2023.11.13 hive数据仓库之分区表与分桶表操作,与复杂类型的运用
目录
0.hadoop hive的文档
1.一级分区表
2.一级分区表练习2
3.创建多级分区表
4.分区表操作
5.分桶表
6. 分桶表进行排序
7.分桶的原理
8.hive的复杂类型
9.array类型: 又叫数组类型,存储同类型的单数据的集合
10.struct类型: 又叫结构类型,可以存储不同类型单数据的集合
11.map类型: 又叫映射类型,存储键值对数据的映射(根据key找value)
0.hadoop hive的文档
hive文档: https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
hdfs文档: https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
yarn文档: https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
mr文档: https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
1.一级分区表
创建分区表: create [external] table [if not exists] 表名(字段名 字段类型 , 字段名 字段类型 , ... )partitioned by (分区字段名 分区字段类型)... ;
自动生成分区目录并插入数据: load data [local] inpath '文件路径' into table 分区表名 partition (分区字段名='值');
注意: 如果加local后面文件路径应该是linux本地路径,如果没有加那么就是hdfs文件路径
建表
create database hive3; use hive3; --练习1 创建一级分区表 -- 创建分区表: create [external] table [if not exists] -- 表名(字段名 字段类型 , 字段名 字段类型 , ... ) -- partitioned by (分区字段名 分区字段类型) ;-- 自动生成分区目录并插入数据: load data [local] inpath -- '文件路径' into table 分区表名 partition (分区字段名='值');--建表 create table if not exists score (name string,subject string,grade int) partitioned by (dt string) row format delimited fields terminated by '\t' ;
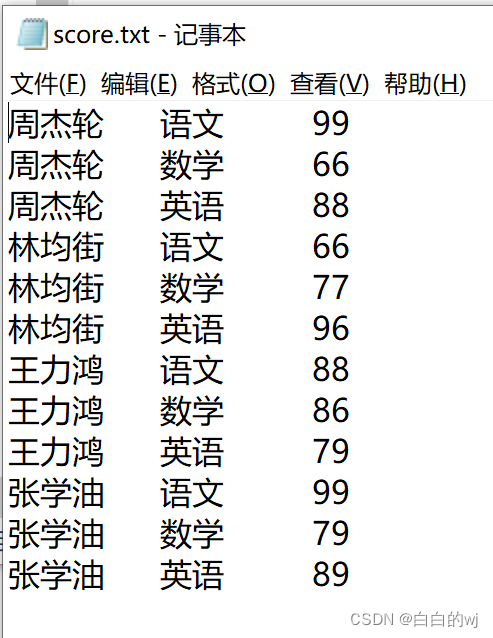
此为score.txt文件
--在hdfs的网页中手动上传score.txt到目录,下面每一次load data都会把这个文件移动 -- 加载数据 load data inpath '/score.txt' into table score partition (dt='2022'); load data inpath '/score.txt' into table score partition (dt='2023'); load data inpath '/score.txt' into table score partition (dt='2024');
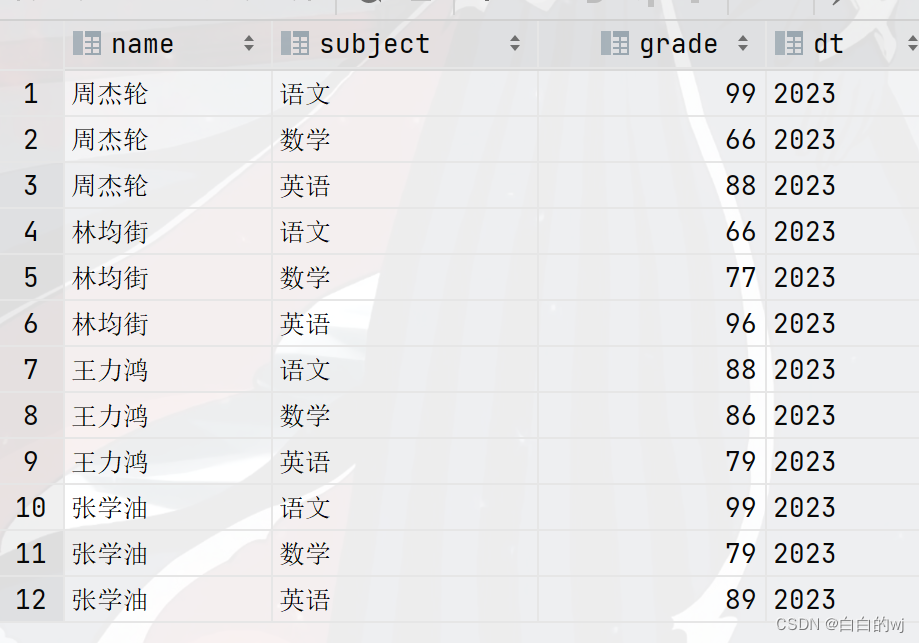
--查询数据 select * from score;--此时dt的三个年份都存在了这个表里 --如,查询2023年的数据,效率提升 select * from score where dt = '2023'; select * from score where dt = '2022'; select * from score where dt = '2024';
可以直接根据年份作为条件来查询表的内容,结果如下
2.一级分区表练习2
1.建表
--练习2建一个新表,-- 创建分区表: create [external] table [if not exists]
-- 表名(字段名 字段类型 , 字段名 字段类型 , ... )
-- partitioned by (分区字段名 分区字段类型) ;
--建表
create table one_part_order(oid string,name string,price double,num int
)partitioned by (year string)
row format delimited
fields terminated by ' ';2.加载数据
四个order.txt文件如下
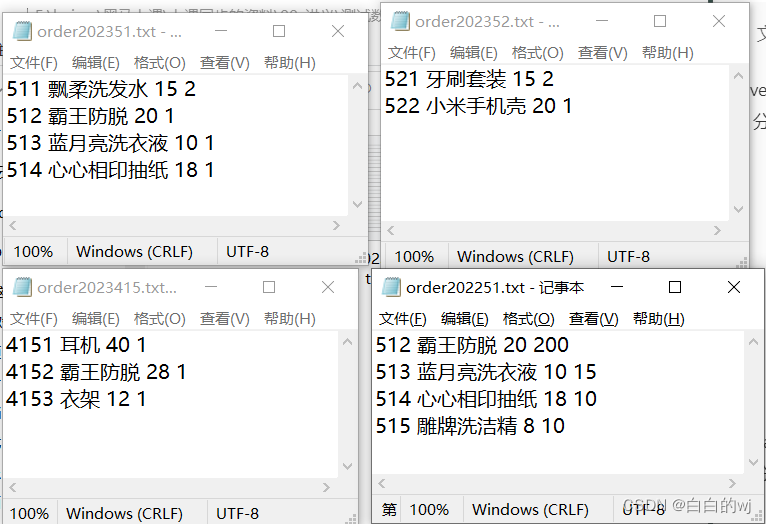
--加载数据,现在hdfs中准备好文件,再使用load加载数据到分区表中
load data inpath '/itcast/order202251.txt'into table one_part_order partition (year='2022');load data inpath '/itcast/order2023415.txt'into table one_part_order partition (year='2023');load data inpath '/itcast/order202351.txt'into table one_part_order partition (year='2023');load data inpath '/itcast/order202352.txt'into table one_part_order partition (year='2023');3.验证数据
select * from one_part_order ;
select * from one_part_order where year = '2023';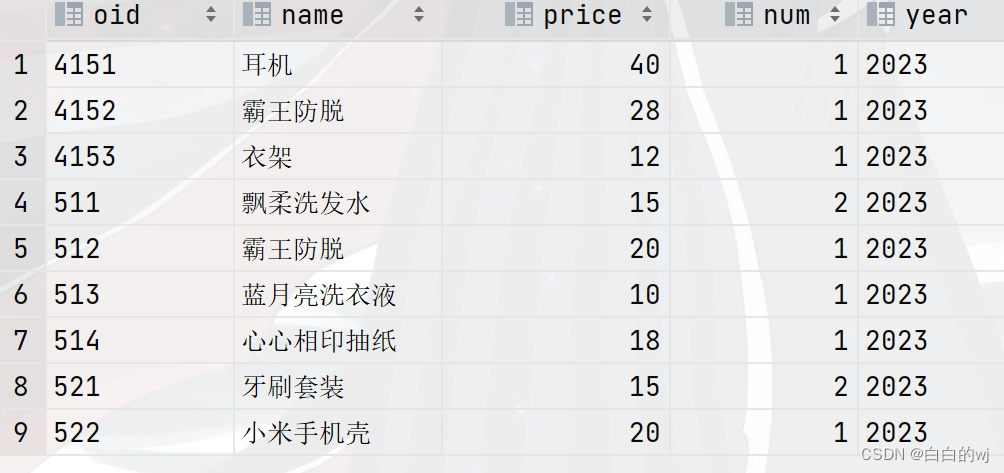
3.创建多级分区表
创建分区表: create [external] table [if not exists] 表名(字段名 字段类型 , 字段名 字段类型 , ... )partitioned by (一级分区字段名 分区字段类型, 二级分区字段名 分区字段类型 , ...) ; 自动生成分区目录并插入数据: load data [local] inpath '文件路径' into table 分区表名 partition (一级分区字段名='值',二级分区字段名='值' , ...);注意: 如果加local后面文件路径应该是linux本地路径,如果没有加那么就是hdfs文件路径
1.建表
--删表
drop table more_part_order;
truncate table multi_part_order;
--建表
create table multi_part_order(oid string,pname string,price double,num int)partitioned by (year string,month string,day string)
row format delimited
fields terminated by ' ';或者
--建表
create table multi_part1_order(oid string,pname string,price double,num int)partitioned by (year string,month string,day string)
row format delimited
fields terminated by ' ';
2.加载数据
--加载数据
