【人工智能Ⅰ】7-KNN 决策树
【人工智能Ⅰ】7-KNN & 决策树
7-1 KNN(K near neighbour)
思想:一个样本与数据集中的k个样本最相似,若这k个样本大多数属于某类别,则该个样本也属于这类别
距离度量
样本相似性用欧氏距离定义
L p ( x i , x j ) = ( Σ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ p ) 1 / p L_p(x_i,x_j)=(Σ_{l=1}^{n}|x_i^{(l)}-x_j^{(l)}|^p)^{1/p} Lp(xi,xj)=(Σl=1n∣xi(l)−xj(l)∣p)1/p
流程
1:计算已知类别数据集中的点与当前点之间的距离
2:按递增排序距离
3:选取与当前点距离最小的k个点
4:统计k个点的类别及其频率
5:返回频率最高的类别,作为当前点的预测分类
优点
1:简单有效
2:适用大样本自动分类
缺点
1:类别分类不标准化
2:不均衡性
3:计算量较大
k值选择
1:误差
- 近似误差:对现有训练集的训练误差(过小说明过拟合)
- 估计误差:对测试集的测试误差(过小说明对未知数据的预测能力好)
2:k值
- 过小:近似误差小,估计误差大
- 过大:估计误差小,近似误差大
- k值一般取一个较小的数,采用【交叉验证法】择优
3:交叉验证法
将数据集划分为N个大小相似的互斥子集,并且尽量保证每个子集数据分布的一致性。
这样可获取N组训练 - 测试集,从而进行N次训练和测试。
7-2 决策树(Decision tree)
根据特征解决数据分类问题
- 每个节点选择一个特征提出问题,通过判断将数据分为2类,再继续提问
- 问题是在已知各种情况发生概率基础上,构成决策树,求取值大于等于0的概率
- 再投入新数据时,根据树上的问题,将数据划分到合适叶子上
- 事先确定每个样本的属性和类别,节点表示属性测试,分支表示测试输出,叶子节点表示类别
数据
1:训练数据(构造决策树,即决策机制)
2:测试数据(验证决策树的错误率)
构造树的依据
1:信息熵
表示信息的复杂程度
H = − ∑ i = 1 n p i ∗ l o g 2 ( p i ) H=-∑_{i=1}^np_i*log_2(pi) H=−i=1∑npi∗log2(pi)
2:信息增益
划分数据集前后,信息熵的差值
决策树过程
1:选择根节点
计算决策的信息熵H,和每个属性的信息熵
信息增益是【H - 选定属性的信息熵】
选取信息增益最大的属性作为根节点
2:选择新的节点
3:构建完整树
4:剪枝
减少树的高度,避免过拟合
(1)预剪枝干:设定一个树高度,当构建树达到高度时停止
(2)后剪枝:任由决策树构建完成,从底部开始判断哪些枝干应该剪掉
预剪枝更快,后剪枝更精确
决策树总结
1: 一棵决策树包含一个根节点、若干个内部结点和若干个叶结点
2:在决策过程中提出的每个判定问题都是对某个属性的“测试”(节点)
3:每个测试的结果或导出最终结论,或导出进一步的判定问题
4:根节点包含了样本全集,其中叶节点对应于决策结果(是或否),其他每个结点对应于一个属性测试
5:从根节点到每个叶节点的路径对应一个判定测试序列
决策树叶子节点的生成
递归过程
导致递归返回的情况:
1:当前节点包含的样本全属于同一类别,无需划分
2:当前属性为空或所有样本在所有属性上取值相同,无需划分。把当前节点标记为叶节点,并将其类别设定为该节点所含样本最多的类别
3:当前节点包含的样本集为空,不能划分,同样把当前节点标记为叶节点
决策树学习的生成算法
根据不同的目标函数,算法分为ID3、C4.5、CART
建立决策树的关键,即在当前状态下选择哪个属性作为分类依据
| 算法类别 | ID3 | C4.5 | CART |
|---|---|---|---|
| 划分标准 | 信息增益 | 信息增益率 | 基尼指数(最小) |
决策树优缺点
优点
