C现代方法(第19章)笔记——程序设计
文章目录
- 第19章 程序设计
- 19.1 模块
- 19.1.1 内聚性与耦合性
- 19.1.2 模块的类型
- 19.2 信息隐藏
- 19.2.1 栈模块
- 19.3 抽象数据类型
- 19.3.1 封装
- 19.3.2 不完整类型
- 19.4 栈抽象数据类型
- 19.4.1 为栈抽象数据类型定义接口
- 19.4.2 用定长数组实现栈抽象数据类型
- 19.4.3 改变栈抽象数据类型中数据项的类型
- 19.4.4 用动态数组实现栈抽象数据类型
- 19.4.5 用链表实现栈抽象数据类型
- 19.5 抽象数据类型的设计问题
- 19.5.1 命名惯例
- 19.5.2 错误处理
- 19.5.3 通用抽象数据类型
- 19.5.4 新语言中的抽象数据类型
- 问与答
- 写在最后
第19章 程序设计
——只要有模块化就有可能发生误解:隐藏信息的另一面是阻断沟通。
实际应用中的程序显然比本书中的例子要大,但你可能还没意识到会大多少。更快的
CPU和更大的主存已经使我们可以编写一些几年前还完全不可行的程序。图形用户界面的流行大大增加了程序的平均长度。如今,大多数功能完整的程序至少有十万行代码,百万行的程序已经很常见,甚至千万行以上的程序都听说过。虽然
C语言不是专门用来编写大型程序的,但许多大型程序的确是用C语言编写的。这会很复杂,需要很多的耐心和细心,但确实可以做到。本章将讨论那些有助于编写大型程序的技术,并且会展示C语言的哪些特性(例如static存储类)特别有用。编写大型程序(通常称为“大规模程序设计”)与编写小型程序有很大的不同——就如同写一篇学期论文(当然是双倍行距
10页)与写一本1000页的书之间的差别一样。大型程序需要更加注意编写风格,因为会有许多人一起工作。需要有正规的文档,同时还需要对维护进行规划,因为程序可能会经历多次修改。相比于小型程序,编写大型程序尤其需要更仔细的设计和更详细的计划。正如
Smalltalk编程语言的设计者Alan Kay所言,“You can build a doghouse out of anything”。建造犬舍不需要任何特别的设计,可以使用任何原材料,但是对于人居住的房屋就不能这么干了,后者要复杂得多。
第15章曾经讨论过用C语言编写大型程序,但更多地侧重于语言的细节。本章会再次讨论这个主题,并着重讨论好的程序设计所需要的技术。全面地讨论程序设计问题显然超出了本书的范围,但我会尽量简要地涵盖一些在程序设计中比较重要的观念,并展示如何使用它们来编写出易读、易于维护的C程序。
19.1节讨论如何将C程序看作一组相互提供服务的模块。随后会介绍如何使用信息隐藏(19.2节)和抽象数据类型(19.3节)来改进程序模块。19.4节通过一个示例(栈数据类型)展示了如何在C语言中定义和实现抽象数据类型。19.5节描述了C语言在定义抽象数据类型方面的一些局限,并讨论了解决方案。
19.1 模块
设计
C程序(或其他任何语言的程序)时,最好将它看作一些独立的模块。模块是一组服务的集合,其中一些服务可以被程序的其他部分(称为客户)使用。每个模块都有一个接口来描述所提供的服务。模块的细节(包括这些服务自身的源代码)都包含在模块的实现中。
在C语言环境下,这些“服务”就是函数。模块的接口就是头文件,头文件中包含那些可以被程序中其他文件调用的函数原型。模块的实现就是包含该模块中函数定义的源文件。
为了解释这个术语,我们来看一下第15章中的计算器程序。这个程序由calc.c文件和一个栈模块组成。calc.c文件包含main函数,栈模块则存储在stack.h和stack.c文件中(见下面的图)。文件calc.c是栈模块的客户;文件stack.h是栈模块的接口,它提供了客户需要了解的全部信息;stack.c文件是栈模块的实现,其中包括栈函数的定义以及组成栈的变量的声明。
//stack.h #include <stdbool.h> void make_empty(void); bool is_empty(void); bool is_full(void); void push(int i); int pop(void);//cal.c #include "stack.h" int main(void){make_empty();... }//stack.c #include "stack.h" int contents[100]; int top = 0; void make_empty(void){... } bool is_empty(void) {... } bool is_full(void) {... } void push(int i) {... } int pop(void) {... }
C库本身就是一些模块的集合。库中每个头都是一个模块的接口。例如,<stdio.h>是包含输入/输出函数的模块的接口,<string.h>是包含字符串处理函数的模块的接口。
将程序分割成模块有一系列好处:
- 抽象。如果模块设计合理,则可以将其作为抽象对待。我们知道模块会做什么,但不需要知道这些功能的实现细节。因为抽象的存在,所以不必为了修改部分程序而了解整个程序是如何工作的。同时,抽象让一个团队的多个程序员共同开发一个程序更容易。一旦对模块的接口达成一致,实现每一个模块的责任可以被分派到各个成员身上。团队成员可以更大程度上相互独立地工作。
- 可复用性。任何一个提供服务的模块都可能在其他程序中复用。例如,我们的栈模块就是可复用的。由于通常很难预测模块的未来使用情况,最好将模块设计成可复用的。
- 可维护性。将程序模块化后,程序中的错误通常只会影响一个模块实现,因而更容易找到并修正错误。在修正了错误之后,重建程序只需重新编译该模块实现(然后重新链接整个程序)即可。更广泛地说,为了提高性能或将程序移植到另一个平台上,我们甚至可以替换整个模块的实现。
上面这些好处都很重要,但其中可维护性是最重要的。现实中大多数程序会使用许多年,在使用过程中会发现问题,并做一些改进以适应需求的变化。将程序按模块来设计会使维护更容易。维护一个程序就像维护一辆汽车一样,修理轮胎应该不需要同时检修引擎。
我们就以
第16章和第17章中的inventory程序为例。最初的程序(参见16.3节)将零件记录存储在一个数组中。假设在程序使用了一段时间后,客户不同意对可以存储的零件数量设置固定的上限。为了满足客户的需求,我们可能会改用链表(17.5节就是这么做的)。为了做这个修改,需要仔细检查整个程序,找出所有依赖于零件存储方式的地方。如果一开始就采用不同的方式来设计程序(使用一个独立的模块来处理零件的存储),就可能只需要重写这一个模块的实现,而不需要重写整个程序。
一旦确定要进行模块化设计,设计程序的过程就变成了确定究竟应该定义哪些模块,每个模块应该提供哪些服务,以及各个模块之间的相互关系是什么。现在就来简要地看看这些问题。如果需要了解程序设计的更多信息,可以参考软件工程方面的图书,比如Ghezzi、Jazayeri和Mandrioli的Fundamentals of Software Engineering。
19.1.1 内聚性与耦合性
好的模块接口并不是声明的随意集合。在设计良好的程序中,模块应该具有下面
2个性质:
- 高内聚性。模块中的元素应该彼此紧密相关。可以认为它们是为了同一目标而相互合作的。高内聚性会使模块更易于使用,同时使程序更容易理解。
- 低耦合性。模块之间应该尽可能相互独立。低耦合性可以使程序更便于修改,并方便以后复用模块。
我们的计算器程序有这些性质吗?实现栈的模块明显是具有内聚性的:其中的函数表示与栈相关的操作。整个程序的耦合性也很低,文件calc.c依赖于stack.h(当然stack.c也依赖于stack.h),但除此之外就没有其他明显的依赖关系了。
19.1.2 模块的类型
由于需要具备高内聚性、低耦合性,模块通常分为下面几类:
- 数据池。
数据池是一些相关的变量或常量的集合。在C语言中,这类模块通常只是一个头文件。从程序设计的角度来说,通常不建议将变量放在头文件中,但建议把相关常量放在头文件中。在C库中,<float.h>头(23.1节)和<limits.h>头(23.2节)都属于数据池。 - 库。库是一个相关函数的集合。例如
<string.h>头就是字符串处理函数库的接口。 - 抽象对象。
抽象对象是指对于隐藏的数据结构进行操作的函数的集合。(本章中的术语“对象”含义与其他章中的不同。在C语言术语中,对象仅仅是可以存储值的一块内存,而在本章中,对象是一组数据以及针对这些数据的操作的集合。如果数据是隐藏起来的,那么这个对象是“抽象”的。)我们讨论的栈模块属于这一类。 - 抽象数据类型(ADT)。
将具体数据实现方式隐藏起来的数据类型叫作抽象数据类型。客户模块可以使用该类型来声明变量,但不会知道这些变量的具体数据结构。如果客户模块需要对这种变量进行操作,则必须调用抽象数据类型模块所提供的函数。抽象数据类型在现代程序设计中起着非常重要的作用。我们会在19.3节~19.5节回过头来讨论。
