分布式数据库Schema 变更 in F1 TiDB
分布式数据库Schema 变更 in F1 & TiDB
【转载】TiDB 源码阅读系列文章(十七)DDL 源码解析 | PingCAP
上述文章主要叙述了从DDL语句发起到执行的过程,简单介绍了弄一套相同的模式来后台处理数据回填,从而提高DDL的并发度的一个方案。
Google F1
【转载】分布式 Schema 变更在 Google F1 的实践 - 知乎 (zhihu.com)
【转载】谷歌 F1 Online DDL的关键点:状态间兼容性 - 知乎 (zhihu.com)
TiDB
【转载】builddatabase/f1/schema-change-implement.md at master · ngaut/builddatabase (github.com)
新定义
- 元数据记录:system database 和 system table 记录异步变更schema的元数据。
- State:根据F1,引入中间状态,none | delete-only | write-only | write reorganization | public(和F1基本一样),删除操作的状态与它的顺序相反,write reorganization 改为 delete reorganization,虽然都是 reorganization 状态,但是由于可见级别是有很大区别的,所以将其分为两种状态标记。
- Lease
- Job:每个单独的 DDL 操作可看做一个 job,放到job queue,等此操作完成时,会将此 job 从 job queue 删除,并在存入 history job queue,便于查看历史 job。
- Worker:每个节点都有一个 worker 用来处理 job。
- **Owner:**整个系统只有一个节点的 worker 能当选 owner 角色,每个节点都可能当选这个角色,当选 owner 后 worker 才有处理 job 的权利。owner 这个角色是有任期的,owner 的信息会存储在 KV 层中。worker定期获取 KV 层中的 owner 信息,如果其中 ownerID 为空,或者当前的 owner 超过了任期,则 worker 可以尝试更新 KV 层中的 owner 信息(设置 ownerID 为自身的 workerID),如果更新成功,则该 worker 成为 owner。在租期内这个用来确保整个系统同一时间只有一个节点在处理 schema 变更。
- Background operations:用于 delete reorganization 的优化处理,引入了 background job, background job queue, background job history queue, background worker 和 background owner,它们的功能跟上面提到的角色功能一一对应。
变更流程
介绍 TiDB SQL 层中处理异步 schema 变更的流程
MySQL client 发起change;
- Load schema:是在每个节点(这个模块跟之前提到的 worker 一样,便于理解可以这样认为)启动时创建的一个 gorountine, 用于在到达每个租期时间后去加载 schema,如果某个节点加载失败 TiDB Server 将会自动挂掉。此处加载失败包括加载超时。
- start job:是在 TiDB SQL 层接收到请求后,给 job 分配 ID 并将之存入 KV 层,之后等待 job 处理完成后返回给上层,汇报处理结果。
- worker:每个节点起一个处理 job 的 goroutine,它会定期检查是否有待处理的 job。 它在得到本节点上 start job 模块通知后,也会直接去检查是否有待执行的 job 。
- owner:可以认为是一个角色,信息存储在 KV 层,其中包括记录当前当选此角色的节点信息。
- job queue:是一个存放 job 的队列,存储在 KV 层,逻辑上整个系统只有一个。
- job history queue:是一个存放已经处理完成的 job 的队列,存储在 KV 层,逻辑上整个系统只有一个。
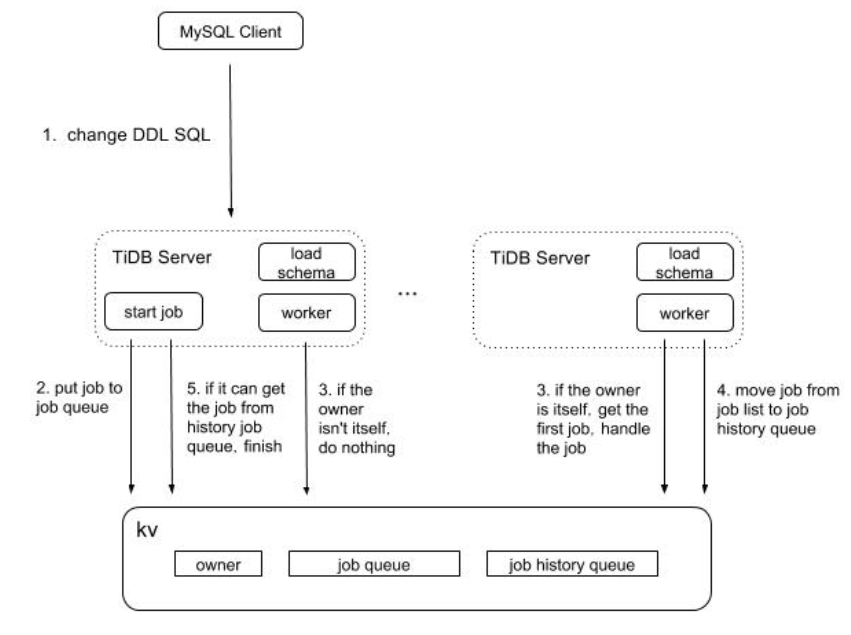
基本流程:
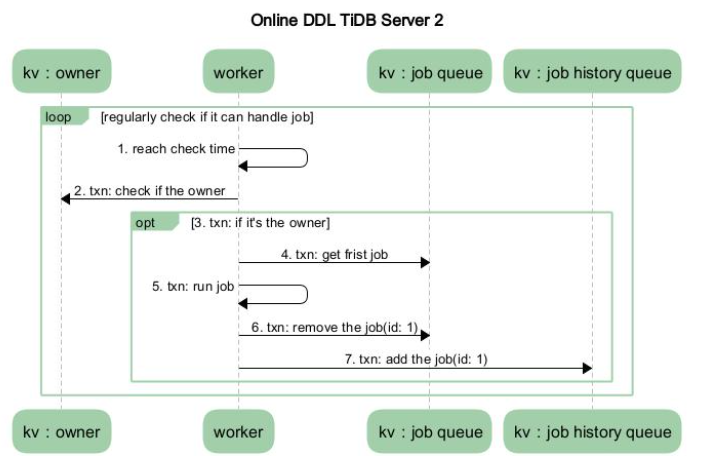
