YOLO图像识别
YOLO(you only look once),指只需要浏览一次就可以识别出图中的物体的类别和位置。
也因为只需要看一次,YOLO被称为Region-free方法,相比于Region-based方法,YOLO不需要提前找到可能存在目标的Region。
与之相对应的是Region-base方法,,一个典型的Region-base方法流程是:先通过计算机图形学(或者深度学习)的方法,对图片进行分析,找出若干个可能存在物体的区域(first look),将这些区域裁剪下来,放入一个图片分类器中,由分类器分类(second look)。
Region-free方法也被称为单阶段(1-stage)模型,Region-based方法方法也被称为两阶段(2-stage)方法。 Yolo目标检测算法是基于监督学习的,每张图片的监督信息是它所包含的N个物体,每个物体的信息有五个,分别是:物体的中心位置(x,y)、高(h)、宽(w)以及物体类别。
YOLO 的预测是基于整个图片的,并且它会一次性输出所有检测到的目标信息,包括类别和位置。而在YOLO之前的常用算法则是先通过不同尺度大小的窗口在图像上进行滑动,去对一个个物体进行识别;通过设计不同大小的窗口,让这些窗口按照最小的步长滑动,把窗口里的所有图片都放入分类器中一一进行识别。即使是后续的R-CNN通过提前扫描一下图片,得到2000个左右的Region(即窗口)去取代滑窗法中可能得到的几十万个窗口(Region Proposal),并提出Selective Search的算法。
YOLO与前面算法的区别主要在于YOLO通过一次将所有的目标识别出来,而之前的算法是选好区域再进行分类,两次一个是only once,另一个则是select and classificay。
算法原理:
1.YOLO的第一步是分割图片,它将图片分割为a×a个grid,每个grid的大小都是相等。
不同于之前滑窗法让每个框只能识别出一个物体,且要求这个物体必须在这个框之内,YOLO只要求这个物体的中心落在这个框框之中,这边使得算法不用设计非常非常大的框去框住一些占用较多像素块的目标。
2.基于grid生成bounding box
通过让a×a个grid每个都预测出B个bounding box,这个bounding box有5个量(物体的中心位置(x,y)、高(h)、宽(w)以及这次预测的置信度)。
每个grid不仅只预测B个bounding box,它还要负责预测这个框框中的物体是什么类别的,这里的类别用one-hot(即每一个类别对应一个或多个寄存器,通过0/1标识该目标是否属于这个类别,并且每个目标只能有一个类别)编码表示。
注意,虽然一个grid有多个bounding boxes,但是只能识别出一个物体,因此每个grid需要预测物体的类别,而bounding box不需要。
也就是说,如果我们有a×a个框框,每个框框的bounding boxes个数为B,分类器可以识别出C种不同的物体,那么所有整个ground truth的长度为:a×a×(b×5+c)
图文参考知乎答主:Frank Tian
在上面的例子中,图片被分成了49个框,每个框预测2个bounding box,因此上面的图中有98个bounding box。
可以看到大致上每个框里确实有两个bounding box,这些BOX中有的边框比较粗,有的比较细,这是置信度不同的表现,置信度高的比较粗,置信度低的比较细。
bounding box
bounding box可以锁定物体的位置,这要求它输出四个关于位置的值,分别是x,y,h和w。我们在处理输入的图片的时候想让图片的大小任意,这一点对于卷积神经网络来说不算太难,但是,如果输出的位置坐标是一个任意的正实数,模型很可能在大小不同的物体上泛化能力有很大的差异。
这时候当然有一个常见的套路,就是对数据进行归一化,让连续数据的值位于0和1之间。
对于x和y而言,这相对比较容易,毕竟x和y是物体的中心位置,既然物体的中心位置在这个grid之中,那么只要让真实的x除以grid的宽度,让真实的y除以grid的高度就可以了。
但是h和w就不能这么做了,因为一个物体很可能远大于grid的大小,预测物体的高和宽很可能大于bounding box的高和宽,这样w除以bounding box的宽度,h除以bounding box的高度依旧不在0和1之间。
解决方法是让w除以整张图片的宽度,h除以整张图片的高度。
下面的例子是一个448448的图片,有33的grid,展示了计算x,y,w,h的真实值(ground truth)的过程:
图文参考知乎答主:Frank Tian
confidence
confidence的计算公式是:
这个IOU的全称是intersection over union,也就是交并比,它反应了两个框框的相似度。
的意思是预测的bounding box和真实的物体位置的交并比。
Pr(Obj) 是一个grid有物体的概率,在有物体的时候ground truth为1,没有物体的时候ground truth为0.
上述大雁的例子中有9个grid,每个grid有两个bounding box,每个bounding box有5个预测值,假设分类器可以识别出3种物体,那么ground truth的总长度为a×a×(b×5+c)=3×3×(2×5+3)=117
