Django之路由层
文章目录
- 路由匹配
- 语法
- 路由配置注意事项
- 转换器
- 注册自定义转化器
- 无名分组和有名分组
- 无名分组
- 有名分组
- 反向解析
- 简介
- 普通反向解析
- 无名分组、有名分组之反向解析
- 路由分发
- 简介
- 为什么要用路由分发?
- 路由分发实现
- 伪静态的概念
- 名称空间
- 虚拟环境
- 什么是虚拟环境?
- 如何创建虚拟环境?
- 终端命令
- pycharm创建虚拟环境
- Django1.x与2.x版本的区别
路由匹配
路由匹配的特点是,只要匹配上来 就会立刻结束执行对应的视图函数
语法
Django2、3用的路由匹配都是path,完整语法path(‘网址后缀’,函数名)
Django1用的路由匹配是urls,完整语法url(r’^网址后缀’, 函数名)
在django1.x版本中,路由 第一个参数是正则表达式,第二个参数是函数名url(r'^admin/', 函数名),在django2.x及以上版本:path第一个参数写什么就匹配什么(精准匹配),匹配到直接执行对应的视图函数path('admin/',函数名), '这种写法不支持正则表达式'当然2.x版本也有可以使用正则匹配的方式:re_path(正则表达式,函数名) '其作用和django1.x的url使用效果一模一样'
路由配置注意事项
1.正则表达式不需要添加一个前导的反斜杠,因为每个URL都有。例如,应该是^index而不是 ^/index2.每个正则表达式前面的'r' 是可选的但是建议加上。它告诉Python 这个字符串是“原始的” —— 字符串中任何字符都不应该转义3.如果我们想匹配的路径就只是index/,那么正则表达式应该有开始符与结束符, 如 ^index/$。这样逻辑才算严谨4.路由结尾的斜杠我们在输入网址的时候与正确网址确实一个/ 但是成功进去了默认情况下不写斜杠 django会做二次处理第一次匹配不上,会让浏览器加斜杠再次请求'''如果我们想要少了'/'则进不去就得去django配置文件中指定是否自动添加斜杠(到settings文件中末尾添加)APPEND_SLASH = False,当配置文件中没有这个配置时,APPEND_SLASH的值是True''''''注意: 在输入一次url地址后,浏览器会将其记录到缓存中,若第二次输入相同的url地址,浏览器也会直接在url地址后 填充/结尾,如果想规避浏览器缓存的影响,可以像下面这么测试,并且每次测试都换一下?后的变量,保证url地址每次都不同http://127.0.0.1:8000/index?aaaaa=111111 对应视图函数index1http://127.0.0.1:8000/index/?aaaaa=22222 对应视图函数index2''' '由于第一个参数是正则,所以当项目特别大,对应关系特别多的时候要格外注意是否会出现路由顶替的现象'小拓展:可以定制一个主页面,用户不懈怠后缀可以直接访问url(r'^$',views.index)也可以定义一个尾页,用户输入一个没有对象关系的直接返回url(r'.*',views.error)
注意事项五:
按照匹配规则,是从上到下只要正则表达式匹配成功,就不会往下执行。
例子:
当浏览器要打开下面的web网页接口 ?URL=127.0.0.1:8000/testadd路由层代码展示:urlpatterns = [url('test',views.test),url('testadd',views.testadd)]视图层代码展示:def test(request):return HttpResponse('from test')def testadd(request):return HttpResponse('from testadd')
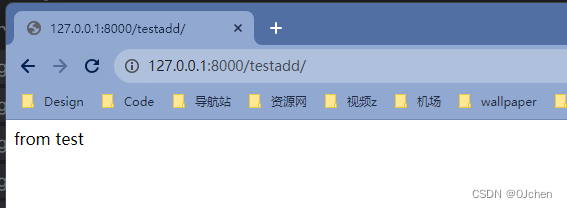
当路由匹配到第一个正则(test)就成功匹配了,就不会继续往下执行。
因为按照路由的匹配规则,从上到下只要正则表达式匹配成功,就不会继续往下执行了
如何解决上述问题?
方式1:
我们在输入URL默认会加斜杠,因为django内部帮我们做了重定向,一次匹配不行,url后面加斜杠再来一次按照下面的顺序依次匹配url('test/',views.test),url('testadd/',views.testadd)
方式2:
settings配置文件内添加(控制django是否自动添加斜杠匹配APPEND_SLASH = False/True # 默认是True自动添加斜杠
事项五其本质还是因为url方式是使用得正则表达式来匹配的原因,如果真正想要
精准匹配到想要的那最好是给网址后缀加上开始符和结束符如url(‘^index/$’)。
转换器
正常情况下很多网站都会有很多相似的网址,如果我们每一个都单独开设路由不合理django2.x及以上版本路由动态匹配有转换器(五种)str:匹配除路径分隔符外的任何非空字符串。 StringConverter()int:匹配0或者任意正整数。 IntConverter()slug:匹配任意一个由字母或数字组成的字符串。 SlugConverter()uuid:匹配格式化后的UUID。 UUIDConverter()path:能够匹配完整的URL路径。 PathConverter()'还支持自定义转换器(自己写正则表达式匹配更加细化内容)''转换器 将对应位置匹配到的数据转换成固定的数据类型'路由层:path('index/<int:year>/<str:info>/',views.index)转换器有几个名字,那么视图函数的形参就必须对应视图层:def index(request,year,info):print(year,info)return HttpResponse('from index')
