学习网络编程No.9【应用层协议之HTTPS】
引言:
北京时间:2023/10/29/7:34,好久没有在周末早起了,该有的困意一点不少。伴随着学习内容的深入,知识点越来越多,并且对于爱好刨根问底的我来说,需要了解的知识就像一座大山,压得我踹不过气来。在这种情形之下,我非常害怕写博客,当然本质也就是在害怕为了搞懂一个知识点而不断深入的过程,以及将所学知识联系在一起的过程,最后根据知识点之间的联系,按照思维逻辑对其进行文字总结的过程。当然上述过程对于没有经历过的你来说,应该是非常抽象的,但对于我来说就像是一个总结上述语句的过程,一个用恰当语句将自己认为最深层次的看法表述的过程。说难不难,说简单不简单,短短几句话你阅读起来只需几十秒,而对我却需要几十分钟。当然这是在我没有明确引言写什么的情况下,毕竟可以写的东西太多了…。很好,该引言深入浅出的将我对写博客的理解进行了一定的分析,当然目前应该是灵感有限的问题,上述语句在总结过程有所欠缺,之后有新的感悟我一定会及时记录。下面让我们一起进入该篇博客的主题HTTPS的学习,当然更多的是对HTTP协议的进阶和深入。

回顾HTTP概念相关知识
在上篇博客中,我们从明确HTTP是一个协议,是一个广泛用于各浏览器的协议,浏览器是一个向特定服务器发送连接请求的客户端程序出发,我们明确了HTTP协议诞生的原因,明确了HTTP协议在网络数据传输中扮演的角色,明确了HTTP协议的格式,进而明确了HTTP协议的功能。原来HTTP协议就是用来规范浏览器和Web服务器之间的数据传输。
当然上述是我们针对上篇博客对HTTP协议进行的一个高度总结,这里我们对其展开了解,首先我们以我们自己实现的网络版本计算器场景与浏览器客户端和服务端的实现作对比,明确浏览器客户端和浏览器服务端之间一定存在某种自我实现协议,从而明确如果当浏览器被不同的开发人员实现,那么浏览器客户端和浏览器服务端之间使用的协议就一定是不同的,那么此时因为浏览器的功能是相同的,而协议是不同的,最终就会导致所有Web服务器需要兼容所有的浏览器协议。这样就不仅会提高服务器的开发和维护成本,也会增加用户的使用成本。为了解决这一问题,HTTP协议就被某些顶级的组织开发,并设置为浏览器默认使用协议。其次,以上述知识为背景,结合我们对浏览器功能的默认理解(已知条件),此时我们知道浏览器在与Web服务器建立连接的过程,本质就是在根据HTTP协议向Web服务器发送一个HTTP请求,当Web服务器收到该HTTP请求之后,服务器同理根据HTTP协议对HTTP请求进行解析和数据提取,然后再根据被提取数据做出对应的HTTP响应。自此,我们明确了HTTP协议的使用场景。最后,同理依据HTTP协议使用场景,我们深入学习了HTTP的协议格式,明确了HTTP协议的请求格式和HTTP协议的响应格式。并且在理解HTTP协议请求格式时,其中涉及有关URL相关的知识在上篇博客中我们也进行了详细介绍,其中就包括什么是URL,为什么要有URL,为什么URL需要进行urlencode/urldecode,什么是encode/decode等相关知识的理解。以上大致就是我们在上篇博客中所谈到的知识,下面让我们一起进入该篇博客的学习。
HTTP请求 / 响应代码实践
对上篇博客有了一定回顾之后,此时心里就非常的踏实,谁让人的记忆总是如此的抽象,间接证明上述工作是一个非常有必要进行的工作。当然刚开始时非常痛苦,同理,想要以惯用思维逻辑将自己的理解以文字的形式表述以及构建逻辑语句是一个让人不舒服的过程。所以当我们完成了上述的回顾总结,此时我们正式进入新知识的学习,本质也就是对上篇博客结尾处所说的HTTP请求和响应进行深入理解,不单单只是从宏观概念去看,而是投入到代码之中,在具体场景下以代码的形式看。
想要从代码的角度深入HTTP请求和响应,前提当然是我们对HTTP请求格式和响应格式已经了然于胸,明确HTTP协议的报头和有效载荷,明确报头含有的字段和字符标识,从而清楚应该如何对HTTP请求和响应进行数据读取和格式控制。带着对上述知识的明确,此时我们正式开始代码实践过程,同理编码过程是递进的,所以我们大方向分为三个步骤。不过注意:这三个步骤都是基于同一个场景下,同理就是经典的服务端和客户端数据传输场景,当然此时的客户端一定就是我们本地主机上的浏览器,而服务端通过我们自己的云服务器实现。当然如果你自己有实力,你也可以自己实现一个具有浏览器功能,使用HTTP协议的客户端,我反正是没有,你行你上。所以此时当我们明确了实践场景,我们就可以按照如下三个步骤,对HTTP请求和响应进行深入学习啦!
1.实现服务端,切实的看到浏览器发送给服务端的数据
在之前,无论是明确HTTP协议的理论概念,还是明确HTTP协议的宏观概念,我们都只是在纸上谈兵而已,并没有客观实际的看到具体的数据,所以此时为了深入HTTP协议的请求和响应,第一步我们就来实际的看看浏览器到底有没有完成发送HTTP请求的工作,发送的HTTP请求数据具体长什么样。
第一步想要实现上述所说,此时我们首先就需要利用套接字API,实现一个属于我们自己的服务器,当然此时这个过程无论是在我们学习套接字时,还是学习序列化和反序列化实现网络版本计算器时,我们都已经见识过了,大致过程非常简单,也就是在某源文件中包含服务器功能实现头文件,在源文件中调用头文件中的初始化服务器接口和启动服务器接口,并且在源文件中将某任务执行逻辑接口通过函数指针的形式初始化服务器,让服务器在启动之后,可以接收浏览器客户端发送数据的同时,对浏览器发送数据,也就是HTTP请求进行数据解析和数据处理,最终根据对应数据进行HTTP响应的构建。而对于上述所说的初始化服务器和启动服务器,我们肯定并不陌生,本质也就是在使用套接字API中对应的接口完成,当然因为此时我们使用的是TCP协议,所以我们在服务器中还需要对其进行并行化处理,也就是让其从单执行流变成多执行流。这个过程我们一般使用线程/线程池来完成,具体过程以及具体分析我们在之前博客中都有进行过深度讲解。如下代码所示:
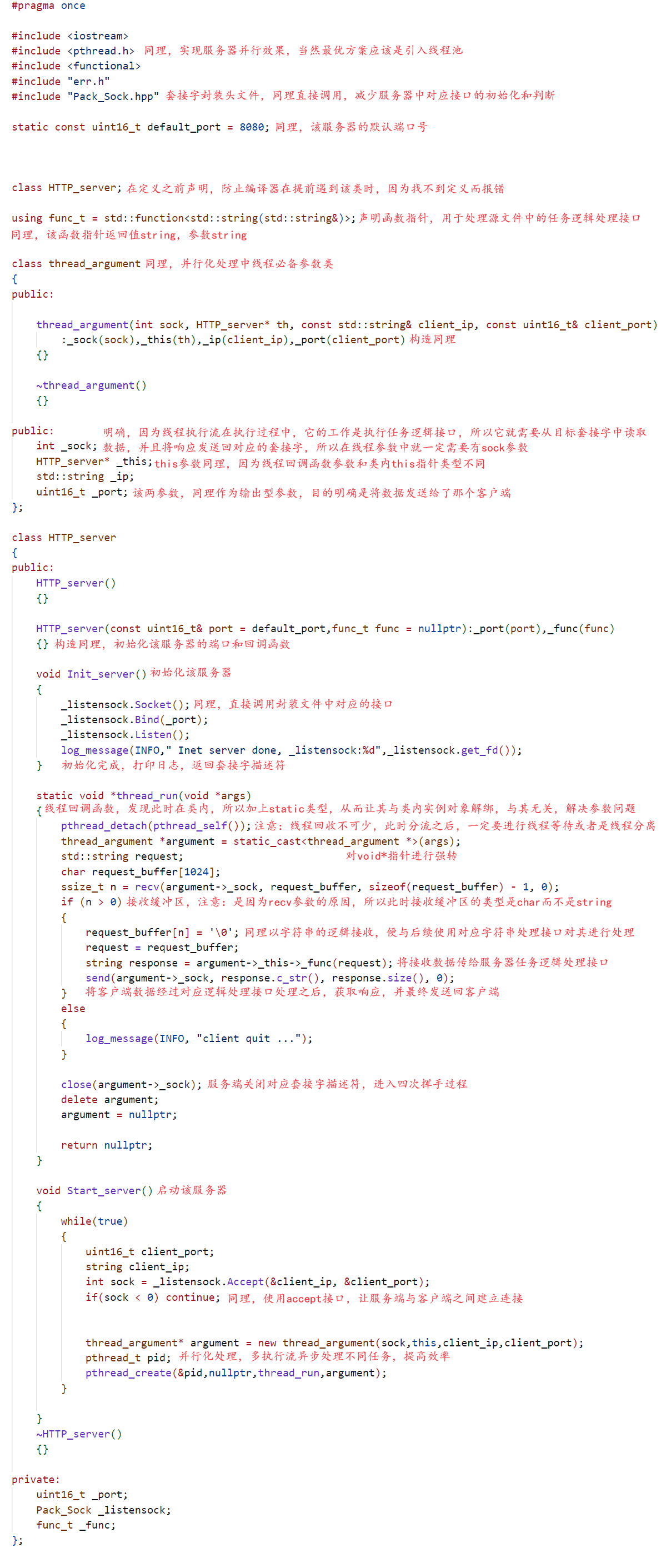
如上代码,就是一份网络服务器程序最基本的构建过程,当然这个过程的构建无论是我们之前学习网络套接字时,还是学习序列化反序列化时,我们都已经经历过了。并且上 述也已经对其基本实现逻辑和过程进行了简单的描述,这里我们就不再赘述。我们此时最主要的工作是看到浏览器在访问我们自己实现的服务器时,发送给对应服务器的数据到底与我们想象中的是否一样。而基于对上述代码的理解,我们明白,对于浏览器请求数据的处理我们是放在了func接口中,当然也就是源文件中用于初始化服务器的任务逻辑处理接口,具体代码如下所示:

所以根据源文件中代码所示,当我们运行该代码,系统就会完成服务器的初始化和启动工作,最终回调初始化时的默认函数接口server_io_task。且根据上图,此时我们就明确了该服务器对应的任务逻辑处理接口,明确该服务器目前只是简单按照我们的预期将浏览器发送过来的HTTP请求数据显示到终端而已。所以最后当我们真正使用浏览器访问该服务器时(IP地址+端口号),该服务器就会接收到如下数据:

所以如图中数据所示,此时我们发现我们就真正的看到了HTTP请求数据,看到了HTTP请求格式。然后结合我们对HTTP协议概念方面的理解,此时我们就可以很容易的区分HTTP请求中不同数据代表的含义,并且在请求头中此时我们就能够具体的看到对应的Key/Value数据,其中Host表示的就是访问该服务器的主机IP和端口,Connection表示的是对应主机是否希望和服务器保持连接,而Upgrade-Insecure-Requests表示是否将HTTP请求更改为HTTPS连接(保证数据安全性),User-Agent则表示的是用户代理信息,其中就包括浏览器类型、浏览器版本以及运行该浏览器的操作系统,剩下的Accept表示的是用户接收响应数据时服务器需要匹配的格式,Accept-Encoding和Accept-Language同理表示用户接收数据使用的编码方式和语言,最后一个Cookie则代表用户Cookie信息对应的sessionid,该点后序我们会详谈,如上就是有关请求头中的所有内容。所以当服务器接收到了这个HTTP请求之后,服务器不仅需要读取请求体,它也需要对请求行和请求头做数据解析和提取,然后依据对应读取信息做出相应的处理,最终将一个完整的、可靠的HTTP响应返回。
2.服务器收到HTTP请求,对其进行反序列化操作
通过上述代码以及一系列的操作,此时我们就真实的看到了浏览器发送到我们服务器上的数据了,明确了因为浏览器使用的是HTTP协议,所以在我们自己服务器上接收到的就是以HTTP协议为标准的请求格式。所以当服务器接收到数据之后,此时服务器就需要对数据进行解析,然后根据对应解析出来的数据,调用特定的功能,完成特定的任务,当然此时这个解析过程就是一个经典的反序列化过程。最终获取到对应的结果数据,将结果数据依据HTTP响应格式对其重新进行序列化工作,当然也就是对其进行响应数据构造的工作。通过上述的描述,此时我们就能清楚的明白一个点,无论对应协议是不是我们自己定制的,只要你想要使用对应协议,你就需要清楚该协议的定制过程,也就是该协议的标准格式,只有这样你在处理发送数据或者是响应数据时才有抓手,才有依赖,才有进行下一步的能力,特别是在网络数据传输情况下,你如果不知道对端使用的协议,那么你就无法解析到对应的数据,也就无法响应数据,当然这也就是当今网络为什么大家使用的都是同一套方法,使用的都是同一个网络协议栈。当然此时底层我们先不关心,目前我们主要针对的是应用层协议HTTP,所以此时当我们明确了HTTP协议对应请求格式以及响应格式之后,我们就可以进行如下工作的处理,如下代码所示:
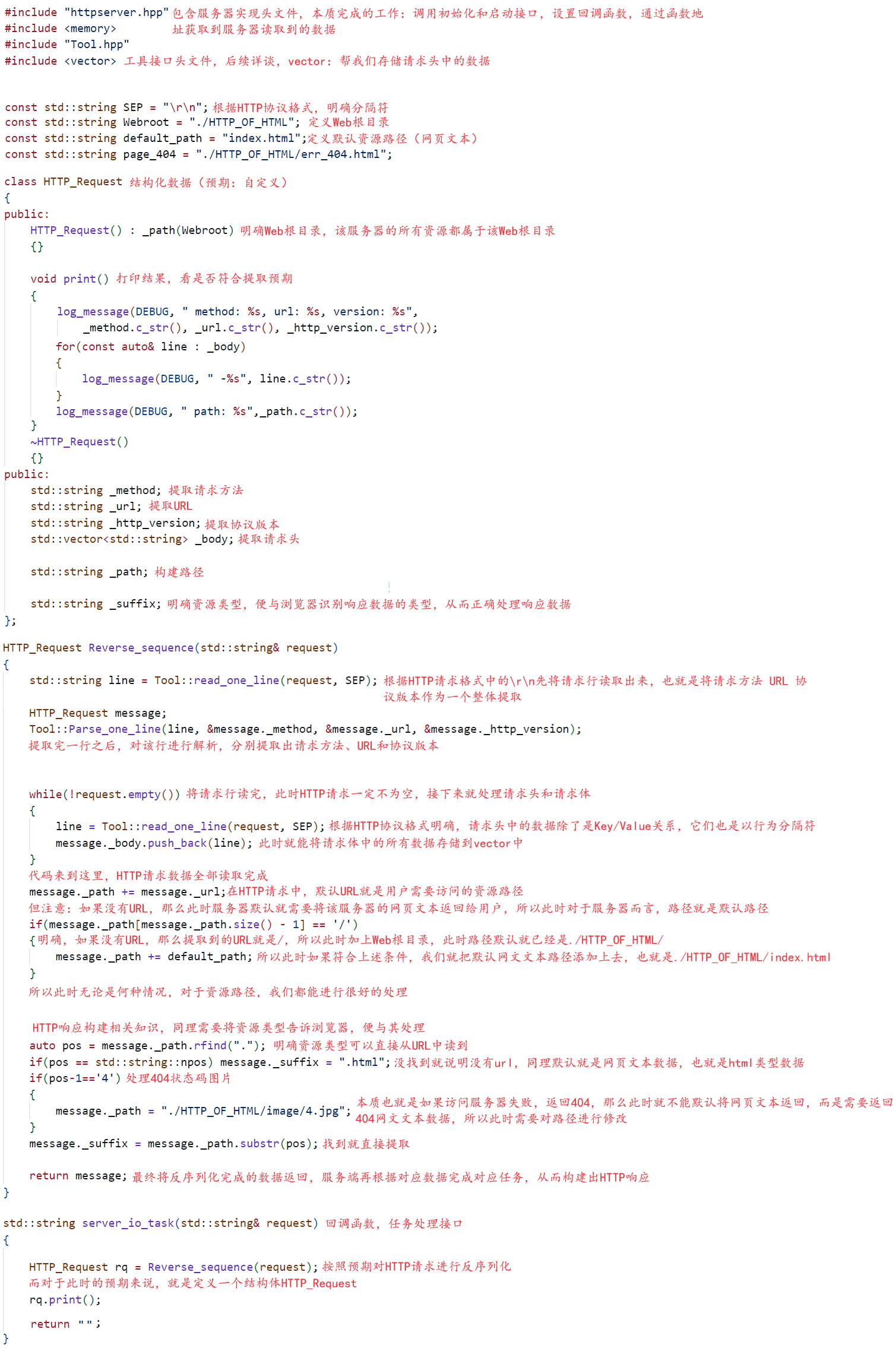
如上代码,我们就完成了一系列的工作,当然本质也就是在对HTTP请求数据按照我们的预期做反序列化工作。原理非常简单,与我们之前学习序列化反序列化相关知识一样,首先按照预期确定结构化数据,然后根据协议,当然此时的协议不是我们自己定制的协议,而是正宗的HTTP协议,明确协议格式和分隔符,最后根据协议格式和分隔符对数据进行字符操作,提取出目标数据的同时将其赋值给结构化数据中对应的字段。所以最终凭借上述的操作,我们就可以得到如下数据,也就是我们从HTTP请求中提取出来的目标数据:

3.反序列化完成,凭借获取数据构建HTTP响应
获取到了上述数据之后,下一步也就是最后一步,就是在服务端构建HTTP响应,也就是将响应数据根据HTTP协议的响应格式返回给浏览器。只不过在我们构建HTTP响应时,我们还需要解决几个问题。其一,当用户在访问服务器资源时,服务器并没有对应的资源怎么办?其二,反之如果服务器上有目标资源,那么服务器又应该如何返回呢?其三,在构建HTTP响应时,响应头中的数据应该是什么呢?是和请求头数据一模一样吗?
所以如果我们想要成功构建HTTP响应,首先我们就需要解决上述问题,而为了解决上述问题,我们就需要明确几个概念。从HTTP响应格式出发,此时我们就需要明确状态码和状态码描述,也就是明确不同的HTTP请求,服务端会有不同的处理结果,有不同的处理结果,最后就需要使用状态码将对应的处理结果返回给客户端。如200/300/400/500分别表示的就是请求成功/请求资源重定向/请求格式错误/服务器内部错误,当然对于服务端来说,远不止只有这几个处理结果,例如还有经典的404状态码表示的就是请求资源不存在。当然对于这些不同状态码对应的状态码描述都是由HTTP协议规定好的,我们只需要按需使用就行。所以当我们明确了有关状态码相关知识,此时我们就明白当服务器没有资源时应该怎么办了,直接返回404状态码以及状态码描述,当然除了这些,我们还需要依据状态码处理机制中的错误处理机制,将404页面或者是404错误文本通过请求体返回给客户端。所以同理,当服务器上存在目标资源,我们依然就是根据状态码处理机制,设置对应状态码200的同时,将目标资源数据设置到请求体中,最后返回。但,无论是将404错误文本还是目标资源返回给客户端,只要是请求体(有效载荷)中包含数据,那么浏览器就必须知道这些数据的大小以及类型,以便于后续浏览器直接对数据进行提取和渲染工作。所以此时我们就明确了最后一个问题,在构建HTTP响应时,响应头中的数据和请求头不完全一样,它会包含Content-Length/Content-Type 等字段,用于表示有效载荷数据的大小及类型,当然也会包含其它字段,Content-Encoding/Cache-Control/Location 将更多的响应信息告诉浏览器,便与其处理目标数据。明确了上述知识,此时构建HTTP响应就如同砍瓜切菜一般简单,如下代码所示:

从上述代码中,我们可以看出,根据HTTP响应格式,我们可以很好的构建出一个简易的响应数据,其中该响应数据的响应头中包含了有效载荷的大小以及类型,当然上述我们只是通过字符串的形式简单的模拟了一个有效载荷,而真正的有效载荷必须是以文件的形式存在,而不是以字符串的形式添加在代码中,因为有效载荷是资源,资源可能是图片/视频/音频等…,并且资源也需要被重复使用,当然也为了保持代码的可读性和可维护性,所以我们都不能直接对有效载荷编码,而是将其放到文件中,通过特定的接口去读取特定文件中的数据。当然对于我们来说,读取特定目录下的特定文件这种文件操作,我们可以直接使用open/read或者是fopen/fread简单完成,但问题就来了,我们应该如何获取到指定目录下文件的大小呢?所以此时我们就需要新认识一个系统调用接口stat,具体使用方式:int stat(const char *path, struct stat *buf); 第一个参数表示目标文件的绝对路径,当stat接口获取到绝对路径,操作系统就会在我们当前的工作路径下寻找该绝对路径文件,间接也就表明,服务器的Web根目录一定需要存放在服务器的工作目录中。只有这样,最后stat接口才能成功找到目标资源所在的文件,从而获取到文件的属性信息。同理,第二个参数就是一个输出型参数,将目标文件的属性信息通过结构化的形式返回给我们,最后我们通过该结构化数据就能读取到其中文件的任意属性信息了,如文件的大小。所以最终我们对有效载荷,也就是服务器资源的管理方式就会变成下述代码的形式(先以文件构建资源,再读取文件)。
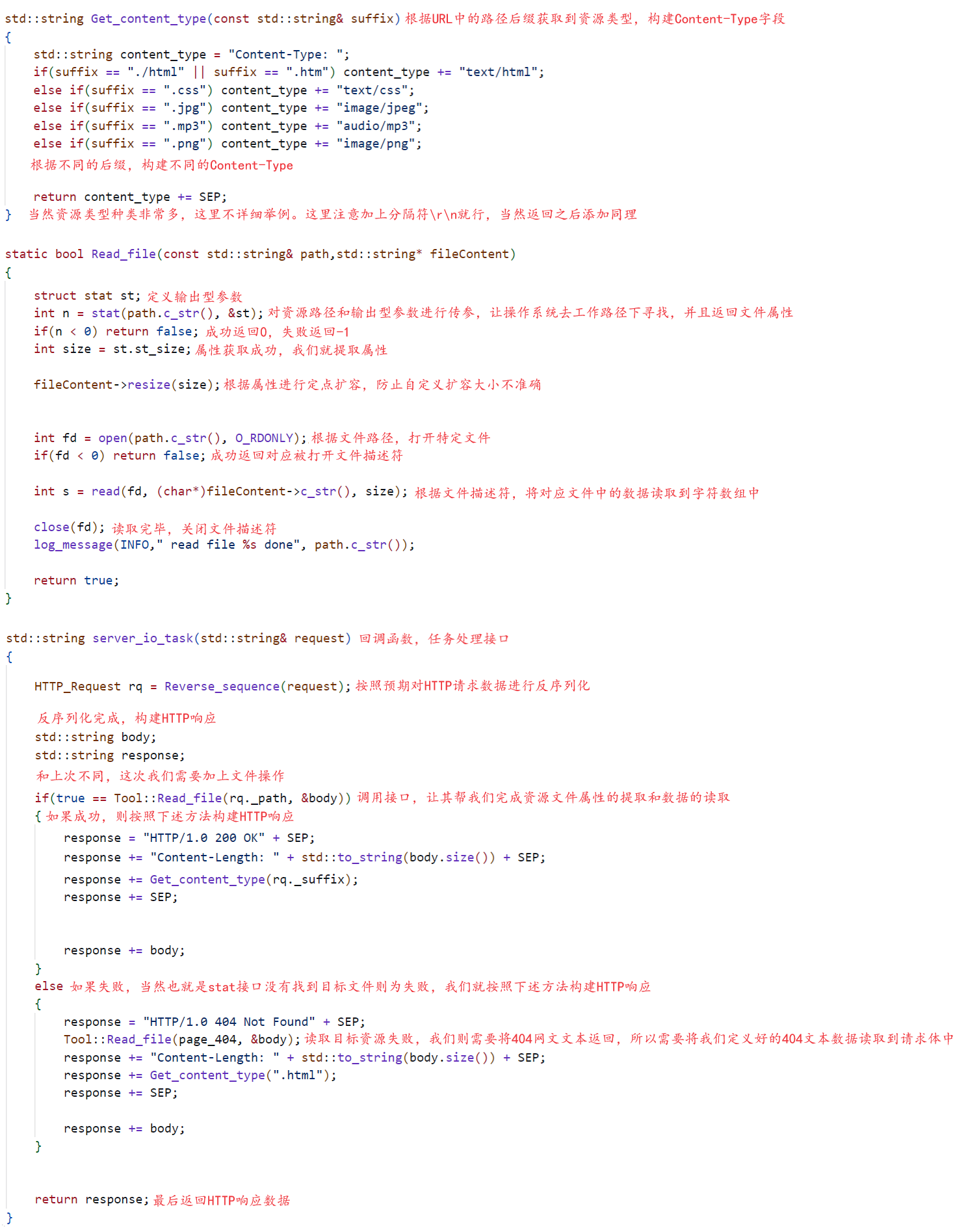
从上述代码我们就可以看出,为什么当时在进行反序列化的过程中,需要特意的构建资源路径,为什么需要在服务器工作路径下定义Web根目录,为什么需要构建默认返回路径,为什么需要构建404错误文本路径,原来一切都是为了可以更好的配合stat接口、open接口、read接口完成对特定文件的属性和数据提取,从而真正实现一个服务器在HTTP响应中对有效载荷的处理逻辑。
总: 所以上述就是我们对HTTP请求/响应代码实践的全部内容,本质很简单,以我们的对比模仿能力,上述内容和我们在学习序列化反序列化,自己实现网络版本计算器没有任何区别。不就是作为服务端,对客户端发送的请求数据进行一个解析处理的反序列化过程和一个对响应数据进行序列化的过程。同理只不过此时的协议从自定义协议变成了HTTP协议而已。当然上述代码中还有部分知识未展示,如:前端相关的知识,也就是我们在构建HTTP响应读取文件时,一般首先我们需要返回一个网页文本信息,或者是返回404页面时,我们都需要使用部分的前端知识,如:html等…,这里不详谈,因为有关前端的知识我们一点都不关心,我们需要明确的只是网络数据在应用层传输的过程。也就是根据HTTP协议反序列化/序列化数据的一个过程,本质也就是明确在应用层我们是如何获取到数据,如何对数据做处理。
拓展HTTP相关知识
该篇博客来到这里,主要内容大致我们就完成了,下述属于对HTTP相关知识进行拓展,当然这个拓展在上述讲解过程中也有一定的涉及,但是没有详谈,因为并不符合我们上述的行文逻辑。所以下面我们针对几个方面对其进行一定的讲解,如:请求方法中GET和POST的区别,什么是重定向状态码,什么是Cookie安全,什么是会话保持等一系列相关知识。
深入理解请求方法之GET/POST
同理当我们完成了上述代码实践工作,现在就是一个处理细枝末节的好时候,所以此时我们就来深入学习一下有关请求方法的知识,首先明确对于HTTP协议而言,最常用的请求方法是GET和POST,但是除了这两种方法之外,还有其它非常多的方法,如:PUT/HEAD/DELETE/LINK等…,具体这些方法对应的功能是什么,这里我们不详谈,我们只需要明白GET和POST方法的作用是获取服务器资源的同时,顺便将用户参数提交给服务器。当然因为GET和POST的这一功能,也就能明白为什么GET和POST是最常用的请求方法了,因为构建HTTP请求一般就只是为了获取到服务器资源而已。那么此时问题就来了,GET和POST有什么区别呢?我们什么时候使用GET,什么时候使用POST呢?所以让我们带着这个问题,一起来看下图,如图所示:

首先明确,无论平时我们是使用浏览器客户端程序,还是其它客户端程序,亦或者是Web服务器的网页,我们所能看到的数据提交框一般都是由表单创建的,本质当然也就是因为表单是唯一可以获取用户数据,然后发送给服务端的HTML元素。所以当我们在构建HTTP请求想要获取服务器资源并且将用户数据提交给服务器的同时,表单就是一个必不可少的元素。其次我们要明白,如上图表单中存在着method字段,这个字段表示的就是HTTP请求中的请求方法。所以同理在浏览器构建HTTP请求时,HTTP请求中的请求方法就是根据对应Web服务器网页文本中的表单决定的,当然明确浏览器默认表单中的请求方法是GET,也就是我们在还没获取到网页文本数据之前,浏览器是通过GET方法帮我们获取数据。所以当我们明确了上述知识之后,我们就知道如何修改HTTP请求的请求方法了,只要对表单中的method字段进行修改就行,如下就是POST方法表单,当然也就是POST方法的HTTP请求:

所以此时针对上述两幅图最后不同的结果,此时我们就明确了GET/POST请求方法的不同,对于GET方法来说,它是直接通过URL提交用户参数,而对于POST方法来说,它则是通过有效载荷来提交用户参数。所以通过这一点的不同,此时我们就能区分GET和POST的区别以及明白在不同场景下使用GET还是使用POST的问题,本质也就是因为GET是将用户数据存放在URL之中,而浏览器默认会对URL进行回显,导致用户数据不私密。反之同理,POST方法是将用户数据存在有效载荷中,相对GET来说,它较为私密。所以明确,GET方法一般用在对用户数据私密性要求不高的场景,如:搜索引擎,而POST方法则一般用在用户数据私密性要求高的场景,如:账号密码登录。
注:上述我们并没有使用安全性的概念,而是私密性,本质也就是我们后续学习HTTPS的原因,因为类似HTTP请求这种数据,在不加密,也就是不使用HTTPS协议的情况下,它都是极不安全的,后续详谈。
重定向状态码知识理解
在上述HTTP请求/响应代码实践构建HTTP响应的过程中,我们对状态码相关知识有了一定的理解,明确状态码就是用来告诉客户端,服务端对该次HTTP请求的处理结果,从而让客户端可以根据状态码来明确下一步进行的操作和处理方法。并且明确对于状态码来说,一般可以分为5类,信息性状态码(1xx)、成功状态码(2xx)、重定向状态码(3xx)、客户端错误状态码(4xx)、服务器错误状态码(5xx),而对于上述5类状态码来说,其它4类都非常好理解,所以我们不重点讲解,我们只要重点将重定向状态码弄清楚就行。
首先从大方向上看,重定向状态码与我们之前在学习系统编程之基础IO中的输入重定向/输出重定向在原理上是相同的,只不过前者此时是对URL进行重定向,而后者是对文本数据进行重定向,本质理解也就是在进行一个替换或者是更改的过程。类比输入重定向/输出重定向,前者是将本来从键盘读取数据的过程直接变成从某个文件中读取,后者同理是将本来要输出到显示器上的数据直接变成输出到某个文件中。我们此时就可以明确,对于重定向状态码来说,它也是一样的,只不过它是在将HTTP请求中的URL替换成一个新的URL,也就是当某浏览器使用URL访问到某服务器时,因为服务器的原因,它需要让浏览器明确此时这个URL并不能满足它的需求,然后将能满足需求的新的URL返回给浏览器,让浏览器对这个新的URL发起链接。所以当一个服务器因为某种原因(服务器维护/特定方法要求),导致其目前无法满足客户端需求时,它就需要返回3xx重定向状态码,而其中最常见的就包括301/302/303/307。当然想要深入了解重定向状态码,此时我们就需要对不同的重定向状态码进行区分,首先同理从大方向出发,重定向状态码可以分为永久重定向状态码和临时重定向状态码,而上述四种常见状态码中301/303表示的就是永久重定向状态码,302/307表示的则是临时重定向状态码,那么问题就来了,这两种状态码有什么不同呢?所以此时我们就明确,对于永久重定向状态码和临时重定向状态码来说,顾名思义它们最大的区别就在于一个是永久一个是临时,什么意思呢?也就是如果服务器返回的是永久重定向状态码,那么当浏览器识别到该状态码之后,浏览器就会将历史记录中的URL从旧的替换成新的,并且将书签(收藏夹)中的URL更新,反之则不会。其次从小方向出发,重定向状态码还可以分为对请求方法是否有要求,如何理解呢?其实本质也就是当你从访问旧的URL到访问新的URL,这之间存在请求方法是否改变的区分。所以此时根据这一点,重定向状态码就还可以分为两类,一类对请求方法没有要求,使用GET/POST都行,反之有一定要求,当然明确这个要求本质是基于场景下讨论的,也就是基于你新的URL对应的网文文本表单在提交数据时是否存在要求。所以前者可以分为301/302,后者303/307,并且对于后者来说,请求方法的要求也是不同的,对于303来说,它要求的是访问新URL的方法和访问旧URL的方法相反,反之307要求访问新URL的方法和旧URL的方法保持一致。上述就是有关重定向状态码理论方面的所有知识,总而言之,重定向状态码的使用都是基于不同的场景。上述理论明确,下面同理就让我们来看看相关代码实践,如下图所示:
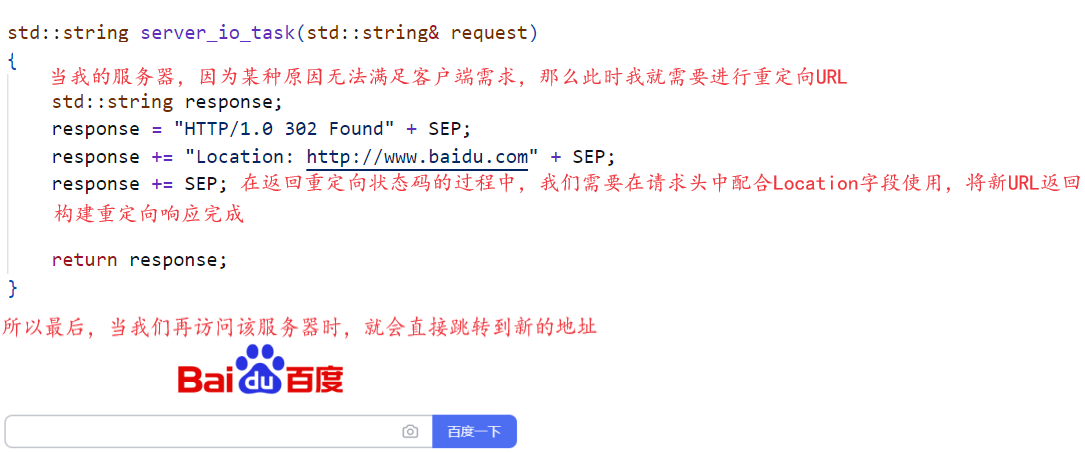
从图中我们就能看出,当我们的服务器因为某种原因需要让用户进行URL重定向时,我们就可以在请求头中添加Location 关键字,从而将新URL响应回给客户端,最后当客户端收到HTTP响应之后,浏览器就会依据这个新的URL再次向目标服务器发送HTTP请求,从而获取目标资源。以上就是有关重定向状态码代码实践部分,接下来我们再来谈谈有关临时重定向和永久重定向不同的使用场景。其中对于临时重定向而言,以日常生活为例子,如:当我们访问某个网页(哔哩哔哩),这个步骤我们很清楚,只要给浏览器提供对应网页的URL,浏览器就会帮我们发送HTTP请求,然后对应网页把它的网页文本返回给浏览器,然后浏览器渲染给我们,我们拿到目标网页,此时一切都是正常的,但是如果当你想要获取该目标网页上的某个目标资源时,你就会发现,它会跳出一个登录账号密码的页面,只有当你完成了登录,你才能正常获取该目标资源。所以明确,当你想要从目标网页上获取数据时,也就是浏览器在二次构建HTTP请求时,如果服务器检测到你还未登录,那么此时服务器返回的HTTP响应就是一个临时重定向资源,将登录页面通过新URL的形式提供给你。然后其次是永久重定向,对于永久重定向而言,它的使用场景就比较暴力了,一般就是在更换域名,或者是直接更换服务器的情况下使用,也就是为了不造成流量损失,我们就可以在用户访问旧URL时,直接将新URL以永久重定向的形式给它,从而让其下次访问时,直接访问的就是新的域名或者服务器。
拓展:这个位置既然谈单有关临时重定向相关的知识,此时我们就可以拓展有关爬虫的知识,首先明确,爬虫是一个根据特定的规则和算法向全网服务器不断发送HTTP请求,然后获取响应数据的一个可执行程序。其次明确,搜索引擎离不开爬虫,这也就是为什么搜索引擎能够帮助我们获取到任意我们想要获取的数据,基本原理也就是搜索引擎获取用户数据,对用户数据做分析,与当前已有数据做匹配,若不匹配,提取关键字,让爬虫根据关键字构建HTTP请求访问目标服务器,获取响应,最后返回给用户。所以明确了爬虫的基本工作原理,此时我们就明白,当爬虫向某服务器发送了HTTP请求,如果该服务器最终返回的是一个临时重定向,也就是一个新的URL,那么爬虫默认就拥有了该服务器上对应的数据,但如果此时该服务器关闭了该临时重定向,也就是再访问该URL不再获取到资源,那么当用户想要从搜索引擎上访问该资源的时候,就会显示该链接已过期或者是该资源已过期。所以搜索引擎为了减少这种情况的发生,也就是克服临时重定向带来的问题,它就需要频繁的更新,也就是让爬虫程序一直爬一直爬。
