将数据转化为JSON格式,写出到文件之中
# 4.1 转换为JSON格式的RDD
# 4.2 写出为文件
(file_rdd.map(lambda x: x.split("\t")).map(lambda x: {"time": x[0],"user_id": x[1],"key_word": x[2],"rank1": x[3],"rank2": x[4],"url": x[5]}).saveAsTextFile("D:\\IOText\\综合案例"))
结语
有啥好说的。呃呃呃呃呃呃呃没啥好说的
下班
┏(^0^)┛
相关文章:
第三阶段第一章——PySpark实战
学习了这么多python的知识,是时候来搞点真玩意儿了~~ 春风得意马蹄疾,一日看尽长安花 o(* ̄︶ ̄*)o 1.前言介绍 (1)什么是spark Apache Spark是一个开源的分布式计算框架,用于处理大规模数据集的…...
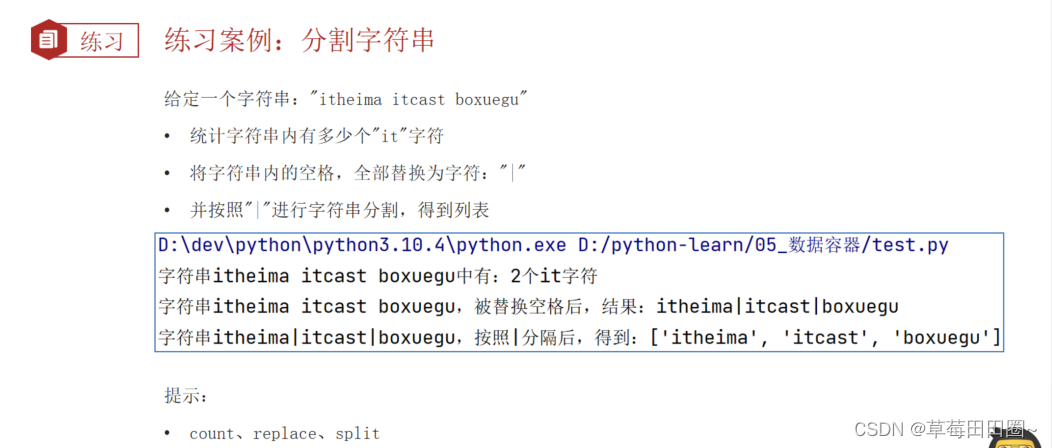
Python数据容器(字符串)
字符串 1.字符串 字符串也是数据容器的一种,字符串是字符的容器,一个字符串可以存放任意数量的字符。 2.字符串的下标索引 从前向后,下标从0开始从后向前,下标从-1开始 # 通过下标索引获取特定位置的字符 name python print(na…...