我们假定大雁的类别的one-hot为100,另外两个类别分布用010和001进行标识,并且规定每个grid的ground truth的顺序是confidence, x, y, w, h, c1, c2, c3。
那么第一个(左上角)grid的ground truth应该是:0, ?, ?, ?, ?, ?, ?, ?(这里的"?"的意思是任意值,并不会参与计算损失函数。)
实际上除了最中间的grid以外,其他的grid的ground truth都是这样的。
中间的ground truth应该是:iou, 0.48, 0.28, 0.50, 0.32, 1, 0, 0;
iou要根据x, y, w, h的预测值现场计算。
非极大值抑制(NMS)
在实际情况中,让每个grid找到负责的物体,并把它识别出来了。但是还存在一个问题:如果物体很大,而框框又很小,一个物体被多个框框识别了怎么办? 这里,我们要用到一个基于交并比实现的非极大值抑制Non-maximal suppression(NMS)技术。
例如在上面狗狗的图里,B1,B2,B3,B4这四个框框可能都说狗狗在框里,但是最后的输出应该只有一个框,那怎么把其他框删除呢?
这里就用到了confidence,confidence预测有多大的把握这个物体在我的框里,我们在同样是检测狗狗的框里,也就是B1,B2,B3,B4中,选择confidence最大的,把其余的都删掉,也就是只保留B1.
理论上只用 Pr(obj)也可以选出应该负责识别物体的grid,但是可能会不太精确。这里训练的目标是预测 Pr(obj)*IOU,让本来不应该预测物体的grid的confidence尽可能的小,既然 Pr(obj)的效果不太理想,那我就让 IOU尽可能小。
由于bounding boxes是用中点坐标+宽高表示的,每个grid预测的bounding box都要求其中心在这个grid内,那么如果不是最中间的grid,其他的grid的IOU自然而言就会比较低了,也因此真正的最中间的grid的confidence往往会比较大。
在判断出这几个bounding boxes识别的是同一个物体时,首先判断这几个grid的类别是不是相同的,假设上面的B1,B2,B3和B4识别的都是狗狗,那么进入下一步,保留B1,然后判断B2,B3和B4要不要删除;将B1成为极大bounding box,计算极大bounding box和其他几个bounding box的IOU,如果超过一个阈值,例如0.5,就认为这两个bounding box实际上预测的是同一个物体,就把其中confidence比较小的删除。
最后,结合极大bounding box和grid识别的种类,判断图片中有什么物体,它们分别是什么,它们分别在哪。
confidence有两个功能:一个是用来极大值抑制,另一个就是在最后输出结果的时候,将某个bounding box的confidencd和这个bounding box所属的grid的类别概率相乘,然后输出。
举个例子,比如某个grid中的某个bounding box预测到了一个物体,将这个bounding box送入神经网络(其实是整张图片一起送进去的,我们这样说是为了方便),然后神经网络对bounding box说,这里有一个物体的概率是0.8.然后神经网络又对grid说,你这个grid里物体最可能是狗,概率是0.7。 那最后这里是狗的概率就是 0.8×0.7=0.56 。
YoloV8模型结构
YOLOv3之前的所有YOLO对象检测模型都是用C语言编写的,并使用了Darknet框架,Ultralytics发布了第一个使用PyTorch框架实现的YOLO (YOLOv3);YOLOv3之后,Ultralytics发布了YOLOv5,在2023年1月,Ultralytics发布了YOLOv8,包含五个模型,用于检测、分割和分类。 YOLOv8 Nano是其中最快和最小的,而YOLOv8 Extra Large (YOLOv8x)是其中最准确但最慢的,具体模型见后续的图。
YOLOv8附带以下预训练模型:
目标检测在图像分辨率为640的COCO检测数据集上进行训练。
实例分割在图像分辨率为640的COCO分割数据集上训练。
图像分类模型在ImageNet数据集上预训练,图像分辨率为224。
YOLOv8 概述
具体到 YOLOv8 算法,其核心特性和改动可以归结为如下:
提供了一个全新的SOTA模型(state-of-the-art model),包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于YOLACT的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是一套参数应用所有模型,大幅提升了模型性能。
Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从Anchor-Based 换成了 Anchor-Free
Loss 计算方面采用了TaskAlignedAssigner正样本分配策略,并引入了Distribution Focal Loss
