【入门Flink】- 10基于时间的双流联合(join)
统计固定时间内两条流数据的匹配情况,需要自定义来实现——可以用窗口(window)来表示。为了更方便地实现基于时间的合流操作,Flink 的 DataStrema API 提供了内置的 join 算子。
窗口联结(Window Join)
一段时间的双流合并
定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理。
stream1.join(stream2).where(<KeySelector>) // stream1 的 keyBy.equalTo(<KeySelector>) // stream2 的 keyBy.window(<WindowAssigner>).apply(<JoinFunction>)
public class WindowJoinDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<Tuple2<String, Integer>> ds1 = env.fromElements(Tuple2.of("a", 1),Tuple2.of("a", 2),Tuple2.of("b", 3),Tuple2.of("c", 4)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String,Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> ds2 = env.fromElements(Tuple3.of("a", 1, 1),Tuple3.of("a", 11, 1),Tuple3.of("b", 2, 1),Tuple3.of("b", 12, 1),Tuple3.of("c", 14, 1),Tuple3.of("d", 15, 1)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String,Integer, Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));DataStream<String> join = ds1.join(ds2).where(r1 -> r1.f0) // ds1 的keyby.equalTo(r2 -> r2.f0) // ds2 的keyby.window(TumblingEventTimeWindows.of(Time.seconds(10))).apply(new JoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {/*** 关联上的数据,调用 join 方法* @param first ds1 的数据* @param second ds2 的数据*/@Overridepublic String join(Tuple2<String, Integer> first, Tuple3<String, Integer, Integer> second) throws Exception {return first + "<----->" + second;}});join.print();env.execute();}
}
输出:
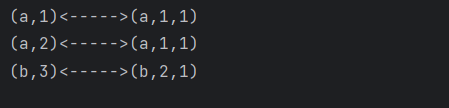
window join:
- 两条流落在同一个时间窗口范围内才能匹配
- 根据 keyBy 的 key,来进行匹配关联
- 只能拿到匹配上的数据,类似有固定时间范围的
inner join
间隔联结(Interval Join)
存在如下场景:两条流匹配的两个数据有可能刚好“卡在”窗口边缘两侧,窗口内就都没有匹配了,可以使用“间隔联结”(interval join)来解决。
原理
给定两个时间点,分别叫作间隔的“上界”(upperBound)和“下界”(lowerBound);可以开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp +upperBound], 即以 a 的时间戳为中心,下至下界点、上至上界点的一个闭区间:这段时间作为可以匹配另一条流数据的“窗口”范围。
匹配的条件为:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
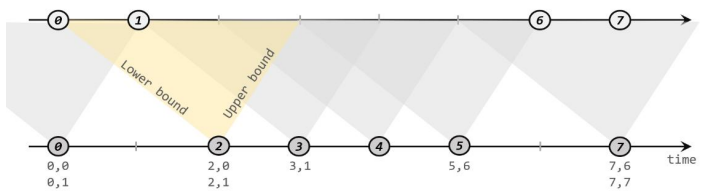
stream1
.keyBy(<KeySelector>)// KeyedStream 调用
.intervalJoin(stream2.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1)).process (new ProcessJoinFunction<Integer, Integer, String(){@Overridepublic void processElement(Integer left, Integer right,Context ctx, Collector<String> out){out.collect(left + "," + right);}
});
处理迟到数据,可以使用左右侧输出流
完整代码:
