【ElasticSearch系列-07】ES的开发场景和索引分片的设置及优化
ElasticSearch系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】ElasticSearch下载和安装 | https://zhenghuisheng.blog.csdn.net/article/details/129260827 |
| 【二】ElasticSearch概念和基本操作 | https://blog.csdn.net/zhenghuishengq/article/details/134121631 |
| 【三】ElasticSearch的高级查询Query DSL | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【四】ElasticSearch的聚合查询操作 | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【五】SpringBoot整合elasticSearch | https://blog.csdn.net/zhenghuishengq/article/details/134212200 |
| 【六】Es集群架构的搭建以及集群的核心概念 | https://blog.csdn.net/zhenghuishengq/article/details/134258577 |
| 【七】ES的开发场景和索引分片的设置及优化 | https://blog.csdn.net/zhenghuishengq/article/details/134302130 |
ES的开发场景和索引分片的设置及优化
- 一,ES的开发场景和索引分片的设置及优化
- 1,ES应用场景
- 1.1,信息搜索库
- 1.2,时间序列库
- 2,分片的设计和管理
- 2.1,单个分片
- 2.2,多个分片
- 2.2.1,算分不准原因
- 2.3,分片的设计
- 2.3.1,分片类型选择以及优缺点
- 2.3.2,主分片设计与案例
- 2.3.3,副本分片设计
- 3,ElasticSearch底层读写原理
- 3.1,数据的写入
- 3.1.1,数据写入的流程
- 3.2.2,数据存储文件形式
- 3.2,数据的读取
- 3.2.1,根据id查询
- 3.2.2,根据关键字查询
- 3.3,数据读写优化
一,ES的开发场景和索引分片的设置及优化
在上一篇中,讲解了Es集群的搭建,以及一些索引,分片,副本等的概念,接下来这篇主要讲解在实际开发中,ElasticSearch的一些应用场景
1,ES应用场景
在实际开发中,es主要有两种应用场景:一种是基于数据量大,但是数据增长量慢的应用场景,如订单查询,商品查询等;一种是基于数据量大,数据增长量快的应用场景,如每天都会有大量的日志信息,通过时间序列对日志进行存储和查询等。
1.1,信息搜索库
这就是第一种情况,针对于数据量大,但是增长量慢的应用场景。如在一个商城app中,其商品的信息、订单的信息等,在数据加入到es之后,可以选择通过商品的类型或者名称进行分片存储,在查询时只需要根据商品类型或者名称查询对应的分片结点即可
这种场景更加需要考虑的是搜索的相关度,如涉及算分,权重这些,与时间的范围无关。
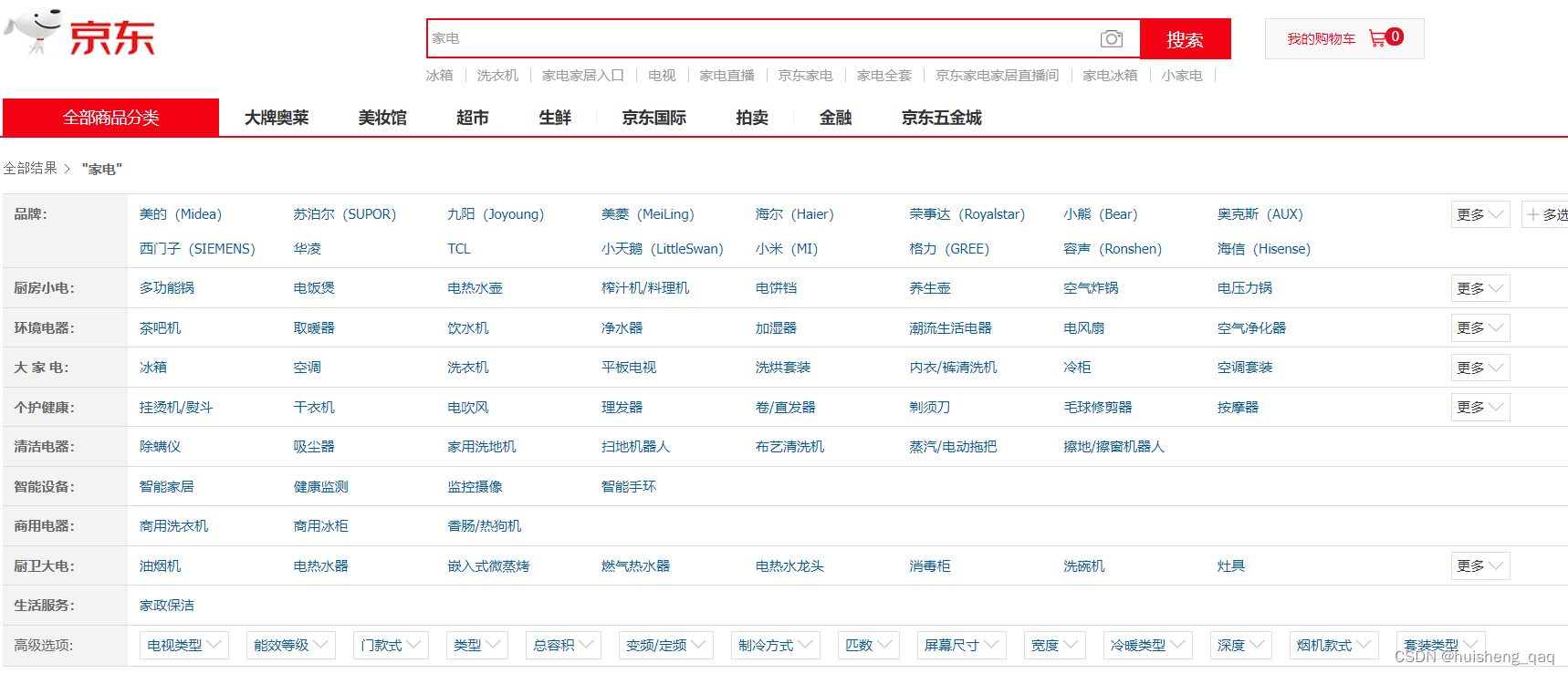
如上图中搜索框中输入的家电,下面会展示所有的家电信息,品牌等,那么在es中做索引分片时,就可以根据品牌进行分片存储等。需要注意的是,单个分片最好不要数据量太大,如不要超过20g,如果数据量太多,可以通过增加副本分片的数量,从而提高吞吐量
如果是单个索引的数据量太大,可以通过reindex进行索引拆分,可以根据某种枚举字段进行拆分,如订单可以根据区域进行拆分,商品根据品牌进行拆分等。
1.2,时间序列库
根据时间序列进行统计,容日志的查询等,一般每条数据都会有一条时间戳,并且每条文档基本上都不会更新,主要是为了查询,因此对数据的写入要求会比较高。如每天有几万条数据插入到es数据库中
在创建索引时,可以直接根据时间进行创建索引,如每天或者每周或者每月的方式进行划分,如每天有上万条日志信息,那么就可以直接根据时间进行创建索引,每天晚上可以开启一个定时任务去创建索引,随后今天一天的数据全部存储在这个索引中,后续作统计时,只需要定位到这个索引片即可
PUT /logs_2023-11-07
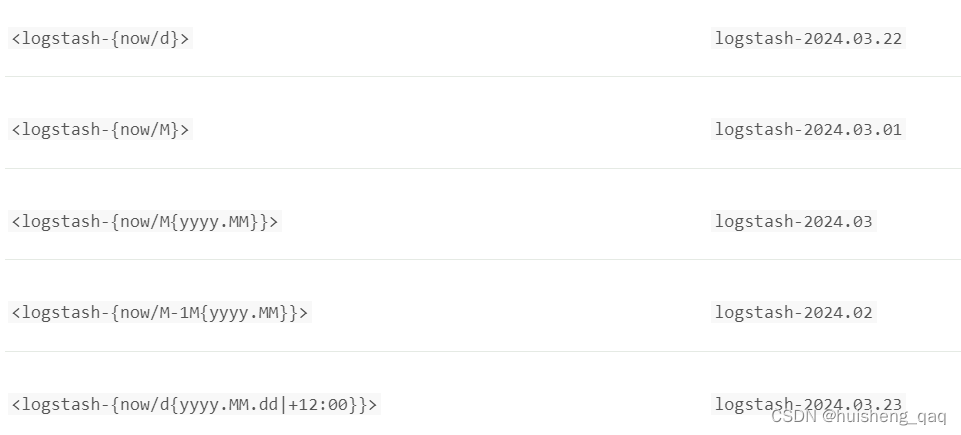
也可以直接选择使用这个Date Math表达式,其语法如下
<static_name{date_math_expr{date_format|time_zone}}>
使用这个Date Math的官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.16/date-math-index-names.html
如官方文档给的实例,显示的结果就是创建今天的日期的索引,前缀就是my-index
# PUT /<my-index-{now/d}>
PUT /%3Cmy-index-%7Bnow%2Fd%7D%3E
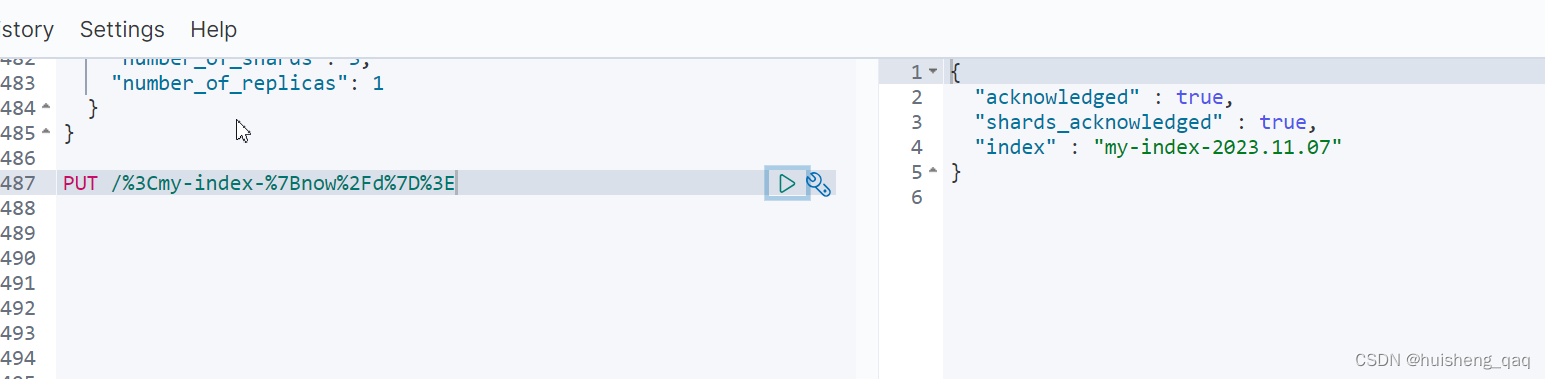
上面的百分号在官网中也有对应的值,只需要根据这些值进行修改即可

