Flink 基础 -- 应用开发(Table API SQL) 概念和通用API
1、概述
Apache Flink提供了两个关系API——Table API和SQL——用于统一的流和批处理。Table API是一个用于Java、Scala和Python的语言集成查询API,它允许以非常直观的方式组合来自关系操作符(如选择、过滤和连接)的查询。Flink的SQL支持基于Apache Calcite,它实现了SQL标准。无论输入是连续的(streaming,流)还是有界的(batch,批处理),在两个接口中指定的查询都具有相同的语义并指定相同的结果。
Table API和SQL接口与Flink的DataStream API无缝集成。您可以轻松地在所有api和构建在它们之上的库之间切换。例如,您可以使用MATCH_RECOGNIZE子句从表中检测模式,然后使用DataStream API基于匹配的模式构建警报。
1.1 表程序依赖关系
为了使用Table API和SQL定义数据管道,您需要将Table API作为一个依赖项添加到项目中。
有关如何为Java和Scala配置这些依赖项的更多信息,请参阅项目配置部分。
如果您正在使用Python,请参考Python API的文档
1.2 下一步做什么
- 概念和公共API:Table API和SQL的共享概念和API。
- 数据类型:列出预定义的数据类型及其属性。
- 流式概念:针对表API或SQL的特定于流式的文档,例如时间属性的配置和更新结果的处理。
- 连接到外部系统:用于向外部系统读写数据的可用连接器和格式。
- Table API:支持的Table API的操作和API。
- SQL:支持的SQL操作和语法。
- 内置函数: 表API和SQL中支持的函数。
- SQL Client:使用Flink SQL,在没有编程知识的情况下向集群提交一个表程序。
- SQL网关:一种服务,它允许多个客户端从远程并发地执行SQL。
- SQL JDBC驱动程序: 向
sql-gateway提交SQL语句的JDBC驱动程序。
2、概念和通用API
Table API和SQL集成在一个联合API中。这个API的核心概念是一个表(Table),它作为查询的输入和输出。本文档展示了具有表API和SQL查询的程序的公共结构,如何注册表,如何查询表,以及如何发出(emit)表。
2.1 Table API和SQL程序的结构
下面的代码示例展示了表API和SQL程序的公共结构。
import org.apache.flink.table.api.*;
import org.apache.flink.connector.datagen.table.DataGenConnectorOptions;// Create a TableEnvironment for batch or streaming execution.
// See the "Create a TableEnvironment" section for details.
TableEnvironment tableEnv = TableEnvironment.create(/*…*/);// Create a source table
tableEnv.createTemporaryTable("SourceTable", TableDescriptor.forConnector("datagen").schema(Schema.newBuilder().column("f0", DataTypes.STRING()).build()).option(DataGenConnectorOptions.ROWS_PER_SECOND, 100L).build());// Create a sink table (using SQL DDL)
tableEnv.executeSql("CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE SourceTable (EXCLUDING OPTIONS) ");// Create a Table object from a Table API query
Table table1 = tableEnv.from("SourceTable");// Create a Table object from a SQL query
Table table2 = tableEnv.sqlQuery("SELECT * FROM SourceTable");// Emit a Table API result Table to a TableSink, same for SQL result
TableResult tableResult = table1.insertInto("SinkTable").execute();
表API和SQL查询可以很容易地集成并嵌入到数据流程序(
DataStream programs)中。请查看数据流API集成页面,了解如何将数据流转换为表,反之亦然。
2.2 创建一个表环境(TableEnvironment)
TableEnvironment 是表API和SQL集成的入口点,它负责:
- Registering a
Tablein the internal catalog - Registering catalogs
- Loading pluggable modules
- Executing SQL queries
- Registering a user-defined (scalar, table, or aggregation) function
- Converting between
DataStreamandTable(in case ofStreamTableEnvironment)
Table 总是绑定到一个特定的TableEnvironment。不可能在同一个查询中组合不同TableEnvironments中的表(tables),例如,连接或联合它们。TableEnvironment是通过调用静态TableEnvironment.create()方法创建的。
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode()//.inBatchMode().build();TableEnvironment tEnv = TableEnvironment.create(settings);
或者,用户可以从现有的StreamExecutionEnvironment中创建一个StreamTableEnvironment来与DataStream API进行互操作。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
2.3 在编目Catalog 中创建表
TableEnvironment维护用标识符创建的表的编目映射。每个标识符由3部分组成:编目名、数据库名和对象名。如果未指定编目或数据库,则将使用当前默认值(请参阅表标识符展开部分中的示例)。
表可以是虚表(VIEWS)或常规表(TABLES)。VIEWS可以从现有的Table对象(通常是Table API或SQL查询的结果)创建。TABLES 描述外部数据,如文件、数据库表或消息队列。
2.3.1 临时表与永久表
表可以是临时的,绑定到单个Flink会话的生命周期,也可以是永久的,并且在多个Flink会话和集群中可见。
永久表需要一个编目(catalog)(比如Hive Metastore)来维护表的元数据。永久表创建后,它对连接到编目的任何Flink会话都是可见的,并且将继续存在,直到表被显式删除。
另一方面,临时表总是存储在内存中,并且只在创建它们的Flink会话期间存在。这些表对其他会话是不可见的。它们不绑定到任何编目或数据库,但可以在其中一个名称空间中创建。如果临时表对应的数据库被删除,则临时表不会被删除。
遮蔽(Shadowing)
可以注册具有与现有永久表相同标识符的临时表。临时表会遮蔽永久表,并且只要临时表存在,永久表就无法访问。所有带有该标识符的查询都将对临时表执行。
这可能对实验有用。它允许首先对临时表运行完全相同的查询,例如,只有一个数据子集,或者数据被混淆。一旦验证查询是正确的,就可以针对实际的生产表运行它。
2.3.2 创建表
虚拟表
在SQL术语中,Table API对象对应于VIEW(虚拟表)。它封装了一个逻辑查询计划。它可以在编目(catalog)中创建,如下所示:
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section// table is the result of a simple projection query
Table projTable = tableEnv.from("X").select(...);// register the Table projTable as table "projectedTable"
