使用 Redis 实现生成分布式全局唯一ID(使用SpringBoot环境实现)
目录
- 一、前言
- 二、如何通过Redis设计一个分布式全局唯一ID生成工具
- 2.1、使用 Redis 计数器实现
- 2.2、使用 Redis Hash结构实现
- 三、通过代码实现分布式全局唯一ID工具
- 3.1、编写获取工具
- 3.2、测试获取工具
- 四、总结
一、前言
在很多项目中生成类似订单编号、用户编号等有唯一性数据时还用的UUID工具,或者自己根据时间戳+随机字符串等组合来生成,在并发小的时候很少出问题,当并发上来时就很可能出现重复编号的问题了,单体项目和分布式项目都是如此,要想解决这个问题也有很多种方法,可以自己写一个唯一ID生成规则,也可以通过数据库来实现全局ID生成这个和使用Redis实现其实类似,还可以使用比较成熟的雪花算法工具实现,每种方法都有各自的优缺点这里不展开说明,这里详细说明如何使用Redis实现生成分布式全局唯一ID。
还有一个问题为什么不能直接使用数据库的自增ID,而是需要单独生成一个分布式全局唯一ID,类似订单IDON202311090001,在数据库中有自增ID,对于当前业务来说就是唯一的为什么不能用,还要去生成一个独立的订单ID,对于这个问题要从几个方面分析:
1、数据库自增ID是有序增长的很容易就被人猜到,比如我现在下一单看到的订单ID为999那么就知道你的系统里最多只有999单,还有如果接口设计不合理,比如取消订单接口只校验了用户是否登录没有校验订单是否属于该用户,接收一个订单ID就能将订单取消,那么这样很容易就被人抓住漏洞,类似的情况有很多,也很多人写接口是不会注意这个问题。
2、这种自增ID没有意义,而且不同业务的自增ID是重合的,对于信息区分度很低,而且考虑到多业务交互和用户端展示也都是不合适的,想想看要是你在某宝下单,订单ID是999,或者在对接别人订单系统时,给你的订单ID是999是不是很奇怪。
3、分库分表时自增ID会重复
需要集成文章可以查看:
SpringBoot集成Lettuce客户端操作Redis:https://blog.csdn.net/weixin_44606481/article/details/133907103
二、如何通过Redis设计一个分布式全局唯一ID生成工具
用户下单调用下单逻辑,先进行业务逻辑处理,然后携带订单ID标识通过分布式全局唯一ID工具获取一个唯一的订单ID,这个订单ID标识就是用于区分业务的,获取到订单ID后将数据组装入库,分布式全局唯一ID工具可以做成一个内嵌的utils,也可以封装成一个独立的jar,还可以做成一个分布式全局唯一ID生成服务供其它业务服务调用。
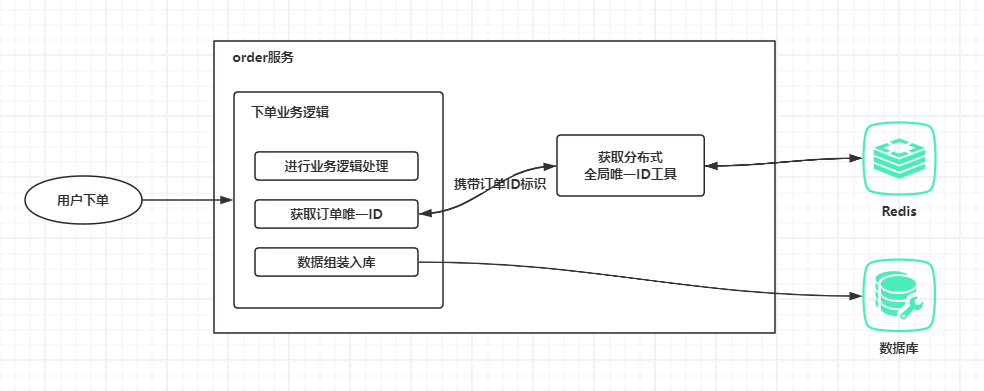
2.1、使用 Redis 计数器实现
Redis的String结构提供了计数器自增功能,类似Java中的原子类,还要优于Java的原子类,因为Redis是单线程执行的缓存读写本身就是线程安全的,也不用进行原子类的乐观锁操作,每一次获取分布式全局唯一ID时就将自增序列加1。
# 给key为GENERATEID:NO的value自增1,如果这key不存在则会添加到Redis中并且设置value为1
## GENERATEID:key前缀
## NO:订单ID标识
127.0.0.1:6379> incr GENERATEID:NO
(integer) 1
2.2、使用 Redis Hash结构实现
Redis Hash结构中的每一个field也可以进行自增操作,可以用一个Hash结构存储所有的标识信息和自增序列,方便管理,比较适合并发不高的小项目所有服务都是用的一个Redis,如果并发较高就不合适了,毕竟Redis操作普通String结构肯定比操作Hash结构快。
# 给key为GENERATEID,field为no的value自增1,如果这key不存在则会添加到Redis中并且设置value为1
## GENERATEID:分布式全局唯一ID Hash key
## NO:Hash结构中的field
127.0.0.1:6379> hincrby GENERATEID NO 1
(integer) 1
三、通过代码实现分布式全局唯一ID工具
这里使用Redis 计数器实现,自增序列以天为单位存储,在实际业务中,比如生成订单编号组成规则都类似NO1699631999000-1(业务标识key+当前时间戳+自增序列),这个规则可以自己定义,保证最终生成的订单编号不重复即可,不建议直接一个自增序列干到底,订单编号这类型的数据都是有长度限制的,或者是要求生成20字符的订单编号,如果增长的过长反而不好处理。
