Pytorch自动混合精度的计算:torch.cuda.amp.autocast
1 autocast介绍
1.1 什么是AMP?
默认情况下,大多数深度学习框架都采用32位浮点算法进行训练。2017年,NVIDIA研究了一种用于混合精度训练的方法,该方法在训练网络时将单精度(FP32)与半精度(FP16)结合在一起,并使用相同的超参数实现了与FP32几乎相同的精度。
FP16也即半精度是一种计算机使用的二进制浮点数据类型,使用2字节存储。而FLOAT就是FP32。
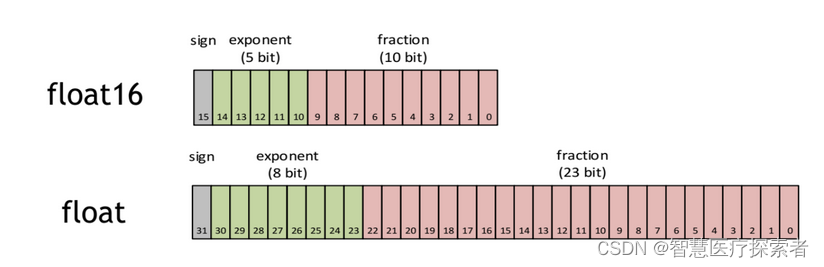
1.2 autocast作用
torch.cuda.amp.autocast是PyTorch中一种混合精度的技术(仅在GPU上训练时可使用),可在保持数值精度的情况下提高训练速度和减少显存占用。
def __init__(self, enabled : bool = True, dtype : torch.dtype = torch.float16, cache_enabled : bool = True):
它是一个自动类型转换器,可以根据输入数据的类型自动选择合适的精度进行计算,从而使得计算速度更快,同时也能够节省显存的使用。使用autocast可以避免在模型训练过程中手动进行类型转换,减少了代码实现的复杂性。
在深度学习中,通常会使用浮点数进行计算,但是浮点数需要占用更多的显存,而低精度数值可以在减少精度的同时,减少缓存使用量。因此,对于正向传播和反向传播中的大多数计算,可以使用低精度型的数值,提高内存使用效率,进而提高模型的训练速度。
1.3 autocast原理
autocast的要做的事情,简单来说就是:在进入算子计算之前,选择性的对输入进行cast操作。为了做到这点,在PyTorch1.9版本的架构上,可以分解为如下两步:
- 在PyTorch算子调用栈上某一层插入处理函数
- 在处理函数中对算子的输入进行必要操作
核心代码:autocast_mode.cpp
2 autocast优缺点
PyTorch中的autocast功能是一个性能优化工具,它可以自动调整某些操作的数据类型以提高效率。具体来说,它允许自动将数据类型从32位浮点(float32)转换为16位浮点(float16),这通常在使用深度学习模型进行训练时使用。
2.1 autocast优点
-
提高性能:使用16位浮点数(half precision)进行计算可以在支持的硬件上显著提高性能,特别是在最新的GPU上。
-
减少内存占用:16位浮点数占用的内存比32位少,这意味着在相同的内存限制下可以训练更大的模型或使用更大的批量大小。
-
自动管理:
autocast能够自动管理何时使用16位浮点数,何时使用32位浮点数,这降低了手动管理数据类型的复杂性。 -
保持精度:尽管使用了较低的精度,但
autocast通常能够维持足够的数值精度,对最终模型的准确度影响不大。
2.2 autocast缺点
-
硬件要求:并非所有的GPU都支持16位浮点数的高效运算。在不支持或优化不足的硬件上,使用
autocast可能不会带来性能提升。 -
精度问题:虽然在大多数情况下精度损失不显著,但在某些应用中,尤其是涉及到小数值或非常大的数值范围时,降低精度可能会导致问题。
-
调试复杂性:由于
autocast在模型的不同部分自动切换数据类型,这可能会在调试时增加额外的复杂性。 -
算法限制:某些特定的算法或操作可能不适合在16位精度下运行,或者在半精度下的实现可能还不成熟。
-
兼容性问题:某些PyTorch的特性或第三方库可能还不完全支持半精度运算。
在实际应用中,是否使用autocast通常取决于特定任务的需求、所使用的硬件以及对性能和精度的权衡。通常,对于大多数现代深度学习应用,特别是在使用最新的GPU时,使用autocast可以带来显著的性能优势。
3 使用示例
3.1 autocast混合精度计算