tableEnv.createTemporaryView("projectedTable", projTable);
注意:Table 对象类似于关系数据库系统中的VIEW对象,也就是说,定义表(Table)的查询没有被优化,但是当另一个查询引用注册的表时将被内联。如果多个查询引用同一个已注册表,则每个引用查询将被内联并执行多次,即注册表的结果将不会被共享。
Connector Tables
还可以通过连接器声明创建关系数据库中已知的TABLE。连接器描述了存储表数据的外部系统。存储系统,如Apache Kafka或常规文件系统可以在这里声明。
这样的表可以直接使用表API创建,也可以通过切换到SQL DDL来创建。
// Using table descriptors
final TableDescriptor sourceDescriptor = TableDescriptor.forConnector("datagen").schema(Schema.newBuilder().column("f0", DataTypes.STRING()).build()).option(DataGenConnectorOptions.ROWS_PER_SECOND, 100L).build();tableEnv.createTable("SourceTableA", sourceDescriptor);
tableEnv.createTemporaryTable("SourceTableB", sourceDescriptor);// Using SQL DDL
tableEnv.executeSql("CREATE [TEMPORARY] TABLE MyTable (...) WITH (...)");
2.3.3 扩展表标识符
表总是使用由编目、数据库和表名组成的3部分标识符注册。
用户可以将其中的一个编目和一个数据库设置为“当前编目”和“当前数据库”。有了它们,上面提到的3部分标识符中的前两个部分可以是可选的——如果没有提供它们,将引用当前编目和当前数据库。用户可以通过表API或SQL切换当前编目和当前数据库。
标识符遵循SQL要求,这意味着它们可以用反号字符(`)进行转义。
TableEnvironment tEnv = ...;
tEnv.useCatalog("custom_catalog");
tEnv.useDatabase("custom_database");Table table = ...;// register the view named 'exampleView' in the catalog named 'custom_catalog'
// in the database named 'custom_database'
tableEnv.createTemporaryView("exampleView", table);// register the view named 'exampleView' in the catalog named 'custom_catalog'
// in the database named 'other_database'
tableEnv.createTemporaryView("other_database.exampleView", table);// register the view named 'example.View' in the catalog named 'custom_catalog'
// in the database named 'custom_database'
tableEnv.createTemporaryView("`example.View`", table);// register the view named 'exampleView' in the catalog named 'other_catalog'
// in the database named 'other_database'
tableEnv.createTemporaryView("other_catalog.other_database.exampleView", table);
2.4 查询表
Table API
Table API是用于Scala和Java的语言集成查询API。与SQL不同,查询没有指定为Strings ,而是在宿主语言中逐步组成。
这个API基于Table类,它表示一个表(流或批处理),并提供应用关系操作的方法。这些方法返回一个新的Table对象,它表示对输入Table应用关系操作的结果。一些关系操作由多个方法调用组成,例如table.groupBy(...).select(),其中groupBy(…)指定表的分组,而select(…)是表分组上的投影。
Table API文档描述了流和批处理表上支持的所有Table API操作。
下面的例子展示了一个简单的Table API聚合查询:
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section// register Orders table// scan registered Orders table
Table orders = tableEnv.from("Orders");
// compute revenue for all customers from France
Table revenue = orders.filter($("cCountry").isEqual("FRANCE")).groupBy($("cID"), $("cName")).select($("cID"), $("cName"), $("revenue").sum().as("revSum"));// emit or convert Table
// execute query
SQL
Flink的SQL集成基于Apache Calcite,它实现了SQL标准。SQL查询被指定为常规字符串。
SQL文档描述了Flink对流和批处理表的SQL支持。
下面的示例展示了如何指定查询并将结果作为Table返回。
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section// register Orders table// compute revenue for all customers from France
Table revenue = tableEnv.sqlQuery("SELECT cID, cName, SUM(revenue) AS revSum " +"FROM Orders " +"WHERE cCountry = 'FRANCE' " +"GROUP BY cID, cName");// emit or convert Table
// execute query
下面的示例展示了如何指定将其结果插入到已注册表中的更新查询。
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section// register "Orders" table
// register "RevenueFrance" output table// compute revenue for all customers from France and emit to "RevenueFrance"
tableEnv.executeSql("INSERT INTO RevenueFrance " +"SELECT cID, cName, SUM(revenue) AS revSum " +"FROM Orders " +"WHERE cCountry = 'FRANCE' " +"GROUP BY cID, cName");
混合表API和SQL
Table API和SQL查询可以很容易地混合,因为两者都返回Table对象:
- 可以在SQL查询返回的
Table对象上定义Table API查询。 - 通过在
TableEnvironment中注册结果表并在SQL查询的FROM子句中引用它,可以根据表API查询的结果定义SQL查询。
2.5 Emit a Table
通过将表写入TableSink来发出(emitted)表。TableSink是一个通用接口,支持多种文件格式(例如CSV, Apache Parquet, Apache Avro),存储系统(例如JDBC, Apache HBase, Apache Cassandra, Elasticsearch),或者消息系统(例如Apache Kafka, RabbitMQ)。
批处理Table 只能写入BatchTableSink,而流Table 需要AppendStreamTableSink, RetractStreamTableSink或UpsertStreamTableSink。
请参阅有关表源和接收器的文档,了解有关可用接收器的详细信息以及如何实现自定义DynamicTableSink的说明。
