Java编程--定时器/线程池/工厂模式/ ThreadPoolExecutor
前言
逆水行舟,不进则退!!!
目录
什么是定时器
实现一个定时器
自己实现一个定时器
什么是线程池
线程池的使用:
什么是工厂模式?
自己实现一个线程池:
ThreadPoolExecutor 类
什么是Runnable 任务?
什么是 Callable 任务?
获取异步的执行结果 是什么意思?
ThreadPoolExecutor类的构造方法有7个参数,
什么是定时器
在Java编程中,定时器是一种工具,它用于在指定的时间点主动触发某个事件,而无需外力去开启或启动。这种机制可以节省人力并实现统一管理。 其中,java.util.Timer类是最常用的定时器实现方式,它允许开发者安排在指定时间运行的任务。 使用Timer类创建定时器主要包括以下步骤:
首先,创建一个Timer对象;
其次,创建一个TimerTask对象,该对象包含了要执行的代码;
然后,将TimerTask对象添加到Timer对象中;
最后,调用Timer对象的schedule方法来安排任务的执行。
此外,定时计划任务功能在Java中主要使用的就是Timer对象,它在内部使用多线程的方式进行处理,所以Timer对象一般又和多线程技术结合紧密。
定时器的使用:
import java.util.Timer;
import java.util.TimerTask;public class ThreadDemo10 {public static void main(String[] args) {System.out.println("程序启动");// Timer 类就是 标准库的定时器Timer timer = new Timer();timer.schedule(new TimerTask() { //TimerTask是timer.schedule方法的第一个参数,// 其实就是Runnable,TimerTask就是一个实现了Runnable的抽象类。// 也要通过run() 方法来描述一段代码。@Overridepublic void run() {System.out.println("运行定时器任务3");}}, 3000); // TimerTask 的第二个参数是,指定的时间,// 意思就是,一段时间后,触发第一个参数描述的代码。// 多写两个,感受一下定时执行的任务timer.schedule(new TimerTask() { @Overridepublic void run() {System.out.println("运行定时器任务2");}}, 2000); timer.schedule(new TimerTask() { @Overridepublic void run() {System.out.println("运行定时器任务1");}}, 1000); }
}实现一个定时器
自己实现一个定时器
分析:
1,让被注册的任务,能够在指定时间被执行。
2,一个定时器是可以注册 N 个任务的,N 个任务会按照最初约定的时间,按顺序执行。
若要实现 1, 就需要在定时器内部,单独弄一个线程,让这个线程周期性的扫描,判断任务是否是到时间了。如果到时间了,就执行,没到时间,就再等等。并且 N 个任务也需要保存。
所以,定时器中的核心:
1, 有一个扫描线程,负责查看时间到没到,到了就执行相应任务
2, 还要有一个数据结构,来保存所有被注册的任务。
选用什么数据结构呢: 每个任务都是带着“时间”的, 所以我们这里选用优先级队列来存储。 时间段小的,优先级就高, 此时的扫描线程只用扫描队首元素即可,不必遍历整个队列。
此处的优先级队列是要在 多线程 环境下使用,要考虑线程安全问题。
import java.util.concurrent.PriorityBlockingQueue;//开始写 定时器
class MyTimer {//扫描线程private Thread t = null;// 有一个阻塞优先级队列, 来保存任务private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();//扫描线程的具体实现public MyTimer() {t = new Thread(() -> {while(true) {try {//取出队首元素,检查看看队首元素任务是否到时间了,//如果时间没到,就把任务再塞回队列中//如果时间到了,就执行任务。MyTask myTask = queue.take(); // 将任务从 阻塞优先级队列中拿出来。synchronized (this) { // 这里使用 wait 主要是为了防止 忙等。// 这个 synchronized 本来是放到 wait 那里,// 放到这里是为了 保证 取出任务 和 wait 原子化, 防止在中间线程被调度走而且同时来了新任务。long curTime = System.currentTimeMillis(); //获取当前的时间if (curTime < myTask.getTime()) {//说明当前的时间 还没到要执行任务的时间queue.put(myTask); // 再把任务 放回到阻塞优先级队列中。//在 put 之后, 进行wait 等待// 等待指定时间this.wait(myTask.getTime() - curTime); // wait 操作,要搭配 锁 来进行的} else {// 已经到了要执行任务的时间了, 可以开始执行任务了。myTask.run();}}} catch (InterruptedException e) {e.printStackTrace();}}});t.start();}//提供一个 schedule() 方法,来注册任务 : 两个参数://第一个参数:执行的 任务//第二个参数:执行任务前等待的时间。public void schedule(Runnable runnable, long after) {//第二个参数这里,需要换算为 : 当前的时刻 + 需要等待的时间。MyTask task = new MyTask(runnable, System.currentTimeMillis() + after);queue.put(task);synchronized (this) {this.notify(); // 唤醒一下扫描线程}}}//任务的具体描述
