Python - 利用 OCR 技术提取视频台词、字幕

目录
一.引言
二.视频处理
1.视频样式
2.视频截取
◆ 裁切降帧
◆ 处理效果
3.视频分段
三.OCR 处理
1.视频帧处理
2.文本识别结果
3.后续工作与优化
◆ 识别去重
◆ 多线程提效
◆ 片头片尾优化
四.总结
一.引言
视频经常会配套对应的台词或者字幕,通过文本与字幕可以更好地理解视频内容。本文介绍如何使用 moviepy 库处理视频并使用 paddleocr 库实现视频文本识别,从而获取视频中出现的文字信息。
二.视频处理
1.视频样式
样例中我们以老电视剧 <三国演义> 为例,处理其剧集信息并获取对话文本。

视频中字幕展示位置位于视频正下发居中位置,为了减少 OCR 的识别工作量,提高 OCR 识别成功率,我们会优先对视频截取,只保留下方台词部分的关键帧信息。
2.视频截取
◆ 裁切降帧
from moviepy.editor import *# 对视频进行裁剪与缩放clip = VideoFileClip('/Users/Desktop/1.mkv')print("Ori FPS:{} Duration:{} Height:{} Width:{}".format(clip.fps, clip.duration, clip.w, clip.h))cut_clip = clip.crop(y2=clip.h - 11, height=70)cut_clip = cut_clip.set_fps(3)print("Cut FPS:{} Duration:{} Height:{} Width:{}".format(cut_clip.fps, cut_clip.duration, cut_clip.w, cut_clip.h))
- VideoFileClip
电影文件的视频剪辑类,必传的只有 filename 即视频文件的名称。它支持多种视频格式: .ogov、.mp4、.mpeg、.avi、.mov、.mkv 等。这里下载的 <三国演义> 使用的是 .mkv 格式。
- crop
crop 方法用于裁切视频。x1、y1 代表裁剪区域的左上角坐标。默认为视频的左上角;x2、y2 代表裁剪区域的右下角坐标。默认为视频的右下角。width,height 代表裁剪区域的宽度和高度。如果设置了这两个参数,x2、y2 的值将被忽略。center 代表裁剪区域的中心点坐标,如果设置了这个参数,x1、y1、x2、y2 的值将被忽略。所有坐标值都是以像素为单位的。当剪辑是图像剪辑时,可以进一步通过指定参数来优化裁剪效果。上面的参数含义表示将 clip 视频的底部向上 11 个像素开始裁剪,向上裁剪出 70 个像素高度的新片段,获得剪辑后的新视频。
- set_fps
set_fps 参数是用于设置帧率的。帧率是指在视频中每秒钟展示多少个连续的画面,单位是 fps(frames per second),译为 '每秒帧数'。如果你想让视频播放得更流畅,可以将帧率设置得更高。原始视频帧率较高 FPS=25,由于 OCR 识别相同帧内容可能相同,所以我们 set_fps(3) 以降低需要处理的视频帧数量,提高效率。
◆ 处理效果

Ori FPS:25.0 Duration:2625.36 Height:704 Width:528
Cut FPS:3 Duration:2625.36 Height:704 Width:70通过打印视频关键信息,我们得到裁切后的视频参数,可以看到新的视频宽度已缩减,且 FPS 帧率也下降为每秒 3 帧:

这里不同视频字母位置不同,大家可以本地测试几次,就能大致选到合适的位置参数。
3.视频分段
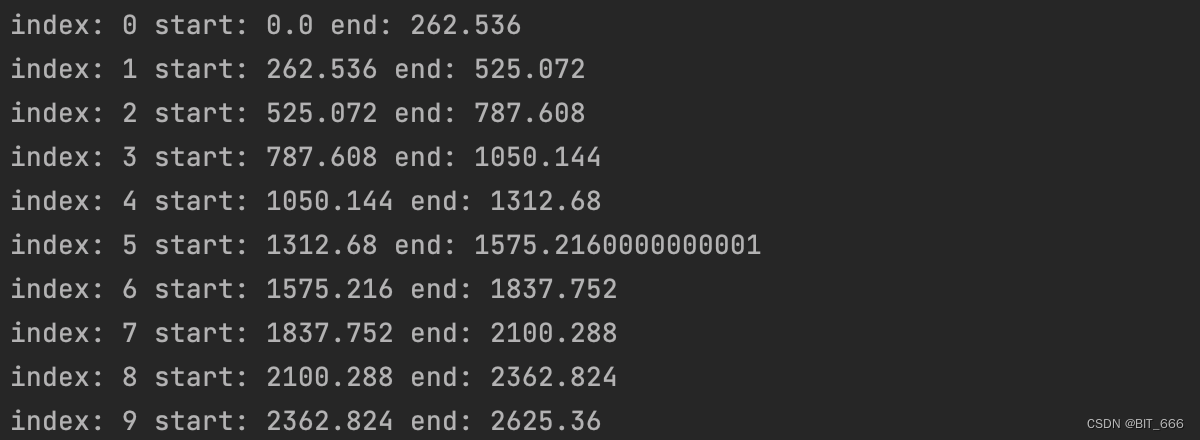
epoch = 10step = cut_clip.duration / epoch# 截取多个片段clips = []index = 0while index < epoch:# 获取分段的起止时间start = index * stepend = min(start + step, clip.duration)if start < clip.duration:sub_clip = cut_clip.subclip(start, end)print("index: {} start: {} end: {}".format(index, start, end))clips.append([start, sub_clip])else:breakindex += 1为了并发处理视频帧,我们可以将视频分为多段 cut,每一个 cut 启动一个 Process 进行 OCR 识别,所以我们通过 subclip 方法对视频进行了分段截取。这里 start、end 对应视频的秒数,通过 clip.duration 可以获取视频的总长,自定义分段数即可,这里我们划分 10 段:
可以通过 save 方法将每个分段保存到目录下供本地检查和校对:
三.OCR 处理
1.视频帧处理
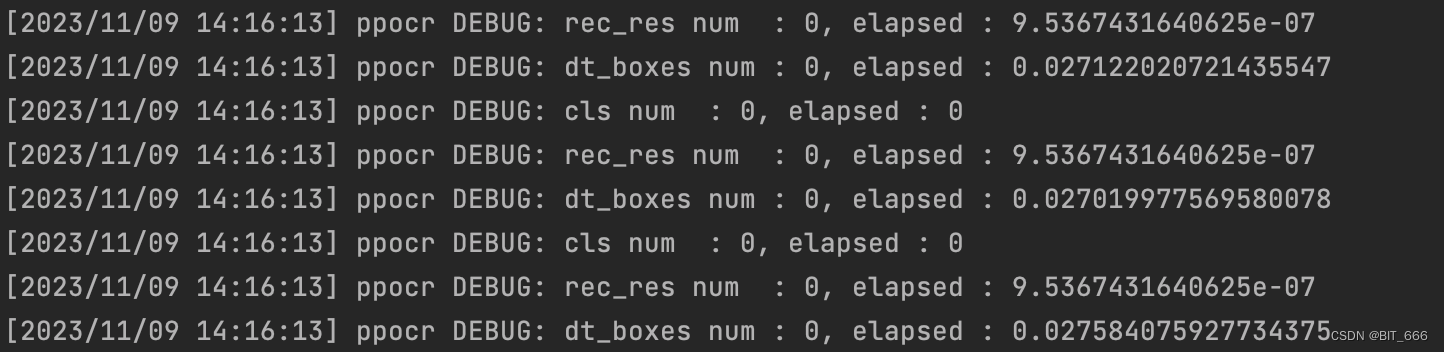
from paddleocr import PaddleOCRdef process_frame_by_ocr(st, tmp_clip):ocr = PaddleOCR(use_angle_cls=True, lang="ch", use_gpu=True)frame_rate = 1 / 3for cnt, cur_frame in enumerate(tmp_clip.iter_frames()):cur_start = frame_rate * (cnt + 1) + sttry:# det=True 表示在进行光学字符识别(OCR)之前,先对图像进行检测。result = ocr.ocr(cur_frame, det=True)if result is not None:see = result[0][0][1]cur_time = int(cur_start)doc_json = {'st': cur_time, "text": see}ocr_text = json.dumps(doc_json, ensure_ascii=False)open('result.json', 'a', encoding='utf-8').write(ocr_text + '\n')except Exception:pass这里引入 paddleocr 库进行视频帧的 OCR 文字识别,由于我们修改刷新率 FPS=3,所以每 s 有3帧视频,这里通过 frame_rate 记录每一帧出现的时间,其次调用 .ocr 方法识别图像,如果 result 识别到字幕即 text,我们会 'a' 添加至我们的 result.json 中并记录该台词出现的时间。下图为运行日志,由于识别过程中可能存在无字幕的情况,针对这类情况直接 pass:
2.文本识别结果
result.json 中会保存字幕在视频中出现的对应时间,text 除了识别内容外,还有一个概率标识其置信度,置信度越高,识别效果越靠谱。