19.2 信息隐藏
设计良好的模块经常会对它的客户隐藏一些信息。例如,我们的栈模块的客户就不需要知道栈是用数组、链表还是其他形式存储的。这种故意对客户隐藏信息的方法叫作
信息隐藏。信息隐藏有以下2大优点:
- 安全性。如果客户不知道栈是如何存储的,就不可能通过栈的内部机制擅自修改栈的数据。它们必须通过模块自身提供的函数来操作栈,而这些函数都是我们编写并测试过的。
- 灵活性。无论对模块的内部机制进行多大的改动,都不会很复杂。例如,我们可以首先将栈用数组实现,以后再改用链表或其他方式实现。我们当然需要重写这个模块的实现,但只要模块是按正确的方式设计的,就不需要改变模块的接口。
在C语言中,强制信息隐藏的主要工具是static存储类型(18.2节)。将具有文件作用域的变量声明为static可以使其具有内部链接,从而避免它被其他文件(包括模块的客户)访问。(将函数声明为static也是有用的——函数只能被同一文件中的其他函数直接调用。)
19.2.1 栈模块
为了清楚地看到信息隐藏所带来的好处,下面来看看栈模块的两种实现。一种使用
数组,另一种使用链表。假设模块的头文件如下所示:
//stack.h
#ifndef STACK_H
#define STACK_H #include <stdbool.h> /* C99 only */ void make_empty(void);
bool is_empty(void);
bool is_full(void);
void push(int i);
int pop(void); #endif
首先,用数组实现这个栈:
#include <stdio.h>
#include <stdlib.h>
#include "stack.h" #define STACK_SIZE 100 static int contents[STACK_SIZE];
static int top = 0; static void terminate(const char *message)
{ printf("%s\n", message); exit(EXIT_FAILURE);
} void make_empty(void)
{ top = 0;
} bool is_empty(void)
{ return top == 0;
} bool is_full(void)
{ return top == STACK_SIZE;
} void push(int i)
{ if (is_full()) terminate("Error in push: stack is full."); contents[top++] = i;
} int pop(void)
{ if (is_empty()) terminate("Error in pop: stack is empty."); return contents[--top];
}
组成栈的变量(contents和top)都被声明为static了,因为没有理由让程序的其他部分直接访问它们。terminate函数也声明为static。这个函数不属于模块的接口;相反,它只能在模块的实现内使用。
出于风格的考虑,一些程序员使用宏来指明哪些函数和变量是
“公有”的(可以在程序的任何地方访问),哪些是“私有”的(只能在一个文件内访问):
#define PUBLIC /* empty */
#define PRIVATE static
将static写成PRIVATE是因为static在C语言中有很多用法,使用PRIVATE可以更清晰地指明这里它是被用来强制信息隐藏的。下面是使用PUBLIC和PRIVATE后栈实现的样子:
PRIVATE int contents[STACK_SIZE];
PRIVATE int top = 0; PRIVATE void terminate(const char *message) { ... } PUBLIC void make_empty(void) { ... } PUBLIC bool is_empty(void) { ... } PUBLIC bool is_full(void) { ... } PUBLIC void push(int i) { ... } PUBLIC int pop(void) { ... }
现在换成使用
链表实现:
//stack2.c
#include <stdio.h>
#include <stdlib.h>
#include "stack.h" struct node { int data; struct node *next;
}; static struct node *top = NULL; static void terminate(const char *message)
{ printf("%s\n", message); exit(EXIT_FAILURE);
} void make_empty(void)
{ while (!is_empty()) pop();
} bool is _empty(void)
{ return top == NULL;
} bool is_full(void)
{ return false;
} void push(int i)
{ struct node *new_node = malloc(sizeof(struct node)); if (new_node == NULL) terminate("Error in push: stack is full."); new_node->data = i; new_node->next = top; top = new_node;
} int pop(void)
{ struct node *old_top; int i; if (is_empty()) terminate("Error in pop: stack is empty."); old_top = top; i = top->data; top = top->next; free(old_top); return i;
}
注意!!is_full函数每次被调用时都返回false。链表对大小没有限制,所以栈永远不会满。程序运行时仍然可能(不过可能性不大)出现内存不够的问题,从而导致push函数失败,但事先很难测试这种情况。
我们的栈示例清晰地展示了信息隐藏带来的好处:使用stack1.c还是使用stack2.c来实现栈模块无关紧要。这两个版本都能匹配模块的接口定义,因此相互替换时不需要修改程序的其他部分。
19.3 抽象数据类型
作为抽象对象的模块(像上一节中的栈模块)有一个严重的缺点:
无法拥有该对象的多个实例(本例中指多个栈)。为了达到这个目的,需要创建一个新的类型。
一旦定义了Stack类型,就可以有任意个栈了。下面的程序片段显示了如何在同一个程序中有两个栈:
Stack s1, s2; make_empty(&s1);
make_empty(&s2);
push(&s1, 1);
push(&s2, 2);
if (!is_empty(&sl)) printf("%d\n", pop(&s1)); /* prints "1" */
我们并不知道s1和s2究竟是什么(是结构,还是指针),但这并不重要。对于栈模块的客户,s1和s2是抽象,它只响应特定的操作(make_empty、is_empty、is_full、push以及pop)。
接下来将stack.h改成提供Stack类型的方式,其中Stack是结构。这需要给每个函数增加一个Stack类型(或Stack *)的形式参数。stack.h现在如下:
#define STACK_SIZE 100 typedef struct { int contents[STACK_SIZE]; int top;
} Stack; void make_empty(Stack *s);
bool is_empty(const Stack *s);
bool is_full(const Stack *s);
void push(Stack *s, int i);
int pop(Stack *s);
函数make_empty、push和pop参数的栈变量应为指针,因为这些函数会改变栈的内容。is_empty和is_full函数的参数并不需要是指针,但这里我们仍然使用了指针。给这两个函数传递Stack指针比传递Stack值更有效,因为传递值会导致整个数据结构被复制。
19.3.1 封装
遗憾的是,上面的
Stack不是抽象数据类型,因为stack.h暴露了Stack类型的具体实现方式,因此无法阻止客户将Stack变量作为结构直接使用:
Stack s1; s1.top =0;
s1.contents[top++] = 1;
