4 Paimon数据湖之Hive Catalog的使用
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html
Paimon提供了两种类型的Catalog:Filesystem Catalog和Hive Catalog。
- Filesystem Catalog:会把元数据信息存储到文件系统里面。
- Hive Catalog:则会把元数据信息存储到Hive的Metastore里面,这样就可以直接在Hive中访问Paimon表了。注意:此时也会同时在文件系统中存储一份元数据信息,相当于元数据会存储两份,这个大家需要特别注意一下。
还有就是我们在使用Hive Catalog的时候,Paimon中的数据库名称、表名称,以及字段名称都要小写,因为这些数据存储到Hive Metastore的时候,会统一存储为小写。
下面我们来具体演示一下Paimon如何使用Hive Catalog来存储元数据。
在Flink中操作Paimon的时候想要使用Hive Catalog,需要依赖于Flink Hive connector,以及hive-exec和flink-table-api-scala-bridge。
flink-table-api-scala-bridge这个依赖我们之前已经添加过了,所以只需要添加另外两个即可:
<!-- flink-hive-connector -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_2.12</artifactId><version>1.15.0</version><!--<scope>provided</scope>-->
</dependency>
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version><exclusions><exclusion><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId></exclusion></exclusions><!--<scope>provided</scope>-->
</dependency>
创建package:tech.xuwei.paimon.catalog
创建object:PaimonHiveCatalog
代码如下:
package tech.xuwei.paimon.catalogimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** Paimon使用Hive Catalog* Created by xuwei*/
object PaimonHiveCatalog {def main(args: Array[String]): Unit = {//创建执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setRuntimeMode(RuntimeExecutionMode.STREAMING)val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的Catalog--使用Hive CatalogtEnv.executeSql("""|CREATE CATALOG paimon_hive_catalog WITH(| 'type'='paimon',| 'metastore' = 'hive',| 'uri' = 'thrift://bigdata04:9083',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_hive_catalog")//创建Paimon表tEnv.executeSql("""|CREATE TABLE IF NOT EXISTS p_h_t1(| name STRING,| age INT,| PRIMARY KEY (name) NOT ENFORCED|)|""".stripMargin)//向表中插入数据tEnv.executeSql("""|INSERT INTO p_h_t1(name,age) VALUES('jack',18),('tom',20)|""".stripMargin)}}
接下来到bigdata04节点上启动hive的metastore服务。
[root@bigdata04 ~]# cd /data/soft/apache-hive-3.1.2-bin/
[root@bigdata04 apache-hive-3.1.2-bin]# nohup bin/hive --service metastore -p 9083 2>&1 >/dev/null &
然后运行代码PaimonHiveCatalog
代码运行之后可以到先到hdfs中确认一下是否能看到元数据信息:
[root@bigdata04 ~]# hdfs dfs -cat /paimon/default.db/p_h_t1/schema/schema-0
{"id" : 0,"fields" : [ {"id" : 0,"name" : "name","type" : "STRING NOT NULL"}, {"id" : 1,"name" : "age","type" : "INT"} ],"highestFieldId" : 1,"partitionKeys" : [ ],"primaryKeys" : [ "name" ],"options" : { }
可以发现,在hdfs中依然是可以看到的,因为我们前面说了,使用hive catalog时也会同时在hdfs中存储一份元数据。
最后我们到hive中确认一下:
注意:由于目前bigdata04节点的环境变量中有HADOOP_CLASSPATH,所以直接使用hive客户端会看到很多日志信息,所以建议使用hive的beeline客户端。
此时需要先启动hiveserver2服务。
[root@bigdata04 ~]# cd /data/soft/apache-hive-3.1.2-bin/
[root@bigdata04 apache-hive-3.1.2-bin]# bin/hiveserver2
使用beeline客户端进行连接
[root@bigdata04 apache-hive-3.1.2-bin]# bin/beeline -u jdbc:hive2://localhost:10000 -n root
0: jdbc:hive2://localhost:10000> show tables;
+--------------------+
| tab_name |
+--------------------+
| flink_stu |
| orders |
| p_h_t1 |
| s1 |
| student_favors |
| student_favors_2 |
| student_score |
| student_score_bak |
| t1 |
+--------------------+
9 rows selected (1.727 seconds)
0: jdbc:hive2://localhost:10000> select * from p_h_t1;
Error: Error while compiling statement: FAILED: RuntimeException java.lang.ClassNotFoundException: org.apache.paimon.hive.mapred.PaimonInputFormat (state=42000,code=40000)
此时是可以在hive中查看到p_h_t1这个表的,但是在操作这个表的时候会报错,提示缺少依赖,现在报这个错是正常的,等后面我们会有一个单独的小节来讲Paimon和Hive引擎的集成。
目前通过hive catalog可以将paimon的元数据同时存储到hive的metastore中,但是还无法在hive中操作paimon的表,其实主要是因为缺少一个依赖,在这大家先知道这个问题即可。
注意:如果我们此时操作的是分区表,那么分区信息默认是无法同步到Hive Metastore的。
也就是说默认情况下,Paimon不会将新创建的分区同步到Hive Metastore中。我们在Hive中只能看到一个未分区的普通表。
如果想解决这个问题,也很简单,只需要在paimon的表属性中设置metastore.partitioned-table=true即可。
下面开发一个案例:
创建object:PaimonHiveCatalogPartitionTable,基于PaimonHiveCatalog进行复制。
完整代码如下:
package tech.xuwei.paimon.catalogimport org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** Paimon使用Hive Catalog* 操作分区表* Created by xuwei*/
object PaimonHiveCatalogPartitionTable {def main(args: Array[String]): Unit = {//创建执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setRuntimeMode(RuntimeExecutionMode.STREAMING)val tEnv = StreamTableEnvironment.create(env)//创建Paimon类型的Catalog--使用Hive CatalogtEnv.executeSql("""|CREATE CATALOG paimon_hive_catalog WITH(| 'type'='paimon',| 'metastore' = 'hive',| 'uri' = 'thrift://bigdata04:9083',| 'warehouse'='hdfs://bigdata01:9000/paimon'|)|""".stripMargin)tEnv.executeSql("USE CATALOG paimon_hive_catalog")//创建Paimon表tEnv.executeSql("""|CREATE TABLE IF NOT EXISTS p_h_par(| id INT,| name STRING,| dt STRING,| PRIMARY KEY (id, dt) NOT ENFORCED|) PARTITIONED BY (dt) WITH(| 'metastore.partitioned-table' = 'true'|)|""".stripMargin)//向表中插入数据tEnv.executeSql("""|INSERT INTO p_h_par(id,name,dt)|VALUES(1,'jack','20230101'),(2,'tom','20230102')|""".stripMargin)}}
在idea中执行代码。
然后到hive中进行验证,可以执行show partitions p_h_par;进行验证。
或者到hive metastore里面进行确认,查看mysql中的partitions表,这个表里面存储的是分区信息,如果能看到分区信息,就说明Paimon表的分区信息同步过来了。

