单链表--C语言版(从0开始,超详细解析,小白一看就会)
目录
一、前言
🍎 为什么要学习链表
💦顺序表有缺陷
💦 优化方案:链表
二、链表详解
🍐链表的概念
🍉链表的结构组成:节点
🍓链表节点的连接(逻辑结构与物理结构的区分)
🍌链表的分类
🍊单链表各个接口的实现
⭕接口1:定义结构体SLTNode
⭕接口2:创建一个新的节点(SLTNode* BuySLTNode)
⭕接口3:单链表创建连续的节点(SLTNode* CreateSlist)
⭕接口4:单链表的尾插(SLTPushBack)
⭕接口5:单链表的尾删(SLTPopBack)
⭕接口6:单链表的头插(SLTPushFront)
⭕接口7:单链表的头删( SLTPopFront)
⭕接口8:单链表的节点查找( SLTNode* SLTFind)
⭕接口9:单链表在pos位置之后插入数据x( SLTInsertAfter)
⭕接口10:单链表在pos位置之前插入数据x( SLTInsert)
⭕接口11:删除单链表中pos位置之后的数据( SLTEraseAfter)
⭕接口12:删除单链表中pos位置的数据( SLTErase)
⭕接口13:单链表的数值打印( SLTPrint)
⭕接口14:单链表的销毁( SLTDestory)
三、单链表的完整代码
🍇SList.h
🍋SList.c
🥝Test.c
🍍代码运行的菜单界面
四、共勉
一、前言
在之前的几篇文章中已经详细介绍了什么是数据结构,什么是线性表,什么是顺序表。其中线性表中包含了:数组、顺序表、链表、队列等。那么此刻为什么还要再去学习链表,链表在数据结构里面代表了什么呢?这里我将给大家依次解惑,让大家真正的搞懂数据结构,学习起来才更有动力!
🍎 为什么要学习链表
💦顺序表有缺陷
缺陷一:空间经常不够,需要扩容
1️⃣:根据上一节对顺序表的讲解大家都应该知道顺序表和数组的本质是差不多的,存放的数据都是连续的,but在需要进行尾插和头插等操作时,可能会出现空间不够,需要进行扩容的操作。
2️⃣:针对于扩容,这个度我们就很难掌控,扩容大了容易浪费空间,扩容小了又要重复性的进行反复扩容,影响效率。
缺陷二:插入或者删除数据是需要挪动大量的数据,效率低下
1️⃣:由于顺序表存放的数据都是连续的,当对顺序表进行头插时,需要将所有数据从后往前挪动,进行头删时,需要将所有数据从前往后挪动。因此我们发现顺序表对数据的插入和删除都需要挪动大量的数据,时间复杂度过高,导致效率低下。
💦 优化方案:链表
优化一:使用链表节点解决空间不够的情况
1️⃣:对于空间不够需要扩容的情况,我们采用malloc动态申请所需要的空间,需要存储一个数据就开辟一块空间,此时这一块空间就叫做---------节点。
优化二: 使用链表中节点与节点之间的关系解决复杂度高的问题
1️⃣:我们可以让前一个节点存放下一个节点的地址,让它们相互关联起来,当我们需要使用的时候,只需要修改当前节点所存储放的内存地址即可。
此时此刻大家看到链表有如此强大的功能,是不是很想看看链表到底是什么样子,接下来让我们一起去学习吧!

二、链表详解
🍐链表的概念
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,但链表在逻辑上是连续的,顺序的,而数据元素的逻辑顺序是通过链表中的指针连接次序实现的。

此时链表就像一个火车,由一个个节点连接起来,且节点是无序的,每一个车厢可以切换和插入去除(节点的插入和删除)。
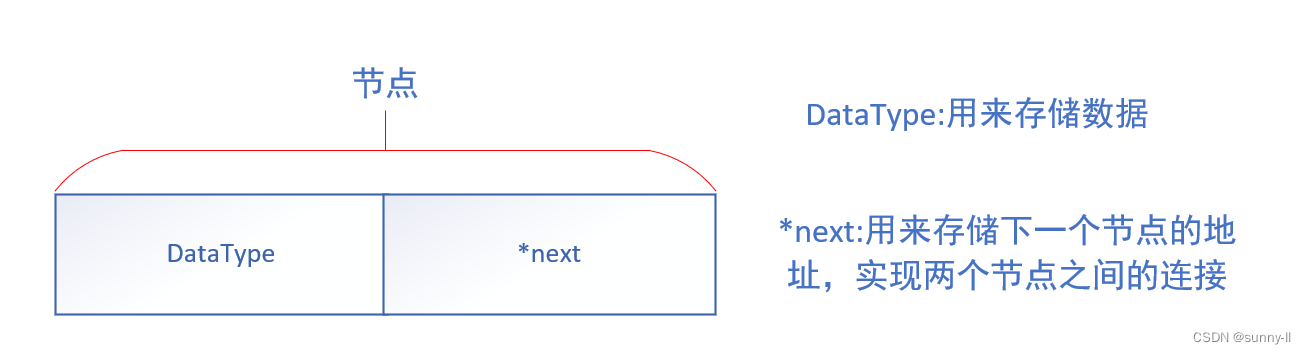
🍉链表的结构组成:节点
🔑链表是由一个个节点组成的。
🔑节点由俩个部分组成。
▶一部分用来存储数据,
▶另一部分用来存储下一个节点的地址。
🔑注意:节点在内存中是散乱分布的,它们是通过地址来寻找下一个节点。这和数组的连续存储有着很大的区别。
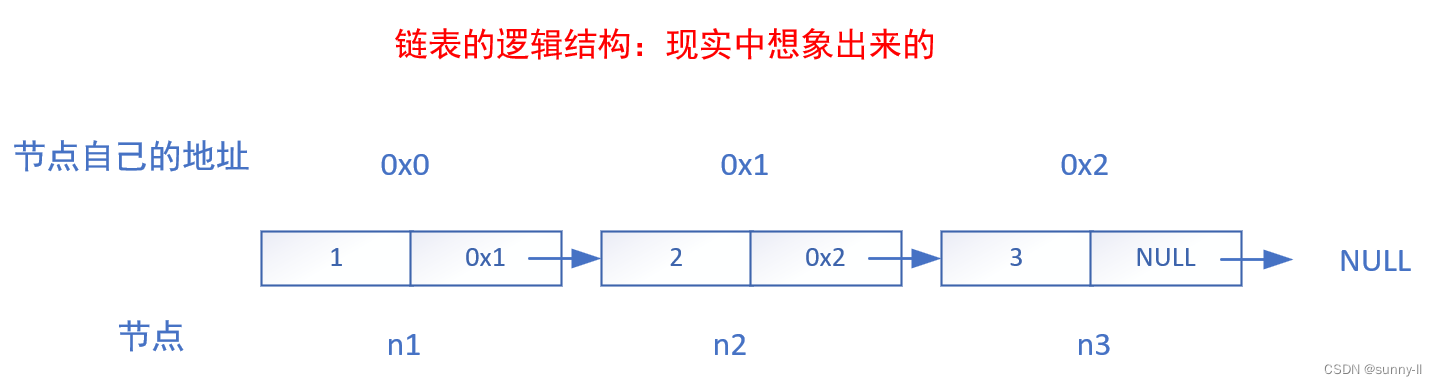
🍓链表节点的连接(逻辑结构与物理结构的区分)
💦链表的逻辑结构图:
注意:此时的链表是我们人为想象出来的,是为了让大家更好的去理解链表,现实中并不存在箭头,并且现实中每一个节点的地址都不一定连续,而且可能会离得很远。
💦链表的物理结构图:
总结:通过上面两个结构图,我们清楚的了解到,链表其实是通过指针地址来依次找到每一个节点。这也就是大家经常说的链表只在逻辑结构上连续(方便理解)在物理结构上不连续(实际情况)。