3.后续工作与优化
◆ 识别去重
我们看到,虽然设置了 FPS=3,但是重复的文本还是很多,在得到原始的 result.json 文件后,我们还需要对文件进行去重和优选的步骤,一方面我们可以根据时间先后和字符长度,选择更为完整的句子,另一方面我们可以标胶不同识别结果的置信度,我们可以取数值更高置信度更高的样本作为最终结果。
◆ 多线程提效
我们可以尝试使用 multiprocessing 多线程处理多个分段任务,这里处理一集大约耗时为 5 min,采用多线程可以大大提高处理的效率。
[2023/11/09 14:14:15] ppocr DEBUG: rec_res num : 0, elapsed : 1.1920928955078125e-06
...
[2023/11/09 14:19:30] ppocr DEBUG: rec_res num : 0, elapsed : 0.0◆ 片头片尾优化
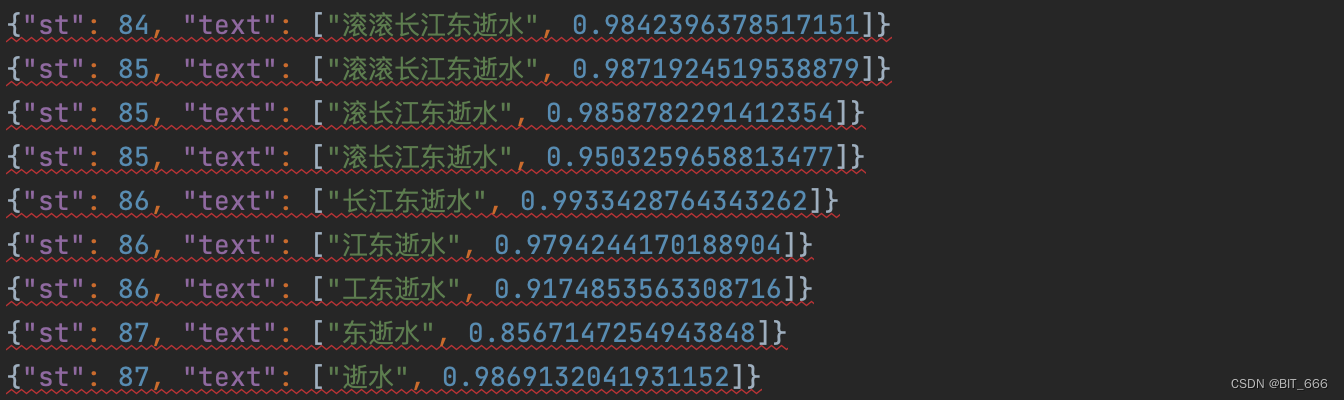
查看 result.json 的前端部分可以看到类似的滚动识别字幕,这是因为片头曲的滚动字幕造成的。我们可以像视频 APP 那样掐头去尾,获取更纯净的视频内容。这与片头片尾时间,最简单的就是我们打开视频掐一下,转换成 s 单位即可。

四.总结
本文介绍了基本的视频截取与识别的方法,就功能性而言,其实现了基本的功能。但是就结果而言,如果想要获取一些传统剧集的字幕与时间,我们可以直接到对应的字幕网站或者解析视频自带的字幕 SRT 文件,肥肠的方便:

相关文章:
Python - 利用 OCR 技术提取视频台词、字幕
目录 一.引言 二.视频处理 1.视频样式 2.视频截取 ◆ 裁切降帧 ◆ 处理效果 3.视频分段 三.OCR 处理 1.视频帧处理 2.文本识别结果 3.后续工作与优化 ◆ 识别去重 ◆ 多线程提效 ◆ 片头片尾优化 四.总结 一.引言 视频经常会配套对应的台词或者字幕,…...
VUE页面导出PDF方案
1,技术方案为:html2canvas把页面生成canvas图片,再通过jspdf生成PDF文件; 2,安装依赖: npm i html2canvas -S npm i jspdf -S 3,封装导出pdf方法exportPdf.js: // 页面导出为pdf格式 //titl…...

机器学习笔记 - WGAN生成对抗网络概述和示例
一、简述 Wasserstein GAN或WGAN是一种生成对抗网络,它最小化地球移动器距离 (EM) 的近似值,而不是原始 GAN 公式中的 Jensen-Shannon 散度。与原始 GAN 相比,它的训练更加稳定,模式崩溃的证据更少,并且具有可用于调试和搜索超参数的有意义的曲线。 Wasserstein 生成对抗网…...

HoudiniVex笔记_P0_Houdini中文文档与翻译
1、19.0版本中文说明文档 链接:https://pan.baidu.com/s/1oJcX5pdnBZ_YWWwOSnFB5g?pwdz3tw 提取码:z3tw 2、翻译插件 有上网条件的同学可以试试这个翻译插件:双语网页翻译 - 电子书翻译 - PDF翻译 - 字幕文件翻译浏览器扩展 | 沉浸式翻译…...