官网提供的转义表达式有这些,如now/d等等,从<、-、{、}、/ 等一一的按照上面的值进行替换即可
如果是需要查询最近的数据,也可以采用冷热分离的架构,将最近几天的数据加入到hot热点数据中;并且在存储日志这种信息是,丢失几条数据也是没事的,因此在设置副本的数量时,可以直接设置为0
如果前端是要固定的查询一个索引,那么可以通过别名的方式去新增索引,先将原索引删除,然后将创建的新索引的别名设置为原索引的名称
2,分片的设计和管理
2.1,单个分片
在es7开始,在创建一个索引时,默认是只有一个分片和一个副本的。如下例子,本人就是使用的7.7的版本,在创建一个索引之后,其默认的分片数和副本数就是1。因为直接使用单个分片,可以避免很多问题,如算分问题,聚合问题等
"number_of_shards" : "1",
"number_of_replicas" : "1",
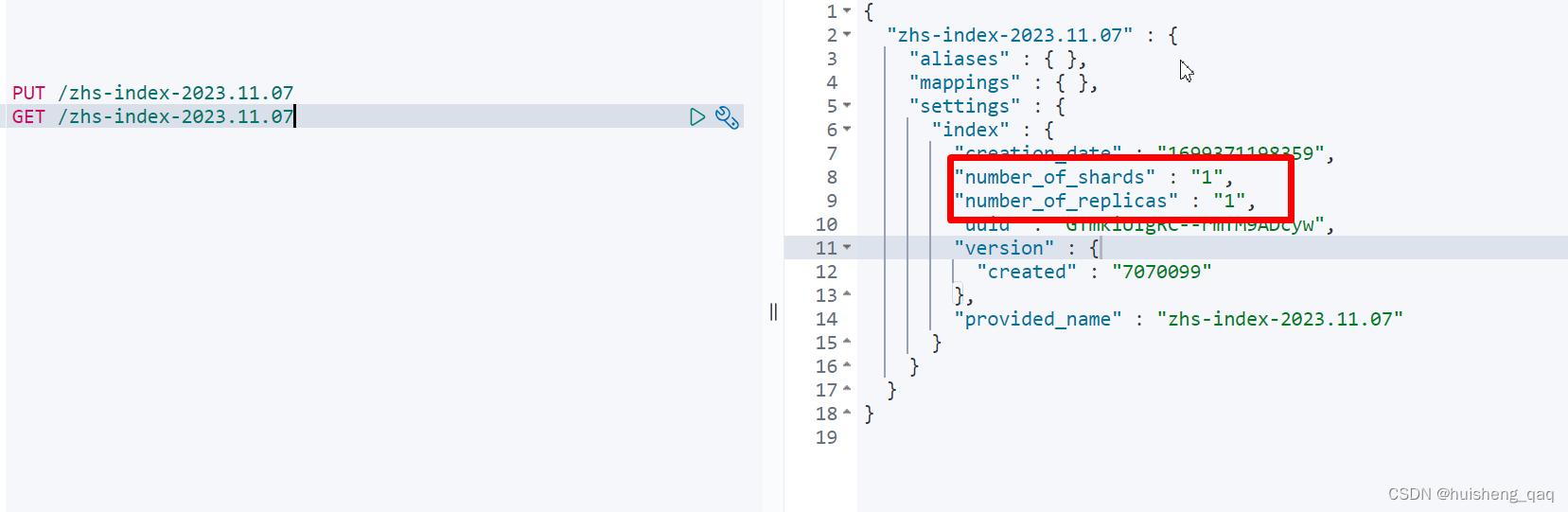
但是单个分片也存在一些缺点,如在集群中,单个分片不能很好的实现水平扩展,除非要手动reindex增加分片,将数据进行拆分
2.2,多个分片
多个分片和单个分片的优缺点刚好相反,多个分片是有利于实现节点的水平扩展的,在性能上会高于单分片的索引。但是多分片也会出现一些问题,如算分不准,聚合查询等问题
2.2.1,算分不准原因
当数据量大的时候,一般数据都是均分分布在各个节点的,因此不会出现这种算分不准的情况,一般是会出现在数据量小的情况,如每个分片的数据量都比较小,举个例子
先创建一个索引,并设置分片数为3
PUT /zhs_db
{"settings":{"number_of_shards" : "3"}
}
随后往文档中插入数据,这里不使用_bulk批量插入,因为批量插入会在一个分片中。往里面插入三条数据,根据hash规则,那么三条数据就会分别落在三个分片中,一个分片中一条数据
POST /zhs_db/_doc/1?routing=zhenghuisheng
{"content":"Cross Cluster elasticsearch Search"
}POST /zhs_db/_doc/2?routing=zhenghuisheng2
{"content":"elasticsearch Search"
}POST /zhs_db/_doc/3?routing=zhenghuisheng3
{"content":"elasticsearch"
}随后进行match查询这个content,并且value为elasticSearch
GET /zhs_db/_search
{"query": {"match": {"content": "elasticsearch"}}
}
在执行上面的查询之后,其结果如下,本来是所占文档比率越高,算分的值越大,就是id为3的占百分百,因此按理来说是算分最高的,然而实际在查询出来的是id为1的算分最高,实际id为1的算分是最低的,因此综合来看,这个算分就是不准的
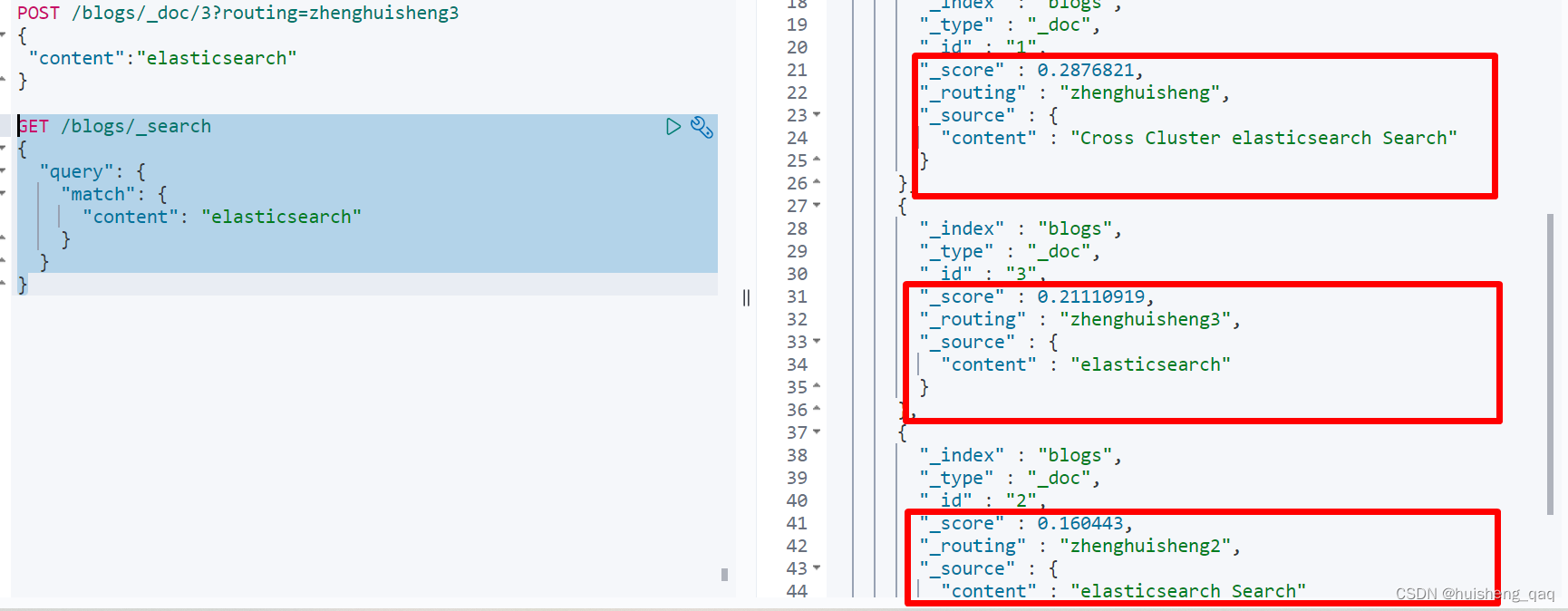
主要原因是每个分片都有自己打分的标准,每个分片都是基于自己分片上的数据的相关度来进行计算的,其最主要原因是数据量少,因此如果是数据量少的情况下,还是建议设置这个分片数为1
当然在数据量小的时候,也有对应的解决方案,就是使用DFS Query Then Fetch ,其原理就是将所有的数据全部搜索出来,然后统一放在一个协调结点中,通过协调节点再进行一次完整的算分。但是在实际开发中,这种方式并不推荐使用,因为其性能相对是较低的
GET /zhs_db/_search?search_type=dfs_query_then_fetch
{"query": {"match": {"content": "elasticsearch"}}
}
2.3,分片的设计
2.3.1,分片类型选择以及优缺点
上面说了单个分片和多个分片使用的优缺点,接下来谈谈在实际开发中,是如何设计这个分片的。