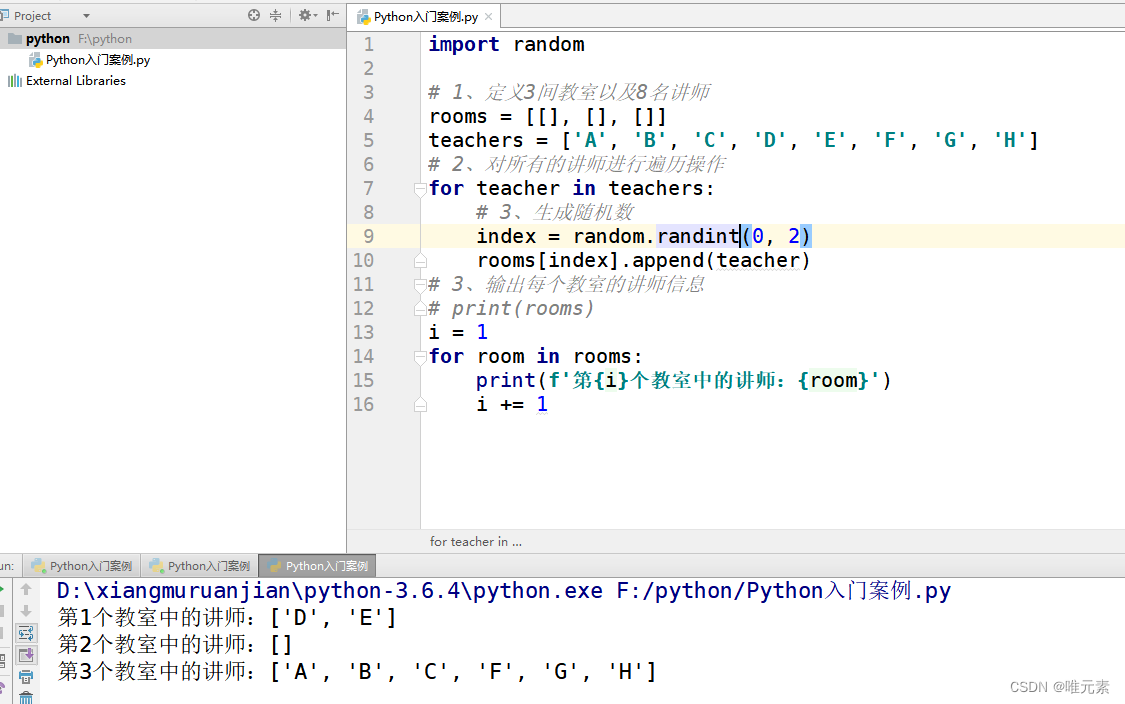
Python---练习:把8名讲师随机分配到3个教室
案例:把8名讲师随机分配到3个教室 列表嵌套:有3个教室[[],[],[]],8名讲师[A,B,C,D,E,F,G,H],将8名讲师随机分配到3个教室中。 分析: 思考1:我们第一间教室、第二间教室、第三间教室,怎么表示…...
python+requests接口自动化测试
原来的web页面功能测试转变成接口测试,之前大多都是手工进行,利用postman和jmeter进行的接口测试,后来,组内有人讲原先web自动化的测试框架移驾成接口的自动化框架,使用的是java语言,但对于一个学java&…...
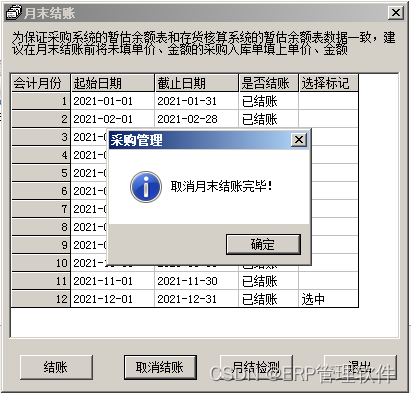
【T3】畅捷通T3采购管理模块反结账,提示:本年数据已经结转,不能取消结账。
【问题描述】 使用畅捷通T3软件过程中, 针对以前年度进行反结账过程中,遇到采购管理模块取消12月份结账, 提示:本年数据已经结转,不能取消结账。 【分析需求】 按正常逻辑,需要清空新年度数据,…...