基于PowerWord的储能在主动配电网中的仿真研究
摘要 主动配电网是智能配电网技术发展的高级阶段,分布式储能是主动配电网的重要组成部分,分布式储能的应用对主动配电网的规划、运行、网络拓扑、故障处理和保护、可再生能源电源的协调优化等方面带来不容忽视的影响,针对这一现状,…...

并查集与最小生成树
并查集 HDOJ-1232 畅通工程 题目: 省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通,输入现有城镇道路统计表(表中列出了每条道路直接连通的城镇),求最少还需要建设的道路数量。(城镇从1到…...

平面运动机器人的传感器外参标定
简述 对任意两个传感器进行外参标定可以采用手眼标定算法来完成,但是,传统手眼标定算法对于运动具有一定的要求,可以证明,至少需要两个以上轴角方向不同的旋转运动才可以正确估计出外参旋转,因此,如果使用…...
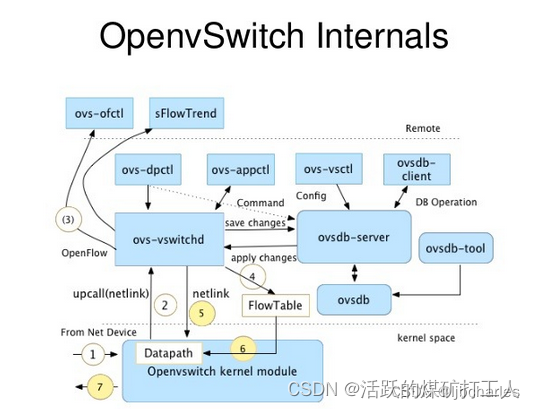
【星海随笔】SDN neutron (二) Neutron-plugin(ML2)
Neutron架构之Neutron-plugin Core-plugin(ML2)篇 Neutron-server接收两种请求: REST API请求:接收REST API请求,并将REST API分发到对应的Plugin(L3RouterPlugin)。 RPC请求:接收Plugin agent请求&#…...

野火i.MX6ULL开发板检测按键evtest(Linux应用开发)
之前一直查找不到evtest,因为没有下载成功,很可能是网络不好,下次可以软件源可以换成国内大学镜像网站。 重新断开板子电源启动,再次连接网络,下载evtest成功!!...

k8s存储
nfs 理论上nfs 其实并不是存储设备,它是一种远程共享存储服务。 k8s 存储卷 volume emptyDir:可以实现pod中的容器之间共享数据, 但是存储卷不能持久化数据,且会随着pod的生命周期一起删除。 hostpash:可以实现持久…...
数据分析实战 | 贝叶斯分类算法——病例自动诊断分析
目录 一、数据及分析对象 二、目的及分析任务 三、方法及工具 四、数据读入 五、数据理解 六、数据准备 七、模型训练 八、模型评价 九、模型调参 十、模型预测 一、数据及分析对象 CSV文件——“bc_data.csv” 数据集链接:https://download.csdn.net/d…...
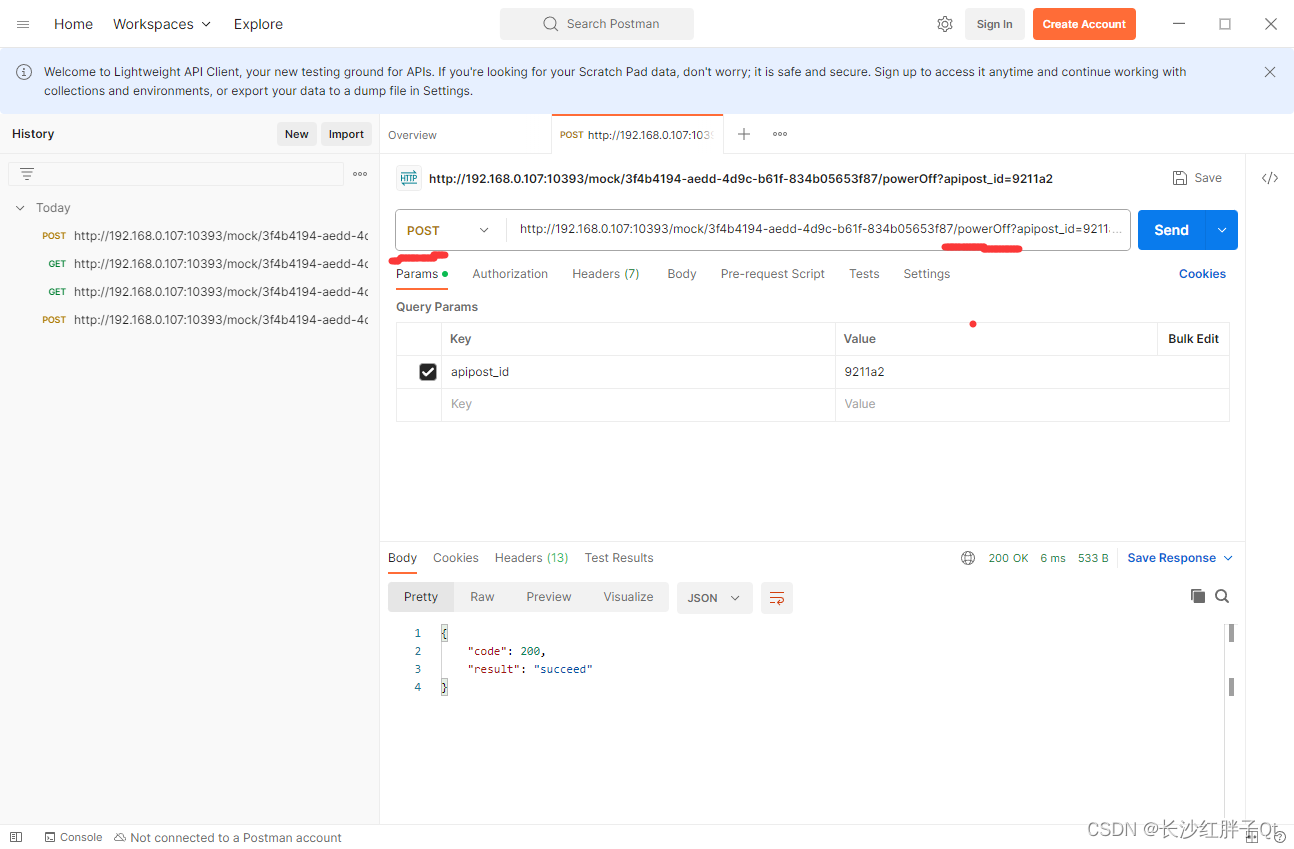
实用技巧:嵌入式人员使用http服务模拟工具模拟http服务器测试客户端get和post请求
文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/134305752 红胖子(红模仿)的博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、OpenGL、ffmpeg、OSG、单片机、软硬结…...