这样就说明Paimon表的分区信息同步过来了。
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html
相关文章:
4 Paimon数据湖之Hive Catalog的使用
更多Paimon数据湖内容请关注:https://edu.51cto.com/course/35051.html Paimon提供了两种类型的Catalog:Filesystem Catalog和Hive Catalog。 Filesystem Catalog:会把元数据信息存储到文件系统里面。Hive Catalog:则会把元数据…...

Verilog刷题[hdlbits] :Bcdadd100
题目:Bcdadd100 You are provided with a BCD one-digit adder named bcd_fadd that adds two BCD digits and carry-in, and produces a sum and carry-out. 为您提供了一个名为bcd_fadd的BCD一位数加法器,它将两个BCD数字相加并带入,并生…...
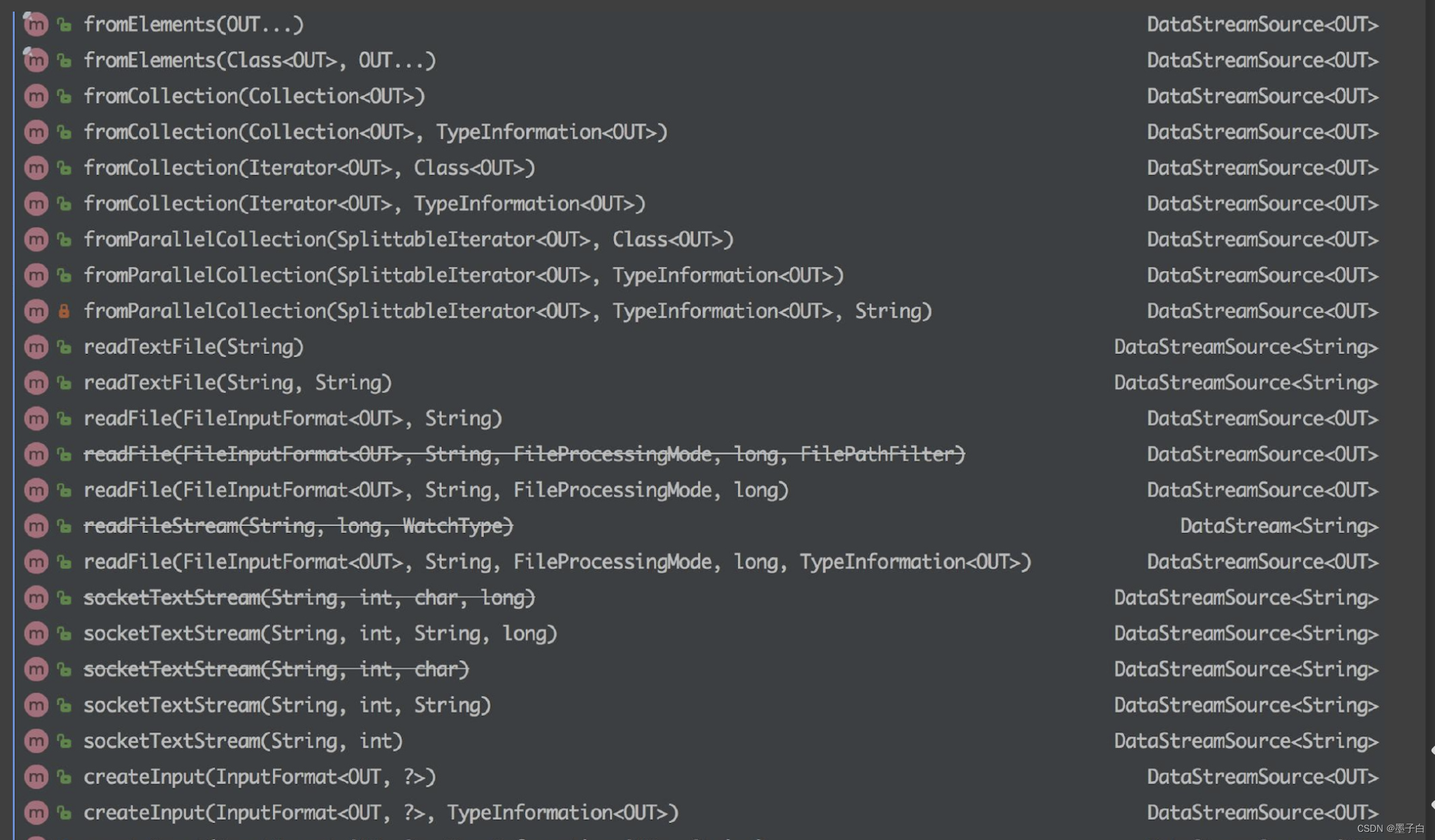
Flink—— Data Source 介绍
