基于海鸥算法改进的DELM分类-附代码
海鸥算法改进的深度极限学习机DELM的分类
文章目录
- 海鸥算法改进的深度极限学习机DELM的分类
- 1.ELM原理
- 2.深度极限学习机(DELM)原理
- 3.海鸥算法
- 4.海鸥算法改进DELM
- 5.实验结果
- 6.参考文献
- 7.Matlab代码
1.ELM原理
ELM基础原理请参考:https://blog.csdn.net/u011835903/article/details/111073635。
自动编码器 AE(Auto Encoder)经过训练可以将输入复制到输出。因为不需要标记数据,训练自动编码器是不受监督的。因此,将AE的思想应用到ELM中,使ELM的输入数据同样被用于输出,即输出Y=X。作为自编码器的极限学习机ELM-AE网络结构如图1所示。

图1.ELM-AE网络结构图
若图1中m>L ,ELM-AE实现维度压缩,将高维度数据映射成低维度特征表达;若 m=L,ELM-AE实现等维度的特征表达;若 m<L ,ELM-AE实现稀疏表达,即原始数据的高维特征表达。
综上,ELM-AE是一个通用的逼近器,特点就是使网络的输出与输入相同,而且隐藏层的输入参数(ai,bi)(a_i,b_i)(ai,bi)随机生成后正交。正交化后的优点有:
(1)根 据 J-L(Johnson-Lindensrauss) 定理,权重和偏置正交化可以将输入数据映射到不同或等维度的空间,从而实现不同功能的特征表达。
(2)权重和偏置的正交化设计可以去除特征以外的噪声,使特征之间均匀,且更加线性独立进而增强系统的泛化能力。
ELM-AE的输出可以用如下表达式表示:
xj=∑i=1LβiG(ai,bi,xj),ai∈Rm,βi∈Rm,j=1,2,...,N,aTa=I,bTb=1(1)x_j=\sum_{i=1}^L \beta_iG(a_i,b_i,x_j),a_i\in R^m,\beta_i\in R^m,j=1,2,...,N,a^Ta=I,b^Tb=1 \tag{1} xj=i=1∑LβiG(ai,bi,xj),ai∈Rm,βi∈Rm,j=1,2,...,N,aTa=I,bTb=1(1)
其中aaa是aia_iai组成的矩阵,bbb是bib_ibi组成的向量。隐藏层的输出权重为:
β=(IC+HTH)−1HTX(2)\beta = (\frac{I}{C}+H^TH)^{-1}HTX \tag{2} β=(CI+HTH)−1HTX(2)
其中,X=[x1,...,xN]X=[x_1,...,x_N]X=[x1,...,xN]是输入数据。
2.深度极限学习机(DELM)原理
根据ELM-AE的特征表示能力,将它作为深度极限学习机 DELM的基本单元。与传统深度学习算法相同,DELM 也是用逐层贪婪的训练方法来训练网络,DELM每个隐藏层的输入权重都使用ELM-AE初始化,执行分层无监督训练,但是与传统深度学习算法不同的是DELM不需要反向微调过程。