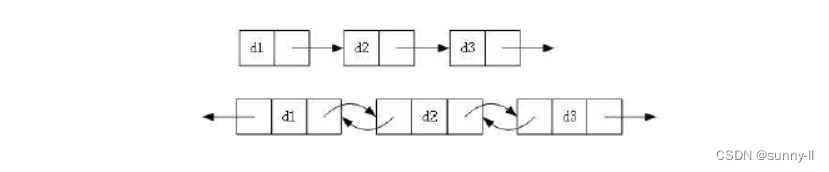
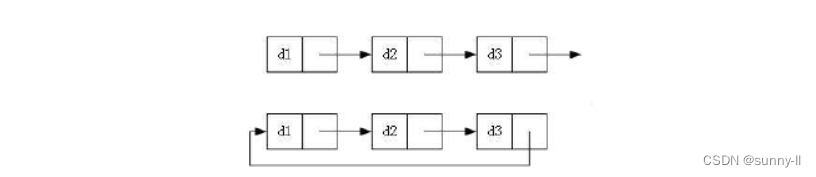
🍌链表的分类
1、单向或者双向
2、带头或者不带头
3、循环或者非循环
注意:我们经常使用的链表主要是单链表和带头双向循环链表,一个结构最简单,一个结构最复杂。
这里就给打击简单介绍一下这两种链表的特点以及用处:
▶无头单向非循环链表:也就是我们俗称的单链表。其结构简单,一般不会单独用来存储数据。实际上更多是作为其他数据结构的子结构,如哈希桶、栈的链式结构等。因为单链表本身有缺陷,所以为常见的考核点之一。
▶带头双向循环链表:结构最复杂,一般用来单独存储数据。实际使用的链表,大多都是带头双向循环链表。虽然这种链表结构最复杂,但是其实有很多优势,并且在一定程度上对单链表的缺陷做出了一定的纠正。

针对本次的博客分享呢,我呢先从结构最简单的单链表开始讲解!