load data inpath '/itcast/order202251.txt' into tablemulti_part_order partition (year='2022',month='05',day='01');load data inpath '/itcast/order2023415.txt' into tablemulti_part_order partition (year='2023',month='04',day='15');load data inpath '/itcast/order202351.txt' into tablemulti_part_order partition (year='2023',month='05',day='01');load data inpath '/itcast/order202352.txt' into tablemulti_part_order partition (year='2023',month='05',day='02');或者
--加载数据
load data inpath '/itcast/order202251.txt' into tablemulti_part1_order partition (year='2022',month='2022-05',day='2022-05-01');load data inpath '/itcast/order2023415.txt' into tablemulti_part1_order partition (year='2023',month='2023-04',day='2023-04-15');load data inpath '/itcast/order202351.txt' into tablemulti_part1_order partition (year='2023',month='2023-05',day='2023-05-01');load data inpath '/itcast/order202352.txt' into tablemulti_part1_order partition (year='2023',month='2023-05',day='2023-05-02');
3.验证数据
--验证数据
select * from multi_part1_order;
select * from multi_part1_order where day = '2023-05-01'; 需求1:查询日期为2023年5月1日的商品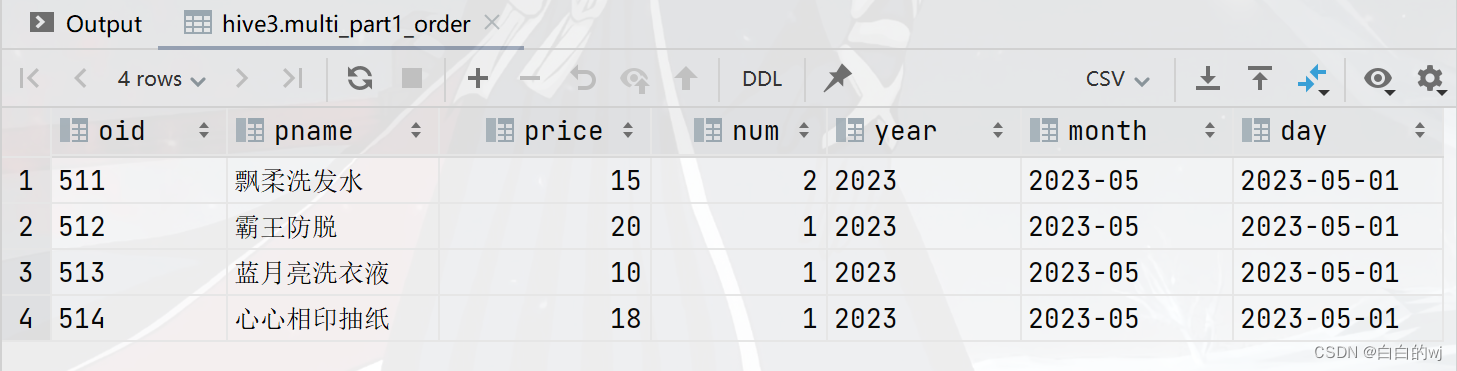
需求2:统计日期2023年5月1日的商品销售额
--统计2023年5月1日,商品的销售额
select sum(price*num) as money from multi_part_orderwhere year='2023'and month='05'and day='01'; 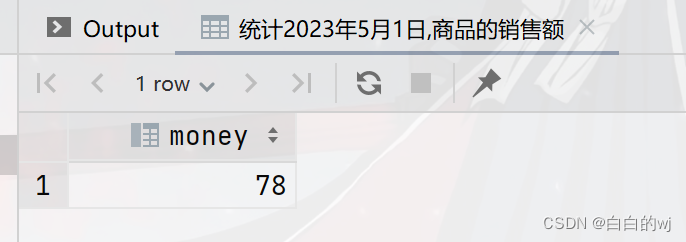
4.分区表操作
添加,删除
--------------------------------分区表操作------------------------------
--添加分区:alter table 分区表名 add partition (分区字段名='值',....);
select * from multi_part1_order;
alter table multi_part1_order add partition (year='2024',month='5',day='01');
--删除分区:alter table 分区表名 drop partition(分区字段名='值',....);
alter table multi_part1_order drop partition (year='2024');
alter table multi_part1_order drop partition (year='2024',month='5',day='01');
alter table multi_part1_order drop partition (year='2024',month='5');修改
--修改分区:alter table 分区表名 partition (分区字段名='旧值' , ...)rename to partition (分区字段名='新值' , ...);
alter table multi_part1_order partition (year='2024',month='5',day='01')rename to partition (year='2030',month='5',day='01');
--本质上是改了原本day01,被移动.并新增了year=2024的目录查看
-- 查看所有分区: show partitons 分区表名;
show partitions multi_part1_order;
-- 同步/修复分区: msck repair table 分区表名;
msck repair table multi_part1_order;5.分桶表
创建基础分桶表:
create [external] table [if not exists] 表名(字段名 字段类型 )clustered by (分桶字段名)
into 桶数量 buckets ;
1.建表
- 创建基础分桶表:
-- create [external] table [if not exists] 表名(字段名 字段类型)clustered by (分桶字段名)into 桶数量 buckets ;
--建表
create table course_base(cid int,cname string,sname string
)clustered by (cid) into 3 buckets
row format delimited fields terminated by '\t';2.加载数据
--加载数据 load data inpath '/itcast/course.txt'into table course_base;
3.验证数据
--验证数据
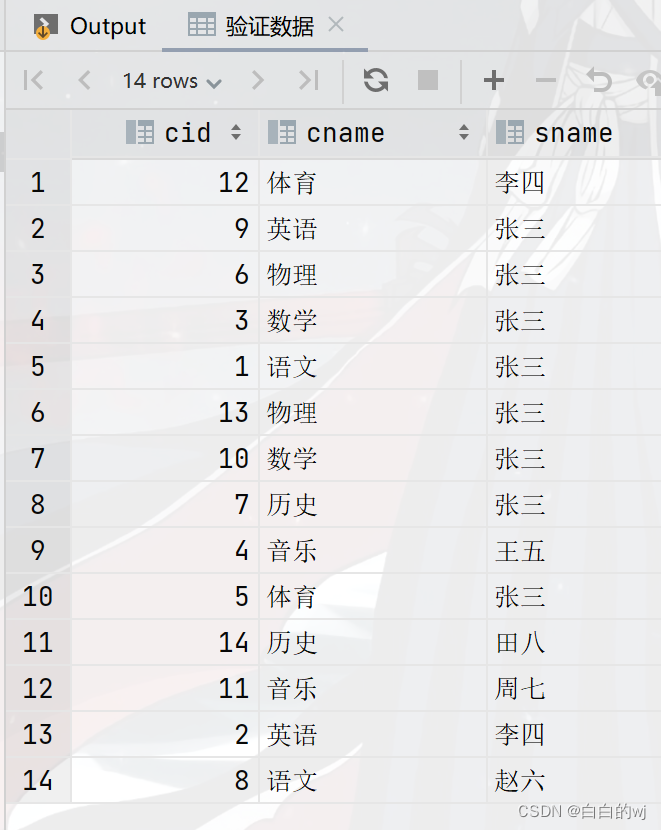
select * from course_base;
--取余数:12/3余0, 9/3余0 , 6/3余0 , 3/3余0 ,1/3余1 ,13/3余1....
6. 分桶表进行排序
--创建基础分桶表,要求分3个桶,桶内根据cid排序 -- 创建基础分桶表,然后桶内排序: -- create [external] table [if not exists] 表名(字段名 字段类型) -- clustered by (分桶字段名)sorted by(排序字段名 asc|desc) # 注意:asc升序(默认) desc降序 -- into 桶数量 buckets ;
1.创建表
--创建分桶表
truncate table course_sort;
create table course_sort(cid int,cname string,sname string
)clustered by (cid) sorted by (cid desc )into 3 buckets
row format delimited fields terminated by '\t';2.加载数据
--加载数据
load data inpath '/input/course.txt'into table course_sort;3. 验证数据
--验证数据
select * from course_sort ;
--生成的三个文件,000000_0 , 000001_0, 000002_0
--验证余数:12/3=0 9/3=0 6/3=0 3/3=0
-- 13/3=1 10/3=1 7/3=1 4/3=1 1/3的结果是0,余1
-- 14/3=2 11/3=2 8/3=2 5/3=2