public class IntervalJoinWithLateDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<Tuple2<String, Integer>> ds1 = env.socketTextStream("hadoop102", 7777).map((MapFunction<String, Tuple2<String, Integer>>) value -> {String[] datas = value.split(",");return Tuple2.of(datas[0], Integer.valueOf(datas[1]));}).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String,Integer>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((value, ts) -> value.f1 * 1000L));SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> ds2 = env.socketTextStream("hadoop102", 8888).map((MapFunction<String, Tuple3<String, Integer, Integer>>) value -> {String[] datas = value.split(",");return Tuple3.of(datas[0], Integer.valueOf(datas[1]), Integer.valueOf(datas[2]));}).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Integer>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((value, ts) -> value.f1 * 1000L));/*** 【Interval join】* 1、只支持事件时间* 2、指定上界、下界的偏移,负号代表时间往前,正号代表时间往后* 3、process 中,只能处理 join 上的数据* 4、两条流关联后的 watermark,以两条流中最小的为准* 5、如果 当前数据的事件时间 < 当前的 watermark,就是迟到数据,主流的 process 不处理* => between 后,可以指定将 左流 或 右流的迟到数据放入侧输出流* *///1. 分别做 keyby,key 其实就是关联条件KeyedStream<Tuple2<String, Integer>, String> ks1 = ds1.keyBy(r1 -> r1.f0);KeyedStream<Tuple3<String, Integer, Integer>, String> ks2 = ds2.keyBy(r2 -> r2.f0);//2. 调用 interval join// 左右测输出流迟到标签OutputTag<Tuple2<String, Integer>> ks1LateTag = new OutputTag<>("ks1-late", Types.TUPLE(Types.STRING, Types.INT));OutputTag<Tuple3<String, Integer, Integer>> ks2LateTag = new OutputTag<>("ks2-late", Types.TUPLE(Types.STRING, Types.INT, Types.INT));SingleOutputStreamOperator<String> process = ks1.intervalJoin(ks2).between(Time.seconds(-2), Time.seconds(2)) // 指定上下界.sideOutputLeftLateData(ks1LateTag) // 将ks1的迟到数据,放入侧输出流.sideOutputRightLateData(ks2LateTag) // 将ks2的迟到数据,放入侧输出流.process(new ProcessJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {/*** 两条流的数据匹配上,才会调用这个方法* @param left ks1 的数据* @param right ks2 的数据* @param ctx 上下文* @param out 采集器*/@Overridepublic void processElement(Tuple2<String, Integer> left, Tuple3<String, Integer, Integer> right, Context ctx, Collector<String> out) throws Exception {// 进入这个方法,是关联上的数据out.collect(left + "<------>" + right);}});process.print("主流");process.getSideOutput(ks1LateTag).printToErr("ks1迟到数据");process.getSideOutput(ks2LateTag).printToErr("ks2迟到数据");env.execute();}
}
相关文章:
【入门Flink】- 10基于时间的双流联合(join)
统计固定时间内两条流数据的匹配情况,需要自定义来实现——可以用窗口(window)来表示。为了更方便地实现基于时间的合流操作,Flink 的 DataStrema API 提供了内置的 join 算子。 窗口联结(Window Join) 一…...

【Python Opencv】图片与视频的操作
文章目录 前言一、opencv图片1.1 读取图像1.2 显示图像1.3 写入图像1.4 示例代码 二、Opencv视频2.1 从相机捕获视频获取摄像头一帧一帧读取显示图片VideoCapture 中的get和set函数示例代码 2.2 从文件播放视频示例代码 2.3 保存视频示例代码 总结 前言 在计算机视觉和图像处理…...
【从入门到起飞】JavaAPI—System,Runtime,Object,Objects类
🎊专栏【JavaSE】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【如愿】 🎄欢迎并且感谢大家指出小吉的问题🥰 文章目录 🍔System类⭐exit()⭐currentTimeMillis()🎄用…...
【Git】的分支和标签的讲解及实际应用场景
目录 讲解 环境讲述 分支标签的区别 分支 命令 场景应用 标签 命令 标签规范 讲解 环境讲述 当软件从开发到正式环境部署的过程中,不同环境的作用 开发环境:用于开发人员进行软件开发、测试和调试。在这个环境中,开发人员可以快速地…...