由于提供了对top和contents成员的访问,模块的客户可以破坏栈。更糟糕的是,由于无法评估客户的修改所产生的效果,我们不能改变栈的存储方式。
我们真正需要的是一种阻止客户知道Stack类型的具体实现的方式。C语言对于封装类型的支持很有限。新的基于C的语言(包括C++、Java和C#)对于封装的支持更好一些。
19.3.2 不完整类型
C语言提供的唯一封装工具为不完整类型(incomplete type),在17.9节和第17章最后的“问与答”部分简单提过)。C标准对不完整类型的描述:“描述了对象但缺少定义对象大小所需的信息。”例如,声明
struct t; /* incomplete declaration of t */
告诉编译器t是一个结构标记,但并没有描述结构的成员。因此,编译器并没有足够的信息来确定该结构的大小。这样做的意图是,不完整类型会在程序的其他地方将信息补充完整。
不完整类型的使用是受限的。因为编译器不知道不完整类型的大小,所以不能用它来声明变量:
struct t s; /*** WRONG ***/
但是完全可以定义一个指针类型引用不完整类型:
typedef struct t *T;
这个类型定义表明,类型T的变量是指向标记为t的结构的指针。现在可以声明类型T的变量,将其作为函数的参数进行传递,并可以执行其他合法的指针运算(指针的大小并不依赖于它指向的对象,这就解释了为什么C语言允许这种行为)。但我们不能对这些变量使用->运算符,因为编译器对t结构的成员一无所知。
19.4 栈抽象数据类型
为了说明抽象数据类型怎样利用不完整类型进行封装,需要开发一个基于19.2节描述的栈模块的栈抽象数据类型(Abstract Data Type, ADT)。这一过程中将用3种不同的方法来实现栈。
19.4.1 为栈抽象数据类型定义接口
首先,需要一个定义栈抽象数据类型的头文件,并给出代表栈操作的函数原型。现在将该头文件命名为
stackADT.h。Stack类型将作为指针指向stack_type结构,该结构存储栈的实际内容。这个结构是一个不完整类型,在实现栈的文件中信息将变得完整。该结构的成员依赖于栈的实现方法。下面是stackADT.h文件的内容:
/*
stackADT.h(版本1)
*/
#ifndef STACKADT_H
#define STACKADT_H #include <stdbool.h> /* since C99 */ typedef struct stack_type *Stack; Stack create(void);
void destroy(Stack s);
void make_empty(Stack s);
bool is_empty(Stack s);
bool is_full(Stack s);
void push(Stack s, int i);
int pop(Stack s); #endif
包含头文件stackADT.h的客户可以声明Stack类型的变量,这些变量都可以指向stack_type结构。之后客户就可以调用在stackADT.h中声明的函数来对栈变量进行操作。但是客户不能访问stack_type结构的成员,因为该结构的定义在另一个文件中。
需要注意的是,每一个函数都有一个Stack参数或返回一个Stack值。19.3节中的栈函数都具有Stack *类型的参数。导致这种差异的原因是,Stack变量现在是指针,指向存放着栈内容的stack_type结构。如果函数需要修改栈,则改变的是结构本身,而不是指向结构的指针。
同样需要注意函数create和destroy。模块通常不需要这些函数,但抽象数据类型需要。create会自动给栈分配内存(包括stack_type结构需要的内存),同时把栈初始化为“空”状态。destroy将释放栈的动态分配内存。
下面的客户文件可以用于测试栈抽象数据类型。它创建了两个栈,并对它们执行各种操作:
/*
stackclient.c
*/
#include <stdio.h>
#include "stackADT.h" int main(void)
{ Stack s1, s2; int n; s1 = create(); s2 = create(); push(s1, 1); push(s1, 2); n = pop(s1); printf("Popped %d from s1\n", n); push(s2, n); n = pop(s1); printf("Popped %d from s1\n",n); push(s2, n); destroy(s1); while (!is_empty(s2)) printf("Popped %d from s2\n", pop(s2)); push(s2, 3); make_empty(s2); if (is_empty(s2)) printf("s2 is empty\n"); else printf("s2 is not empty\n"); destroy(s2); return 0;
}
如果栈抽象数据类型的实现是正确的,程序将产生如下输出:
Popped 2 from s1
Popped 1 from s1
Popped 1 from s2
Popped 2 from s2
s2 is empty
19.4.2 用定长数组实现栈抽象数据类型
实现栈抽象数据类型有多种方法,这里介绍的第一种方法是最简单的。
stackADT.c文件中定义了结构stack_type,该结构包含一个定长数组(记录栈中的内容)和一个整数(记录栈顶):
/*
stackADT.c
*/
#include <stdio.h>
#include <stdlib.h>
#include "stackADT.h" #define STACK_SIZE 100 struct stack_type { int contents[STACK_SIZE]; int top;
}; static void terminate (const char *message)
{ printf("%s\n", message); exit(EXIT_FAILURE);
} Stack create(void)
{ Stack s = malloc(sizeof(struct stack_type)); if (s == NULL) terminate("Error in create: stack could not be created."); s->top = 0; return s;
} void destroy(Stack s)
{ free(s);
} void make_empty(Stack s)
{ s->top = 0;
} bool is_empty(Stack s)
{ return s->top == 0;
} bool is_full(Stack s)
{ return s->top == STACK_SIZE;
} void push(Stack s, int i)
{ if (is_full(s)) terminate("Error in push: stack is full."); s->contents[s->top++] = i;
} int pop(Stack s)
{ if (is_empty(s)) terminate("Error in pop: stack is empty."); return s->contents[--s->top];
}
这个文件中的函数最显眼的地方是,它们用->运算符而不是.运算符来访问stack_type结构的contents和top成员。参数s是指向stack_type结构的指针,而不是结构本身,所以使用.运算符是非法的。
19.4.3 改变栈抽象数据类型中数据项的类型
现在我们已经有了栈抽象数据类型的一个版本,下面对其进行改进。首先,注意到栈里的项都是整数,太具有局限性了。事实上,栈中的数据项类型是无关紧要的,可以是其他基本类型(
float、double、long等),也可以是结构、联合或指针。
为了使栈抽象数据类型更易于针对不同的数据项类型进行修改,我们在 stackADT.h中增加了一行类型定义。现在用类型名Item表示待存储到栈中的数据的类型。
/*
stackADT.h(版本2)
*/
#ifndef STACKADT_H
#define STACKADT_H #include <stdbool.h> /* since C99 */ typedef int Item;
typedef struct stack_type *Stack; Stack create(void);
void destroy(Stack s);
void make_empty(Stack s);
bool is_empty(Stack s);
bool is_full(Stack s);
void push(Stack s, Item i);
Item pop (Stack s); #endif