3.1、编写获取工具
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.time.LocalDate;
import java.util.concurrent.TimeUnit;@Component
public class RedisGenerateIDUtils {@Autowiredprivate RedisTemplate<String, Object> redisTemplate;// key前缀private String PREFIX = "GENERATEID:";/*** 获取全局唯一ID* @param key 业务标识key*/public String generateId(String key) {// 获取对应业务自增序列Long incr = getIncr(key);// 组装最后的结果,这里可以根据需要自己定义,这里是按照业务标识key+当前时间戳+自增序列进行组装String resultID = key + System.currentTimeMillis() + "-" + incr;return resultID;}/*** 获取对应业务自增序列*/private Long getIncr(String key) {String cacheKey = getCacheKey(key);Long increment = 0L;// 判断Redis中是否存在这个自增序列,如果不存在添加一个序列并且设置一个过期时间if (!redisTemplate.hasKey(cacheKey)) {// 这里存在线程安全问题,需要加分布式锁,这里做简单实现String lockKey = cacheKey + "_LOCK";// 设置分布式锁boolean lock = redisTemplate.opsForValue().setIfAbsent(lockKey, 1, 30, TimeUnit.SECONDS);if (!lock) {// 如果没有拿到锁进行自旋return getIncr(key);}increment = redisTemplate.opsForValue().increment(cacheKey);// 我这里设置24小时,可以根据实际情况设置当前时间到当天结束时间的插值redisTemplate.expire(cacheKey, 24, TimeUnit.HOURS);// 释放锁redisTemplate.delete(lockKey);} else {increment = redisTemplate.opsForValue().increment(cacheKey);}return increment;}/*** 组装缓存key*/private String getCacheKey(String key) {return PREFIX + key + ":" + getYYYYMMDD();}/*** 获取当前YYYYMMDD格式年月日*/private String getYYYYMMDD() {LocalDate currentDate = LocalDate.now();int year = currentDate.getYear();int month = currentDate.getMonthValue();int day = currentDate.getDayOfMonth();return "" + year + month + day;}
}
3.2、测试获取工具
import com.redisscene.utils.RedisGenerateIDUtils;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.concurrent.*;@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedisSceneApplication.class)