class MyTask implements Comparable<MyTask> {//要执行的任务内容private Runnable runnable;// 任务在啥时候执行(使用 毫秒时间戳)private long time;public MyTask(Runnable runnable, long time) {this.runnable = runnable;this.time = time;}//获取当前任务的时间public long getTime() {return time;}//执行任务public void run() {runnable.run();}@Overridepublic int compareTo(MyTask o) {// 返回 小于0, 大于0, 0 这三个数字// this 比 o 大, 返回 >0;return (int)(this.time - o.time);}
}public class ThreadDemo11 {public static void main(String[] args) {MyTimer myTimer = new MyTimer();myTimer.schedule(new Runnable() {@Overridepublic void run() {System.out.println("任务1");}}, 1000);myTimer.schedule(new Runnable() {@Overridepublic void run() {System.out.println("任务2");}}, 2000);}
}注意:
1,在创建一个新任务那里,在将任务创建好,放入堆中之后,有一步唤醒操作,这里的唤醒操作是唤醒扫描线程那里的等待。在扫描线程中,会将最优先的任务拿出来看看,如果还没到执行的时间,那就再将任务放回到优先级队列中,并且阻塞需要等待的时间。就是这里,如果在阻塞等待时间内,又来了一个优先级更高的任务(时间更短,比刚刚阻塞等待的时间还短),就需要扫描线程重新去优先级队列中拿出最优先的任务,重新计算阻塞等待的时间,然后阻塞等待。所以说,这里的这个唤醒机制很有必要。
2,在扫描线程中,synchronized(this) 这行代码 锁住的是实现MyTimer类 的 对象,同一时间,只能有一个线程可以访问到这个对象。
拓展:如果类中有多个静态方法,使用synchronized 修饰其中一个静态方法,那也同样是对整个类进行了加锁,同一时间,只能有一个线程可以访问到该类的任何静态方法。但是并没有对实现这个类的对象加锁。
什么是线程池
线程池: 为了使多线程开发更高效,使多线程的使用更轻便,而产生。事先把需要使用的线程创建好,放到“池”中,后面需要使用的时候,直接从池里获取,用完后也还给 “池”, 这两个动作要比 创建/销毁 更高效。
创建线程/销毁线程 是交给 操作系统内核 完成的。而从池子里获取/还给池, 是咱们自己用户代码就能实现的,不必交给内核操作。
什么是操作系统内核?
答:操作系统内核是操作系统最基本的部分,是一个提供硬件抽象层、磁盘及文件系统控制、多任务等功能的系统软件。它是为众多应用程序提供对计算机硬件的安全访问的一部分软件,这种访问是有限的,并且内核决定一个程序在什么时候对某部分硬件操作多长时间。直接对硬件操作是非常复杂的,所以内核通常提供一种硬件抽象的方法来完成这些操作。
无论是商业的还是个人开发的操作系统内核,都被视为计算机系统的基石和黑盒。这意味着用户通常不需要知道内核内部是如何实现的,只需要使用该内核提供的服务即可。
我们不清楚内核的具体行为,也就意味着不可控,当我们将任务交给操作系统内核,何时等到系统的回应也是不可控的,因为系统内核不仅仅这一个任务。所以,相比于内核来说,用户态,执行程序的行为是可控的。
线程池的使用:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
// 使用标准库中的线程池
public class ThreadDemo12 {public static void main(String[] args) {// 创建了一个固定线程数目的线程池// 这里的创建 使用了工厂模式ExecutorService pool = Executors.newFixedThreadPool(10);for(int i = 0; i <1000; i++) {int n = i;pool.submit(new Runnable() {@Overridepublic void run() { // 这个 run() 方法 不是由主线程调用的,// 而是由线程池中的线程调用。System.out.println("hello " + n);}});}}
}
什么是工厂模式?
答:用一句话表示:使用普通方法,来代替构造方法创建对象。那为什么需要代替构造方法了?因为在某些情况下,我们可能要构造多个不同情况的对象,但是使用构造方法的重载又有一些局限性(重载方法 名称相同,参数个数和类型不同),这种情况对我们实现一些代码时有些限制,于是就有了工厂模式。
普通方法,方法名字没有限制的,因此有多种方法构造,就可以直接使用不同的方法名即可,此时,方法的参数是否要区分就已经不重要了。
自己实现一个线程池:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;class MyThreadPool {// 此处不涉及到时间, 此处只有任务,就直接使用 Runnable 即可// 阻塞队列中元素的类型为 Runnable 接口类型private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();// n 表示线程的数量public MyThreadPool(int n) {// 在这里创建线程// for循环来创建线程for(int i = 0; i < n; i++) {Thread t = new Thread(() -> {// while 循环来让线程不断地从队列中取任务。while(true) {try {Runnable runnable = queue.take();runnable.run();} catch (InterruptedException e) {e.printStackTrace();}}});t.start();}}// 注册任务给线程池public void submit (Runnable runnable) {try {queue.put(runnable);} catch (InterruptedException e) {e.printStackTrace();}}}public class ThreadDemo16 {public static void main(String[] args) {MyThreadPool pool = new MyThreadPool(10);for(int i = 0; i < 1000; i++) {int n = i;pool.submit(new Runnable() {@Overridepublic void run() {System.out.println("hello " + n);}});}}