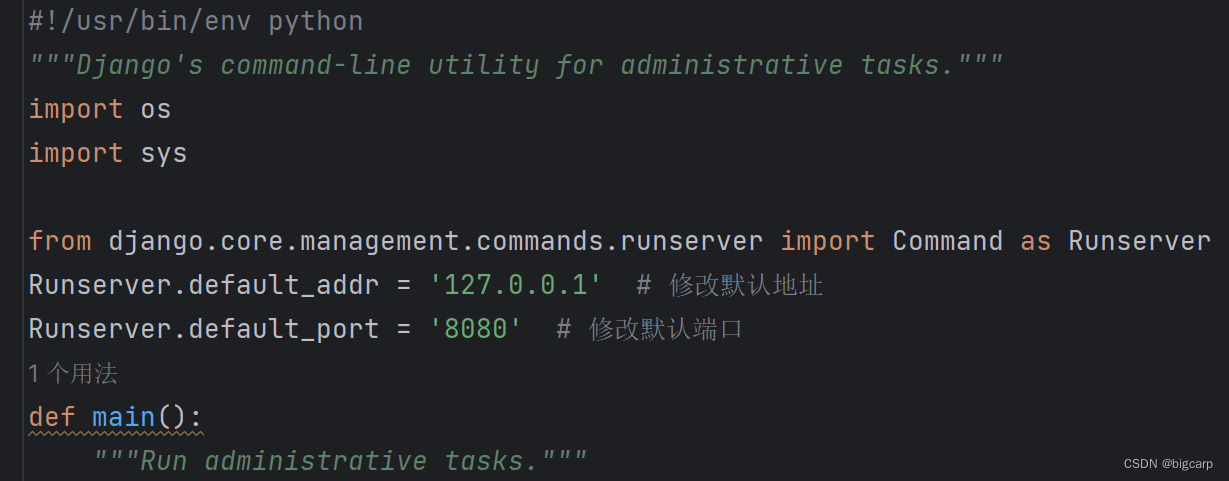
修改django开发环境runserver命令默认的端口
runserver默认8000端口 虽然python manage.py runserver 8080 可以指定端口,但不想每次runserver都添加8080这个参数 可以通过修改manage.py进行修改,只需要加三行: from django.core.management.commands.runserver import Command as Ru…...

kubeadm安装k8s高可用集群
目录 一、环境规划 二、注意事项: 三、环境准备: 1. 关闭防火墙规则,关闭selinux,关闭swap交换: 2. 修改主机名 3. 所有节点修改hosts文件: 4. 所有节点时间同步: 5. 所有节点实现Linux的资…...

来看看电脑上有哪些不为人知的小众软件?
电脑上的各类软件有很多,除了那些常见的大众化软件,还有很多不为人知的小众软件,专注于实用功能,简洁干净、功能强悍。 1.桌面停靠栏工具——BitDock BitDock是一款运行在Windows系统中的桌面停靠栏工具,功能实…...
一个进程最多可以创建多少个线程?
前言 话不多说,先来张脑图~ linux 虚拟内存知识回顾 虚拟内存空间长啥样 在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同位数的系统,地址空间的范围也不同。比如最常见的 32 位和 64 位系统&am…...
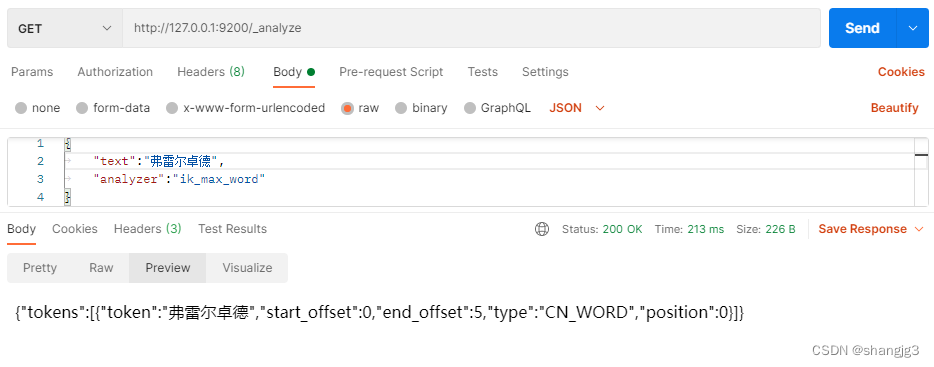
ElasticSearch文档分析
ElasticSearch文档分析 包含下面的过程: 将一块文本分成适合于倒排索引的独立的 词条将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall 分析器执行上面的工作。分析器实际上是将三个功能封装到了一个包里: 字符过滤器 首先&a…...