Data Source 简介 Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来ÿ…...
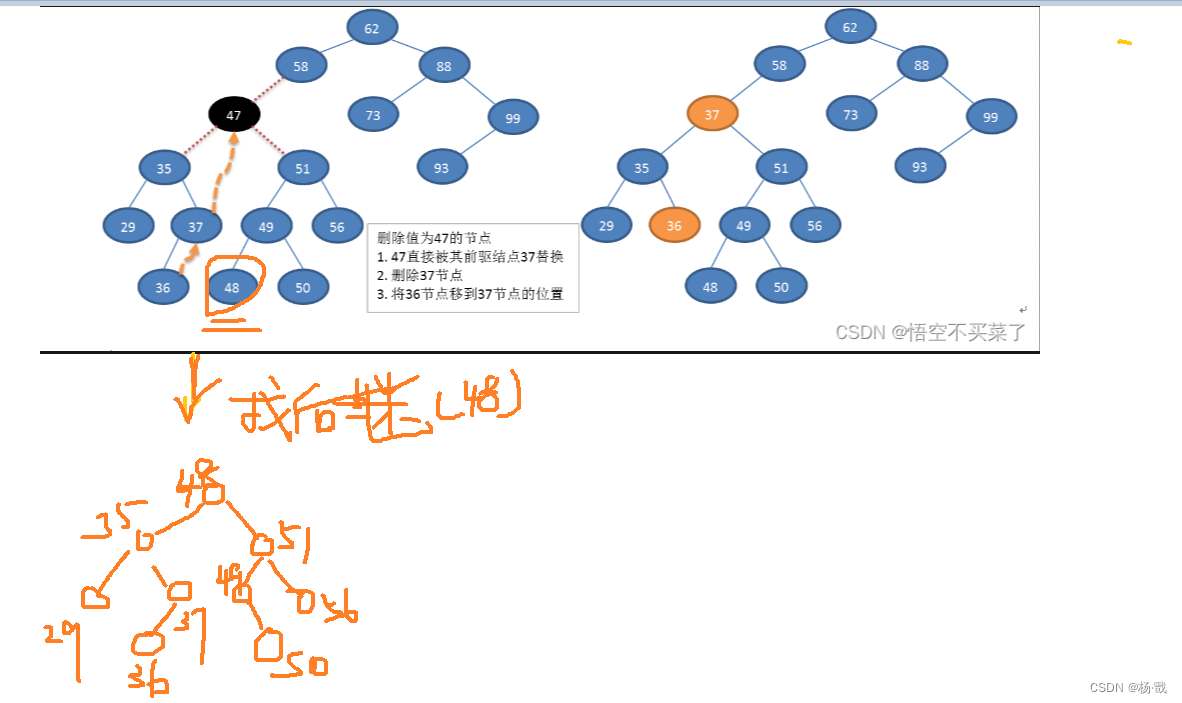
树之二叉排序树(二叉搜索树)
什么是排序树 说一下普通二叉树可不是左小右大的 插入的新节点是以叶子形式进行插入的 二叉排序树的中序遍历结果是一个升序的序列 下面是两个典型的二叉排序树 二叉排序树的操作 构造树的过程即是对无序序列进行排序的过程。 存储结构 通常采用二叉链表作为存储结构 不能 …...
管易云与电商平台的无代码集成:实现API连接与用户运营
管易云简介及其与电商平台的合作 金蝶管易云是金蝶集团旗下以电商为核心业务的子公司,是国内最早的电商ERP服务商之一,总部在上海,与淘宝、天猫、 京东、拼多多、抖音等300多家主流电商平台建立合作关系,同时管易云是互联网平台首…...
)
ElementUI的el-upload上传组件与表单一起提交遇到的各种问题以及解决办法(超详细,每个步骤都有详细解读)
背景: 使用ruoyi-vue进行2次开发,需要实现表单与文件上传一起提交,并且文件上传有4个,且文件校验很复杂,因此ruoyi-vue集成的上传组件FileUpload调试几天后发现真不太适用,最终选择element UI原生组件el-upload(FileUpload也是基于el-upload实现的),要实现表单与文件同…...