除新增了Item类型外,push和pop函数也做了修改。push现在具有一个Item类型的参数,而pop则返回Item类型的值。从现在起我们将使用这一版本的stackADT.h来代替先前的版本。
为了跟stackADT.h匹配,stackADT.c文件也需要做相应的修改,但改动很小。stack_type结构将包含一个数组,数组的元素是Item类型而不是int类型:
struct stack_type { Item contents[STACK_SIZE]; int top;
};
push和pop的函数体部分没有改变,相应的改变仅仅是把push的第二个参数和pop的返回值改成了Item类型。
stackclient.c文件可以用于测试新的stackADT.h和stackADT.c,以验证Stack类型仍然可以很好地工作。(确实如此!)现在就可以通过修改stackADT.h中Item类型的定义来任意修改数据项类型了。(尽管我们不需要改变stackADT.c文件,但仍然需要对它进行重新编译。)
19.4.4 用动态数组实现栈抽象数据类型
栈抽象数据类型的另一个问题是,每一个栈的大小的最大值是固定的(目前设置为
100)。当然,这一上限值可以根据我们的意愿任意增加,但使用Stack类型创建的所有栈都会有同样的上限值。这样我们就不能拥有容量不同的栈了,也不能在程序运行的过程中设置栈的大小。
有两种方法可以解决这个问题。一种方法是把栈作为链表来实现,这样就没有固定的大小限制了。稍后我们将讨论这种方法,下面先来看看另一种方法——将栈中的数据项存放在动态分配的数组(17.3节)中。
这种方法的关键在于修改stack_type结构,使contents成员为指向数据项所在数组的指针,而不是数组本身:
struct stack_type { Item *contents; int top; int size;
};
我们还增加了一个新成员size来存储栈的最大容量(contents指向的数组长度)。下面将使用这个成员检查“栈满”的情况。
create函数有一个参数指定所需栈的最大容量:
Stack create(int size);
调用create函数时,它会创建一个stack_type结构和一个长度为size的数组。结构的contents成员将指向这个数组。
除了在create函数中新增size参数外,文件stackADT.h和之前的一致。(重新命名为stackADT2.h。)但文件stackADT.c需要进行较多的修改:
/*
stackADT2.c
*/
#include <stdio.h>
#include <stdlib.h>
#include "stackADT2.h" struct stack_type { Item *contents; int top; int size;
}; static void terminate (const char *message)
{ printf("%s\n", message); exit(EXIT_FAILURE);
} Stack create(int size)
{ Stack s = malloc(sizeof(struct stack_type)); if (s == NULL) terminate("Error in create: stack could not be created."); s->contents = malloc(size * sizeof(Item)); if (s->contents == NULL) { free(s); terminate("Error in create: stack could not be created."); } s->top = 0; s->size = size; return s;
} void destroy(Stack s)
{ free(s->contents); free(s);
} void make_empty(Stack s)
{ s->top = 0;
} bool is_empty(Stack s)
{ return s->top == 0;
} bool is_full (Stack s)
{ return s->top == s->size;
} void push(Stack s, Item i)
{ if (is_full(s)) terminate("Error in push: stack is full."); s->contents[s->top++] = i;
} Item pop(Stack s)
{ if (is_empty(s)) terminate("Error in pop: stack is empty."); return s->contents[--s->top];
}
现在create函数调用malloc2次:一次是为stack_type结构分配空间,另一次是为包含栈数据项的数组分配空间。任意一处malloc失败都会导致调用terminate函数。destroy函数必须调用free函数两次来释放由create分配的内存。
stackclient.c文件可以再次用于测试栈抽象数据类型。但create函数的调用需要有所改变,因为现在的create函数需要参数。例如,可以将语句
s1 = create();
s2 = create();
改为
s1 = create(100);
s2 = create(200);
19.4.5 用链表实现栈抽象数据类型
使用动态分配数组实现栈抽象数据类型比使用定长数组更灵活,但客户在创建栈时仍然需要指定其最大容量。如果使用链表来实现栈,就不需要预先设定栈的大小了。
下面的实现与19.2节中的stack2.c文件相似。链表中的结点用如下结构表示:
struct node { Item data; struct node *next;
};
data成员的类型现在是Item而不是int,但除此之外结构和之前是一样的。
stack_type结构包含一个指向链表首结点的指针:
struct stack_type { struct node *top;
};
乍一看,这个结构似乎有点冗余:我们可以简单地把Stack定义为struct node*,同时让Stack的值为指向链表首结点的指针。但是,我们仍然需要这个stack_type结构,这样可以使栈的接口保持不变。(如果不这样做,任何一个对栈进行修改的函数都需要Stack *类型的参数而不是Stack参数。)此外,如果将来想存储更多的信息,stack_type结构的存在可以简化对实现的修改。例如,如果以后想给stack_type结构增加栈数据项的计数器,可以很容易地为stack_type结构增加一个成员来存储该信息。
我们不需要对stackADT.h做任何修改。(我们使用这个头文件,不用 stackADT2.h。)测试的时候仍然可以使用stackclient.c文件,但需要做一些改动,下面是新版本:
/*
stackADT3.c
*/
#include <stdio.h>
#include <stdlib.h>
#include "stackADT.h" struct node { Item data; struct node *next;
}; struct stack_type { struct node *top;
}; static void terminate(const char *message)
{ printf("%s\n", message); exit(EXIT_FAILURE);
} Stack create(void)
{ Stack s = malloc(sizeof(struct stack_type)); if (s == NULL) terminate("Error in create: stack could not be created."); s->top = NULL; return s;
} void destroy(Stack s)
{ make_empty(s); free(s);
} void make_empty(Stack s)
{ while (!is_empty(s)) pop(s);
} bool is_empty(Stack s)
{ return s->top == NULL;
} bool is_full(Stack s)
{ return false;
} void push(Stack s, Item i)
{ struct node *new_node = malloc(sizeof(struct node)); if (new_node == NULL) terminate("Error in push: stack is full."); new_node->data = i; new_node->next = s->top; s->top = new_node;