with autocast(): 语句块内的代码会自动进行混合精度计算,也就是根据输入数据的类型自动选择合适的精度进行计算,并且这里使用了GPU进行加速。使用示例如下:
# 导入相关库
import torch
from torch.cuda.amp import autocast# 定义一个模型
class MyModel(torch.nn.Module):def __init__(self):super(MyModel, self).__init__()self.linear = torch.nn.Linear(10, 1)def forward(self, x):with autocast():x = self.linear(x)return x# 初始化数据和模型
x = torch.randn(1, 10).cuda()
model = MyModel().cuda()# 进行前向传播
with autocast():output = model(x)# 计算损失
loss = output.sum()# 反向传播
loss.backward()3.2 autocast与GradScaler一起使用
因为autocast会损失部分精度,从而导致梯度消失的问题,并且经过中间层时可能计算得到inf导致最终loss出现nan。所以我们通常将GradScaler与autocast配合使用来对梯度值进行一些放缩,来缓解上述的一些问题。
from torch.cuda.amp import autocast, GradScalerdataloader = ...
model = Model.cuda(0)
optimizer = ...
scheduler = ...
scaler = GradScaler() # 新建GradScale对象,用于放缩
for epoch_idx in range(epochs):for batch_idx, (dataset) in enumerate(dataloader):optimizer.zero_grad()dataset = dataset.cuda(0)with autocast(): # 自动混精度logits = model(dataset)loss = ...scaler.scale(loss).backward() # scaler实现的反向误差传播scaler.step(optimizer) # 优化器中的值也需要放缩scaler.update() # 更新scalerscheduler.step()
...4 可能出现的问题
使用autocast技术进行混精度训练时loss经常会出现'nan',有以下三种可能原因:
- 精度损失,有效位数减少,导致输出时数据末位的值被省去,最终出现nan的现象。该情况可以使用GradScaler(上文所示)来解决。
- 损失函数中使用了log等形式的函数,或是变量出现在了分母中,并且训练时,该数值变得非常小时,混精度可能会让该值更接近0或是等于0,导致了数学上的log(0)或是x/0的情况出现,从而出现'inf'或'nan'的问题。这种时候需要针对该问题设置一个确定值。例如:当log(x)出现-inf的时候,我们直接将输出中该位置的-inf设置为-100,即可解决这一问题。
- 模型内部存在的问题,比如模型过深,本身梯度回传时值已经非常小。这种问题难以解决。
相关文章:
Pytorch自动混合精度的计算:torch.cuda.amp.autocast
1 autocast介绍 1.1 什么是AMP? 默认情况下,大多数深度学习框架都采用32位浮点算法进行训练。2017年,NVIDIA研究了一种用于混合精度训练的方法,该方法在训练网络时将单精度(FP32)与半精度(FP16)结合在一起ÿ…...
一文看懂香港优才计划和高才通计划的区别和优势?如何选?
一文看懂香港优才计划和高才通计划的区别和优势?如何选? 为什么很多人都渴望有个香港身份? 英文这里和内地文化相近,语言相通,同时税率较低、没有外汇管制,有稳定金融体制和良好的营商环境,诸多…...

