365天深度学习训练营 第P6周:好莱坞明星识别
- 🍨 本文为🔗365天深度学习训练营 内部限免文章(版权归 K同学啊 所有)
- 🍦 参考文章地址: 🔗第P6周:好莱坞明星识别 | 365天深度学习训练营
- 🍖 作者:K同学啊 | 接辅导、程序定制
文章目录
- 我的环境:
- 一、前期工作
- 1. 设置 GPU
- 2. 导入数据
- 3. 划分数据集
- 二、调用vgg-16模型
- 三、训练模型
- 1. 设置超参数
- 2. 编写训练函数
- 3. 编写测试函数
- 4. 正式训练
- 四、结果可视化
- 1.Loss 与 Accuracy 图
我的环境:
- 语言环境:Python 3.6.8
- 编译器:jupyter notebook
- 深度学习环境:
- torch==0.13.1、cuda==11.3
- torchvision==1.12.1、cuda==11.3
一、前期工作
1. 设置 GPU
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torchvision import transforms, datasetsif __name__=='__main__':''' 设置GPU '''device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print("Using {} device\n".format(device))
Using cuda device
2. 导入数据
import os, PIL, pathlib
data_dir = 'D:/jupyter notebook/DL-100-days/datasets/48-data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[5] for path in data_paths]
print(classeNames)
['Angelina Jolie','Brad Pitt','Denzel Washington','Hugh Jackman','Jennifer Lawrence','Johnny Depp','Kate Winslet','Leonardo DiCaprio','Megan Fox','Natalie Portman','Nicole Kidman','Robert Downey Jr','Sandra Bullock','Scarlett Johansson','Tom Cruise','Tom Hanks','Will Smith']
train_transforms = transforms.Compose([transforms.Resize([224,224]),# resize输入图片transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换成tensortransforms.Normalize(mean = [0.485, 0.456, 0.406],std = [0.229,0.224,0.225]) # 从数据集中随机抽样计算得到
])total_data = datasets.ImageFolder(data_dir,transform=train_transforms)
total_data
Dataset ImageFolderNumber of datapoints: 1800Root location: hlwStandardTransform
Transform: Compose(Resize(size=[224, 224], interpolation=PIL.Image.BILINEAR)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
3. 划分数据集
train_size = int(0.8*len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data,[train_size,test_size])
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
二、调用vgg-16模型
from torchvision.models import vgg16model = vgg16(pretrained = True).to(device)
for param in model.parameters():param.requires_grad = Falsemodel.classifier._modules['6'] = nn.Linear(4096,len(classNames))model.to(device)
# 查看要训练的层
params_to_update = model.parameters()
# params_to_update = []
for name,param in model.named_parameters():if param.requires_grad == True:
# params_to_update.append(param)print("\t",name)
三、训练模型
1. 设置超参数
# 优化器设置
optimizer = torch.optim.Adam(params_to_update, lr=1e-4)#要训练什么参数/
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.92)#学习率每5个epoch衰减成原来的1/10
loss_fn = nn.CrossEntropyLoss()
2. 编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,一共900张图片num_batches = len(dataloader) # 批次数目,29(900/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
3. 编写测试函数
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,8(255/32=8,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
4. 正式训练
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
filename='checkpoint.pth'for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)scheduler.step()#学习率衰减model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)# 保存最优模型if epoch_test_acc > best_acc:best_acc = epoch_train_accstate = {'state_dict': model.state_dict(),#字典里key就是各层的名字,值就是训练好的权重'best_acc': best_acc,'optimizer' : optimizer.state_dict(),}torch.save(state, filename)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
print('best_acc:',best_acc)
Epoch: 1, Train_acc:12.2%, Train_loss:2.701, Test_acc:13.9%,Test_loss:2.544
Epoch: 2, Train_acc:20.8%, Train_loss:2.386, Test_acc:20.6%,Test_loss:2.377
Epoch: 3, Train_acc:26.1%, Train_loss:2.228, Test_acc:22.5%,Test_loss:2.274
…
Epoch:19, Train_acc:51.6%, Train_loss:1.528, Test_acc:35.8%,Test_loss:1.864
Epoch:20, Train_acc:53.9%, Train_loss:1.499, Test_acc:35.3%,Test_loss:1.852
Done
best_acc: 0.37430555555555556
四、结果可视化
1.Loss 与 Accuracy 图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
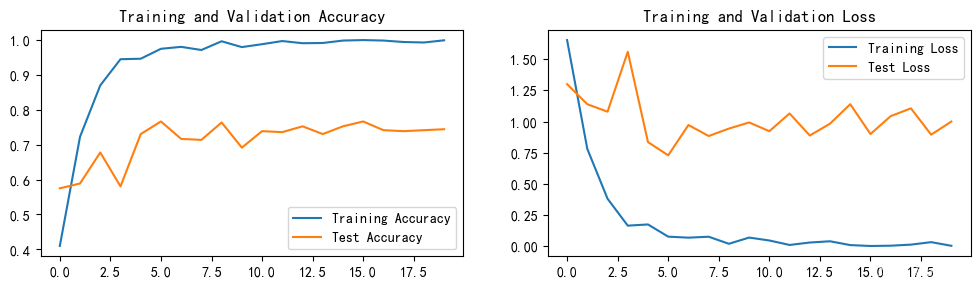
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
相关文章:
365天深度学习训练营 第P6周:好莱坞明星识别
🍨 本文为🔗365天深度学习训练营 内部限免文章(版权归 K同学啊 所有)🍦 参考文章地址: 🔗第P6周:好莱坞明星识别 | 365天深度学习训练营🍖 作者:K同学啊 | 接…...