往往来说,分片的数量是需要大于结点数的,那么这样基本都是优选考虑多分片数据,这样有利于在新增数据节点时,可以进行自动的分配,并且如果一个索引的数据分布在不同的节点,这样就可以并行的执行,并且在数据写入时,也可以分散到多个机器。
但是分片过多,也会带来一些副作用,因为每一个分片就是一个Lucene索引,其实就是一个进程,如果过多的分片,就会占用机器的资源,导致带来额外的开销,并且所有的分片都是需要Master主节点进行维护和管理,这样就会导致master主节点承受更大的负担,因此分片需要控制在10W之内
2.3.2,主分片设计与案例
在实际开发中,日志类的数据只需要设置主分片数,但是不需要设置副本数,而其他的数据增长量慢的需要设置主分片数和副本数,接下来谈谈主分片数需要如何设计
- 当数据为搜索类时,如商品信息类,那么单个分片不要超过20个G的数据
- 当数据为日志类时,如订单类、流水类,那么单个分片不要超过50G的数据
搜索类设计:如根据品牌进行设计,一个品牌对应一个索引,一个索引对应一个主分片和一个副本分片
日志类设计:每天创建一个日志索引,每个日志索引创建10个分片,一个月需要创建300个分片,不需要副本
2.3.3,副本分片设计
一般在实际开发中,副本都是设置为0或者1,日志类数据不需要副本,可以直接设置为0,搜索类数据一般设置为1,副本就是类似于主分片的一个从分片,有主分片中的全部数据。
副本分片数据就是数据在住分片中插入完成之后,再在副本分片中再保存一份,如果副本分片数过多,那么在存入副本数据时就会花费更多的时间,在写性能上会有一定的影响
但是副本分片也有好处,首先就是可以提高查询的效率,并且可以防止数据丢失,保证数据的安全性,因此副本分片是需要的,但是也不能设计太大,日志类除外。并且可以通过不断的调整副本分片的个数,来是整个系统的查询率和响应率达到最佳状态
为了避免分配的不均衡,分片数的调整如下:
- index.routing.allocation.total_shards_per_node:表示在索引中每个Node的最大分片数量,-1表示无穷大
- cluster.routing.allocation.total_shards_per_node:表示在集群中每个Node结点最大分片的数量,-1表示无穷多个
3,ElasticSearch底层读写原理
上面谈到了分片和副本的一些概念和设计,接下来通过es写入数据的流程来分析,分片和副本的功能到底是什么。
3.1,数据的写入
3.1.1,数据写入的流程
在前面谈到了通过不同的数据节点实现不同的功能,写入请求是需要先通过协调节点,在转发到data数据节点存储,随后先将数据存储到主分片上面,然后再将数据同步到副本分片上面,其具体的流程实现如下
- 1,在用户发起写请求之后,首先该请求会先到协调节点
- 2,协调结点接收到这个请求之后,会通过route路由的方式将请求转发给对应的节点
- 3,随后会将数据同步到该节点的主分片上,如果有副本分片,则将数据给副本分片也同步一份
- 4,当master主分片和副本分片都同步完数据之后,协调节点再给客户端一个存入成功的响应
3.2.2,数据存储文件形式
segment file :在mysql中,mysql是以页为单位存储在磁盘中,在ElasticSearch中,是通过这个Segment file的方式存储,每一个文件的本质就是一个倒排索引,一个大的分片中,都是由各个小的Segment file文件合并成的。文件过多时会自动合并各个小文件,也可以手动强制合并,在合并时会将被标记删除的文档给物理删除
commit point :当将某个文档删除时,ElasticSearch不会立马删除,而是先通过这个commit point文件做一个标志,每个文件中都有.del的一个标志,如果设置了被删除的状态,那么在查询数据时,默认会将这个文档给过滤掉。这个也有点类似于mysql的行格式,里面有字段用于标记是否被删除
translog文件 :类似于mysql的redolog文件,防止因为宕机造成数据丢失,用于做数据恢复
os cache :缓存,每隔一s会进行一个刷盘操作,也可以通过refresh强制刷盘