DTC Network旗下代币DSTC大蒜头即将上线,市场热度飙升
全球数字资产领导者DTC Network宣布其代币DSTC(大蒜头)即将于近期上线,引发市场广泛关注。DTC Network以其创新性的区块链技术和多维度的网络构建,致力于打造一个融合Web3.0、元宇宙和DAPP应用的去中心化聚合公共平台,…...
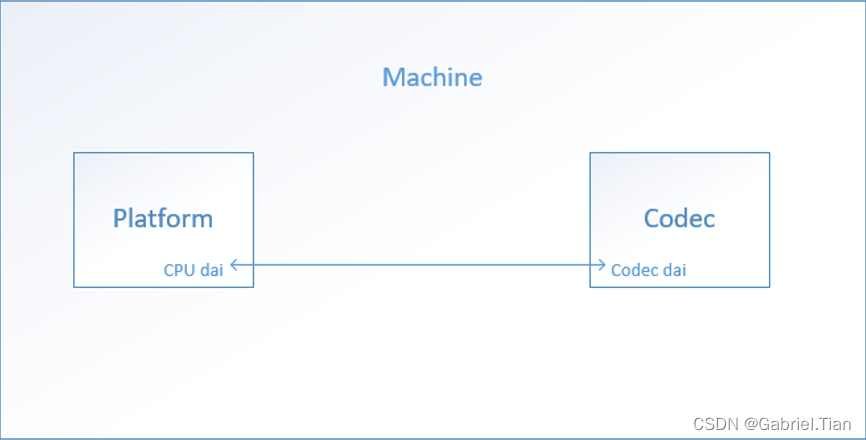
高通SDX12:ASoC 音频框架浅析
一、简介 ASoC–ALSA System on Chip ,是建立在标准ALSA驱动层上,为了更好地支持嵌入式处理器和移动设备中的音频Codec的一套软件体系。 本文基于高通SDX12平台,对ASoC框架做一个分析。 二、整体框架 1. 硬件层面 嵌入式Linux设备的Audio subsystem可以划分为Machine(板…...