public class RedisGenerateIDTest {@Autowiredprivate RedisGenerateIDUtils redisGenerateIDUtils;@Testpublic void t1() throws InterruptedException {// 定义一个线程池 设置核心线程数和最大线程数都为100,队列根据需要设置ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 100, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10000));CountDownLatch countDownLatch = new CountDownLatch(10000);long beginTime = System.currentTimeMillis();// 获取10000个全局唯一ID 看看是否有重复CopyOnWriteArraySet<String> ids = new CopyOnWriteArraySet<>();for (int i = 0; i < 10000; i++) {executor.execute(() -> {// 获取全局唯一IDlong beginTime02 = System.currentTimeMillis();String orderNo = redisGenerateIDUtils.generateId("NO");System.out.println("获取单个ID耗时 time=" + (System.currentTimeMillis() - beginTime02));if (ids.contains(orderNo)) {System.out.println("重复ID=" + orderNo);} else {ids.add(orderNo);}countDownLatch.countDown();});}countDownLatch.await();// 打印获取到的全局唯一ID集合数量System.out.println("获取到全局唯一ID count=" + ids.size());System.out.println("耗时毫秒 time=" + (System.currentTimeMillis() - beginTime));}
}
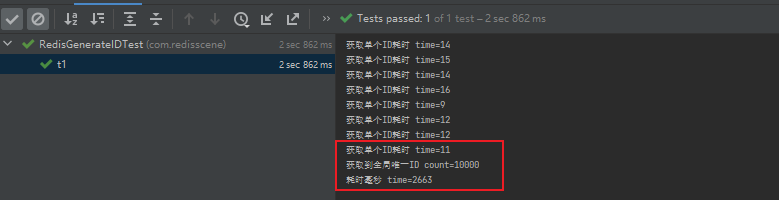
四、总结
通过测试可以看到100并发生成全局唯一ID是没问题的,而且获取单个ID耗时在10-20毫秒左右,一般的业务已经完全够用,这个耗时也要看Redis性能和项目配置决定的,如果对于这种唯一ID生成并发量非常高的业务,可以提前生成一个唯一ID池存储在本地内存中,业务要获取唯一ID先去池中获取,如果获取不到再去Redis获取,自增序列一次性增加多个,然后将这个区间的值存储在本地缓存即可。
相关文章:
使用 Redis 实现生成分布式全局唯一ID(使用SpringBoot环境实现)
目录 一、前言二、如何通过Redis设计一个分布式全局唯一ID生成工具2.1、使用 Redis 计数器实现2.2、使用 Redis Hash结构实现 三、通过代码实现分布式全局唯一ID工具3.1、编写获取工具3.2、测试获取工具 四、总结 一、前言 在很多项目中生成类似订单编号、用户编号等有唯一性数…...
Pytorch CUDA CPP简易教程,在Windows上操作
文章目录 前言一、使用的工具二、学习资源分享三、libtorch环境配置1.配置CUDA、nvcc、cudnn2.下载libtorch3.CLion配置libtorch4.CMake Application指定Environment variables5.测试libtorch 四、PyTorch CUDA CPP项目流程1.使用CLion结合torch extension编写可以调用cuda的C代…...

服务器怎么连接
服务器怎么连接 服务器可以通过多种方式连接,主要取决于服务器的操作系统、网络配置和连接方式等因素。 1. SSH连接:如果服务器使用的是Linux操作系统,可以通过SSH协议连接。需要使用SSH客户端工具,例如PuTTY,在登录页…...
线性代数-Python-05:矩阵的逆+LU分解
文章目录 1 矩阵的逆1.1 求解矩阵的逆 2 初等矩阵2.1 初等矩阵和可逆性 3 矩阵的LU分解3.1 LU分解的实现 1 矩阵的逆 1.1 求解矩阵的逆 def inv(A):if A.row_num() ! A.col_num():return Nonen A.row_num()"""矩阵A单位矩阵"""ls LinearSyste…...

shell实用脚本命令
1. declare declare 命令是一个非常常用的命令之一,它可以用来声明变量的类型和属性,比如变量的作用域、是否只读等等。 一、declare命令的基本用法 declare 命令可以用来声明变量,其最基本的用法如下:declare 变量名 在上面的命…...