注册自定义转化器
对于一些复杂或者复用的需要,可以定义自己的转化器。转化器是一个类或接口,它的要求有三点:
regex类属性,字符串类型to_python(self, value)方法,value是由类属性regex所匹配到的字符串,返回具体的Python变量值,以供Django传递到对应的视图函数中。to_url(self, value)方法,和to_python相反,value是一个具体的Python变量值,返回其字符串,通常用于url反向引用。
例子:
class FourDigitYearConverter: regex = '[0-9]{4}' def to_python(self, value): return int(value) def to_url(self, value): return '%04d' % value
使用register_converter 将其注册到URL配置中:
from django.urls import register_converter, path from . import converters, views register_converter(converters.FourDigitYearConverter, 'yyyy') urlpatterns = [ path('articles/2003/', views.special_case_2003), path('articles/<yyyy:year>/', views.year_archive), ... ]
无名分组和有名分组
无名分组
分组就是给某一段正则表达式用小括号括起来
from django.urls import path,re_pathfrom app01 import viewsurlpatterns = [re_path('^test/(\d{4})/', views.test)]无名分组:会将括号内正则表达式匹配到的内容当做位置参数传递给视图函数
注意:
- 若要从URL 中捕获一个值,只需要在它周围放置一对圆括号。
- 不需要添加一个前导的反斜杠,因为每个URL 都有。例如,应该是^articles 而不是 ^/articles。
- 每个正则表达式前面的’r’ 是可选的但是建议加上。它告诉Python 这个字符串是“原始的” —— 字符串中任何字符都不应该转义
- urlpatterns中的元素按照书写顺序从上往下逐一匹配正则表达式,一旦匹配成功则不再继续
代码实现
urls.py(路由文件)'会把括号中匹配的数字当成位置参数传给视图函数'path('^test/(\d(4))/',views.test)views.py(视图文件)def test(request,xxx):print(xxx)return HttpResponse('from test')正则: \d(4) : 匹配4个任意数字
有名分组
上面的示例使用简单的、没有命名的正则表达式组(通过圆括号)来捕获URL 中的值并以位置 参数传递给视图。在更高级的用法中,可以使用命名的正则表达式组来捕获URL 中的值并以关键字 参数传递给视图。
在Python 正则表达式中,命名正则表达式组的语法是
(?Ppattern),其中name 是组的名称,pattern 是要匹配的模式。
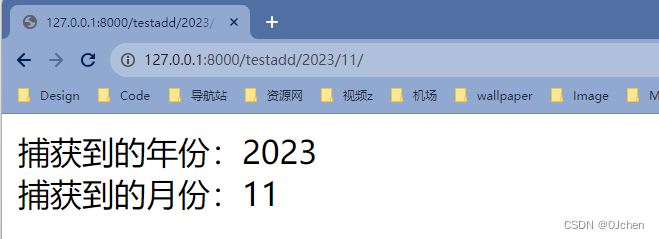
from django.urls import path,re_pathfrom app01 import viewsurlpatterns = [re_path('^testadd(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.testadd)]有名分组:会将括号内正则表达式匹配到的内容当做关键字参数传递给视图函数(捕获的值作为关键字参数而不是位置参数传递给视图函数。)注意上述的分组不能混合使用!!!def testadd(request,year,month): # 必须使用分组名才能接收到print(year,month)return HttpResponse(f'捕获到的年份:{year}<br/>捕获到的月份:{month}')
注意:有名分组可以允许有多个分组名,但不允许一个无名分组一个或者多个有名分组存在。即有名分组和无名分组不能混合是使用
单个有名或者无名分组是可以使用多次的
'''无名分组与有名分组不建议混合使用'''path('^index/(\d(4))/(?P<year>[a-z])/$',views.index) # 不建议1.无名分组单个使用多次path('^index/(\d(4))/(\d(4))/(\d(4))/',views.index),2.有名分组单个使用多次path('^index/(?P<year>\d+)/(?P<age>\d+)/(?P<month>\d+)/',views.index),def index(request,*args,**kwargs):print(args)return HttpResponse('index')
反向解析
简介
在使用Django 项目时,一个常见的需求是获得URL 的最终形式,以用于嵌入到生成的内容中(视图中和显示给用户的URL等)或者用于处理服务器端的导航(重定向等)。人们强烈希望不要硬编码这些URL(费力、不可扩展且容易产生错误)或者设计一种与URLconf 毫不相关的专门的URL 生成机制,因为这样容易导致一定程度上产生过期的URL。
在需要URL 的地方,对于不同层级,Django 提供不同的工具用于URL 反查:
- 在模板中:使用url 模板标签。
