UDP主要丢包原因及具体问题分析
一、主要丢包原因
1、接收端处理时间过长导致丢包:调用recv方法接收端收到数据后,处理数据花了一些时间,处理完后再次调用recv方法,在这二次调用间隔里,发过来的包可能丢失。对于这种情况可以修改接收端,将包接收后存入一个缓冲区,然后迅速返回继续recv。
2、发送的包巨大丢包:虽然send方法会帮你做大包切割成小包发送的事情,但包太大也不行。例如超过50K的一个udp包,不切割直接通过send方法发送也会导致这个包丢失。这种情况需要切割成小包再逐个send。
3、发送的包较大,超过接受者缓存导致丢包:包超过mtu size数倍,几个大的udp包可能会超过接收者的缓冲,导致丢包。这种情况可以设置socket接收缓冲。以前遇到过这种问题,我把接收缓冲设置成64K就解决了。
int nRecvBuf=32*1024;//设置为32K
setsockopt(s,SOL_SOCKET,SO_RCVBUF,(const char*)&nRecvBuf,sizeof(int));
4、发送的包频率太快:虽然每个包的大小都小于mtu size 但是频率太快,例如40多个mut size的包连续发送中间不sleep,也有可能导致丢包。这种情况也有时可以通过设置socket接收缓冲解决,但有时解决不了。所以在发送频率过快的时候还是考虑sleep一下吧。
5、局域网内不丢包,公网上丢包。这个问题我也是通过切割小包并sleep发送解决的。如果流量太大,这个办法也不灵了。总之udp丢包总是会有的,如果出现了用我的方法解决不了,还有这个几个方法: 要么减小流量,要么换tcp协议传输,要么做丢包重传的工作。
二、具体问题分析
1.发送频率过高导致丢包
很多人会不理解发送速度过快为什么会产生丢包,原因就是UDP的SendTo不会造成线程阻塞,也就是说,UDP的SentTo不会像TCP中的SendTo那样,直到数据完全发送才会return回调用函数,它不保证当执行下一条语句时数据是否被发送。(SendTo方法是异步的)这样,如果要发送的数据过多或者过大,那么在缓冲区满的那个瞬间要发送的报文就很有可能被丢失。至于对“过快”的解释,作者这样说:“A few packets a second are not an issue; hundreds or thousands may be an issue.”(一秒钟几个数据包不算什么,但是一秒钟成百上千的数据包就不好办了)。 要解决接收方丢包的问题很简单,首先要保证程序执行后马上开始监听(如果数据包不确定什么时候发过来的话),其次,要在收到一个数据包后最短的时间内重新回到监听状态,其间要尽量避免复杂的操作(比较好的解决办法是使用多线程回调机制)。
2.报文过大丢包
至于报文过大的问题,可以通过控制报文大小来解决,使得每个报文的长度小于MTU。以太网的MTU通常是1500 bytes,其他一些诸如拨号连接的网络MTU值为1280 bytes,如果使用speaking这样很难得到MTU的网络,那么最好将报文长度控制在1280 bytes以下。
3.发送方丢包
发送方丢包:内部缓冲区(internal buffers)已满,并且发送速度过快(即发送两个报文之间的间隔过短); 接收方丢包:Socket未开始监听; 虽然UDP的报文长度最大可以达到64 kb,但是当报文过大时,稳定性会大大减弱。这是因为当报文过大时会被分割,使得每个分割块(翻译可能有误差,原文是fragmentation)的长度小于MTU,然后分别发送,并在接收方重新组合(reassemble),但是如果其中一个报文丢失,那么其他已收到的报文都无法返回给程序,也就无法得到完整的数据了。
--------------------------------------------------------------------------------
最近在研究linux下的UDP的传输,但是由于UDP协议本身的一些原因,在数据量非常大的时候会造成一定数量的丢包,数量越大,丢包率越高.
为了解决丢包这个问题,我从网上查到了一些资料,大致可以从三个方面来解决这个问题.
1. 从发送端解决(推荐)
适用条件: ①发送端是可以控制的.②微秒数量级的延迟可以接受.
解决方法:发送时使用usleep(1)延迟1微秒发送,即发送频率不要过快,延迟1微妙发送,可以很好的解决这个问题.