STM32——端口复用与重映射概述与配置(HAL库)
文章目录 前言一、什么是端口复用?什么是重映射?有什么区别?二、端口复用配置 前言 本篇文章介绍了在单片机开发过程中使用的端口复用与重映射。做自我学习的简单总结,不做权威使用,参考资料为正点原子STM32F1系列精英…...
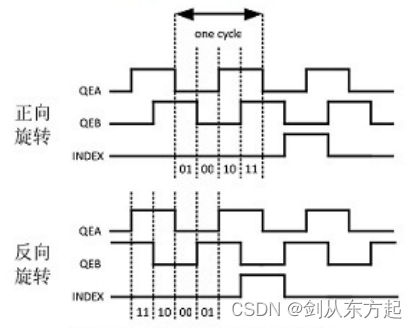
ABZ正交编码 - 异步电机常用的位置信息确定方式
什么是正交编码? ab正交编码器(又名双通道增量式编码器),用于将线性移位转换为脉冲信号。通过监控脉冲的数目和两个信号的相对相位,用户可以跟踪旋转位置、旋转方向和速度。另外,第三个通道称为索引信号&am…...
Linux学习第41天:Linux SPI 驱动实验(二):乾坤大挪移
Linux版本号4.1.15 芯片I.MX6ULL 大叔学Linux 品人间百味 思文短情长 本章的思维导图如下: 二、I.MX6U SPI主机驱动分析 主机驱动一般都是由SOC厂商写好的。不作为重点需要掌握的内容。 三、SPI设备驱动编写流程 1、SP…...
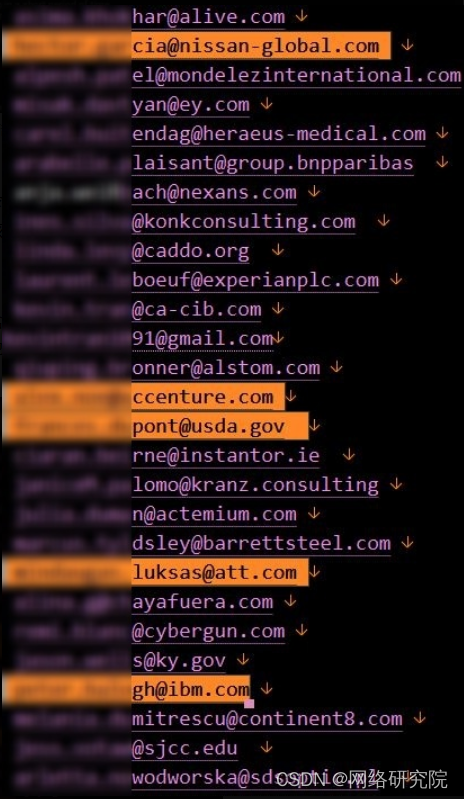
黑客泄露 3500 万条 LinkedIn 用户记录
被抓取的 LinkedIn 数据库分为两部分泄露:一部分包含 500 万条用户记录,第二部分包含 3500 万条记录。 LinkedIn 数据库保存了超过 3500 万用户的个人信息,被化名 USDoD 的黑客泄露。 该数据库在臭名昭著的网络犯罪和黑客平台 Breach Forum…...
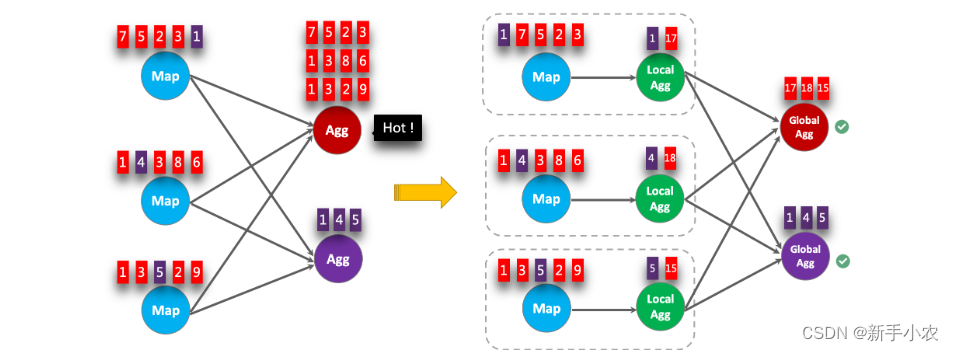
Flink SQL -- 反压
1、测试反压: 1、反压: 指的是下游消费数据的速度比上游产生数据的速度要小时会出现反压,下游导致上游的Task反压。 2、测试反压:使用的是DataGen CREATE TABLE words (word STRING ) WITH (connector datagen,rows-per-second…...