训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
骨干网络和 Neck
骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是一套参数应用所有模型,大幅提升了模型性能。 具体改动为:
第一个卷积层的 kernel 从 6x6 变成了 3x3
所有的 C3 模块换成 C2f,可以发现多了更多的跳层连接和额外的 Split 操作
去掉了 Neck 模块中的 2 个卷积连接层
Backbone 中 C2f 的block 数从 3-6-9-3 改成了 3-6-6-3
查看 N/S/M/L/X 等不同大小模型,可以发现 N/S 和 L/X 两组模型只是改了缩放系数,但是 S/M/L 等骨干网络的通道数设置不一样,没有遵循同一套缩放系数。如此设计的原因应该是同一套缩放系数下的通道设置不是最优设计,YOLOv7 网络设计时也没有遵循一套缩放系数作用于所有模型
C3模块
针对C3模块,其主要是借助CSPNet提取分流的思想,同时结合残差结构的思想,设计了所谓的C3 Block,这里的CSP主分支梯度模块为BottleNeck模块,也就是所谓的残差模块。同时堆叠的个数由参数n来进行控制,也就是说不同规模的模型,n的值是有变化的。
其实这里的梯度流主分支,可以是任何之前的模块,比如,美团提出的YOLOv6中就是用来重参模块。
RepVGGBlock来替换BottleNeck Block来作为主要的梯度流分支,而百度提出的PP-YOLOE则是使用了RepResNet-Block来替换BottleNeck Block来作为主要的梯度流分支。而YOLOv7则是使用了ELAN Block来替换BottleNeck Block来作为主要的梯度流分支。
C3模块和名字思路一致,在模块中使用了3个卷积模块(Conv+BN+SiLU),以及n个BottleNeck。
通过C3代码可以看出,对于cv1卷积和cv2卷积的通道数是一致的,而cv3的输入通道数是前者的2倍,因为cv3的输入是由主梯度流分支(BottleNeck分支)依旧次梯度流分支(CBS,cv2分支)cat得到的,因此是2倍的通道数,而输出则是一样的。
C2f模块
C2f模块就是参考了C3模块以及ELAN的思想进行的设计,让YOLOv8可以在保证轻量化的同时获得更加丰富的梯度流信息。
SPPF
SPP(Spatial Pyramid Pooling) SPP全称为空间金字塔池化结构,主要是为了解决两个问题:
有效避免了对图像区域裁剪、缩放操作导致的图像失真等问题;
解决了卷积神经网络对图相关重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
SPPF(Spatial Pyramid Pooling - Fast)
这个是YOLOv5作者Glenn Jocher基于SPP提出的,速度较SPP快很多,所以叫SPP-Fast
左边是SPP,右边是SPPF。
Head 部分
Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。 YOLOv5 Head 结构如下所示:
YOLOv8 Head 结构:
不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法。
损失函数
Loss 计算过程包括 2 个部分: 正负样本分配策略和 Loss 计算。 现代目标检测器大部分都会聚焦在正负样本分配策略上,典型的如 YOLOX 的 simOTA、TOOD 的 TaskAlignedAssigner 和 RTMDet 的 DynamicSoftLabelAssigner,这类 Assigner 大都是动态分配策略,而 YOLOv5 采用的依然是静态分配策略。考虑到动态分配策略的优异性,YOLOv8 算法中则直接引用了 TOOD 的 TaskAlignedAssigner。
TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
s 是标注类别对应的预测分值,u 是预测框和 gt 框的 iou,两者相乘就可以衡量对齐程度。
对于每一个 GT,对所有的预测框基于 GT 类别对应分类分数,预测框与 GT 的 IoU 的加权得到一个关联分类以及回归的对齐分数 alignment_metrics
对于每一个 GT,直接基于 alignment_metrics 对齐分数选取 topK 大的作为正样本
Loss 计算包括 2 个分支: 分类和回归分支,没有了之前的 objectness 分支。
分类分支依然采用 BCE Loss
回归分支需要和 Distribution Focal Loss 中提出的积分形式表示法绑定,因此使用了 Distribution Focal Loss, 同时还使用了 CIoU Loss
3 个 Loss 采用一定权重比例加权即可。
Mosaic增强
深度学习研究往往侧重于模型架构,但YOLOv5和YOLOv8中的训练过程是它们成功的重要组成部分。 YOLOv8在在线训练中增强图像。在每个轮次,模型看到的图像变化略有不同。 Mosaic增强,将四张图像拼接在一起,迫使模型学习新位置,部分遮挡和不同周围像素的对象。
相关文章:

YOLO图像识别
YOLO(you only look once),指只需要浏览一次就可以识别出图中的物体的类别和位置。 也因为只需要看一次,YOLO被称为Region-free方法,相比于Region-based方法,YOLO不需要提前找到可能存在目标的Region。 与…...
2023NewStarCTF
目录 一、阳光开朗大男孩 二、大怨种 三、2-分析 四、键盘侠 五、滴滴滴 六、Include? 七、medium_sql 八、POP Gadget 九、OtenkiGirl 一、阳光开朗大男孩 1.题目给出了secret.txt和flag.txt两个文件,secret.txt内容如下: 法治自由公正爱国…...

计算机网络的发展及应用
计算机网络是计算机技术和通信技术高度发展并相互结合的产物。一方面,通信系统为计算机之间的数据传送提供最重要的支持;另一方面,由于计算机技术渗透到了通信领域,极大地提高了通信网络的性能。计算机网络的诞生和发展࿰…...
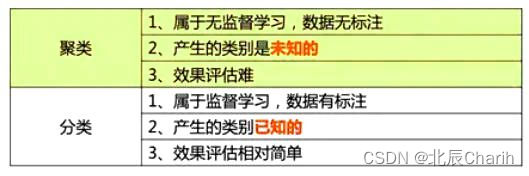
K-means(K-均值)算法
K-means(k-均值,也记为kmeans)是聚类算法中的一种,由于其原理简单,可解释强,实现方便,收敛速度快,在数据挖掘、聚类分析、数据聚类、模式识别、金融风控、数据科学、智能营销和数据运…...