线性代数(五) | 矩阵对角化 特征值 特征向量
文章目录 1 矩阵的特征值和特征向量究竟是什么?2 求特征值和特征向量3 特征值和特征向量的应用4 矩阵的对角化 1 矩阵的特征值和特征向量究竟是什么? 矩阵实际上是一种变换,是一种旋转伸缩变换(方阵) 不是方阵的话还有可能是一种…...

读书笔记:彼得·德鲁克《认识管理》第12章 服务机构的绩效管理
一、章节内容概述 要提高服务机构和服务部门的绩效水平,需要的不是天才,相反,首先需要的是清晰的目标和任务,其次是把资源集中用于优先事项,再次需要明确的成果衡量标准,最后需要系统性地抛弃过时的目标和…...

基于FPGA的模板匹配红外目标跟踪算法设计
为什么要写这篇文章 我写这篇文章的原因是一天在B站看到了一个大神发的视频是关于跟踪一个无人机的,看到作者跟网友的回复说是用的图像匹配算法,我就在网上搜索相关资料,最终找到一篇文献。文献中对该算法的评价很高,满足制导系统…...
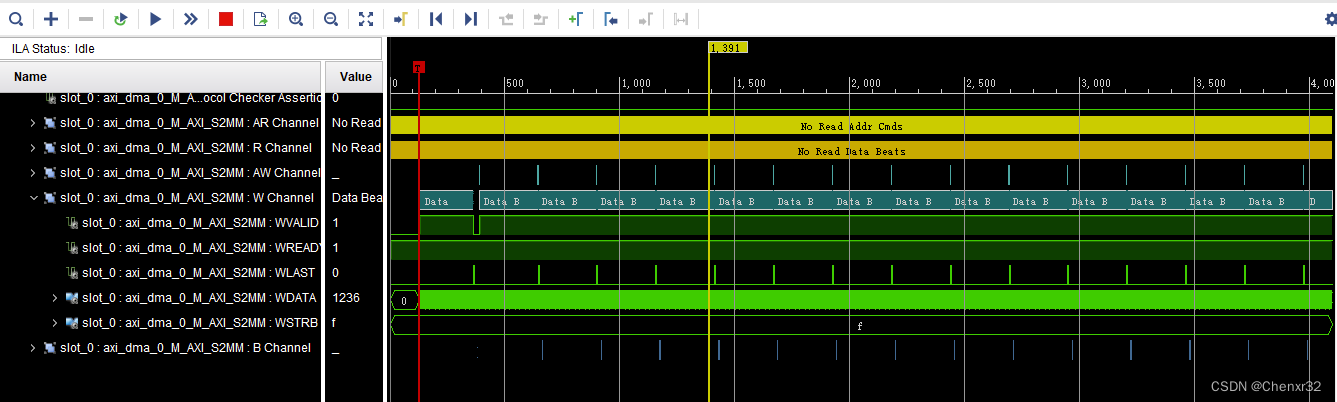
ZYNQ通过AXI DMA实现PL发送连续大量数据到PS DDR
硬件:ZYNQ7100 软件:Vivado 2017.4、Xilinx SDK 2017.4 ZYNQ PL 和 PS 的通信方式有 AXI GPIO、BRAM、DDR等。对于数据量较少、地址不连续、长度规则的情况,BROM 比较适用。而对于传输速度要求高、数据量大、地址连续的情况,比…...

用于强化学习的置换不变神经网络
一、介绍 如果强化学习代理提供的输入在训练中未明确定义,则通常表现不佳。一种新方法使 RL 代理能够正常运行,即使受到损坏、不完整或混乱的输入的影响也是如此。 “大脑能够使用来自皮肤的信息,就好像它来自眼睛一样。我们不是用眼睛看&…...

【华为OD题库-008】座位调整-Java
题目 疫情期间课堂的座位进行了特殊的调整,不能出现两个同学紧挨着,必须隔至少一个空位。给你一个整数数组desk表示当前座位的占座情况,由若干0和1组成,其中0表示没有占位,1表示占位。在不改变原有座位秩序情况下&…...

4 Paimon数据湖之Hive Catalog的使用
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html Paimon提供了两种类型的Catalog:Filesystem Catalog和Hive Catalog。 Filesystem Catalog:会把元数据信息存储到文件系统里面。Hive Catalog:则会把元数据…...