DELM的思想是通过最大限度地降低重构误差使输出可以无限接近原始输入,经过每一层的训练,可以学习到原始数据的高级特征。图2描述了DELM模型的训练过程,将输入数据样本X作为第1个ELM-AE的目标输出(X1=XX_1 =XX1=X),进而求取输出权值 β1β_1β1 ;然后将DELM第1个隐藏层的输出矩阵H1H_1H1当作下1个ELM−AEELM-AEELM−AE的输入与目标输出(X2=XX_2=XX2=X),依次类推逐层训练,最后1层用ELMELMELM来训练,使用式(2)来求解DELM的最后1个隐藏层的输出权重βi+1\beta_{i+1}βi+1 。图2中Hi+1H_{i+1}Hi+1 是最后1个隐藏层的输出矩阵,T是样本标签。 Hi+1H_{i+1}Hi+1每1层隐藏层的输入权重矩阵为Wi+1=βi+1TW_{i+1}=\beta_{i+1}^TWi+1=βi+1T。
3.海鸥算法
海鸥搜索算法的具体原理参考博客:https://blog.csdn.net/u011835903/article/details/107535864
4.海鸥算法改进DELM
由上述原理可知原始DELM中的,权重采用随机初始化的方式进行初始化,而初始权重对于整个模型的预测结果影响比较大,于是采用海鸥算法对DELM的初始权重进行优化。适应度函数设计如下:
fitness=2−Accuracy(train)−Accuracy(test)fitness=2-Accuracy(train)-Accuracy(test) fitness=2−Accuracy(train)−Accuracy(test)
适应度函数为,训练集和测试集(验证集)的分类错误率,分类错误率越低,代表分类正确率越高。
5.实验结果
本文对乳腺肿瘤数据进行分类。采用随机法产生训练集和测试集,其中训练集包含 500 个样本,测试集包含 69 个样本 。
%% 导入数据
load data.mat
% 产生训练集/测试集
a = 1:569;
Train = data(a(1:500),:);
Test = data(a(501:end),:);
% 训练数据
P_train = Train(:,3:end);
T_train = Train(:,2);
% 测试数据
P_test = Test(:,3:end);
T_test = Test(:,2);
DELM的参数设置如下:
这里DELM采用1层结构,每层的节点数分别为32。采用sigmoid激活函数。
%% DELM参数设置
ELMAEhiddenLayer = [32];%ELM—AE的隐藏层数,[n1,n2,...,n],n1代表第1个隐藏层的节点数。
ActivF = 'sig';%ELM-AE的激活函数设置
C = inf; %正则化系数
海鸥算法的相关参数设置如下:
%% 优化算法参数设置:
%计算权值的维度
dim=0;
for i = 1:length(ELMAEhiddenLayer)dim = dim+ ELMAEhiddenLayer(i)*size(P_train,2);
end
popsize = 20;%种群数量
Max_iteration = 50;%最大迭代次数
lb = -1;%权值下边界
ub = 1;%权值上边界
fobj = @(X)fun(X,P_train,T_train,P_test,T_test,ELMAEhiddenLayer,ActivF,C);
[Best_pos,Best_score,SSA_cg_curve]=SSA(popsize,Max_iteration,lb,ub,dim,fobj);
最终预测结果如下:


从结果来看,无论训练集还是测试集优化后的结果,均更优。
6.参考文献
[1]颜学龙,马润平.基于深度极限学习机的模拟电路故障诊断[J].计算机工程与科学,2019,41(11):1911-1918.
7.Matlab代码
相关文章:
基于海鸥算法改进的DELM分类-附代码
海鸥算法改进的深度极限学习机DELM的分类 文章目录海鸥算法改进的深度极限学习机DELM的分类1.ELM原理2.深度极限学习机(DELM)原理3.海鸥算法4.海鸥算法改进DELM5.实验结果6.参考文献7.Matlab代码1.ELM原理 ELM基础原理请参考:https://blog.c…...