网络安全自学
前言 一、什么是网络安全 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 无论网络、Web、移动、桌面、云等哪个领域,都有攻与防…...
加速mvn下载seatunnel相关jar包
seatunnel安装的时候,居然要使用mvnw来下载jar包,而且是从https://repo.maven.apache.org 下载,速度及其缓慢,改用自己本地的mvn下载。 修改其安装插件相关脚本,复制install-plugin.sh重命名为install-plugin-mvn.sh …...
:用于计算非支配(non-dominated)前沿)
【函数讲解】botorch中的函数 is_non_dominated():用于计算非支配(non-dominated)前沿
# 获取训练目标值,计算Pareto前沿(非支配解集合),然后从样本中提取出Pareto最优解。train_obj self.samples[1]pareto_mask is_non_dominated(train_obj)pareto_y train_obj[pareto_mask] 源码 这里用到了一个函数 is_non_dom…...
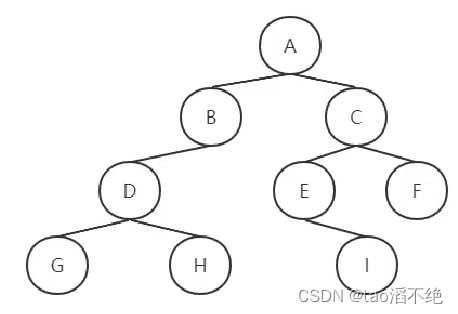
LeetCode题94,44,145,二叉树的前中后序遍历,非递归
注意:解题都要用到栈 一、前序遍历 题目要求 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 示例 1: 输入:root [1,null,2,3] 输出:[1,2,3]示例 2: 输入:root [] 输出:[…...
Python 框架学习 Django篇 (九) 产品发布、服务部署
我们前面编写的所有代码都是在windows上面运行的,因为我们还处于开发阶段 当我们完成具体任务开发后,就需要把我们开发的网站服务发布给真正的用户 通常来说我们会选择一台公有云服务器比如阿里云ecs,现在的web服务通常都是基于liunx操作系统…...