Table.insertInto(String tableName)方法定义了一个完整的端到端管道,将源表发送到已注册的接收表。该方法根据名称从编目中查找表接收器,并验证Table 的模式(Schema)是否与接收器的模式相同。管道可以用TablePipeline.explain()解释,并调用TablePipeline.execute()执行。
下面的例子展示了如何发出(emit)一个Table:
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section// create an output Table
final Schema schema = Schema.newBuilder().column("a", DataTypes.INT()).column("b", DataTypes.STRING()).column("c", DataTypes.BIGINT()).build();tableEnv.createTemporaryTable("CsvSinkTable", TableDescriptor.forConnector("filesystem").schema(schema).option("path", "/path/to/file").format(FormatDescriptor.forFormat("csv").option("field-delimiter", "|").build()).build());// compute a result Table using Table API operators and/or SQL queries
Table result = ...;// Prepare the insert into pipeline
TablePipeline pipeline = result.insertInto("CsvSinkTable");// Print explain details
pipeline.printExplain();// emit the result Table to the registered TableSink
pipeline.execute();
2.6 翻译并执行查询
表API和SQL查询被转换为数据流程序,无论它们的输入是流还是批处理。查询在内部表示为逻辑查询计划,并分两个阶段进行转换:
- Optimization of the logical plan,
- Translation into a DataStream program.
表API或SQL查询在以下情况下被转换:
- 调用
TableEnvironment.executeSql()。此方法用于执行给定的语句,并且在调用此方法后立即转换sql查询。 TablePipeline.execute()被调用。此方法用于执行源到接收器的管道,并且在调用此方法后立即转换Table API程序。- 调用
Table.execute()。此方法用于将表内容收集到本地客户机,并且在调用此方法后立即转换table API。 - 调用
StatementSet.execute()。TablePipeline(通过StatementSet.add()发送到sink)或INSERT语句(通过StatementSet. addinsertsql()指定)将首先在StatementSet中进行缓冲。一旦StatementSet.execute()被调用,它们就会被转换。所有的汇将被优化为一个DAG。 Table在转换为DataStream时进行转换(请参阅与数据流的集成)。转换后,它是一个常规的数据流程序,并在调用StreamExecutionEnvironment.execute()时执行。
2.7 查询优化
Apache Flink利用并扩展了Apache Calcite来执行复杂的查询优化。这包括一系列基于规则和成本的优化,例如:
- Subquery decorrelation based on Apache Calcite
- Project pruning
- Partition pruning
- Filter push-down
- Sub-plan deduplication to avoid duplicate computation
- Special subquery rewriting, including two parts:
- Converts IN and EXISTS into left semi-joins (将IN和EXISTS转换为左半连接)
- Converts NOT IN and NOT EXISTS into left anti-join (将NOT IN和NOT EXISTS转换为左反连接)
- Optional join reordering (可选的连接重排序)
- Enabled via
table.optimizer.join-reorder-enabled
- Enabled via
注意:
IN/EXISTS/NOT IN/NOT EXISTS目前只支持子查询重写的合词条件。
优化器不仅根据计划,还根据数据源提供的丰富统计信息和每个操作的细粒度成本(如io、cpu、网络和内存)做出智能决策。
高级用户可以通过CalciteConfig对象提供自定义优化,该对象可以通过调用TableEnvironment#getConfig#setPlannerConfig提供给表环境。
2.8 Explaining a Table
Table API提供了一种机制来解释用于计算Table的逻辑和优化的查询计划。这是通过Table.explain()方法或StatementSet.explain()方法完成的。Table.explain()返回一个表的计划。StatementSet.explain() 返回多个接收点的计划。它返回一个字符串,描述三个计划:
- 关系查询的抽象语法树,即未优化的逻辑查询计划、
- 优化的逻辑查询计划和
- 物理执行计划。
TableEnvironment.explainSql()和TableEnvironment.executeSql()支持执行EXPLAIN语句来获取计划,请参考EXPLAIN页面。
下面的代码显示了一个使用Table.explain()方法的示例和给定表的相应输出:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);DataStream<Tuple2<Integer, String>> stream1 = env.fromElements(new Tuple2<>(1, "hello"));
DataStream<Tuple2<Integer, String>> stream2 = env.fromElements(new Tuple2<>(1, "hello"));// explain Table API
Table table1 = tEnv.fromDataStream(stream1, $("count"), $("word"));
Table table2 = tEnv.fromDataStream(stream2, $("count"), $("word"));
Table table = table1.where($("word").like("F%")).unionAll(table2);System.out.println(table.explain());
上面示例的结果是
== Abstract Syntax Tree ==
LogicalUnion(all=[true])
:- LogicalFilter(condition=[LIKE($1, _UTF-16LE'F%')])
: +- LogicalTableScan(table=[[Unregistered_DataStream_1]])
+- LogicalTableScan(table=[[Unregistered_DataStream_2]])== Optimized Physical Plan ==
Union(all=[true], union=[count, word])
:- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])
: +- DataStreamScan(table=[[Unregistered_DataStream_1]], fields=[count, word])
+- DataStreamScan(table=[[Unregistered_DataStream_2]], fields=[count, word])== Optimized Execution Plan ==
Union(all=[true], union=[count, word])
:- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])