3.2,数据的读取
数据的查询主要有两种方式,一种是直接根据id进行查询,一种是直接根据关键字进行匹配
3.2.1,根据id查询
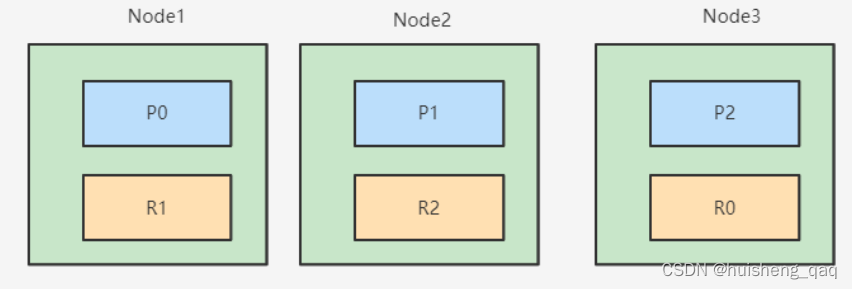
根据id查询的方式是比较简单的,首先也是先由客户端发起请求,随后将请求发送到协调者结点,协调者节点通过这个id进行hash取模定位到Data数据节点,数据节点上有主分片和副本分片,这两种分片都可以进行数据的查询,会通过随机的方式选择副本还在主分片,如下面的P0和R0,会在这两个分片中,选择一个分片作为数据查询的依据,随后将响应结果返回给协调者分片分片,最后再通过协调者分片将数据返回给用户
当然如果副本分片和主分片之间,也可以做一个负载均衡,来提高整个系统的高性能
3.2.2,根据关键字查询
其流程大致和上面的一样,先将请求给协调者节点,随后定位到Data数据节点,但是在查询数据再到返回数据的过程中,需要经历过两个阶段的操作。
因为es底层使用的是倒排索引,因此第一步是先将需要查询带有关键字的数据全部查询出来,随后携带那一行数据的id,再通过id查询,这就是相当于要查询两次,用mysql来解释,就是通过一个加了索引的字段进行数据查询,随后将携带的id进行回表操作
- query phase:第一步就是这个,先将全部的数据返回给协调者节点,再协调者节点中进行过滤、排序等操作
- fetch phase:第二步就是根据第一步所确定的结果,通过数据的id再进行一次查询工作将数据返回
3.3,数据读写优化
上面了解了读写的底层原理,在知道原理之后,那么就可以根据原理进行优化操作。
读取数据优化
如在读取数据时,减少这种通配符查询、前缀查询等需要全文检索的查询;如不需要算分的字段可以使用精确查询;使用Filter Context,利用内部的缓存机制,减少不必要的算分;结合profile、explain分析查询慢的问题等
写入数据优化
在写入数据时,可以使用批量插入数据来增加系统的吞吐量,或者使用多线程的方式插入数据;
分片优化
除了在查询优化,也可以在分片上做优化,数据量不大的情况可以使用单分片,数据量大使用多分片时,需要防止分片过多带来的开销。对于这种时间序列的查询,可以强制的force merge,将不需要的文档删除,从而减少这种segment的数量。
除了上面的几中优化之外,还可以对服务端硬件设备等进行优化,还可以调节这个refresh的频率进行优化、调整translog写入磁盘的频率进行调整等。如下面的这个模板,设置refresh刷新时间,translog刷盘等
DELETE myindex
PUT myindex
{"settings": {"index": {"refresh_interval": "30s", #30s一次refresh"number_of_shards": "2"},"routing": {"allocation": {"total_shards_per_node": "3" #控制分片,避免数据热点}},"translog": {"sync_interval": "30s","durability": "async" #降低translog落盘频率},"number_of_replicas": 0},"mappings": {"dynamic": false, #避免不必要的字段索引,必要时可以通过update by query
索引必要的字段"properties": {}}
}
相关文章:
【ElasticSearch系列-07】ES的开发场景和索引分片的设置及优化
ElasticSearch系列整体栏目 内容链接地址【一】ElasticSearch下载和安装https://zhenghuisheng.blog.csdn.net/article/details/129260827【二】ElasticSearch概念和基本操作https://blog.csdn.net/zhenghuishengq/article/details/134121631【三】ElasticSearch的高级查询Quer…...