7.分桶的原理
分桶原理:
如果是数值类型分桶字段: 直接使用数值对桶数量取模
如果是字符串类型分桶字段: 底层会使用hash算法计算出一个数字然后再对桶数量取模
Hash: Hash是一种数据加密算法,其原理我们不去详细讨论,我们只需要知道其主要特征:同样的值被Hash加密后的结果是一致的
举例: 字符串“binzi”被Hash后的结果是93742710(仅作为示意),那么无论计算多少次,字符串“binzi”的结果都会是93742710。
计算余数: hash('binzi')%3==0
注意: 同样的数据得到的结果一致,如’binzi’ hash取模结果是0,无论计算多少次,它的取模结果都是0
8.hive的复杂类型

---------------------------复杂类型建表格式------------------------ -- 复杂类型建表格式:[row format delimited] # hive的serde机制[fields terminated by '字段分隔符'] # 自定义字段分隔符固定格式[collection ITEMS terminated by '集合分隔符'] # 自定义array同类型集合和struct不同类型集合[map KEYS terminated by '键值对分隔符'] # 自定义map映射kv类型[lines terminated by '\n'] # # 默认即可hive复杂类型: array struct map
9.array类型: 又叫数组类型,存储同类型的单数据的集合
-- array类型: 又叫数组类型,存储同类型的单数据的集合 -- 建表指定类型: array<数据类型> -- 取值: 字段名[索引] 注意: 索引从0开始 -- 获取长度: size(字段名) -- 判断是否包含某个数据: array_contains(字段名,某数据)
需求: 已知data_for_array_type.txt文件,存储了学生以及居住过的城市信息,要求建hive表把对应的数据存储起
1.创建表
----建表,
create table test_array_1(name string,location array<string>
)row format delimited
fields terminated by '\t'
collection items terminated by ',';2.加载数据

