pytorch DistributedDataParallel 分布式训练踩坑记录
目录
- 一、几个比较常见的概念:
- 二、踩坑记录
- 2.1 dist.init_process_group初始化
- 2.2 spawn启动(rank怎么来的)
- 2.3 loss backward
- 2.4 model cuda设置
- 2.5 数据加载
一、几个比较常见的概念:
- rank: 多机多卡时代表某一台机器,单机多卡时代表某一块GPU
- world_size: 多机多卡时代表有几台机器,单机多卡时代表有几块GPU
world_size = torch.cuda.device_count() - local_rank: 多机多卡时代表某一块GPU, 单机多卡时代表某一块GPU
单机多卡的情况要比多机多卡的情况常见的多。 - DP:适用于单机多卡(=多进程)训练。算是旧版本的DDP
- DDP:适用于单机多卡训练、多机多卡。
二、踩坑记录
2.1 dist.init_process_group初始化
这一步就是设定一个组,这个组里面设定你有几个进程(world_size),现在是卡几(rank)。让pycharm知道你要跑几个进程,包装在组内,进行通讯这样模型参数会自己同步,不需要额外操作了。
import os
import torch.distributed as distdef ddp_setup(rank,world_size):os.environ['MASTER_ADDR'] = 'localhost' #rank0 对应的地址os.environ['MASTER_PORT'] = '6666' #任何空闲的端口dist.init_process_group(backend='nccl', #nccl Gloo #nvidia显卡的选择ncclworld_size=world_size, init_method='env://',rank=rank) #初始化默认的分布进程组dist.barrier() #等到每块GPU运行到这再继续往下走
2.2 spawn启动(rank怎么来的)
rank是自动分配的。怎么分配呢?这里用的是spawn也就一行代码。
import torch.multiprocessing as mp
def main (rank:int,world_size:int,args):pass#训练代码 主函数mp.spawn(main,args=(args.world_size,args), nprocs=args.world_size)
注意,调用spawn的时候,没有输入main的其中一个参数rank,rank由代码自动分配。将代码复制两份在两张卡上同时跑,你可以print(rank),会发现输出 0 1。两份代码并行跑。
另外,nprocs=args.world_size。如果不这么写,代码会卡死在这,既不报错,也不停止。
2.3 loss backward
one of the variables needed for gradient computation has been modified by an inplace operationRuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [2048]] is at version 4; expected version 3 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
经过调试发现,当使用nn.DataParallel并行训练或者单卡训练均可正常运行;另外如果将两次模型调用集成到model中,即通过out1, out2 = model(input0, input1) 的方式在分布式训练下也不会报错。
在分布式训练中,如果对同一模型进行多次调用则会触发以上报错,即nn.parallel.DistributedDataParallel方法封装的模型,forword()函数和backward()函数必须交替执行,如果执行多个(次)forward()然后执行一次backward()则会报错。
解决此问题可以聚焦到nn.parallel.DistributedDataParallel接口上,通过查询PyTorch官方文档发现此接口下的两个参数:
- find_unused_parameters: 如果模型的输出有不需要进行反向传播的,此参数需要设置为True;若你的代码运行后卡住不动,基本上就是该参数的问题。
- broadcast_buffers: 该参数默认为True,设置为True时,在模型执行forward之前,gpu0会把buffer中的参数值全部覆盖到别的gpu上。
model = nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], broadcast_buffers=False, find_unused_parameters=True)
2.4 model cuda设置
RuntimeError: NCCL error in: ../torch/lib/c10d/ProcessGroupNCCL.cpp:859, invalid usage, NCCL version 21.1.1
ncclInvalidUsage: This usually reflects invalid usage of NCCL library (such as too many async ops, too many collectives at once, mixing streams in a group, etc).
*这是因为model和local_rank所指定device不一致引起的错误。
model.cuda(args.local_rank)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank],broadcast_buffers=False,find_unused_parameters=True)
2.5 数据加载
使用distributed加载数据集,需要使用DistributedSampler自动为每个gpu分配数据,但需要注意的是sampler和shuffle=True不能并存。
train_sampler = DistributedSampler(trainset)
train_loader = torch.utils.data.DataLoader(trainset,batch_size=args.train_batch_size,num_workers=args.train_workers,sampler=train_sampler)相关文章:

pytorch DistributedDataParallel 分布式训练踩坑记录
目录 一、几个比较常见的概念:二、踩坑记录2.1 dist.init_process_group初始化2.2 spawn启动(rank怎么来的)2.3 loss backward2.4 model cuda设置2.5 数据加载 一、几个比较常见的概念: rank: 多机多卡时代表某一台机器ÿ…...
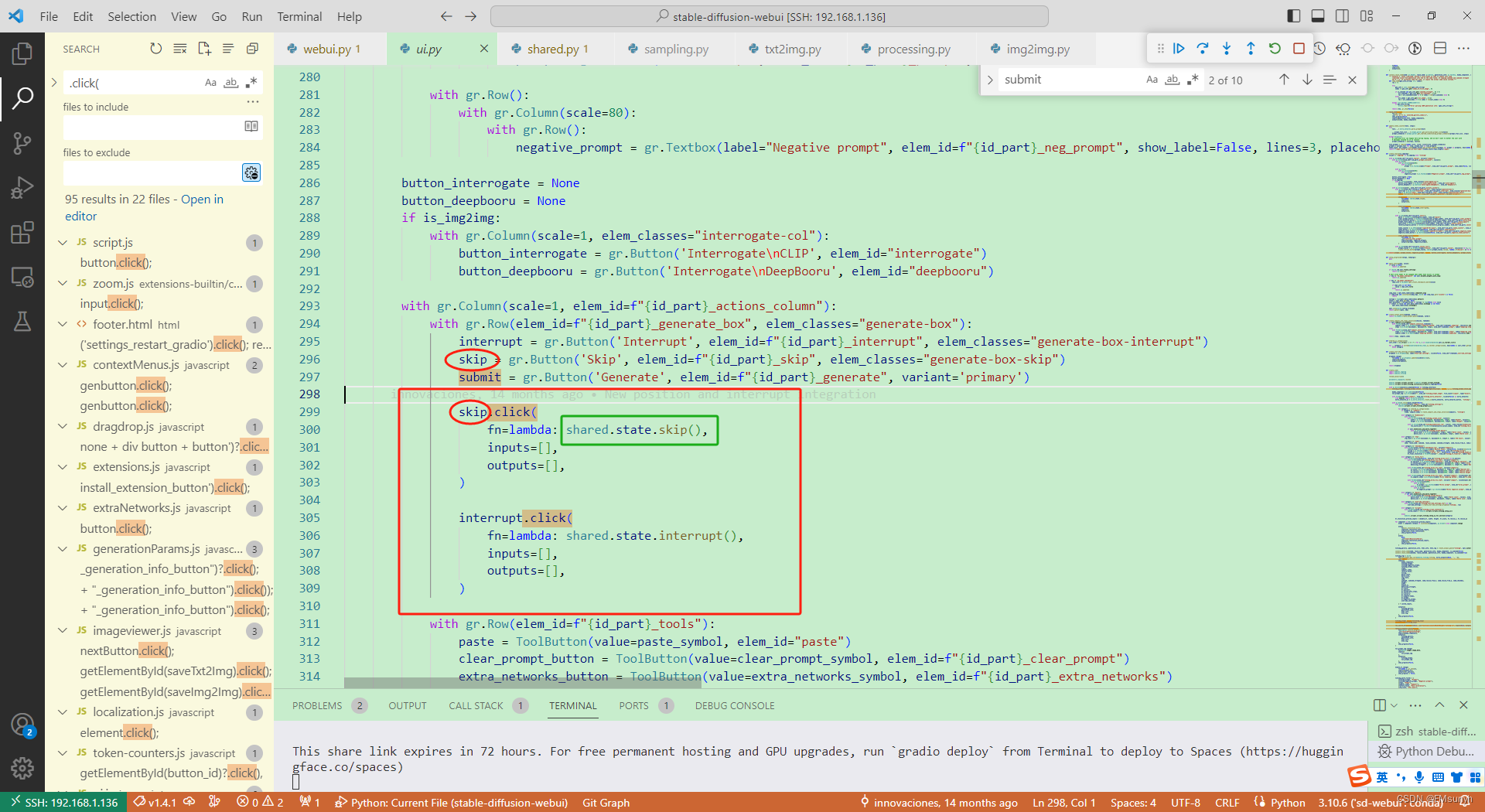
Stable Diffusion webui 源码调试(三)
Stable Diffusion webui 源码调试(三) 个人模型主页:LibLibai stable-diffusion-webui 版本:v1.4.1 内容更新随机,看心情调试代码~ shared 变量 shared变量,简直是一锅大杂烩,shared变量存放…...