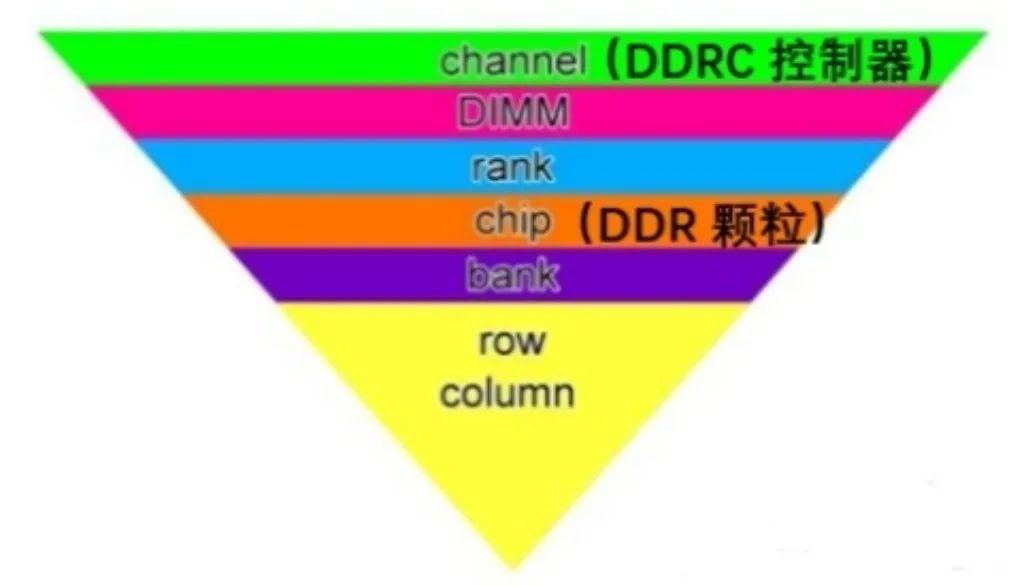
Xilinx FPGA平台DDR3设计详解(一):DDR SDRAM系统框架
DDR SDRAM(双倍速率同步动态随机存储器)是一种内存技术,它可以在时钟信号的上升沿和下降沿都传输数据,从而提高数据传输的速率。DDR SDRAM已经发展了多代,包括DDR、DDR2、DDR3、DDR4和DDR5,每一代都有不同的…...
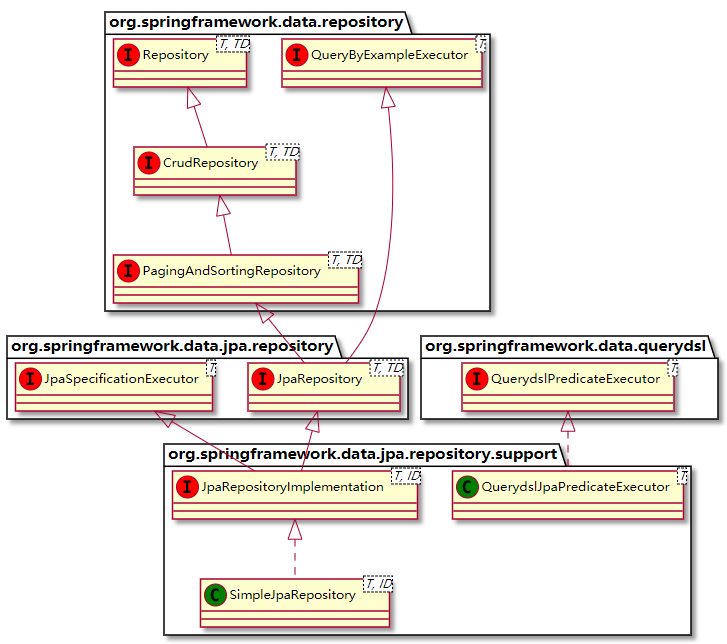
Spring Data JPA方法名命名规则
最近巩固一下JPA,网上看到这些资料,这里记录巩固一下。 一、Spring Data Jpa方法定义的规则 简单条件查询 简单条件查询:查询某一个实体类或者集合。 按照Spring Data的规范的规定,查询方法以find | read | get开头&…...