--加载数据
load data inpath '/itcast/data_for_array_type.txt' into table test_array_1;3.验证数据
--验证数据
select * from test_array_1;
--zhangsan,"[""beijing"",""shanghai"",""tianjin"",""hangzhou""]"
--wangwu,"[""changchun"",""chengdu"",""wuhan"",""beijin""]"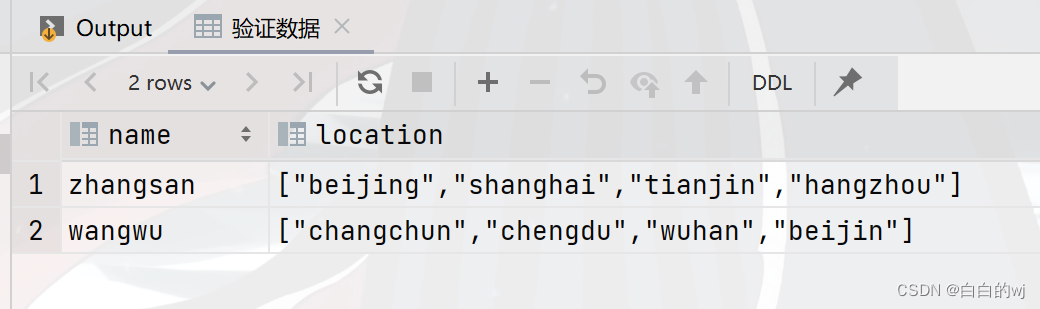
4.需求:查询张三是否在天津住过?
select array_contains(location,'tianjin')from test_array_1 where name = 'zhangsan';
--结果:true5. 需求:查询张三的地址有几个?
select size(location)from test_array_1 where name = 'zhangsan';
--结果:46.需求:查询王五的第二个地址?
select location[1] from test_array_1 where name = 'wangwu';
--结果:chengdu10.struct类型: 又叫结构类型,可以存储不同类型单数据的集合
-- 建表指定类型: struct<子字段名1:数据类型1, 子字段名2:数据类型2 , ...> -- 取值: 字段名.子字段名n
1.建表
-- 建表
create table test_struct_1(id int,name_info struct<name:string,age:int>
)row format delimited fields terminated by '#'
collection items terminated by ':';2.加载数据
--加载数据
load data inpath '/itcast/data_for_struct_type.txt' into table test_struct_1;
3.验证数据
--验证数据
select * from test_struct_1;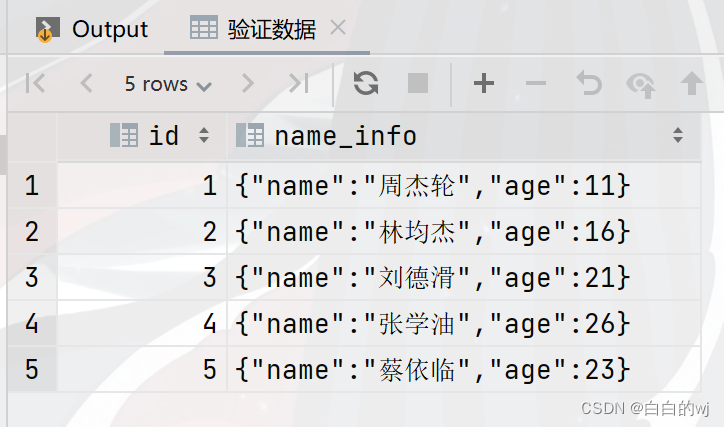
需求1:查询所有用户姓名
select name_info.name from test_struct_1;需求2:查询所有的用户年龄
select name_info.age from test_struct_1;需求3:查询所有用户的平均年龄
11.map类型: 又叫映射类型,存储键值对数据的映射(根据key找value)
-- 建表指定类型: map<key类型,value类型> -- 取值: 字段名[key] -- 获取长度: size(字段名) -- 获取所有key: map_keys() -- 获取所有value: map_values()
1.创建表
--创建表
create table test_map_1(id int,name string,members map<string,string>,age int
)row format delimited
fields terminated by ','
collection items terminated by '#'
map keys terminated by ':';2.加载数据
-- 加载数据
load data inpath '/itcast/data_for_map_type.txt'into table test_map_1;
3.验证数据
--验证数据
select * from test_map_1;