linux基本功系列之mount命令实战
文章目录前言一. mount命令的介绍二. 语法格式及常用选项三. 参考案例3.1 将iso镜像挂载到/mnt上3.2 把某个分区挂载到/sdb1上3.3 用只读的形式把/dev/sdb2挂载到/sdb2上3.4 设置自动挂载总结前言 大家好,又见面了,我是沐风晓月,本文是专栏【…...
力扣Top100题之两数相加(Java解法)
0 题目描述 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字 0 之外,这两个数…...
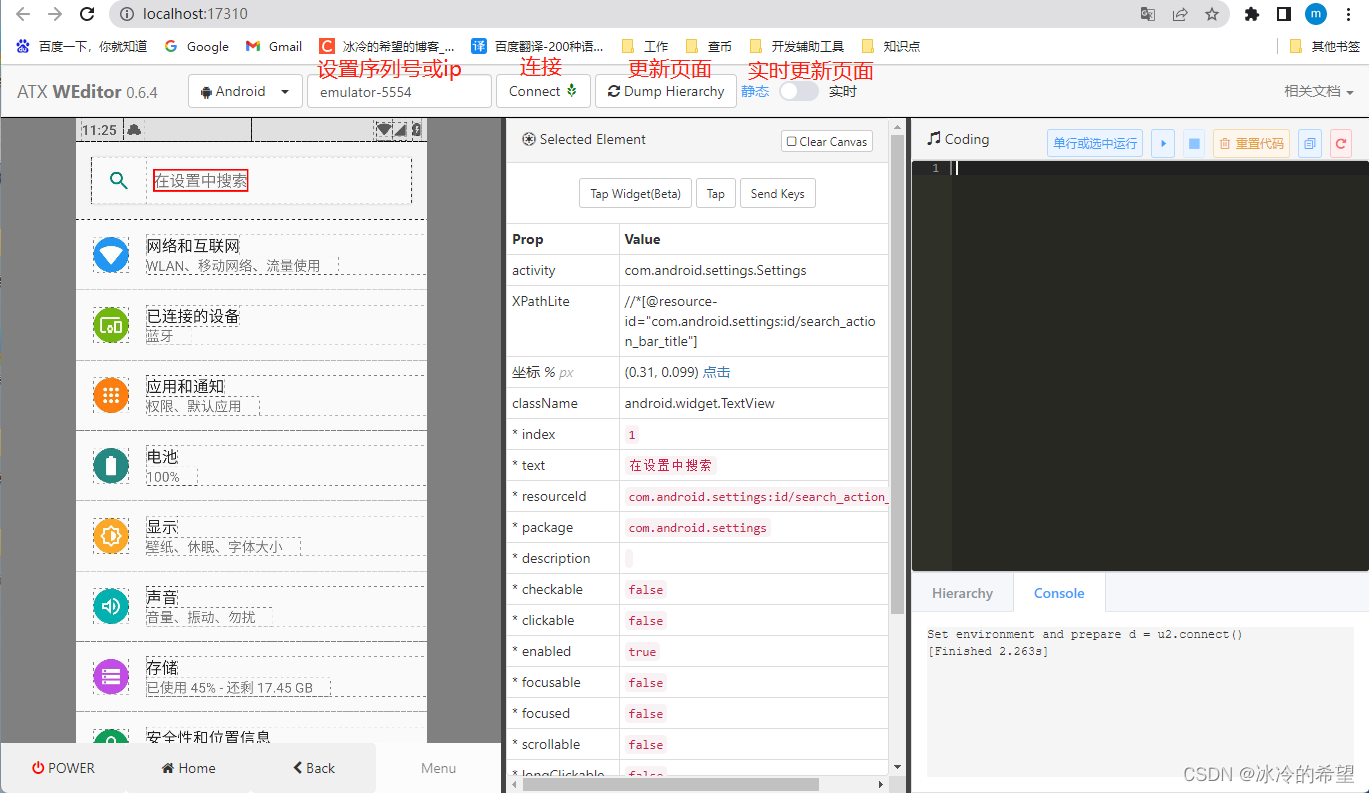
【测试】Python手机自动化测试库uiautomator2和weditor的详细使用
1.说明 我们之前在电脑操作手机进行自动化测试,基本上都是通过Appium的,这个工具确实强大,搭配谷歌官方的UiAutomator基本上可以完成各种测试,但缺点也很明显,配置环境太麻烦了,需要jdk、sdk等,…...