国际化:i18n
什么是国际化? 国际化也称作i18n,其来源是英文单词 internationalization的首末字符和n,18为中间的字符数。由于软件发行可能面向多个国家,对于不同国家的用户,软件显示不同语言的过程就是国际化。通常来讲࿰…...
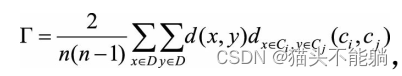
【机器学习5】无监督学习聚类
相比于监督学习, 非监督学习的输入数据没有标签信息, 需要通过算法模型来挖掘数据内在的结构和模式。 非监督学习主要包含两大类学习方法: 数据聚类和特征变量关联。 1 K均值聚类及优化及改进模型 1.1 K-means 聚类是在事先并不知道任何样…...

风景照片不够清晰锐利,四招帮你轻松解决
我们大家在拍摄风景照的时候都希望能够拍摄出清晰锐利的照片。可能会有人问:“什么是锐利?”我们可以从锐度来给大家简单解说下。锐度是反映图片平面清晰度和图像边缘对比度的一个参数。锐度较高的画面,微小的细节部分也会表现得很清晰&#…...

List中的迭代器实现【C++】
List中的迭代器实现【C】 一. list的结构二. 迭代器的区别三. 迭代器的实现i. 类的设计ii. 重载iii. !重载iiii. begin()iiiii. end()iiiii. operator* 四.测试五. const迭代器的实现i. 实现ii 优化实现 六. 整体代码 一. list的结构 其实按照习惯来说,应该要专门出…...
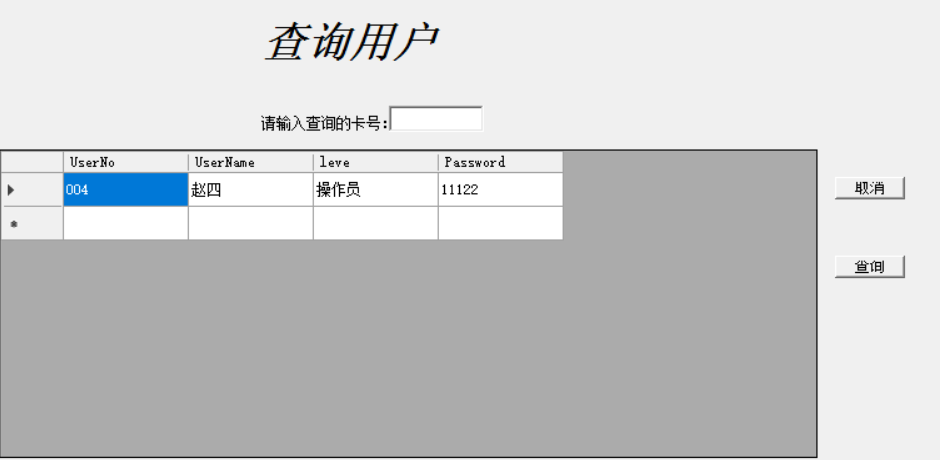