- 在Python 代码中:使用from django.urls import reverse函数
反向解析为的就是防止路由经常变动,这样我们页面的链接、或者函数的重定向就能动态获取到路由可接收的URL。
普通反向解析
要想达到反向解析也很简单,给路由设置一个别名
from django.urls import pathfrom app import viewsurlpatterns = [path('admin/', admin.site.urls),path('index/',views.index,name='index_name'),path('login/',views.login)]
此时如果模板页面需要指向这个URL提交请求的话,且这个接收的URL是不固定的,那么我们就可以使用这个路由个别名来获取它可以接收的URL。
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>Title</title></head><body><h1>登录</h1><a href="{% url 'index_name' %}">点击进入首页</a></body></html>
此时我们页面不管这个别名为:index_name的路由可接收的URL怎么变动,我们都可以直接指向它。
并且,重定向也是可以直接指向到路由别名的。
from django.shortcuts import reverse # 导入模块def index(request):return HttpResponse('from index')def login(request):print(reverse('index_name'))return render(request,'index.html')
但是!如果路由可接收的URL里面存在无名或者有名分组时,就不能这样操作了
无名分组、有名分组之反向解析
在Django1.x中,路由中使用的
url作为匹配,并且URL匹配可以使用正则
而到了Django2.x、Django3.x则改为了path匹配,只有URL完全相同的才能匹配上。
但是Django2.x、Django3.x也可以使用URL匹配使用正则,那就需要使用:re_path
路由层:urls.py
from django.urls import pathfrom app import viewsurlpatterns = [path('admin/', admin.site.urls),re_path('index/(?P<jump>[0-9])',views.index,name='index_name'),path('login/',views.login)]
此时我们的HTML文件如果要指定某个路由,但是这个路由还必须要接收一个参数,那么我们只能在后面手动指定了
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>Title</title></head><body><h1>登录</h1><a href="{% url 'index_name' 6 %}">点击进入首页</a></body></html>
而视图函数如要要动态指向这个路由可接收的URL的话,同时也要向它传递一个参数,将整个URL给补全:
from django.shortcuts import reverse # 导入模块def index(request,jump):print(jump)return HttpResponse('from index')def login(request,):# reverse可以根据别名找到路由可接收的URL,args则是将URL需要的额外参数填进去了print(reverse('index_name',args=(1,)))return render(request,'index.html')
上序操作归总:
无名分组的URL:路由:url(r'^index/(\d+)/',views.index,name='index_name')后端:reverse('index_name',args=(1,)) # 只要给个数字即可前端:<a href="{% url 'index_name' 1 %}"></a> # 只要给个数字即可有名分组的URL:路由:url(r'^index/(?P<id>\d+)/',views.index,name='index_name')后端:reverse('index_name',kwargs={'id':123}) # 只要给个数字即可前端:<a href="{% url 'index_name' id=666 %}"></a> # 只要给个数字即可在后端与前端加上关键字是为了更好辨识而已总结无名有名都可以使用一种(无名)反向解析的形式
路由分发
简介
django是专注于开发应用的,当一个django项目特别庞大的时候所有的路由与视图函数映射关系全部写在总的urls.py很明显太冗余不便于管理,其实django中的每一个app应用都可以有自己的
urls.py、static文件夹、templates文件夹,基于上述特点,使用django做分组开发非常的简便。
可以分开写多个app应用,最后再汇总到一个空的Django项目然后使用路由分发将多个app应用关联起来。
未使用路由分发前:所有请求都由主路由转发到对应视图函数,全部都在一个urls.py文件内。
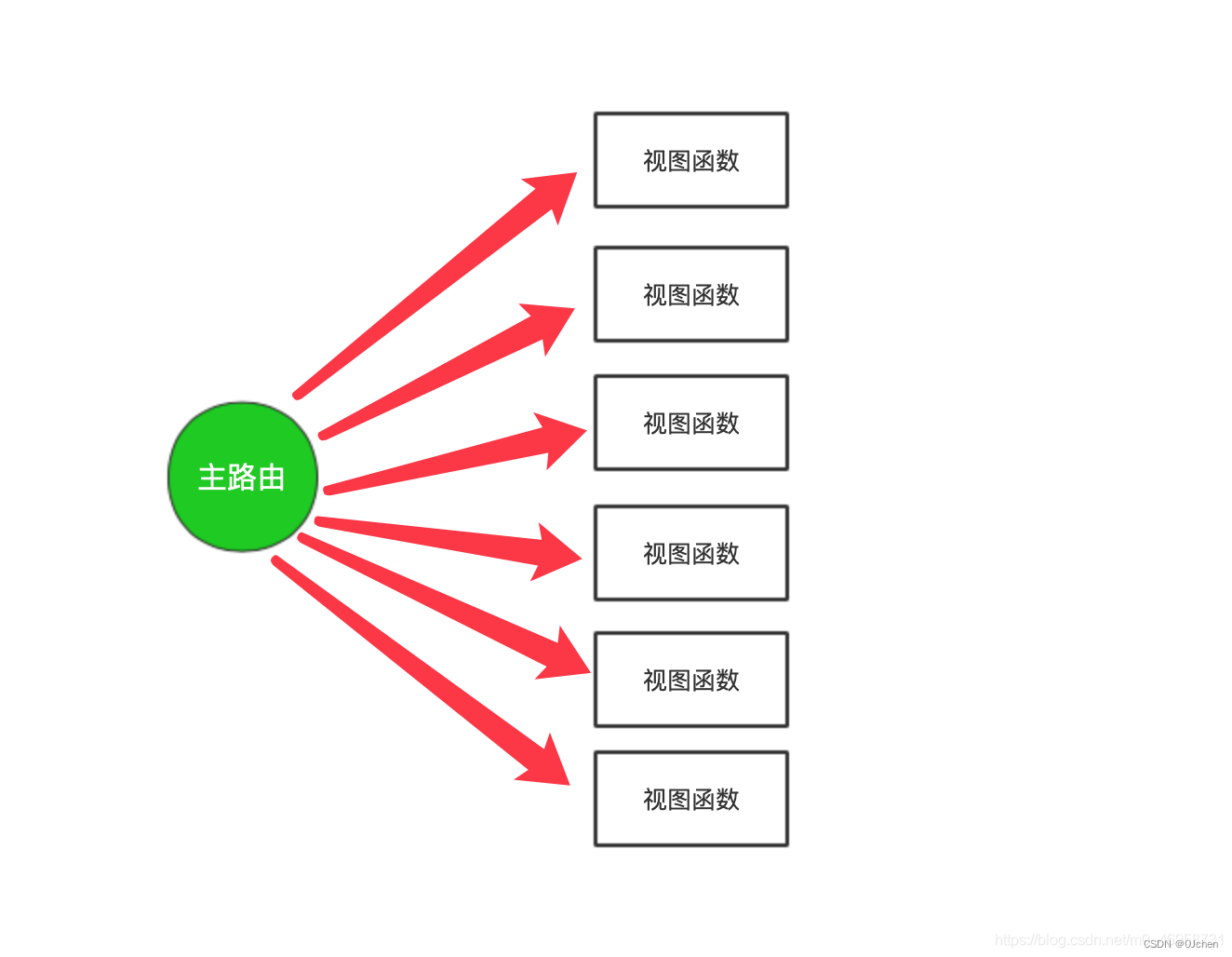
使用路由分发后:将请求的URL由主路由转发到其它负责这个URL的子路由上面去。每个子路由文件都应该存放在对应的app应用下。
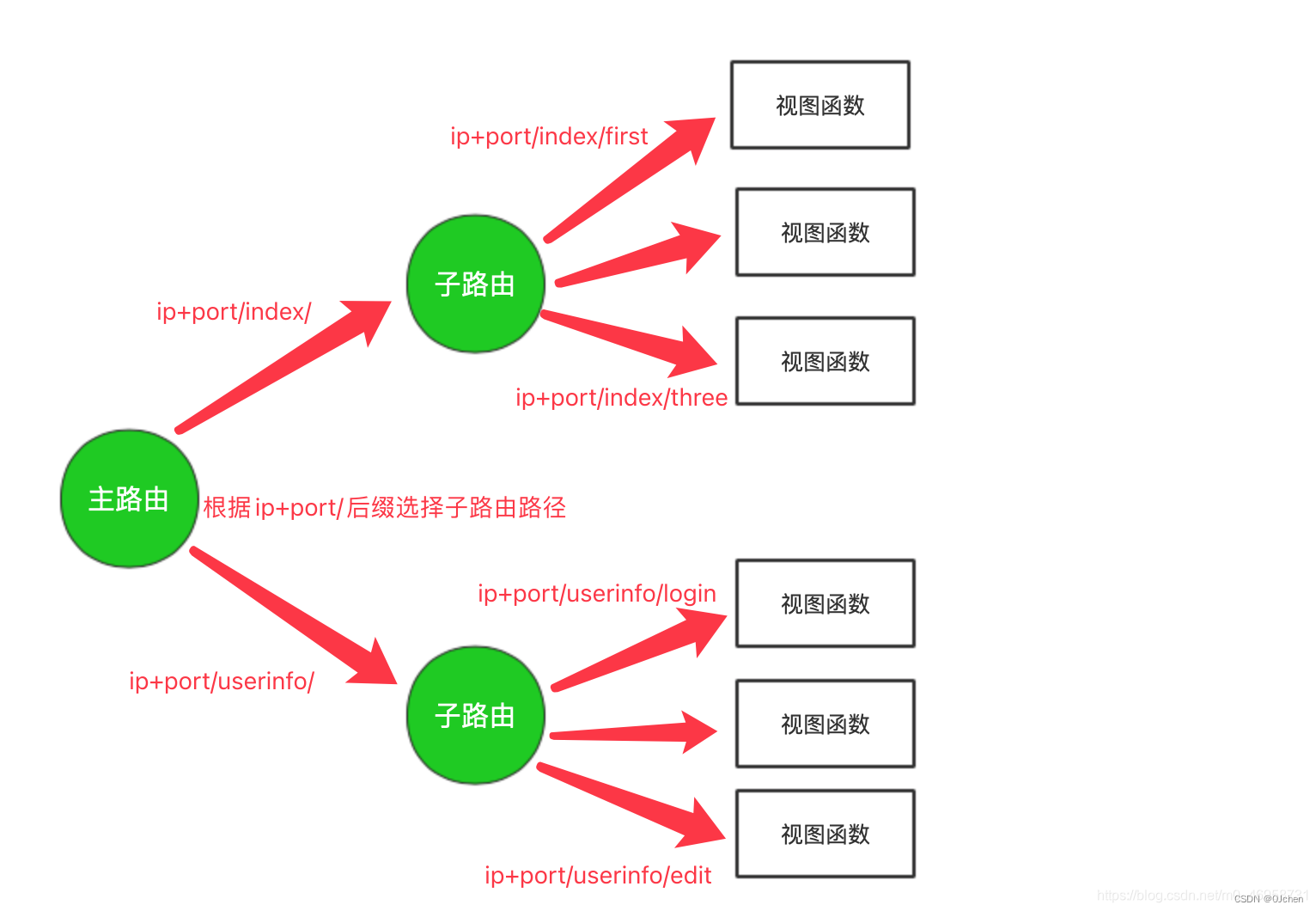
为什么要用路由分发?