《NFL橄榄球》:旧金山49人·橄榄1号位
旧金山四九人(San Francisco 49ers,又译旧金山淘金者) 是美国全国橄榄球联盟球队。成立于1946年,最初作为全美橄榄球联合会(AAFC)的一员参加比赛,后于1950年与克利夫兰布朗一同加入由美国橄榄球联合会合并而成的NFL。现任主教练为…...
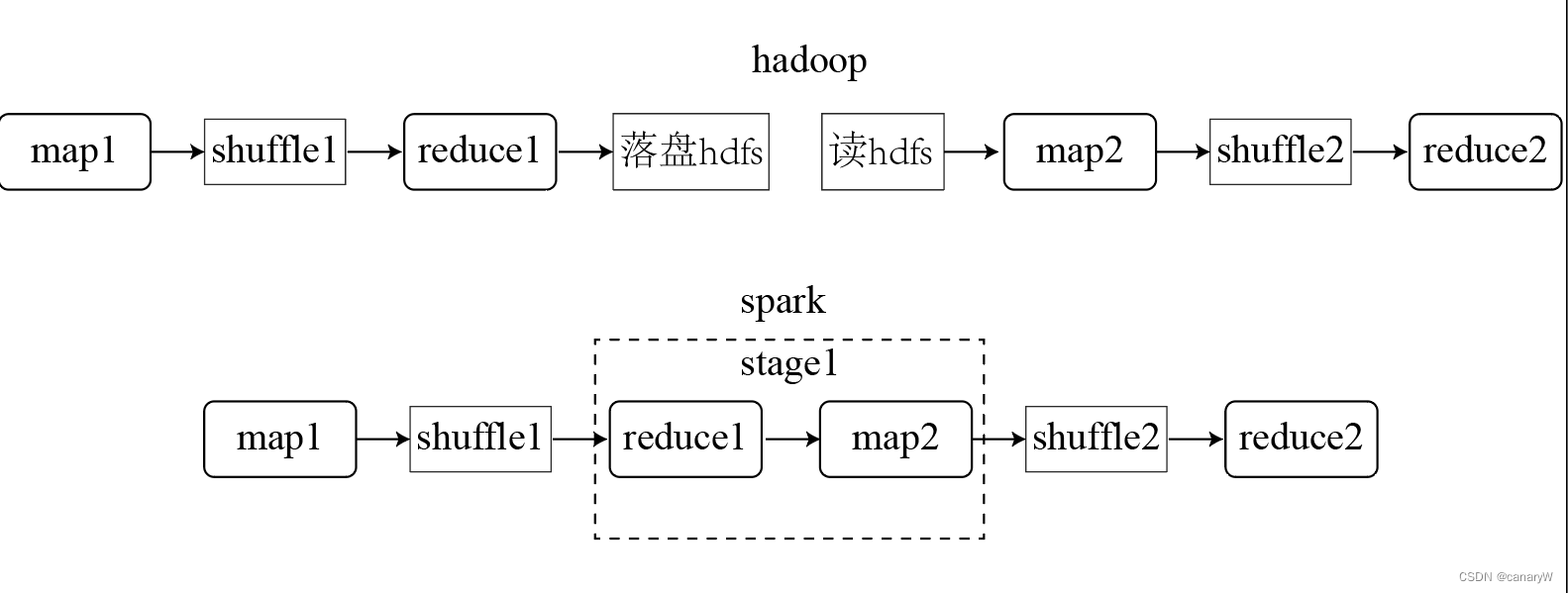
spark为什么比hadoop快
网上一堆人根本对计算框架一知半解就出来糊弄人,常见解答有: spark是基于内存计算,所以快。这跟废话似的,mr计算的时候不也是基于内存? mr shuffle落盘。这也是胡扯, spark shuffle不落盘? 实际…...