VB.NET三层之用户查询窗体
目录 前言: 过程: UI层代码展示: BLL层代码展示: DAL层代码展示: 查询用户效果图: 总结: 前言: 想要对用户进行查询,需要用到控件DataGrideView,通过代码的形式将数据库表中的数据显示在DataGrideview控件中,不用对DatGridView控件…...
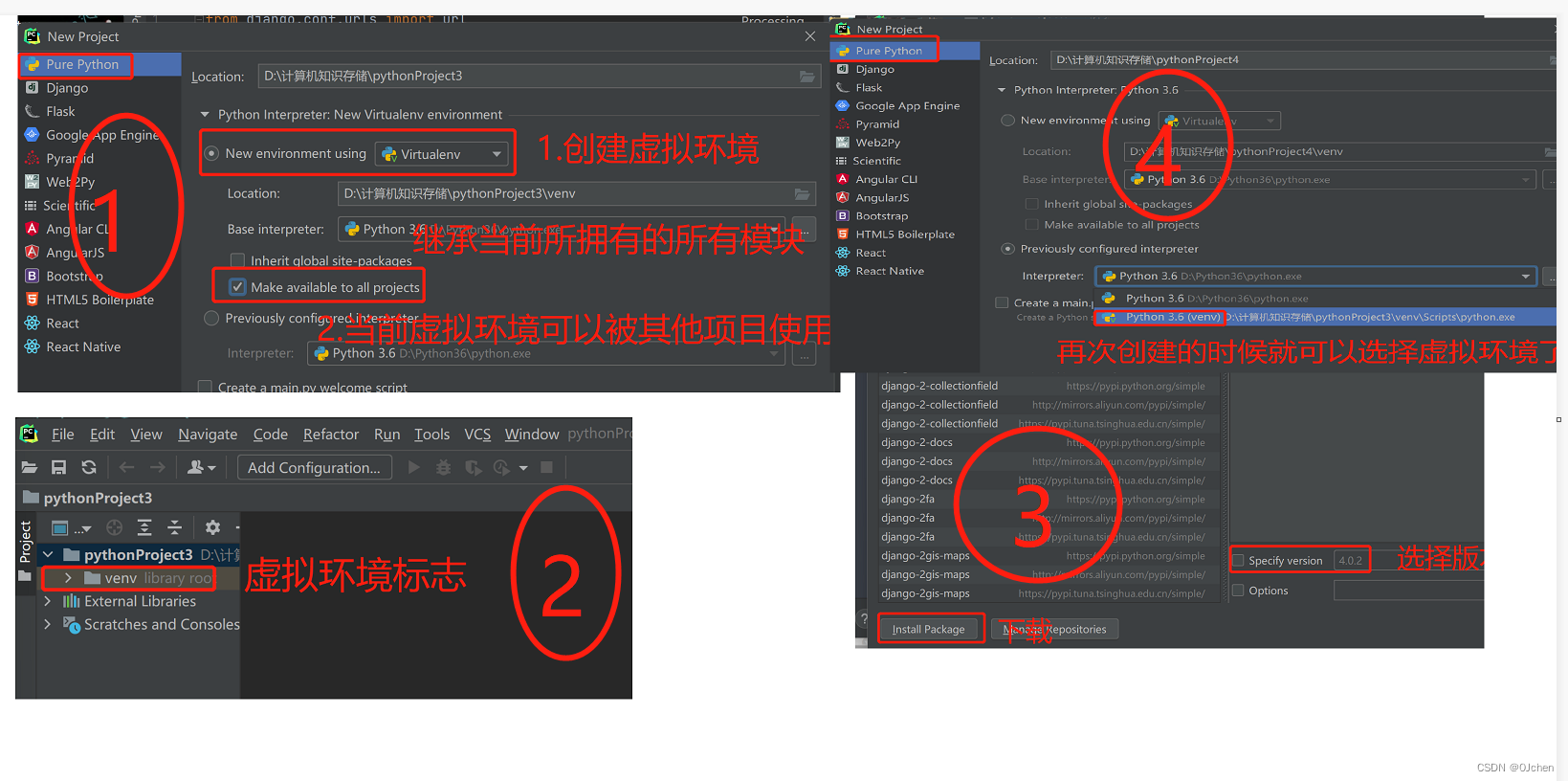
Django之路由层
文章目录 路由匹配语法路由配置注意事项转换器注册自定义转化器 无名分组和有名分组无名分组有名分组 反向解析简介普通反向解析无名分组、有名分组之反向解析 路由分发简介为什么要用路由分发?路由分发实现 伪静态的概念名称空间虚拟环境什么是虚拟环境?…...
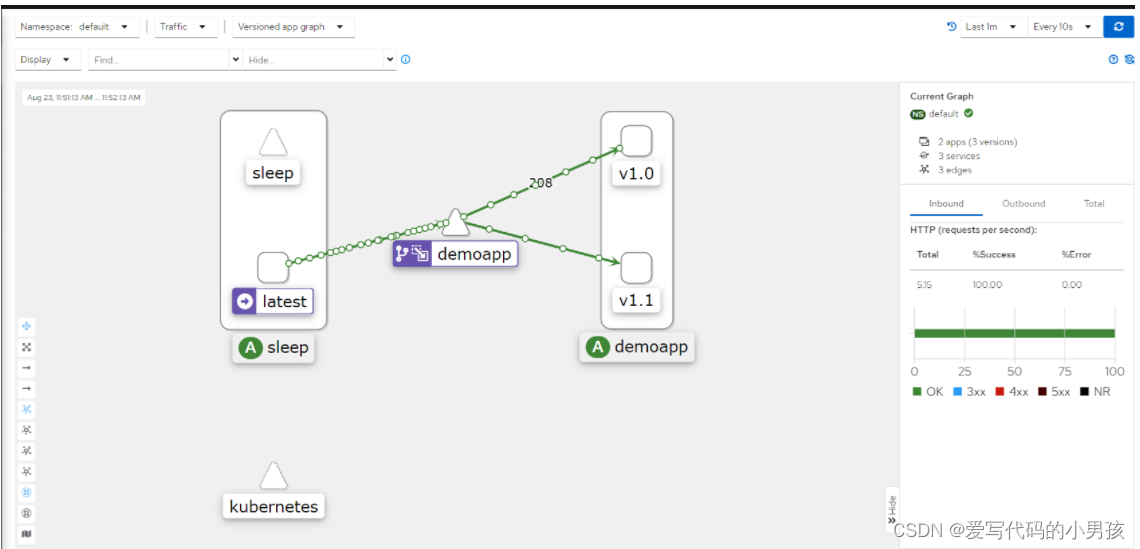
【06】VirtualService高级流量功能
5.3 weight 部署demoapp v10和v11版本 --- apiVersion: apps/v1 kind: Deployment metadata:labels:app: demoappv10version: v1.0name: demoappv10 spec:progressDeadlineSeconds: 600replicas: 3selector:matchLabels:app: demoappversion: v1.0template:metadata:labels:app…...