: +- DataStreamScan(table=[[Unregistered_DataStream_1]], fields=[count, word])
+- DataStreamScan(table=[[Unregistered_DataStream_2]], fields=[count, word])
下面的代码显示了使用StatementSet.explain()方法的多汇计划的示例和相应的输出:
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tEnv = TableEnvironment.create(settings);final Schema schema = Schema.newBuilder().column("count", DataTypes.INT()).column("word", DataTypes.STRING()).build();tEnv.createTemporaryTable("MySource1", TableDescriptor.forConnector("filesystem").schema(schema).option("path", "/source/path1").format("csv").build());
tEnv.createTemporaryTable("MySource2", TableDescriptor.forConnector("filesystem").schema(schema).option("path", "/source/path2").format("csv").build());
tEnv.createTemporaryTable("MySink1", TableDescriptor.forConnector("filesystem").schema(schema).option("path", "/sink/path1").format("csv").build());
tEnv.createTemporaryTable("MySink2", TableDescriptor.forConnector("filesystem").schema(schema).option("path", "/sink/path2").format("csv").build());StatementSet stmtSet = tEnv.createStatementSet();Table table1 = tEnv.from("MySource1").where($("word").like("F%"));
stmtSet.add(table1.insertInto("MySink1"));Table table2 = table1.unionAll(tEnv.from("MySource2"));
stmtSet.add(table2.insertInto("MySink2"));String explanation = stmtSet.explain();
System.out.println(explanation);
the result of multiple-sinks plan is
== Abstract Syntax Tree ==
LogicalLegacySink(name=[`default_catalog`.`default_database`.`MySink1`], fields=[count, word])
+- LogicalFilter(condition=[LIKE($1, _UTF-16LE'F%')])+- LogicalTableScan(table=[[default_catalog, default_database, MySource1, source: [CsvTableSource(read fields: count, word)]]])LogicalLegacySink(name=[`default_catalog`.`default_database`.`MySink2`], fields=[count, word])
+- LogicalUnion(all=[true]):- LogicalFilter(condition=[LIKE($1, _UTF-16LE'F%')]): +- LogicalTableScan(table=[[default_catalog, default_database, MySource1, source: [CsvTableSource(read fields: count, word)]]])+- LogicalTableScan(table=[[default_catalog, default_database, MySource2, source: [CsvTableSource(read fields: count, word)]]])== Optimized Physical Plan ==
LegacySink(name=[`default_catalog`.`default_database`.`MySink1`], fields=[count, word])
+- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])+- LegacyTableSourceScan(table=[[default_catalog, default_database, MySource1, source: [CsvTableSource(read fields: count, word)]]], fields=[count, word])LegacySink(name=[`default_catalog`.`default_database`.`MySink2`], fields=[count, word])
+- Union(all=[true], union=[count, word]):- Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')]): +- LegacyTableSourceScan(table=[[default_catalog, default_database, MySource1, source: [CsvTableSource(read fields: count, word)]]], fields=[count, word])+- LegacyTableSourceScan(table=[[default_catalog, default_database, MySource2, source: [CsvTableSource(read fields: count, word)]]], fields=[count, word])== Optimized Execution Plan ==
Calc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')])(reuse_id=[1])
+- LegacyTableSourceScan(table=[[default_catalog, default_database, MySource1, source: [CsvTableSource(read fields: count, word)]]], fields=[count, word])LegacySink(name=[`default_catalog`.`default_database`.`MySink1`], fields=[count, word])
+- Reused(reference_id=[1])LegacySink(name=[`default_catalog`.`default_database`.`MySink2`], fields=[count, word])
+- Union(all=[true], union=[count, word]):- Reused(reference_id=[1])+- LegacyTableSourceScan(table=[[default_catalog, default_database, MySource2, source: [CsvTableSource(read fields: count, word)]]], fields=[count, word])
相关文章:
 概念和通用API)
Flink 基础 -- 应用开发(Table API SQL) 概念和通用API
1、概述 Apache Flink提供了两个关系API——Table API和SQL——用于统一的流和批处理。Table API是一个用于Java、Scala和Python的语言集成查询API,它允许以非常直观的方式组合来自关系操作符(如选择、过滤和连接)的查询。Flink的SQL支持基于Apache Calcite&#x…...