-- 1,林杰均,"{""father"":""林大明"",""mother"":""小甜甜"",""brother"":""小甜""}",28
-- 2,周杰伦,"{""father"":""马小云"",""mother"":""黄大奕"",""brother"":""小天""}",22
-- 3,王葱,"{""father"":""王林"",""mother"":""如花"",""sister"":""潇潇""}",29
-- 4,马大云,"{""father"":""周街轮"",""mother"":""美美""}",26需求1:查询每个学生的家庭成员关系(就是所有的key)
select name,map_keys(members) from test_map_1;需求2:查询每个学生的家庭成员姓名(就是所有的value)
select name ,map_values(members) from test_map_1;需求3:查询每个学生和对应的父亲名字
select name,members['father'] as father from test_map_1;需求4:查询马大云是否有兄弟
select name,array_contains(map_keys(members),'brother') from test_map_1 where name ='马大云';
-- 需求5:查询每个学生的对应brother姓名,没有brother的学生null补全-- 需求6:查询每个学生的对应brother姓名,没有brother的学生直接不显示
相关文章:
2023.11.13 hive数据仓库之分区表与分桶表操作,与复杂类型的运用
目录 0.hadoop hive的文档 1.一级分区表 2.一级分区表练习2 3.创建多级分区表 4.分区表操作 5.分桶表 6. 分桶表进行排序 7.分桶的原理 8.hive的复杂类型 9.array类型: 又叫数组类型,存储同类型的单数据的集合 10.struct类型: 又叫结构类型,可以存储不同类型单数据的集合…...
Spring Cloud学习(七)【Docker 容器】
文章目录 初识 DockerDocker 介绍Docker与虚拟机Docker架构安装 Docker Docker 基本操作镜像相关命令容器相关命令数据卷 Dockerfile 自定义镜像镜像结构Dockerfile DockerComposeDockerCompose介绍安装DockerCompose Docker镜像仓库常见镜像仓库服务私有镜像仓库 初识 Docker …...
好题分享(2023.11.5——2023.11.11)
目录 前情回顾: 前言: 题目一:补充《移除链表元素》 题目二:《反转链表》 解法一:三指针法 解法二:头插法 题目三: 《相交链表》 题目四:《合并两个有序数列》 题目五&…...
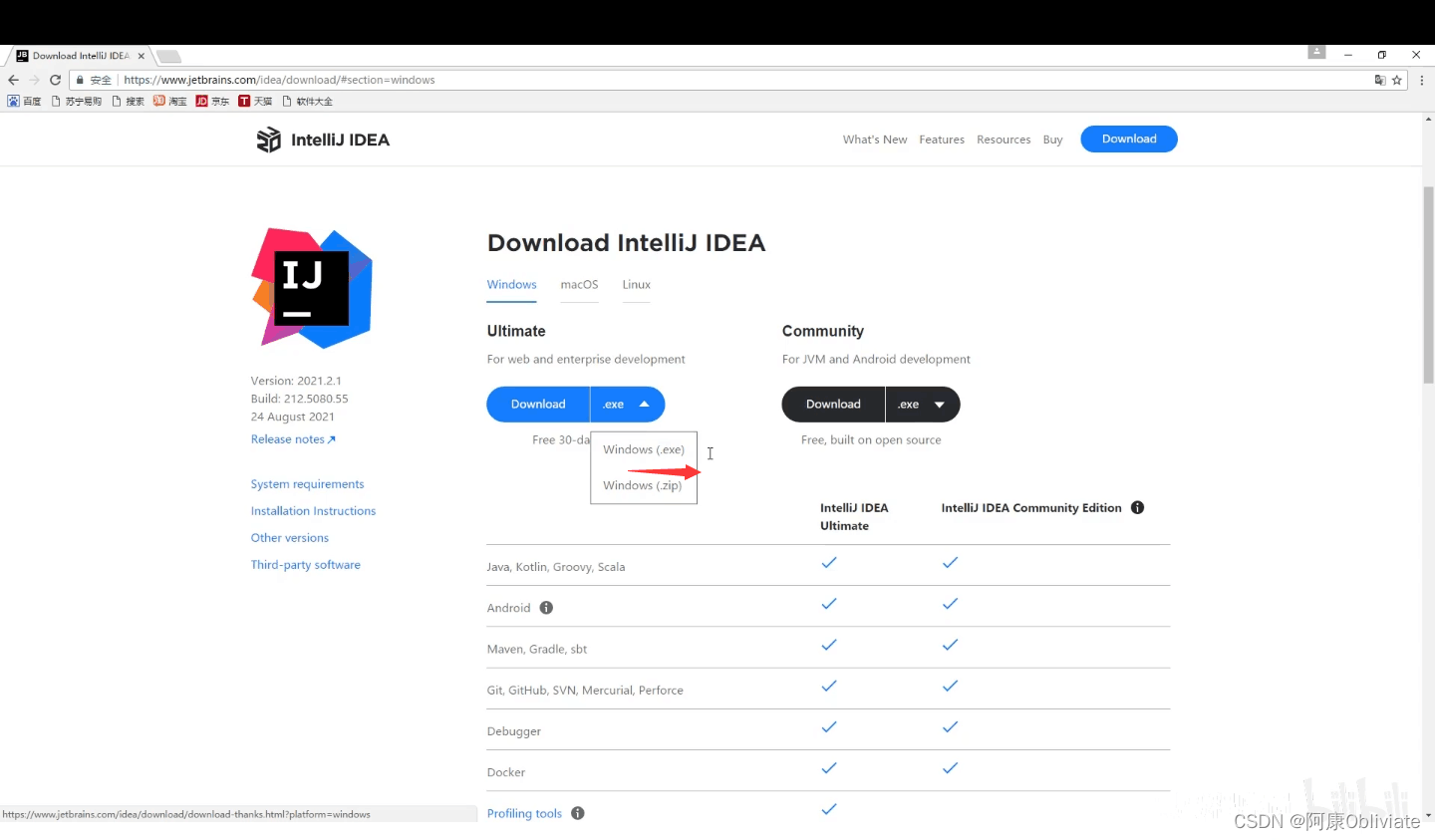
第二章 03Java基础-IDEA相关叙述
文章目录 前言一、IDEA概述二、IDEA下载和安装三、IDEA项目结构介绍四、IDEA的项目和模块操作总结前言 今天我们学习Java基础,IDEA下载以及相关配置和基础使用方法 一、IDEA概述 1.IDEA全称IntelliJ IDEA,是用于Java语言开发的集成工具,是业界公认的目前用于Java程序开发最…...
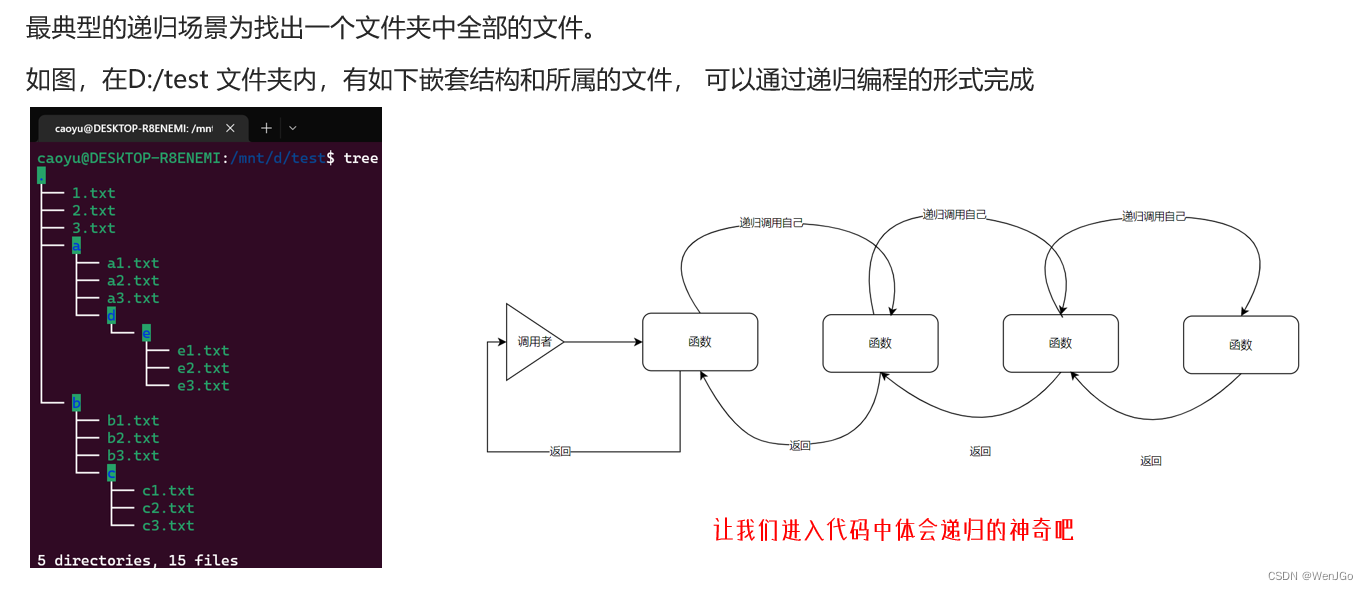
第三阶段第二章——Python高阶技巧
时间过得很快,这么快就来到了最后一篇Python基础的学习了。话不多说直接进入这最后的学习环节吧!!! 期待有一天 春风得意马蹄疾,一日看尽长安花 o(* ̄︶ ̄*)o 1.闭包 什么是闭包? 答…...