Verilog刷题[hdlbits] :Bcdadd100
题目:Bcdadd100 You are provided with a BCD one-digit adder named bcd_fadd that adds two BCD digits and carry-in, and produces a sum and carry-out. 为您提供了一个名为bcd_fadd的BCD一位数加法器,它将两个BCD数字相加并带入,并生…...
Flink—— Data Source 介绍
Data Source 简介 Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来ÿ…...
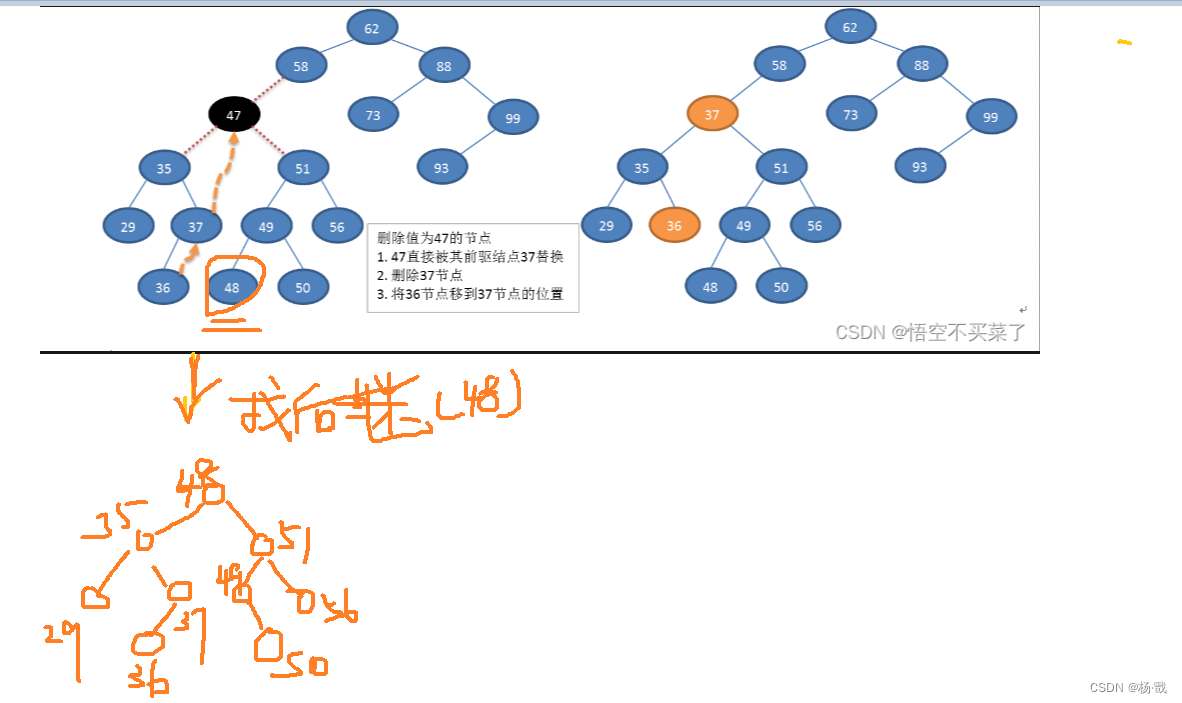
树之二叉排序树(二叉搜索树)
什么是排序树 说一下普通二叉树可不是左小右大的 插入的新节点是以叶子形式进行插入的 二叉排序树的中序遍历结果是一个升序的序列 下面是两个典型的二叉排序树 二叉排序树的操作 构造树的过程即是对无序序列进行排序的过程。 存储结构 通常采用二叉链表作为存储结构 不能 …...
管易云与电商平台的无代码集成:实现API连接与用户运营
管易云简介及其与电商平台的合作 金蝶管易云是金蝶集团旗下以电商为核心业务的子公司,是国内最早的电商ERP服务商之一,总部在上海,与淘宝、天猫、 京东、拼多多、抖音等300多家主流电商平台建立合作关系,同时管易云是互联网平台首…...
)
ElementUI的el-upload上传组件与表单一起提交遇到的各种问题以及解决办法(超详细,每个步骤都有详细解读)
背景: 使用ruoyi-vue进行2次开发,需要实现表单与文件上传一起提交,并且文件上传有4个,且文件校验很复杂,因此ruoyi-vue集成的上传组件FileUpload调试几天后发现真不太适用,最终选择element UI原生组件el-upload(FileUpload也是基于el-upload实现的),要实现表单与文件同…...