详解HTTP请求头之Cookie
进入HTTP协议最后一个知识点,有关Cookie相关知识,当然首先明确在HTTP请求头中并不单单只有Cookie字段,还有如我们上述所说的什么Content-Type/Content-Length/Content-Control/Content-Encoding等一大堆字段,当然这么多字段上述我们也简单讲过了,这里我们也不想详谈,此时同理我们对请求头中的Cookie字段进行着重讲解就行。
在学习什么是Cookie信息之前,首先我们需要明确一个叫会话保持的概念,很简单从两方面去理解它,什么是会话保持,为什么要进行会话保持?对于什么是会话保持这个问题,因为我们目前还在铺垫阶段,所以不能直接追本溯源,此时明确会话保持就是服务器每次都需要对浏览器发送的HTTP请求进行标识符检查,从而判断该次HTTP请求和上次HTTP请求是否属于同一浏览器发出,如果标识符相同,那么对于这次HTTP请求在服务器资源和权限上的处理就和上次相同,从而避免服务器每次都需要要求客户端进行身份验证。所以根据这一原理,此时我们也就明确为什么要进行会话保持,如果没有会话保持,那么每次访问该服务器上的资源我们都需要进行身份验证,也就是账号密码登录,那么对于用户体验来说是非常糟糕的。所以此时我们对于会话保持的概念就有了一定的认识,但是因为HTTP是一个超文本传输协议,它本身是无状态的,也就是说HTTP协议本身并没有会话保持的能力,所以此时HTTP协议为了实现浏览器和服务器之间的会话保持功能,它就采取了Cookie信息和sessio id的解决方法。
清楚了上述知识,此时我们对于HTTP请求头中为什么要有Cookie字段也就一清二楚啦!原来是为了让浏览器和服务器之间具有会话保持的功能,便与用户从服务器上获取资源呀!那么Cookie具体表示的是什么呢?实现会话保持的具体步骤有哪些呢?这两个问题都非常简单,因为后者能直接明确前者,所以我们直接明确会话保持的步骤就行。跳过获取Web服务器网页文本过程,假如此时某网页已经呈现在我们的面前,我们想要获取该网页上的某个资源,那么当该HTTP请求发送出去,服务器就一定会响应给我们一个临时重定向URL,当然这个URL也就是登录注册框,当你在这个临时重定向中完成了登录,也就是通过表单我们将数据提交给了该服务器(POST),当然注意因为临时重定向是一个新的URL,所以此时该数据可以是提交给一个新的服务器,也可以是提交给同一服务器不同路径下的某处理该数据的可执行程序,当然本质也就是需要将该表单数据拿到自己的数据库中进行查找,若匹配成功,那么此时服务器在构建HTTP响应时,同理就会把网页和资源路径所对应的URL再次通过临时重定向返回给浏览器,最终浏览器通过识别状态码,发现是一个3xx,直接再次向Location字段后面的URL发送HTTP请求,从而真正意义上的获取到目标资源。只不过此时浏览器不仅仅只能获取到目标资源,它还可以获取到用户的Cookie信息,因为服务器在第二次返回临时重定向时,为了实现会话保持功能,它就需要将用户提交的身份信息也返回给浏览器,然后让浏览器自动的将用户的身份信息,也就是Cookie信息保存到本地(内存/文件),从而实现浏览器下次在访问该服务器时,可以自动将Cookie信息添加到HTTP请求中,从而真正意义上实现浏览器和服务器的会话保持功能。注意: 上述谈到的知识还不全面,很多地方不完全准确,如:不是说服务器构建临时重定向时,只能返回状态行信息和Location信息(新URL)吗?然后又说在第二次返回临时重定向时,还需要将用户的Cookie信息返回,那么Cookie信息存放在哪里呢?这两个问题我们先不谈,因为下面我们想先解决另一个问题,下述问题明白了,上述我们也就清楚了,问:上述我们说过,当浏览器获取到用户Cookie信息,假设此时Cookie信息就是账号和密码,它就会将这些账号和密码存储在本地文件中,那么如果某天我们点击了某个陌生链接,从而导致运行了某个恶意程序,这个程序将我们浏览器Cookie文件中的Cookie信息给窃取了,我们应该怎么办呢?所以显然上述服务器将用户Cookie信息返回给浏览器的方法是不安全的,所以为了解决这一问题,最好的方法就是将用户的Cookie信息保存在服务端上,然后通过特定数据结构,如哈希(Redis),来构建映射关系,然后让服务器在每次返回用户身份信息时,不要返回Cookie信息,而是将Cookie信息对应的Key值返回回去,当然此时这个Key值也就是传说中的session id,所以有了这一理念,此时我们就明确服务器不再需要返回Cookie信息,而是返回session id,而session id对于Cookie信息来说,只不过是一个编号,并不需要进行非常复杂的存储,所以此时我们就直接将session id通过URL的形式返回给浏览器,这也就是上述谈到两个问题的答案,为什么临时重定向也能返回用户身份信息,因为我直接将session id构建到临时重定向的URL中就行了。
拓展: 根据上述所说,此时我们就可以明确因为Cookie信息保存在服务端,所以我们不担心Cookie信息丢失,但是随之而来面临的问题就是session id可能会丢失,而当我们的session id丢失,其它用户可能依然可以拿着该session id访问到对应的用户数据。所以此时该问题就也需要被解决,因此服务端就会采取很多的措施来防止session id被他人获取,如:异地登录需要进行验证码验证,定期让用户重新登录返回新的session id,对session id进行加密处理。所以此时在这一套机制的控制下,session id的可靠性和安全性就提高了,当然有人会问,那我为什么不能对Cookie信息进行加密处理,然后将Cookie信息返回给浏览器呢?答案必然是可以的,只不过这样做无论是在效率方面,还是在安全方面都不如上述方案,当然也就是目前大家都在使用的方案。
通过数据安全方面引出HTTPS相关知识
该篇博客来到这里,由于HTTP的内容太多,大大超出我的预期,所以HTTPS方面的知识写不了了,只能是下篇博客继续啦!当然本质也就是在谈网络数据传输安全方面的知识。难度不大,都是概念,See you!
相关文章:
学习网络编程No.9【应用层协议之HTTPS】
引言: 北京时间:2023/10/29/7:34,好久没有在周末早起了,该有的困意一点不少。伴随着学习内容的深入,知识点越来越多,并且对于爱好刨根问底的我来说,需要了解的知识就像一座大山,压得…...
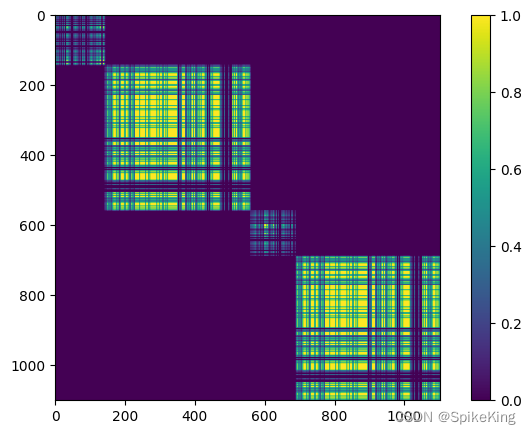
PSP - 蛋白质复合物结构预测 Template Pair 特征 Mask 可视化
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/134333419 在蛋白质复合物结构预测中,在 TemplatePairEmbedderMultimer 层中 ,构建 Template Pair 特征的源码,…...