P9836 种树
容易想到分解因数。 对于一个数 p p p 的因数个数,假设它可以被分解质因数成 a 1 i 1 a 2 i 2 a 3 i 3 ⋯ a k c k a_1^{i_1} a_2^{i_2} a_3^{i_3}\cdots a_k^{c_k} a1i1a2i2a3i3⋯akck 的形式,则其因数个数为 ( i 1 1 ) ( i 2 1 )…...
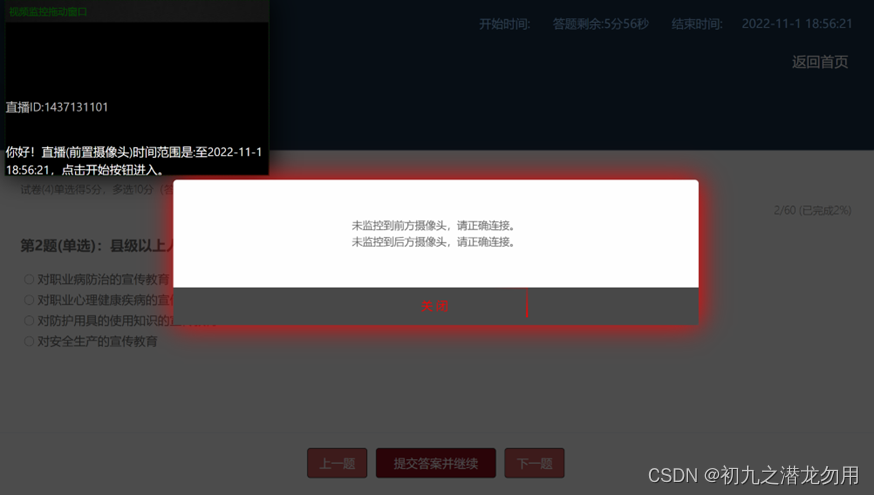
C# 查询腾讯云直播流是否存在的API实现
应用场景 在云考试中,为防止作弊行为的发生,会在考生端部署音视频监控系统,当然还有考官方监控墙系统。在实际应用中,考生一方至少包括两路直播流: (1)前置摄像头:答题的设备要求使…...
JAVA开源项目 于道前端项目 启动步骤参考
1. 安装 启动过程有9个步骤: 1.1 安装 Node JS , V18版本的 (安装步骤省略) 1.2 安装 npm install -g yarn ,node JS里边好像自带npm ,通过npm的命令安装 yarn 1.3 切换到项目中去安装,npm install &a…...
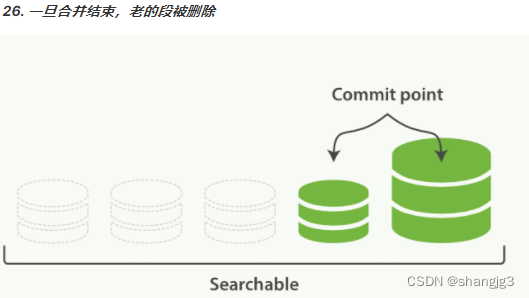
深入理解ElasticSearch分片
1. 路由计算 当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?首先这肯定不会是随机的&…...
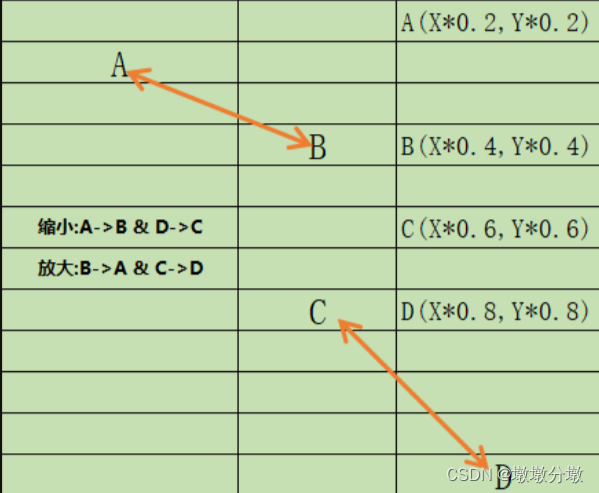
【Python】AppUI自动化—appium自动化元素定位、元素事件操作(17)下
文章目录 前言一.Appium 元素定位1.定位方式种类2.如何定位2.1 id定位2.2 className定位2.3 content-desc 定位2.4 Android Uiautomator定位4.1 text定位4.2 text模糊定位4.3 text正则匹配定位4.4 resourceId定位4.5 resourceId正则匹配定位4.6 className定位4.7 className正则…...