} Item pop(Stack s)
{ struct node *old_top; Item i; if (is_empty(s)) terminate("Error in pop: stack is empty."); old_top = s->top; i = old_top->data; s->top = old_top->next; free(old_top); return i;
}
注意!!destroy函数在调用free函数(释放stack_type结构所占的内存)前先调用了make_empty(释放链表中结点所占的内存)。
19.5 抽象数据类型的设计问题
19.4节描述了栈抽象数据类型,并介绍了几种实现方法。遗憾的是,这里的抽象数据类型存在一些问题,使其达不到工业级强度。下面一起来看看这些问题,并探讨一下可能的解决方案。
19.5.1 命名惯例
目前的栈抽象数据类型函数都采用简短、便于记忆的名字:create、destroy、make_empty、is_empty、is_full、push和pop。如果在一个程序中有多个抽象数据类型,两个模块中就很可能有同名函数,这样就会导致命名冲突。(例如,每个抽象数据类型都需要自己的create函数。)所以,我们可能需要在函数名中加入抽象数据类型本身的名字,比如使用stack_create代替create。
19.5.2 错误处理
栈抽象数据类型通过显示出错消息或终止程序的方式来处理错误。这是一个不错的处理方式。程序员可以通过在每次调用
pop之前调用is_empty,以及在每次调用push之前调用is_full,来避免从空栈中弹出数据项或者向满栈里压入数据项。因此从理论上来讲,对pop和push的调用没有理由会出错。(但在链表实现中,调用is_full并没有效果,后续调用push仍然可能出错。)不过,我们可能希望为程序提供一种从这些错误中恢复的途径,而不是简单地终止程序。
一个可选的方案是让push和pop函数返回一个bool值说明函数调用是否成功。目前push的返回类型为void,所以很容易改为在操作成功时返回true,当栈已满时返回false。但修改pop函数就困难一些了,因为目前pop函数返回的是弹出的值。如果让pop返回一个指向弹出的值的指针而不是返回该值本身,那就可以让pop返回NULL来表示此时栈为空。
最后关于错误处理的一点评论:C标准库包含带参数的assert宏(24.1节),可以在指定的条件不满足时终止程序。可以用该宏的调用取代目前栈抽象数据类型中使用的if语句和terminate函数的调用。
19.5.3 通用抽象数据类型
在
19.4节中,我们通过简化对存储在栈中的数据项类型的修改来改进栈抽象数据类型——我们需要做的工作只是改变Item类型的定义。这样做仍然有些麻烦,如果栈能够适应任意类型的值而不需要改变stack.h文件会更好些。同时我们注意到,现在的抽象数据类型栈还存在一个严重的问题:程序不能创建两个数据类型不同的栈。创建多个栈很容易,但这些栈中的数据项必须具有相同的类型。为了允许多个栈具有不同的数据项类型,需要复制栈抽象数据类型的头文件和源文件,并改变一组文件,使Stack类型及相关的函数具有不同的名字。
我们希望有一个“通用”的栈类型,可以用来创建整数栈、字符串栈或者需要的其他类型的栈。在C中有很多不同的途径可以做到这一点,但没有一个是完全令人满意的。最常见的一种方法是使用void *作为数据项类型,这样就可以压入和弹出任何类型的指针了。如果使用这种方法,stackADT.h文件和我们最初的版本相似,但push和pop函数的原型需要修改为如下形式:
void push(Stack s, void *p);
void *pop(Stack s);
pop返回一个指向从栈中弹出的数据项的指针,如果栈为空,则返回空指针。
使用void *作为数据项类型有2个缺点:
- 第一,这种方法不适用于无法用指针形式表示的数据。数据项可以是字符串(用指向字符串第一个字符的指针表示)或动态分配的结构,但不能是
int、double之类的基本类型。 - 第二,不能进行错误检测。存放
void *数据项的栈允许各种类型的指针共存,因此无法检测出由压入错误的指针类型所导致的错误。
19.5.4 新语言中的抽象数据类型
上面讨论的问题在新的基于
C的语言(如C++、Java和C#)中处理得更好。通过在类中定义函数名可以避免命名冲突的问题。栈抽象数据类型可以用一个Stack类来表示,栈函数都属于这个类,而且仅当作用于Stack对象时才能被编译器识别。这些语言都提供了一种叫作异常处理(exception handling)的特性,允许push和pop等函数在检测出错误时“抛出”异常。客户代码可以通过“捕获”异常来处理错误。C++、Java和C#还专门提供了定义通用抽象数据类型的特性。例如,在C++中可以定义一个栈模板而不用指定数据项的类型。
问与答
问1:本节中提到
C语言不是为开发大型程序设计的。UNIX不是大型程序吗?
答:在C语言被设计出来时还不是。在1978年的一篇论文中,Ken Thompson估计UNIX内核约有10000行C代码(加上一小部分汇编代码)。UNIX其他部分的大小也类似。在1978年的另一篇论文中,Dennis Ritchie和他的同事将PDP-11的C编译器大小设定为9660行。按现在的标准,这绝对只是小型程序。
问2:
C库中有什么抽象数据类型吗?
答:从技术上说,没有。但有一些很接近,包括FILE类型(22.1 节,定义在<stdio.h>中)。在对文件进行操作之前,必须声明FILE *类型的变量:
FILE *fp;
这个fp变量随后会被传递给不同的文件处理函数。
程序员需要把FILE作为一种抽象,在使用时不需要知道FILE具体是怎样的。FILE可能是一个结构类型,但C标准并不保证这一点。实际上,最好不要管FILE值究竟是如何存储的,因为FILE类型的定义对不同的编译器可能(也确实经常)是不一样的。
当然,我们总是可以通过查看stdio.h文件来找到FILE到底是什么。如果这么做,那么就没什么可以阻止我们编写代码来访问FILE的内部机制。例如,我们可能发现FILE结构中有一个名为bsize(文件的缓冲区大小)的成员:
typedef struct { ... int bsize; /* buffer size */ ...
} FILE;
一旦知道了bsize成员,就无法阻止我们直接访问特定文件的缓冲区大小:
printf("Buffer size: %d\n", fp->bsize);
然而,这样做并不好,因为其他C编译器可能将缓冲区大小存储在其他名字中,或者用不同的方式跟踪这个值。试图修改bsize成员则更糟糕:
fp->bsize = 1024;
这是一件非常危险的事,除非我们知道文件存储的全部细节。即使我们的确知道相关的细节,不同的编译器或是同一编译器的新版本也可能不一样。
问3:除了不完整结构类型,还有别的不完整类型吗?
答:最常见的不完整类型之一出现于声明数组但不指定大小时:
extern int a[];
在这个声明(第一次遇到这个声明是在15.2节)之后,a具有不完整类型,因为编译器不知道a的大小。有可能a在程序的另一个文件中定义,该定义补充了缺失的长度信息。
另一种不完整类型出现在没有指定数组的长度但提供了初始化器的数组声明中:
int a[] = {1, 2, 3};
在这个例子中,数组a刚开始具有不完整类型,但初始化器使得该类型完整了。
声明联合标记而不指明联合的成员也会创建不完整类型。 弹性数组成员(17.9节,C99的特性)就具有不完整类型。最后,void也是不完整类型。void类型具有不同寻常的性质,它永远不能变成完整类型,因此无法声明这种类型的变量。
问4:不完整类型在使用上有别的限制吗?
答:有下面这些限制:
sizeof运算符不能用于不完整类型(这不奇怪,因为不完整类型的大小未知)。- 结构或联合的成员(弹性数组成员除外)不可以具有不完整类型。
- 类似地,数据元素不可以具有不完整类型。
- 最后,函数定义中的形式参数不可以具有不完整类型(在函数声明中可以)。编译器会“调整”函数定义中的每个数组形式参数使其具有指针类型,从而阻止其具有不完整类型。
写在最后
本文是博主阅读《C语言程序设计:现代方法(第2版·修订版)》时所作笔记,日后会持续更新后续章节笔记。欢迎各位大佬阅读学习,如有疑问请及时联系指正,希望对各位有所帮助,Thank you very much!
相关文章:
笔记——程序设计)
C现代方法(第19章)笔记——程序设计
文章目录 第19章 程序设计19.1 模块19.1.1 内聚性与耦合性19.1.2 模块的类型 19.2 信息隐藏19.2.1 栈模块 19.3 抽象数据类型19.3.1 封装19.3.2 不完整类型 19.4 栈抽象数据类型19.4.1 为栈抽象数据类型定义接口19.4.2 用定长数组实现栈抽象数据类型19.4.3 改变栈抽象数据类型中…...