一文读懂 Zebec Chain 的“先行网络” Nautilus 链
最近,Zebec 上线了 DAO 治理系统后,上线并通过了关于 Nautilus 链的提案,这也是DAO系统上线后通过的首个提案。 Nautilus 链可以被看作是Zebec Chain上线前的“先行”链,并且是目前行业内为数不多的以“Layer3”作为特点的模块化通…...

FuzzyMathematicalModel模糊数学模型-2-多目标模糊综合评价案例分享
主函数:clc, clear% 输入模糊矩阵的原型x [4700 6700 5900 8800 76005000 5500 5300 6800 600004.0 06.1 05.5 07.0 06.80030 0050 0040 0200 01601500 0700 1000 0050 0100];r muti_objective_fuzzy_analysis(x);% 各指标在决策中占的权重(专家系统,自…...

单链表--C语言版(从0开始,超详细解析,小白一看就会)
目录 一、前言 🍎 为什么要学习链表 💦顺序表有缺陷 💦 优化方案:链表 二、链表详解 🍐链表的概念 🍉链表的结构组成:节点 🍓链表节点的连接(逻辑结构与物理结构的区…...
)
cv2-特征点匹配(bf、FLANN)
cv2-特征点匹配(bf、KNN、FLANN) 文章目录cv2-特征点匹配(bf、KNN、FLANN)1. 暴力匹配法(bf)1.1 bf.match()1.2 bf.knnMatch()3. FLANN匹配法4. 总结1. 暴力匹配法(bf) (…...
基于matlab多功能相控阵雷达资源管理的服务质量优化
一、前言此示例说明如何为基于服务质量 (QoS) 优化的多功能相控阵雷达 (MPAR) 监控设置资源管理方案。它首先定义必须同时调查的多个搜索扇区的参数。然后,它介绍了累积检测范围作为搜索质量的度量,并展示了…...
立创eda专业版学习笔记(6)(pcb板移动节点)
先要看一个设置方面的东西: 进入设置-pcb-通用 我鼠标放到竖着的线上面,第一次点左键是这样选中的: 再点一次左键是这样选中的: 这个时候,把鼠标放到转角的地方,点右键,就会出现对于节点的选项…...

Java面试——MyBatis相关知识
目录 1.什么是MyBatis 2.MyBatis优缺点 3.MyBatis工作原理 4.MyBatis缓存模式 5.MyBatis代码相关问题 6.MyBatis和hibernate区别 1.什么是MyBatis MyBatis是一个半ORM持久层框架(对象关系映射),基于JDBC进行封装,使得开发者…...
Cortex-M0编程入门
目录1.嵌入式系统编程入门微控制器是如何启动的嵌入式程序设计2.输入和输出3.开发流程4.C编程和汇编编程5.什么是程序映像6.C编程:数据类型7.用C语言操作外设8.Cortex微控制器软件接口标准(CMSIS)简介标准化内容组织结构使用方法优势1.嵌入式…...