322. 零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。 你可以认为每种硬币的数量是无限的。 示…...
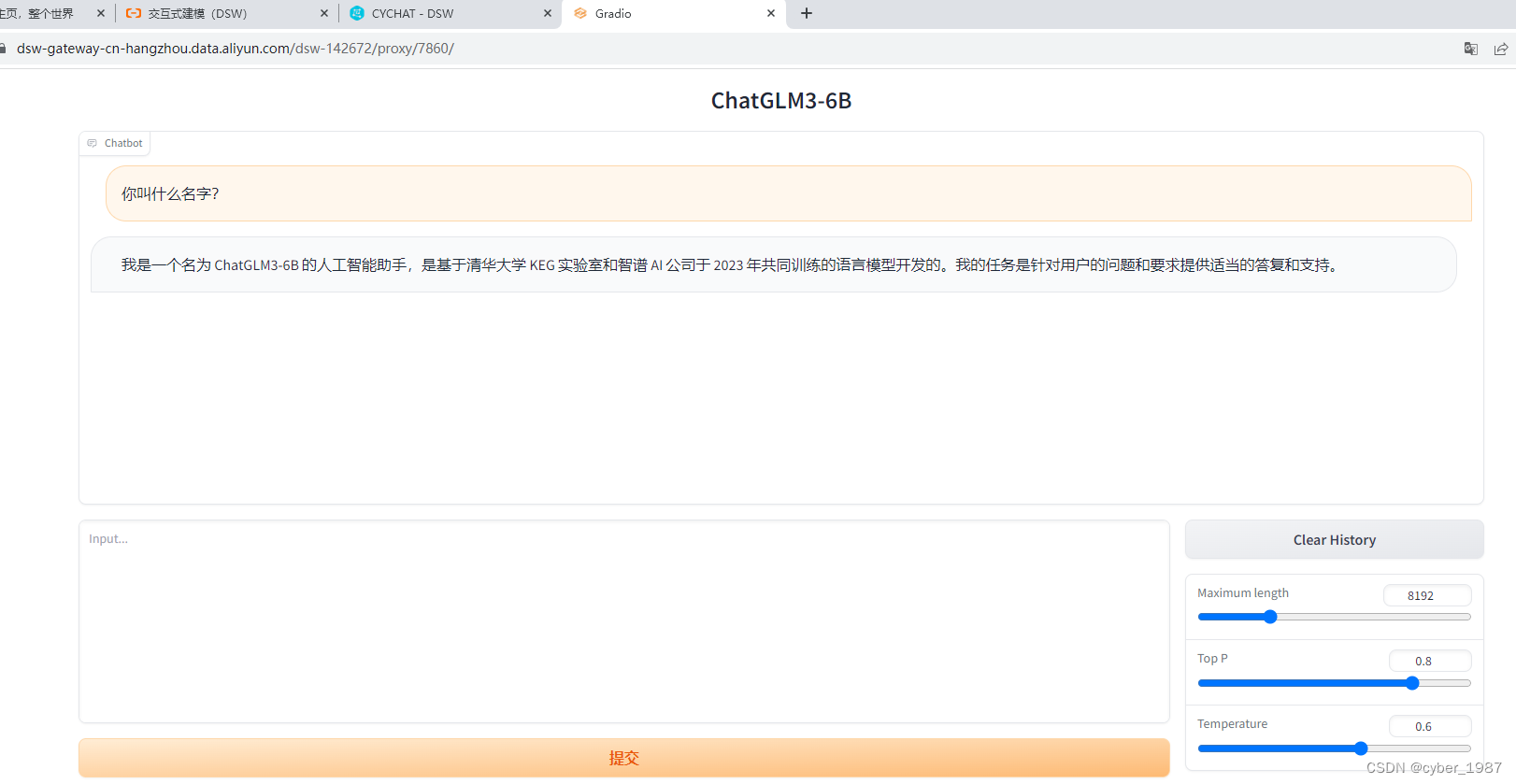
【大模型-第一篇】在阿里云上部署ChatGLM3
前言 好久没写博客了,最近大模型盛行,尤其是ChatGLM3上线,所以想部署试验一下。 本篇只是第一篇,仅仅只是部署而已,没有FINETUNE、没有Langchain更没有外挂知识库,所以从申请资源——>开通虚机——>…...

