从HDFS到对象存储,抛弃Hadoop,数据湖才能重获新生?
Hadoop与数据湖的关系
- 1、Hadoop时代的落幕
- 2、Databricks和Snowflake做对了什么
- 3、Hadoop与对象存储(OSD)
- 4、Databricks与Snowflake为什么选择对象存储
- 5、对象存储面临的挑战
1、Hadoop时代的落幕
十几年前,Hadoop是解决大规模数据分析的“白热化”方法,如今却被企业加速抛弃。曾经顶级的Hadoop供应商都在为生存而战,Cloudera于2021年10月8日完成了私有化过程,黯然退市
从数据湖方向发力的Databricks,却逃脱了“过时”的命运,于2021年宣布获得16亿美元的融资。另一个大数据领域的新星——云数仓Snowflake,2020年一上市就创下近12年来最大IPO金额,成为行业领跑者
行业日新月异,十年时间大数据的领导势力已经经历了一轮更替。面对新的浪潮,我们需要做的是将行业趋势和技术联系起来,思考技术之间的关联和背后不变的本质
Hadoop与Cloudera的潮起潮落详见文章:传送门
2、Databricks和Snowflake做对了什么
Hadoop和数据湖都是2006年开始兴起的概念。为什么同时期兴起,经历十多年发展,Hadoop逐渐衰落,数据湖反而迎来了热潮?
网络上有个说法:“公有云玩家”以零成本赠送Hadoop产品,加速了Hortonworks和Cloudera等厂商的衰落。但像 nowflake这样的新兴企业,它最大的合作伙伴却是AWS等云厂商。作为云厂商的生态系统合作伙伴,Snowflake推动了大量Amazon EC2/S3的销售
在我们看来,Hadoop只是数据湖的一种实现,而新一代数据湖通过拥抱云计算和开源社区,经历了新生
Databricks和Snowflake都抓住了OLAP的数据分析场景,基于兴起的云技术在数据存储和数据消费之间构建了新的中间数据抽象层(Data Virtualization),即屏蔽了底层系统的异构性,又提供了远超Hadoop生态系统的用户体验。这是他们能够成功的根本原因
在云计算的背景下,计算存储相分离的设计概念逐渐清晰,促进了现代数据湖和数据仓库的架构在数据存储和数据消费端的进一步解耦以及业界标准接口的规范化,这使得开源社区通过这些标准接口贡献新技术的发展成为可能
同时,公有云计算平台的出现,某种程度上加速了数据的垄断和计算需求的集中,推动业界对于数据以及数据处理做出更明确的需求定义,针对性地投入开源项目,以社区这种更灵活开放的方式促进技术发展,再反哺公有平台的进化和发展
传统的关系型数据库,如Oracle、DB2、MySQL、SQL Server等采用行式存储法,而一些新兴分布式数据库所采用的列式存储相较于行式存储能加速OLAP工作负载的性能,这已经是众所周知的事实
但在我们看来,更加革命性的变化是列式存储格式的标准化。Parquet和ORC的列式存储格式都是2013年发明的,随着时间的推移,它们已经被接受为业界通用的列式存储格式。数据是有惯性的,要对数据进行迁移和格式转换都需要算力来克服惯性;而数据的标准化格式意味着用户不再被某一特定的OLAP系统所绑定(Locked In),而是可以根据需要,选择最合适的引擎来处理自己的数据