【Leetcode Sheet】Weekly Practice 15
Leetcode Test 2586 统计范围内的元音字符串数(11.7) 给你一个下标从 0 开始的字符串数组 words 和两个整数:left 和 right 。 如果字符串以元音字母开头并以元音字母结尾,那么该字符串就是一个 元音字符串 ,其中元音字母是 a、e、i、o、u…...

人力资源社会保障部办公厅关于推行专业技术人员职业资格电子证书的通知
(人社厅发〔2021〕97号) 各省、自治区、直辖市及新疆生产建设兵团人力资源社会保障厅(局),中共海南省委人才发展局,国务院有关部门、直属机构人事部门,有关协会、学会: 为贯彻落实…...
什么是光电耦合器?如何选择型号及种类
光电耦合器(英文缩写为OC)亦称光电隔离器,简称光耦;以光为媒介传输电信号;它对输入、输出电信号有良好的隔离作用,是目前种类最多、用途最广的光电器件之一;所以,它在各种电路中得到广泛的应用。 光耦合器…...
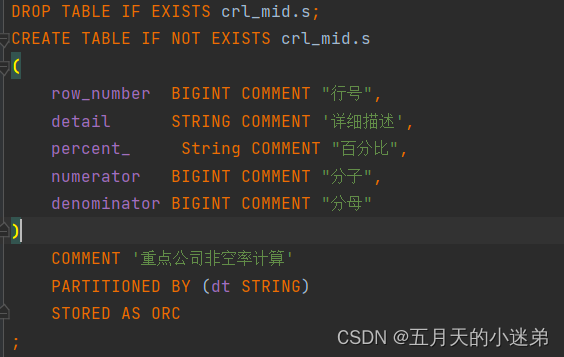
hive里因为列名用了关键字导致建表失败
代码 现象 ParseException line 6:4 cannot recognize input near percent String COMMENT in column name or primary key or foreign key 23/11/13 11:52:57 ERROR org.apache.hadoop.hive.ql.Driver: FAILED: ParseException line 6:4 cannot recognize input near percent …...

MySQL 报错 incorrect datetime value ‘0000-00-00 00:00:00‘ for column
使用navicat导入数据时报错: MySQL 报错 incorrect datetime value ‘0000-00-00 00:00:00’ for column 这是因为当前的MySQL不支持datetime为0的情况。 MySQL报incorrect datetime value ‘0000-00-00 00:00:00’ for column错误原因,是由于在MySQL5.7…...
升级操作)
Jira Data Center(非集群)升级操作
一、升级准备 Jira 管理界面执行升级检查下载升级包,使用原操作方式相同的方式安装。我这里原来的版本是通过./atlassian-jira-software-9.11.2-x64.bin安装的,接下来下载atlassian-jira-software-9.11.3-x64.bin的安装文件停止 Jira,bin/st…...