假设系统中只有两个节点,TiDB Server 1 和 TiDB Server 2。其中 TiDB Server 1 是 DDL 操作的接收节点, TiDB Server 2 是 owner。如下图 2 展示的是在 TiDB Server 1 中涉及的流程,图 3 展示的是在 TiDB Server 2 中涉及的流程。
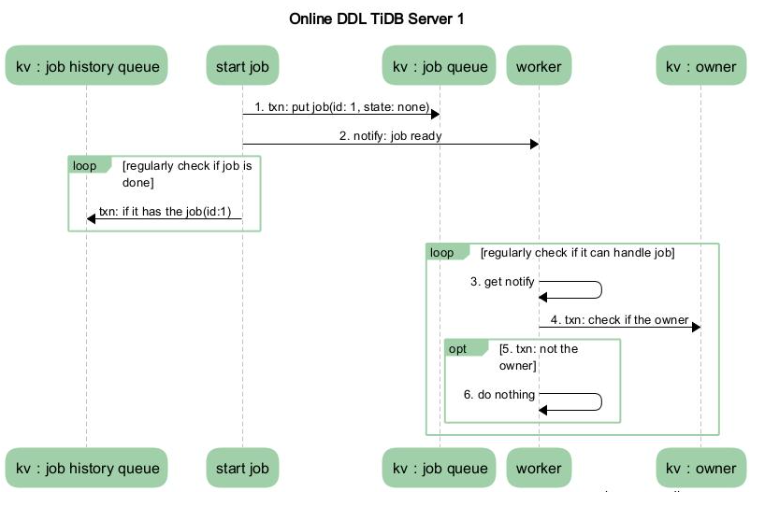
- MySQL Client 发送给 TiDB Server 一个更改 DDL 的 SQL 语句请求。
- 某个 TiDB Server 收到请求(MySQL Protocol 层收到请求进行解析优化),然后到达 TiDB SQL 层进行执行。这步骤主要是在 TiDB SQL 层接到请求后,会起个 start job 的模块根据请求将其封装成特定的 DDL job,然后将此 job 存储到 KV 层, 并通知自己的 worker 有 job 可以执行。
- 收到请求的 TiDB Server 的 worker 接收到处理 job 的通知后,判断自身是否处于 owner 的角色,如果处于 owner 角色则直接处理此 job,如果没有处于此角色则退出不做任何处理。图中我们假设没有处于此角色,那么其他的某个 TiDB Server 中肯定有一个处于此角色的,如果那个处于 owner 角色节点的 worker 通过定期检测机制来检查是否有 job 可以被执行时,发现了此 job,那么它就会处理这个 job。
- 当 worker 处理完 job 后, 它会将此 job 从 KV 层的 job queue 中移除,并放入 job history queue。
- 之前封装 job 的 start job 模块会定期去 job history queue 查看是否有之前放进去的 job 对应 ID 的 job,如果有则整个 DDL 操作结束。
- TiDB Server 将 response 返回 MySQL Client。
详细流程:以在 Table 中添加 column 为例详细介绍 worker 处理 job 的整个流程
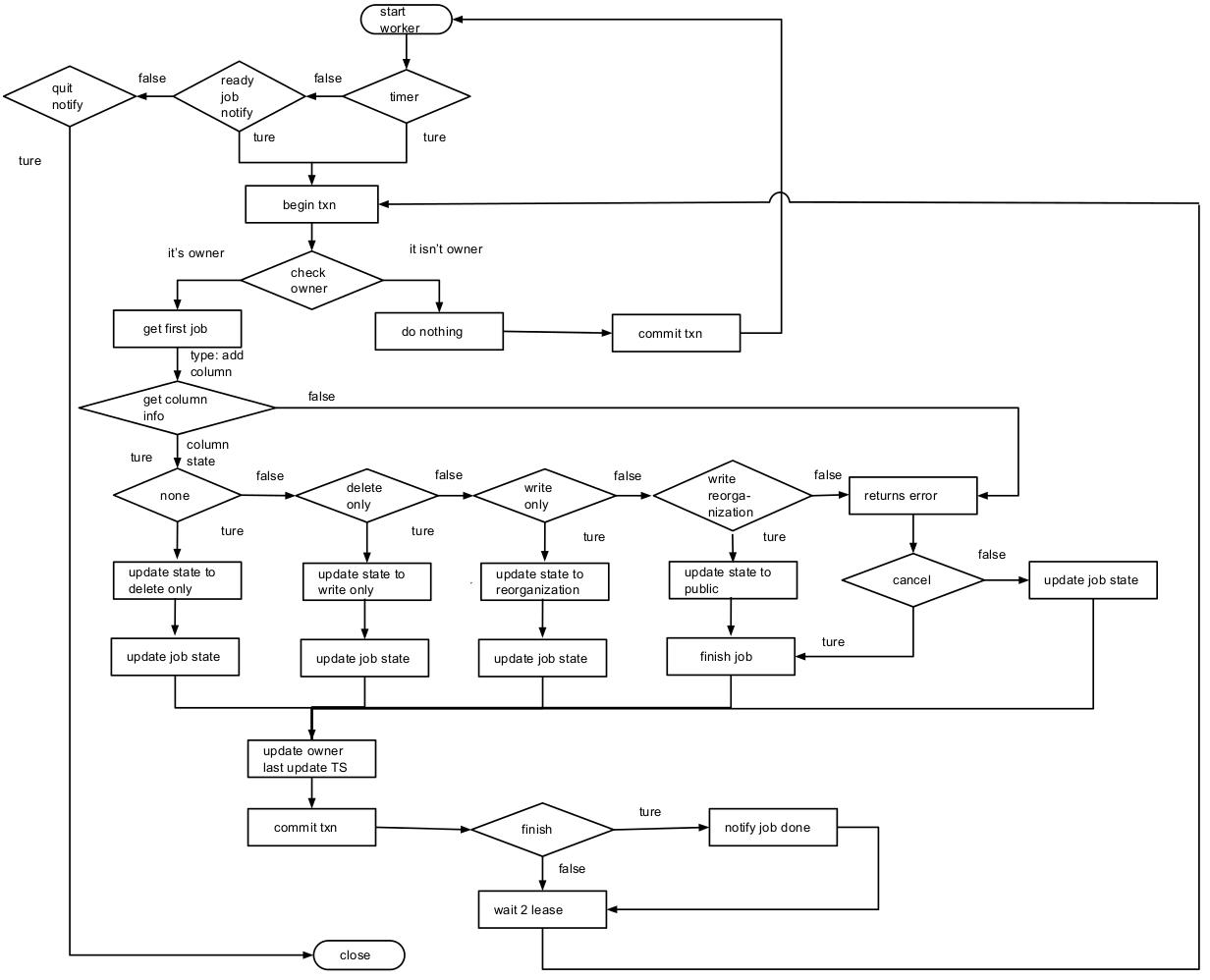
TiDB server1:
-
start job 给 start worker 传递了 job 已经准备完成的信号。
-
worker 开启一个事务,检查自己是否是 owner 角色,结果发现不是 owner 角色(此处跟先前的章节保持一致,假设此节点 worker 不是 owner 角色),则提交事务退出处理 job 的循环,回到 start worker 等待信号的循环。如果是owner,则是TiDB Server2的任务。
- start job 的定时检查触发后,会检查 job history queue 是否有之前自己放入 job queue 中的 job(通过 jobID)。如果有则此 DDL 操作在 TiDB SQL 完成,上抛到 MySQL Protocol 层,最后返回给 Client, 结束这个操作。
TiDB server2:
- start worker 中的定时器到达时间。
- 开启一个事务,检查发现本节点为 owner 角色。
- 从 KV 层获取队列中第一个 job(假设就是 TiDB Server 1 之前放入的 job),判断此 job 的类型并对它做相应的处理。
- 此处 job 的类型为 add column,然后流程到达图中 get column information 步骤。
- 取对应 table info(主要通过 job 中 schemaID 和 tableID 获取),然后确定添加的 column 在原先的表中不存在或者为不可见状态。
- 如果新添加的 column 在原先表中不存在,那么将新 column 信息关联到 table info。
- 在前面两个步骤中发生某些情况会将此 job 标记为 cancel 状态,并返回 error,到达图中 returns error 流程。比如发现对应的数据库、数据表的状态为不存在或者不可见(即它的状态不为 public),发现此 column 已存在并为可见状态等一些错误,这里就不全部列举了。
- schema 版本号加 1。