第二大突破性技术是分布式查询引擎的出现,如SparkSQL、Presto等。随着数据存储由中心式向分布式演进,如何在分布式系统之上提供快速高效的查询功能成为一大挑战,而众多MPP架构的查询引擎的出现很好地解决了这个问题。SQL查询不再是传统数据库或者数据仓库的独门秘籍
在解决了分布式查询的问题之后,下一个问题是,对于存储于数据湖中的数据,很多是非结构化的和半结构化的,如何对它们进行有效地组织和查询呢?
在2016到2017年之间,Delta Lake、Iceberg、Hudi相继诞生。这些类似的产品在相近的时间同时出现,表明它们都解决了业界所亟需解决的问题。这个问题就是,传统数据湖是为大数据、大数据集而构建的,它不擅长进行真正快速的SQL查询,并没有提供有效的方法将数据组织成表的结构。由此,在缺乏有效的数据组织和查询能力的情况下,数据湖就很容易变成数据沼泽(Data Swamp)
利用云基础架构,是Databricks和Snowflake成功的关键
如果仔细了解一下Databricks和Snowflake的发展历程,可以发现两者的出发点有所不同。Databricks是立足于数据湖,进行了向数据仓库方向的演化,提出了湖仓一体的理念;而Snowflake在创建之初就是为了提供现代版的数据仓库,近些年来也开始引入数据湖的概念,但本质上说它提供的还是一个数据仓库
Snowflake利用云技术革新了传统数据仓库。它提供了一个基于公有云的、完全托管的数据仓库,把传统的软硬件一体的消费模式改造为了软件服务的模式(SaaS)
无论是存储还是计算,Snowflake都利用了公有云提供的基础设施,从而使任何人都可以在云端使用数据仓库服务
另一方面,传统的数据湖在数据分析上存在不足,不能很好地提供OLAP场景的支持。因此,Databricks通过Delta Lake提供的表结构和Spark提供的计算引擎,构建了一套完整的基于数据湖的OLAP解决方案。Databricks的愿景是基于数据湖提供包括AI和BI在内的企业数据分析业务的一站式解决方案
与Snowflake相似的是,Databricks也充分利用了云基础架构提供的存储和计算服务,在其上构建了入门成本低、定价随使用而弹性扩展的软件服务方案
3、Hadoop与对象存储(OSD)
近年来,存储正在经历新一轮革命:从Hadoop到对象存储(OSD)
数据湖和Hadoop并不是竞争关系。作为一种架构,数据湖会将其它技术整合到一起,而Hadoop则成为了一种可以用来构建数据湖的组件。换句话说,Hadoop和数据湖的关系是互补的,在可预见的未来,随着数据湖继续流行,Hadoop还将继续存在
然而,数据湖会抛弃Hadoop吗?有可能。因为作为一种综合性技术架构,除了Hadoop HDFS外,数据湖还可以选择“对象存储”作为它的核心存储
现在越来越多的,像Databricks、Snowflake这样的数据平台类创业公司选择采用对象存储作为存储的核心
从头开始搭建一个分布式存储很难。所谓“计算出了问题大不了重试,而数据出了问题则是真出了问题”。所以很多数据平台类的公司如Databricks、Snowflake等都会借着计算存储分离的趋势,选择公有云提供的存储服务作为它们的数据和元数据存储,而公有云上最通用的分布式存储就是对象存储