}
ThreadPoolExecutor 类
ThreadPoolExecutor : 最原生的线程池
ThreadPoolExecutor是Java中线程池的核心实现类,它主要用来执行被提交的任务。通过ThreadPoolExecutor的execute()方法,用户可以提交Runnable任务进行执行;而通过submit()方法,用户不仅可以提交Runnable任务和Callable任务,还能获取异步的执行结果。
使用ThreadPoolExecutor的主要优点在于,当系统中频繁地创建线程时,如果线程过多,会带来调度开销,进而影响缓存局部性和整体性能。而通过使用线程池,可以避免在处理短时间任务时频繁地创建与销毁线程所带来的代价。线程池维护着多个线程,等待着监督管理者分配可并发执行的任务,这既保证了内核的充分利用,又防止了过分调度。
什么是Runnable 任务?
在Java中,Runnable接口表示一个可以被线程执行的任务,它本身是一个抽象任务,只定义了要执行的操作,并没有具体的实现。这个接口里包含一个无返回值的方法run()。Runnable没有启动线程的能力,因此必须使用Thread类中的start方法才能够启动一个线程。Runnable的run()方法定义没有抛出任何异常,所以任何的Checked Exception都需要在run()实现方法中自行处理。
什么是 Callable 任务?
与Runnable相似的Callable接口也能被线程执行,但Callable接口的task能返回一个结果,也可以抛出Exception。两者都可以被ExecutorService执行,其中Callable的call()方法只能通过ExecutorService的submit(Callable task)方法来执行,并且会返回一个Future,是表示任务等待完成的对象。
获取异步的执行结果 是什么意思?
异步执行结果是指在程序执行过程中,某个耗时较长的操作(通常是IO操作或者计算密集型任务)在执行时并不会阻止其它操作的进行,当这个耗时操作完成时,该操作的结果将会被后续的操作或者函数使用。异步编程是一种提高程序性能的方式,它允许同一时间发生(处理)多个事件。
例如,在Java中,当我们调用一个耗时较长的功能(方法)时,如网络请求或大规模计算,这个方法并不会阻塞程序的执行流程,程序会继续往下执行。当这个功能执行完毕时,比如数据接收完毕或者计算完成,程序能够获得执行完毕的消息或能够访问到执行的结果(如果有返回值或需要返回值时)。
另外,在更现代的编程模式中,如回调函数、Promises、Futures和CompletableFuture等,可以以非阻塞的方式获取任务执行结果,这种方式不仅提高了程序的响应速度和执行效率,而且使得代码逻辑更加清晰易懂。
ThreadPoolExecutor类的构造方法有7个参数,
分别是:
1. corePoolSize:线程池中会维护一个最小的线程数量,这些线程处理空闲状态,他们也不会 被销毁,除非设置了allowCoreThreadTimeOut。这里的最小线程数量即是corePoolSize。
2. maximumPoolSize:线程池允许的最大线程数量。
3. keepAliveTime:当线程池中的线程数量超过corePoolSize时,多余的空闲线程的存活时间。
4. unit:keepAliveTime的时间单位。
5. workQueue:任务队列,用于存放待执行的任务。
6. threadFactory:创建新线程的工具类。
7. handler:当线程池中的线程数量超过maximumPoolSize且任务队列已满时,如何处理新提交的任务。
注解:
1,corePoolSize 核心线程数 和 maximumPoolSize 最大线程数 的区别:
核心线程数是指线程池中一直保持的线程数,哪怕它们处于空闲状态。这意味着即使线程池中没有任务,这些核心线程也会一直保持存在,以便于快速响应新的任务请求
最大线程数则是指线程池中允许的最大线程数,这包括了空闲线程和正在工作的线程。如果线程池的任务队列已满且所有的核心线程都在工作,那么此时如果有新任务提交,线程池会根据设置的策略决定是否创建新的线程
举两个例子:
1),在一家公司中, 核心线程数就是正式员工, 最大线程数就是 正式员工 + 实习生;当所有的正式员工都在忙碌,并且还有新的任务下来,这时就会招收一些实习生来缓解压力。如果长时间任务比较少,实习生一直在摸鱼(线程空闲),那么就会销毁这个线程,但是呢核心线程数并不会被销毁(即使线程空闲)
2),假设你开了一家餐厅,这家餐厅的服务员就是线程,而顾客就是任务。核心线程数就好比是你固定的服务员人数,无论餐厅是否忙碌,这些服务员都会在岗位上待命,随时准备为顾客服务。 最大线程数则好比是餐厅能够容纳的最大服务员数量,包括正在工作的和待命的。如果所有的服务员都在工作,并且还有新的顾客进来,那么就需要根据餐厅的规定来决定是否需要再雇佣新的服务员。 例如,你的餐厅规定,当所有服务员都在工作时,如果有新的顾客进来,那么就不能再接待更多的顾客了,除非有服务员完成他们的工作并腾出位置。这就是最大线程数的作用。
2,keepAliveTime 简单解释就是 实习生可以摸鱼的最大时间,超过这个线程就销毁。unit: keepAliveTime 是摸鱼时间的时间单位
3,handler 其实就是一个拒绝策略 ThreadPoolExecutor类的构造方法中,处理提交任务超过线程池最大容量的拒绝策略有四种:
1) AbortPolicy(默认):直接抛出RejectedExecutionException异常,阻止系统正常运行。
2) DiscardOldestPolicy:丢弃等待队列中最旧的任务,然后重新尝试执行任务(重复此过程直到能够执行任务为止)。
3) DiscardPolicy:直接丢弃新来的任务,不抛出异常。
4) CallerRunsPolicy:让调用者自己运行任务。