快速入门安装及使用git与svn的区别常用命令
一、导言 1、什么是svn? SVN是Subversion的简称,是一个集中式版本控制系统。与Git不同,SVN没有分布式的特性。在SVN中,项目的代码仓库位于服务器上,团队成员通过向服务器提交和获取代码来实现版本控制。SVN记录了每个…...

超详细介绍如何使用 OpenCV 和 BGS 库进行背景扣除
深入研究这些 CV 系统背后的想法,我们可以观察到,在大多数情况下,初始步骤包含背景减除 (BS),这有助于获得视频流中对象的相对粗略和快速的识别,以便对其进行进一步的精细处理。在当前的文章中,我们将介绍几种在准确性和处理时间 BS 方法方面值得注意的算法:SuBSENSE和基…...

STM32F4、GD32F4 内部硬件CRC使用方法和踩坑实录
背景 某项目用到了IC卡刷卡启动功能,程序中对读取IC卡的相关数据后要进行CRC校验,本文介绍如何在STM32F4 GD32F4 平台上使用标准库函数进行CRC硬件校验。 摘要 本文介绍如何在STM32F4、GD32F4 平台上使用标准库函数进行CRC硬件校验。包括容易出现的问题和解决方法。涉及STM3…...
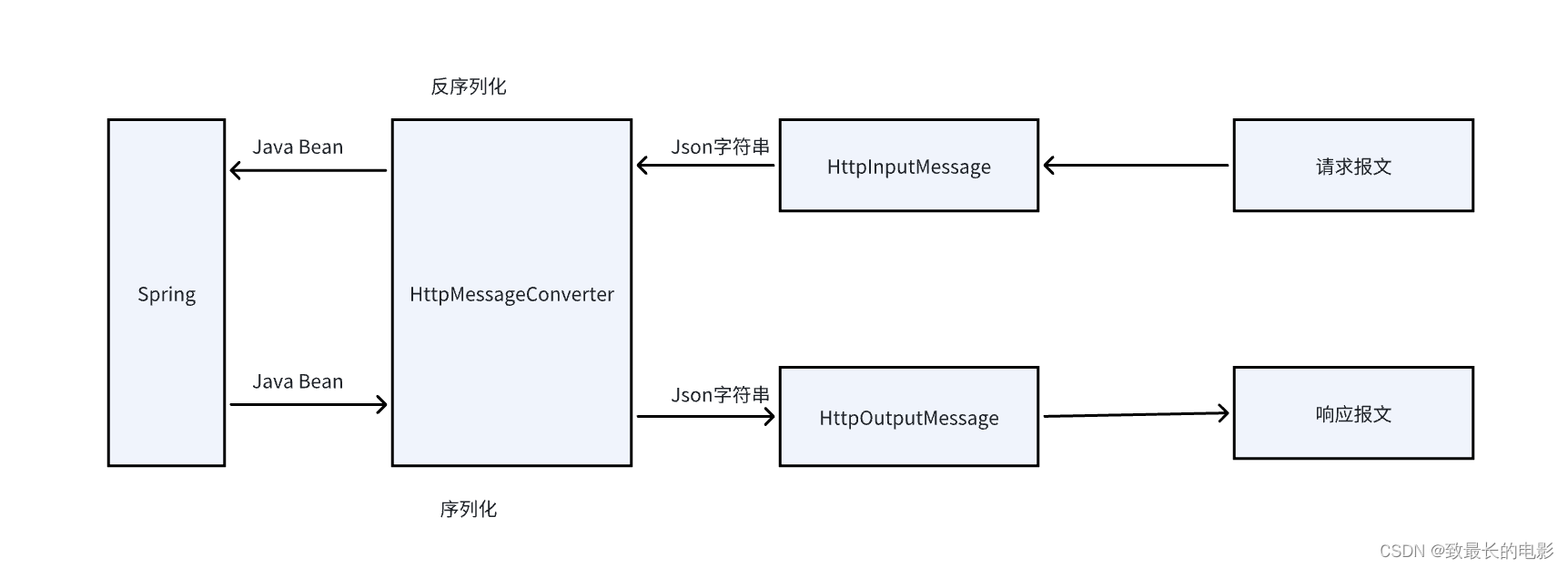
【SpringBoot】序列化和反序列化介绍
一、认识序列化和反序列化 Serialization(序列化)是一种将对象以一连串的字节描述的过程;deserialization(反序列化)是一种将这些字节重建成一个对象的过程。将程序中的对象,放入文件中保存就是序列化&…...