对象存储详解见文章:传送门
4、Databricks与Snowflake为什么选择对象存储
为什么Databricks与Snowflake会选择采用对象存储作为存储的核心?
从技术角度来说,首先,对象存储即为非结构化存储,数据以原始对象的形式存在。这点贴合数据湖对于先存储原始数据,再读取完整数据信息后续分析的要求
其次,对象存储拥有更先进的分布式系统架构,在可扩展性和跨站点部署上,比传统存储更具优势。由于对象存储简化了文件系统中的一些特性,没有原生的层级目录树结构,对象之间几乎没有关联性,因此对象存储的元数据设计能更为简单,能够提供更好的扩展性。此外,数据湖业务往往也需要底层存储提供多站点备份和访问的功能,而绝大部分对象存储原生支持多站点部署。通常用户只要配置数据的复制规则,对象存储就会建立起互联的通道,将增量和/或存量数据进行同步。对于配置了规则的数据,你可以在其中任何一个站点进行访问,由于跨站点的数据具备最终一致性,在有限可预期的时间内,用户会获取到最新的数据
第三,在协议层面,由AWS提出的S3协议已经是对象存储事实上的通用协议,这个协议在设计之初就考虑到了云存储的场景,可以说对象存储在协议层就是云原生的协议,在数据接口的选择和使用上更具灵活性
第四,对象存储本身就是应云存储而生,一开始起家的用户场景即为二级存储备份场景,本身就具备了低价的特性
因此,对象存储是云时代的产物,支持原始数据存储、分布式可扩展、高灵活性、低价,都是对象存储之所以被选择的原因
5、对象存储面临的挑战
新一代数据平台的基本架构都是存算分离,即计算层和存储层是松耦合的。计算层无状态,所有的数据、元数据以及计算产生的中间数据都会存储于存储层之中。这一架构的优势包括更好的扩展性(计算、存储独立扩展),更好的可用性(计算层的失效不影响存储,因此能够很快恢复),以及更低的成本。为了适应存算分离的架构,对象存储本身也需要进一步发展
想要适应存算分离的大趋势,不是简单地把现有存储对接到计算层就可以完成的,存储本身要经历新一轮架构革命才能更好地服务于计算层
在架构之外,数据平台型业务也给对象存储的特性提出了若干新的挑战
第一个挑战是数据分析型业务所需要的性能要远高于数据备份的场景,对象存储需要能够提供与计算需求相匹配的大带宽与低延时。另一方面,对象存储还需要根据业务场景来优化性能
第二个挑战来自于数据分析所包含的众多元数据操作。因此对象存储不仅要能够提供大带宽,还要在处理小对象和元数据操作,同时提供足够的性能。这就比较考验对象存储的元数据管理能力
第三个挑战是对象存储如何兼顾性能和成本。数据湖中存储了庞大的企业数据,但在任一时间点,可能只有一小部分数据是被数据分析业务所需要的。如果所有数据都放在性能最优的物理介质上(比如非易失性内存),那么成本将变得过高,失去了云存储的经济性,而如果在对象存储的前端再加一层Cache层,无疑也会增加整个系统的复杂度。因此如何有效识别冷热数据,并将它们分区放置是对象存储需要解决的问题
第四个挑战是对象存储如何与开源生态相结合。现阶段比较成熟的在数据湖之上提供表结构的开源产品是Delta Lake、Iceberg和Hudi。同时从应用场景上来说,在传统的离线数据分析场景之外,实时数据分析的业务场景正在增加。
参考文章:https://cloud.tencent.com/developer/news/870840
相关文章:
从HDFS到对象存储,抛弃Hadoop,数据湖才能重获新生?
Hadoop与数据湖的关系 1、Hadoop时代的落幕2、Databricks和Snowflake做对了什么3、Hadoop与对象存储(OSD)4、Databricks与Snowflake为什么选择对象存储5、对象存储面临的挑战 1、Hadoop时代的落幕 十几年前,Hadoop是解决大规模数据分析的“白…...