🍊单链表各个接口的实现
这里先建立三个文件:
1️⃣ :SList.h文件,用于函数声明
2️⃣ :SList.c文件,用于函数的定义
3️⃣ :Test.c文件,用于测试函数
建立三个文件的目的: 将单链表作为一个项目来进行书写,方便我们的学习与观察。
⭕接口1:定义结构体SLTNode
🔑单链表的结构体由两个部分组成:
▶一部分用来存储数据,
▶另一部分用来存储下一个节点的地址。
typedef int SLTDataType; //数据类型 typedef struct SListNode {int data; // 每一个节点上存储的数据struct SListNode* next; // 在结构体内定义指针,用的时候需要开辟新的空间 ,在堆上开辟新的空间// 注意:这个 next指向的是结构体本身 的地址 ----> 在链表里面 此时 next 指向下一个结构体的地址。 }SLTNode;
⭕接口2:创建一个新的节点(SLTNode* BuySLTNode)
🔑函数原理:在堆上开辟一个新的空间,用于存放新的数据和下一个节点的地址
// 单链表创建一个新节点 // 此时返回的是 newnode (newnode是结构体指针,所以函数名为:SLNode* BuySLTNode(int x)) // 此时是一个传值调用(函数的形参与实参的转换) SLTNode* BuySLTNode(SLTDataType x) {// 1.开辟出结构本身的 内存空间 将空间地址 存放在 指针变量(结构体指针)newnode 中// 2.此时每一个结构体的 地址就完成了赋值SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); // 为这个结构体开辟空间并将首地址传递给结构体指针if (newnode == NULL) // 如果为空,表示申请失败{perror("malloc fail");exit(-1);}newnode->data = x; // 将这个节点的值,存放进去newnode->next = NULL; // 将这个节点的地址先设置为空,为后续的 节点二做准备(因为一般情况下next里面存放的是下一个节点的地址)return newnode; // 返回开辟的结构体本身的地址 }
⭕接口3:单链表创建连续的节点(SLTNode* CreateSlist)
🔑函数原理:根据接口2,形成一个完成的单链表
// 单链表创建连续的节点 SLTNode* CreateSlist(int n) {SLTNode* phead = NULL;SLTNode* ptail = NULL; //用于保存头节点for (int i = 0; i < n; i++){SListNode* newnode = BuySLTNode(i); //创建一个新的节点if (phead == NULL){ptail = phead = newnode; //开始在头节点的时候将 结构体指针 ptail,phead都指向 第一个创建的节点 }else // 当判断此时这个节点不是头节点的时候{ptail->next = newnode; // 先把此时这个节点的 新地址mewnode 传给next 以便于他们连接起来ptail = newnode; // 再把指针ptail 转移到这个节点,依次往后推,就形成了一条来链子一样的链表 }}return phead; // 返回头指针 } // 注意 :在局部变量里面的 phead 和 ptail 出了局部变量之后就会被销毁
⭕接口4:单链表的尾插(SLTPushBack)
🔑函数原理:在链表的尾部插入数据们需要考虑两点,当链表为空时直接插入。若链表不为空,先找到尾部在进行插入。
// 尾插 // 传址调用 // &plist=pphead *(&plist)=*pphead=plist *(*(&plist))=**pphead // 注意:pphead 是 plist 的拷贝 ------ pphead 的改变plist是不会改变的 void SLTPushBack(SLTNode** pphead, SLTDataType x) // pphead 是 plist的地址 ,*pphead 就是 plist, **pphead就是plist地址里面存放的东西 {// assert(phead); 此处不能进行断言,因为空链表也可以进行尾插SLTNode* newnode = BuySLTNode(x); //新插入的数据,和数据的地址if (*pphead == NULL) //判断是头节点是否为空{*pphead = newnode;}else{SLTNode* tail = *pphead; // 找尾巴while (tail->next != NULL) // 注意:我们此时寻找的是 指向下一个地址的 next {tail = tail->next; // tail向后移动一位}tail->next = newnode; // 将新的节点插入在尾部 同时 BuySTLNode(x) 将会是最后一个 next 指向空.} }注意:此时需要大家重视的是函数的二级指针传参问题,大家可以参考我上一篇文章,对函数的形参,实参的的深度理解。
https://blog.csdn.net/weixin_45031801/article/details/128069009
⭕接口5:单链表的尾删(SLTPopBack)
🔑函数原理:和单链表的尾插一样分两步进行
// 尾删 void SLTPopBack(SLTNode** pphead) {// 暴力检查assert(*pphead); // 防止链表已经删除完了,继续删除(空链表就不能尾删了)//温柔检查/*if (*pphead = NULL){return;}*/if ((* pphead)->next == NULL) //只有一个节点单独处理{free(*pphead);*pphead = NULL;}else{SLTNode* tail = *pphead; while (tail->next->next != NULL){tail = tail->next;}free(tail->next); //删除尾节点,将其从空间中除去tail->next = NULL; // 防止野指针的出现} }
⭕接口6:单链表的头插(SLTPushFront)
🔑函数原理:创建一个新的节点,接在原有的链表上即可
// 头插 void SLTPushFront(SLTNode** pphead, SLTDataType x) {SLTNode* newnode = BuySLTNode(x); //创建一个新的节点newnode->next = *pphead; //把原来的头节点给与next*pphead = newnode; //把新创建得节点变成头节点 }
⭕接口7:单链表的头删( SLTPopFront)
🔑函数原理:需要进行断言,判断函数头节点是否为空,同时保存第二个节点的地址
// 头删 注意:插入都不需要断言,删除需要断言,防止要删除得第一个为空 void SLTPopFront(SLTNode** pphead) {assert(*pphead); //断言SLTNode* next = (*pphead)->next; //先保存第二个节点得地址free(*pphead);*pphead = next; //将第二个节点地址,变为头节点地址 }
⭕接口8:单链表的节点查找( SLTNode* SLTFind)
🔑函数原理:进行链表的遍历查找即可
// 链表的查找 ---- 返回一个地址 // 有返回值,此时是传值调用 // 因为返回值是结构体里面的成员,所以返回函数为SLTNode* SLFind() // 实参传过来的是一个头节点地址,所以接收也是用指针形参接收 SLTNode* SLTFind(SLTNode* phead, SLTDataType x) {SLTNode* cur = phead; //保存头节点while (cur != NULL){if (cur->data == x){return cur;}cur = cur->next;}return NULL; }
⭕接口9:单链表在pos位置之后插入数据x( SLTInsertAfter)
🔑函数原理:根据接口9先找到pos的位置,在进行插入即可
// 单链表在pos位置之后插入x // 注意:此时改变的是结构体的成员--->next地址,并没有改变实际的数值 void SLTInsertAfter(SLTNode* p, SLTDataType x) //此时这里的 *p 是pos节点的地址 {assert(p); //检查 p 是否为空SLTNode* newnode = BuySLTNode(x); // 创建一个新的节点newnode->next = p->next; // 把原本pos下一个节点的位置传给newnode->nextp->next = newnode; // 再把newnode设置为pos位置的next }
⭕接口10:单链表在pos位置之前插入数据x( SLTInsert)
🔑函数原理:此时需要判断Pos的位置是否在头节点处,分情况处理
//在pos之前插入x // &plist=pphead *(&plist)=*pphead=plist *(*(&plist))=**pphead void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) {assert(pos); // 判断pos是否存在if(*pphead==pos) //如果pos就是头节点{SLTPushFront(pphead, x); //头插函数}else //pos不是头节点{SLTNode* prev = *pphead; //保存头节点while (prev->next != pos) //找到pos之前的位置{prev = prev->next;}SLTNode* newnode = BuySLTNode(x); //新建一个节点prev->next = newnode;newnode->next = pos;} }
⭕接口11:删除单链表中pos位置之后的数据( SLTEraseAfter)
🔑函数原理:找到pos位置,进行删除即可
void SLTEraseAfter(SLTNode* pos) {assert(pos); // 检查pos位置是否存在if (pos->next == NULL) //判断pos位置之后是否为空{return; //若是空,什么都不做}else{SLTNode* nextNode = pos->next; //此时需要将pos的next的地址换掉pos->next = nextNode->next;free(nextNode);} }
⭕接口12:删除单链表中pos位置的数据( SLTErase)
🔑函数原理:需要进行判断pos是否在头节点,分情况进行
//删除pos位置 // &plist=pphead *(&plist)=*pphead=plist *(*(&plist))=**pphead void SLTErase(SLTNode** pphead, SLTNode* pos) {assert(pos); //判断pos是否存在if (pos == *pphead) //如果pos位置在头部就是头删{SLTPopFront(pphead);}else{ SLTNode* prev = *pphead; //保存头节点while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);} }
⭕接口13:单链表的数值打印( SLTPrint)
// 单链表的数值打印 void SLTPrint(SLTNode* phead) // 这里的phead 与上边的phead 是不一样的 {// assert(phead); 此处不能进行断言,因为空链表也可以进行打印SLTNode* cur = phead;while (cur != NULL){//printf("%d-> ", cur->data); //打印出头节点的值//printf("\n");printf("%d->", cur->data);// 继续走向下一个节点// 因为每一个节点的 next 都是指向下一个节点的地址// 所以此时,将第一个节点的 next 传给 cur 就走向了下一个节点,直到最后一个节点 next 为空结束cur = cur->next;}printf("NULL\n"); }
⭕接口14:单链表的销毁( SLTDestory)
// 单链表的销毁 // 注意:顺序表是申请的一大块空间,销毁时就直接销毁了 // 注意:但是单链表是一个节点一个节点申请的,所以释放的时候也需要一个一个释放 // &plist=pphead *(&plist)=*pphead=plist *(*(&plist))=**pphead void SLTDestory(SLTNode** pphead) {SLTNode* cur = *pphead; //保存头节点while (cur != NULL){SLTNode* next = cur->next; //先保存下一个地址,在释放,防止到不到下一个地址free(cur);cur = next;}*pphead = NULL; // 将头指针制空,防止野指针出现,虽然释放了,但是地址依然存在,防止继续访问野指针 }