JavaWeb Day09 Mybatis-基础操作02-XML映射文件动态SQL
目录 Mybatis动态SQL介绍编辑 一、案例 ①Mapper层 ②测试类 ③EmpMapper.xml ④结果 二、标签 (一)if where标签 ①EmpMapper.xml ②案例 ③总结 (二)foreach标签 ①SQL语句 ②Mapper层 ③EmpMapper.xml ④…...

CV学习基础
脸部检测是基于图像的明暗变化模式进行判断,需要将图像先进行灰度化处理 马赛克处理需先将图像缩小然后夸大回原尺寸。 保存训练好的算法用joblib 进行以下操作时已经使用cv2.cvtColor()完成了灰度化 图像平滑化(模糊处理):cv…...

设计模式之禅之设计模式-原型模式
设计模式之禅之设计模式-原型模式 一:原型模式的定义 用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。 原型模式(Prototype Pattern)的简单程度仅次于单例模式和迭代器模式。正是由于简单,使用的场景才非常地多。 原型模式的核心是一…...
Spring的循环依赖问题
文章目录 1.什么是循环依赖2.代码演示3.分析问题4.问题解决5.Spring循环依赖6. 疑问点6.1 为什么需要三级缓存6.2 没有三级缓存能解决吗?6.3 三级缓存分别什么作用 1.什么是循环依赖 上图是循环依赖的三种情况,虽然方式有点不一样,但是循环依…...