- 将 job 的 schema 状态和 table 中 column 状态标记为 delete only, 更新 table info 到 KV 层。
- 因为 job 状态没有 finish(即 done 或者 cancel 状态),所以直接将 job 在上一步更新的信息写入 KV 层。
- 在执行前面的操作时消耗了一定的时间,所以这里将更新 owner 的 last update timestamp 为当前时间(防止经常将 owner 角色在不同服务器中切换),并提交事务。
- 循环执行步骤 2、 3、 4.a、5、 6、 7 、8,不过将6中的状态由 delete only 改为 write only。
- 循环执行步骤 2、 3、 4.a、5、 6、 7 、8,不过将6中的状态由 write only 改为 write reorganization。
- 循环执行步骤 2、 3、 4.a、5,获取当前事务的快照版本,然后给新添加的列填写数据。通过应版本下需要得到的表的所有 handle(相当于 rowID),出于内存和性能的综合考量,此处处理为批量获取。然后针对每行新添加的列做数据填充,具体操作如下(下面的操作都会在一个事务中完成):
- 用先前取到的 handle 确定对应行存在,如果不存在则不对此行做任何操作。
- 如果存在,通过 handle 和 新添加的 columnID 拼成的 key 获取对应列。获取的值不为空则不对此行做任何操作。
- 如果值为空,则通过对应的新添加行的信息获取默认值,并存储到 KV 层。
- 将当前的 handle 信息存储到当前 job reorganization handle 字段,并存储到 KV 层。假如 12 这个步骤执行到一半,由于某些原因要重新执行 write reorganization 状态的操作,那么可以直接从这个 handle 开始操作。
- 将调整 table info 中 column 和 index column 中的位置,将 job 的 schema 和 table info 中新添加的 column 的状态设置为设置为public, 更新 table info 到 KV 层。最后将 job 的状态改为 done。
- 因为 job 状态已经 finish,将此 job 从 job queue 中移除并放入 job history queue 中。
- 执行步骤8,与之前的步骤一样 12, 13, 14 和 15 在一个事务中。
优化:
原本删除操作是:public → write only → delete only → delete reorganization → none,优化的处理是去掉 delete reorganization 状态,并把此状态需要处理的元数据的操作放到 delete only 状态时,把具体删除数据的操作放到后台处理,然后直接把状态标为 none。
好处:对删除数据库,删除数据表等减少一个状态,即 2 倍 lease 的等待时间。
实现:
在其处于 delete only 状态时,就会把元数据删除,而对起表中具体数据的删除则推迟到后台运行,然后结束 DDL job。
到后台运行的任务的流程跟之前处理任务的流程类似,详细过程如下:
- 在图 4 中判定 finish 操作为 true 后,判断如果是可以放在后台运行(暂时还只是删除数据库和表的任务),那么将其封装成 background job 放入 background job queue, 并通知本机后台的 worker 将其处理。
- 后台 job 也有对应的 owner,假设本机的 backgroundworker 就是 background owner 角色,那么他将从 background job queue 中取出第一个 background job, 然后执行对应类型的操作(删除表中具体的数据)。 如果执行完成,那么从 background job queue 中将此 job 删除,并放入 background job history queue 中。 注意步骤2和步骤 3需要在一个事务中执行。
相关文章:
分布式数据库Schema 变更 in F1 TiDB
分布式数据库Schema 变更 in F1 & TiDB 【转载】TiDB 源码阅读系列文章(十七)DDL 源码解析 | PingCAP 上述文章主要叙述了从DDL语句发起到执行的过程,简单介绍了弄一套相同的模式来后台处理数据回填,从而提高DDL的并发度的一…...