三、单链表的完整代码
🍇SList.h
#pragma once #include <stdio.h> #include <string.h> #include <stdlib.h> #include <math.h> #include <assert.h>typedef int SLTDataType; //数据类型 typedef struct SListNode {int data; // 每一个节点上存储的数据struct SListNode* next; // 在结构体内定义指针,用的时候需要开辟新的空间 ,在堆上开辟新的空间// 注意:这个 next指向的是结构体本身 的地址 ----> 在链表里面 此时 next 指向下一个结构体的地址。 }SLTNode;void SLTDestory(SLTNode** pphead); // 单链表的销毁SLTNode* BuySLTNode(SLTDataType x); // 将数据放在节点中,并返回节点的地址-----创建一个新节点.SLTNode* CreateSlist(int n); // 创建做需要的 节点个数 void SLTPrint(SLTNode* phead); // 打印输出单链表中的节点void SLTPushBack(SLTNode** pphead, SLTDataType x); // 尾插void SLTPushFront(SLTNode** pphead, SLTDataType x); // 头插void SLTPopBack(SLTNode** pphead); // 尾删void SLTPopFront(SLTNode** pphead); // 头删SLTNode* SLTFind(SLTNode* phead, SLTDataType x); //单链表的查找// 分析思考为什么不在pos位置之前插入呢? void SLTInsertAfter(SLTNode* pos, SLTDataType x); //单链表在pos位置之后插入x// 分析思考为什么不删除pos位置 void SLTEraseAfter(SLTNode* pos); //单链表删除pos位置之后的值void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x); //在pos之前插入xvoid SLTErase(SLTNode** pphead, SLTNode* pos); //删除pos位置// 总结:1.改变int,传递int* 给形参,*形参进行交换改变 // 2.改变int*,传递给int**给形参,*形参进行交换改变//在数组中 [] 其实解引用的意思
🍋SList.c
#define _CRT_SECURE_NO_WARNINGS 1 #include "SList.h"// 什么时候用到二级指针 :当需要改写时候进行使用 // 当程序只是进行 读 的时候就不需要用到二级指针// 单链表的销毁 // 注意:顺序表是申请的一大块空间,销毁时就直接销毁了 // 注意:但是单链表是一个节点一个节点申请的,所以释放的时候也需要一个一个释放 // &plist=pphead *(&plist)=*pphead=plist *(*(&plist))=**pphead void SLTDestory(SLTNode** pphead) {SLTNode* cur = *pphead; //保存头节点while (cur != NULL){SLTNode* next = cur->next; //先保存下一个地址,在释放,防止到不到下一个地址free(cur);cur = next;}*pphead = NULL; // 将头指针制空,防止野指针出现,虽然释放了,但是地址依然存在,防止继续访问野指针 }// 单链表创建一个新节点 // 此时返回的是 newnode (newnode是结构体指针,所以函数名为:SLNode* BuySLTNode(int x)) // 此时是一个传值调用(函数的形参与实参的转换) SLTNode* BuySLTNode(SLTDataType x) {// 1.开辟出结构本身的 内存空间 将空间地址 存放在 指针变量(结构体指针)newnode 中// 2.此时每一个结构体的 地址就完成了赋值SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); // 为这个结构体开辟空间并将首地址传递给结构体指针if (newnode == NULL) // 如果为空,表示申请失败{perror("malloc fail");exit(-1);}newnode->data = x; // 将这个节点的值,存放进去newnode->next = NULL; // 将这个节点的地址先设置为空,为后续的 节点二做准备(因为一般情况下next里面存放的是下一个节点的地址)return newnode; // 返回开辟的结构体本身的地址 }// 单链表创建连续的节点 SLTNode* CreateSlist(int n) {SLTNode* phead = NULL;SLTNode* ptail = NULL; //用于保存头节点for (int i = 0; i < n; i++){SListNode* newnode = BuySLTNode(i); //创建一个新的节点if (phead == NULL){ptail = phead = newnode; //开始在头节点的时候将 结构体指针 ptail,phead都指向 第一个创建的节点 }else // 当判断此时这个节点不是头节点的时候{ptail->next = newnode; // 先把此时这个节点的 新地址mewnode 传给next 以便于他们连接起来ptail = newnode; // 再把指针ptail 转移到这个节点,依次往后推,就形成了一条来链子一样的链表 }}return phead; // 返回头指针 } // 注意 :在局部变量里面的 phead 和 ptail 出了局部变量之后就会被销毁// 单链表的数值打印 void SLTPrint(SLTNode* phead) // 这里的phead 与上边的phead 是不一样的 {// assert(phead); 此处不能进行断言,因为空链表也可以进行打印SLTNode* cur = phead;while (cur != NULL){//printf("%d-> ", cur->data); //打印出头节点的值//printf("\n");printf("%d->", cur->data);// 继续走向下一个节点// 因为每一个节点的 next 都是指向下一个节点的地址// 所以此时,将第一个节点的 next 传给 cur 就走向了下一个节点,直到最后一个节点 next 为空结束cur = cur->next;}printf("NULL\n"); }// 尾插 // 传址调用 // &plist=pphead *(&plist)=*pphead=plist *(*(&plist))=**pphead // 注意:pphead 是 plist 的拷贝 ------ pphead 的改变plist是不会改变的 void SLTPushBack(SLTNode** pphead, SLTDataType x) // pphead 是 plist的地址 ,*pphead 就是 plist, **pphead就是plist地址里面存放的东西 {// assert(phead); 此处不能进行断言,因为空链表也可以进行尾插SLTNode* newnode = BuySLTNode(x); //新插入的数据,和数据的地址if (*pphead == NULL) //判断是头节点是否为空{*pphead = newnode;}else{SLTNode* tail = *pphead; // 找尾巴while (tail->next != NULL) // 注意:我们此时寻找的是 指向下一个地址的 next {tail = tail->next; // tail向后移动一位}tail->next = newnode; // 将新的节点插入在尾部 同时 BuySTLNode(x) 将会是最后一个 next 指向空.} }// 尾删 void SLTPopBack(SLTNode** pphead) {// 暴力检查assert(*pphead); // 防止链表已经删除完了,继续删除(空链表就不能尾删了)//温柔检查/*if (*pphead = NULL){return;}*/if ((* pphead)->next == NULL) //只有一个节点单独处理{free(*pphead);*pphead = NULL;}else{SLTNode* tail = *pphead; while (tail->next->next != NULL){tail = tail->next;}free(tail->next); //删除尾节点,将其从空间中除去tail->next = NULL; // 防止野指针的出现} }// ******* 单链表的优势就在于 头删和头插 ********** // 注意:插入都不需要断言,删除需要断言,防止要删除得第一个为空 // 头插 void SLTPushFront(SLTNode** pphead, SLTDataType x) {SLTNode* newnode = BuySLTNode(x); //创建一个新的节点newnode->next = *pphead; //把原来的头节点给与next*pphead = newnode; //把新创建得节点变成头节点 }// 头删 注意:插入都不需要断言,删除需要断言,防止要删除得第一个为空 void SLTPopFront(SLTNode** pphead) {assert(*pphead); //断言SLTNode* next = (*pphead)->next; //先保存第二个节点得地址free(*pphead);*pphead = next; //将第二个节点地址,变为头节点地址 }// 链表的查找 ---- 返回一个地址 // 有返回值,此时是传值调用 // 因为返回值是结构体里面的成员,所以返回函数为SLTNode* SLFind() // 实参传过来的是一个头节点地址,所以接收也是用指针形参接收 SLTNode* SLTFind(SLTNode* phead, SLTDataType x) {SLTNode* cur = phead; //保存头节点while (cur != NULL){if (cur->data == x){return cur;}cur = cur->next;}return NULL; }// 单链表在pos位置之后插入x // 注意:此时改变的是结构体的成员--->next地址,并没有改变实际的数值 void SLTInsertAfter(SLTNode* p, SLTDataType x) //此时这里的 *p 是pos节点的地址 {assert(p); //检查 p 是否为空SLTNode* newnode = BuySLTNode(x); // 创建一个新的节点newnode->next = p->next; // 把原本pos下一个节点的位置传给newnode->nextp->next = newnode; // 再把newnode设置为pos位置的next }//在pos之前插入x // &plist=pphead *(&plist)=*pphead=plist *(*(&plist))=**pphead void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) {assert(pos); // 判断pos是否存在if(*pphead==pos) //如果pos就是头节点{SLTPushFront(pphead, x); //头插函数}else //pos不是头节点{SLTNode* prev = *pphead; //保存头节点while (prev->next != pos) //找到pos之前的位置{prev = prev->next;}SLTNode* newnode = BuySLTNode(x); //新建一个节点prev->next = newnode;newnode->next = pos;} }//单链表删除pos位置之后的值 void SLTEraseAfter(SLTNode* pos) {assert(pos); // 检查pos位置是否存在if (pos->next == NULL) //判断pos位置之后是否为空{return; //若是空,什么都不做}else{SLTNode* nextNode = pos->next; //此时需要将pos的next的地址换掉pos->next = nextNode->next;free(nextNode);} }//删除pos位置 // &plist=pphead *(&plist)=*pphead=plist *(*(&plist))=**pphead void SLTErase(SLTNode** pphead, SLTNode* pos) {assert(pos); //判断pos是否存在if (pos == *pphead) //如果pos位置在头部就是头删{SLTPopFront(pphead);}else{ SLTNode* prev = *pphead; //保存头节点while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);} }