SpringBoot使用MyBatis多数据源
SpringBoot使用MyBatis多数据源 我们以 Mybatis Xml和注解两种版本为例,给大家展示如何如何配置多数据源。 1、注解方式 数据库文件: DROP TABLE IF EXISTS users; CREATE TABLE users (id bigint(20) NOT NULL AUTO_INCREMENT COMMENT 主键id,userN…...
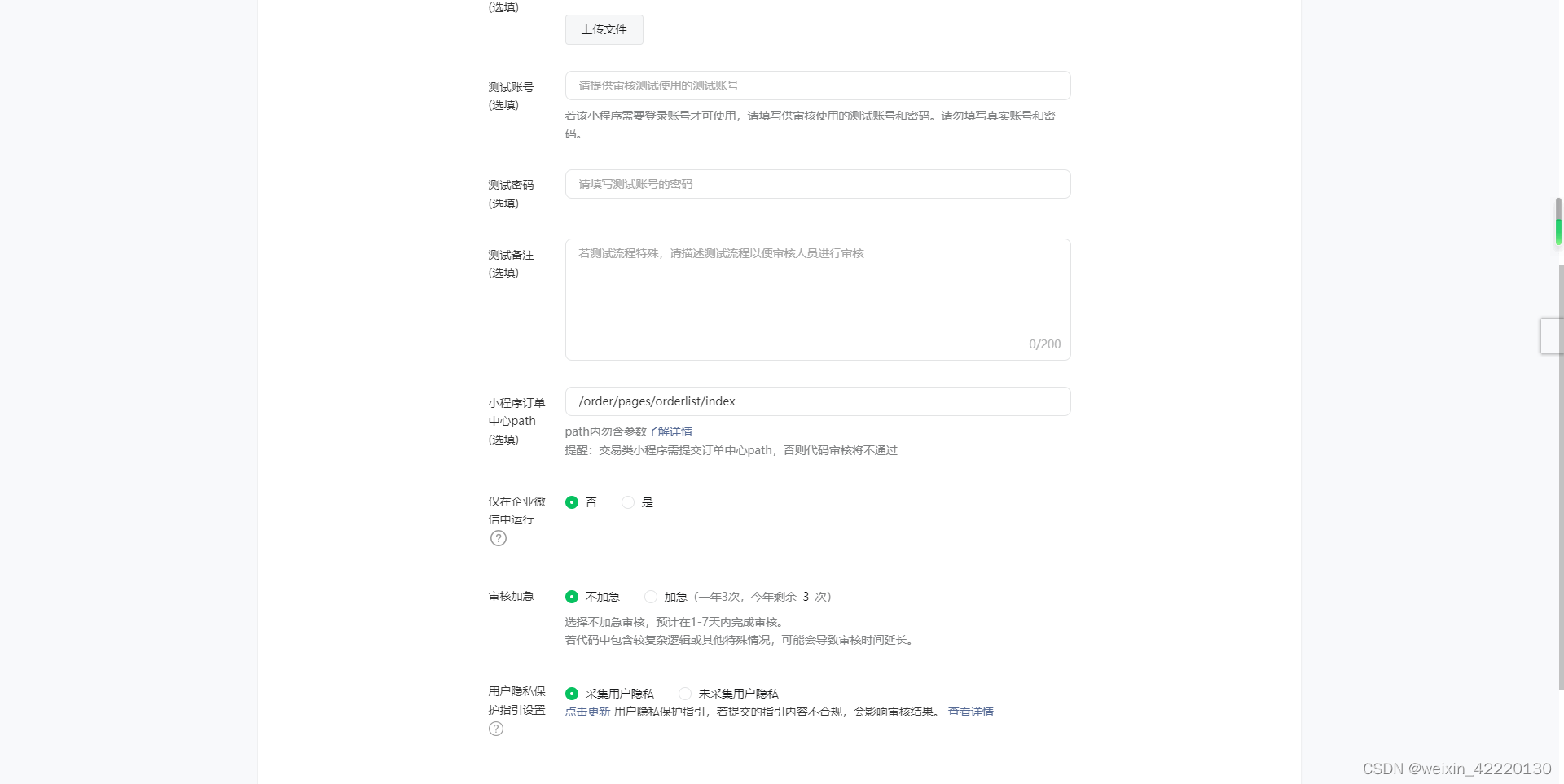
小程序版本审核未通过,需在开发者后台「版本管理—提交审核——小程序订单中心path」设置订单中心页path,请设置后再提交代码审核