2.从接收端解决方法一
适用条件:①无法控制发送端发送数据的频率
解决方法: 用recvfrom函数收到数据之后尽快返回,进行下一次recvfrom,可以通过多线程+队列来解决.收到数据之后将数据放入队列中,另起一个线程去处理收到的数据.
3.从接收端解决方法二
适用条件:①使用方法2依然出现大规模丢包的情况,需要进一步优化
解决方法:使用setsockopt修改接收端的缓冲区大小,
-
int rcv_size = 1024*1024; //1M -
int optlen=sizeof(rcv_size); -
int err=setsockopt(sock,SOL_SOCKET,SO_RCVBUF,(char *)&rcv_size,optlen);//设置好缓冲区大小
设置完毕可以通过
setsockopt(sock,SOL_SOCKET,SO_RCVBUF,(char *)&rcv_size,(socklen_t *)&optlen);来查看当前sock的缓冲区大小
但是,会发现查到的大小并不是1M而是256kb,后来发现原来是linux系统默认缓冲区大小为128kb,设置最大是这个的2倍
所以需要通过修改系统默认缓冲区大小来解决
使用root账户在命令行下输入:
vi /etc/sysctl.conf添加一行记录(1049576=1024*1024=1M)
net.core.rmem_max=1048576保存之后输入
/sbin/sysctl -p使修改的配置生效
此时可以通过 sysctl -a|grep rmem_max 来看配置是否生效.
生效之后可以再次运行程序来getsockopt看缓冲区是否变大了,是否还会出现丢包现象了
楼主使用的是方法2+方法3 双管齐下,已经不会出现丢包现象了,如果还有不同程度的丢包 可以通过方法三种继续增加缓冲区大小的方式来解决
--------------------------------------------------------------------------------
UDP丢包
我们是后一个包丢掉了
最近在做一个项目,在这之前,做了个验证程序.
发现客户端连续发来1000个1024字节的包,服务器端出现了丢包现象.
纠其原因,是服务端在还未完全处理掉数据,客户端已经数据发送完毕且关闭了.
有没有成熟的解决方案来解决这个问题.
我用过sleep(1),暂时解决这个问题,但是这不是根本解决办法,如果数据量大而多,网络情况不太好的话,还是有可能丢失.
你试着用阻塞模式吧...
select...我开始的时候好像也遇到过..不过改为阻塞模式后就没这个问题了...
采用回包机制,每个发包必须收到回包后再发下一个
UDP丢包是正常现象,因为它是不安全的。
丢包的原因我想并不是“服务端在还未完全处理掉数据,客户端已经数据发送完毕且关闭了”,而是服务器端的socket接收缓存满了(udp没有流量控制,因此发送速度比接收速度快,很容易出现这种情况),然后系统就会将后来收到的包丢弃。你可以尝试用setsockopt()将接收缓存(SO_RCVBUF)加大看看能不能解决问题。
服务端采用多线程pthread接包处理
UDP是无连接的,面向消息的数据传输协议,与TCP相比,有两个致命的缺点,一是数据包容易丢失,二是数据包无序。
要实现文件的可靠传输,就必须在上层对数据丢包和乱序作特殊处理,必须要有要有丢包重发机制和超时机制。
常见的可靠传输算法有模拟TCP协议,重发请求(ARQ)协议,它又可分为连续ARQ协议、选择重发ARQ协议、滑动窗口协议等等。
如果只是小规模程序,也可以自己实现丢包处理,原理基本上就是给文件分块,每个数据包的头部添加一个唯一标识序号的ID值,当接收的包头部ID不是期望中的ID号,则判定丢包,将丢包ID发回服务端,服务器端接到丢包响应则重发丢失的数据包。
模拟TCP协议也相对简单,3次握手的思想对丢包处理很有帮助。
udp是不安全的,如果不加任何控制,不仅会丢失包,还可能收到包的顺序和发送包的顺序不一样。这个必须在自己程序中加以控制才行。
收到包后,要返回一个应答,如果发送端在一定时间内没有收到应答,则要重发。
UDP本来存在丢包现象,现在的解决方案暂时考虑双方增加握手.
这样做起来,就是UDP协议里面加上了TCP的实现方法.