- 解决项目的总路由匹配关系过多的情况
- 总路由分开于干路由与视图函数的的直接对应关系
- 总路由是一个分发处理(识别当前url是属于哪个应用下的,直接分发对应的应用去处理)
- 当请求来了,总路由不做对应关系,根据请求直接访问哪个app的功能,直接将请求发送给对应的app
- 提前创建好应用app01(创建即注册)、app02,然后记得注册app02
路由分发实现
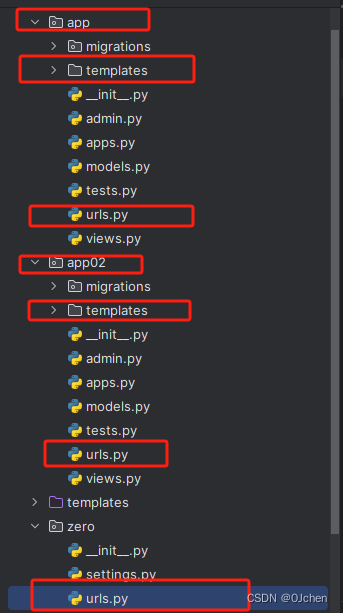
首先我们创建一个新的Django项目,然后创建两个app应用,保持如下目录结构:
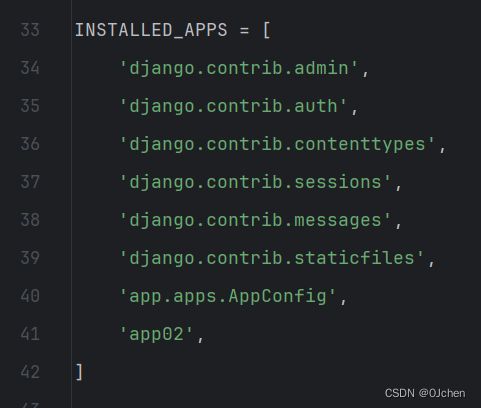
也别忘记在settings配置文件中注册应用
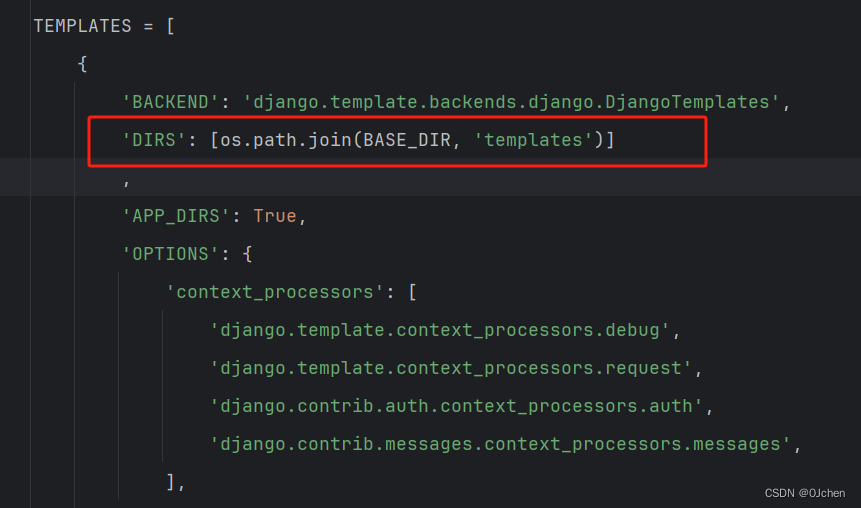
templates文件夹路径也需要配置一下
此时我们开始配置主路由,分配URL请求转发给哪个子路由执行;主路由在我们的Django项目文件夹内urls.py
from django.urls import path,include # 导入一个include路由分发模块from app import views# 导入子路由的url,避免重命,取别名from app import urls as app_urlsfrom app02 import urls as app02_urls # 增加别名是因为我们导入的两个urls名称相同urlpatterns = [path('admin/', admin.site.urls),path('home/',include(app_urls)), # 将ip+port/home/ 以这些为起始请求交给app>urls.py路由处理path('userinfo/',include(app02_urls)),
注意:如果使用的是url作为路由的话,切记路由规则结尾不能使用$
此时我们分别配置两个应用下的子路由、视图函数、模板文件。
app>urls.py
from django.urls import pathfrom app01 import viewsurlpatterns = [path('index/', views.index),]
app>templates>index.html
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>index</title></head><body><h1>This Is App01 Index</h1></body></html>
app>views.py
from django.shortcuts import renderdef index(request):return render(request,'index.html')
app02>urls.py
from django.urls import pathfrom app02 import viewsurlpatterns = [path('login/', views.login)]
app02>templates>login.html
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>login</title></head><body><h1>This Is App02 Login</h1></body></html>
app02>templates>views.py
from django.shortcuts import renderdef login(request):return render(request,'login.html')
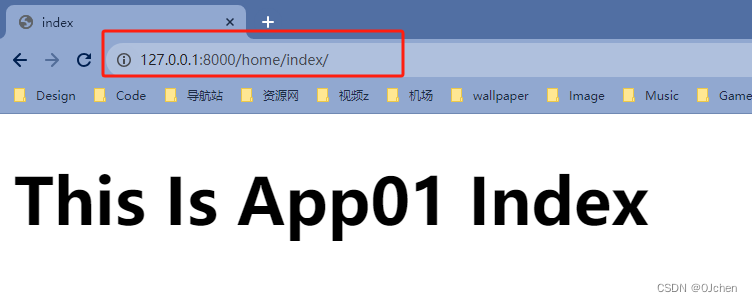
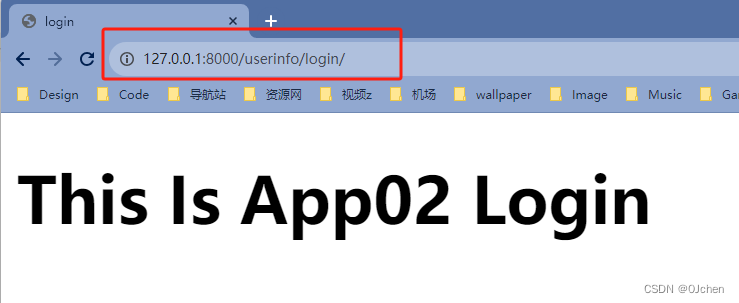
注意:port一定要是本机的Django服务端口。
上面主路由配置难免不够简单,随着子路由越来越多,导入的模块也越来越多了,继续缩短写法!