灰度与二值化
人工智能的学习之路非常漫长,不少人因为学习路线不对或者学习内容不够专业而举步难行。不过别担心,我为大家整理了一份600多G的学习资源,基本上涵盖了人工智能学习的所有内容。点击下方链接,0元进群领取学习资源,让你的学习之路更加顺畅!记得…...

No183.精选前端面试题,享受每天的挑战和学习
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...
[C国演义] 第十八章
第十八章 最长斐波那契子序列的长度最长等差数列等差序列划分II - 子序列 最长斐波那契子序列的长度 力扣链接 子序列 ⇒ dp[i] — — 以 arr[i] 结尾的所有子序列中, 斐波那契子序列的最长长度子序列 ⇒ 状态转移方程 — — 根据最后一个位置的组成来划分 初始化 — — 根…...

发送失败的RocktMQ消息,你遇到过吗?
背景 需要通过flink同时向测试和线上的RocketMQ中写入数据 现象 在程序中分别创建了两个MqProducer,设置了不同的nameServerAddr,分别调用不同的producer向不同环境发消息,返回发送成功,但是在线上MQ中却查不到数据࿰…...

Unity中全局光照GI的总结
文章目录 前言一、在编写Shader时,有一些隐蔽的Bug不会直接报错,我们需要编译一下让它显示出来,方便修改我们选择我们的Shader,点击编译并且展示编译后的Shader后的内容,隐蔽的Bug就会暴露出来了。 二、我们大概回顾一…...

毫米波雷达技术在自动驾驶中的关键作用:安全、精准、无可替代
自动驾驶技术正以前所未有的速度不断演进,而其中的关键之一就是毫米波雷达技术。作为自动驾驶系统中的核心感知器件之一,毫米波雷达在保障车辆安全、实现精准定位和应对复杂环境中发挥着不可替代的作用。本文将深入探讨毫米波雷达技术在自动驾驶中的关键…...

Jetson平台180度鱼眼相机畸变校正调试记录
1.需求说明 由于使用180度GMSL鱼眼相机,畸变很大; 如需算法使用,必须进行畸变校正 2. 硬件说明 相机: 森云 SG2-AR0233-5300-GMSL2-190H 主板: Jetson NX 3. opencv畸变矫正处理 3.1 获取内参系数 现在森云相机可以直接读取内部flash获取内参系数 3.2 畸变处理 …...
axios请求的问题
本来不想记录,但是实在没有办法,因为总是会出现post请求,后台接收不到数据的情况,还是记录一下如何的解决的比较好。 但是我使用export const addPsiPurOrder data > request.post(/psi/psiPurOrder/add, data); 下面是封装的代码。后台接…...

【pandas刷题系列】Leetcode Problem: [595. 大的国家]
Problem: 595. 大的国家 文章目录 思路解题方法复杂度Code 思路 筛选出对应的数据,然后将不需要的列去除 解题方法 筛选出对应的数据,然后将不需要的列去除 复杂度 时间复杂度: O ( n ) O(n) O(n) 空间复杂度: O ( n ) O(n) O(n) Code import pandas a…...

【打卡】牛客网:BM46 最小的K个数
资料: 1. 排序 sort(name.begin(),name.end()); //升序 sort(name.rbegin(),name.rend()); //降序 【C】vector数组排序_vector排序_比奇堡咻飞兜的博客-CSDN博客 2. 把v2的部分值赋给v1 v1.assign(v2.begin(), v2.end()); // 用新元素替换vector 中的元素。…...

Android各类View触摸监听器失效
在XML布局中出现重叠的View,位置靠后定义的View会覆盖住位置靠前的View;即靠后的View会拦截触碰事件导致靠前的View无法收到触碰事件,无法触发监听器。 //例.<?xml version"1.0" encoding"utf-8"?> <android…...

未整理的知识链接
【scala】下划线用法总结 【scala】下划线用法总结_scala 下划线-CSDN博客 Spark Sql Row 的解析 Spark Sql Row 的解析 - 简书 spark dataframe foreach spark dataframe foreach_mob64ca12f0cf8f的技术博客_51CTO博客 spark- Dataframe基本操作-查询 https://blog.csdn.n…...
【2011年数据结构真题】
41题 41题解答: (1)图 G 的邻接矩阵 A 如下所示: 由题意得,A为上三角矩阵,在上三角矩阵A[6][6]中,第1行至第5行主对角线上方的元素个数分别为5, 4, 3, 2, 1 用 “ 平移” 的思想,…...
【科研绘图】MacOS上的LaTeX公式插入工具——LaTeXiT
在Mac上经常用OmniGraffle绘图,但是有个致命缺点是没办法插入LaTeX公式,很头疼。之前有尝试用Pages文稿插入公式,但是调字体和颜色很麻烦。并且,PPT中的公式插入感觉也不太好看。 偶然机会了解到了LaTeXiT这个工具,可…...