RT-DETR算法改进:更换损失函数DIoU损失函数,提升RT-DETR检测精度
💡本篇内容:RT-DETR算法改进:更换损失函数DIoU损失函数 💡本博客 改进源代码改进 适用于 RT-DETR目标检测算法(ultralytics项目版本) 按步骤操作运行改进后的代码即可🚀🚀🚀 💡改进 RT-DETR 目标检测算法专属 文章目录 一、DIoU理论部分 + 最新 RT-DETR算法…...

【ICE】2:基于webrtc的 ice session设计及实现
工厂函数:CreateICESession_t 外部声明,sdk内部实现。创建IICESession :外部可见,内部也可见 /// Factory function prototype. How you get this factory will depend on how you are linking with /// this code. typedef IICESession *( *CreateICESession_t )( const…...

Vue组件传
跟禹神学vue--总结 1 父组件给子组件传递参数--props传参 (1)父组件中准备好数据 data() {return {todos:[{id:001,title:01,done:true},{id:002,title:02,done:false},{id:003,title:03,done:true}]} } (2)父组件中引入子组件…...
)
轻量封装WebGPU渲染系统示例<25>- 颜色附件数据更新替换(源码)
当前示例源码github地址: https://github.com/vilyLei/voxwebgpu/blob/feature/rendering/src/voxgpu/sample/ColorAttachmentReplace.ts 此示例基于此渲染系统实现,当前示例TypeScript源码如下: const rttTex0 { diffuse: { uuid: rtt0, rttTexture: {} } }; c…...

c语言练习第11周(1~5)
数列 1 1 2 3 5 8 13 21 ... 被称为斐波纳数列。 输入若干个正整数N,输出这个序列的前 N 项的和。 题干数列 1 1 2 3 5 8 13 21 ... 被称为斐波纳数列。 输入若干个正整数N,输出这个序列的前 N 项的和。输入样例3 5 4 1输出样例…...

阿里云国际站服务器如何升级内存容量?
阿里云服务器是阿里云供给的计算服务,它具有高效安稳、可扩展性强等特色,适用于各种应用环境。在运用阿里云服务器的过程中,或许会遇到内存容量缺乏的状况,这时候就需求晋级内存容量。那么,阿里云服务器怎么晋级内存容…...
神经网络(第二周)
一、简介 1.1 需求预测示例 1.1.1 逻辑回归算法 根据价格预测商品是否畅销。特征:T恤的价格;分类:销售量高1/销售量低0;使用逻辑回归算法进行分类,拟合效果如下图所示: 1.1.2 神经元和神经网络 将逻辑回…...
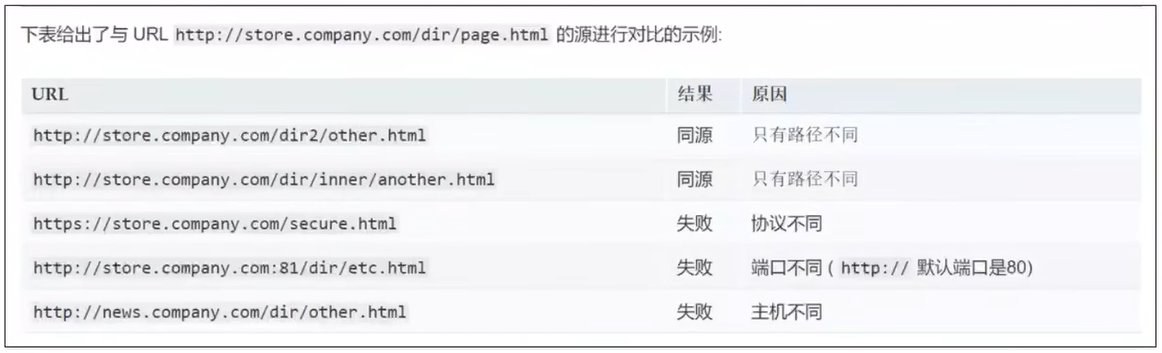
《网络协议》04. 应用层(DNS DHCP HTTP)
title: 《网络协议》04. 应用层(DNS & DHCP & HTTP) date: 2022-09-05 14:28:22 updated: 2023-11-12 06:55:52 categories: 学习记录:网络协议 excerpt: 应用层、DNS、DHCP、HTTP(URI & URL,ABNF…...