2023-11-14 mysql-主从复制-相关文档
摘要: 2023-11-14 mysql-主从复制-相关文档 官方文档: MySQL :: MySQL 8.0 Reference Manual :: 17 Replication MySQL :: MySQL 8.0 Reference Manual :: 18 Group Replication 相关参数: mysql> show variables like %repl%; +-----------------------------------------…...
ios 对话框 弹框,输入对话框 普通对话框
1 普通对话框 UIAlertController* alert [UIAlertController alertControllerWithTitle:"a" message:"alert12222fdsfs" pr…...
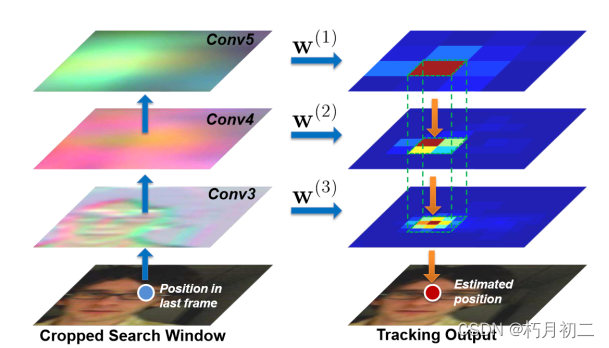
(论文阅读23/100)Hierarchical Convolutional Features for Visual Tracking
文献阅读笔记(分层卷积特征) 简介 题目 Hierarchical Convolutional Features for Visual Tracking 作者 Chao Ma, Jia-Bin Huang, Xiaokang Yang and Ming-Hsuan Yang 原文链接 arxiv.org/pdf/1707.03816.pdf 关键词 Hierarchical convolution…...