from django.urls import path,include # 导入一个include路由分发模块urlpatterns = [path('admin/', admin.site.urls),path('home/',include('app.urls')), # 将ip+port/home/ 以这些为起始请求交给app>urls.py路由处理path('userinfo/',include('app02.urls')),
当一个Django项目存在多个app应用,使用路由分法是很有必要的,减少了单个文件代码冗余,更便于管理。
伪静态的概念
伪静态: 其实就是把动态页面改成静态页面
伪静态: 其实就是把动态页面改成静态页面动态页面:"""它不是在html页面中写死的,它是根据后端的数据变化而变化"""我们的页面上的数据是从数据库查询出来都是可以是动态页面静态页面:htmlcss案例:https://www.cnblogs.com/bigsai/p/17827160.html # 这个就是伪装之后的页面伪装的目的:"""为了更好的被各大搜索引擎抓大,静态页面是最容易被抓到的,有个别的网站就会做伪装,seo"""seo:优化关键词被容易搜索到sem: 广告(RMB)怎么样去伪装 url(r'^v1/v2/test.html/$', views.test) # 加上了html后缀
名称空间
其实每个路由都可以有属于自己的名称空间,只是目前我们并没有使用到而已。请见如下例子:
如果当多个应用在反向解析的时候出现了路由别名冲突的情况,那么就会无法识别。
这些HTML文件向根据路由别名来动态指向URL,但是此时别名冲突了,我们该如何解决呢
<a href={% url 'index_name' %}>app01应用</a><a href={% url 'index_name' %}>app02应用</a>
解决方式一:名称空间,总路由内定义
urlpatterns = [path('admin/', admin.site.urls),path('home/', include('app01.urls',namespace='app01')),path('userinfo/', include('app02.urls',namespace='app02'))]
那么HTML文件可以根据主路由设置的名称空间,正确找到其下面的子路由的别名;
<a href={% url 'app01:index_name' %}>app01应用</a><a href={% url 'app02:index_name' %}>app02应用</a>
reverse解析也可以这样找到某个主路由下面的子路由别名,获取其路由规则
reverse('app01:index_name')
解决方式2:别名不能冲突(加上自己应用名作为前缀),在子路由内定义
# app01>urls.pypath('login/', views.login,name='app01_index_name')# app02>urls.pypath('index/', views.index,name='app02_index_name')
但是更推荐使用方式一,因为每次只需要加上名称空间作为前缀就可以找到其下面对应的子路由别名。更主要的是:少写很多字符
虚拟环境
什么是虚拟环境?
项目1需要使用:django1.11 python38项目2需要使用:django2.22 pymysql requests python38项目3需要使用:django3.22 request_html flask urllib3 python38虚拟环境:能够针对相同版本的解释器创建多个分身 每个分身可以有自己独立的环境pycharm创建虚拟环境:(每创建一个虚拟环境就相当于重新下载了一个全新的解释器)
实际开发过程,我们需要给不同的项目配备不同的环境,项目需要用到的环境是什么我们就给装什么样的环境。一般不用的我们不装,因为虚拟环境创建太多(第三方模块或者工具太),是会消耗硬盘空间。
目前我们不使用虚拟环境,所有的模块统一下载到本地
如何创建虚拟环境?
终端命令
1.创建一个虚拟环境python -m venv pyvenv38 # 只能是python2.激活activate(cd scripts进入文件内删)3.关闭deactivate
注意:python命令此处不支持多版本共存的操作 python27 python36 python38
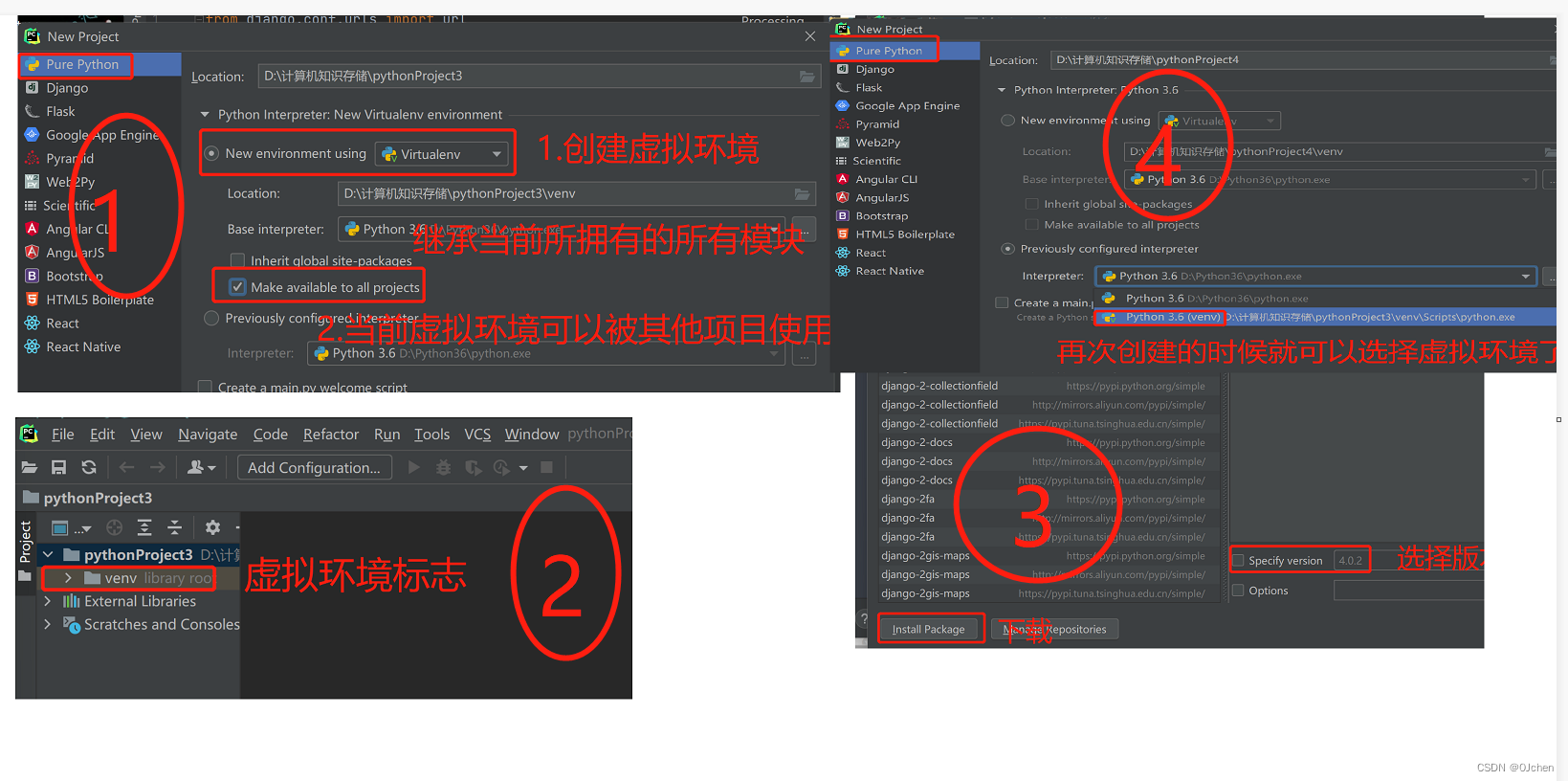
pycharm创建虚拟环境
1、创建虚拟环境2、虚拟环境标志3、虚拟环境下载django4、使用虚拟环境如果下载过程出现问题了,就复制提示的解决方法到文件上方框里去执行pip install --index-url http://mirrors.aliyun.com/pypi/simple/ django==1.11.11 --trusted-host mirrors.aliyun.com
Django1.x与2.x版本的区别
1. 路由文件django1.x中使用的是url:支持正则django2.x中使用的是path(不支持正则:精准匹配)和re_path(url):支持正则path:但是它只支持五种转换器Django默认支持以下5个转化器:● str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式● int,匹配正整数,包含0。● slug,匹配字母、数字以及横杠、下划线组成的字符串。● uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。● path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)自定义转化器2. 创建表关系django2中必须指定参数:on_delete:djanxo1中不用指定:级联更新级联删除
相关文章:
Django之路由层
文章目录 路由匹配语法路由配置注意事项转换器注册自定义转化器 无名分组和有名分组无名分组有名分组 反向解析简介普通反向解析无名分组、有名分组之反向解析 路由分发简介为什么要用路由分发?路由分发实现 伪静态的概念名称空间虚拟环境什么是虚拟环境?…...