springboot自己添加的配置文件没有绿色叶子问题
在IntelliJ IDEA中,不同文件类型通常会有不同的图标,以便更容易识别它们。如果您的自己添加的 .properties 文件和项目中自动生成的 .properties 文件显示不同的图标,这可能是因为它们被识别为不同的文件类型。 通常情况下,Intel…...
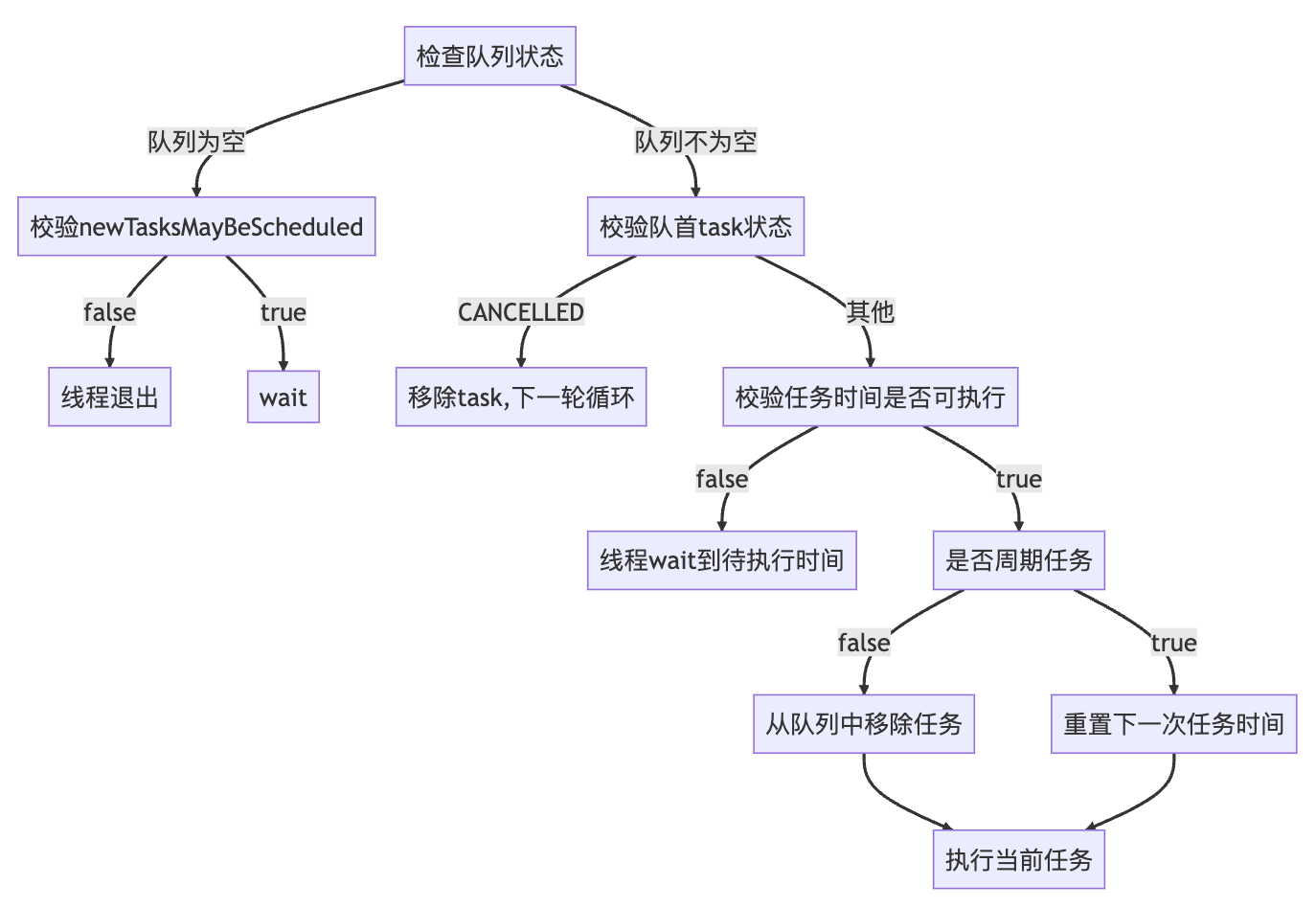
【Java】定时任务 - Timer/TimerTask 源码原理解析
一、背景及使用 日常实现各种服务端系统时,我们一定会有一些定时任务的需求。比如会议提前半小时自动提醒,异步任务定时/周期执行等。那么如何去实现这样的一个定时任务系统呢? Java JDK提供的Timer类就是一个很好的工具,通过简单…...