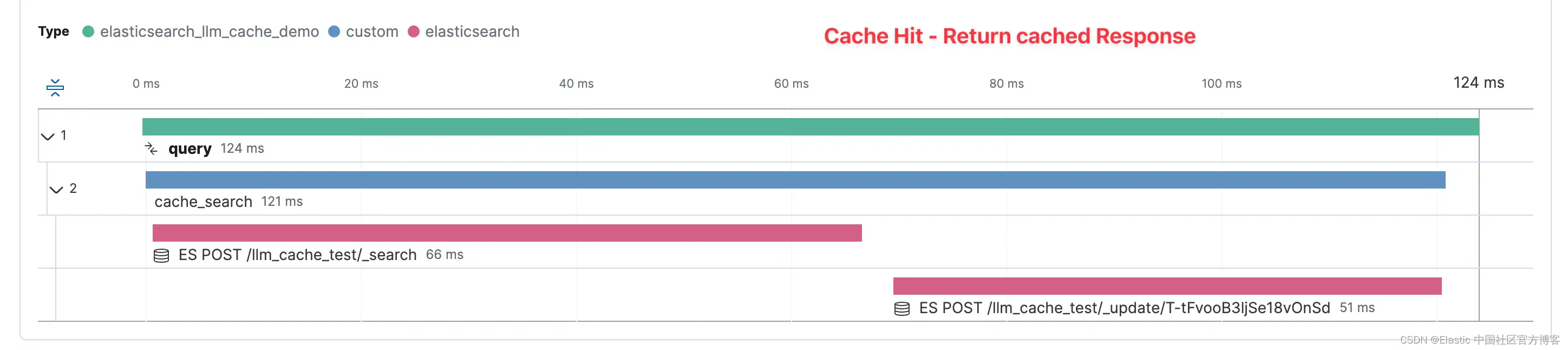
Elasticsearch 作为 GenAI 缓存层
作者:JEFF VESTAL,BAHA AZARMI 探索如何将 Elasticsearch 集成为缓存层,通过降低 token 成本和响应时间来优化生成式 AI 性能,这已通过实际测试和实际实施进行了证明。 随着生成式人工智能 (GenAI) 不断革新从客户服务到数据分析…...
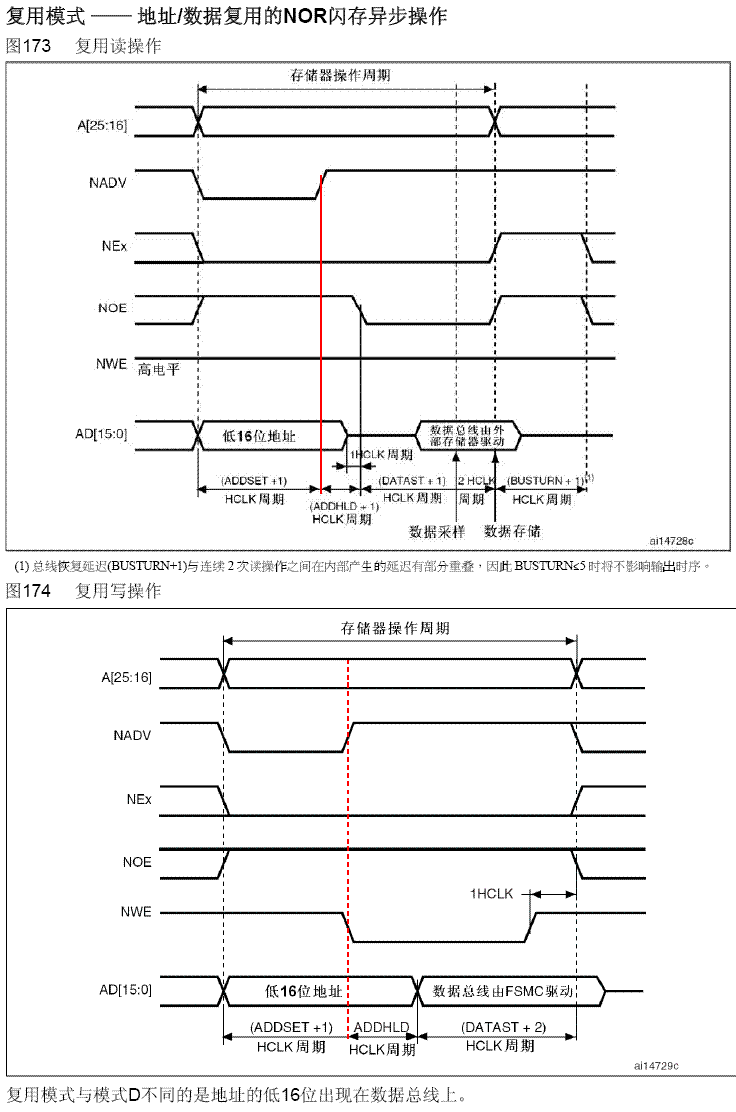
FPGA与STM32_FSMC总线通信实验
FPGA与STM32_FSMC总线通信实验 内部存储器IP核的参数设置创建IP核FPGA代码STM32标准库的程序 STM32F407 上自带 FSMC 控制器,通过 FSMC 总线的地址复用模式实现STM32 与 FPGA 之间的通信,FPGA 内部建立 RAM 块,FPGA 桥接 STM32 和 RAM 块&…...

maven配置自定义下载路径,以及阿里云下载镜像
1.配置文件 <?xml version"1.0" encoding"UTF-8"?> <settings xmlns"http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation"http://maven.apache.org…...

01.单一职责原则
单一职责原则 概述 简单来说就是一个类只描述一件事, 比如我们熟知的 userDao.java 只负责 用户域功能。如果userDao既操作user表又操作order表,这显然不合理。正确的做法是让orderDao.java去操作order表。 对类来说的,一个类应该只负责一项…...

RT-Thread上部署TinyMaix推理框架,使MCU赋予AI能力
概要 当谈到微控制器(MCU)和人工智能(AI)的结合,我们进入了一个激动人心的领域。传统上,AI应用程序需要大型计算机或云服务器的处理能力,但随着技术的发展,现在可以将AI嵌入到微控制器中。这为嵌入式系统、物联网设备、机器人和各种其他应用开启了新的可能性。 MCU A…...
)
设计模式 -- 策略模式(Strategy Pattern)
策略模式:一种行为型模式,这些设计模式特别关注对象之间的通信。在策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 context 对象的执行算法。 介绍 意图:定义一系列的算…...
Spring Boot 集成 ElasticSearch
1 加入依赖 首先创建一个项目,在项目中加入 ES 相关依赖,具体依赖如下所示: <dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.1.0</version&g…...

百度智能云正式上线Python SDK版本并全面开源!
文章目录 1. SDK的优势2. 千帆SDK:快速落地LLM应用3. 如何快速上手千帆SDK3.1 SDK快速启动3.2 SDK进阶指引3.3 通过Langchain接入千帆SDK 4. 开源社区 百度智能云千帆大模型平台再次升级!在原有API基础上,百度智能云正式上线Python SDK&#…...
LeetCode(3)删除有序数组中的重复项【数组/字符串】【简单】
目录 1.题目2.答案3.提交结果截图 链接: 26. 删除有序数组中的重复项 1.题目 给你一个 非严格递增排列 的数组 nums ,请你** 原地** 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保…...

前端视角中的微信登录
目录 引入 流程介绍 具体实现 引入 本文主要讲解网站应用中微信登录的具体流程是怎么样的,以及作为前端开发人员在这整个流程中的主要任务是什么。 如果想要实现微信登录的功能,需要开发人员到微信开放平台注册相应的账号,进行注册应用&am…...

Python 中使用 Selenium 隐式等待
selenium 包用于使用 Python 脚本进行自动化和测试。 我们可以使用它来访问网页中的各个元素并使用它们。 该包中有许多方法可用于根据不同属性检索元素。 加载页面时,会动态检索一些元素。 与其他元素相比,这些元素的加载速度可能不同。 Python 中使用…...