工作学习记录
1、Spring的Lifecycle和SmartLifecycle Spring的Lifecycle和SmartLifecycle,可以没用过,但不能不知道!-CSDN博客 2、Shiro安全框架提供了认证、授权、企业会话管理、加密、缓存管理相关的功能,使用Shiro可以非常方便的完成项目的…...
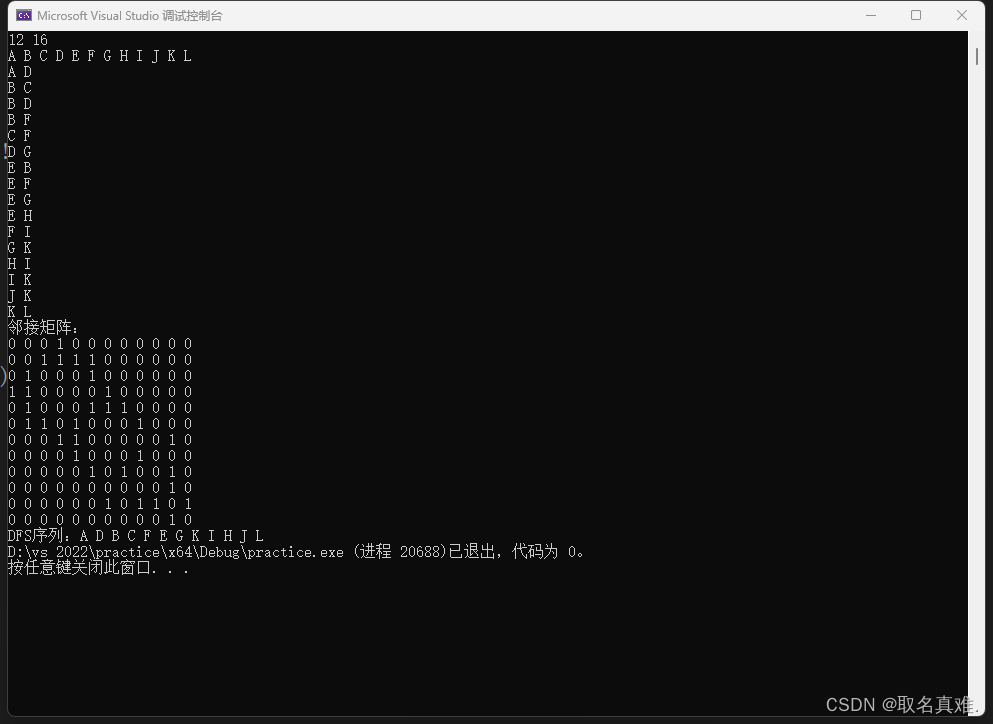
邻接矩阵储存图实现深度优先遍历(C++)
目录 基本要求: 图的结构体: 图的构造: 图的深度优先(DFS): 图的打印输出: 完整代码: 测试数据: 运行结果: 通过给出的图的顶点和边的信息,…...
-42)
hdlbits系列verilog解答(100位加法器)-42
文章目录 一、问题描述二、verilog源码三、仿真结果一、问题描述 通过实例化 100 个完整加法器来创建一个 100 位二进制纹波进位加法器。加法器将两个 100 位数字和一个进位相加,以产生一个 100 位的总和并执行。为了鼓励您实际实例化全加法器,还要在纹波进位加法器中输出每…...