跨境人都在用的指纹浏览器到底有什么魔力?三分钟带你了解透彻
什么是指纹浏览器?这是东哥近期收到最多的粉丝私信咨询,指纹两个字大家都很熟悉,指纹浏览器就变得陌生起来。之前东哥也跟大家分享过很多次指纹浏览器的用法,鉴于还是很多人不认识这个好用的工具,东哥今天就来详细给大…...
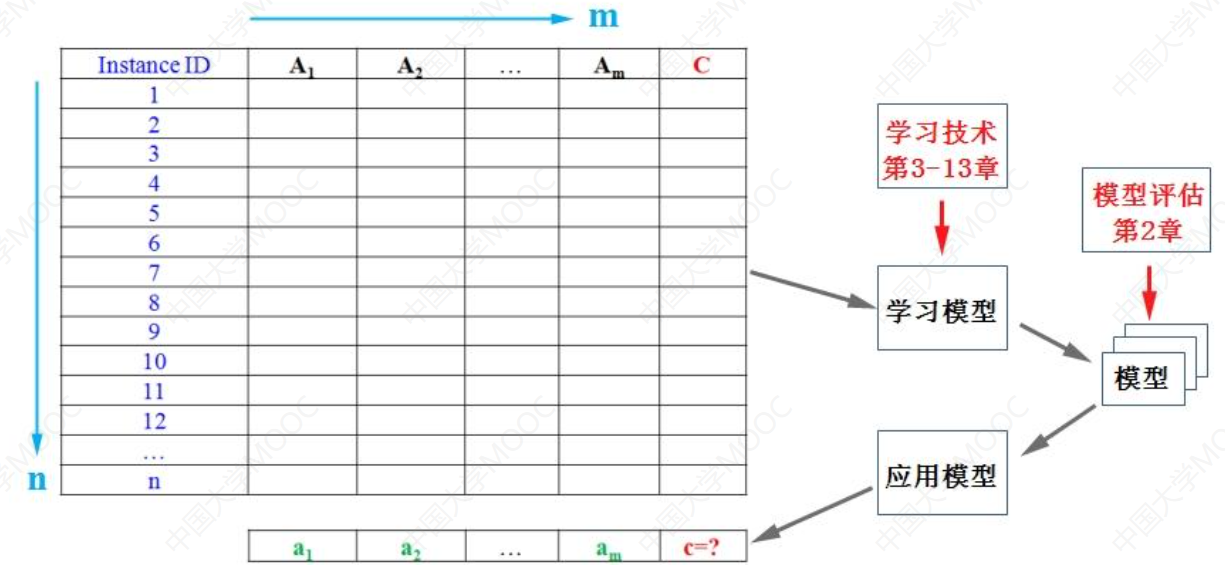
机器学习概述
机器学习是人工智能的核心研究领域之一,其研究动机是为了让计算机系统具有人的学习能力以便实现人工智能。目前被广泛采用的机器学习的定义是“利用经验来改善计算机系统自身的性能”。由于“经验在计算机系统中主要是以数据的形式存在的,因此机器学习需…...
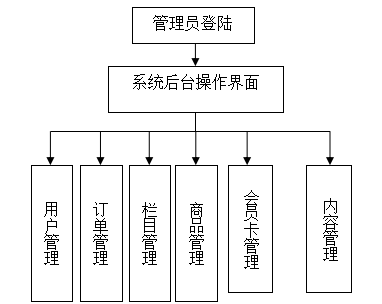
企业网站自动生成系统的设计和实现
技术:Java、JSP等摘要:随着Internet技术的发展,人们的日常生活已经离不开网络。未来社会人们的生活和工作将越来越依赖于数字技术的发展,越来越数字化、网络化、电子化、虚拟化。Internet的发展历程以及目前的应用状况和发展趋势&…...

sikuli+eclipse对于安卓app自动化测试的应用
Sikuli是什么? 下面是来自于官网的介绍:Sikuli is a visual technology to automate and test graphical user interfaces (GUI) using images (screenshots). Sikuli includes Sikuli Script, a visual scripting API for Jython, and Sikuli IDE, an …...
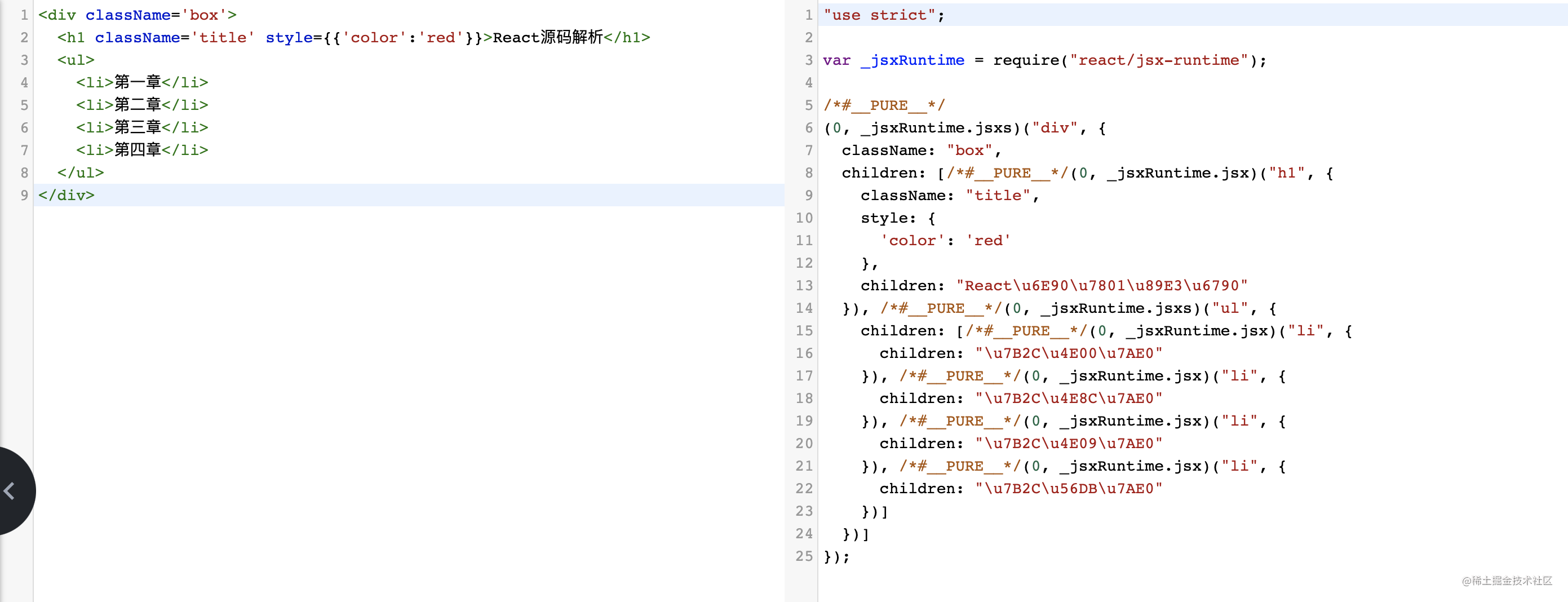
react源码分析:babel如何解析jsx
同作为MVVM框架,React相比于Vue来讲,上手更需要JavaScript功底深厚一些,本系列将阅读React相关源码,从jsx -> VDom -> RDOM等一些列的过程,将会在本系列中一一讲解 工欲善其事,必先利其器 经过多年的…...