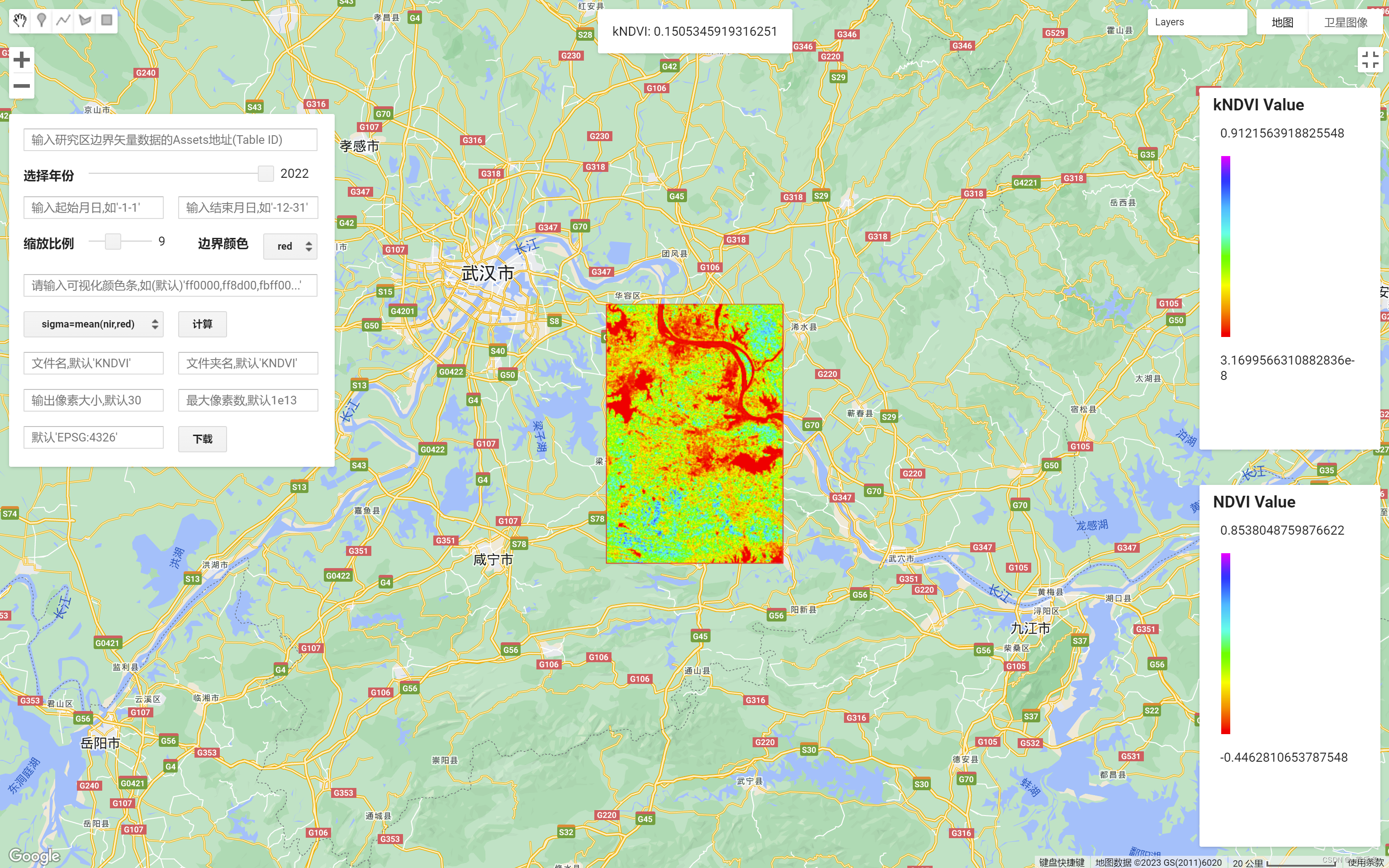
GEE:基于 Landsat 计算的 kNDVI 应用 APP
作者:CSDN @ _养乐多_ 本文记录了在Google Earth Engine(GEE)平台中,使用 Landsat 遥感数据计算 kNDVI 的应用 APP 链接,并介绍该 APP 的使用方法和步骤。该APP可以为用户展示 NDVI 和 kNDVI 的遥感影像,进行对比分析。该 APP 在 Google Earth Engine(GEE)平台中实现。…...

Spring 缓存注解
Spring Cache 框架给我们提供了 Cacheable 注解用于缓存方法返回内容。但是 Cacheable 注解不能定义缓存有效期。这样的话在一些需要自定义缓存有效期的场景就不太实用。 按照 Spring Cache 框架给我们提供的 RedisCacheManager 实现,只能在全局设置缓存有效期。这…...

微信小程序前端开发
目录 前言: 1. 框架选择和项目搭建 2. 小程序页面开发 3. 数据通信和接口调用 4. 性能优化和调试技巧 5. 小程序发布和上线 前言: 当谈到微信小程序前端开发时,我们指的是使用微信小程序框架进行开发的一种方式。在本文中,我…...

C# OpenCvSharp DNN HybridNets 同时处理车辆检测、可驾驶区域分割、车道线分割
效果 项目 代码 using OpenCvSharp; using OpenCvSharp.Dnn; using System; using System.Collections.Generic; using System.Drawing; using System.IO; using System.Linq; using System.Numerics; using System.Text; using System.Windows.Forms;namespace OpenCvSharp_D…...
无需开发,精臣云可轻松连接用户运营、广告推广等行业应用
精臣智慧标识科技有限公司简介 武汉精臣智慧标识科技有限公司,是国内便携式标签打印机创新品牌和实物管理解决方案服务商。在物品标签还处在繁琐的PC打印时代,精臣公司便创造性地从智能便携角度出发,顺应移动互联时代趋势,推出了…...

第三阶段第一章——PySpark实战
学习了这么多python的知识,是时候来搞点真玩意儿了~~ 春风得意马蹄疾,一日看尽长安花 o(* ̄︶ ̄*)o 1.前言介绍 (1)什么是spark Apache Spark是一个开源的分布式计算框架,用于处理大规模数据集的…...
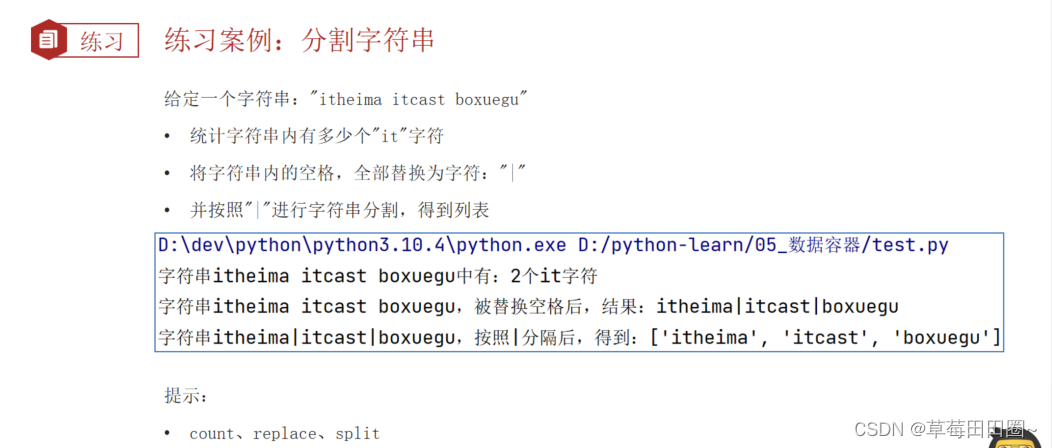
Python数据容器(字符串)
字符串 1.字符串 字符串也是数据容器的一种,字符串是字符的容器,一个字符串可以存放任意数量的字符。 2.字符串的下标索引 从前向后,下标从0开始从后向前,下标从-1开始 # 通过下标索引获取特定位置的字符 name python print(na…...