Flink之Java Table API的使用
Java Table API的使用 使用Java Table API开发添加依赖创建表环境创建表查询表输出表使用示例 表和流的转换流DataStream转换成表Table表Table转换成流DataStream示例数据类型 自定义函数UDF标量函数表函数聚合函数表聚合函数 API方法汇总基本方法列操作聚合操作Joins合并操作排…...
【Unity细节】Unity中如何让组件失活而不是物体失活
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 😶🌫️收录于专栏:unity细节和bug 😶🌫️优质专栏 ⭐【…...

[设计模式] 建造者模式
一、引言 起因是学习okhttp过程中遇到的这段代码 Request request original.newBuilder().url(original.url()).header("Authorization", "Bearer " BearerTokenUtils.getToken(configuration.getApiKey(), configuration.getApiSecret())).header(&quo…...
)
在DDD领域驱动下的微服务数据库的MVC设计思路(高度可行性)
在DDD领域驱动下的微服务架构中使用MVC设计思路来设计数据库是可行的,因为MVC是一种经典的软件架构模式,可以将应用程序分为三个主要部分:模型、视图和控制器。在微服务架构中,每个微服务可以看作是一个模块,可以使用M…...
Leetcode2834. 找出美丽数组的最小和
Every day a Leetcode 题目来源:2834. 找出美丽数组的最小和 解法1:贪心 从最小正整数 1 开始枚举,设当前数为 num,如果 nums 里没有 target - num,就说明可以添加 num,依次填满直到有 n 个数即可。 用…...