python flask_restful “message“: “Failed to decode JSON object: None“
1、问题表现 "message": "Failed to decode JSON object: None"2、出现的原因 Werkzeug 版本过高 3、解决方案 pip install Werkzeug2.0解决效果 可以正常显示json数据了 {"message": {"rate": "参数错误"} }...
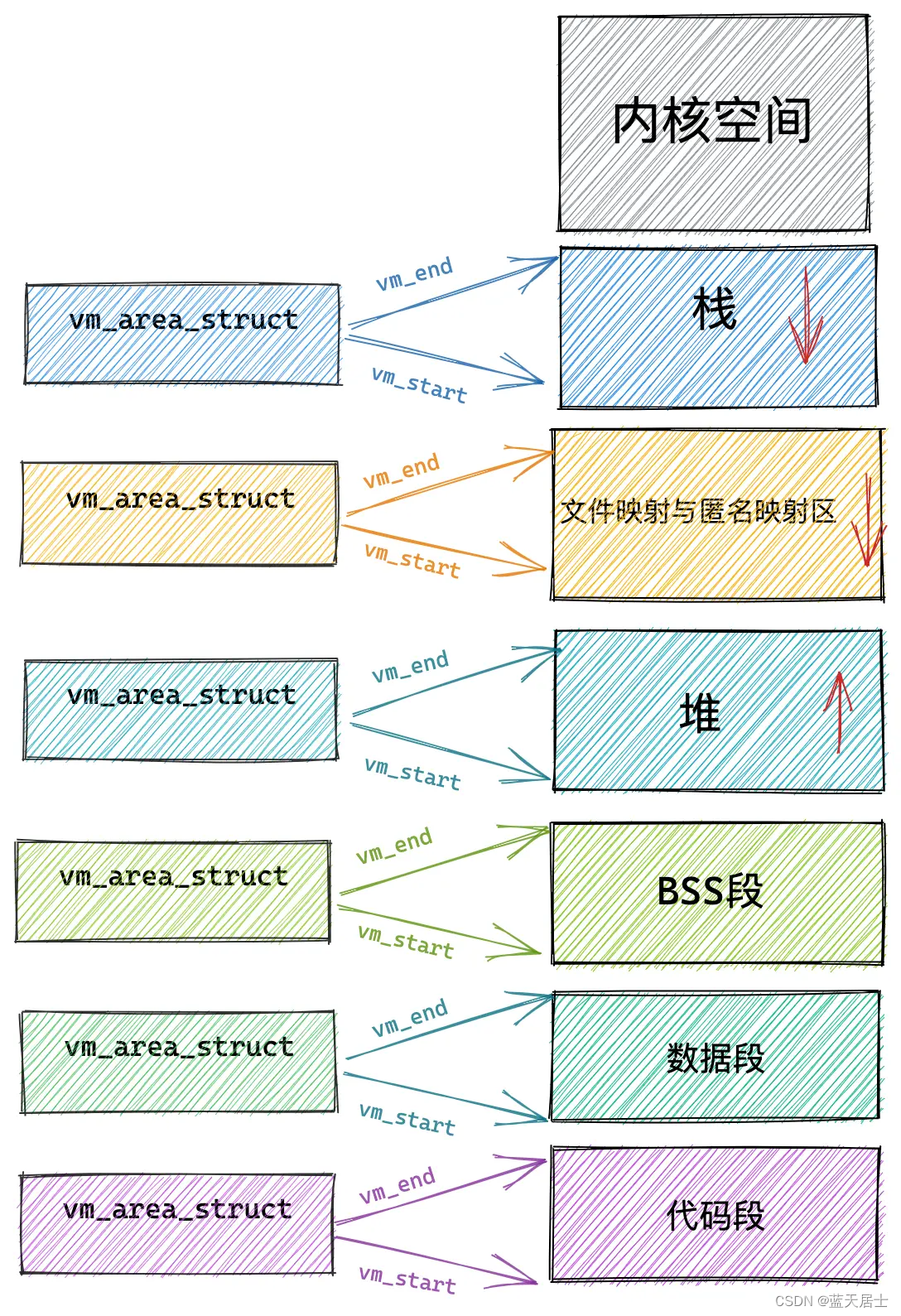
Linux内核有什么之内存管理子系统有什么第六回 —— 小内存分配(4)
接前一篇文章:Linux内核有什么之内存管理子系统有什么第五回 —— 小内存分配(3) 本文内容参考: linux进程虚拟地址空间 《趣谈Linux操作系统 核心原理篇:第四部分 内存管理—— 刘超》 特此致谢! 二、小…...
)
【OpenHarmony内核】Harmony内核之线程操作函数(二)
文章目录 前言一、获取线程优先级二、转交控制运行权三、挂起线程3.1 线程的挂起是什么意思?3.2 函数介绍四、恢复线程五、分离指定的线程5.1 分离线程是什么意思5.2 函数介绍六、等待线程终止运行七、终止当前线程的运行八、终止指定线程的运行九、获取活跃线程数总结前言 O…...