RK3568开发笔记-amixer开机设置音量异常
目录 前言 一、amixer介绍 1. 显示音频设备信息 2. 显示音量信息...
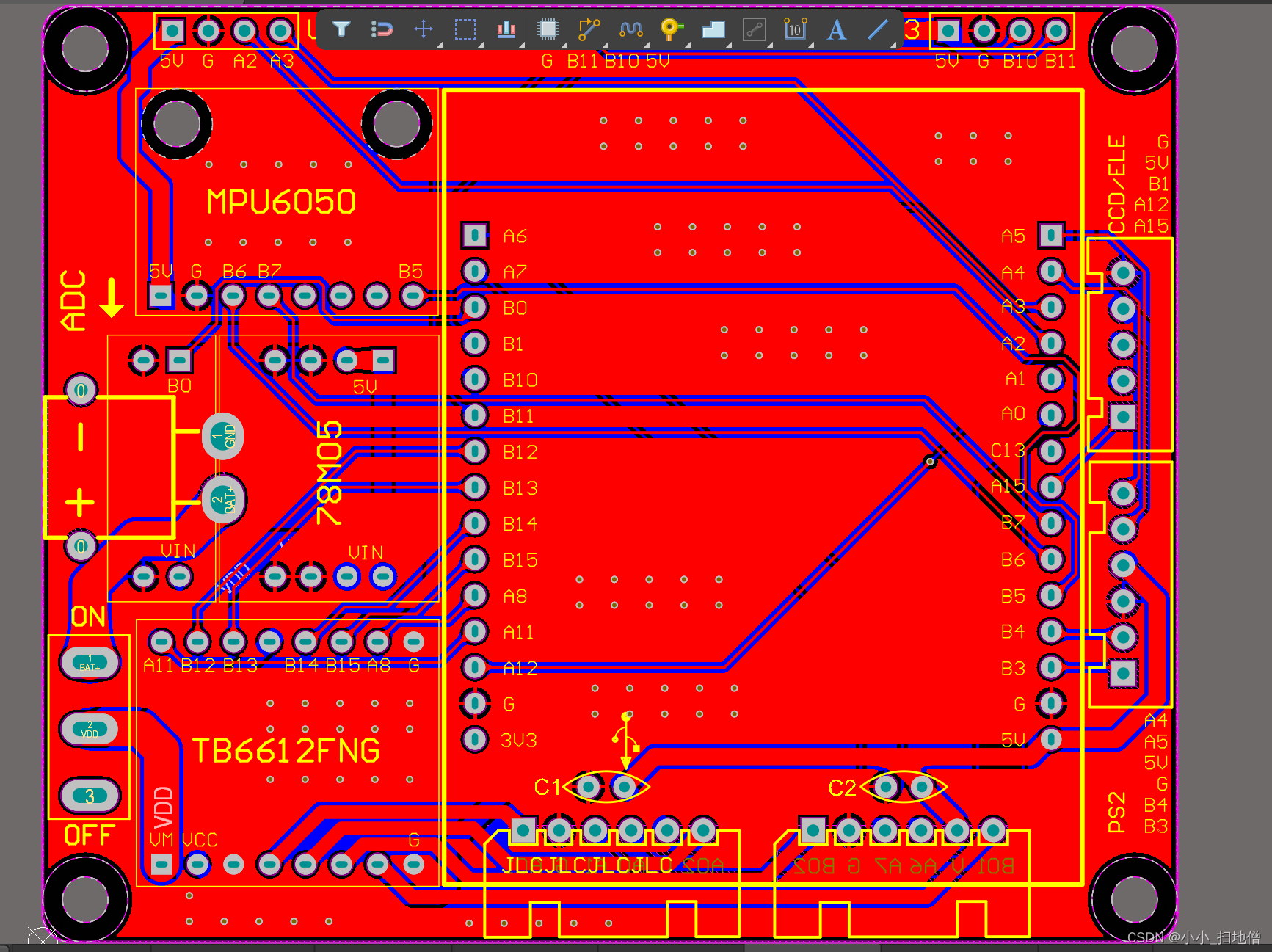
STM32两轮平衡小车原理详解(开源)
一、引言 关于STM32两轮平衡车的设计,我想在读者阅读本文之前应该已经有所了解,所以本文的重点是代码的分享和分析。至于具体的原理,我觉得读者不必阅读长篇大论的文章,只需按照本文分享的代码自己亲手制作一辆平衡车,…...
)
区间内的真素数问题(C#)
题目:区间内的真素数 找出正整数 M 和 N 之间(N 不⼩于 M)的所有真素数。真素数的定义:如果⼀个正整数P 为素数,且其反序也为素数,那么 P 就为真素数。例如,11,13 均为真素数&#…...
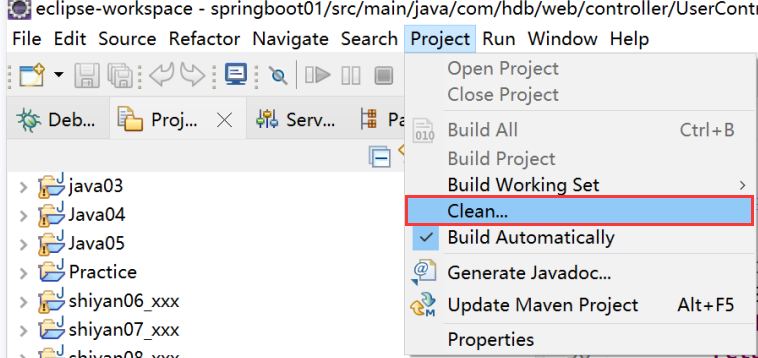
eclipse安装lombok插件
lombok插件下载:Download 下载完成,lombok.jar放到eclipse根目录,双击jar运行 运行界面,点击Install安装。 安装完成,重启IDE,rebuild 项目。 rebuild 项目...

故障演练 | 微服务架构下如何做好故障演练
前言 微服务架构场景中,应用系统复杂切分散。长期运行时,局部出现故障时不可避免的。如果发生故障时不能进行有效反应,系统的可用性将极大地降低。 什么是故障演练 故障演练是指模拟生产环境中可能出现的故障,测试系统或应用在…...
Python爬虫-获取汽车之家车家号
前言 本文是该专栏的第9篇,后面会持续分享python爬虫案例干货,记得关注。 地址:aHR0cHM6Ly9jaGVqaWFoYW8uYXV0b2hvbWUuY29tLmNuL0F1dGhvcnMjcHZhcmVhaWQ9MjgwODEwNA== 需求:获取汽车之家车家号数据 笔者将在正文中介绍详细的思路以及采集方法,废话不多说,跟着笔者直接往…...

No195.精选前端面试题,享受每天的挑战和学习
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...

pytest与testNg自动化框架
一.pytest 1.安装pytest: pip install pytest 2.编写用例 - 收集用例 - 执行用例 - 生成报告 3.pytest如何自动识别用例 识别规则如下: 1、搜索根目录:默认从当前目录中搜集测试用例,即在哪个目录下运行pytest命令,…...

数据库安全:Hadoop 未授权访问-命令执行漏洞.
数据库安全:Hadoop 未授权访问-命令执行漏洞. Hadoop 未授权访问主要是因为 Hadoop YARN 资源管理系统配置不当,导致可以未经授权进行访问,从而被攻击者恶意利用。攻击者无需认证即可通过 RESTAPI 部署任务来执行任意指令,最终完…...

前端---认识HTML
文章目录 什么是HTML?HTML的读取、运行HTML的标签注释标签标题标签段落标签换行标签格式化标签图片标签a标签表格标签列表标签表单标签form标签input标签文本框单选框复选框普通按钮提交按钮文件选择框 select标签textarea标签特殊标签div标签span标签 什么是HTML&a…...
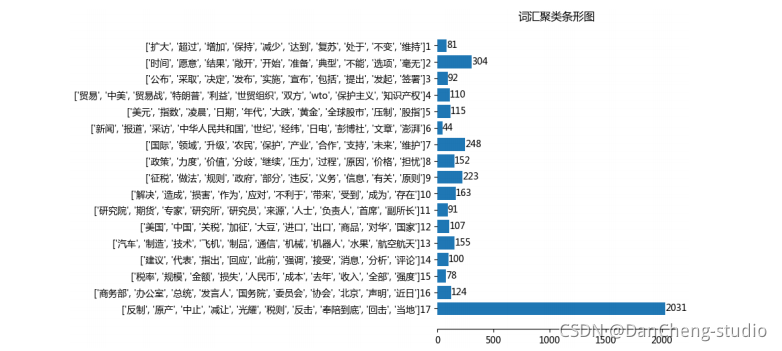
竞赛 题目:基于FP-Growth的新闻挖掘算法系统的设计与实现
文章目录 0 前言1 项目背景2 算法架构3 FP-Growth算法原理3.1 FP树3.2 算法过程3.3 算法实现3.3.1 构建FP树 3.4 从FP树中挖掘频繁项集 4 系统设计展示5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 基于FP-Growth的新闻挖掘算法系统的设计与实现…...

保姆级jupyter lab配置清单
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...
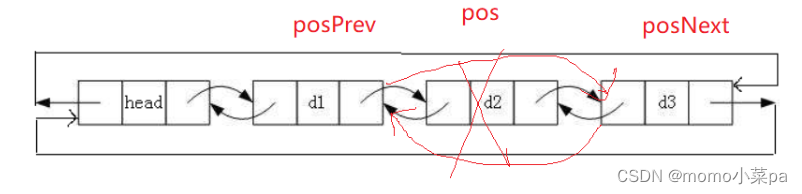
数据结构预算法--链表(单链表,双向链表)
1.链表 目录 1.链表 1.1链表的概念及结构 1.2 链表的分类 2.单链表的实现(不带哨兵位) 2.1接口函数 2.2函数的实现 3.双向链表的实现(带哨兵位) 3.1接口函数 3.2函数的实现 1.1链表的概念及结构 概念:链表是一种物理存储结…...