1:易于理解和实现,需要的背景知识少,直接体现数据特点
2:数据准备简单或不必要,可同时处理数据型和常规型属性
3:易于通过静态测试对模型评测(可信度)、逻辑表达式
缺点
1:对连续性的字段比较难预测
2:对有时间顺序的数据,需要预处理
3:若类别过多,错误增加快
7-3 集成学习
通过建立几个模型组合,解决单一预测问题
工作原理:生成多个分类器
集成学习方法分类
1:基于boosting(提升)
| Adaboost |
|---|
| 梯度提升决策树(GBDT) |
| XGBoost(extreme gradient boosting) |
| LightGBM |
基本思想:
(1)每个样本均赋予一个权重
(2)T次迭代,每次迭代后对分类错误的样本加大权重,下次迭代更加关注分类错误的样本
特点:
前面的学习器改变后面学习器的权重,学习器采用串联方式连接
采用线性加权方式进行组合,每个基学习器都有相应的权重,对于错误率小的基学习器会有更大的权重
2:基于bagging(装袋)
| 随机森林(Random Forest) |
|---|
| 极端随机树(Extremely randomized trees,Extra-Trees) |
基本思想:
对原始训练样本集采用自助随机采样,即有放回的随机采样,产生n个新的训练样本子集,以此分别训练n个基学习器,最后采用某种组合策略集成为强学习器
特点:
对于分类问题,通常使用简单投票法;对于回归问题,通常使用简单平均法
Adaboost
1: 初始化训练样本的权重分布,每个样本具有相同权重
2:训练一个弱分类器,如果样本分类正确,则在构造下一个训练集中,它的权重就会被降低;反之,提高样本的权重
3:用更新过的样本集去训练下一个弱分类器
4:各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,降低分类误差率大的弱分类器的权重
5: 将所有弱分类组合成强分类器
随机森林
随机:随机选取训练样本集、随机选取分裂属性集
森林:多棵决策树
过程:决策树的生长和投票
(依靠决策树的投票选择,决定最后的分类结果)
每棵树的生成
1:有放回的采样N个样本,构成训练集
2:无放回的随机选择m个特征,计算其信息增益并择优(通常 m = sqrt(M))
3:使用一般决策树的构建方法,得到一棵分类或预测的决策树
4:重复1-3步,得到H棵决策树,将某个测试样本输入H棵树得到H个结果,使用投票机制或最终分类结果判别测试样本所属的类别
随机森林的生成
分类效果(错误率)的相关因素:
1:森林中任意2棵树的相关性
相关性越大,错误率越大
2:森林中每棵树的分类能力
每棵树的分类能力越强,整个森林的错误率越低
随机森林唯一的参数:特征选择个数m
减少m,树的相关性和分类能力会降低
袋外错误率OOB error
最优m的选择,主要依据计算袋外错误率
第k棵树的袋外样本数据:没有参与第k棵树生成的训练实例
袋外错误率:对每棵树用未被选中的训练样本点,统计每棵树的误分率,最后取平均值得到随机森林的袋外错误率
随机森林特点
优点:
1-两个随机性的引入,不容易陷入过拟合,具有很好的抗噪声能力
2-对数据集适应能力强,可处理连续型和离散型数据,数据无需规范化,可运行大数据集
3-不需要降维,可处理高维特征的输入样本
4-在生成过程中,可获得内部生成误差的无偏估计
5-可处理缺省值问题
缺点:
1-噪声较大,可能过拟合
2-对有不同级别属性的数据,级别划分较多的属性会对随机森林产生更大的影响,随机森林在这类数据上产出的属性权值不可信
投票机制
1:简单投票机制
假设每个分类器平等
| 一票否决 |
|---|
| 少数服从多数 |
| 有效多数 |
| 阈值表决 |
2:贝叶斯投票机制
基于每个基本分类器在过去的分类表现,设定一个权值,按照这个权值进行投票
7-4 机器学习概念回顾
有监督学习:分类,回归
无监督学习:聚类,降维
相关文章:

【人工智能Ⅰ】7-KNN 决策树
【人工智能Ⅰ】7-KNN & 决策树 7-1 KNN(K near neighbour) 思想:一个样本与数据集中的k个样本最相似,若这k个样本大多数属于某类别,则该个样本也属于这类别 距离度量 样本相似性用欧氏距离定义 L p ( x i , x…...

【LeetCode】26. 删除有序数组中的重复项
26. 删除有序数组中的重复项 难度:简单 题目 给你一个 非严格递增排列 的数组 nums ,请你原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素…...

K8S知识点(八)
(1)实战入门-Label 通过标签实现Pod的区分,说白了就是一种标签选择机制 可以使用命令是否加了标签: 打标签: 更新标签: 筛选标签: 修改配置文件,重新创建一个pod 筛选࿱…...

25.4 MySQL 函数
1. 函数的介绍 1.1 函数简介 在编程中, 函数是一种组织代码的方式, 用于执行特定任务. 它是一段可以被重复使用的代码块, 通常接受一些输入(参数)然后返回一个输出. 函数可以帮助开发者将大型程序分解为更小的, 更易于管理的部分, 提高代码的可读性和可维护性.函数在编程语言…...

Unity 下载Zip压缩文件并且解压缩
1、Unity下载Zip压缩文件主要使用UnityWebRequest类。 可以参考以下方法: webRequest UnityWebRequest.Get(Path1); //压缩文件路径webRequest.timeout 60;webRequest.downloadHandler new DownloadHandlerBuffer();long fileSize GetLocalFileSize(Path2); …...

c++11新特性篇-委托构造函数和继承构造函数
C11引入了委托构造函数(Delegating Constructor)和C11及后续标准引入了继承构造函数(Inheriting Constructor)两个特性。 1.委托构造函数 委托构造函数是C11引入的一个特性,它允许一个构造函数调用同一类的另一个构造…...
案例)
Flink SQL处理回撤流(Retract Stream)案例
Flink SQL支持处理回撤流(Retract Stream),下面是一个使用Flink SQL消费回撤流的案例: 假设有一个数据流,包含用户的姓名和年龄,希望计算每个姓名的年龄总和。 以下是示例代码: // 创建流执行…...
)
6.5.事件图层(MapEventsOverlay)
愿你出走半生,归来仍是少年! 简单来说就是一个不参与绘制但是可进行交互的图层,它具备了单击和长按的交互功能。 booleanonSingleTapConfirmed(MotionEvent e, MapView mapView)booleanonLongPress(MotionEvent e, MapView mapView) 通过继承它重写上方…...
供暖系统如何实现数据远程采集?贝锐蒲公英高效实现智慧运维
山西某企业专注于暖通领域,坚持为城市集中供热行业和楼宇中央空调行业提供全面、专业的“智慧冷暖”解决方案。基于我国供热行业的管理现状,企业成功研发并推出了可将能源供应、管理与信息化、自动化相融合的ICS-DH供热节能管理系统。 但是,由…...
Flutter笔记:关于Flutter中的大文件上传(上)
Flutter笔记 关于Flutter中的大文件上传(上) 大文件上传背景与 Flutter 端实现文件分片传输 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址&#…...
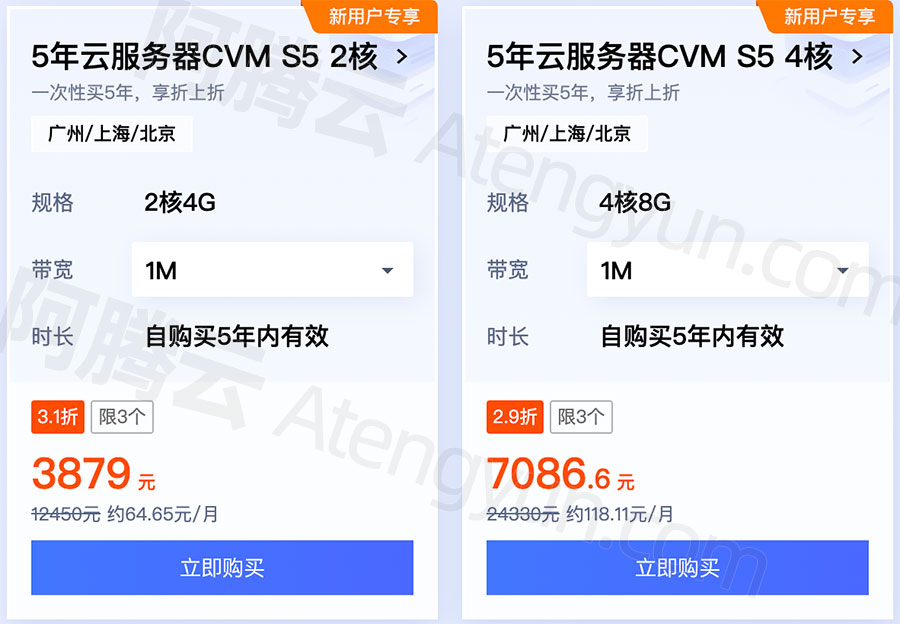
腾讯云CVM服务器5年可选2核4G和4核8G配置
腾讯云服务器网整理五年云服务器优惠活动 txyfwq.com/go/txy 配置可选2核4G和4核8G,公网带宽可选1M、3M或5M,系统盘为50G高性能云硬盘,标准型S5实例CPU采用主频2.5GHz的Intel Xeon Cascade Lake或者Intel Xeon Cooper Lake处理器,…...
数据结构:反射
基本概念 反射中的四个类 Class类 Java文件在被编译之后,生成了.class文件,JVM此时解读.class文件,将其解析为java.lang.Class 对象,在程序运行时每个java文件就最终变成了Class类对象的一个实例。通过反射机制应用这个 实例就…...