小程序版本审核未通过,需在开发者后台「版本管理—提交审核——小程序订单中心path」设置订单中心页path,请设置后再提交代码审核 因小程序尚未发布,订单中心不能正常打开查看,请先发布小程序后再提交订单中心PATH申请 初次提交…...
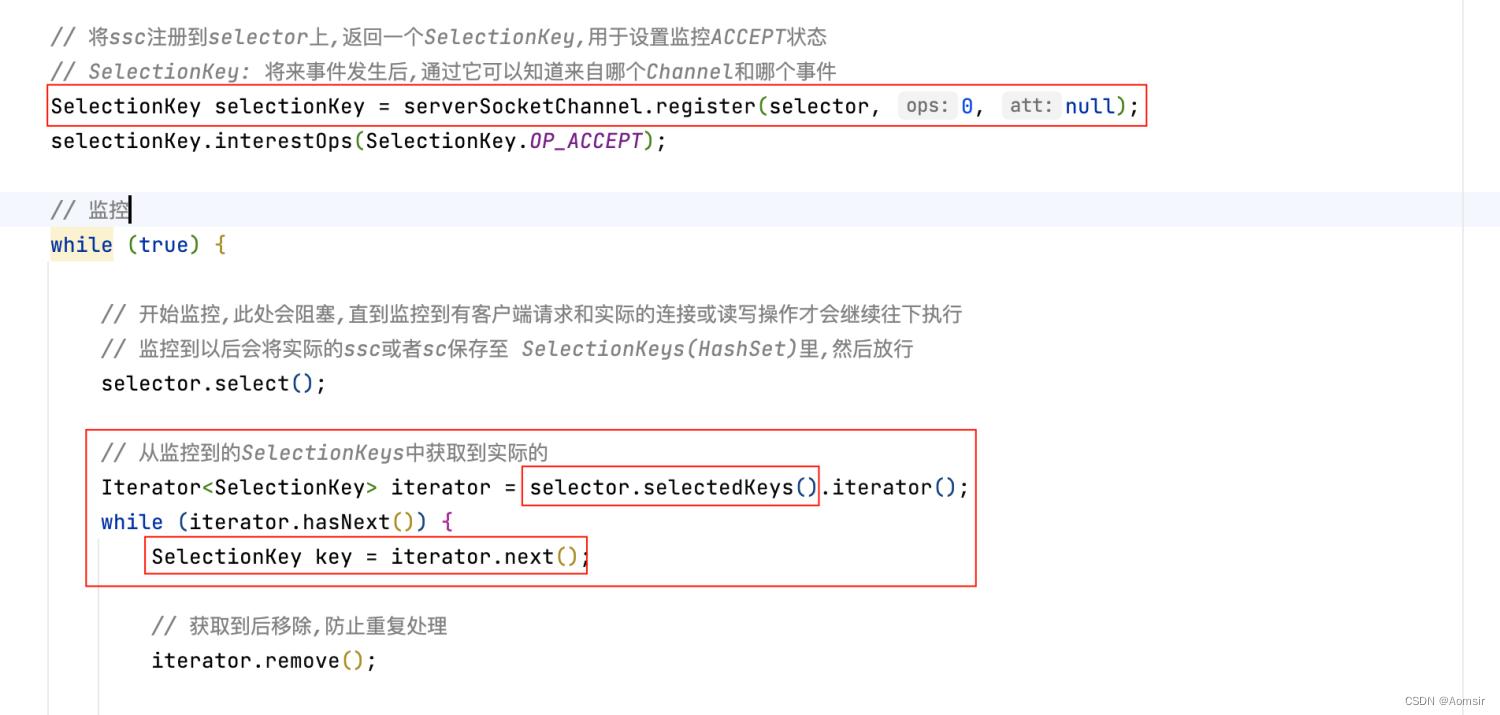
Netty入门指南之NIO Selector监管
作者简介:☕️大家好,我是Aomsir,一个爱折腾的开发者! 个人主页:Aomsir_Spring5应用专栏,Netty应用专栏,RPC应用专栏-CSDN博客 当前专栏:Netty应用专栏_Aomsir的博客-CSDN博客 文章目录 参考文献前言问题解…...