学者观察 | 数字经济中长期发展中的区块链影响力——清华大学柴跃廷
导语 区块链是一种全新的分布式基础架构与计算范式,既能利用非对称加密和冗余分布存储实现信息不可篡改,又可以利用链式数据结构实现数据信息可溯源。当前,区块链技术已成为全球数据交易、金融结算、国际贸易、政务民生等领域的信息基础设施…...

python-flask笔记
服务器图形工具:FinalShellpython虚拟环境用anaconda 标题技术架构和依赖 python3.8 环境 Flask 后端框架 flask-marshmallow webargs 处理参数接收 postgresql 数据库 psycopg2-binary postgresql操作库 Flask-SQLAlchemy orm操作库 flask-admin 超管管理后台 …...

tensor和ndarray的相互转换,同时需要注意cuda和cpu的迁移
从tensor到ndarray:.detach() 方法用于创建一个新的张量,新张量与原始张量共享数据内存,但是不会被计算图追踪。这意味着在新张量上的操作不会影响到原始张量,同时也可以避免梯度传播,适合于提取中间结果。 # 当tenso…...
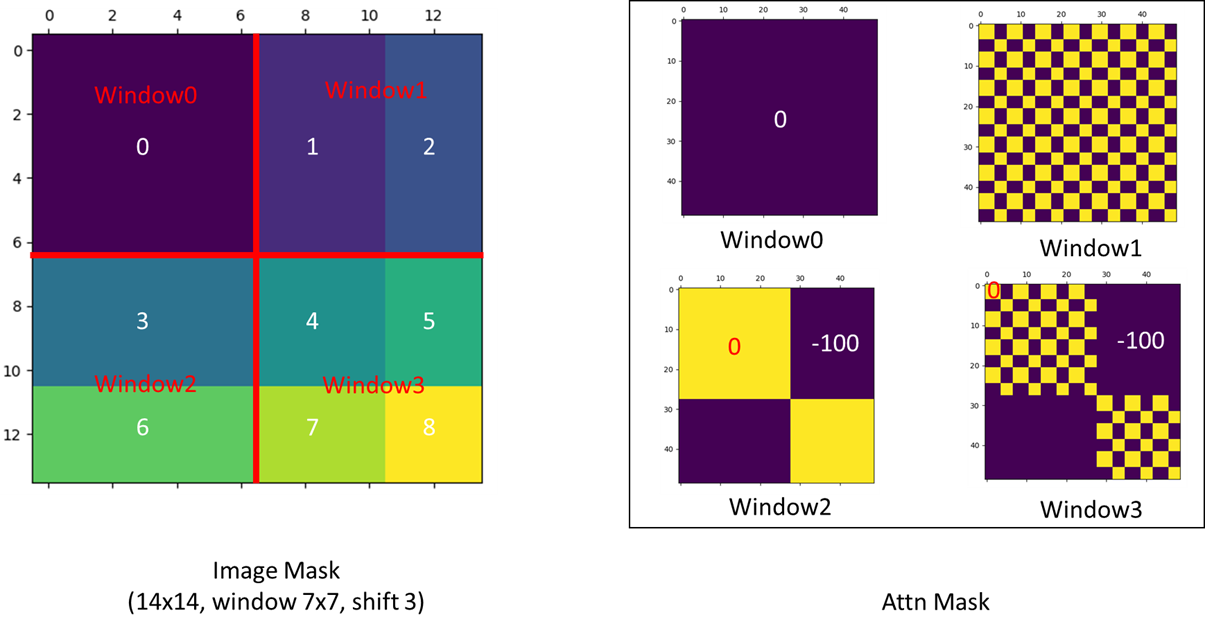
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》阅读笔记
论文标题 《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》 Swin 这个词貌似来自后面的 Shifted WindowsShifted Windows:移动窗口Hierarchical:分层 作者 微软亚洲研究院出品 初读 摘要 提出 Swin Transformer 可以…...
 概念和通用API)
Flink 基础 -- 应用开发(Table API SQL) 概念和通用API
1、概述 Apache Flink提供了两个关系API——Table API和SQL——用于统一的流和批处理。Table API是一个用于Java、Scala和Python的语言集成查询API,它允许以非常直观的方式组合来自关系操作符(如选择、过滤和连接)的查询。Flink的SQL支持基于Apache Calcite&#x…...