我是专注学习的章鱼哥~
相关文章:
Java编程--定时器/线程池/工厂模式/ ThreadPoolExecutor
前言 逆水行舟,不进则退!!! 目录 什么是定时器 实现一个定时器 自己实现一个定时器 什么是线程池 线程池的使用: 什么是工厂模式? 自己实现一个线程池: ThreadPoolExecutor 类…...

【python】Django——django简介、django安装、创建项目、快速上手
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ Django基础——django安装、创建django项目、django快速上手 django简介django安装1. conda创建环境pydjango2. pip安装django3. django目录 创建项目1. 打开终端(cmd)2. 进入某个目录3.创建项目命令4.django项目…...
未来之选:为什么向量数据库是您的数据管理利器
文章目录 前言什么是向量数据库?向量数据库的机制向量数据库的优点查询向量数据库 什么是向量Embedding?Amazon OpenSearch Service总结 前言 向量数据库擅长处理复杂的高维数据,正在彻底改变商业世界的数据检索和分析。它们执行相似性搜索…...

隧道施工工艺流程vr线上虚拟展示成为产品3D说明书
行业内都知道,汽车生产的大部分都需要冲压加工来完成,因此汽车冲压工艺是汽车制造过程中的重要环节,传统的展示方式往往局限于二维图纸和实地操作,难以充分展现工艺的细节和流程。然而,随着技术的进步,汽车…...
)
Nacos(含安装)
Nacos是一个开源的动态服务发现、配置和管理平台。它提供了服务发现、服务健康检查、动态配置管理、服务元数据管理等功能,支持多种服务发现和注册方式。Nacos可以帮助开发者快速构建一个具有弹性和高可用性的微服务应用程序。Nacos的全称是Named after Configurati…...

本地跑项目解决跨域问题
跨域问题: 指的是浏览器不能执行其他网站的脚本,它是由浏览器的同源策略造成的,是浏览器对 javascript 施加的安全限制。 同源策略: 是指协议(protocol)、域名(host)、端口号&…...

聊聊logback的isDebugEnabled
序 本文主要研究一下logback的isDebugEnabled isDebugEnabled public final class Loggerimplements org.slf4j.Logger, LocationAwareLogger, LoggingEventAware, AppenderAttachable<ILoggingEvent>, Serializable {//......public boolean isDebugEnabled() {retur…...

ChatGPT+Roblox,元宇宙的AI叙事逻辑#Leveling Up
MixCopilot 嗨,亲爱的听众朋友们!欢迎收听我们的播客节目!我是你们的主播:MixCopilot 混合副驾。今天我们要为大家带来的是我们的AI革命系列节目之一。这个系列节目聚焦于AI领域的一些最有影响力的建设者,他们将会讨论…...
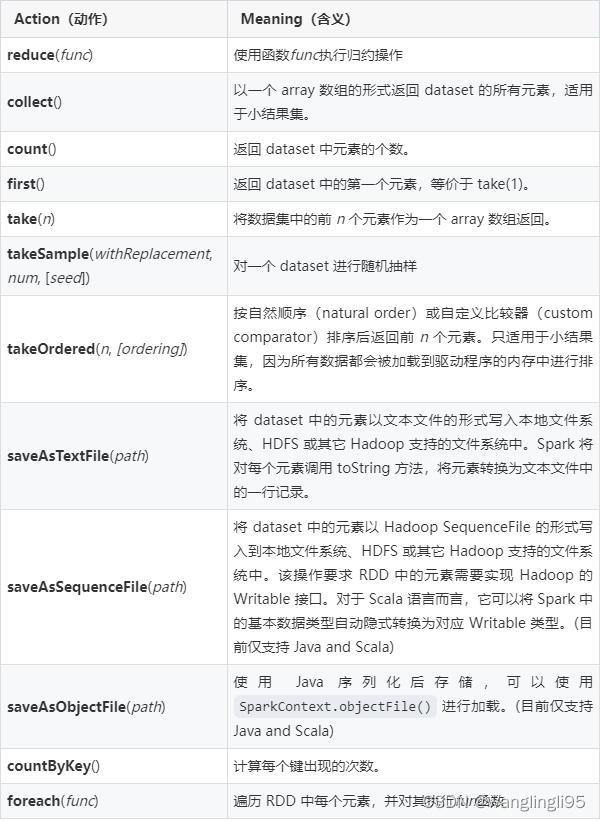
Spark算子
一、编写spark程序的准备工作(程序入口 SparkContext) 1.创建SparkConf val conf new SparkConf().setMaster("local[2]").setAppName("hello-app") 2.创建sparkContext val sc: SparkContext new SparkContext(conf) 二、基…...
Containerd接入Harbor仓库
在使用容器时,避免不了会使用到私有仓库,一般都是采用 harbor 作为私有仓库,docker 对接 harbor 仓库非常简单,哪 containerd 如何对接 harbor 呢? 在内网使用 harbor 根据个人习惯,一般都是非 http 并且是…...
)
Angular 组件介绍及使用(一)
Angular 概述 Angular 是一个用于构建 Web 应用程序的开源前端框架,由 Google 团队开发和维护。它采用 TypeScript 编程语言,并借鉴了一些传统的 Web 开发模式和最佳实践,提供了强大而灵活的工具和特性。 以下是 Angular 的一些概述要点&am…...