程序中采用的是pthread处理,丢包率时大时小,不稳定可靠
我感觉原因可能有两个,一个是客户端发送过快,网络状况不好或者超过服务器接收速度,就会丢包。
第二个原因是服务器收到包后,还要进行一些处理,而这段时间客户端发送的包没有去收,造成丢包。
解决方法,一个是客户端降低发送速度,可以等待回包,或者加一些延迟。
二是,服务器部分单独开一个线程,去接收UDP数据,存放在一个缓冲区中,又另外的线程去处理收到的数据,尽量减少因为处理数据延时造成的丢包。
有两种方法解决楼主的问题:
方法一:重新设计一下协议,增加接收确认超时重发。(推荐)
方法二:在接收方,将通信和处理分开,增加个应用缓冲区;如果有需要增加接收socket的系统缓冲区。(本方法不能从根本解决问题,只能改善)
网络丢包,是再正常不过的了。
既然用UDP,就要接受丢包的现实,否则请用TCP。
如果必须使用UDP,而且丢包又是不能接受的,只好自己实现确认和重传,说白了,就是自己实现TCP(当然是部分和有限的简单实现)。
UDP是而向无连接的,用户在实施UDP编程时,必须制定上层的协议,包括流控制,简单的超时和重传机制,如果不要求是实时数据,我想TCP可能会更适合你!
-------------------------
1:什么是丢包率?
你的电脑向目标发送一个数据包,如果对方没有收到.就叫丢包.
比如你发10个,它只收到9个. 那么丢包率就是 10%
数据在网络中是被分成一各个个数据报传输的,每个数据报中有表示数据信息和提供数据路由的桢.而数据报在一般介质中传播是总有一小部分由于两个终端的距离过大会丢失,而大部分数据包会到达目的终端.所谓网络丢包率是数据包丢失部分与所传数据包总数的比值.正常传输时网络丢包率应该控制在一定范围内.
2:什么是吞吐量?
网络中的数据是由一个个数据包组成,防火墙对每个数据包的处理要耗费资源。吞吐量是指在没有帧丢失的情况下,设备能够接受的最大速率。其测试方法是:在测试中以一定速率发送一定数量的帧,并计算待测设备传输的帧,如果发送的帧与接收的帧数量相等,那么就将发送速率提高并重新测试;如果接收帧少于发送帧则降低发送速率重新测试,直至得出最终结果。吞吐量测试结果以比特/秒或字节/秒表示。
吞吐量和报文转发率是关系防火墙应用的主要指标,一般采用FDT(Full Duplex Throughput)来衡量,指64字节数据包的全双工吞吐量,该指标既包括吞吐量指标也涵盖了报文转发率指标。
随着Internet的日益普及,内部网用户访问Internet的需求在不断增加,一些企业也需要对外提供诸如WWW页面浏览、FTP文件传输、DNS域名解析等服务,这些因素会导致网络流量的急剧增加,而防火墙作为内外网之间的唯一数据通道,如果吞吐量太小,就会成为网络瓶颈,给整个网络的传输效率带来负面影响。因此,考察防火墙的吞吐能力有助于我们更好的评价其性能表现。这也是测量防火墙性能的重要指标。
吞吐量的大小主要由防火墙内网卡,及程序算法的效率决定,尤其是程序算法,会使防火墙系统进行大量运算,通信量大打折扣。因此,大多数防火墙虽号称100M防火墙,由于其算法依靠软件实现,通信量远远没有达到100M,实际只有10M-20M。纯硬件防火墙,由于采用硬件进行运算,因此吞吐量可以达到线性90-95M,是真正的100M防火墙。
对于中小型企业来讲,选择吞吐量为百兆级的防火墙即可满足需要,而对于电信、金融、保险等大公司大企业部门就需要采用吞吐量千兆级的防火墙产品。
3:检测丢包率
下载一个世纪前线,在百度可以找到,很小的程序。
NetIQ Chariot 一款网络应用软件性能测试工具
网络吞吐量测试,CHARIOT测试网络吞吐量
相关文章:

UDP主要丢包原因及具体问题分析
一、主要丢包原因 1、接收端处理时间过长导致丢包:调用recv方法接收端收到数据后,处理数据花了一些时间,处理完后再次调用recv方法,在这二次调用间隔里,发过来的包可能丢失。对于这种情况可以修改接收端,将包接收后存入…...