acwing算法基础之搜索与图论--kruskal算法
目录 1 基础知识2 模板3 工程化 1 基础知识 kruskal算法的关键步骤为: 将所有边按照权重从小到大排序。定义集合S,表示生成树。枚举每条边(a,b,c),起点a,终点b,边长c。如果结点a和结点b不连通(用并查集来…...

微信H5跳转微信小程序
官方文档:目录 | 微信开放文档 方法一:微信浏览器打开的h5跳转方式 HTML代码 <wx-open-launch-weapp id"launch-btn" username"所需跳转的小程序原始id" path"pages/pay/pay"><script type"text/wxtag…...

Yii2 引入 外部无命名空间的类,Class not found
记一次问题解决 问题描述 支付宝开放平台SDK v2 无命名空间。需 require 引入。 require Yii::$app->vendorPath."/alipay-sdk-php/v2/aop/AopClient.php"; var_dump(new AopClient([]));exit();上述写法会直接报错。 Class temporary\controllers\AopClient …...

设计模式是测试模式咩?
设计模式和测试模式概述 软件的生命周期为什么要进行测试(测试的目的)?软件的设计模式1. **瀑布模型**3. 增量和迭代模型4. 敏捷模型5. 喷泉模型 测试模型V模型W模型 一个应用程序从出生到“死亡”会经过非常漫长的流程…… 软件的生命周期 …...