仓库自动化中的RFID技术的应用浅谈
仓库自动化与RFID技术的结合代表着现代供应链管理的一个重要革新。这两者的协同作用能够显著提升仓储效率、降低成本、增强库存管理、提高货物跟踪的准确性,并且使仓库操作更加智能化。 仓库自动化是一种通过应用自动化技术和系统来管理和优化仓库操作的方法。这种…...
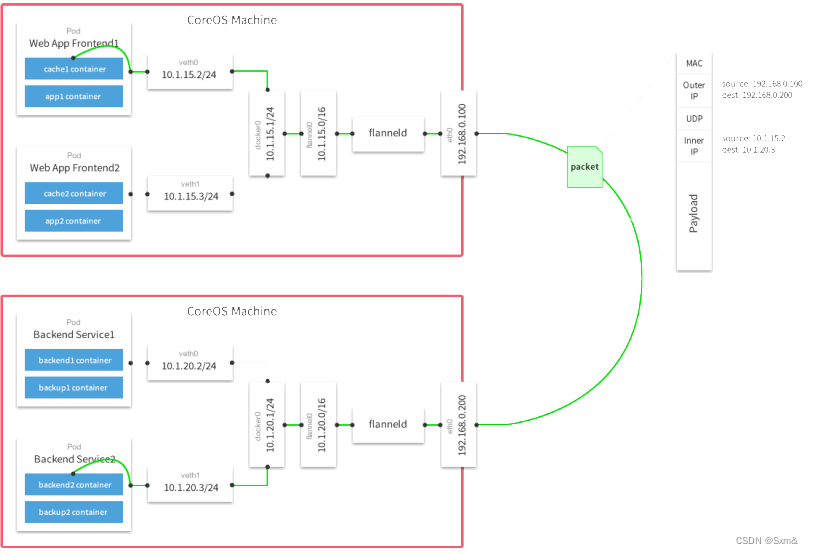
容器网络-Underlay和Overlay
一、主机网络 前面讲了容器内部网络,但是容器最终是要部署在主机上,跨主机间的网络访问又是怎么样的,跨主机网络主要有两种方案。 二、 Underlay 使用现有底层网络,为每一个容器配置可路由的网络IP。也就是说容器网络和主机网络…...
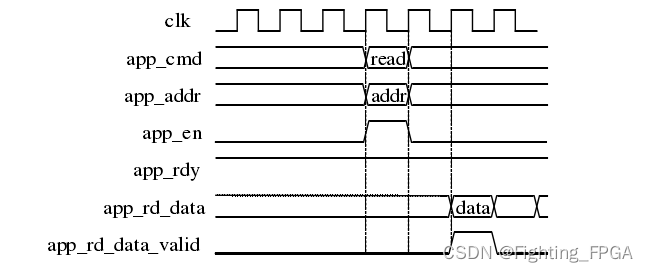
基于FPGA的PCIe-Aurora 8/10音频数据协议转换系统设计阅读笔记
文章可知网下载阅读,该论文设计了一种 PC 到光纤模块(基于Aurora的光纤传输)的数据通路,成功完成了Aurora 以及 DDR 等模块的功能验证。 学习内容: 本次主要学习了Pcie高速串行总线协议、Aurora高速串行总线协议、DDR相…...

stm32控制舵机sg90
一、sg90简介 首先介绍说一下什么是舵机。舵机是一种位置(角度)伺服的驱动器。适用于一些需要角度不断变化的,可以保持的控制系统。sg90就是舵机的一种。 舵机的工作原理比较简单。舵机内部有一个基准电压,单片机产生的PWM信号通…...
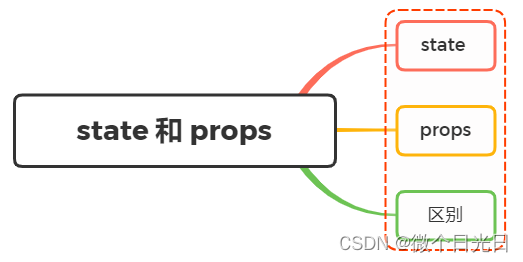
state 和 props 有什么区别?
一、state 一个组件的显示形态可以由数据状态和外部参数所决定,而数据状态就是 state,一般在 constructor 中初始化 当需要修改里面的值的状态需要通过调用 setState 来改变,从而达到更新组件内部数据的作用,并且重新调用组件 r…...