图形库篇 | EasyX | 图像处理
图形库篇 | EasyX | 图像处理 图像类型 IMAGE表示图像,用于定义一个图像变量,与导入的图片资源一一对应。 IMAGE img;加载与绘制图像 函数功能函数加载图像void loadimage(IMAGE* pDstImg,LPCTSTR pImgFile,int nwidth = 0,int nHeight = 0,bool bResize = false)绘制图像v…...

AWTK UI 自动化测试工具发布
AWTK UI 自动化 提供了兼容 Appium 的接口,可以使用 Appium 的工具来进行 UI 自动化测试。但是使用起来有点麻烦,用的人不多,所以最终决定开发一个 AWTK 专用的 UI 自动化测试工具。相比 Appium,这个工具有下列特点: …...
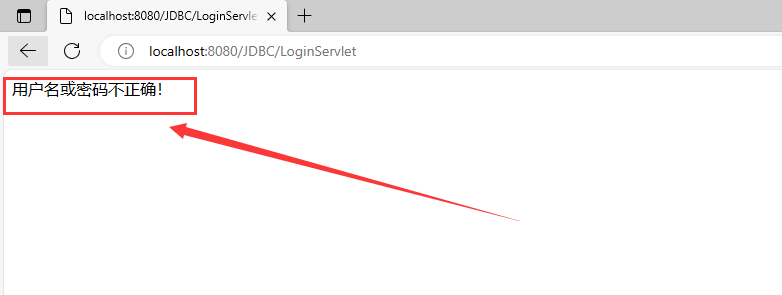
Java后端开发——JDBC入门实验
JDBC(Java Database Connectivity)是Java编程语言中用于与数据库建立连接并进行数据库操作的API(应用程序编程接口)。JDBC允许开发人员连接到数据库,执行各种操作(如插入、更新、删除和查询数据)…...