Aspose.OCR for .NET 2023Crack
Aspose.OCR for .NET 2023Crack 为.NET在图片上播放OCR使所有用户和程序员都可以从特定的图像片段中提取文本和相关的细节,如字体、设计以及书写位置。这一特定属性为OCR的性能及其在扫描遵循排列的记录时的功能提供了动力。OCR的库使用一条线甚至几条线来处理这些特…...
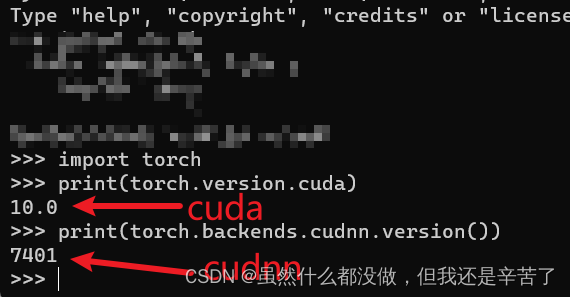
conda环境中pytorch1.2.0版本安装包安装一直失败解决办法!!!
conda环境中pytorch1.2.0版本安装包安装一直失败解决办法 cuda10.0以及cudnn7.4现在以及安装完成,就差torch的安装了,现在torch我要装的是1.2.0版本的,安装包以及下载好了,安装包都是在这个网站里下载的(点此进入&…...
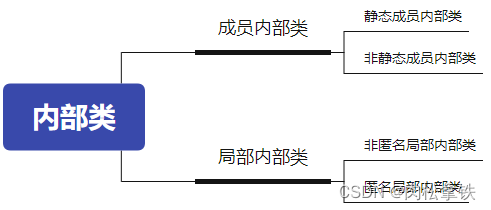
后端面试问题(学习版)
JAVA相关 JAVA语言概述 1. 一个".java"源文件中是否可以包含多个类?有什么限制? 可以。 一个源文件可以声明多个类,但是最多只能有一个类使用public进行声明 且要求声明public的类的类名与源文件相同。 2. Java的优势ÿ…...

数据管理系统-week1-介绍
文章目录 一、数据它是什么?二、电子存储设备三、持久存储设备1、硬盘驱动器(HDD)、硬盘、硬盘驱动器是一种用于存储和检索数字信息的机电持久存储设备。2、固态硬盘(SSD)使用非易失性存储器,即使用NAND闪存…...

【SpringBoot】手写模拟SpringBoot核心流程
依赖包 新建一个工程,包含两个 module: springboot 模块,表示 springboot 源码实现;user 模块,表示业务系统,使用 springboot 模块; 依赖包:Spring、SpringMVC、Tomcat 等ÿ…...

应对.locked勒索病毒:恢复、预防全方位攻略
导言: .locked勒索病毒并非简单的数字威胁,它是一场对个人和企业数字资产的精密审判。这种病毒通过各种方式感染系统,从而以瞬间之间将用户的关键文件变成数字拼图,无情地要求赎金以换取解锁的密钥。如果您正在经历勒索病毒数据恢…...

基于DS1302时钟液晶12864显示2路闹钟仿真及源程序
一、系统方案 1、本设计采用51单片机作为主控器。 2、DS1302采集年月日时分秒送到液晶12864显示。 3、按键年月日时分秒,两路闹钟。 二、硬件设计 原理图如下: 三、单片机软件设计 1、首先是系统初始化 uchar clock_time[6] {0X00,0X59,0X23,0X09,0X…...

AGC034E Complete Compress
AGC034E Complete Compress 洛谷[AGC034E] Complete Compress 题目大意 给你一棵有 n n n个节点的树,并用 01 01 01串告诉你哪些节点上有棋子(恰好一棵)。 你可以进行若干次操作,每次操作可以将两颗距离至少为 2 2 2的棋子向彼…...

python设计模式12:状态模式
什么是状态机? 关键属性: 状态和转换 状态: 系统当前状态 转换:一种状态到另外一种状态的变化。 转换由触发事件或是条件启动。 状态机-状态图 状态机使用场景: 自动售货机 电梯 交通灯 组合锁 停车计时…...
)
JS对图片尺寸和DPI进行编辑修改(1寸照修改为2寸照)
各种报名都对照片有大小限制,鉴于这种情况,网上搜了后拼凑出了如下代码,用于解决1寸照片修改为2寸照片,同时将DPI修改为300,当然也可以根据自己的情况修改代码: HTML <input type"file" id&…...