数据结构线性表——栈
前言:哈喽小伙伴们,今天我们将一起进入数据结构线性表的第四篇章——栈的讲解,栈还是比较简单的哦,跟紧博主的思路,不要掉队哦。 目录 一.什么是栈 二.如何实现栈 三.栈的实现 栈的初始化 四.栈的操作 1.数据入栈…...

自定义 springboot 启动器 starter 与自动装配原理
Maven 依赖 classpath 类路径管理 Maven 项目中的类路径添加来源分为三类 自定义 springboot starter starter 启动器定义的规则自定义 starter 示例 自动装配 文章链接...

16 _ 二分查找(下):如何快速定位IP对应的省份地址?
通过IP地址来查找IP归属地的功能,不知道你有没有用过?没用过也没关系,你现在可以打开百度,在搜索框里随便输一个IP地址,就会看到它的归属地。 这个功能并不复杂,它是通过维护一个很大的IP地址库来实现的。地址库中包括IP地址范围和归属地的对应关系。 当我们想要查询202…...

vb.net圣经带快捷键,用原装的数据库
Imports System.Data.SqlServerCe Imports System.Text.RegularExpressions Imports System.Data.OleDbPublic Class Form1Dim jiuyue As String() {"创", "出", "利", "民", "申", "书", "士", "…...
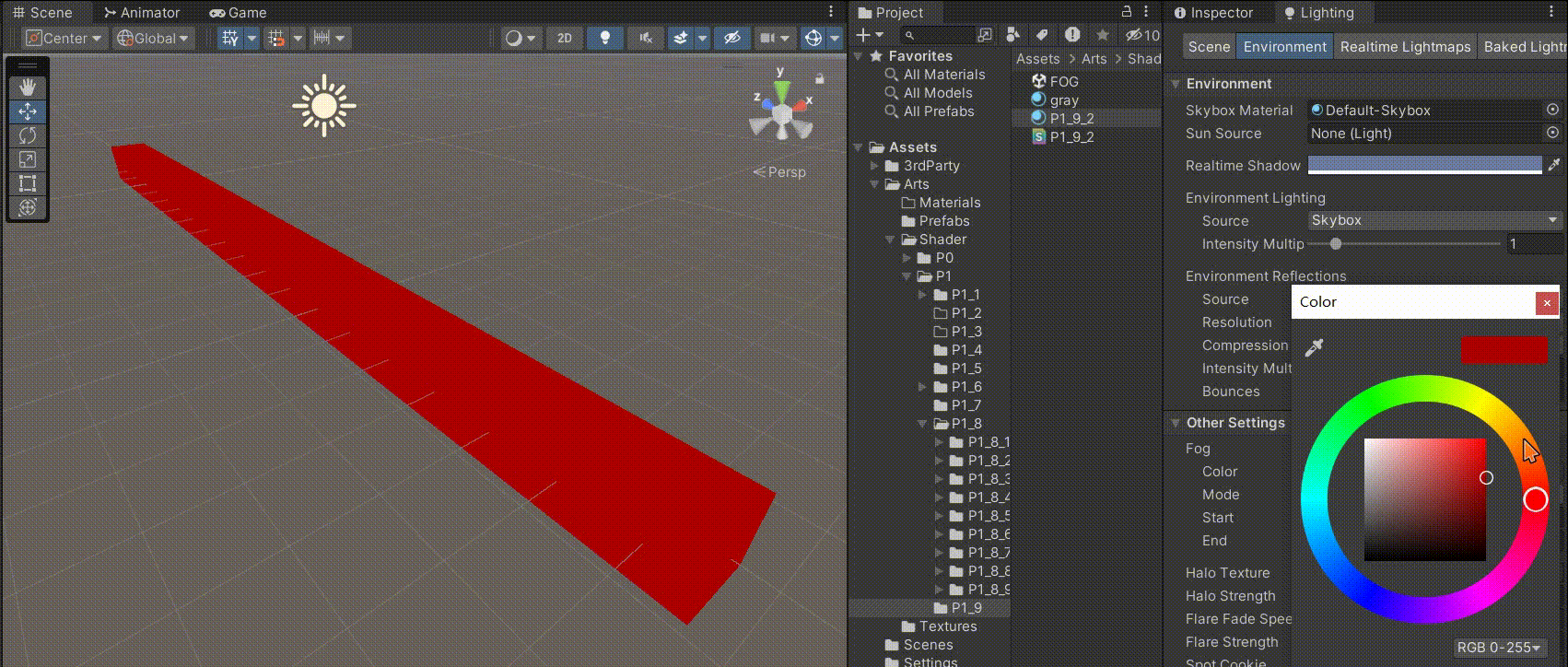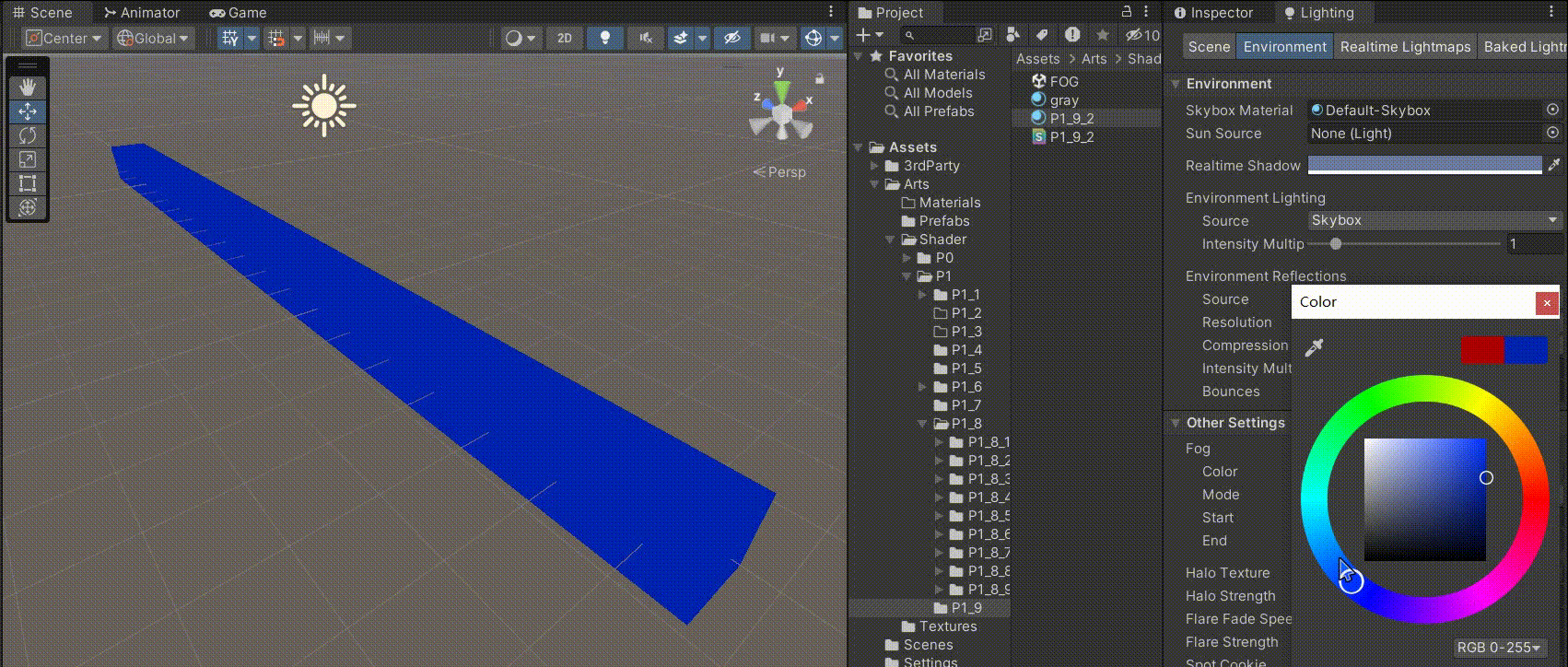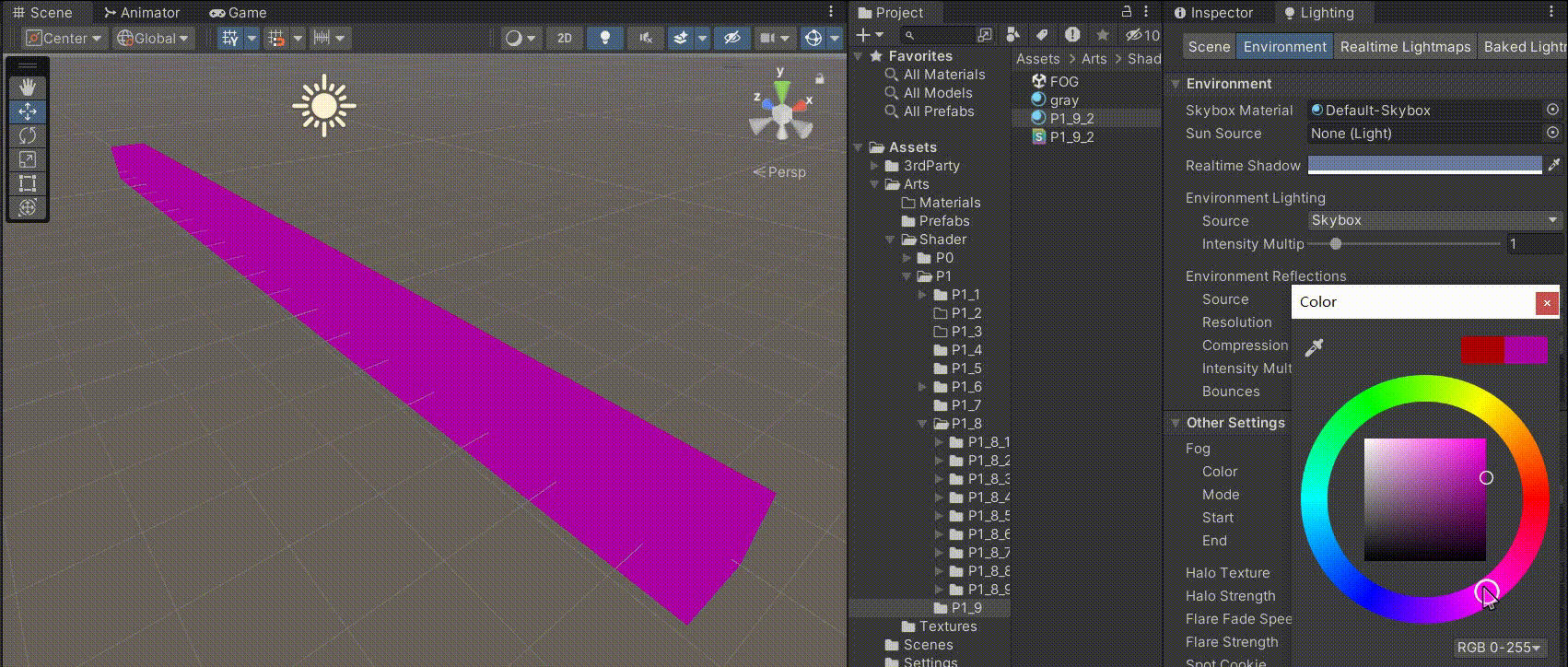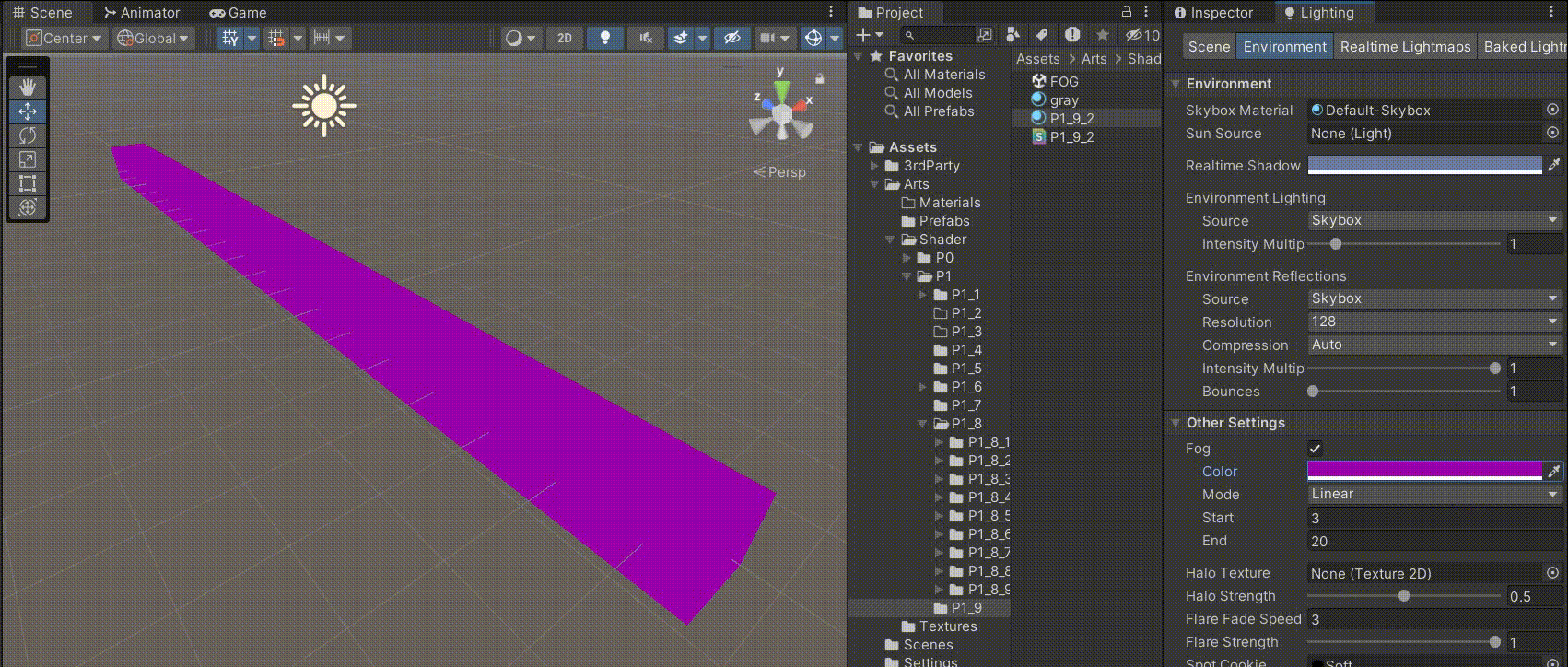
Unity中Shader的雾效
文章目录 前言一、Unity中的雾效在哪开启二、Unity中不同种类雾的区别1、线性雾2、指数雾1(推荐用这个,兼具效果和性能)3、指数雾2(效果更真实,性能消耗多) 三、在我们自己的Shader中实现判断,是…...