LCA
定义 最近公共祖先简称 LCA(Lowest Common Ancestor)。两个节点的最近公共祖先,就是这两个点的公共祖先里面,离根最远的那个。 性质 如果 不为 的祖先并且 不为 的祖先,那么 分别处于 的两棵不同子树中&#…...

ts学习02-数据类型
新建index.html <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title> </h…...

javaSE的发展历史以及openjdk和oracleJdk
1 JavaSE 的发展历史 1.1 Java 语言的介绍 SUN 公司在 1991 年成立了一个称为绿色计划(Green Project)的项目,由 James Gosling(高斯林)博士领导,绿色计划的目的是开发一种能够在各种消费性电子产品&…...
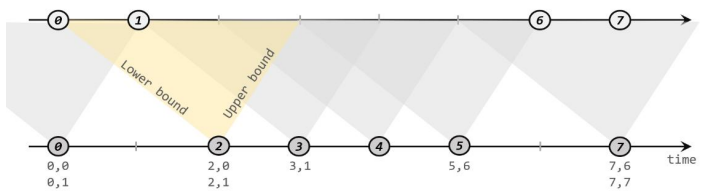
【入门Flink】- 10基于时间的双流联合(join)
统计固定时间内两条流数据的匹配情况,需要自定义来实现——可以用窗口(window)来表示。为了更方便地实现基于时间的合流操作,Flink 的 DataStrema API 提供了内置的 join 算子。 窗口联结(Window Join) 一…...

【Python Opencv】图片与视频的操作
文章目录 前言一、opencv图片1.1 读取图像1.2 显示图像1.3 写入图像1.4 示例代码 二、Opencv视频2.1 从相机捕获视频获取摄像头一帧一帧读取显示图片VideoCapture 中的get和set函数示例代码 2.2 从文件播放视频示例代码 2.3 保存视频示例代码 总结 前言 在计算机视觉和图像处理…...
【从入门到起飞】JavaAPI—System,Runtime,Object,Objects类
🎊专栏【JavaSE】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【如愿】 🎄欢迎并且感谢大家指出小吉的问题🥰 文章目录 🍔System类⭐exit()⭐currentTimeMillis()🎄用…...
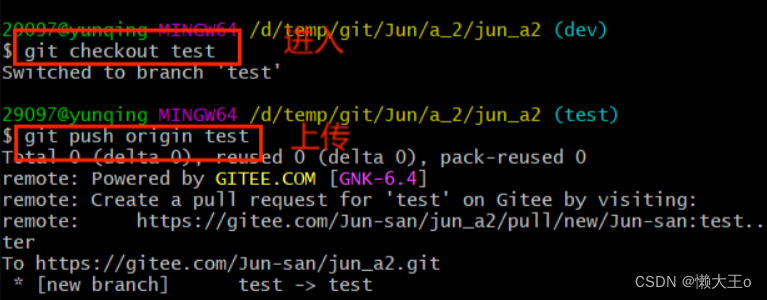
【Git】的分支和标签的讲解及实际应用场景
目录 讲解 环境讲述 分支标签的区别 分支 命令 场景应用 标签 命令 标签规范 讲解 环境讲述 当软件从开发到正式环境部署的过程中,不同环境的作用 开发环境:用于开发人员进行软件开发、测试和调试。在这个环境中,开发人员可以快速地…...
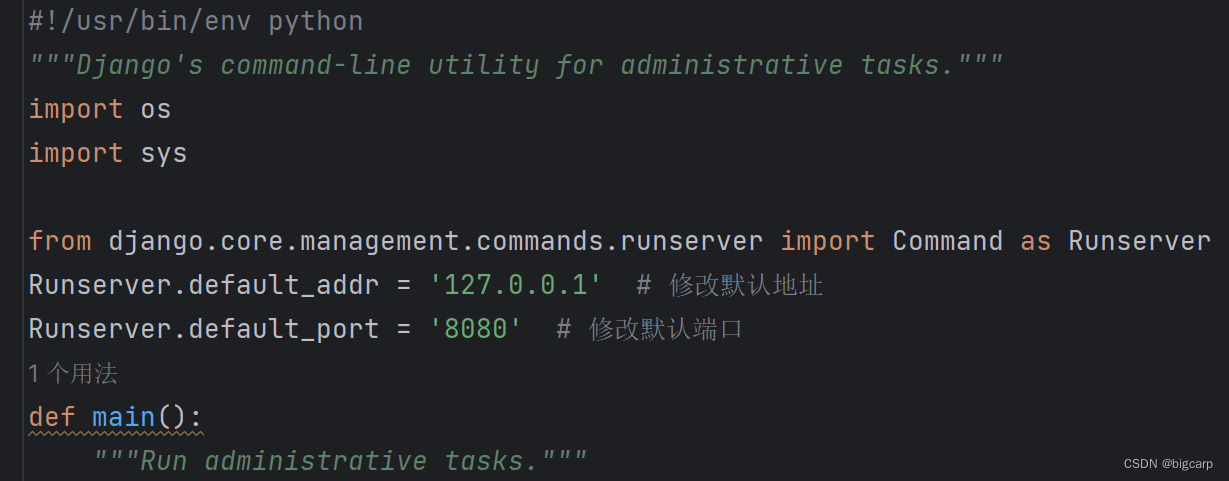
修改django开发环境runserver命令默认的端口
runserver默认8000端口 虽然python manage.py runserver 8080 可以指定端口,但不想每次runserver都添加8080这个参数 可以通过修改manage.py进行修改,只需要加三行: from django.core.management.commands.runserver import Command as Ru…...