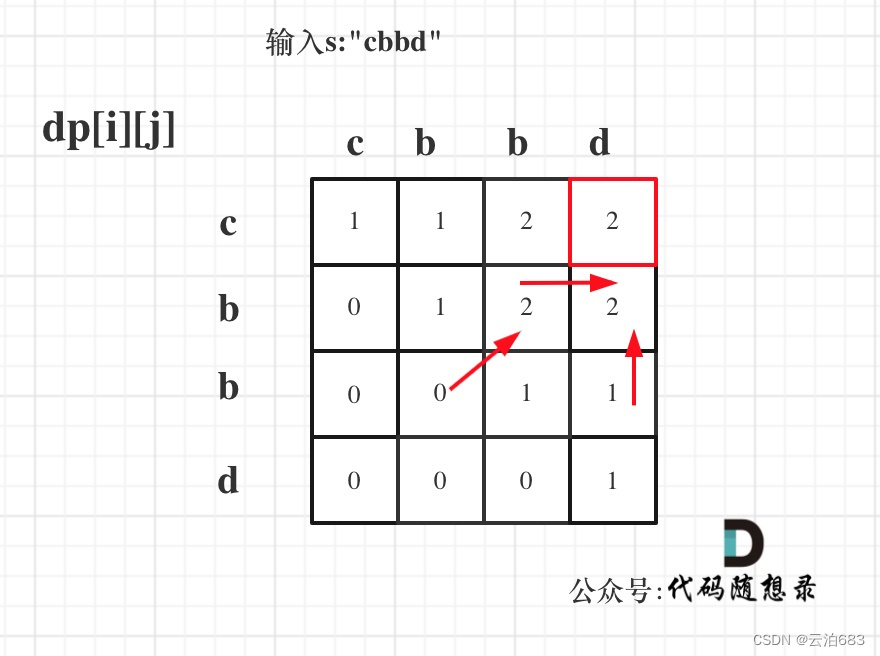
647. 回文子串 516.最长回文子序列
647. 回文子串 题目: 给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。 回文字符串 是正着读和倒过来读一样的字符串。 子字符串 是字符串中的由连续字符组成的一个序列。 具有不同开始位置或结束位置的子串,即使是由相…...

点云从入门到精通技术详解100篇-双传感器模式的非结构化环境检测与识别
目录 前言 国内外研究现状 可通行区域检测的研究 障碍物检测的研究...

Nginx-反向代理
反向代理 1 语法 server {listen 82; server_name www.liyong.f.com;location ~* .*(css|js|html|images). {proxy_pass http://11.22.19.81:8088; } 上面的示例的意思是: 当访问:http://www.liyong.f.com:82/static/css/OneMap.b728e2e4.css 转发到 …...
Java封装一个根据指定的字段来获取子集的工具类
工具类 ZhLambdaUtils SuppressWarnings("all") public class ZhLambdaUtils {/*** METHOD_NAME*/private static final String METHOD_NAME "writeReplace";/*** 获取到lambda参数的方法名称** param <T> parameter* param function functi…...

【HUST】网安纳米|2023年研究生纳米技术考试参考
目录 1 纳米材料是什么 2 纳米材料的结构特性 3 纳米结构的其他特性 4 纳米结构的检测技术 5 纳米材料的应用 打印建议:PPT彩印(这样重点比较突出),每面12张PPT,简单做一下关键词目录,亲测可以看清。如…...

【移远QuecPython】EC800M物联网开发板的MQTT协议腾讯云数据上报
【移远QuecPython】EC800M物联网开发板的MQTT协议腾讯云数据上报 文章目录 导入库初始化设置MQTT注册回调订阅发布功能开启服务发送消息函数打包调用测试效果附录:列表的赋值类型和py打包列表赋值BUG复现代码改进优化总结 py打包 导入库 from TenCentYun import TX…...
关灯游戏及扩展
7.8 图形界面应用案例——关灯游戏 题目: [案例]游戏初步——关灯游戏。 关灯游戏是很有意思的益智游戏,玩家通过单击关掉(或打开)一盏灯。如果关(掉(或打开)一个电灯,其周围(上下左右)的电灯也会触及开关,成…...
)
深度解析:用Python爬虫逆向破解dappradar的URL加密参数(最详细逆向实战教程,小白进阶高手之路)
特别声明:本篇文章仅供学习与研究使用,不得用做任何非法用途,请大家遵守相关法律法规 目录 一、逆向目标二、准备工作三、逆向分析 - 太详细了!3.1 逆向前的一些想法3.1.1 加密字符串属性猜测3.1.2 是否可以手动复制加密API?3.2 XHR断点调试3.3 加密前各参数属性的变化情况…...