python flask_restful “message“: “Failed to decode JSON object: None“
1、问题表现 "message": "Failed to decode JSON object: None"2、出现的原因 Werkzeug 版本过高 3、解决方案 pip install Werkzeug2.0解决效果 可以正常显示json数据了 {"message": {"rate": "参数错误"} }...
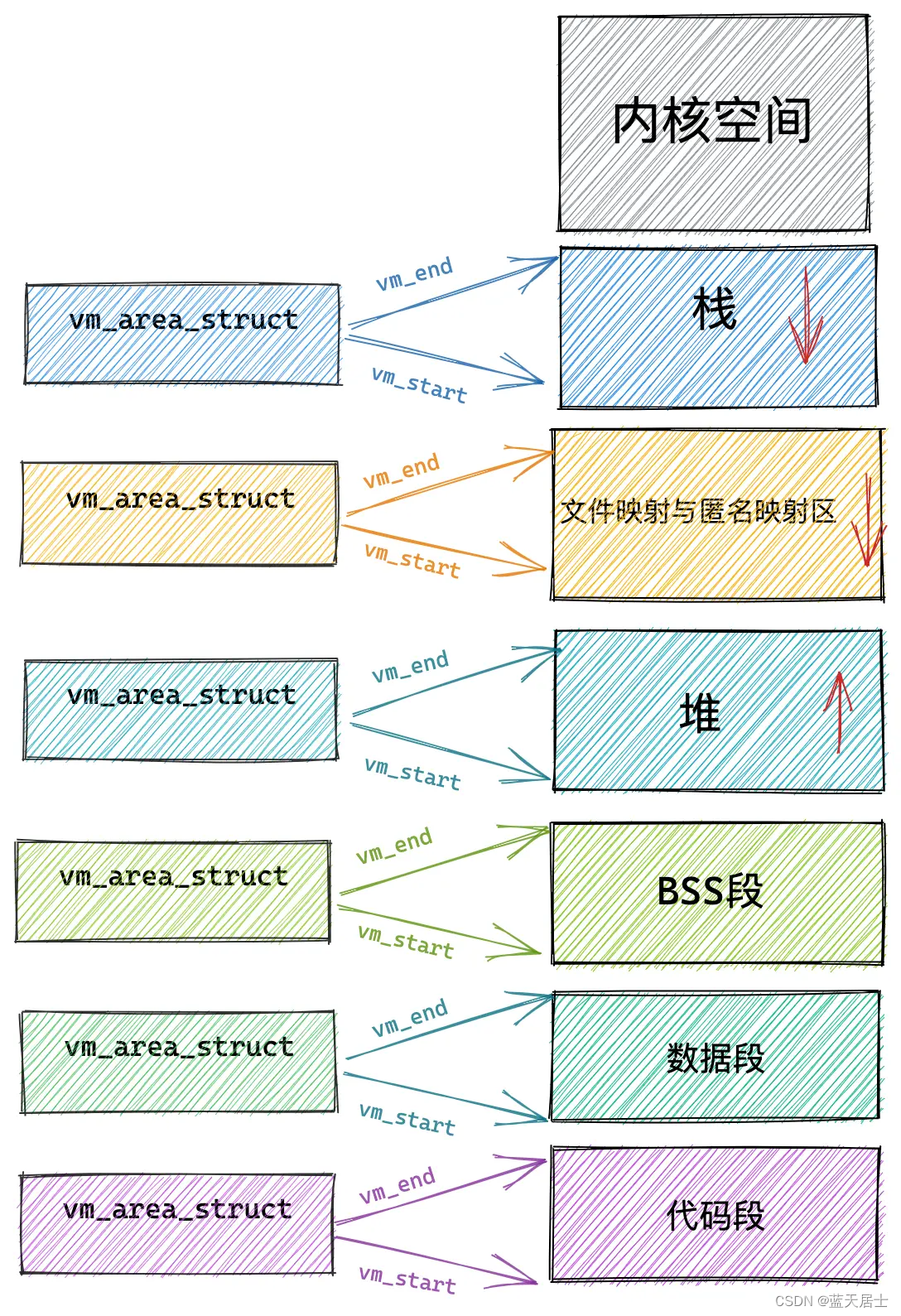
Linux内核有什么之内存管理子系统有什么第六回 —— 小内存分配(4)
接前一篇文章:Linux内核有什么之内存管理子系统有什么第五回 —— 小内存分配(3) 本文内容参考: linux进程虚拟地址空间 《趣谈Linux操作系统 核心原理篇:第四部分 内存管理—— 刘超》 特此致谢! 二、小…...
)
【OpenHarmony内核】Harmony内核之线程操作函数(二)
文章目录 前言一、获取线程优先级二、转交控制运行权三、挂起线程3.1 线程的挂起是什么意思?3.2 函数介绍四、恢复线程五、分离指定的线程5.1 分离线程是什么意思5.2 函数介绍六、等待线程终止运行七、终止当前线程的运行八、终止指定线程的运行九、获取活跃线程数总结前言 O…...