kubeadm安装k8s高可用集群
目录 一、环境规划 二、注意事项: 三、环境准备: 1. 关闭防火墙规则,关闭selinux,关闭swap交换: 2. 修改主机名 3. 所有节点修改hosts文件: 4. 所有节点时间同步: 5. 所有节点实现Linux的资…...

来看看电脑上有哪些不为人知的小众软件?
电脑上的各类软件有很多,除了那些常见的大众化软件,还有很多不为人知的小众软件,专注于实用功能,简洁干净、功能强悍。 1.桌面停靠栏工具——BitDock BitDock是一款运行在Windows系统中的桌面停靠栏工具,功能实…...
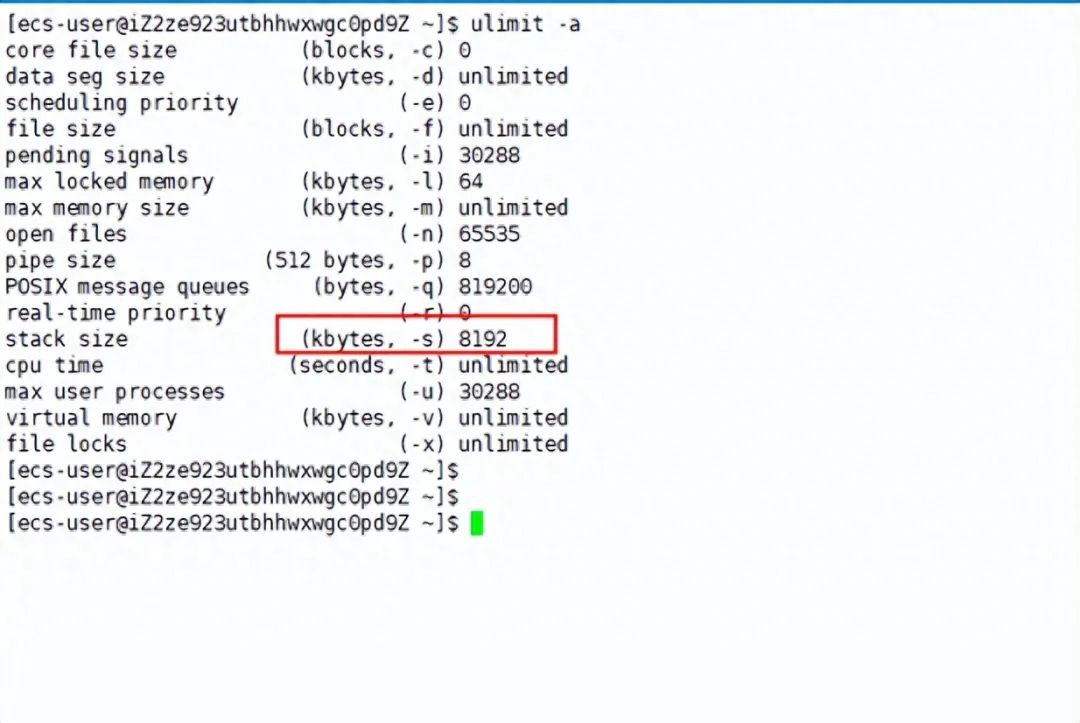
一个进程最多可以创建多少个线程?
前言 话不多说,先来张脑图~ linux 虚拟内存知识回顾 虚拟内存空间长啥样 在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同位数的系统,地址空间的范围也不同。比如最常见的 32 位和 64 位系统&am…...
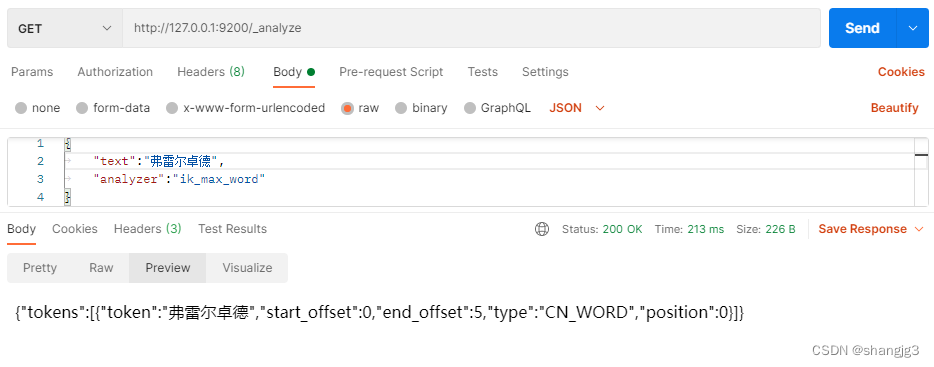
ElasticSearch文档分析