MiniJinja过滤器大全:内置与自定义过滤器的深度解析
MiniJinja过滤器大全:内置与自定义过滤器的深度解析 【免费下载链接】minijinja MiniJinja is a powerful but minimal dependency template engine for Rust compatible with Jinja/Jinja2 项目地址: https://gitcode.com/gh_mirrors/mi/minijinja MiniJinj…...

如何快速下载Steam游戏清单:Onekey一键获取Depot Manifest完整指南
如何快速下载Steam游戏清单:Onekey一键获取Depot Manifest完整指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey Onekey是一款专为Steam平台设计的Depot Manifest下载器࿰…...
)
Claude读论文系列(十)
精读笔记:CoDe-R CoDe-R: Refining Decompiler Output with LLMs via Rationale Guidance and Adaptive Inference arXiv: 2604.12913 | cs.SE / cs.AI / cs.CR 会议:IJCNN 2026(已收录) 机构:未标注(第一作…...

模块解耦的重要性
**模块解耦为什么如此重要? 1. 开发效率提升:清晰的模块边界让团队并行开发互不干扰; 2. 维护成本降低:bug修复和功能迭代的影响范围可控; 3. 代码复用性强:通用模块可在多个项目间复用; 4. 测试…...

从PointNet到PointNeXt:为什么‘共享’MLP是点云模型设计的基石?
从PointNet到PointNeXt:为什么‘共享’MLP是点云模型设计的基石? 点云数据处理一直是计算机视觉和三维感知领域的核心挑战之一。不同于规整的二维图像像素排列,点云数据具有无序性、非均匀性和稀疏性三大特征,这使得传统卷积神经网…...

SVGSON:企业级SVG-JSON双向转换解决方案助力生产就绪的图形数据处理
SVGSON:企业级SVG-JSON双向转换解决方案助力生产就绪的图形数据处理 【免费下载链接】svgson Transform svg files to json notation 项目地址: https://gitcode.com/gh_mirrors/sv/svgson 如何解决SVG图形在程序化处理和存储中的格式转换挑战 问题导向&am…...

Universal x86 Tuning Utility:解锁被封印的硬件潜能,你的电脑比你想象的更强大
Universal x86 Tuning Utility:解锁被封印的硬件潜能,你的电脑比你想象的更强大 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-…...

如何快速扩展Connexion框架功能:插件开发的完整指南
如何快速扩展Connexion框架功能:插件开发的完整指南 【免费下载链接】connexion Connexion is a modern Python web framework that makes spec-first and api-first development easy. 项目地址: https://gitcode.com/gh_mirrors/co/connexion Connexion是一…...
)
告别臃肿文档!用Spire.Doc for Python生成Word文件,体积直接减半(附对比Python-docx代码)
Python文档生成革命:Spire.Doc如何实现Word文件体积减半 在自动化办公和批量文档处理的场景中,Python开发者经常面临一个棘手问题——生成的Word文件体积异常臃肿。当使用流行的python-docx库创建一个仅含"Hello, World!"的文档时,…...

【CKF与RTS,MATLAB例程】二维非线性目标跟踪,观测为距离+角度,滤波使用容积卡尔曼滤波,附加RTS平滑,获得高精度定位。附代码下载链接
通过模拟二维平面下目标的运动模型与传感器的距离/方位/俯仰观测,利用容积卡尔曼滤波(CKF)进行前向状态估计,并结合RTS算法进行后向平滑优化,最终对比可视化三者的轨迹与定位精度 原创代码,包运行成功。请勿…...