🥝Test.c
#define _CRT_SECURE_NO_WARNINGS 1 // ------- 单链表 ----------//// 顺序表的缺陷: // 1. 空间不够,需要扩容 (realloc) // 扩容 (尤其是异地扩容) 是有一定的代价的。 // 其次还可能存在一定的空间浪费 // 2.头部或者中部的插入删除,需要挪动数据,效率低下.// 改进优化: (链表的出现) // 1. 按需申请释放.(按照需求去申请释放)(用指针将他们连接起来) // 2. 不要挪动数据. // 3. 存储数据的空间叫做节点(结点)#include "SList.h"// 创建一个链表----进行每一个节点的测试 void TestSList1() {// BuySLTNode()函数 :求出每一个节点的地址// SLTNode * n :表示指针变量,将每个节点的地址传给指针变量// 也就是说,每次都是不同的结构体,但是每一个结构体的类型都是相同的/*SLTNode* n1 = BuySLTNode(1); SLTNode* n2 = BuySLTNode(2); SLTNode* n3 = BuySLTNode(3);SLTNode* n4 = BuySLTNode(4);n1->next = n2;n2->next = n3;n3->next = n4;n4->next = NULL;*/// 例如创建一个 n 个节点的链表SLTNode* plist = CreateSlist(4); // 此时就创建了 一个链表 有4个链子SLTPrint(plist); // 0->1->2->3->NULL }// 创建一个链表,并且进行尾插的测试 void TestSList2() {SLTNode* plist = CreateSlist(4); // 此时就创建了 一个链表 有4个链子SLTPushBack(&plist, 100);SLTPrint(plist); // 0->1->2->3->100->NULLSLTDestory(&plist); //进行销毁单链表SLTPrint(plist); } // 不创建链表,直接进行尾插. void TestSList3() {SLTNode* plist = NULL;SLTPushBack(&plist, 100);SLTPushBack(&plist, 200);SLTPushBack(&plist, 300);SLTPrint(plist); }// 尾删. void TestSList4() {SLTNode* plist = NULL;SLTPushBack(&plist, 100);SLTPushBack(&plist, 200);SLTPushBack(&plist, 300);SLTPrint(plist);SLTPopBack(&plist);SLTPrint(plist);SLTPopBack(&plist);SLTPrint(plist);SLTPopBack(&plist);SLTPrint(plist); SLTPopBack(&plist);SLTPrint(plist); }// 头插. void TestSList5() {SLTNode* plist = NULL;SLTPushBack(&plist, 100);SLTPushBack(&plist, 200);SLTPushBack(&plist, 300);SLTPrint(plist);SLTPushFront(&plist, 20);SLTPrint(plist); } // 头删 (头删是单链表的优势). void TestSList6() {SLTNode* plist = NULL;SLTPushBack(&plist, 100);SLTPushBack(&plist, 200);SLTPushBack(&plist, 300);SLTPrint(plist);SLTPopFront(&plist);SLTPrint(plist); } // 单链表的查找. void TestSList7() {SLTNode* plist = NULL;SLTPushBack(&plist, 100);SLTPushBack(&plist, 200);SLTPushBack(&plist, 300);SLTPrint(plist);SLTNode* pos = SLTFind(plist, 300);if (pos != NULL){printf("找到了\n");}else{printf("找不到\n");}SLTPrint(pos); } // 单链表在pos位置之后插入数据. void TestSList8() {SLTNode* plist = NULL;SLTPushBack(&plist, 100);SLTPushBack(&plist, 200);SLTPushBack(&plist, 300);SLTPrint(plist);SLTNode* pos = SLTFind(plist, 200);if (pos != NULL){SLTInsertAfter(pos, 30); // 插入数据30.printf("找到了\n");}else{printf("找不到\n");}SLTPrint(plist); } // 单链表在pos位置之前插入数据. void TestSList9() {SLTNode* plist = NULL;SLTPushBack(&plist, 100);SLTPushBack(&plist, 200);SLTPushBack(&plist, 300);SLTPushBack(&plist, 400);SLTPushBack(&plist, 500);SLTPrint(plist);SLTNode* pos = SLTFind(plist, 300);if (pos != NULL){SLTInsert(&plist,pos, 30); // 插入数据30.printf("找到了\n");}else{printf("找不到\n");}SLTPrint(plist); } // 单链表删除pos位置之后的节点. void TestSList10() {SLTNode* plist = NULL;SLTPushBack(&plist, 100);SLTPushBack(&plist, 200);SLTPushBack(&plist, 300);SLTPushBack(&plist, 400);SLTPushBack(&plist, 500);SLTPrint(plist);SLTNode* pos = SLTFind(plist, 500);if (pos != NULL){SLTEraseAfter(pos); // 删除pos位置之后的数据.printf("找到了\n");}else{printf("找不到\n");}SLTPrint(plist); } // 单链表中删除pos位置 void TestSList11() {SLTNode* plist = NULL;SLTPushBack(&plist, 100);SLTPushBack(&plist, 200);SLTPushBack(&plist, 300);SLTPushBack(&plist, 400);SLTPushBack(&plist, 500);SLTPrint(plist);SLTNode* pos = SLTFind(plist, 300);if (pos != NULL){SLTErase(&plist, pos); // 删除pos位置之后的数据.printf("找到了\n");}else{printf("找不到\n");}SLTPrint(plist); } void menu() {printf("***********************************************************\n");printf("1、头插节点 2、头删节点 \n");printf("\n");printf("3、尾插节点 4、尾删节点 \n");printf("\n");printf("5、在单链表中查找pos数据 6、在单链表pos位置之后插入一个新的节点\n");printf("\n");printf("7、删除单链表pos位置之后的节点 8、在单链表pos位置之前插入新的节点 \n");printf("\n");printf("9、在单链表中删除pos位置的数据 10、打印数据 \n");printf("\n");printf("-1、退出 \n");printf("***********************************************************\n");} int main() {printf("*************** 欢迎大家来到单链表的测试 ****************\n");int option = 0;SLTNode* plist = NULL;SLTNode* pos = NULL;do{menu();printf("请输入你的操作:>");scanf("%d", &option);int sum = 0; int x = 0;int y = 0;int z = 0;int w = 0;int a = 0;int b = 0;int c = 0;int d = 0;switch (option){case 1:printf("请依次输入你要尾插的数据:,以-1结束\n");scanf("%d", &sum);while (sum != -1){SLTPushBack(&plist, sum); // 1.头插scanf("%d", &sum);}break;case 2:SLTPopFront(&plist); // 2.头删break;case 3:printf("请输入想要尾插的数据:");scanf("%d", &x); // 3.尾插SLTPushBack(&plist, x);break;case 4:SLTPopBack(&plist); // 4.尾删break;case 5: printf("请输入想要查找的pos数据:");scanf("%d", &y);pos = SLTFind(plist, y);if (pos != NULL) // 5.在单链表中查找pos数据{printf("找到了\n");}else{printf("找不到pos位置\n");}break;case 6: // 6.在单链表pos位置后插入一个新的节点printf("请输入想要查找的pos数据:");scanf("%d", &z);pos = SLTFind(plist, z);if (pos != NULL){printf("请输入想要在pos位置后插入的数据:");scanf("%d", &w);SLTInsertAfter(pos, w); // 插入数据w.}else{printf("找不到pos位置,无法插入\n");}break;case 7:printf("请输入想要查找的pos数据:");scanf("%d", &a);pos = SLTFind(plist, a); if (pos != NULL){SLTEraseAfter(pos); // 7.删除pos位置之后的数据.}else{printf("找不到pos位置,无法删除\n");}break;case 8:printf("请输入想要查找的pos数据:");scanf("%d", &b);pos = SLTFind(plist, b);if (pos != NULL){printf("请输入想要在pos位置后插入的数据:");scanf("%d", &c);SLTInsert(&plist, pos, c); // 在单链表pos位置之前插入数据c.}else{printf("找不到pos位置,无法插入\n");}break;case 9:printf("请输入想要查找的pos数据:");scanf("%d", &d);pos = SLTFind(plist, d);if (pos != NULL){SLTErase(&plist, pos); // 删除pos位置的数据.}else{printf("找不到pos位置,无法删除\n");}case 10:SLTPrint(plist);break;default:if (option == -1){exit(0); // 退出程序 }else{printf("输入错误,请重新输入\n");}break;}} while (option != -1);return 0; }
🍍代码运行的菜单界面