搜广推 WideDeep 与 DeepCrossNetwork (DCN) - 记忆+泛化共存
😄 这节来讲讲Wide&Deep与Deep&CrossNetwork (DCN)。从下图可看出WD非常重要,后面衍生出了一堆WD的变体。本节要讲的WD和DCN结构都非常简单,但其设计思想值得学习。 🚀 wide&deep:2016年,谷歌提出。 🚀 Deep&CrossNetwork (DCN):2017年,谷歌和斯坦…...
项目管理工具dhtmlxGantt甘特图入门教程(十四):导出/导入 Excel到 iCal
这篇文章给大家讲解利用dhtmlxgantt导入/导出Excel到iCal的操作方法。 dhtmlxGantt是用于跨浏览器和跨平台应用程序的功能齐全的Gantt图表,可满足应用程序的所有需求,是完善的甘特图图表库 DhtmlxGantt正版试用下载(qun;765665…...
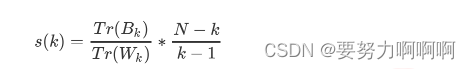
k-means聚类总结
1.概述 聚类算法又叫做‘无监督学习’,其目的是将数据划分成有意义或有用的组(或簇)。 2.KMeans 关键概念:簇与质心 KMeans算法将一组N个样本的特征矩阵X划分为K个无交集的簇,直观上来看是簇是一组一组聚集在一起的…...

char * 和const char *的区别
一、含义的不同 char* 表示一个指针变量,并且这个变量是可以被改变的。 const char*表示一个限定不会被改变的指针变量。 二、模式的不同 char*是常量指针,地址不可以改变,但是指针的值可变。 const char*是指向常量的常量指针ÿ…...

【剑指offer】JZ3 数组中重复的数字、 JZ4 二维数组中的查找
目录 JZ3 数组中重复的数字 思路: 解题步骤: JZ4 二维数组中的查找 思路 JZ3 数组中重复的数字 描述: 在一个长度为n的数组里的所有数字都在0到n-1的范围内。 数组中某些数字是重复的,但不知道有几个数字是重复的。也不知道每…...

数据采集 - 笔记
1 redis GitHub - redis/redis: Redis is an in-memory database that persists on disk. The data model is key-value, but many different kind of values are supported: Strings, Lists, Sets, Sorted Sets, Hashes, Streams, HyperLogLogs, Bitmaps. Redis 通常被称为数…...