字符串函数能有什么坏心思?
🚀write in front🚀 📝个人主页:认真写博客的夏目浅石. 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:夏目的C语言宝藏 💬总结:希望你看完之…...
Vue3 组件之间的通信
组件之间的通信 经过前面几章的阅读,相信开发者已经可以搭建一个基础的 Vue 3 项目了! 但实际业务开发过程中,还会遇到一些组件之间的通信问题,父子组件通信、兄弟组件通信、爷孙组件通信,还有一些全局通信的场景。 …...
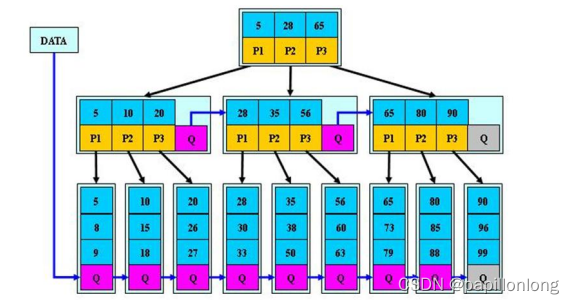
多路查找树
1.二叉树与 B 树 1.1二叉树的问题分析 二叉树的操作效率较高,但是也存在问题, 请看下面的二叉树 二叉树需要加载到内存的,如果二叉树的节点少,没有什么问题,但是如果二叉树的节点很多(比如 1 亿), 就 存在如下问题:问…...

Mybatis——注入执行sql查询、更新、新增以及建表语句
文章目录前言案例dao和mapper编写XXXmapper.xml编写编写业务层代码,进行注入调用额外扩展--创建表语句前言 在平时的项目开发中,mybatis应用非常广泛,但一般都是直接CRUD类型sql的执行。 本片博客主要说明一个另类的操作,注入sq…...

即时通讯系列-4-如何设计写扩散下的同步协议方案
1. 背景信息 上篇提到了, IM协议层是主要解决会话和消息的同步, 在实现上, 以推模式为主, 拉模式为辅. 本文Agenda: (How)如何同步(How)如何设计同步位点如何设计 Gap过大(SyncGapOverflow) 机制如何设计Ack机制总结 提示: 本系列文章不会单纯的给出结论, 希望能够分享的是&…...

tui-swipe-action组件上的按钮点击后有阴影的解决方法
大家好,我是雄雄,欢迎关注微信公众号:雄雄的小课堂。 目录 前言问题描述问题解决前言 一直未敢涉足电商领域,总觉得这里面的道道很多,又是支付、又是物流的,还涉及到金钱,所以我们所做的项目,一直都是XXXX管理系统,XXX考核系统,移动端的也是,XX健康管理平台…… 但…...

【大数据Hadoop】Hadoop 3.x 新特性总览
Hadoop 3.x 新特性剖析系列11. 概述2. 内容2.1 JDK2.2 EC技术2.3 YARN的时间线V.2服务2.3.1 伸缩性2.3.2 可用性2.3.3 架构体系2.4 优化Hadoop Shell脚本2.5 重构Hadoop Client Jar包2.6 支持等待容器和分布式调度2.7 支持多个NameNode节点2.8 默认的服务端口被修改2.9 支持文件…...

Python-第三天 Python判断语句
Python-第三天 Python判断语句一、 布尔类型和比较运算符1.布尔类型2.比较运算符二、if语句的基本格式1.if 判断语句语法2.案例三、 if else 语句1.语法2.案例四 if elif else语句1.语法五、判断语句的嵌套1.语法六、实战案例一、 布尔类型和比较运算符 1.布尔类型 布尔&…...