45 深度学习(九):transformer
文章目录 transformer原理代码的基础准备位置编码Encoder blockmulti-head attentionFeed Forward自定义encoder block Deconder blockEncoderDecodertransformer自定义loss 和 学习率mask生成函数训练翻译 transformer 这边讲一下这几年如日中天的新的seq2seq模式的transform…...

java中用javax.servlet.ServletInputStream.readLine有什么安全问题吗?怎么解决实例?
使用 javax.servlet.ServletInputStream.readLine 方法在处理 Servlet 请求时可能存在以下安全问题,以及相应的解决方案: 缓冲区溢出:readLine 方法会将数据读取到一个缓冲区中,并根据换行符分隔成行。如果输入流中包含过长的行或…...
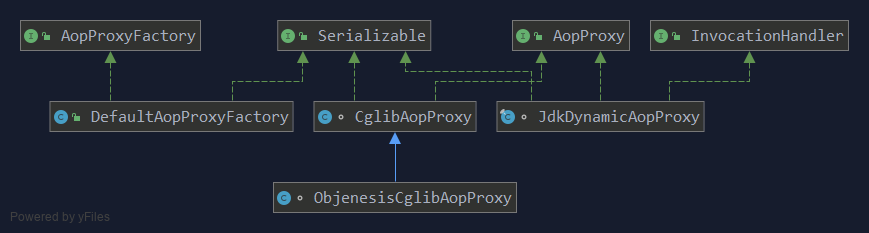
面试官问 Spring AOP 中两种代理模式的区别?很多面试者被问懵了
面试官问 Spring AOP 中两种代理模式的区别?很多初学者栽了跟头,快来一起学习吧! 代理模式是一种结构性设计模式。为对象提供一个替身,以控制对这个对象的访问。即通过代理对象访问目标对象,并允许在将请求提交给对象前后进行一…...
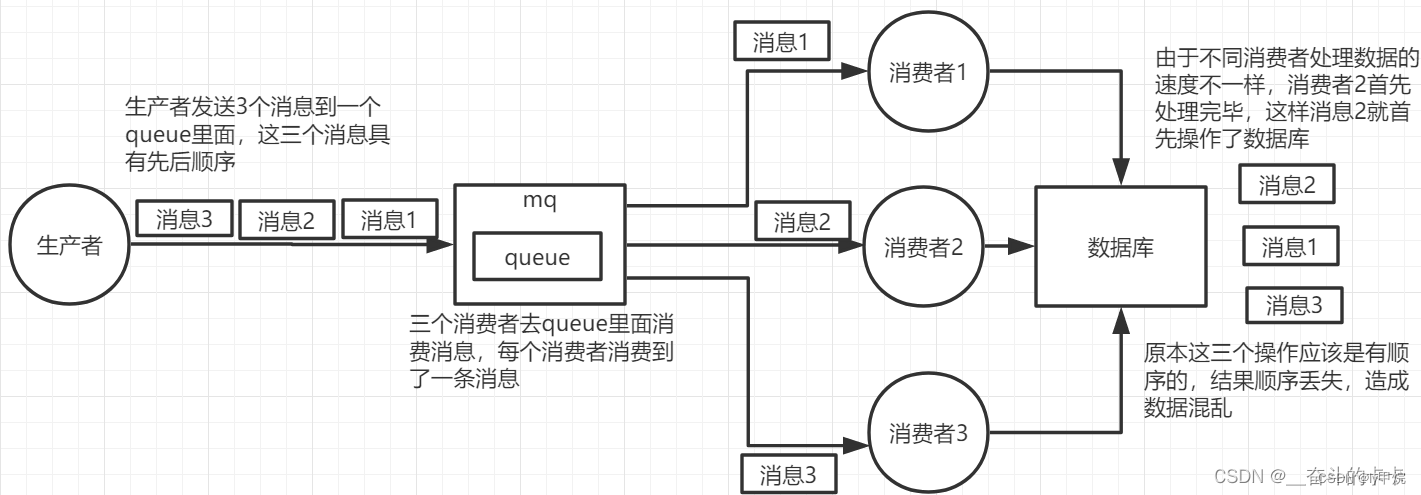
MQ四大消费问题一锅端:消息不丢失 + 消息积压 + 重复消费 + 消费顺序性
RabbitMQ-如何保证消息不丢失 生产者把消息发送到 RabbitMQ Server 的过程中丢失 从生产者发送消息的角度来说,RabbitMQ 提供了一个 Confirm(消息确认)机制,生产者发送消息到 Server 端以后,如果消息处理成功ÿ…...