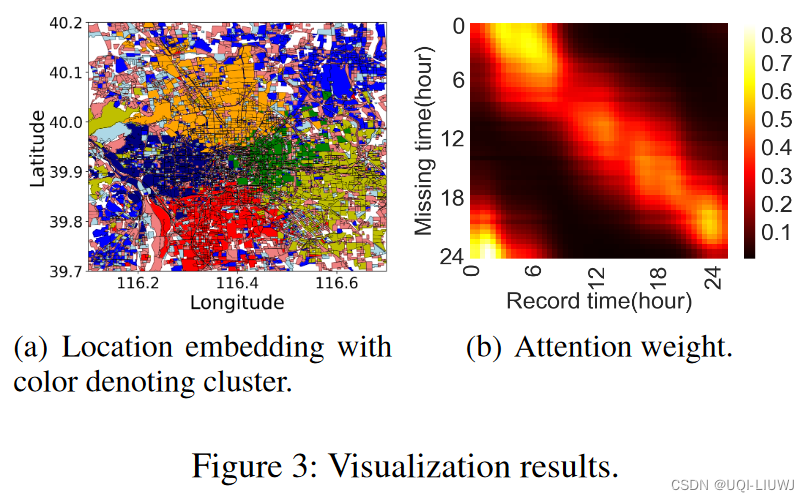
论文笔记:AttnMove: History Enhanced Trajectory Recovery via AttentionalNetwork
AAAI 2021 1 intro 1.1 背景 将用户稀疏的轨迹数据恢复至细粒度的轨迹数据是十分重要的恢复稀疏轨迹数据至细粒度轨迹数据是非常困难的 已观察到的用户位置数据十分稀疏,使得未观察到的用户位置存在较多的不确定性真实数据中存在大量噪声,如何有效的挖…...

Django之视图层
目录 一、三板斧的使用 二、JsonReponse序列化类的使用 三、 form表单上传文件 数据准备 数据处理 (1)post请求数据 (2)文件数据获取 四、 FBV与CBV 五、CBV的源码分析 as_view 方法 一、三板斧的使用 HttpResponse 返回字符串类型render 渲染html页面,并…...
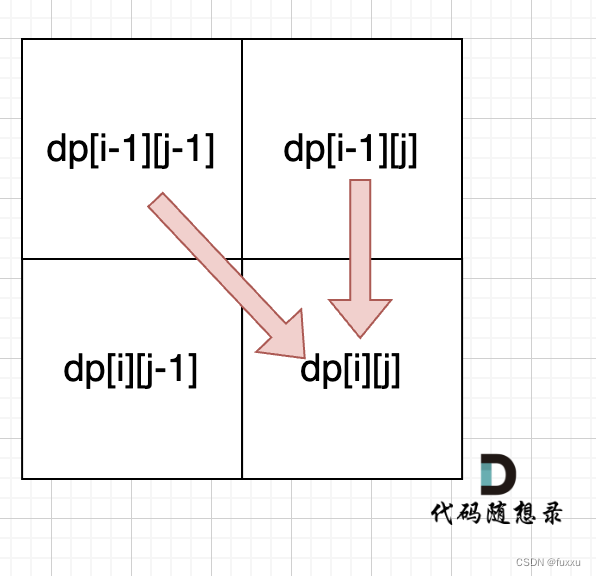
DAY54 392.判断子序列 + 115.不同的子序列
392.判断子序列 题目要求:给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是…...
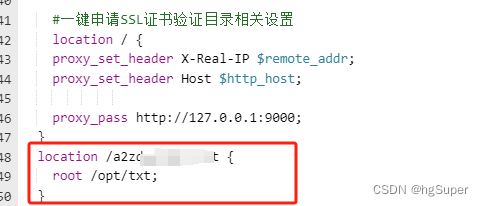
【Nginx】nginx | 微信小程序验证域名配置
【Nginx】nginx | 微信小程序验证域名配置 一、说明二、域名管理 一、说明 小程序需要添加头条的功能,内容涉及到富文本内容显示图片资源存储在minio中,域名访问。微信小程序需要验证才能显示。 二、域名管理 服务器是阿里云,用的宝塔管理…...