Git 服务器上的 LFS 下载
以llama为例: https://huggingface.co/meta-llama/Llama-2-7b-hf Github # 1. 安装完成后,首先先初始化;如果有反馈,一般表示初始化成功 git lfs install # 2. 如果刚刚下载的那个项目没啥更改,重新下一遍&#x…...

Canvas和SVG:你应该选择哪一个?
如果你是一个Web开发者,你可能已经听说过Canvas和SVG。这两种技术都可以用来创建图形和动画,但它们有什么区别?在这篇文章中,我们将探讨Canvas和SVG的区别以及它们的应用场景,帮助你决定哪种技术更适合你的项目。 什么…...

openGauss学习笔记-122 openGauss 数据库管理-设置密态等值查询-密态支持函数/存储过程
文章目录 openGauss学习笔记-122 openGauss 数据库管理-设置密态等值查询-密态支持函数/存储过程122.1 创建并执行涉及加密列的函数/存储过程 openGauss学习笔记-122 openGauss 数据库管理-设置密态等值查询-密态支持函数/存储过程 密态支持函数/存储过程当前版本只支持sql和P…...

BEVFormer 论文阅读
论文链接 BEVFormer BEVFormer,这是一个将Transformer和时间结构应用于自动驾驶的范式,用于从多相机输入中生成鸟瞰(BEV)特征利用查询来查找空间/时间,并相应地聚合时空信息,从而为感知任务提供更强的表示…...
Centos批量删除系统重复进程
原创作者:运维工程师 谢晋 Centos批量删除系统重复进程 客户一台CENTOS 7系统负载高,top查看有很多sh的进程,输入命令top -c查看可以看到对应的进程命令是/bin/bash 经分析后发现是因为该脚本执行时间太长,导致后续执…...
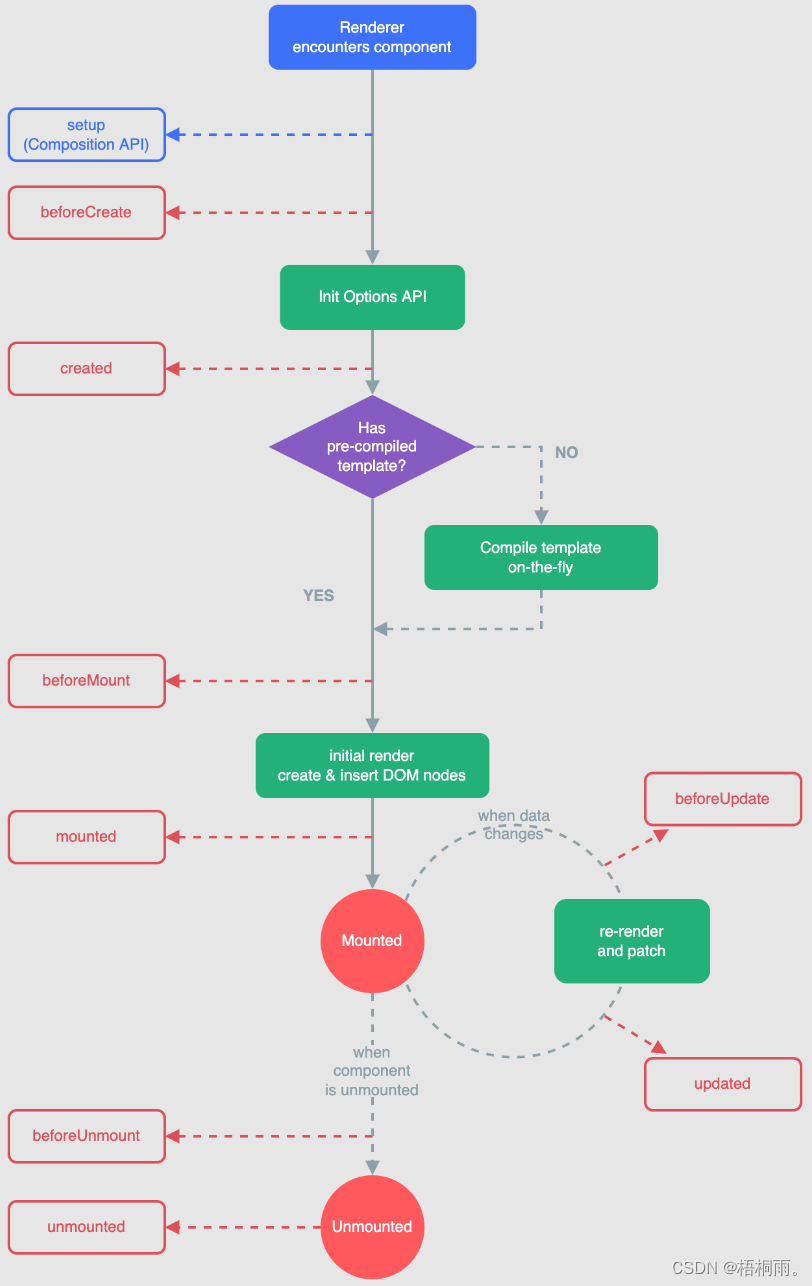
VUE组件的生命周期
每个 Vue 组件实例在创建时都需要经历一系列的初始化步骤,比如设置好数据侦听,编译模板,挂载实例到 DOM,以及在数据改变时更新 DOM。在此过程中,它也会运行被称为生命周期钩子的函数,让开发者有机会在特定阶…...

【Git系列】Github指令搜索
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

【OpenCV】用数组给Mat图像赋值,单/双/三通道 Mat赋值
文章目录 5 Mat赋值5.1 Mat(int rows, int cols, int type, const Scalar& s)5.2 数组赋值 或直接赋值5.2.1 3*3 单通道 img5.2.2 3*3 双通道 img5.2.3 3*3 三通道 img5 Mat赋值 5.1 Mat(int rows, int cols, int type, const Scalar& s) Mat m(3, 3, CV_8UC3,Scalar…...
Doris:读取Doris数据的N种方法
目录 1.MySQL Client 2.JDBC 3. 查询计划 4.Spark Doris Connector 5.Flink Doris Connector 1.MySQL Client Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL,用户可以通过各类客户端工具来访问 Doris。登录到doris服务器后&a…...

ceph-deploy bclinux aarch64 ceph 14.2.10
ssh-copy-id,部署机免密登录其他三台主机 所有机器硬盘配置参考如下,计划采用vdb作为ceph数据盘 下载ceph-deploy pip install ceph-deploy 免密登录设置主机名 hostnamectl --static set-hostname ceph-0 .. 3 配置hosts 172.17.163.105 ceph-0 172.…...
:使用lxml抓取相亲信息)
爬虫项目(13):使用lxml抓取相亲信息
文章目录 书籍推荐完整代码效果书籍推荐 如果你对Python网络爬虫感兴趣,强烈推荐你阅读《Python网络爬虫入门到实战》。这本书详细介绍了Python网络爬虫的基础知识和高级技巧,是每位爬虫开发者的必读之作。详细介绍见👉: 《Python网络爬虫入门到实战》 书籍介绍 完整代码…...