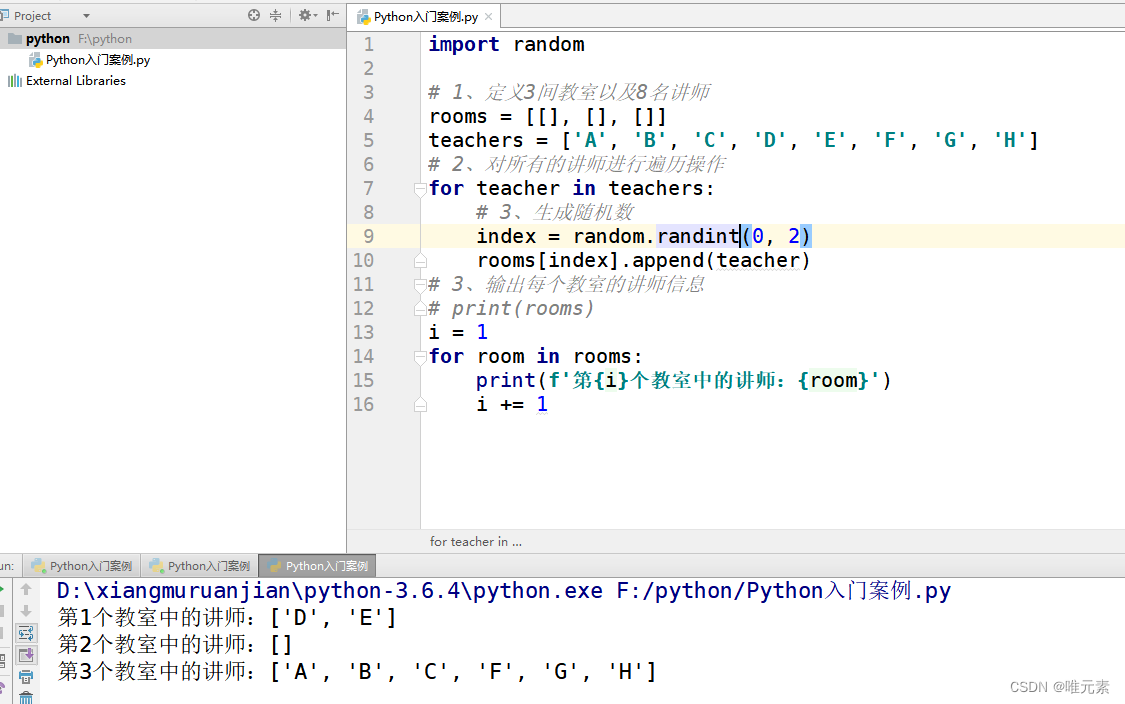
Python---练习:把8名讲师随机分配到3个教室
案例:把8名讲师随机分配到3个教室 列表嵌套:有3个教室[[],[],[]],8名讲师[A,B,C,D,E,F,G,H],将8名讲师随机分配到3个教室中。 分析: 思考1:我们第一间教室、第二间教室、第三间教室,怎么表示…...

效果实测:AI全身全息感知镜像在复杂动作下的识别精度展示
效果实测:AI全身全息感知镜像在复杂动作下的识别精度展示 1. 引言:全息感知技术的突破性进展 在虚拟现实、智能健身和远程协作等新兴领域,精准捕捉人体动作一直是个技术难题。传统方案要么需要昂贵的专业设备,要么只能识别单一维…...

初试FreeRTOS:创建上位机接收数据驱动个舵机任务,如裸机般无感
本课概览 Microsoft Agent Framework (MAF) 提供了一套强大的 Workflow(工作流) 框架,用于编排和协调多个智能体(Agent)或处理组件的执行流程。 本课将以通俗易懂的方式,帮助你理解 MAF Workflow 的核心概念…...
)
Windows 11下ROS2 Humble与PyCharm环境搭建全攻略(附常见错误解决方案)
Windows 11下ROS2 Humble与PyCharm环境搭建全攻略(附常见错误解决方案) 在机器人操作系统(ROS)生态中,Windows平台的支持一直是个痛点。随着ROS2 Humble版本的发布,微软与开源社区的深度合作为Windows开发者…...

UE4/UE5委托实战避坑:从触发器交互到UI响应,手把手教你四种委托的正确用法
UE4/UE5委托实战避坑指南:从触发器交互到UI响应的四种委托深度解析 在虚幻引擎开发中,委托系统是实现对象间通信的核心机制之一。很多开发者虽然了解基础语法,但在实际项目中面对触发器交互、UI响应等具体场景时,常常陷入选择困境…...
)
宝塔面板7.9.0强制登录?手把手教你三种绕过方法(含恢复教程)
宝塔面板7.9.0强制登录机制解析与安全绕过方案实践指南 最近不少运维同行反馈,宝塔面板7.9.0版本开始强制要求账户登录才能使用完整功能。对于需要快速部署环境又希望保持操作简洁的技术人员来说,这个变化确实带来了一些困扰。今天我们就从技术实现角度&…...
)
AGI训练数据版权困局全解密(含OpenAI、Anthropic、通义实验室三方诉讼实证)
第一章:AGI的知识产权与专利分析 2026奇点智能技术大会(https://ml-summit.org) 通用人工智能(AGI)作为前沿技术交叉领域,其知识产权格局呈现高度动态性与跨国性。全球主要专利局数据显示,2020–2024年间AGI相关发明…...
)
AGI的认知发育曲线 vs 人类儿童:2026奇点大会发布的首份跨模态神经符号成长图谱(含127个可迁移认知里程碑)
第一章:2026奇点智能技术大会:AGI与认知科学 2026奇点智能技术大会(https://ml-summit.org) 本届大会首次设立“AGI-Neuro Interface”联合实验室展台,聚焦大语言模型与人类工作记忆建模的交叉验证。来自MIT McGovern研究所与DeepMind联合团…...
)
别再死磕公式了!用MATLAB手把手复现DIC中的FA-GN与IC-GN算法(附完整代码)
MATLAB实战:从零实现DIC中的FA-GN与IC-GN算法 在材料力学、生物医学等领域的变形测量中,数字图像相关技术(Digital Image Correlation, DIC)已成为不可或缺的工具。但对于初学者而言,如何将复杂的数学公式转化为可运行…...

猫抓Cat-Catch:终极网页资源嗅探与下载解决方案
猫抓Cat-Catch:终极网页资源嗅探与下载解决方案 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾为无法保存心爱的在线视频而烦…...
)
STM32F103C8T6新手避坑指南:用软件IIC读取MPU6050原始数据,串口打印实测(附完整工程)
STM32F103C8T6实战:从零搭建MPU6050数据采集系统(附避坑手册) 第一次接触STM32和MPU6050传感器时,我花了整整三天时间才让串口成功输出数据。期间经历了IIC通信失败、数据异常、硬件连接错误等各种问题。本文将分享这些实战经验&a…...