【Git】Git分支与应用分支Git标签与应用标签
一,Git分支 1.1 理解Git分支 在 Git 中,分支是指一个独立的代码线,并且可以在这个分支上添加、修改和删除文件,同时作为另一个独立的代码线存在。一个仓库可以有多个分支,不同的分支可以独立开发不同的功能࿰…...
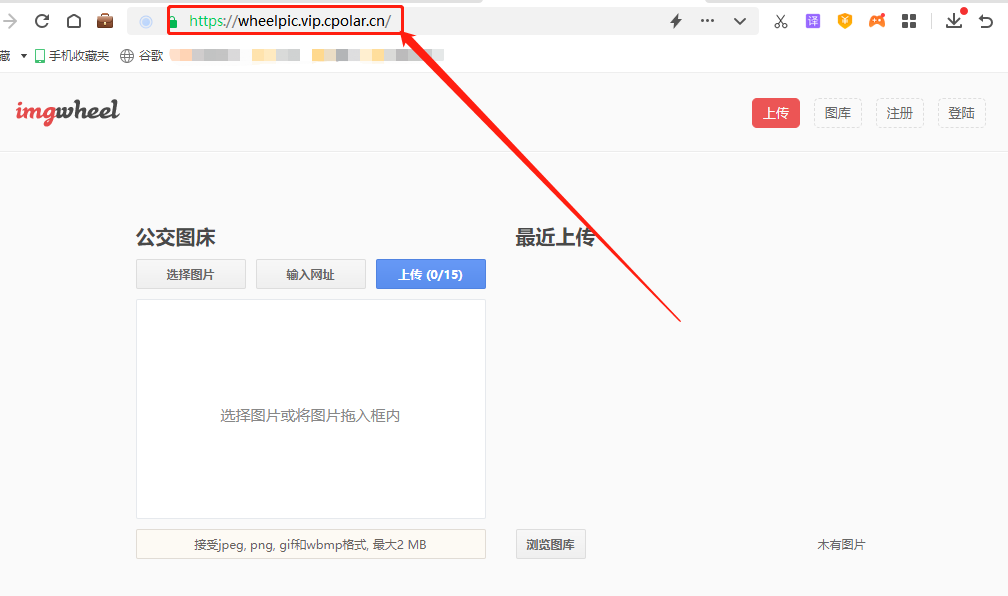
本地PHP搭建简单Imagewheel私人云图床,在外远程访问——“cpolar内网穿透”
文章目录 1.前言2. Imagewheel网站搭建2.1. Imagewheel下载和安装2.2. Imagewheel网页测试2.3.cpolar的安装和注册 3.本地网页发布3.1.Cpolar临时数据隧道3.2.Cpolar稳定隧道(云端设置)3.3.Cpolar稳定隧道(本地设置) 4.公网访问测…...
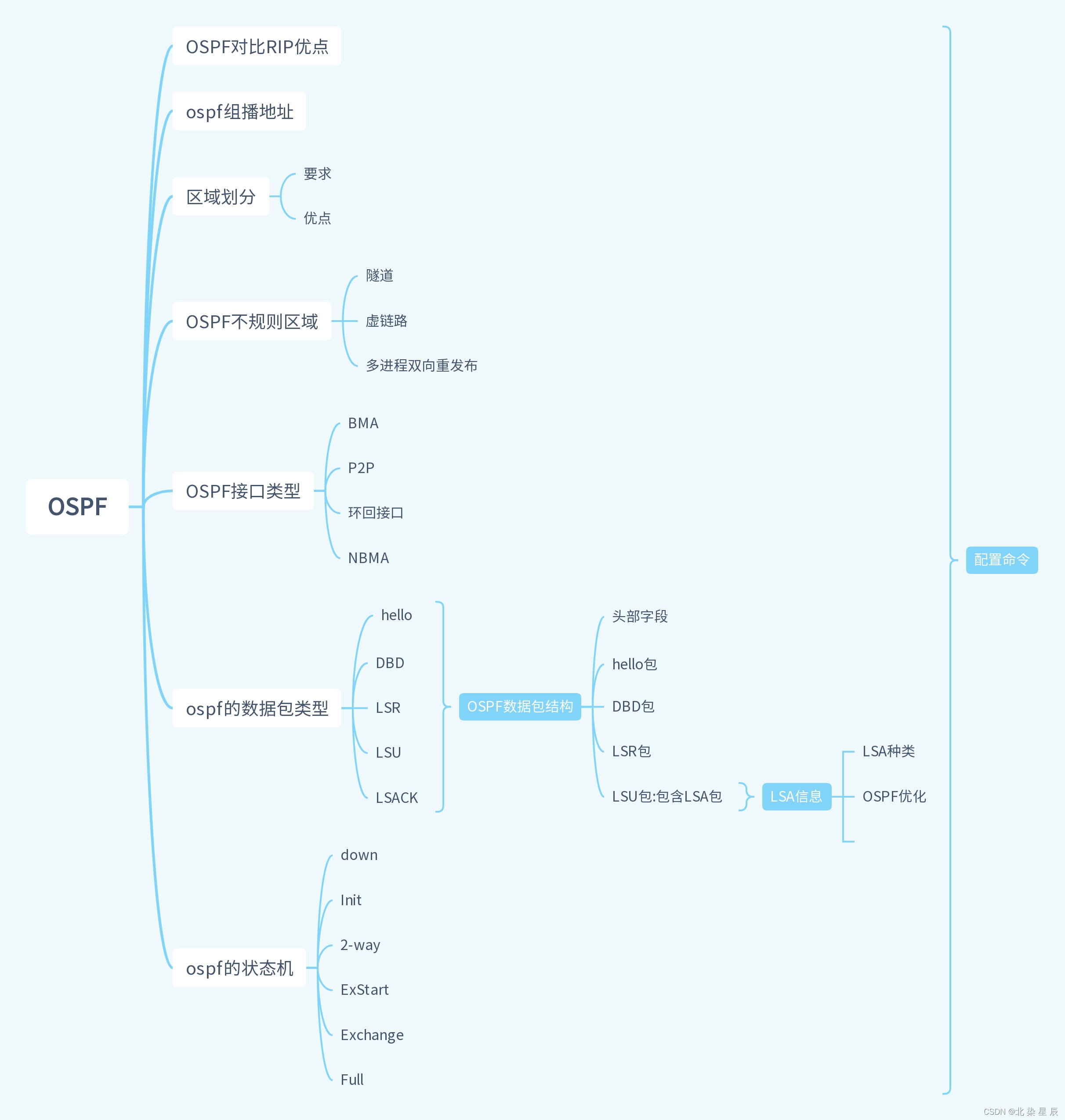
HCIP---OSPF思维导图
...
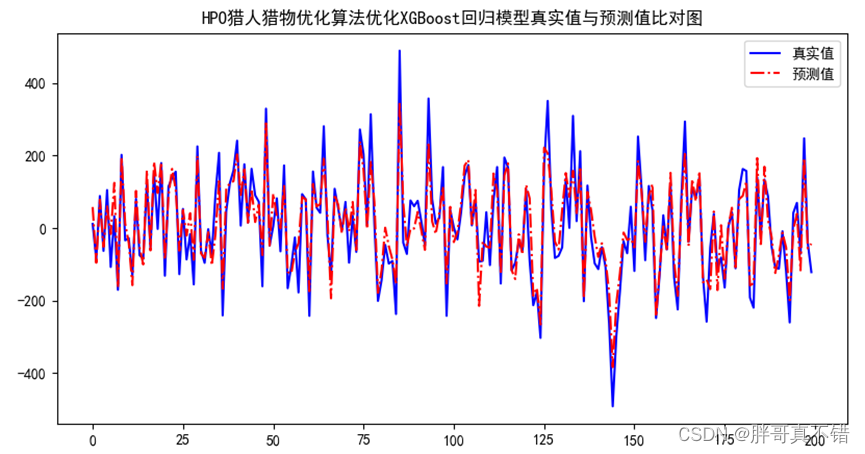
Python实现猎人猎物优化算法(HPO)优化XGBoost回归模型(XGBRegressor算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 猎人猎物优化搜索算法(Hunter–prey optimizer, HPO)是由Naruei& Keynia于2022年提出的一种最新的…...