ElasticSearch文档分析 包含下面的过程: 将一块文本分成适合于倒排索引的独立的 词条将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall 分析器执行上面的工作。分析器实际上是将三个功能封装到了一个包里: 字符过滤器 首先&a…...
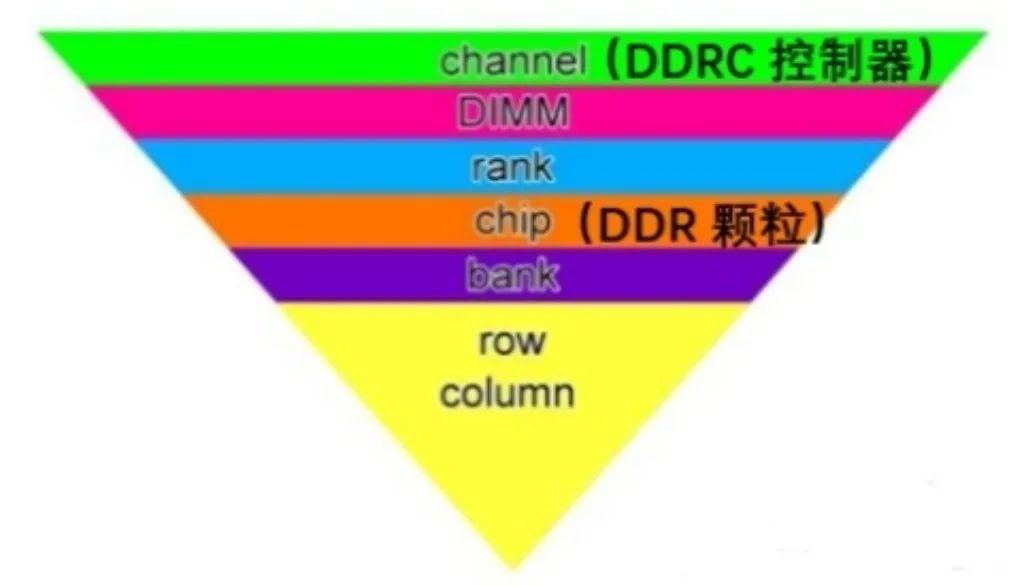
Xilinx FPGA平台DDR3设计详解(一):DDR SDRAM系统框架
DDR SDRAM(双倍速率同步动态随机存储器)是一种内存技术,它可以在时钟信号的上升沿和下降沿都传输数据,从而提高数据传输的速率。DDR SDRAM已经发展了多代,包括DDR、DDR2、DDR3、DDR4和DDR5,每一代都有不同的…...
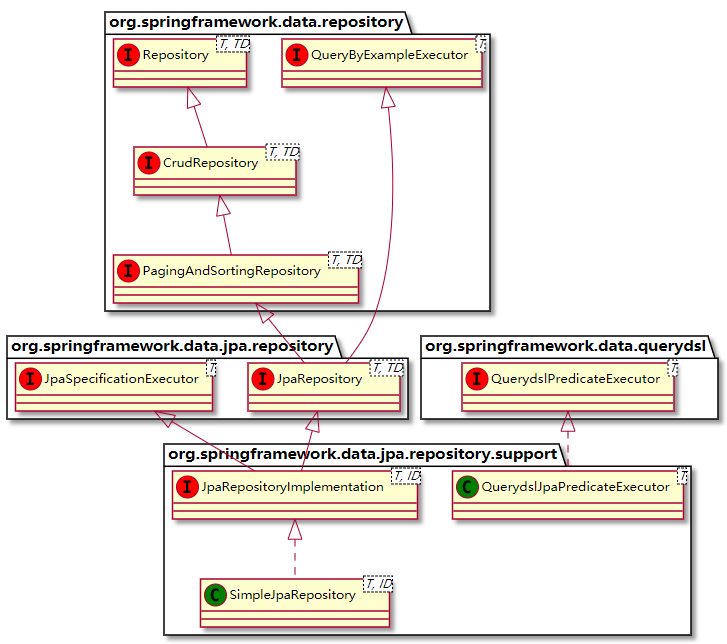
Spring Data JPA方法名命名规则
最近巩固一下JPA,网上看到这些资料,这里记录巩固一下。 一、Spring Data Jpa方法定义的规则 简单条件查询 简单条件查询:查询某一个实体类或者集合。 按照Spring Data的规范的规定,查询方法以find | read | get开头&…...