失手删表删库,赶紧跑路?!
在数据资源日益宝贵的数字时代公司最怕什么?人还在,库没了是粮库、车库,还是小金库?实际上,这里的“库”是指的数据库Ta是公司各类信息的保险柜小到企业官网和客户信息大到金融机构的资产数据和国家秘密即便没有跟数据…...
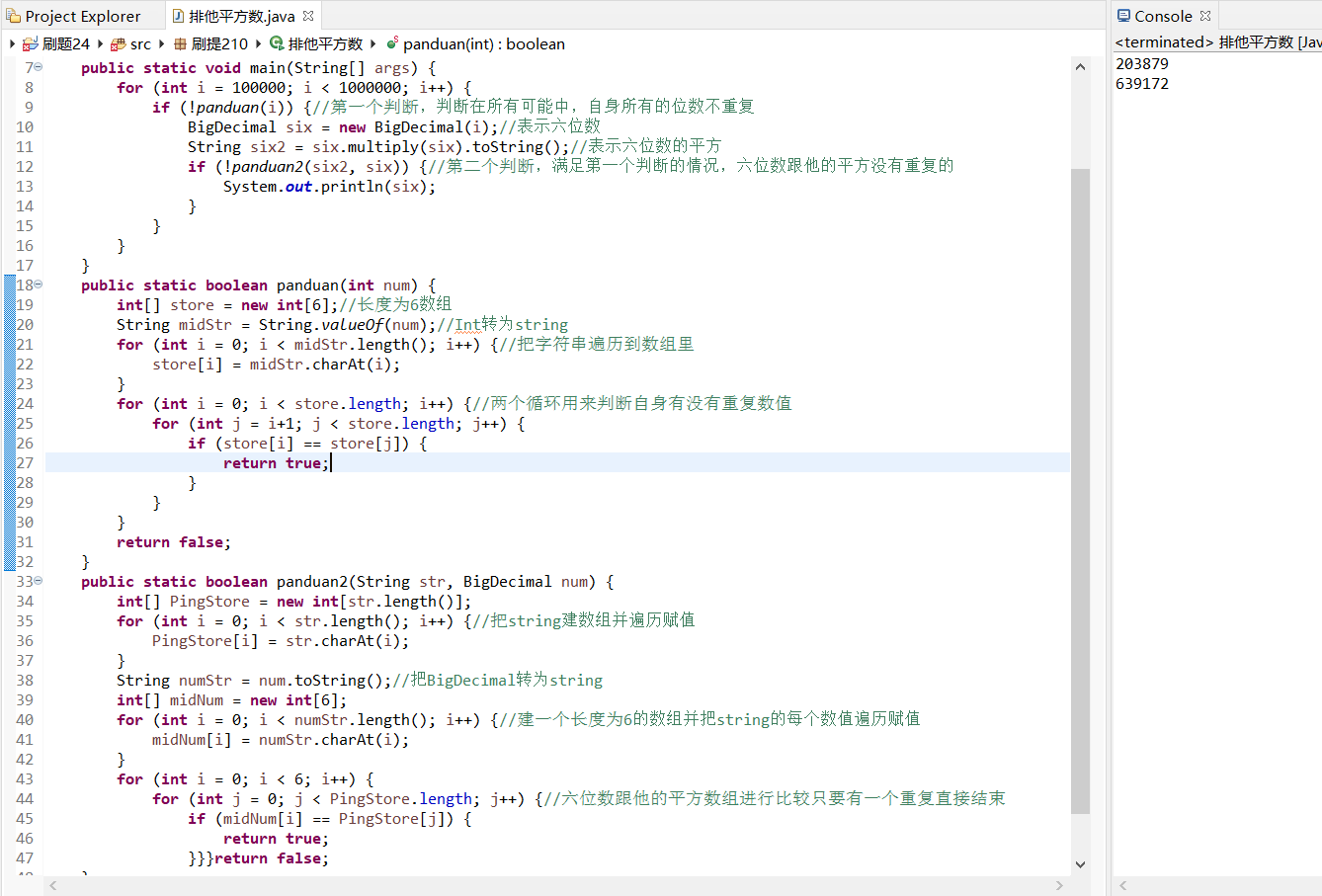
技术树基础——16排它平方数(Bigdecimal,int,string,数组的转换)
题目:03879 * 203879 41566646641这有什么神奇呢?仔细观察,203879 是个6位数,并且它的每个数位上的数字都是不同的,并且它平方后的所有数位上都不出现组成它自身的数字。具有这样特点的6位数还有一个,请你…...