正则表达式 ;grep ;sed实验笔记
复习 开发脚本:已知变量num10,判断num值,如果大于 5 且小于 15,则输出"5<num<15"。 #!/bin/bash num10 # if [ $num -gt 5 ] && [ $num -lt 15 ];then # if [ $num -gt 5 -a $num -lt 15 ];then if ((5&l…...

Windows 下部署与配置 Hermes Agent 完全指南:AI 智能体、OpenRouter、LLM、本地大模型、WSL2、自动化、自进化 AI、Ollama、Claude 3.5、GPT-4
本文内容深度融合相关以下技术相关词的汇,放在文章开头以便于您快速阅读以及学习: 平台:Windows、WSL2核心项目:Hermes AgentAI 能力:AI 智能体(AI Agent)、自进化 AI、自动化任务、代码解释器、…...

知识图谱-Neo4j实战指南:从安装到应用开发
1. 为什么选择Neo4j构建知识图谱 第一次接触Neo4j时,我被它处理复杂关系的效率震惊了。传统关系型数据库在处理多表关联查询时性能急剧下降,而Neo4j查询6度人脉关系只需毫秒级响应。这就像在拥挤的十字路口,关系型数据库是红绿灯指挥的车辆&a…...

终极指南:如何使用Tiny11Builder为老旧电脑打造轻量级Windows 11系统
终极指南:如何使用Tiny11Builder为老旧电脑打造轻量级Windows 11系统 【免费下载链接】tiny11builder Scripts to build a trimmed-down Windows 11 image. 项目地址: https://gitcode.com/GitHub_Trending/ti/tiny11builder 还在为老旧电脑运行Windows 11时…...
)
鸿蒙Next实战:5分钟搞定跨应用拖拽图片功能(附完整代码)
鸿蒙Next实战:5分钟搞定跨应用拖拽图片功能(附完整代码) 在移动应用开发中,跨应用数据交互一直是提升用户体验的关键技术点。想象一下,用户无需繁琐的保存-导入流程,只需简单拖拽就能将图片从相册应用转移到…...
根本不是移动端生态,完全没法挑战安卓)
Ubuntu Touch / PureOS / PostmarketOS 太小众 - Linux 桌面发行版(Ubuntu、Debian、CentOS)根本不是移动端生态,完全没法挑战安卓
视角 顶层。 1)安卓开源 vs OpenHarmony 开源:本质结构确实一样 对,商业模式、开源结构、卡脖子风险是同一类逻辑: AOSP(安卓开源) 底层框架开源,但GMS 闭源、垄断、可卡脖子OpenHarmony&#…...

Agent评测体系:如何量化Agent的能力与可靠性
会根据问题选择召回策略、决定是否多次搜索、过滤重复结果,还能将高价值信息回写知识图谱库。 Agentic RAG 在普通RAG(“召回-增强-生成”)基础上更具主动性: 相比自然语言回答,精准性和可复现性更高,但对执行环境要求高,需在隔离…...

C# ModbusRtu与TCP协议上位机源码:包含存储、数据到SQL SERVER、趋势曲线...
C# ModbusRtu或者TCP协议上位机源码,包括存储,数据到SQL SERVER数据库,趋势曲线图,数据报表,实时和历史报警界面,有详细注释,需要哪个协议版本ModbusRTU 上位机工程:功能全景与技术实…...

ExtractorSharp游戏资源编辑工具:从零开始掌握NPK与IMG文件编辑的完整指南
ExtractorSharp游戏资源编辑工具:从零开始掌握NPK与IMG文件编辑的完整指南 【免费下载链接】ExtractorSharp Game Resources Editor 项目地址: https://gitcode.com/gh_mirrors/ex/ExtractorSharp 你是否曾想过自定义游戏中的角色外观、武器特效或界面元素&a…...

Alienware灯光控制终极指南:轻量级工具完整解决方案
Alienware灯光控制终极指南:轻量级工具完整解决方案 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 还在为臃肿的Alienware Command Center…...