React Native Interactable跨平台开发终极指南:iOS与Android差异处理技巧
React Native Interactable跨平台开发终极指南:iOS与Android差异处理技巧 【免费下载链接】react-native-interactable Experimental implementation of high performance interactable views in React Native 项目地址: https://gitcode.com/gh_mirrors/re/react…...

pe_to_shellcode测试验证:如何确保PE转换后的功能完整性
pe_to_shellcode测试验证:如何确保PE转换后的功能完整性 【免费下载链接】pe_to_shellcode Converts PE into a shellcode 项目地址: https://gitcode.com/gh_mirrors/pe/pe_to_shellcode pe_to_shellcode是一款专业的PE转shellcode工具,能够将可…...

Blender模型导入Unity材质丢失?5步搞定FBX材质完美迁移
Blender模型导入Unity材质丢失?5步搞定FBX材质完美迁移 当你花了数小时在Blender中精心雕琢模型材质,导出FBX到Unity后却发现材质全部丢失——这种崩溃感每个3D开发者都深有体会。材质丢失问题看似简单,实则涉及Blender与Unity两套完全不同的…...

从晶体管到ALU:计算机运算基础全解析
1. 从晶体管到二进制:计算机运算的物理基础现代计算机的核心运算能力源于晶体管这一基础电子元件的巧妙运用。晶体管本质上是一个由半导体材料制成的三端器件,通过控制其中一个电极(基极或栅极)的电压,可以精确控制另外…...

百度飞桨PaddleOCR图片印章检测技术简介
百度飞桨PaddleOCR图片印章检测技术简介 全文链接 百度飞桨PaddleOCR图片印章检测技术简介 github仓库:使用PaddleOCR识别图片红色印章文字 red-seal-ocr 3.X和2.X区别较大,建议使用3.X版本。 PaddleX简介 PaddleX github地址PaddleX模型产线使用概览…...

2025届必备的六大降重复率助手横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 纵然人工智能辅助毕业论文写作现如今已然成为一种学术方面的新常态,可是却需要去…...

嵌入式IMU姿态解算:轻量级卡尔曼滤波器实现Pitch/Roll估计
1. 项目概述Kalman滤波器库是一个面向嵌入式姿态解算的轻量级C语言实现,专为资源受限的MCU(如STM32F0/F1/F4系列、nRF52、ESP32等)设计。其核心工程目标明确:在无磁力计辅助、仅依赖IMU原始数据(加速度计陀螺仪&#x…...

Maven父子工程搭建:微服务项目模块化架构基础
Maven父子工程搭建:微服务项目模块化架构基础 一、为什么需要Maven父子工程? 在单体应用向微服务架构演进的过程中,项目规模会迅速膨胀。想象一个电商系统,包含用户中心、商品服务、订单服务、支付服务、库存服务等数十个模块—…...

Unity WebGL小游戏上抖音,从踩坑到上线:一份避坑指南与性能优化清单
Unity WebGL小游戏上抖音:性能优化与避坑实战手册 当你第一次将Unity WebGL小游戏发布到抖音平台时,可能会遇到各种意想不到的性能瓶颈和兼容性问题。iOS设备上的内存限制、WebGL与Native的性能差距、包体大小控制等挑战,都可能让原本流畅的游…...

不只是投屏:挖掘Scrcpy + ADB在Mac上的高阶玩法,提升开发调试效率
不只是投屏:挖掘Scrcpy ADB在Mac上的高阶玩法,提升开发调试效率 在移动应用开发与测试的日常工作中,效率工具的选择往往决定了生产力水平。Scrcpy作为一款开源的安卓设备投屏工具,其价值远不止于简单的屏幕镜像。当它与ADB&#…...