二十五、W5100S/W5500+RP2040树莓派Pico<Modebus TCP Server示例>
文章目录 1 前言2 简介2 .1 什么是Modbus TCP?2.2 Modbus TCP指令介绍2.3 请求数据过程2.4 Modbus TCP协议优点2.5 Modbus TCP应用场景 3 WIZnet以太网芯片4 Modbus TCP示例概述以及使用4.1 流程图4.2 准备工作核心4.3 连接方式4.4 主要代码概述4.5 结果演示 5 注意…...

Android画个圆点状态灯
1、创建一个 XML 文件在 res/drawable 目录下(默认为黑色) <?xml version"1.0" encoding"utf-8"?> <shape xmlns:android"http://schemas.android.com/apk/res/android"android:shape"oval"><…...

高性能网络编程 - 解读3种线程模型
文章目录 Pre线程模型1:传统阻塞 I/O 服务模型线程模型2:Reactor 模式Reactor 模式的基本设计思想Reactor 模式中的关键组成3种典型实现单 Reactor 单线程单 Reactor 多线程主从 Reactor 多线程 小结 线程模型3:Proactor 模型 Pre 高性能网络…...
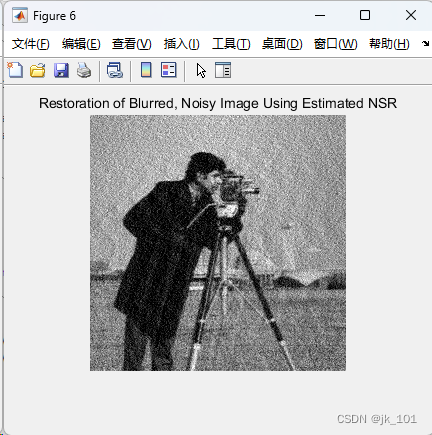
MATLAB中deconvwnr函数用法
目录 语法 说明 示例 使用 Wiener 滤波对图像进行去模糊处理 deconvwnr函数的功能是使用 Wiener 滤波对图像进行去模糊处理。 语法 J deconvwnr(I,psf,nsr) J deconvwnr(I,psf,ncorr,icorr) J deconvwnr(I,psf) 说明 J deconvwnr(I,psf,nsr) 使用 Wiener 滤波算法对…...

赛宁网安入选国家工业信息安全漏洞库(CICSVD)2023年度技术组成员单
近日,由国家工业信息安全发展研究中心、工业信息安全产业发展联盟主办的“2023工业信息安全大会”在北京成功举行。 会上,国家工业信息安全发展研究中心对为国家工业信息安全漏洞库(CICSVD)提供技术支持的单位授牌表彰。北京赛宁…...

Git系列之Git集成开发工具及git扩展使用
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是君易--鑨,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的博客专栏《Git实战开发》。🎯🎯 &a…...

selenium headless 无头模式慢
selenium设置headlessTrue发现非常慢,headlessFalse要快很多。 最后测试发现升级到selenium最新版本,selenium4.15.2。设置--headlessnew,解决了,速度正常了。 新版selenium有了两种headless模式,参见:He…...
快速修复因相机断电导致视频文件打不开的问题
3-5 本文主要解决因相机突然断电导致拍摄的视频文件打不开的问题。 在日常工作中,有时候需要使用相机拍摄视频,比如现在有不少短视频拍摄的需求,如果因电池突然断电的原因,导致拍出来的视频播放不了,这时候就容易出大…...