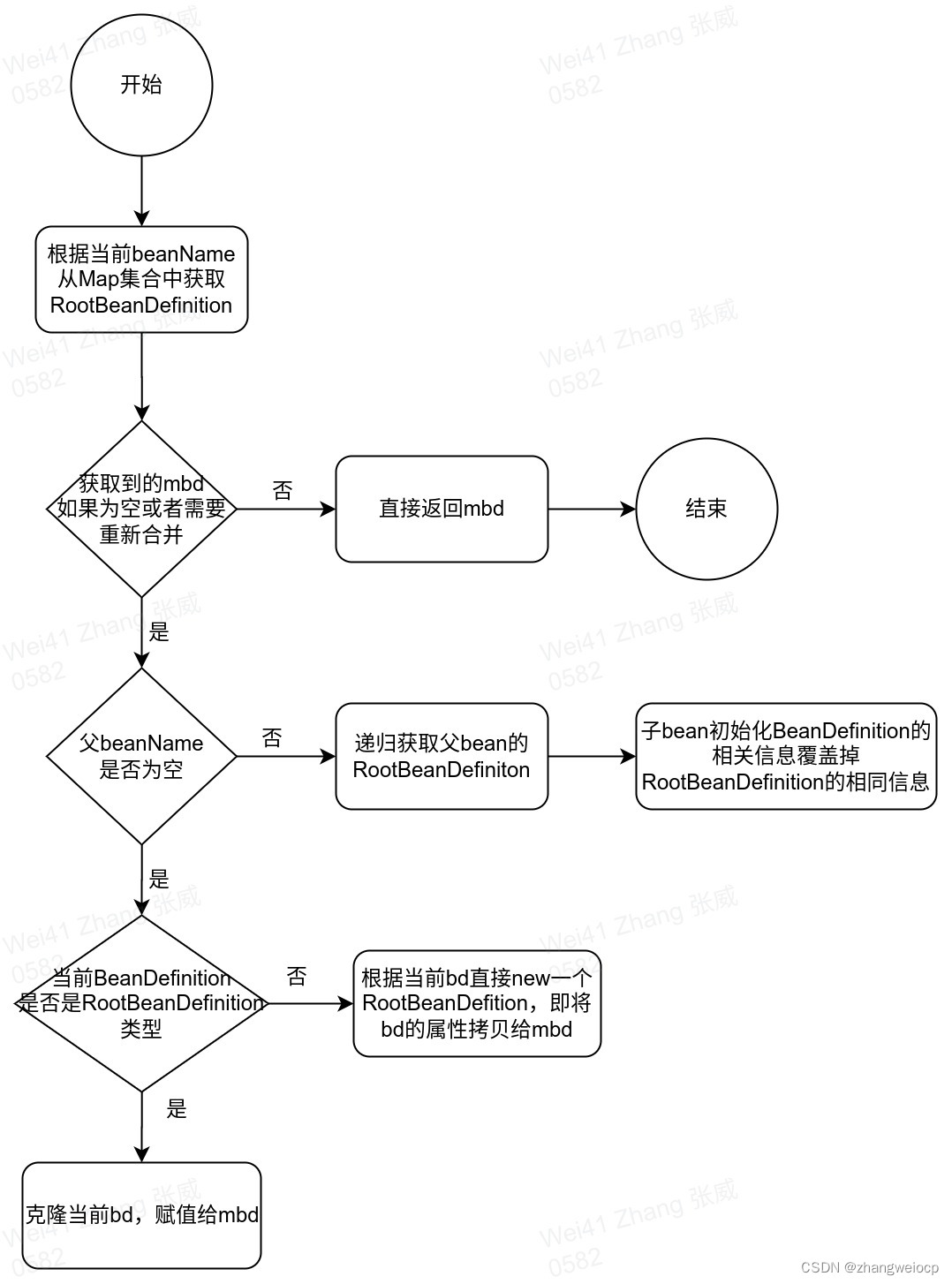
Spring IOC - BeanDefinition解析
1. BeanDefinition的属性 BeanDefinition作为接口定义了属性的get、set方法。这些属性基本定义在其直接实现类AbstractBeanDefinition中,各属性的含义如下表所示: 类型 名称 含义 常量 SCOPE_DEFAULT 默认作用域:单例模式 AUT…...