Android 升级软件后清空工厂模式测试进度
Android 升级软件后清空工厂模式测试进度 最近收到项目需求反馈:升级软件后,进入工厂模式测试项,界面显示测试项保留了升级前的测试状态(有成功及失败),需修改升级软件后默认清空测试项测试状态,具体修改参照如下: /…...

Promise原理、以及Promise.race、Promise.all、Promise.resolve、Promise.reject实现;
为了向那道光亮奔过去,他敢往深渊里跳; 于是今天朝着Promise的实现前进吧,写了四个小时,终于完结撒花; 我知道大家没有耐心,当然我也坐的腰疼,直接上代码,跟着我的注释一行行看过去…...
)
mysql---MHA(高可用)
MHA概述 magterhight availabulity :基于主库的高可用环境下,主故障切换基础要求:主从架构 (一主两从)解决mysql的单点故障问题,一旦数据库崩溃,MHA会在0-30s内这东东完成故障切换。复制方式:半…...
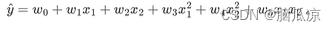
人工智能基础_机器学习032_多项式回归升维_原理理解---人工智能工作笔记0072
现在开始我们来看多项式回归,首先理解多维 原来我们学习的使用线性回归,其实就是一条直线对吧,那个是一维的,我们之前学的全部都是一维的对吧,是一维的,然后是多远的,因为有多个x1,x2,x3,x4... 但是比如我们有一个数据集,是上面这种,的如果用一条直线很难拟合,那么 这个时候,…...

C#截取范围
string[] strs new string[]{"1e2qe","23123e21","3ewqewq","4fewfew","5fsdfds"};var list strs[1..2];Range p 0..3;var list strs[Range];...
用 winget 在 Windows 上安装 kubectl
目录 kubectl 是什么? 安装 kubectl 以管理员身份打开 PowerShell 使用 winget 安装 kubectl 测试一下,确保安装的是最新版本 导航到你的 home 目录: 验证 kubectl 配置 kubectl 是什么? kubectl 是 Kubernetes 的命令行工…...

AI智能体架构设计:从成本黑洞到价值引擎的解耦之道
1. 从成本黑洞到价值引擎:为什么你的AI智能体架构正在吞噬预算又到了季度技术复盘会,财务那边递过来的云账单和工程人力成本,是不是又让你倒吸一口凉气?你看着报表上那个名为“AI智能体平台”的项目,它的资源消耗曲线几…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...
损坏诊断全解)
半导体元件(二极管/三极管/MOS管/IC)损坏诊断全解
半导体元件(二极管、三极管、MOS 管、集成电路)是 PCB 的核心功能单元,对过压、过流、ESD、高温极度敏感,损坏后直接导致电路功能失效、短路烧板。很多工程师维修时盲目更换芯片,不仅成本高,还易误判。一…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

Qri高级功能:如何使用JSON Schema验证和描述数据集结构
Qri高级功能:如何使用JSON Schema验证和描述数据集结构 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一个强大的开源数据协作工具,它提供了丰富的功能来帮助用户管理、共享和验证…...