pandas读写json的知识点
pandas对象可以直接转换为json,使用to_json即可。里面的orient参数很重要,可选值为columns,index,records,values,split,table A B C x 1 4 7 y 2 5 8 z 3 6 9 In [236]: dfjo.to_json(orient"columns") Out[236]: {"A":{"x&qu…...

图论——Dijkstra算法matlab代码
Dijkstra算法步骤 (1)构造邻接矩阵 (2)定义起始点 (3)运行代码 M[ 0 5 9 Inf Inf Inf InfInf 0 Inf Inf 12 Inf InfInf 3 0 15 Inf 23 InfInf 6 …...
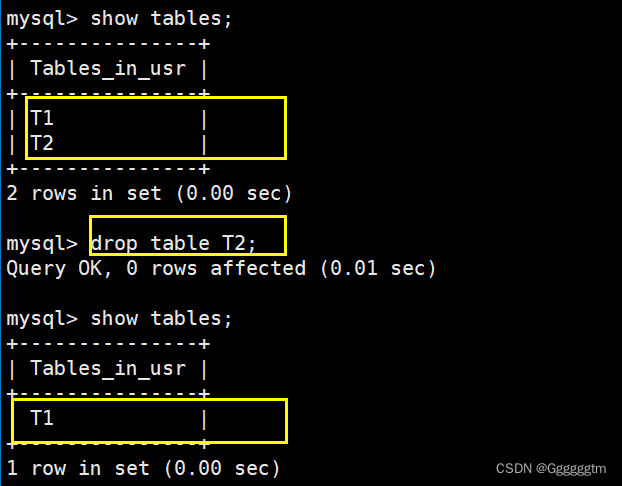
[MySQL] MySQL表的基础操作
文章目录 一、创建表 1、1 SQL语法 1、2 实例演示 二、查询表 三、修改表 3、1 修改表名字 3、2 新增列(字段) 3、3 修改列类型 3、4 修改列名 3、5 删除表 四、总结 🙋♂️ 作者:Ggggggtm 🙋♂️ 👀 专…...

SQL 部分解释。
这段SQL代码的主要作用是从V_order_L表中查询数据,并与V_AATB1DU_F52_M表进行左连接。查询的结果会按照订单时间(orderTime)、POS代码(posCode)和区间名称(f.DName)进行分组。 具体来说…...
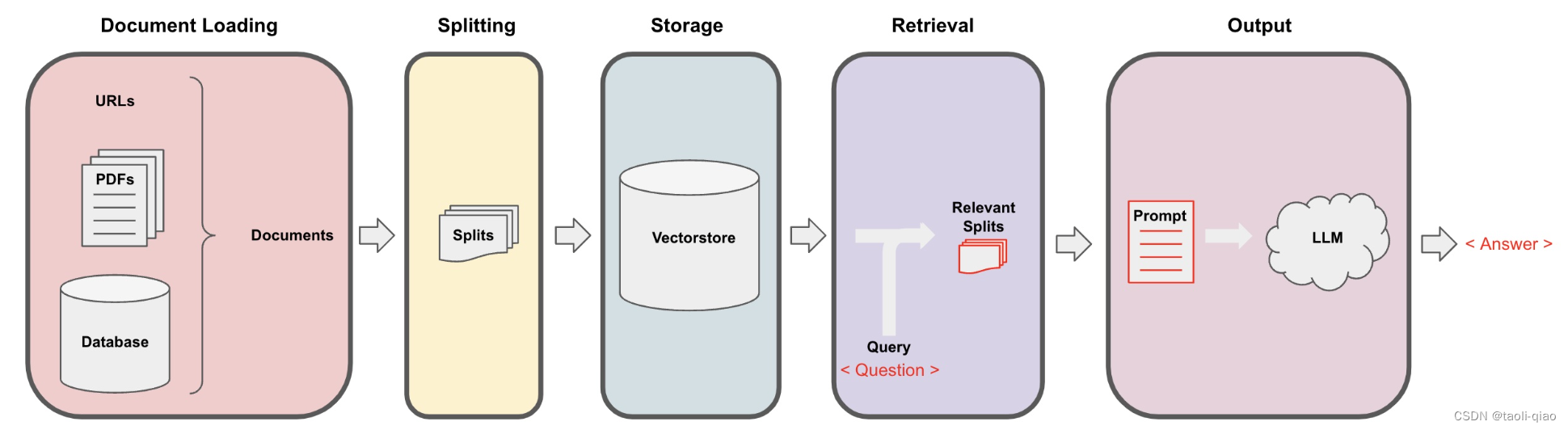
利用LangChain实现RAG
检索增强生成(Retrieval-Augmented Generation, RAG)结合了搜寻检索生成能力和自然语言处理架构,透过这个架构,模型可以从外部知识库搜寻相关信息,然后使用这些信息来生成response。要完成检索增强生成主要包含四个步骤…...

零基础学习Matlab,适合入门级新手,了解Matlab
一、认识Matlab Matlab安装请参见博客 安装步骤 1.界面 2.清空环境变量及命令 (1)clear all :清除Workspace中的所有变量 (2)clc:清除Command Window中的所有命令 二、Matlab基础 1.变量命名规则 &a…...

CCF ChinaSoft 2023 论坛巡礼 | 自动驾驶仿真测试论坛
2023年CCF中国软件大会(CCF ChinaSoft 2023)由CCF主办,CCF系统软件专委会、形式化方法专委会、软件工程专委会以及复旦大学联合承办,将于2023年12月1-3日在上海国际会议中心举行。 本次大会主题是“智能化软件创新推动数字经济与社…...

vue封装useWatch hook支持停止监听和重启监听功能
import { watch, reactive } from vue;export function useWatch(source, cb, options) {const state reactive({stop: null});function start() {state.stop watch(source, cb, options);}function stop() {state.stop();state.stop null;}// 返回一个对象,包含…...