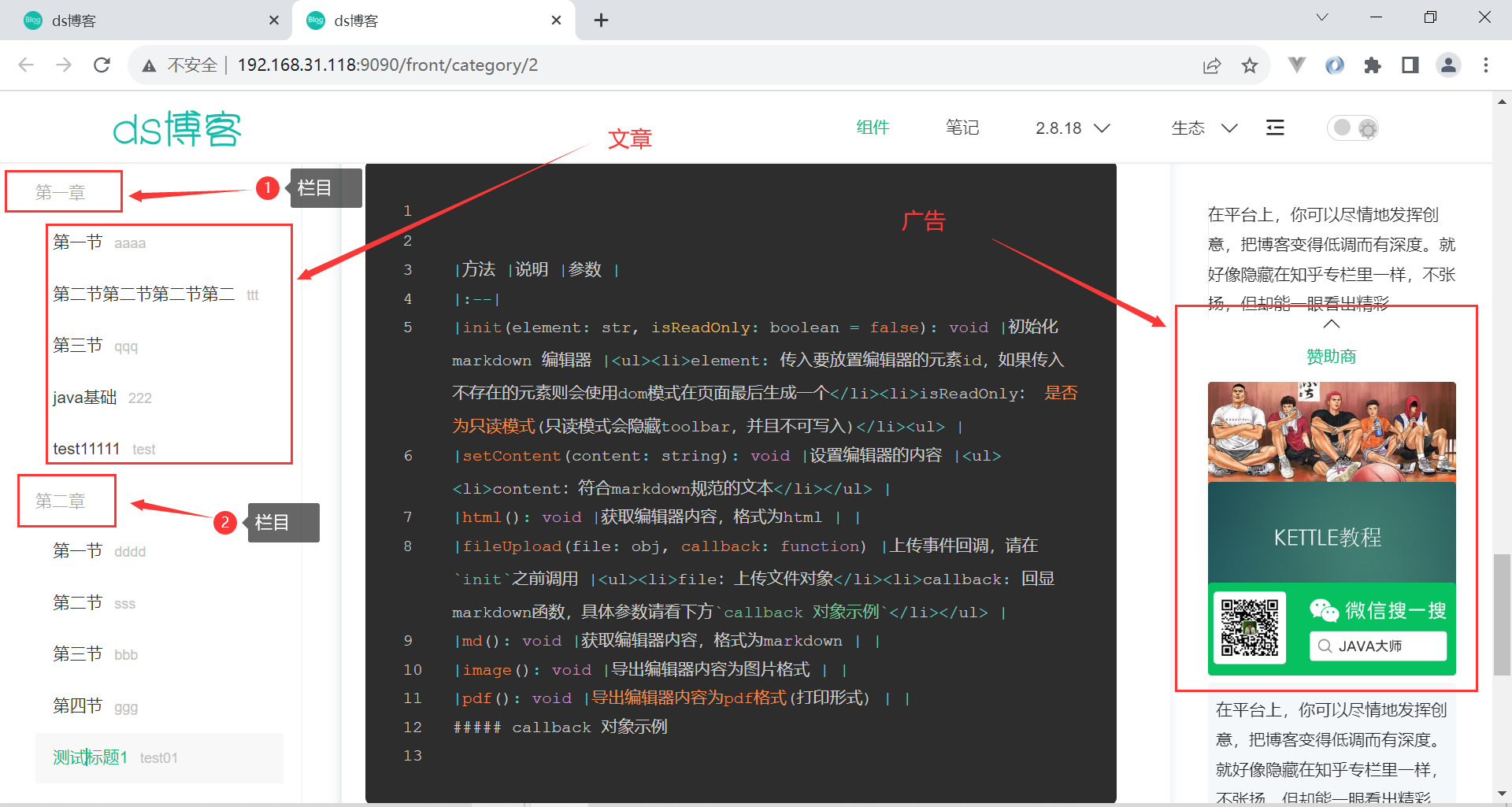
ds前后台博客系统
源码私信或者公众号java大师获取 博客简介:本博客采用Spring Boot LayUI做为基础,进行的博客系统开发,与bootvue相比,更为适合开发简单的系统,并且更容易上手,简单!高效!更易上手&a…...
)
算法leetcode|88. 合并两个有序数组(rust重拳出击)
文章目录 88. 合并两个有序数组:样例 1:样例 2:样例 3:提示: 分析:题解:rust:go:c:python:java: 88. 合并两个有序数组: …...