从U9C到钉钉:基于OPENAPI的审批流集成实战与避坑指南
1. 为什么需要U9C与钉钉审批流集成 在企业日常运营中,U9C作为ERP系统承担着核心业务管理功能,而钉钉则是移动办公和流程审批的利器。但两套系统各自为政时,会产生不少痛点。最常见的就是业务人员在U9C中生成采购单后,还要手动到钉…...

3个超实用技巧解决Upscayl GPU加速初始化失败问题
3个超实用技巧解决Upscayl GPU加速初始化失败问题 【免费下载链接】upscayl 🆙 Upscayl - #1 Free and Open Source AI Image Upscaler for Linux, MacOS and Windows. 项目地址: https://gitcode.com/GitHub_Trending/up/upscayl 您是否也曾满怀期待地下载了…...

3步轻松备份QQ空间回忆:GetQzonehistory让青春记忆永不丢失
3步轻松备份QQ空间回忆:GetQzonehistory让青春记忆永不丢失 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾担心QQ空间里的青春记忆会随着时间流逝而消失࿱…...

等了47年,苹果这台史上最强电脑,真的要逆天了!
嘿,距离 2026 年 6 月的 WWDC 开发者大会只剩不到两个月了,你准备好了吗?我桌上这台 M2 Pro Mac mini 已经勤勤恳恳服役了三年。但根据最新的风声,苹果即将在 6 月发布搭载 M5 Max 和 M5 Ultra 芯片的 Mac Studio。随着 Mac Pro 逐…...

LS2K0300 龙芯智能车开发:基于WSL的交叉编译环境一站式配置指南
1. 为什么选择WSL搭建龙芯开发环境 最近在折腾LS2K0300龙芯智能车项目时,发现很多小伙伴都在问同一个问题:为什么非要用WSL?直接在Windows上装个虚拟机不行吗?作为一个踩过无数坑的老司机,我必须说WSL真的是Windows下…...

收藏!后端转大模型开发1年,从CRUD麻木到眼里有光,小白也能参考的转行实录
做后端开发整整五年,说句实在话,日常工作几乎离不开CRUD的循环——增删改查反复敲,偶尔优化下接口响应速度、排查线上突发的bug,日子过得像精准运转的发条钟,安稳是真安稳,但越往后走,心里的恐慌…...

Qwen3.5-9B后端开发核心技能树:从网络协议到系统设计
Qwen3.5-9B后端开发核心技能树:从网络协议到系统设计 1. 后端开发者的成长路线图 后端开发就像建造一座大楼的地基和骨架,虽然用户看不见,但决定了整个系统的稳定性和扩展性。作为一位有10年经验的架构师,我将带你系统性地梳理后…...

【深度剖析】CentOS7紧急救援模式:从I/O误报到/usr/lib目录丢失的完整修复实录
1. 当CentOS7突然罢工:紧急救援模式初体验 那天早上我像往常一样启动节后复工的CentOS7虚拟机,结果迎接我的不是熟悉的登录界面,而是一串令人心跳加速的红色报错。屏幕最上方赫然显示着"Welcome to emergency mode!",后…...

终极指南:3步快速备份你的QQ空间完整历史记录
终极指南:3步快速备份你的QQ空间完整历史记录 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否担心QQ空间的珍贵记忆会随着时间流逝而消失?GetQzonehistory…...

5个技巧,让Qwen-Image-2512-SDNQ帮你生成电商级产品图
5个技巧,让Qwen-Image-2512-SDNQ帮你生成电商级产品图 1. 为什么选择Qwen-Image-2512-SDNQ生成产品图 在电商运营中,高质量的产品图片直接影响转化率。传统摄影需要专业设备、场地和后期处理,成本高且周期长。Qwen-Image-2512-SDNQ模型通过…...