SAP ABAP基础语法-Excel上传(十)
EXCEL BDS模板上传及赋值 上传模板事务代码:OAER l 功能代码:向EXCEL模板中写入数据示例代码如下 REPORT ZEXCEL_DOI. “doi type pools TYPE-POOLS: soi. *SAP Desktop Office Integration Interfaces DATA: container TYPE REF TO cl_gui_custom_c…...
记录一次某某虚拟机的逆向
导语 学了一段时间的XPosed,发现XPosed真的好强,只要技术强,什么操作都能实现... 这次主要记录一下我对这款应用的逆向思路 apk检查 使用MT管理器检查apk的加壳情况 发现是某数字的免费版本 直接使用frida-dexdump 脱下来后备用 应用分…...
upload-labs关卡7(基于黑名单的空格绕过)通关思路
文章目录 前言一、回顾上一关知识点二、靶场第七关通关思路1、看源代码2、空格绕过3、检查文件是否成功上传 总结 前言 此文章只用于学习和反思巩固文件上传漏洞知识,禁止用于做非法攻击。注意靶场是可以练习的平台,不能随意去尚未授权的网站做渗透测试…...

CnosDB 在最近新发布的 2.4.0 版本中增加对时空函数的支持。
CnosDB 在最近新发布的 2.4.0 版本中增加对时空函数的支持。 概述 时空函数是一种用于描述时空结构和演化的函数。它在物理学、数学和计算机科学等领域中都有广泛的应用。时空函数可以描述物体在时空中的位置、速度、加速度以及其他相关属性。 用法 CnosDB 将使用一种全新的…...

python实现炒股自动化,个人账户无门槛量化交易的开始
本篇作为系列教程的引子,对股票量化程序化自动交易感兴趣的朋友可以关注我,现在只是个粗略计划,后续会根据需要重新调整,并陆续添加内容。 股票量化程序化自动交易接口 很多人在找股票个人账户实现程序化自动交易的接口࿰…...

AI 时代,计算机专业学生该怎么学?恫
整体排查思路 我们的目标是验证以下三个环节是否正常: 登录成功时:服务器是否正确生成了Session并返回了包含正确 JSESSIONID的Cookie给浏览器。 浏览器端:浏览器是否成功接收并存储了该Cookie。 后续请求:浏览器在执行查询等操作…...

量子力学语言:狄拉克符号法进阶全集
量子力学语言:狄拉克符号法进阶全集 这是一篇面向“已经见过狄拉克符号,但还没有彻底吃透它”的完整长文。目标不是只会抄写公式,而是真正理解:狄拉克符号到底是什么、为什么它能统一波函数和矩阵、它怎样承载测量、表象变换、多体系统与密度矩阵。 导读 很多人第一次接触…...

揭秘.NET 9全新AI Runtime:如何绕过JIT瓶颈,让ONNX模型推理延迟直降41%?
第一章:.NET 9全新AI Runtime的架构演进与设计哲学.NET 9 引入了原生 AI Runtime,标志着运行时从通用计算平台向智能工作负载优先平台的关键跃迁。其核心并非简单叠加模型推理能力,而是重构执行模型——将提示工程、token 编排、异步流式推理…...

实时手机检测-通用GPU算力优化:TensorRT加速后吞吐量提升3.2倍
实时手机检测-通用GPU算力优化:TensorRT加速后吞吐量提升3.2倍 1. 引言:当手机检测遇上性能瓶颈 想象一下,在一个大型活动现场,安保系统需要实时分析数百路监控视频,精准识别出每一部正在使用的手机,以防…...

OpenClaw多通道接入:Qwen3-4B同时服务飞书与钉钉机器人
OpenClaw多通道接入:Qwen3-4B同时服务飞书与钉钉机器人 1. 为什么需要多通道接入? 上周我遇到一个尴尬场景:团队部分成员用飞书沟通,另一些用钉钉。当我尝试用OpenClaw搭建自动化助手时,发现默认配置只能对接单一平台…...

Python拉取视频流的性能优化实战
一、背景与挑战在安防监控、直播推流、视频分析等场景中,我们经常需要使用Python拉取网络视频流(RTSP、HLS、HTTP-FLV等)。然而Python并非以高性能著称,面对高码率、多路视频流时,容易遇到:延迟累积&#x…...

MySQL 主从延迟根因诊断法
📌 解决思路:从网络、IO、SQL 到参数,系统化定位高并发下的同步瓶颈 📌 适用版本:MySQL 5.7 / 8.0 📌 适用场景:高并发写入、主从延迟告警、从库追不上主库 目录 一、先量化延迟:别…...

面试官问我‘龟兔赛跑’怎么找链表环起点,我用Floyd算法5分钟讲清楚了
面试官问我‘龟兔赛跑’怎么找链表环起点,我用Floyd算法5分钟讲清楚了 "链表环检测"是技术面试中的高频考点,而真正能让面试官眼前一亮的,往往不是背诵代码的能力,而是对算法原理的透彻理解。最近一次大厂面试中&#x…...

嵌入式系统软件抗干扰技术实战解析
1. 嵌入式系统抗干扰技术概述在工业控制、智能家居和物联网设备等嵌入式应用场景中,电磁干扰、电源波动等环境因素常常导致系统运行异常。作为一名有十年嵌入式开发经验的工程师,我处理过数十起由干扰引起的系统故障案例。硬件抗干扰措施如屏蔽、滤波固然…...

飞跨电容三电平拓扑的实战解析:从数学原理到SiC MOSFET的高频设计
1. 飞跨电容三电平拓扑的数学起源 飞跨电容三电平(FCML)拓扑的命名并非随意,它实际上植根于18世纪的数学拓扑学。数学拓扑学研究的是几何图形在连续变形下保持不变的性质,这个概念最早由欧拉在1736年研究柯尼斯堡七桥问题时提出。…...