芯片设计中的Vt选择:如何平衡SVT、LVT和ULVT的速度与功耗
芯片设计中的Vt选择:如何平衡SVT、LVT和ULVT的速度与功耗 在28nm以下先进工艺节点中,阈值电压(Vt)选择已成为芯片设计的关键决策点。某次流片失败案例显示,由于ULVT单元使用比例过高,导致芯片静态功耗超标4…...
工作原理系列(十二))
AI智能体视觉检测系统(TVA)工作原理系列(十二)
——实战部署:TVA在柔性产线中的落地与ROI分析 作为技术人员,最终要面对的是项目的落地与交付。TVA系统在柔性产线(多品种、小批量)中的部署具有独特的优势。以一个汽车座椅调节器工厂为例,该工厂需要混线生产数十种型…...

别再用top了!用Linux内核自带的perf工具,5分钟定位线上服务CPU毛刺
告别top:用perf工具5分钟精准定位Linux服务CPU毛刺问题 凌晨3点,服务器告警铃声划破寂静——某核心服务的CPU使用率突然从15%飙升至98%,响应延迟突破秒级。运维团队迅速登录机器,习惯性输入top命令,却只看到"java…...

如何快速解密微信聊天记录:WechatDecrypt工具完全指南
如何快速解密微信聊天记录:WechatDecrypt工具完全指南 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 微信聊天记录承载着我们珍贵的回忆和重要的工作沟通,但当更换设备或需要数据…...

终极艾尔登法环帧率解锁与游戏增强完整指南:如何彻底释放高刷新率显示器潜力
终极艾尔登法环帧率解锁与游戏增强完整指南:如何彻底释放高刷新率显示器潜力 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.…...

抖音音频提取开源工具:一键获取背景音乐的高效解决方案
抖音音频提取开源工具:一键获取背景音乐的高效解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...
)
别再死记硬背了!用Plecs的AC Sweep功能,5分钟看懂电路稳定性(附波德图判据详解)
电力电子工程师的Plecs速成课:用AC Sweep一键生成波德图的实战指南 在电力电子设计领域,电路稳定性分析就像给系统做"心电图"——而波德图就是那张能揭示潜在风险的关键报告单。传统教材总爱从传递函数推导开始,让工程师陷入拉普拉…...
)
别再让上电火花吓到你!手把手教你用分立器件搞定12V电源缓启动(附完整BOM清单)
12V电源缓启动电路实战指南:从原理到BOM的完整解决方案 每次插拔12V电源时那刺眼的火花和随之而来的系统复位,是否让你感到头疼?这背后隐藏的浪涌电流问题,不仅可能损坏精密元器件,还会缩短连接器寿命。本文将带你深入…...

深入解析x86控制寄存器CR0:从分页机制到写保护的关键作用
1. CR0寄存器:x86架构的"控制中枢" 如果把CPU比作计算机的大脑,那么CR0寄存器就像是这个大脑的"控制面板"。这个32位的特殊寄存器直接决定了处理器如何管理内存、如何处理异常、甚至如何执行最基本的指令。我第一次在内核源码中看到…...

JAVA OOP概念POJO、DTO、DAO、PO、BO、VO详解
在 Java 后端开发中,面对复杂的业务场景和团队协作,如果没有清晰的数据对象分层,代码很容易变成“意大利面”——数据库字段变更影响前端接口,敏感信息意外泄露,业务逻辑与数据访问混为一谈。 今天,我们结合…...