Flink之Java Table API的使用
Java Table API的使用 使用Java Table API开发添加依赖创建表环境创建表查询表输出表使用示例 表和流的转换流DataStream转换成表Table表Table转换成流DataStream示例数据类型 自定义函数UDF标量函数表函数聚合函数表聚合函数 API方法汇总基本方法列操作聚合操作Joins合并操作排…...
【Unity细节】Unity中如何让组件失活而不是物体失活
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 😶🌫️收录于专栏:unity细节和bug 😶🌫️优质专栏 ⭐【…...

[设计模式] 建造者模式
一、引言 起因是学习okhttp过程中遇到的这段代码 Request request original.newBuilder().url(original.url()).header("Authorization", "Bearer " BearerTokenUtils.getToken(configuration.getApiKey(), configuration.getApiSecret())).header(&quo…...
)
在DDD领域驱动下的微服务数据库的MVC设计思路(高度可行性)
在DDD领域驱动下的微服务架构中使用MVC设计思路来设计数据库是可行的,因为MVC是一种经典的软件架构模式,可以将应用程序分为三个主要部分:模型、视图和控制器。在微服务架构中,每个微服务可以看作是一个模块,可以使用M…...
Leetcode2834. 找出美丽数组的最小和
Every day a Leetcode 题目来源:2834. 找出美丽数组的最小和 解法1:贪心 从最小正整数 1 开始枚举,设当前数为 num,如果 nums 里没有 target - num,就说明可以添加 num,依次填满直到有 n 个数即可。 用…...

acwing算法基础之搜索与图论--kruskal算法
目录 1 基础知识2 模板3 工程化 1 基础知识 kruskal算法的关键步骤为: 将所有边按照权重从小到大排序。定义集合S,表示生成树。枚举每条边(a,b,c),起点a,终点b,边长c。如果结点a和结点b不连通(用并查集来…...

微信H5跳转微信小程序
官方文档:目录 | 微信开放文档 方法一:微信浏览器打开的h5跳转方式 HTML代码 <wx-open-launch-weapp id"launch-btn" username"所需跳转的小程序原始id" path"pages/pay/pay"><script type"text/wxtag…...

Yii2 引入 外部无命名空间的类,Class not found
记一次问题解决 问题描述 支付宝开放平台SDK v2 无命名空间。需 require 引入。 require Yii::$app->vendorPath."/alipay-sdk-php/v2/aop/AopClient.php"; var_dump(new AopClient([]));exit();上述写法会直接报错。 Class temporary\controllers\AopClient …...

设计模式是测试模式咩?
设计模式和测试模式概述 软件的生命周期为什么要进行测试(测试的目的)?软件的设计模式1. **瀑布模型**3. 增量和迭代模型4. 敏捷模型5. 喷泉模型 测试模型V模型W模型 一个应用程序从出生到“死亡”会经过非常漫长的流程…… 软件的生命周期 …...