2023.11.13 hive数据仓库之分区表与分桶表操作,与复杂类型的运用
目录 0.hadoop hive的文档 1.一级分区表 2.一级分区表练习2 3.创建多级分区表 4.分区表操作 5.分桶表 6. 分桶表进行排序 7.分桶的原理 8.hive的复杂类型 9.array类型: 又叫数组类型,存储同类型的单数据的集合 10.struct类型: 又叫结构类型,可以存储不同类型单数据的集合…...
Spring Cloud学习(七)【Docker 容器】
文章目录 初识 DockerDocker 介绍Docker与虚拟机Docker架构安装 Docker Docker 基本操作镜像相关命令容器相关命令数据卷 Dockerfile 自定义镜像镜像结构Dockerfile DockerComposeDockerCompose介绍安装DockerCompose Docker镜像仓库常见镜像仓库服务私有镜像仓库 初识 Docker …...
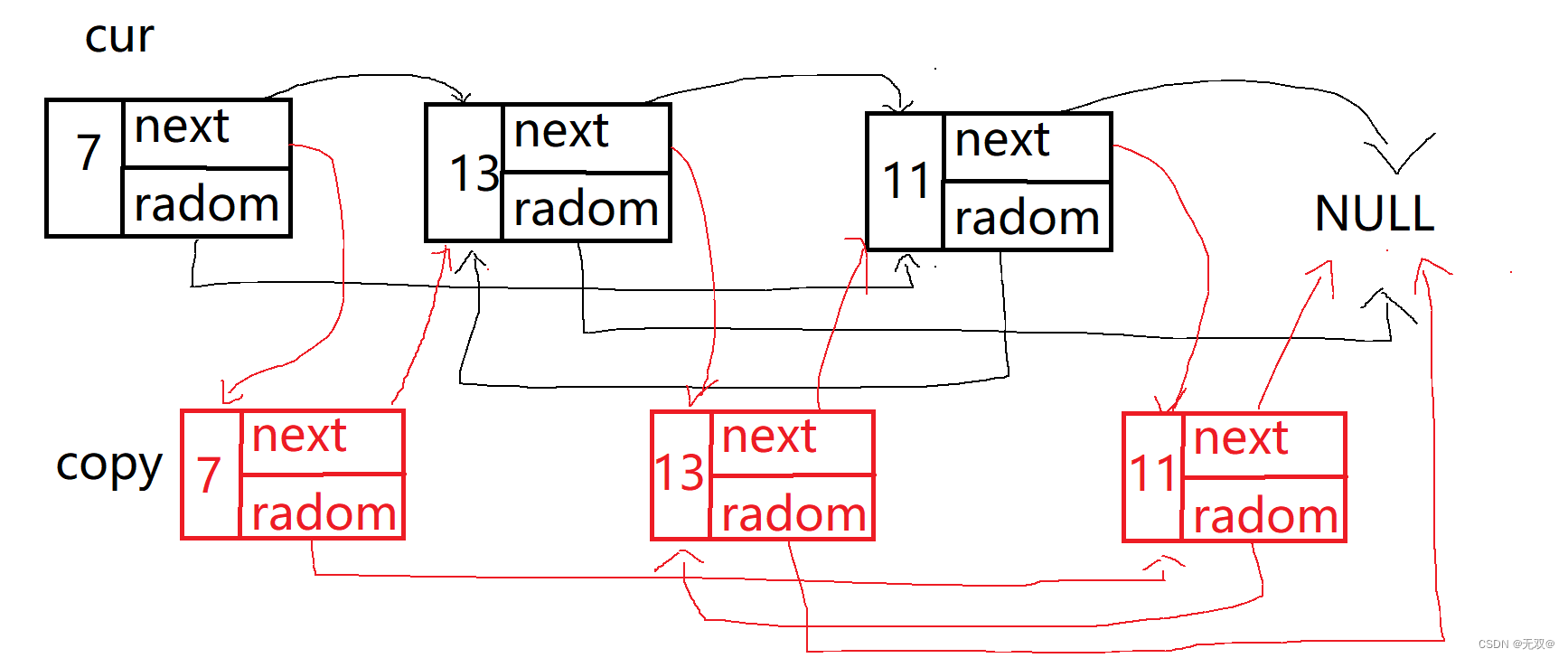