04动手实践:手把手带你实现gRPC的Hello World
这篇文章就从实践的角度出发,带大家一起体验一下gRPC的Hello World。文中的代码将全部使用Go语言实现,使用到的示例也是GitHub上提供的grpc-go,下面我们开始: Hello World官方示例 首先我们要clone GitHub上gRPC的源代码到我们本地 git clone https://github.com/grpc/g…...
开发中,EEG实时预处理流程设计与避坑指南)
从实验室到产品:脑机接口(BCI)开发中,EEG实时预处理流程设计与避坑指南
从实验室到产品:脑机接口(BCI)开发中EEG实时预处理流程设计与避坑指南 在咖啡馆见到那位渐冻症患者用脑电波操控机械臂喝咖啡时,我意识到脑机接口技术正从实验室走向真实世界。但鲜有人提及的是,这套酷炫系统背后藏着怎样的信号处理炼狱——当…...

前端未来趋势:别再用老掉牙的技术了
前端未来趋势:别再用老掉牙的技术了 各位前端同行,咱们今天聊聊前端未来趋势。别告诉我你还在使用老掉牙的技术,那感觉就像在使用诺基亚手机。 为什么你需要关注前端未来趋势 最近看到一个项目,还在使用 jQuery,我差点…...

《B4410 [GESP202509 一级] 金字塔》
题目背景 对应的选择、判断题:https://ti.luogu.com.cn/problemset/1189 题目描述 金字塔由 n 层石块垒成。从塔底向上,每层依次需要 nn,(n−1)(n−1),⋯,22,11 块石块。请问搭建金字塔总共需要多少块石块? 输入格式 一行,一…...

教你 .NET Core API 怎么和数据库表一一对应
不用复杂理论,直接照做就能成功! 一、核心规则(记住这 4 句) 类 = 表 类名 = 表名 属性 = 字段 属性名 = 字段名 二、一步一步教你对应(超级简单) 1)数据库有一张表 → 你就写一个类 例如你数据库里有表: sql Users (Id int primary key identity,Name nvarchar(5…...
)
Python农业物联网部署突然中断?揭秘土壤传感器数据丢包率超37%的底层时钟漂移根源(附校准代码)
第一章:Python农业物联网部署在现代农业数字化转型中,Python凭借其丰富的物联网生态库(如paho-mqtt、Adafruit-IO、RPi.GPIO)和轻量级运行特性,成为边缘设备与云平台协同的核心语言。本章聚焦于基于树莓派的土壤温湿度…...

3分钟搞定Vue时间轴组件:打造优雅时间线应用的终极指南
3分钟搞定Vue时间轴组件:打造优雅时间线应用的终极指南 【免费下载链接】timeline-vuejs Minimalist Timeline ⏳ with VueJS 💚 项目地址: https://gitcode.com/gh_mirrors/ti/timeline-vuejs 还在为Vue项目中的时间线展示而烦恼吗?t…...

SSHFS-Win许可证完全指南:GPLv2+、GPLv3与FLOSS异常条款解析
SSHFS-Win许可证完全指南:GPLv2、GPLv3与FLOSS异常条款解析 【免费下载链接】sshfs-win SSHFS For Windows 项目地址: https://gitcode.com/gh_mirrors/ss/sshfs-win SSHFS-Win是一个让Windows用户通过SSH协议挂载远程服务器目录的开源工具,其许可…...

如何通过3个步骤快速掌握BetaFlight黑匣子日志分析
如何通过3个步骤快速掌握BetaFlight黑匣子日志分析 【免费下载链接】blackbox-log-viewer Interactive log viewer for flight logs recorded with blackbox 项目地址: https://gitcode.com/gh_mirrors/bl/blackbox-log-viewer 你是否曾经在调试无人机飞行问题时感到束手…...
进行无人机三维路径规划的详细项目实例(含模型描述及部分示例代码))
项目介绍 MATLAB实现基于灰狼优化算法(GWO)进行无人机三维路径规划的详细项目实例(含模型描述及部分示例代码)
MATLAB实现基于灰狼优化算法(GWO)进行无人机三维路径规划的详细项目实例 更多详细内容可直接联系博主本人 或者访问以下链接地址 MATLAB实现基于灰狼优化算法(GWO)进行无人机三维路径规划的详细项目实例-CSDN博客 https://blo…...

Verilog进阶实战:独热码状态机设计序列检测器的核心技巧
1. 独热码状态机的设计哲学 第一次接触独热码(One-Hot)编码时,我盯着那串只有一个1的状态编码看了半天——这不就是硬件版的"单选题"吗?每个状态都有自己的专属VIP通道,这种设计理念在中小规模状态机中简直是降维打击。记得去年做电…...