Ceph 笔记, ssh写入缓存
硬件建议 — Ceph 文档 写入缓存 企业级 SSD 和 HDD 通常包括断电保护功能,包括 在运行时断电时确保数据耐久性,以及 使用多级缓存来加快直接或同步写入速度。这些设备 可以在两种缓存模式之间切换 -- 刷新到的易失性缓存 具有 fsync 的持久性媒体&a…...
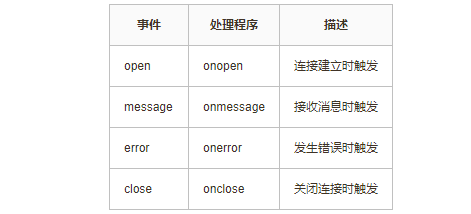
WebSocket魔法师:打造实时应用的无限可能
1、背景 在开发一些前端页面的时候,总是能接收到这样的需求:如何保持页面并实现自动更新数据呢?以往的常规做法,是前端使用定时轮询后端接口,获取响应后重新渲染前端页面,这种做法虽然能达到类似的效果&…...
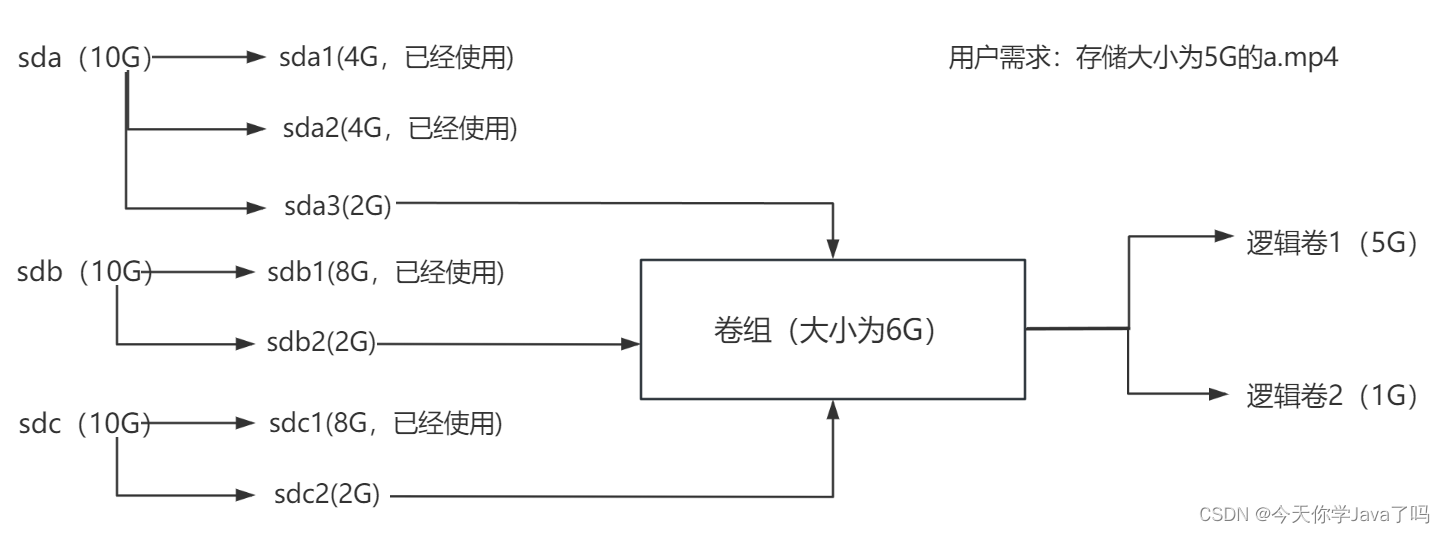
网络运维Day06-补充
文章目录 RAID磁盘阵列RAID0条带模式RAID1镜像模式RAID5高性价比模式RAID01RAID10 逻辑卷一块磁盘的使用流程逻辑卷的使用流程 制作逻辑卷步骤一:添加硬盘步骤二:分区规划步骤三:制作物理卷步骤四:制作卷组步骤五:制作…...
)
用STM32F103C8T6驱动TM1638模块:一个完整的人机交互小项目(附代码避坑点)
STM32F103C8T6与TM1638模块实战:打造智能交互终端全流程解析 在嵌入式开发领域,将微控制器与显示驱动模块有机结合是构建人机交互界面的基础技能。STM32F103C8T6作为经典的ARM Cortex-M3内核微控制器,搭配TM1638这款集LED驱动、键盘扫描于一体…...