【06】VirtualService高级流量功能
5.3 weight 部署demoapp v10和v11版本 --- apiVersion: apps/v1 kind: Deployment metadata:labels:app: demoappv10version: v1.0name: demoappv10 spec:progressDeadlineSeconds: 600replicas: 3selector:matchLabels:app: demoappversion: v1.0template:metadata:labels:app…...

322. 零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。 你可以认为每种硬币的数量是无限的。 示…...
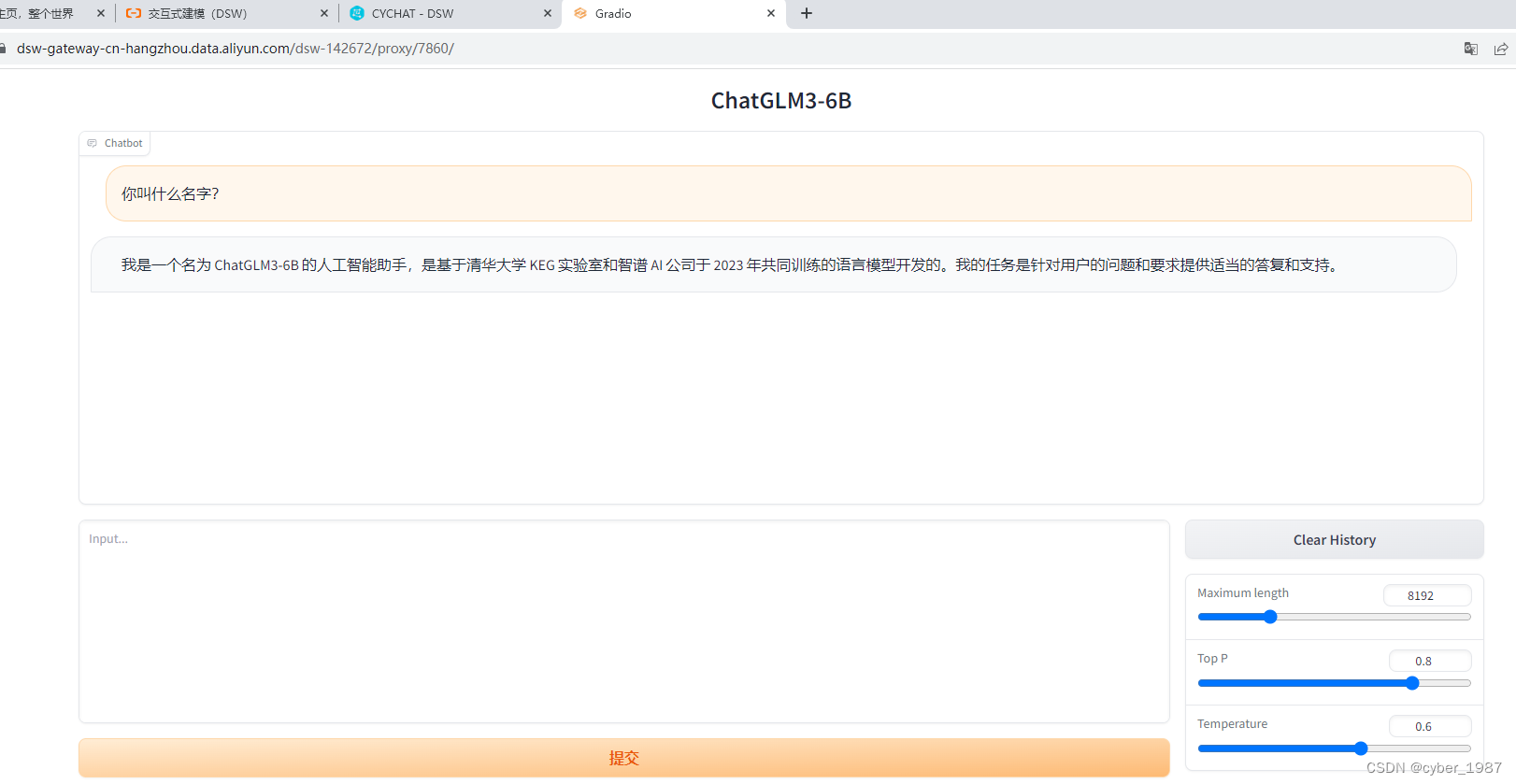
【大模型-第一篇】在阿里云上部署ChatGLM3
前言 好久没写博客了,最近大模型盛行,尤其是ChatGLM3上线,所以想部署试验一下。 本篇只是第一篇,仅仅只是部署而已,没有FINETUNE、没有Langchain更没有外挂知识库,所以从申请资源——>开通虚机——>…...

2023-11-14 mysql-主从复制-相关文档
摘要: 2023-11-14 mysql-主从复制-相关文档 官方文档: MySQL :: MySQL 8.0 Reference Manual :: 17 Replication MySQL :: MySQL 8.0 Reference Manual :: 18 Group Replication 相关参数: mysql> show variables like %repl%; +-----------------------------------------…...
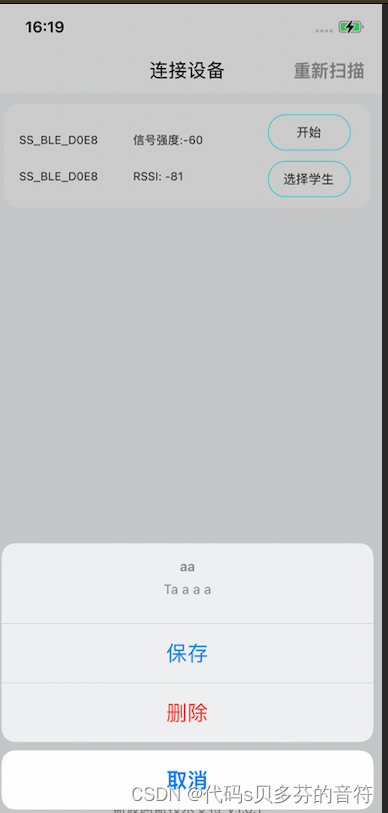
ios 对话框 弹框,输入对话框 普通对话框
1 普通对话框 UIAlertController* alert [UIAlertController alertControllerWithTitle:"a" message:"alert12222fdsfs" pr…...