Qwen3-4B-Instruct镜像免配置:一键拉起暗黑WebUI实操指南
Qwen3-4B-Instruct镜像免配置:一键拉起暗黑WebUI实操指南 无需复杂配置,无需GPU设备,5分钟拥有自己的AI写作大师 1. 为什么选择这个镜像? 如果你正在寻找一个既强大又容易上手的AI写作助手,这个Qwen3-4B-Instruct镜像…...

3种多平台直播效率提升方案:obs-multi-rtmp插件技术实践指南
3种多平台直播效率提升方案:obs-multi-rtmp插件技术实践指南 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 核心摘要 多平台直播已成为内容创作者扩大影响力的必要手段&am…...

AI术语大白话:一张表让你从“小白“变“懂王“
看完这篇,下次开会再也不怕听不懂同事说的"黑话"了。为什么你需要了解这些?现如今,AI已经无处不在,想象一下这个场景:老板:"这个需求用RAGFine-tuning实现,Prompt要优化一下&…...

如何快速配置Obsidian个性化首页:从零开始的完整指南
如何快速配置Obsidian个性化首页:从零开始的完整指南 【免费下载链接】obsidian-homepage Obsidian homepage - Minimal and aesthetic template (with my unique features) 项目地址: https://gitcode.com/gh_mirrors/obs/obsidian-homepage 你是否每天打开…...

告别繁琐手动配置,用快马ai一键生成keil5安装与stm32工程初始化脚本
作为一名嵌入式开发爱好者,我深知Keil5安装和STM32开发环境配置的繁琐。每次换电脑或重装系统,都要重复一堆步骤,特别浪费时间。最近发现InsCode(快马)平台可以智能生成这类环境配置脚本,简直打开了新世界的大门。 环境检测自动化…...

局域网聊天室终极解决方案:无需互联网的即时通讯工具
局域网聊天室终极解决方案:无需互联网的即时通讯工具 【免费下载链接】LAN-Chat-Room 😉基于QT开发的局域网聊天室 项目地址: https://gitcode.com/gh_mirrors/la/LAN-Chat-Room 在办公室、学校或家庭网络中,你是否曾遇到过需要快速分…...
)
电路分析不求人:手把手教你用戴维南定理搞定复杂电路(附Multisim仿真验证)
电路分析实战:用戴维南定理拆解复杂电路的全流程指南 当你面对一个布满电阻、电源和交叉连线的复杂电路图时,是否感到无从下手?戴维南定理就像一把瑞士军刀,能将这些看似棘手的电路简化为一个电压源和一个电阻的串联组合。但理论归…...

凸优化问题中严格凸函数与最优解唯一性的关系
1. 为什么我们需要严格凸函数? 在优化问题中,我们常常会遇到多个局部最优解的情况,这就像在山地徒步时发现多个山谷,每个山谷看起来都很深,但只有一个是真正的最低点。严格凸函数就像是一个设计精良的漏斗,…...

Vue-Touch实战案例:构建支持多点触控的图片查看器
Vue-Touch实战案例:构建支持多点触控的图片查看器 【免费下载链接】vue-touch Hammer.js wrapper for Vue.js 项目地址: https://gitcode.com/gh_mirrors/vu/vue-touch 想要为你的Vue.js应用添加流畅的多点触控交互体验吗?Vue-Touch插件正是你需要…...

释放AI潜能:在快马平台利用多模型协作构建高级任务规划Agent
今天想和大家分享一个特别有意思的实践:如何利用InsCode(快马)平台的多AI模型协作能力,快速搭建一个能处理复杂任务的智能规划Agent。这个项目特别适合想体验AI辅助开发的朋友,整个过程不需要复杂的环境配置,直接在网页上就能完成…...