8年测开经验面试28K公司后,吐血整理出高频面试题和答案
#01、如何制定测试计划? ❶参考点 1.是否拥有测试计划的制定经验 2.是否具备合理安排测试的能力 3.是否具备文档输出的能力 ❷面试命中率 80% ❸参考答案 测试计划包括测试目标、测试范围、测试环境的说明、测试类型的说明(功能,安全&am…...

spring读取properties顺序,重复key问题
最近搞个开源工具,涉及到配置问题。 举例 有个应用A工具,打成jar给人用。应用B引用了A的jar A应用里resources/sys.properties文件里有个coreSize1 B引用了A,期望修改coreSize的值,改成2 开始天真以为,B应用里有同…...

什么是api接口?(基本介绍)
API:应用程序接口(API:Application Program Interface) 应用程序接口是一组定义、程序及协议的集合,通过 API 接口实现计算机软件之间的相互通信。API 的一个主要功能是提供通用功能集。程序员通过调用 API 函数对应用程序进行开发,可以减轻编程任务。 …...

拒绝“见光死”:为什么真正的全域店群RPA必须内置原生指纹浏览器内核?
大家好,我是林焱,一名专注电商底层业务逻辑与企业级 RPA 自动化架构定制的独立开发者。 在 CSDN 的技术交流群里,我经常会遇到一些开发者抛出这样的疑问:“林大,我用 Python 写了一套并发脚本,去管理公司旗…...
)
别再全网搜了!企业微信后台三步找到你的CorpID和Secret(附AccessToken一键生成工具)
企业微信开发实战:3分钟获取CorpID与Secret的终极指南 第一次接触企业微信API开发时,最让人头疼的莫过于找不到CorpID和Secret这两个关键凭证。官方文档信息分散,后台界面又不够直观,很多开发者在这个环节浪费了大量时间。本文将…...

浏览器端微信使用指南:告别繁琐安装,开启轻量沟通新时代
浏览器端微信使用指南:告别繁琐安装,开启轻量沟通新时代 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信PC版的庞大…...

应对2026检测算法:论文AI率居高不下怎么救?5款降AI工具深度实测
最近不少学弟学妹在后台跟我倒苦水,说查重率好不容易低了,结果AI率越改越高。眼看临近DDL,生怕又因为这个耽误答辩。 作为已经摸爬滚打出来的老学长,今天我就根据我总结出来的经验,从检测系统的底层逻辑开始讲起&…...

Java开发者收藏 | 你的经验不是负担,而是转型AI应用开发的加速器!
本文为Java开发者提供了清晰的AI应用开发转型路径。强调Java后端经验在AI领域是宝贵财富而非负担,并介绍了拥抱AI的优势。文章提出了分阶段学习路线,涵盖基础概念、框架选型(Spring AI、LangChain4j、Spring AI Alibaba)、可视化工…...

New-API数据导出功能:轻松管理AI模型使用记录与账单数据
New-API数据导出功能:轻松管理AI模型使用记录与账单数据 【免费下载链接】new-api A unified AI model hub for aggregation & distribution. It supports cross-converting various LLMs into OpenAI-compatible, Claude-compatible, or Gemini-compatible for…...

TINA-TI仿真实战:从运放振铃到电源设计的电路调试指南
1. 为什么我们需要TINA-TI仿真软件 作为一个在硬件设计领域摸爬滚打多年的工程师,我见过太多因为电路设计问题导致的返工案例。记得有一次,我们团队花了两周时间手工焊接的样机,上电后运放输出端出现了严重的振铃现象,不得不全部拆…...

OpenClawBox:构建统一AI网关,实现多模型智能路由与成本优化
1. 项目概述:从零到一,打造你的个人AI路由中枢 如果你和我一样,在深度使用各类大语言模型(LLM)时,常常陷入一种甜蜜的烦恼:ChatGPT-4o的推理能力无与伦比,但价格不菲;Cl…...

英雄联盟玩家必备:5分钟快速上手LeagueAkari完整教程
英雄联盟玩家必备:5分钟快速上手LeagueAkari完整教程 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟繁琐的操作流程…...

FPGA新手避坑指南:用SPWM驱动电机时,你的死区时间加对了吗?
FPGA电机驱动实战:SPWM死区时间设计的核心要点与避坑策略 在数字电源和电机控制领域,FPGA因其并行处理能力和精确时序控制而备受青睐。许多工程师在成功实现SPWM信号生成后,往往忽略了驱动电路中最致命的一环——死区时间设置。我曾亲眼见证过…...