【Leetcode Sheet】Weekly Practice 15
Leetcode Test 2586 统计范围内的元音字符串数(11.7) 给你一个下标从 0 开始的字符串数组 words 和两个整数:left 和 right 。 如果字符串以元音字母开头并以元音字母结尾,那么该字符串就是一个 元音字符串 ,其中元音字母是 a、e、i、o、u…...

人力资源社会保障部办公厅关于推行专业技术人员职业资格电子证书的通知
(人社厅发〔2021〕97号) 各省、自治区、直辖市及新疆生产建设兵团人力资源社会保障厅(局),中共海南省委人才发展局,国务院有关部门、直属机构人事部门,有关协会、学会: 为贯彻落实…...
)
Java整合海康威视热成像SDK实战:从设备登录到实时测温数据获取的完整流程(附避坑指南)
Java整合海康威视热成像SDK实战:从设备登录到实时测温数据获取的完整流程(附避坑指南) 在工业检测、医疗诊断、安防监控等领域,热成像技术的应用越来越广泛。海康威视作为国内领先的安防设备供应商,其热成像设备凭借高…...
)
2001-2024年我国农作物分布栅格数据(小麦、玉米、水稻、甘蔗等)
1 数据介绍 中国农作物分布栅格数据集(2001-2024) 数据简介 本数据集由Yangyang Fu团队开发,提供2001-2024年中国28个省份30米分辨率的农作物分布栅格数据,涵盖单季稻、双季稻、冬小麦、玉米等主要作物类型及其轮作模式。 数…...
及应对策略)
PP-DocLayoutV3入门指南:5类典型失败图诊断(反光/模糊/歪斜/低对比)及应对策略
PP-DocLayoutV3入门指南:5类典型失败图诊断(反光/模糊/歪斜/低对比)及应对策略 1. 引言:当文档布局分析遇到“坏”图片 想象一下,你拿到一份重要的纸质合同,需要快速提取里面的关键信息。你掏出手机拍了张…...

Nanobot与Kubernetes集成:云原生部署方案
Nanobot与Kubernetes集成:云原生部署方案 1. 引言 在云原生时代,如何高效部署和管理AI应用成为开发者面临的重要挑战。Nanobot作为一个超轻量级的AI助手框架,以其仅4000行代码的精简设计和强大功能吸引了广泛关注。但当我们需要在生产环境中…...

GTE语义搜索在网络安全领域的应用:威胁情报分析系统
GTE语义搜索在网络安全领域的应用:威胁情报分析系统 1. 网络安全的新挑战与机遇 每天,安全分析师都要面对海量的威胁数据——从安全警报、漏洞报告到攻击日志,信息量庞大且分散。传统的关键词搜索就像是用渔网捞针,经常漏掉重要…...

Qwen3-0.6B-FP8在单片机开发中的启发:生成嵌入式C语言代码片段
Qwen3-0.6B-FP8在单片机开发中的启发:生成嵌入式C语言代码片段 1. 引言 如果你是一位单片机开发者,可能经常遇到这样的场景:面对一个新的外设模块,或者要实现一个不太熟悉的功能,第一反应就是去翻数据手册、找官方例…...

RMBG-2.0部署避坑指南:常见问题解决方案
RMBG-2.0部署避坑指南:常见问题解决方案 1. 引言 最近RMBG-2.0这个开源背景去除模型确实火得不行,效果确实惊艳,精确到发丝级别的抠图能力让很多开发者跃跃欲试。但在实际部署过程中,不少朋友都遇到了各种坑:环境配置…...

Anything V5进阶使用:结合REST API实现批量自动生成二次元图像
Anything V5进阶使用:结合REST API实现批量自动生成二次元图像 1. 项目概述 Anything V5是基于Stable Diffusion技术的高质量二次元图像生成模型,相比基础版本,它在动漫风格图像生成方面表现出色。本教程将重点介绍如何通过REST API实现批量…...

DAMOYOLO-S在Android移动端的应用探索:离线物体识别App原型开发
DAMOYOLO-S在Android移动端的应用探索:离线物体识别App原型开发 你有没有想过,让手机像人眼一样,不联网也能“看懂”周围的世界?比如,在户外没有信号的地方,手机摄像头一扫,就能立刻告诉你眼前…...

QW_Sensors嵌入式传感器驱动库详解
1. QW_Sensors 库概述QW_Sensors 是一个面向硬件开发者的轻量级嵌入式传感器驱动库,专为 QW Shield 硬件平台设计。该库并非通用型多平台抽象层,而是深度耦合于 QW Shield 的物理布局、供电逻辑、通信拓扑与固件约束,其核心价值在于将底层硬件…...