好题分享(2023.11.5——2023.11.11)
目录 前情回顾: 前言: 题目一:补充《移除链表元素》 题目二:《反转链表》 解法一:三指针法 解法二:头插法 题目三: 《相交链表》 题目四:《合并两个有序数列》 题目五&…...
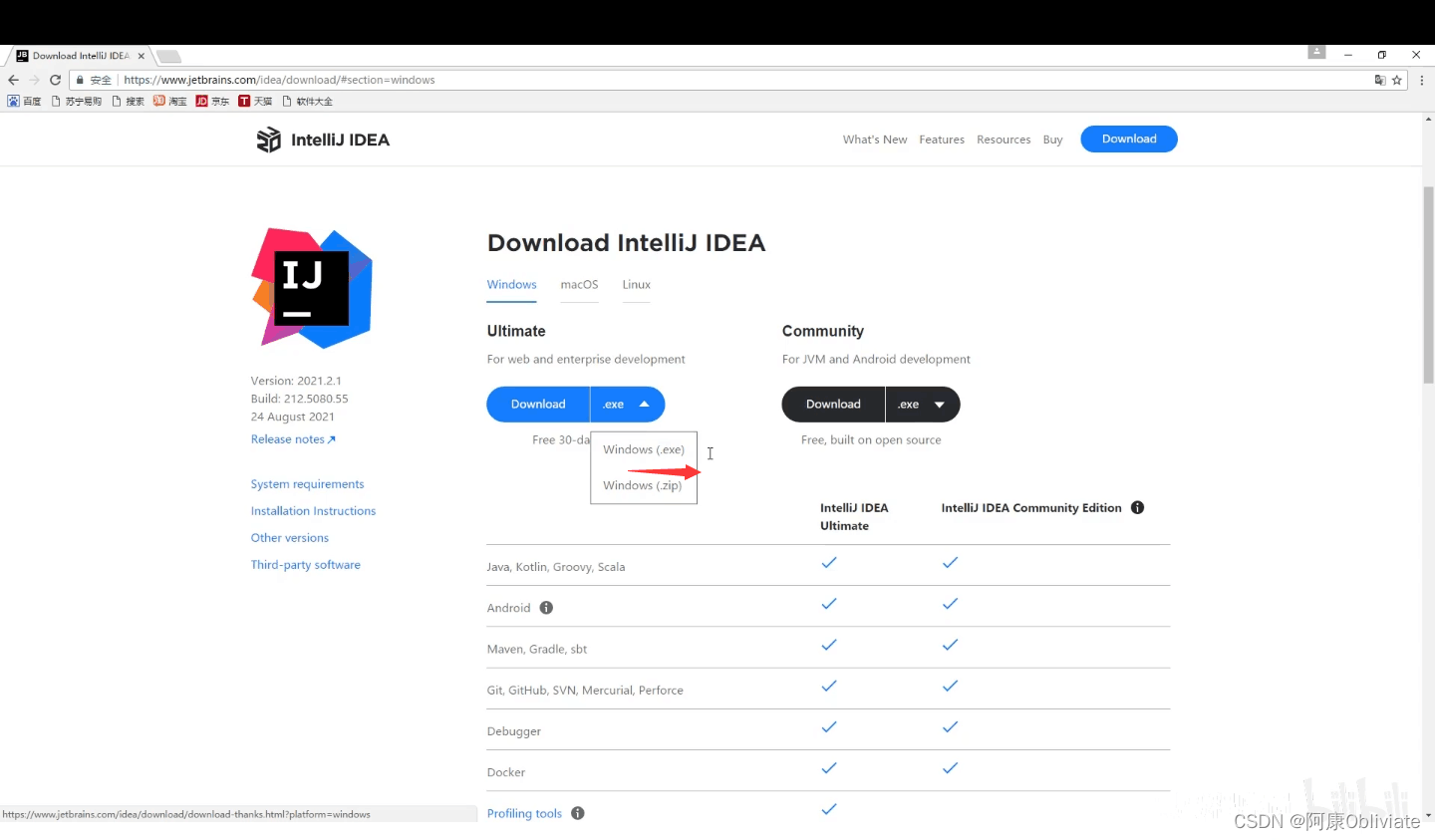
第二章 03Java基础-IDEA相关叙述
文章目录 前言一、IDEA概述二、IDEA下载和安装三、IDEA项目结构介绍四、IDEA的项目和模块操作总结前言 今天我们学习Java基础,IDEA下载以及相关配置和基础使用方法 一、IDEA概述 1.IDEA全称IntelliJ IDEA,是用于Java语言开发的集成工具,是业界公认的目前用于Java程序开发最…...
第三阶段第二章——Python高阶技巧
时间过得很快,这么快就来到了最后一篇Python基础的学习了。话不多说直接进入这最后的学习环节吧!!! 期待有一天 春风得意马蹄疾,一日看尽长安花 o(* ̄︶ ̄*)o 1.闭包 什么是闭包? 答…...