四、共勉
以下就是我对数据结构---单链表的理解,如果有不懂和发现问题的小伙伴,请在评论区说出来哦,同时我还会继续更新对数据结构-------单链表OJ,请持续关注我哦!!!!!


相关文章:
单链表--C语言版(从0开始,超详细解析,小白一看就会)
目录 一、前言 🍎 为什么要学习链表 💦顺序表有缺陷 💦 优化方案:链表 二、链表详解 🍐链表的概念 🍉链表的结构组成:节点 🍓链表节点的连接(逻辑结构与物理结构的区…...
)
cv2-特征点匹配(bf、FLANN)
cv2-特征点匹配(bf、KNN、FLANN) 文章目录cv2-特征点匹配(bf、KNN、FLANN)1. 暴力匹配法(bf)1.1 bf.match()1.2 bf.knnMatch()3. FLANN匹配法4. 总结1. 暴力匹配法(bf) (…...
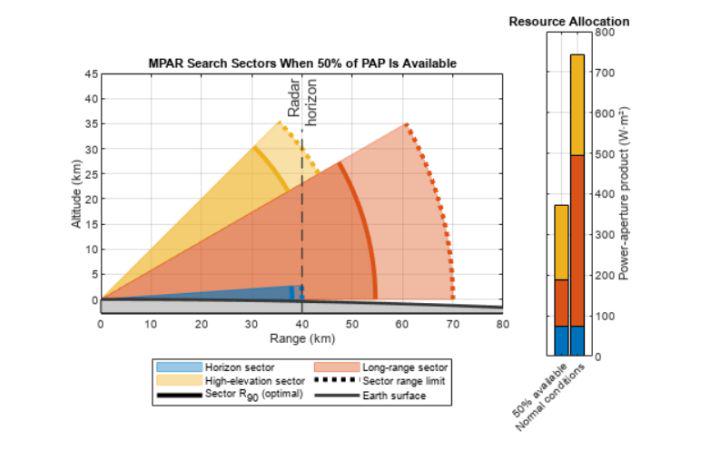
基于matlab多功能相控阵雷达资源管理的服务质量优化
一、前言此示例说明如何为基于服务质量 (QoS) 优化的多功能相控阵雷达 (MPAR) 监控设置资源管理方案。它首先定义必须同时调查的多个搜索扇区的参数。然后,它介绍了累积检测范围作为搜索质量的度量,并展示了…...
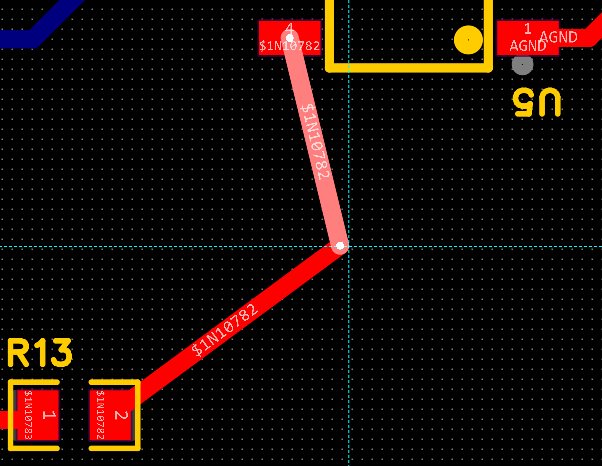
立创eda专业版学习笔记(6)(pcb板移动节点)
先要看一个设置方面的东西: 进入设置-pcb-通用 我鼠标放到竖着的线上面,第一次点左键是这样选中的: 再点一次左键是这样选中的: 这个时候,把鼠标放到转角的地方,点右键,就会出现对于节点的选项…...

Java面试——MyBatis相关知识
目录 1.什么是MyBatis 2.MyBatis优缺点 3.MyBatis工作原理 4.MyBatis缓存模式 5.MyBatis代码相关问题 6.MyBatis和hibernate区别 1.什么是MyBatis MyBatis是一个半ORM持久层框架(对象关系映射),基于JDBC进行封装,使得开发者…...
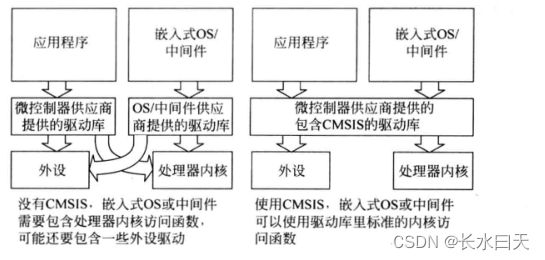
Cortex-M0编程入门
目录1.嵌入式系统编程入门微控制器是如何启动的嵌入式程序设计2.输入和输出3.开发流程4.C编程和汇编编程5.什么是程序映像6.C编程:数据类型7.用C语言操作外设8.Cortex微控制器软件接口标准(CMSIS)简介标准化内容组织结构使用方法优势1.嵌入式…...