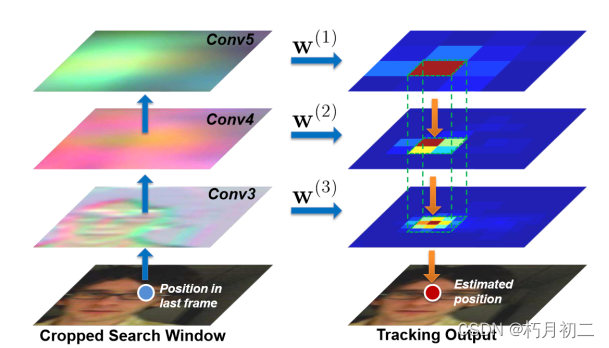
(论文阅读23/100)Hierarchical Convolutional Features for Visual Tracking
文献阅读笔记(分层卷积特征) 简介 题目 Hierarchical Convolutional Features for Visual Tracking 作者 Chao Ma, Jia-Bin Huang, Xiaokang Yang and Ming-Hsuan Yang 原文链接 arxiv.org/pdf/1707.03816.pdf 关键词 Hierarchical convolution…...

基于IGT-DSER智能网关实现GE的PAC/PLC与罗克韦尔(AB)的PLC之间通讯
工业自动化领域的IGT-DSER智能网关模块支持GE、西门子、三菱、欧姆龙、AB等各种品牌的PLC之间通讯(相关资料下载),同时也支持PLC与Modbus协议的工业机器人、智能仪表等设备通讯。网关有多个网口、串口,也可选择WIFI无线通讯。无需编程开发,只…...

创建符合 Web 可访问性标准的 HTML 布局
人们常说网络可访问性是当今万维网的“必须”。“Web 可访问性”一词定义了开发人员需要遵循的一组准则,以使残障人士和 Web 应用程序的交互更加方便。任何网站的内容、UI/UX 设计和布局都应该易于访问。在本文中,Logicify团队为 HTML/CSS 开发人员提供了…...
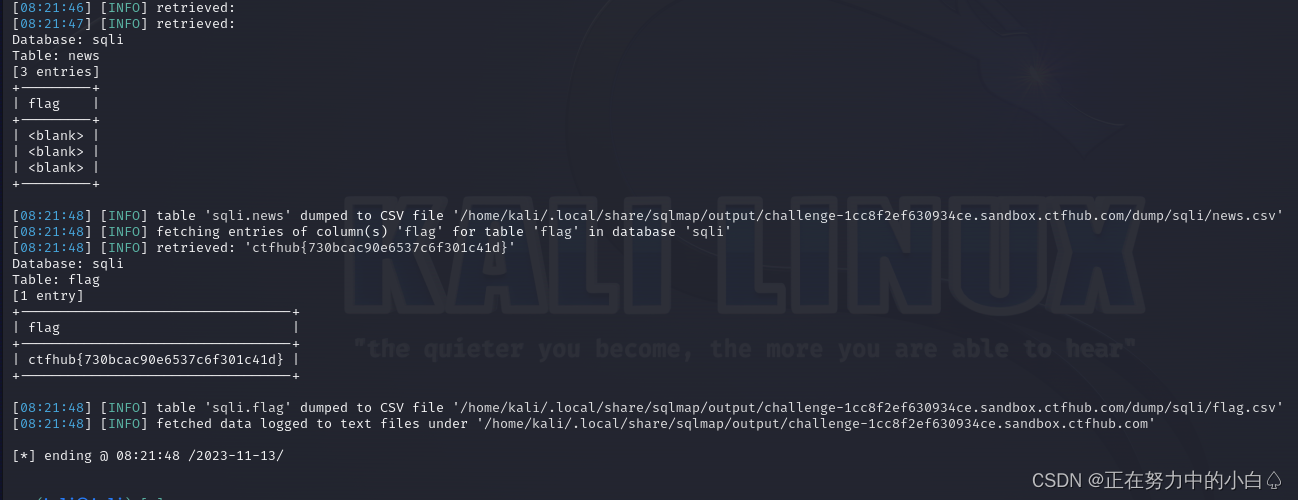
SQL学习(CTFhub)整数型注入,字符型注入,报错注入 -----手工注入+ sqlmap注入
目录 整数型注入 手工注入 为什么要将1设置为-1呢? sqlmap注入 sqlmap注入步骤: 字符型注入 手工注入 sqlmap注入 报错注入 手工注入 sqlmap注入 整数型注入 手工注入 先输入1 接着尝试2,3,2有回显,而3没有回显…...

数字人部署之VITS+Wav2lip数据流转处理以提高实时性
一、模型 VITS模型训练教程VITS-从零开始微调(finetune)训练并部署指南-支持本地云端 Wav2lip是2D数字人,可参考训练嘴型同步模型Wav2Lip PS:以上模型都是开源可用。 二. VITS数据处理问题 VITS模型的输出为一维的numpy类型数据ÿ…...

GPT 学习法:复杂文献轻松的完美理解、在庞大的不确性中找到确定性
GPT 学习法:复杂文献轻松的完美理解、在庞大的不确性中找到确定性 复杂文献 - 基础理解GPT 理解法 - 举例子、归纳、逻辑链推导本质、图示、概念放大器GPT 分析法 - 二分、矩阵、公式、要素、过程 做复杂题:在庞大的不确性中找到确定性思维追踪ÿ…...

前端简单的爱心形状
首先需要创建一个 HTML 文件,然后在其中添加 CSS 样式和 JavaScript 代码。以下是一个简单的示例: 创建一个名为 loveheart.html 的文件 <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8"><…...
)
acwing算法基础之数学知识--求数a的欧拉函数值phi(a)
目录 1 基础知识2 模板3 工程化 1 基础知识 数a的欧拉函数 ϕ ( a ) \phi(a) ϕ(a):表示1~n中与n互质的数的个数。其中两个数互质,是指这两个数的最大公约数为1。 根据定义,我们可以写出如下方法, int gcd(int a, int b) {retu…...