基于IGT-DSER智能网关实现GE的PAC/PLC与罗克韦尔(AB)的PLC之间通讯
工业自动化领域的IGT-DSER智能网关模块支持GE、西门子、三菱、欧姆龙、AB等各种品牌的PLC之间通讯(相关资料下载),同时也支持PLC与Modbus协议的工业机器人、智能仪表等设备通讯。网关有多个网口、串口,也可选择WIFI无线通讯。无需编程开发,只…...

创建符合 Web 可访问性标准的 HTML 布局
人们常说网络可访问性是当今万维网的“必须”。“Web 可访问性”一词定义了开发人员需要遵循的一组准则,以使残障人士和 Web 应用程序的交互更加方便。任何网站的内容、UI/UX 设计和布局都应该易于访问。在本文中,Logicify团队为 HTML/CSS 开发人员提供了…...
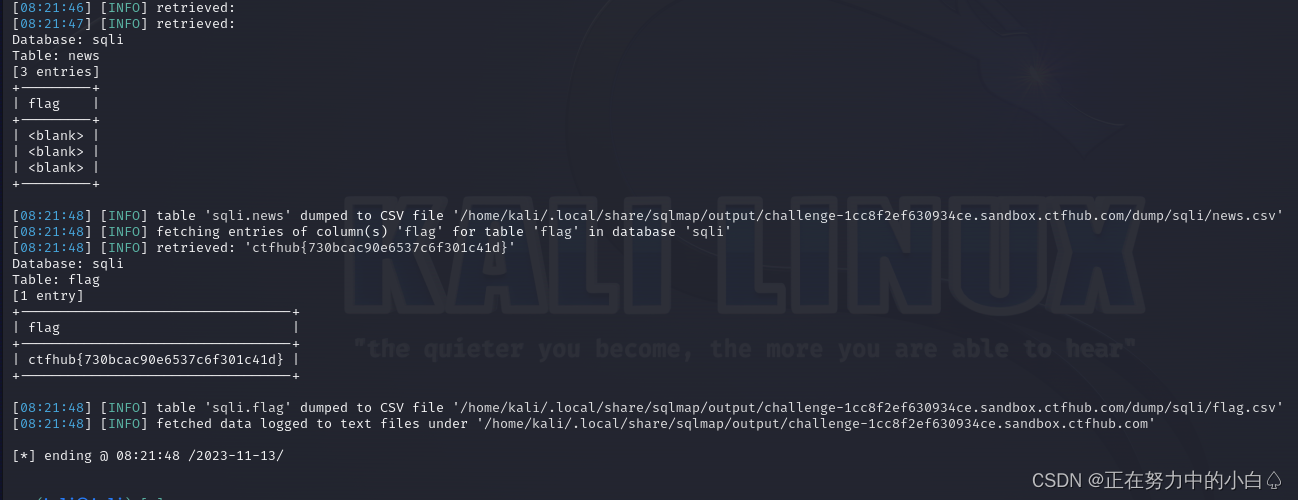
SQL学习(CTFhub)整数型注入,字符型注入,报错注入 -----手工注入+ sqlmap注入
目录 整数型注入 手工注入 为什么要将1设置为-1呢? sqlmap注入 sqlmap注入步骤: 字符型注入 手工注入 sqlmap注入 报错注入 手工注入 sqlmap注入 整数型注入 手工注入 先输入1 接着尝试2,3,2有回显,而3没有回显…...

数字人部署之VITS+Wav2lip数据流转处理以提高实时性
一、模型 VITS模型训练教程VITS-从零开始微调(finetune)训练并部署指南-支持本地云端 Wav2lip是2D数字人,可参考训练嘴型同步模型Wav2Lip PS:以上模型都是开源可用。 二. VITS数据处理问题 VITS模型的输出为一维的numpy类型数据ÿ…...

PostgreSQL CASE语句深度解析:性能、类型与NULL安全实战指南
1. 为什么你必须真正吃透 PostgreSQL 的 CASE 语句——它远不止是 SQL 里的“if-else”翻译器在 PostgreSQL 实战中,我见过太多人把CASE当成一个语法糖:写几个WHEN...THEN,加个ELSE,再套个END,就以为搞定了。结果呢&am…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

MeloTTS实战:多语言语音合成的高效解决方案
MeloTTS实战:多语言语音合成的高效解决方案 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trending/me/…...

终极音乐解锁指南:3步让加密音乐在任何设备自由播放
终极音乐解锁指南:3步让加密音乐在任何设备自由播放 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

智能知识学习平台
智能知识学习平台项目简介技术架构:问答驱动的开发模式前端架构后端架构核心功能:问答式交互贯穿始终1. 自定义构建知识库2.文档查看3.智能问答:知识触手可及4. 智能题目生成:严格遵循文档内容项目亮点用问答驱动的方式构建智慧学…...

语音AI落地最后一公里卡点,PlayAI质量波动真相:采样率适配缺陷、韵律断层、情感衰减三大隐性陷阱
更多请点击: https://intelliparadigm.com 第一章:PlayAI语音质量评测报告总览 PlayAI语音质量评测体系基于客观指标与主观听感双维度构建,覆盖清晰度、自然度、时延、抗噪性及情感一致性五大核心能力。本报告汇总了在标准测试集(…...

终极空洞骑士模组管理器 Lumafly:跨平台一键安装与智能依赖管理指南
终极空洞骑士模组管理器 Lumafly:跨平台一键安装与智能依赖管理指南 【免费下载链接】Lumafly A cross platform mod manager for Hollow Knight written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/lu/Lumafly Lumafly 是一款基于 Avalonia 框…...

Steam Achievement Manager:5分钟掌握游戏成就管理终极技巧
Steam Achievement Manager:5分钟掌握游戏成就管理终极技巧 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager&#x…...