字符串函数能有什么坏心思?
🚀write in front🚀 📝个人主页:认真写博客的夏目浅石. 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:夏目的C语言宝藏 💬总结:希望你看完之…...
Vue3 组件之间的通信
组件之间的通信 经过前面几章的阅读,相信开发者已经可以搭建一个基础的 Vue 3 项目了! 但实际业务开发过程中,还会遇到一些组件之间的通信问题,父子组件通信、兄弟组件通信、爷孙组件通信,还有一些全局通信的场景。 …...
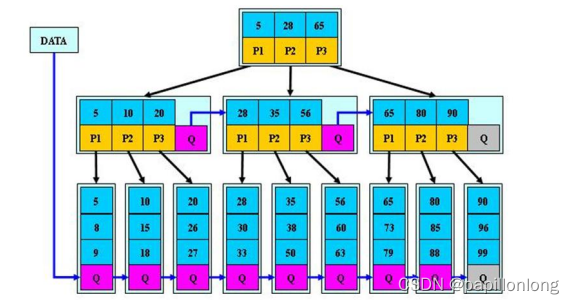
多路查找树
1.二叉树与 B 树 1.1二叉树的问题分析 二叉树的操作效率较高,但是也存在问题, 请看下面的二叉树 二叉树需要加载到内存的,如果二叉树的节点少,没有什么问题,但是如果二叉树的节点很多(比如 1 亿), 就 存在如下问题:问…...

Mybatis——注入执行sql查询、更新、新增以及建表语句
文章目录前言案例dao和mapper编写XXXmapper.xml编写编写业务层代码,进行注入调用额外扩展--创建表语句前言 在平时的项目开发中,mybatis应用非常广泛,但一般都是直接CRUD类型sql的执行。 本片博客主要说明一个另类的操作,注入sq…...

即时通讯系列-4-如何设计写扩散下的同步协议方案
1. 背景信息 上篇提到了, IM协议层是主要解决会话和消息的同步, 在实现上, 以推模式为主, 拉模式为辅. 本文Agenda: (How)如何同步(How)如何设计同步位点如何设计 Gap过大(SyncGapOverflow) 机制如何设计Ack机制总结 提示: 本系列文章不会单纯的给出结论, 希望能够分享的是&…...

tui-swipe-action组件上的按钮点击后有阴影的解决方法
大家好,我是雄雄,欢迎关注微信公众号:雄雄的小课堂。 目录 前言问题描述问题解决前言 一直未敢涉足电商领域,总觉得这里面的道道很多,又是支付、又是物流的,还涉及到金钱,所以我们所做的项目,一直都是XXXX管理系统,XXX考核系统,移动端的也是,XX健康管理平台…… 但…...

【大数据Hadoop】Hadoop 3.x 新特性总览
Hadoop 3.x 新特性剖析系列11. 概述2. 内容2.1 JDK2.2 EC技术2.3 YARN的时间线V.2服务2.3.1 伸缩性2.3.2 可用性2.3.3 架构体系2.4 优化Hadoop Shell脚本2.5 重构Hadoop Client Jar包2.6 支持等待容器和分布式调度2.7 支持多个NameNode节点2.8 默认的服务端口被修改2.9 支持文件…...

Python-第三天 Python判断语句
Python-第三天 Python判断语句一、 布尔类型和比较运算符1.布尔类型2.比较运算符二、if语句的基本格式1.if 判断语句语法2.案例三、 if else 语句1.语法2.案例四 if elif else语句1.语法五、判断语句的嵌套1.语法六、实战案例一、 布尔类型和比较运算符 1.布尔类型 布尔&…...

失手删表删库,赶紧跑路?!
在数据资源日益宝贵的数字时代公司最怕什么?人还在,库没了是粮库、车库,还是小金库?实际上,这里的“库”是指的数据库Ta是公司各类信息的保险柜小到企业官网和客户信息大到金融机构的资产数据和国家秘密即便没有跟数据…...
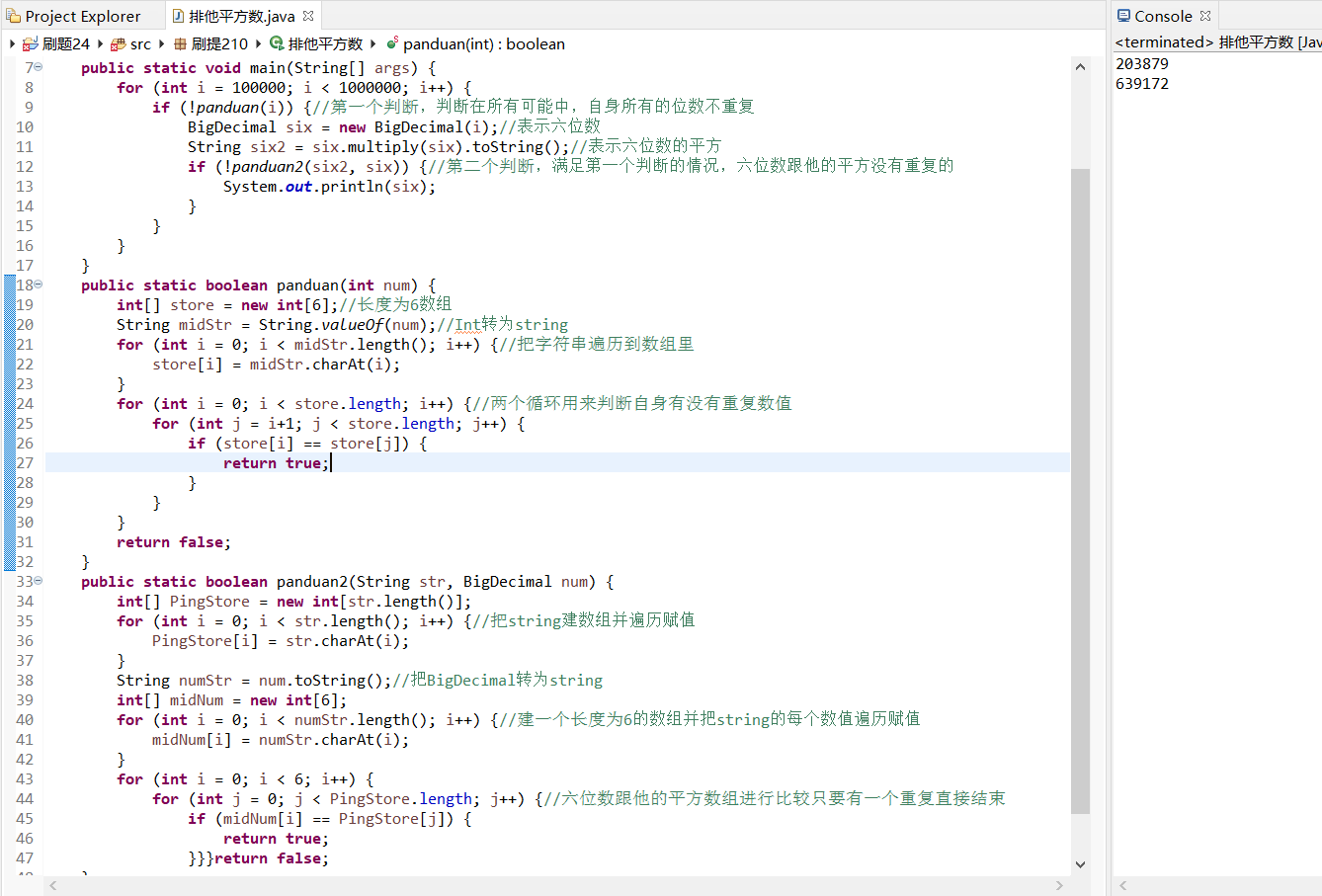
技术树基础——16排它平方数(Bigdecimal,int,string,数组的转换)
题目:03879 * 203879 41566646641这有什么神奇呢?仔细观察,203879 是个6位数,并且它的每个数位上的数字都是不同的,并且它平方后的所有数位上都不出现组成它自身的数字。具有这样特点的6位数还有一个,请你…...