智能配方颗粒管理系统解决方案,专业实现中医药产业数字化-亿发
“中药配方颗粒”,又被称为免煎中药,源自传统中药饮片,经过提取、分离、浓缩、干燥、制粒、包装等工艺加工而成。这种新型配方药物完整保留了原中药饮片的所有特性。既能满足医师的辨证论治和随症加减需求,同时具备强劲好人高效的…...
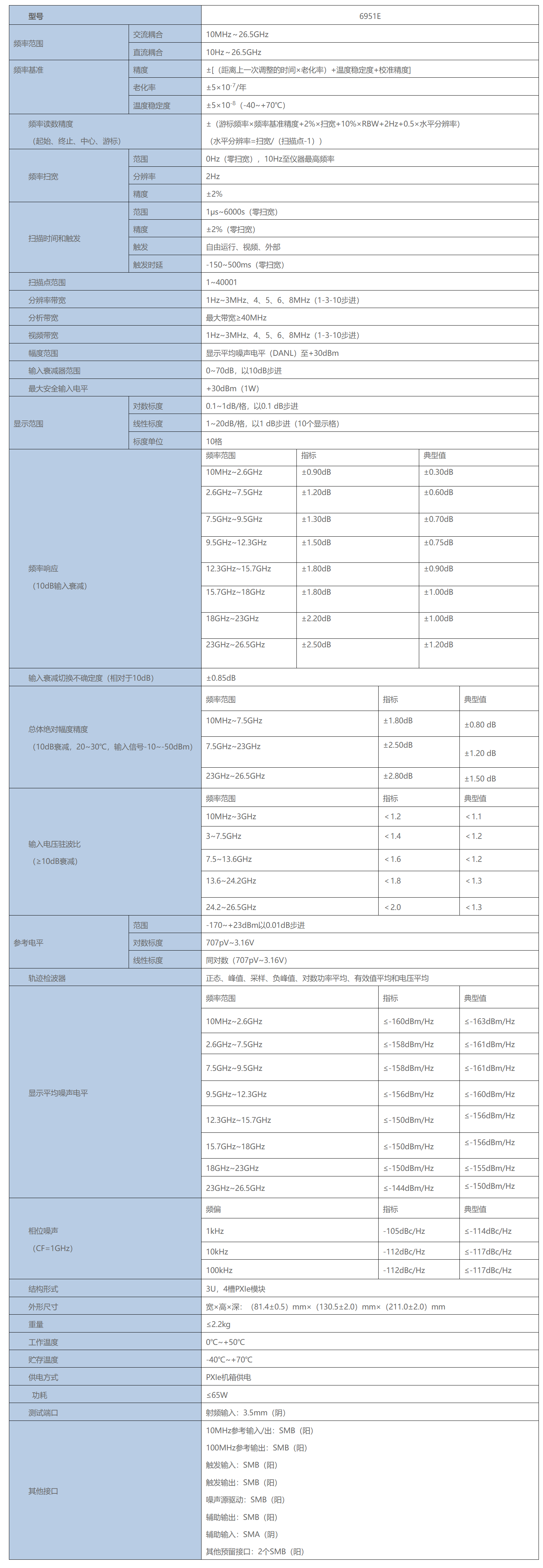
PXI总线测试模块-6951E 信号分析仪
6951E 信号分析仪 频率范围:10Hz~26.5GHz 6951E信号分析仪率范围覆盖10Hz~26.5GHz、带宽40MHz,具备频谱分析、相邻信道功率测试、模拟解调、噪声系数测试等多种测量功能。 6951E信号分析仪采用PXIe总线3U 4槽结构形式ÿ…...

精确杂草控制植物检测模型的改进推广
Improved generalization of a plant-detection model for precision weed control 摘要1、介绍2、结论摘要 植物检测模型缺乏普遍性是阻碍实现自主杂草控制系统的主要挑战之一。 本文研究了训练和测试数据集分布对植物检测模型泛化误差的影响,并使用增量训练来减小泛化误差。…...

Phi-3-mini-4k-instruct保姆级教学:Ollama Web UI自定义System Prompt与温度调节
Phi-3-mini-4k-instruct保姆级教学:Ollama Web UI自定义System Prompt与温度调节 你是不是已经用Ollama Web UI体验过Phi-3-mini-4k-instruct的文本生成能力了?感觉还不错,但总觉得少了点什么?比如,想让模型扮演一个专…...

网工入门必看!4 种网络设备登录方式全解析,从 Console 到 SSH 一次搞懂
做网络运维、数通调试的朋友都知道:所有设备配置的第一步,都是成功登录设备。不管是企业级交换机、路由器、防火墙,还是无线 AC 控制器,主流的登录方式无非 4 种:Console 口登录、Web 界面登录、Telnet 登录、SSH 登录…...
)
从USB2.0协议到Zynq7000实现:手把手拆解一次完整的批量传输(Bulk Transfer)
从USB2.0协议到Zynq7000实现:深入解析批量传输的硬件协同机制 USB批量传输(Bulk Transfer)作为最基础的数据传输模式之一,在嵌入式系统中扮演着关键角色。本文将带您深入理解USB2.0协议中批量传输的完整流程,并揭示Zyn…...

Qwen3.5-9B企业知识库构建:PDF/Markdown文档注入+语义检索集成教程
Qwen3.5-9B企业知识库构建:PDF/Markdown文档注入语义检索集成教程 1. 项目概述 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,具备强大的逻辑推理、代码生成和多轮对话能力。其多模态变体Qwen3.5-9B-VL支持图文输入,并拥有长达128K token…...

如何通过SEO总监的工作经验提升个人价值
SEO总监的工作经验:如何提升个人价值 在当今数字化时代,SEO(搜索引擎优化)已经成为各行各业不可或缺的一部分。作为一名SEO总监,你不仅要了解如何提升企业网站的搜索排名,更要通过自己的工作经验提升个人价…...

快速验证科研工具想法:用快马AI十分钟搭建中科院分区查询原型
作为一名科研工作者,我经常需要查询期刊的中科院分区信息。传统方式要么是手动查阅PDF表格,要么依赖第三方收费工具,效率很低。最近尝试用InsCode(快马)平台快速搭建了一个查询原型,整个过程比想象中简单很多。 需求分析 首先明确…...

Arduino MKR IoT Carrier 库底层控制与工程实践指南
1. Arduino MKR IoT Carrier 库深度解析:面向嵌入式工程师的底层控制指南 Arduino MKR IoT Carrier 是专为 MKR 系列开发板(如 MKR WiFi 1010、MKR NB 1500、MKR GSM 1400 等)设计的硬件抽象层库,其核心目标并非提供通用传感器驱…...

去中心化 AI Agent Harness Engineering 网络与区块链的结合
去中心化 AI Agent Harness Engineering 网络与区块链的结合 1. 引入与连接:开启智能协作新纪元 1.1 一场即将到来的变革 想象一下,在不远的将来,我们的数字世界不再由少数几家科技巨头主导,而是由无数自主运作的智能体组成的生态系统。这些智能体可以自主决策、协作完成…...

FanControl终极指南:3步打造电脑风扇智能控制系统
FanControl终极指南:3步打造电脑风扇智能控制系统 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fan…...

SEO 排名优化软件如何进行竞争对手分析
SEO 排名优化软件如何进行竞争对手分析 在当今的数字营销环境中,SEO(搜索引擎优化)已经成为企业提升在线可见度和吸引潜在客户的关键手段。而SEO排名优化软件作为这一领域的重要工具,其核心功能之一便是竞争对手分析。通过深入了…...