)
别再只盯着STA了!用SDF文件给你的芯片时序验证上个“双保险”(附VCS反标实操)
芯片时序验证的双重保障:SDF文件与STA的协同应用 在芯片设计领域,时序验证是确保电路功能正确性和性能达标的核心环节。许多工程师习惯于依赖静态时序分析(STA)作为唯一的验证手段,却忽视了动态时序仿真(SD…...

Janus-Pro-7B一键部署教程:3步搞定Ubuntu20.04环境配置
Janus-Pro-7B一键部署教程:3步搞定Ubuntu20.04环境配置 如果你是一个在Linux环境下折腾的开发者,看到Janus-Pro-7B这样的模型,第一反应肯定是“效果怎么样?”,第二反应多半是“部署起来麻烦吗?”。毕竟&am…...

手把手教你准备Kubernetes 1.29.4离线安装包:从containerd到etcd的完整下载清单
Kubernetes 1.29.4离线部署全攻略:构建企业级私有化容器平台的必备清单 在金融、军工、能源等对网络隔离要求严格的行业,或是边缘计算、生产车间等网络条件受限的场景中,离线部署Kubernetes集群成为刚需。但面对containerd、CNI插件、etcd等…...

为什么说“季中调拨”能力,决定了服装企业的生死时速?
在服装行业,有一句老话:“做得好是时装,做不好是库存。”过去,这句话更多指向季末的积压。但今天,随着消费节奏加快、流行周期被压缩到以“周”为单位,真正的决胜点已经前移——季中调拨。季中调拨…...

我的第一个mdp演示
我的第一个mdp演示 【免费下载链接】mdp A command-line based markdown presentation tool. 项目地址: https://gitcode.com/gh_mirrors/md/mdp 特性列表 轻量级命令行工具支持Markdown语法代码高亮显示 运行演示: bash mdp demo.md常用控制键: …...
赴宜参与第五届“330“三峡人才日活动 共探协同创新新路径)
港科资讯|香港科大内地办(北京)赴宜参与第五届“330“三峡人才日活动 共探协同创新新路径
2026年3 月29-30日,香港科大内地办(北京)袁冶主任一行受邀参加[第五届宜昌“330”三峡人才日]系列活动,深度对接宜昌人才生态、产业布局与创新资源,共探协同创新新路径。“330” 三峡人才日源自葛洲坝水利枢纽工程 “330 工程” 历史符号&…...

EagleEye DAMO-YOLO TinyNAS实战:基于YOLOv8的高效目标检测部署
EagleEye DAMO-YOLO TinyNAS实战:基于YOLOv8的高效目标检测部署 1. 引言 目标检测在实际应用中经常遇到一个难题:既要检测准确,又要运行速度快。传统的解决方案往往需要在精度和速度之间做出妥协,要么选择复杂的模型导致推理缓慢…...
CSAIL 副主任 Daniel Jackson 分享:解码软件工程底层范式)
重磅嘉宾|麻省理工学院(MIT)CSAIL 副主任 Daniel Jackson 分享:解码软件工程底层范式
当大模型把代码编写门槛拉到最低,软件工程的核心矛盾已从“写不出代码”转向“控不住设计”。AI能快速产出代码片段,却难以把控系统概念、模块边界与长期可靠性。如何让AI辅助开发既高效又可控?如何构建可解释、可组合、可验证的AI-native软件…...

MySQL查询核心语法详解
为了全面解析MySQL表记录查询,我们将从查询语法的核心构成、条件筛选、多表连接、子查询、性能优化等多个维度进行深入探讨,并结合具体案例和代码进行说明。 一、 查询语句(SELECT)基础语法与结构 SELECT语句是MySQL中用于从数据…...

DeerFlow GPU算力优化:vLLM加速Qwen3-4B推理性能调优
DeerFlow GPU算力优化:vLLM加速Qwen3-4B推理性能调优 1. 引言:当深度研究遇上推理瓶颈 想象一下,你正在使用一个强大的AI研究助手,它能帮你搜索资料、分析数据、撰写报告,甚至生成播客。但每次你提出一个稍微复杂点的…...