Aspose.OCR for .NET 2023Crack
Aspose.OCR for .NET 2023Crack 为.NET在图片上播放OCR使所有用户和程序员都可以从特定的图像片段中提取文本和相关的细节,如字体、设计以及书写位置。这一特定属性为OCR的性能及其在扫描遵循排列的记录时的功能提供了动力。OCR的库使用一条线甚至几条线来处理这些特…...

每天拆解一个电路---振荡电路的实战应用与设计技巧
1. 振荡电路基础:从原理到生活化理解 振荡电路就像电子世界里的永动机,只不过它消耗电能来产生周期性的信号。我第一次接触这个概念是在大学电子实验课上,当时看着示波器上凭空出现的正弦波,感觉特别神奇。这种无需外部输入就能持…...
)
从零开始:NVIDIA显卡驱动与CUDA环境搭建全攻略(附常见问题解决)
1. 准备工作:硬件与系统检查 在开始安装NVIDIA显卡驱动和CUDA之前,首先要确保你的硬件和系统满足基本要求。我遇到过不少朋友因为跳过这一步,结果在安装过程中踩坑。 检查显卡型号:打开终端(Linux/macOS)或…...

Ventus GPGPU缓存一致性实战:RCC机制如何简化并行编程与硬件设计
Ventus GPGPU缓存一致性实战:RCC机制如何重构并行计算范式 1. 并行计算的缓存一致性困局 现代GPGPU架构正面临一个根本性矛盾:一方面需要更高的指令级并行度(ILP)来提升计算吞吐量,另一方面又不得不应对线程级并行(TLP)带来的缓存一致性问题。…...

跟着AI学sql
1、左连接(返回左表全部) left join .. on ....表1 Person(PersonId,FirstName,LastName)表2 Address(AddressId,PersonId,City,State)查询每个人的姓、名、城市、州,没有人的地址也要显示select p.FirstName,p.LastName,a.City,a.Statefrom …...

终极SketchUp STL插件指南:3D打印模型转换快速上手教程
终极SketchUp STL插件指南:3D打印模型转换快速上手教程 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl 你是否曾为…...

5分钟快速上手KeymouseGo:免费开源鼠标键盘录制工具完全指南
5分钟快速上手KeymouseGo:免费开源鼠标键盘录制工具完全指南 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo 还…...

DamaiHelper:多平台票务自动化工具的技术解析与实战指南
DamaiHelper:多平台票务自动化工具的技术解析与实战指南 【免费下载链接】damaihelper 支持大麦网,淘票票、缤玩岛等多个平台,演唱会演出抢票脚本 项目地址: https://gitcode.com/gh_mirrors/dam/damaihelper DamaiHelper 是一个支持大…...

D3与镁在人体中的协同关系
D3与镁在人体中的协同关系维生素D3和镁的相互作用维生素D3和镁是两种对人体健康至关重要的营养素。它们在体内不仅各自发挥着重要作用,而且彼此之间还存在密切的协同关系。了解这种协同关系对于科学补充这些营养素非常重要。镁的作用镁是一种重要的矿物质࿰…...

忍者像素绘卷入门指南:Z-Image-Turbo底座模型微调入门路径
忍者像素绘卷入门指南:Z-Image-Turbo底座模型微调入门路径 1. 认识忍者像素绘卷 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工作站,它将传统漫画创作与现代AI技术相结合,打造出独特的16-Bit复古游戏美学风格。这个工具特别适合…...

如何高效去除视频水印:基于LAMA模型的智能修复完整指南
如何高效去除视频水印:基于LAMA模型的智能修复完整指南 【免费下载链接】WatermarkRemover 批量去除视频中位置固定的水印 项目地址: https://gitcode.com/gh_mirrors/wa/WatermarkRemover 还在为视频中顽固的水印而烦恼吗?想要获得纯净无干扰的视…...