04动手实践:手把手带你实现gRPC的Hello World
这篇文章就从实践的角度出发,带大家一起体验一下gRPC的Hello World。文中的代码将全部使用Go语言实现,使用到的示例也是GitHub上提供的grpc-go,下面我们开始: Hello World官方示例 首先我们要clone GitHub上gRPC的源代码到我们本地 git clone https://github.com/grpc/g…...

区块链技术与应用1——BTC-密码学原理
文章目录比特币中的密码学原理1. 哈希函数2. 数字签名3. 比特币中的哈希函数和数字签名简单介绍:比特币与以太坊都是以区块链技术为基础的两种加密货币,因为他们应用最广泛,所以讲区块链技术一般就讲比特币和以太坊。比特币中的密码学原理 1…...

PyTorch学习笔记:data.WeightedRandomSampler——数据权重概率采样
PyTorch学习笔记:data.WeightedRandomSampler——数据权重概率采样 torch.utils.data.WeightedRandomSampler(weights, num_samples, replacementTrue, generatorNone)功能:按给定的权重(概率)[p0,p1,…,pn−1][p_0,p_1,\dots,p_{n-1}][p0,p1,…,pn…...

SpringMVC对请求参数的处理
如何获取SpringMVC中请求中的信息 ? 默认情况下,可以直接在方法的参数中填写跟请求参数一样的名称,此时会默认接受参 数 ,如果有值,直接赋值,如果没有,那么直接给空值 。Controller RequestMapp…...

保姆级教程:在银河麒麟V10桌面版上,用Docker容器化部署SpringBoot + 达梦数据库应用
银河麒麟V10桌面版容器化实战:SpringBoot与达梦数据库的Docker化部署指南 在国产化技术栈日益成熟的今天,将传统应用迁移到容器化环境已成为提升部署效率和系统可移植性的关键路径。银河麒麟V10作为国产操作系统的代表,结合飞腾CPU的硬件生态…...

零基础玩转CTFShow Web1-7:手把手教你用Burp Suite和蚁剑拿flag
零基础玩转CTFShow Web1-7:从工具配置到实战渗透全指南 第一次接触CTF比赛时,看着其他选手在终端里敲出神秘代码就能拿到flag,总觉得这是黑客才能掌握的"黑魔法"。直到自己动手尝试才发现,只要掌握正确的工具和方法&…...
)
告别手动建模!用Blender GIS插件5分钟搞定CARLA地图(附OSM数据源)
告别手动建模!用Blender GIS插件5分钟搞定CARLA地图(附OSM数据源) 在自动驾驶仿真领域,快速构建高精度地图一直是开发者的痛点。传统手动建模方式不仅耗时费力,还难以保证道路网络的拓扑准确性。现在,通过…...
)
CANoe实战:手把手教你用J1939.dbc发送超8字节长帧报文(附完整CAPL代码)
CANoe实战:J1939长帧报文分包发送全解析与CAPL代码优化 在汽车电子开发领域,J1939协议作为商用车通信标准,其长帧报文处理一直是工程师面临的典型挑战。当数据长度超过CAN总线单帧8字节限制时,如何高效实现分包传输?本…...

屠龙刀法35--使用SQL查询器批量生成insert语句
很多网友认为SQL查询器的语句不都是人工输入或者从外面粘贴进去的吗?用查询器批量生成Insert语句感觉有点魔幻哦。的确听起来不太科学,但是对于DBCS来说这个功能的确非常好用。下面我们就举例一步步告诉大家,如何使用这个功能。 第一步&…...

2026权威评测:盘点毕业论文AIGC免费降重神器
【CSDN 资深算法架构师 / NLP技术专栏 导读】 各位还在发际线边缘挣扎的应届生和硕博党们,到了2026年,如果你的电脑里还装着那种老掉牙的“同义词替换”降重软件,我劝你赶紧停手! 最近CSDN社群里哀嚎一片:“知网查重过…...

解锁新可能:ArkData 在智能穿戴设备中的应用
解锁新可能:ArkData 在智能穿戴设备中的应用随着人们对健康生活的重视,智能穿戴设备愈发普及。这些设备能够实时收集心率、步数、睡眠等健康数据,为人们的健康管理提供重要参考。在这一背景下,如何高效管理和利用这些健康数据成为…...

实战指南:基于快马生成电商订单自动化n8n工作流,无缝衔接shopify与crm
实战指南:基于快马生成电商订单自动化n8n工作流,无缝衔接shopify与crm 最近在帮朋友优化他们电商业务的后台流程,发现手动处理订单实在太费时间了。特别是遇到大促期间,订单量暴增,人工操作不仅效率低还容易出错。于是…...

HBuilderX + 极光推送踩坑实录:免费版为啥息屏收不到通知?手把手教你配置与避坑
HBuilderX与极光推送免费版避坑指南:破解息屏通知失效难题 早上八点,你的咖啡还没喝完,测试组的消息就炸开了锅——"昨晚推送的版本在息屏状态下根本收不到通知!"作为使用HBuilderX开发跨平台应用的团队,这个…...

实战演练:基于快马平台快速构建一个电商场景的智能客服AI Agent
实战演练:基于快马平台快速构建一个电商场景的智能客服AI Agent 最近在做一个电商项目,需要给平台增加智能客服功能。传统开发流程要写大量业务逻辑代码,还要处理前后端对接,想想就头大。后来发现用InsCode(快马)平台可以快速实现…...