【Git】Git分支与应用分支Git标签与应用标签
一,Git分支 1.1 理解Git分支 在 Git 中,分支是指一个独立的代码线,并且可以在这个分支上添加、修改和删除文件,同时作为另一个独立的代码线存在。一个仓库可以有多个分支,不同的分支可以独立开发不同的功能࿰…...
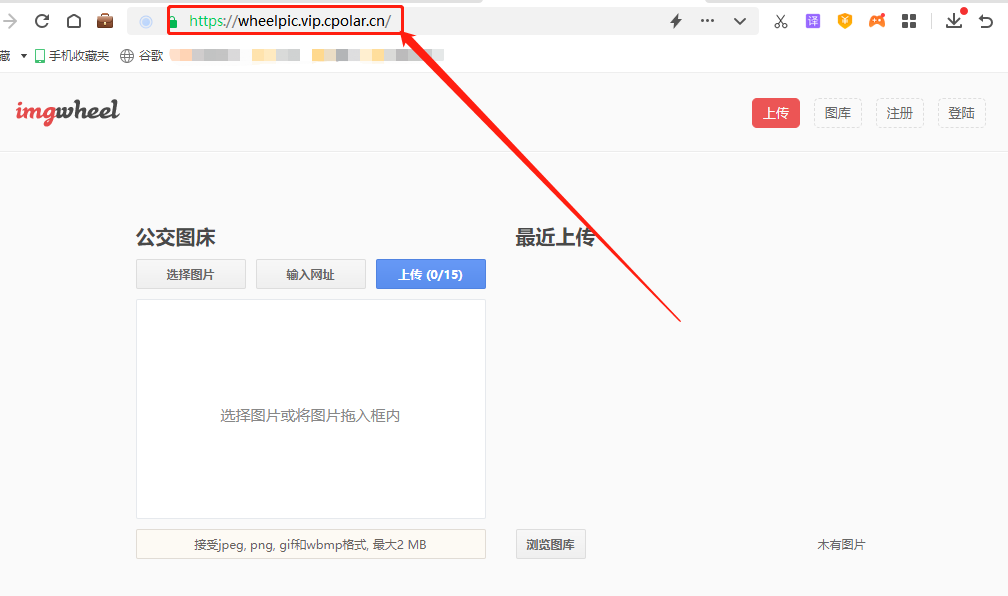
本地PHP搭建简单Imagewheel私人云图床,在外远程访问——“cpolar内网穿透”
文章目录 1.前言2. Imagewheel网站搭建2.1. Imagewheel下载和安装2.2. Imagewheel网页测试2.3.cpolar的安装和注册 3.本地网页发布3.1.Cpolar临时数据隧道3.2.Cpolar稳定隧道(云端设置)3.3.Cpolar稳定隧道(本地设置) 4.公网访问测…...
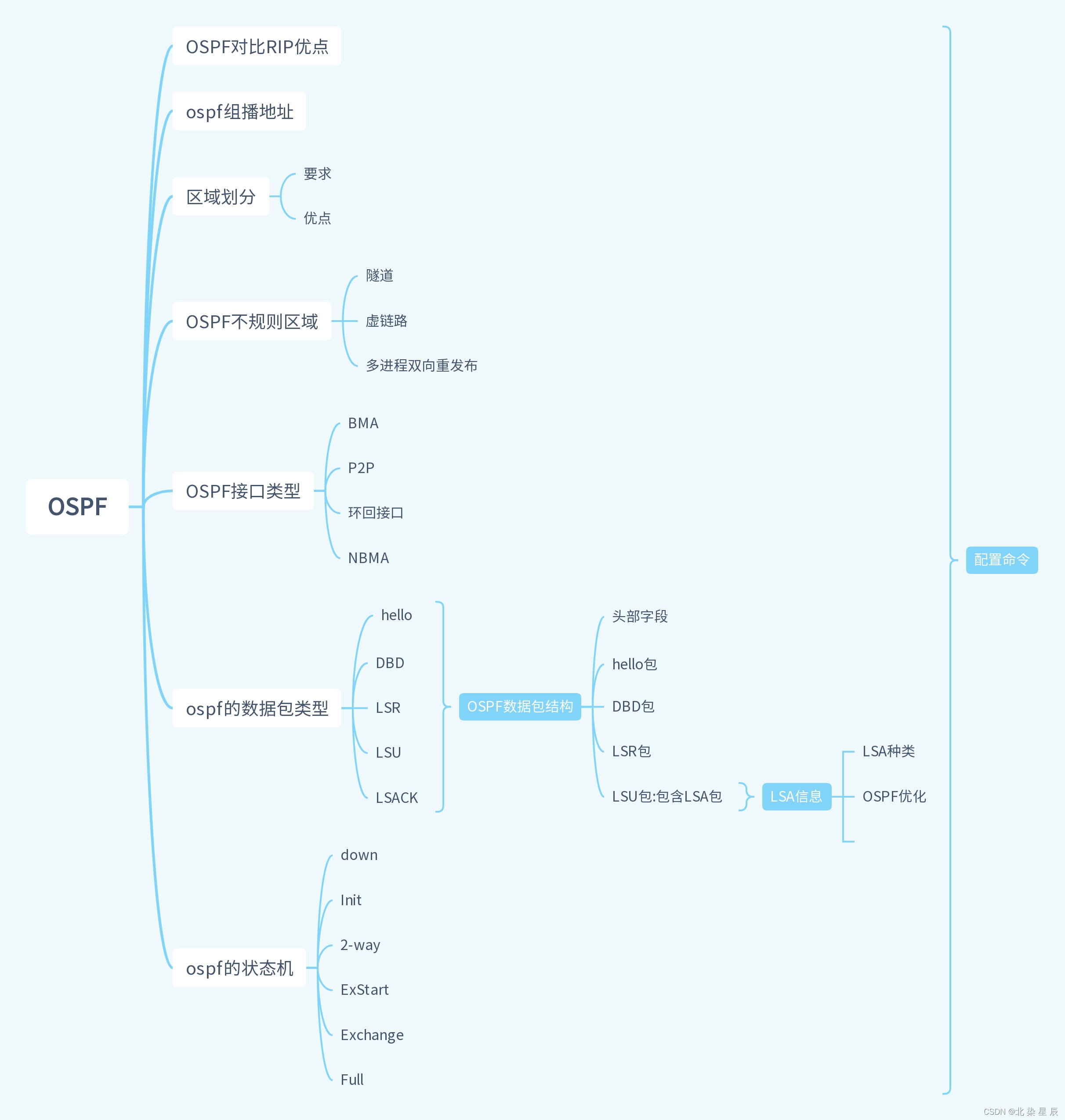
HCIP---OSPF思维导图
...
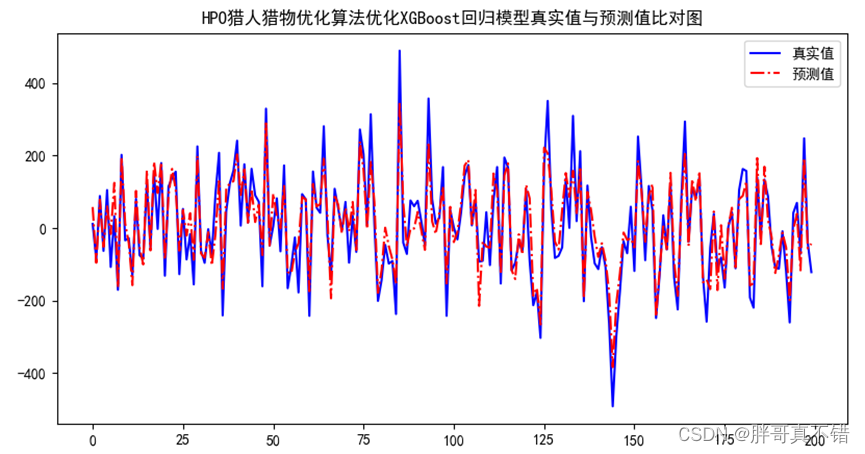
Python实现猎人猎物优化算法(HPO)优化XGBoost回归模型(XGBRegressor算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 猎人猎物优化搜索算法(Hunter–prey optimizer, HPO)是由Naruei& Keynia于2022年提出的一种最新的…...