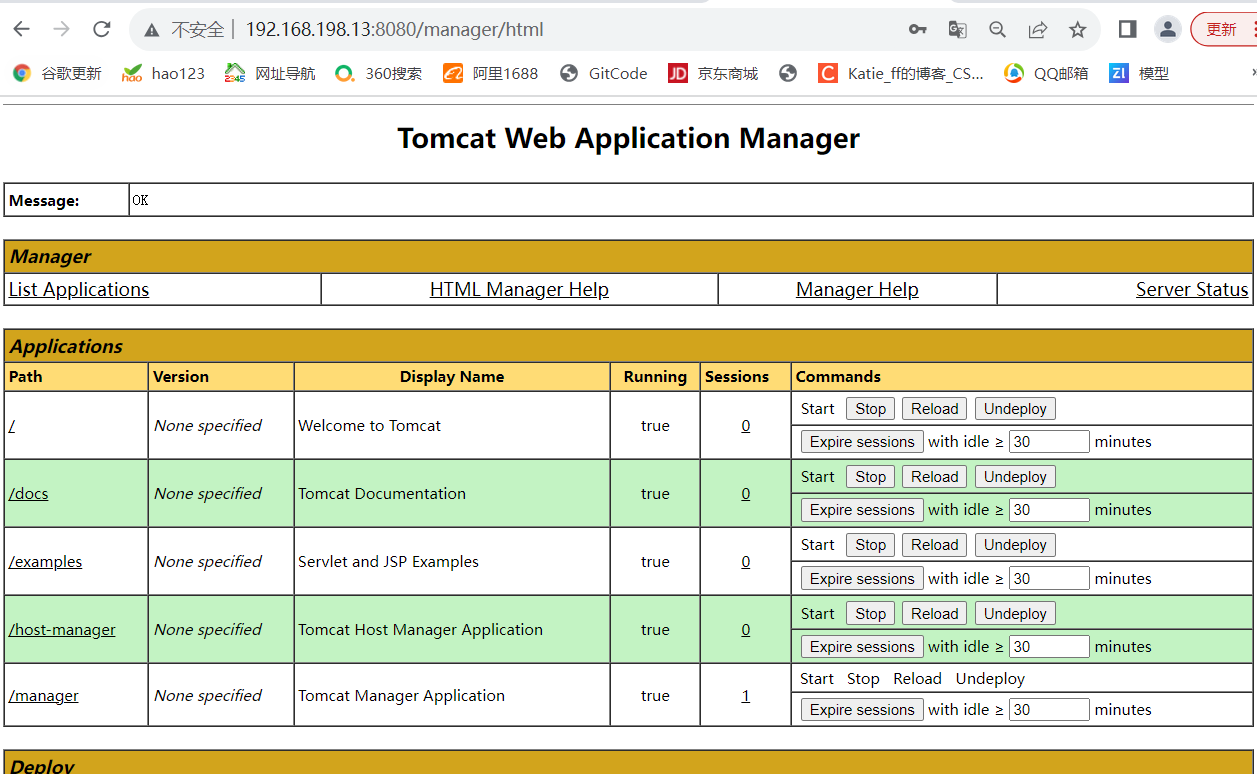
Jenkins的介绍与相关配置
Jenkins的介绍与配置 一.CI/CD介绍 1.CI/CD概念 ①CI 中文意思是持续集成 (Continuous Integration, CI) 是一种软件开发流程,核心思想是在代码库中的每个提交都通过自动化的构建和测试流程进行验证。这种方法可以帮助团队更加频繁地交付软件&#x…...

开源网安受邀参加网络空间安全合作与发展论坛,为软件开发安全建设献计献策
11月10日,在广西南宁举办的“2023网络空间安全合作与发展论坛”圆满结束。论坛在中国兵工学会的指导下,以“凝聚网络空间安全学术智慧,赋能数字经济时代四链融合”为主题,邀请了多位专家及企业代表共探讨网络安全发展与数字经济…...
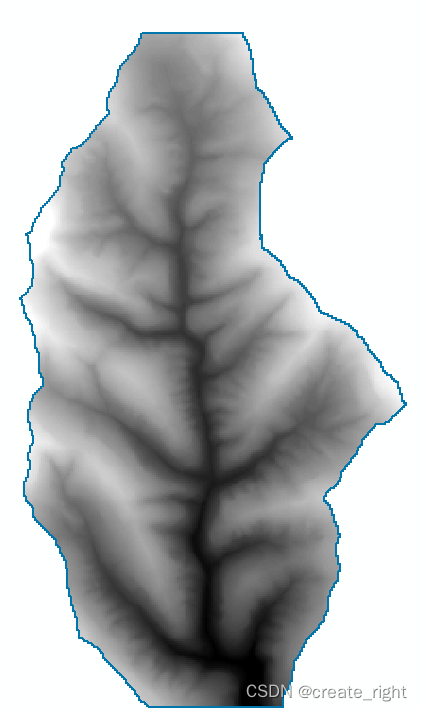
arcgis提取栅格有效边界
方法一:【3D Analyst工具】-【转换】-【由栅格转出】-【栅格范围】 打开一幅栅格数据,利用【栅格范围】工具提取其有效边界(不包含NoData值): 方法二:先利用【栅格计算器】将有效值赋值为1,得到…...

后端接口性能优化分析-问题发现问题定义
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码🔥如果感觉博主的文章还不错的话,请👍三连支持&…...

中国首个通过ASIL D认证的IP发布,国产芯片供应商的机会来了
来自智能汽车的“芯”安全需求正在快速爆发。 一方面,随着智能汽车ADAS的快速迭代与逐渐普及化,以及越来越多元化智能座舱功能的快速上车,由此带来的车辆信息安全场景也在与日俱增,例如云端链接、设备身份认证、自动驾驶安全保障…...
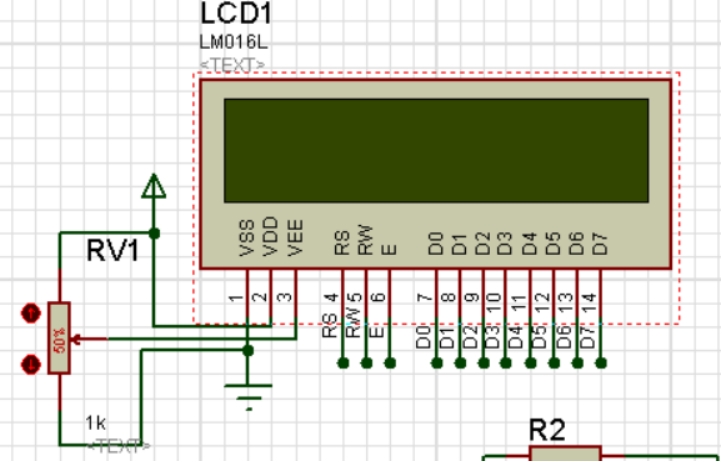
[单片机课程设计报告汇总] 单片机设计报告常用硬件元器件描述
[单片机课程设计必看] 单片机设计报告常用描述 硬件设计 AT89C51最小系统 AT89C51是美国ATMEL公司生产的低电压,高性能CMOS16位单片机,片内含4k bytes的可反复擦写的只读程序存储器和128 bytes的随机存取数据存储器,期间采用ATMEL公司的高…...

第三卷第4章:原型模式设计思想
第三卷第4章:原型模式设计思想 目录介绍 01.案例引入与思考 1.1 痛点场景 1.2 它哪里不舒服 1.3 引出本篇主角 02.原型模式介绍 2.1 原型模式由来 2.2 原型模式定义...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由
终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案
LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirror…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南
5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 在Windows 10系统中使用PL2303 USB转串口设…...
)
内存申请和使用的场景分析(以AP->kernal->ISP为例)
在 ISP(Image Signal Processor)系统中,AP 与 ISP 之间的内存交互本质上是一个**“AP 申请可 DMA 访问的共享内存 → 内核建立映射 → 硬件寻址读写 → 同步与回收”**的过程。下面按数据流分层详细拆解。一、ISP 内存需求的特殊性 与普通应用…...

sd卡分区了数据还能恢复吗,只需3种方法和视频教学,数据就能神奇地回来!
断开读写通信!锁死底层端口!你的sd卡在经历重新分区的一瞬间,其物理层面的扇区正在承受最严酷的逻辑改写。这并非介质烧毁,而是系统内核强行切断了旧有簇链的映射关系,将其标定为休克态。此时若任由操作系统自动加载缩…...

无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统
无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统 【免费下载链接】chaplin A real-time silent speech recognition tool. 项目地址: https://gitcode.com/gh_mirrors/chapl/chaplin 在嘈杂的办公室、安静的图书馆,或是需要绝对隐私的医…...