如何通过smol-macros获得Rust异步编程的终极快速编译优势
如何通过smol-macros获得Rust异步编程的终极快速编译优势 【免费下载链接】smol A small and fast async runtime for Rust 项目地址: https://gitcode.com/gh_mirrors/smo/smol smol是一个轻量级且高效的Rust异步运行时,专为追求极致性能和快速编译的开发者…...

tbls lint检查完全指南:构建高质量数据库的10个最佳实践
tbls lint检查完全指南:构建高质量数据库的10个最佳实践 【免费下载链接】tbls tbls is a CI-Friendly tool to document a database, written in Go. 项目地址: https://gitcode.com/gh_mirrors/tb/tbls tbls是一个CI友好的数据库文档工具,用Go语…...

SublimePicker重复选项选择器的深度使用教程:从基础到高级自定义
SublimePicker重复选项选择器的深度使用教程:从基础到高级自定义 【免费下载链接】SublimePicker A material-styled android view that provisions picking of a date, time & recurrence option, all from a single user-interface. 项目地址: https://git…...

Qwen3-1.7B语音识别教程:支持SRT/VTT字幕生成、时间轴对齐、多说话人区分标注
Qwen3-1.7B语音识别教程:支持SRT/VTT字幕生成、时间轴对齐、多说话人区分标注 1. 引言:从“听不清”到“看得懂”的智能转录 你有没有遇到过这样的场景?一段重要的会议录音,想要整理成文字纪要,结果发现背景嘈杂、多…...

基于java的叙事之眼系统自动化测试
1.公共类(Utils)这是一个叙事之眼写小说自动化测试的公共工具类,进行Selenium 自动化测试,所有测试用例都可以共用它,统一创建、管理 Chrome 浏览器驱动,打开测试页面,设置等待时间,…...

HC32L130安全复用SWD引脚方案
目录 一、引脚与寄存器基础 二、安全配置方案(推荐) 1. 代码实现(上电延时 条件切 GPIO) 2. 下载恢复方法(ISP 模式) 三、关键注意事项 四、总结 要让 HC32L130 的SWDIO (PA13)、SWCLK (PA14) 作为通…...

在有 Vibe 的地方一起 Coding,咖啡一杯,Token 无限丨Real-Time Café 快闪杭州站
RTE 社区这次计划做一件轻松和「Keep Real」的事情: 包下一个咖啡馆, 邀请大家一起来杯咖啡, 坐下来各自 vibe coding。 We’re turning coffee into compute. 未来这将成为 RTE 社区的新系列活动,首站杭州!为了让这…...

HASH、MAC、HMAC 对比
对比汇总表--**Hash(散列)****MAC(消息认证码)****HMAC(哈希MAC)**全称Hash FunctionMessage Authentication CodeHash-based MAC输入任意长度消息消息 密钥消息 密钥输出固定长度摘要固定长度认证码固定…...

终极指南:如何安全处理跨源链接的noopener最佳实践
终极指南:如何安全处理跨源链接的noopener最佳实践 【免费下载链接】developer.chrome.com The frontend, backend, and content source code for developer.chrome.com 项目地址: https://gitcode.com/gh_mirrors/de/developer.chrome.com 在Web开发中&…...