G-Helper完整指南:华硕笔记本的终极轻量级控制工具
G-Helper完整指南:华硕笔记本的终极轻量级控制工具 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar,…...

C#的LINQ查询表达式编译原理与性能优化
C#的LINQ查询表达式编译原理与性能优化 LINQ(Language Integrated Query)是C#中强大的数据查询工具,它将查询能力直接集成到语言中,使开发者能够以声明式方式操作数据。理解其编译原理与性能优化技巧,对于编写高效代码…...

Hogan.js数据绑定终极指南:5个简单步骤实现动态内容渲染
Hogan.js数据绑定终极指南:5个简单步骤实现动态内容渲染 【免费下载链接】hogan.js A compiler for the Mustache templating language 项目地址: https://gitcode.com/gh_mirrors/ho/hogan.js Hogan.js是一个专为Mustache模板语言设计的编译器,由…...

Qwen3-14B Function Calling功能详解:让AI不仅能说,更能实干
Qwen3-14B Function Calling功能详解:让AI不仅能说,更能实干 你有没有想过,让AI不仅能和你聊天,还能帮你查天气、订机票、甚至处理工作流程?这听起来像是科幻电影里的场景,但现在,通过Qwen3-14…...

HG-ha/MTools性能调优:Windows DirectML最佳实践
HG-ha/MTools性能调优:Windows DirectML最佳实践 本文介绍如何通过DirectML加速技术,让HG-ha/MTools在Windows平台上获得最佳性能表现 1. 认识HG-ha/MTools的强大功能 HG-ha/MTools是一款功能全面的现代化桌面工具集,它集成了图片处理、音视…...

协程设计原理与汇编实现:从原语到网络IO Hook
一、为什么需要协程?在高并发网络编程中,我们面临一个经典矛盾:同步编程简单但性能差,异步编程性能高但代码复杂。协程的出现,正是为了用同步的写法获得异步的性能。1.1 同步与异步的本质同步:串行执行&…...
轻量文本生成实操)
RWKV7-1.5B-g1a开源大模型入门指南:低显存(3.8GB)轻量文本生成实操
RWKV7-1.5B-g1a开源大模型入门指南:低显存(3.8GB)轻量文本生成实操 1. 模型简介 rwkv7-1.5B-g1a 是一款基于RWKV-7架构的开源文本生成模型,专为轻量级应用场景设计。这个1.5B参数的模型在多语言文本生成任务上表现出色ÿ…...

别只盯着server.log了!Kafka Controller日志与GC日志里的“宝藏”与“陷阱”
别只盯着server.log了!Kafka Controller日志与GC日志里的“宝藏”与“陷阱” 当Kafka集群出现Leader选举异常、副本同步缓慢或频繁Full GC时,大多数工程师的第一反应是打开server.log翻找线索。但真正的高手会告诉你:controller.log和GC日志才…...

OpenClaw监控方案:百川2-13B-4bits模型运行状态可视化
OpenClaw监控方案:百川2-13B-4bits模型运行状态可视化 1. 为什么需要监控OpenClaw百川模型组合? 去年冬天的一个深夜,我的OpenClaw自动化任务突然卡死。第二天检查时发现是百川2-13B模型显存溢出导致进程崩溃——这种"事后发现"的…...

linux——退出单一线程
pthread_exitexit(0)函数原型: void pthread‐exit(void *retval); retval指针:必须指向全局,堆 #include<stdio.h> #include<pthread.h> #include<unistd.h> #include<string.h> #include<stdlib.h&…...