Python爬虫——入门爬取网页数据
目录 前言 一、Python爬虫入门 二、使用代理IP 三、反爬虫技术 1. 间隔时间 2. 随机UA 3. 使用Cookies 四、总结 前言 本文介绍Python爬虫入门教程,主要讲解如何使用Python爬取网页数据,包括基本的网页数据抓取、使用代理IP和反爬虫技术。 一、…...
爬虫,TLS指纹 剖析和绕过
当你欲爬取某网页的信息数据时,发现通过浏览器可正常访问,而通过代码请求失败,换了随机ua头IP等等都没什么用时,有可能识别了你的TLS指纹做了验证。 解决办法: 1、修改 源代码 2、使用第三方库 curl-cffi from curl…...

Linux shell编程学习笔记25:tty
1 tty的由来 在 1830 年代和 1840 年代,开发了称为电传打字机(teletypewriters)的机器,这些机器可以将发件人在键盘上输入的消息“沿着线路”发送在接收端并打印在纸上。 电传打字机的名称由teletypewriters, 缩短为…...
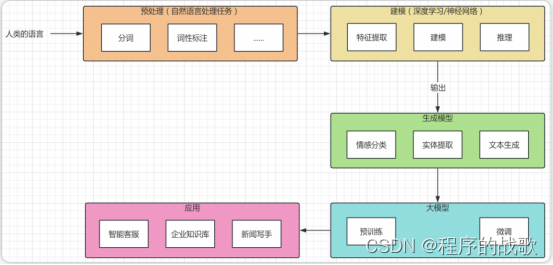
AIGC大模型-初探
大语⾔模型技术链 1. ⾃然语⾔处理 2. 神经⽹络 3. ⾃注意⼒机制 4. Transformer 架构 5. 具体模型 - GPT6. 预训练,微调 7. ⼤模型应⽤ - LangChain 大语⾔模型有什么用? 利⽤⼤语⾔模型帮助我们理解⼈类的命令,从⽽处理⽂本分析…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

基于ESP32与MQTT的家庭环境监测系统:从传感器选型到数据可视化实战
1. 项目概述与核心价值最近几年,我身边越来越多的朋友开始关注家里的空气质量、温湿度这些看不见摸不着,但又实实在在影响生活舒适度和健康的环境指标。从新装修的房子担心甲醛,到有老人小孩的家庭在意PM2.5和二氧化碳浓度,再到南…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...

浏览器指纹识别机制深度剖析与反识别技术实现
一、浏览器指纹技术基础认知1.1 浏览器指纹的核心定义在数字化时代,每一台接入互联网的设备都会留下独特的数字标识,浏览器指纹便是其中最关键的识别凭证之一。浏览器指纹是网站通过 JavaScript 脚本、HTTP 请求头、硬件接口调用等多种技术手段ÿ…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...