大数据Doris(二十二):数据查看导入
文章目录 数据查看导入 数据查看导入 Broker load 导入方式由于是异步的,所以用户必须将创建导入的 Label 记录,并且在查看导入命令中使用 Label 来查看导入结果。查看导入命令在所有导入方式中是通用的,具体语法可执行 HELP SHOW LOAD 查看。 show load order by create…...

STM32 I2C详解
STM32 I2C详解 I2C简介 I2C(Inter IC Bus)是由Philips公司开发的一种通用数据总线 两根通信线: SCL(Serial Clock)串行时钟线,使用同步的时序,降低对硬件的依赖,同时同步的时序稳定…...
)
软考 系统架构设计师系列知识点之云计算(1)
所属章节: 第11章. 未来信息综合技术 第6节. 云计算和大数据技术概述 大数据和云计算已成为IT领域的两种主流技术。“数据是重要资产”这一概念已成为大家的共识,众多公司争相分析、挖掘大数据背后的重要财富。同时学术界、产业界和政府都对云计算产生了…...
VS Code画流程图:draw.io插件
文章目录 简介快捷键 简介 Draw.io是著名的流程图绘制软件,开源免费,对标Visio,用过的都说好。而且除了提供常规的桌面软件之外,直接访问draw.io就可以在线使用,堪称百分之百跨平台,便捷性直接拉满。 那么…...
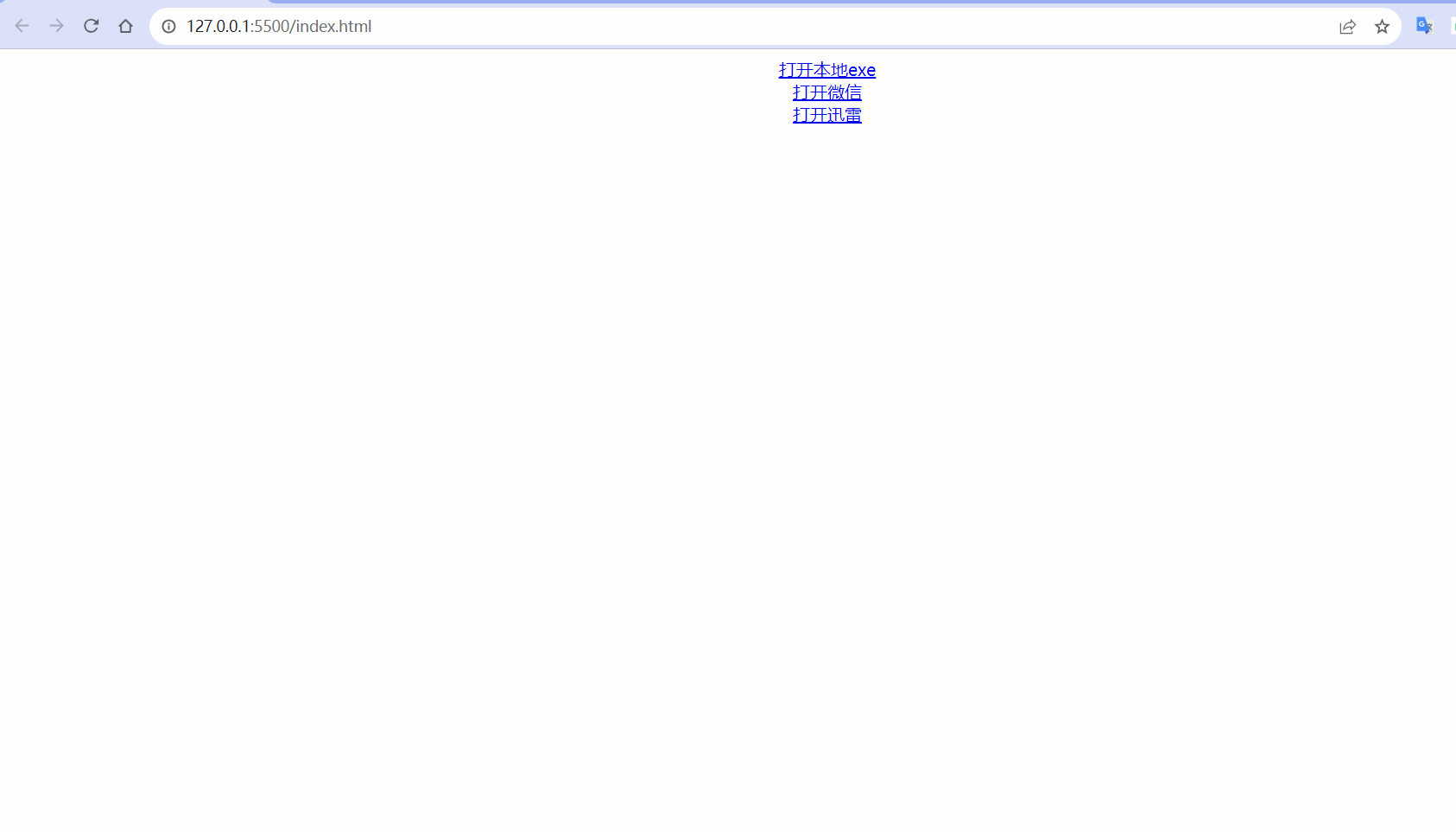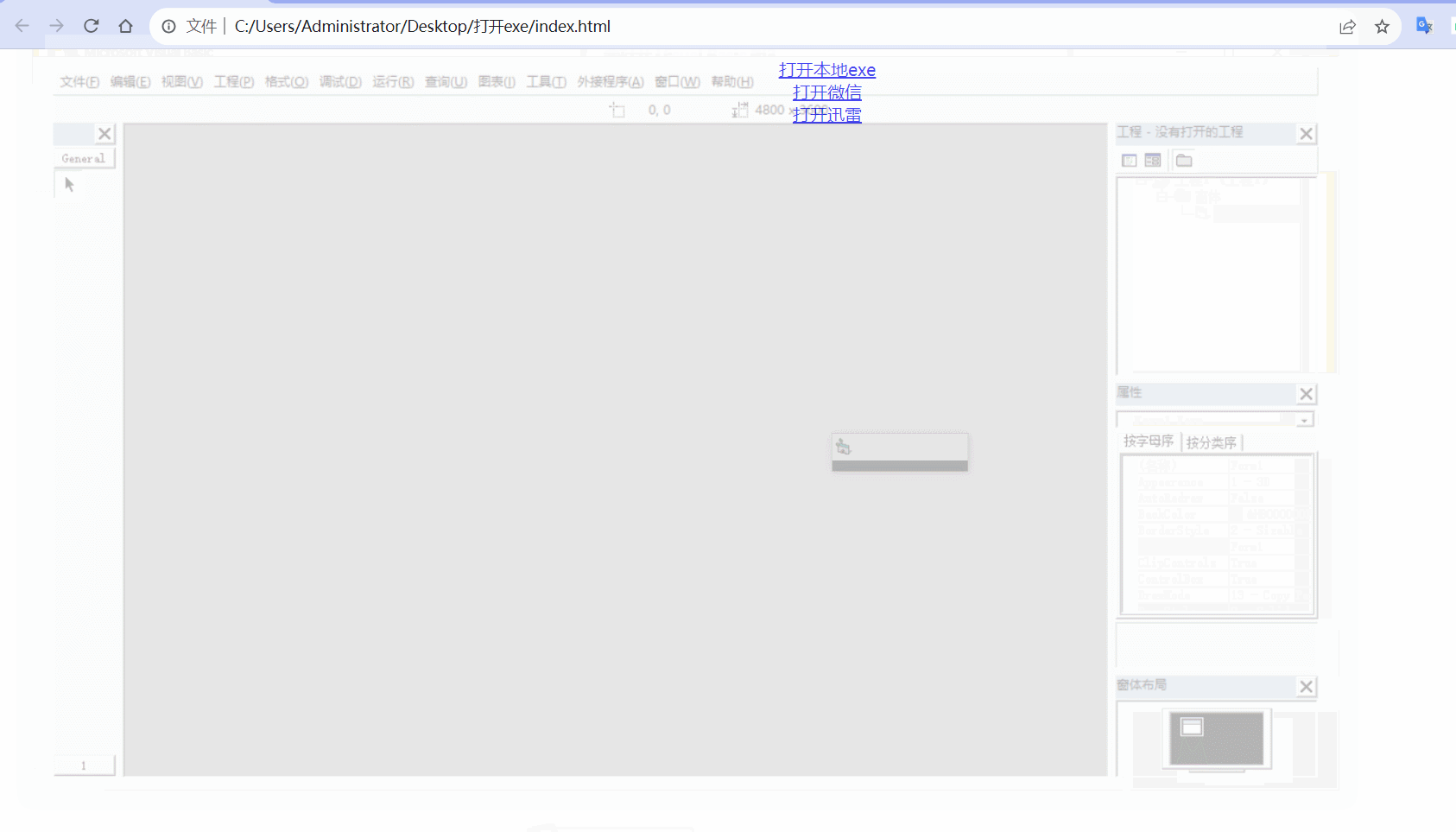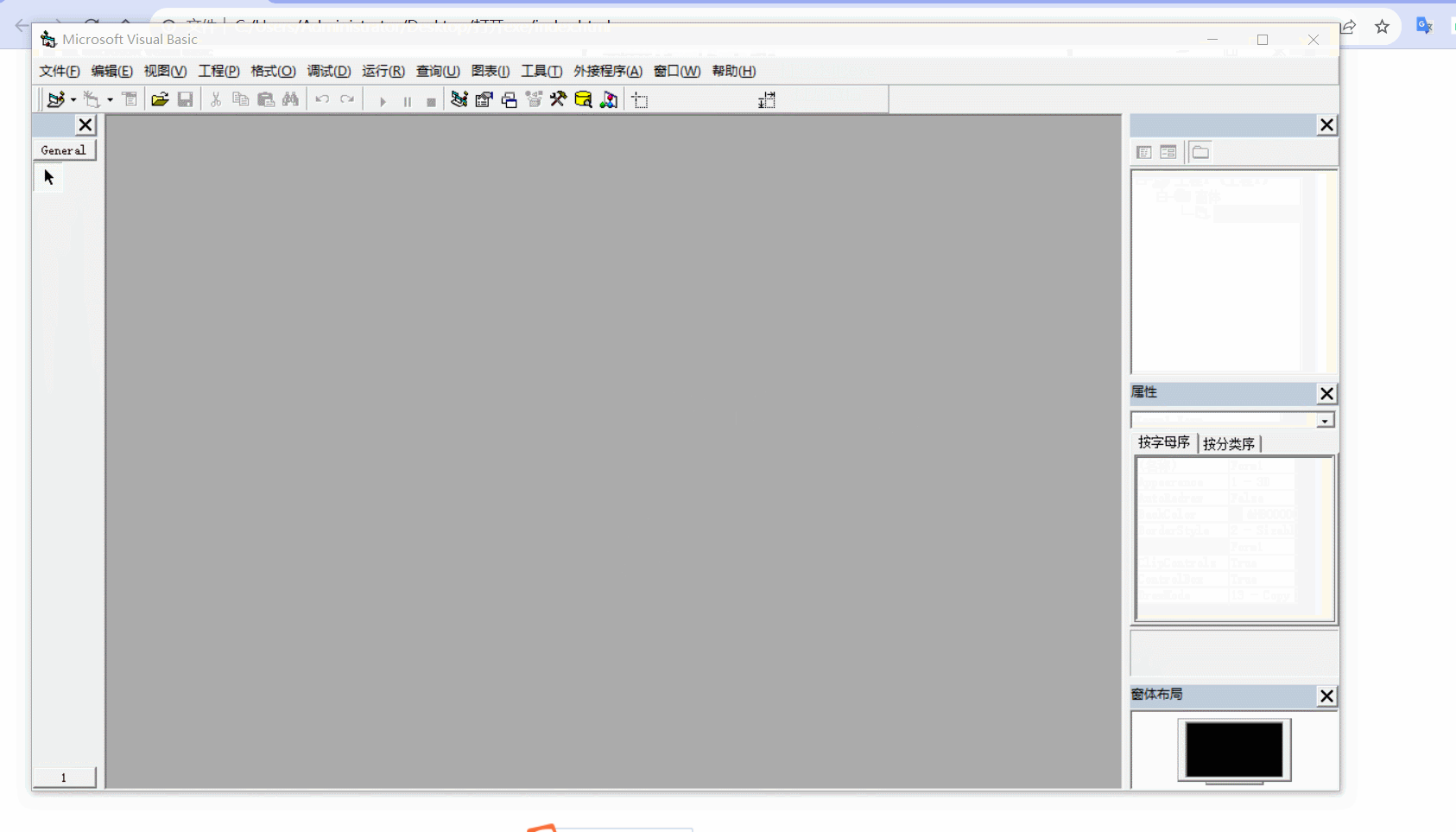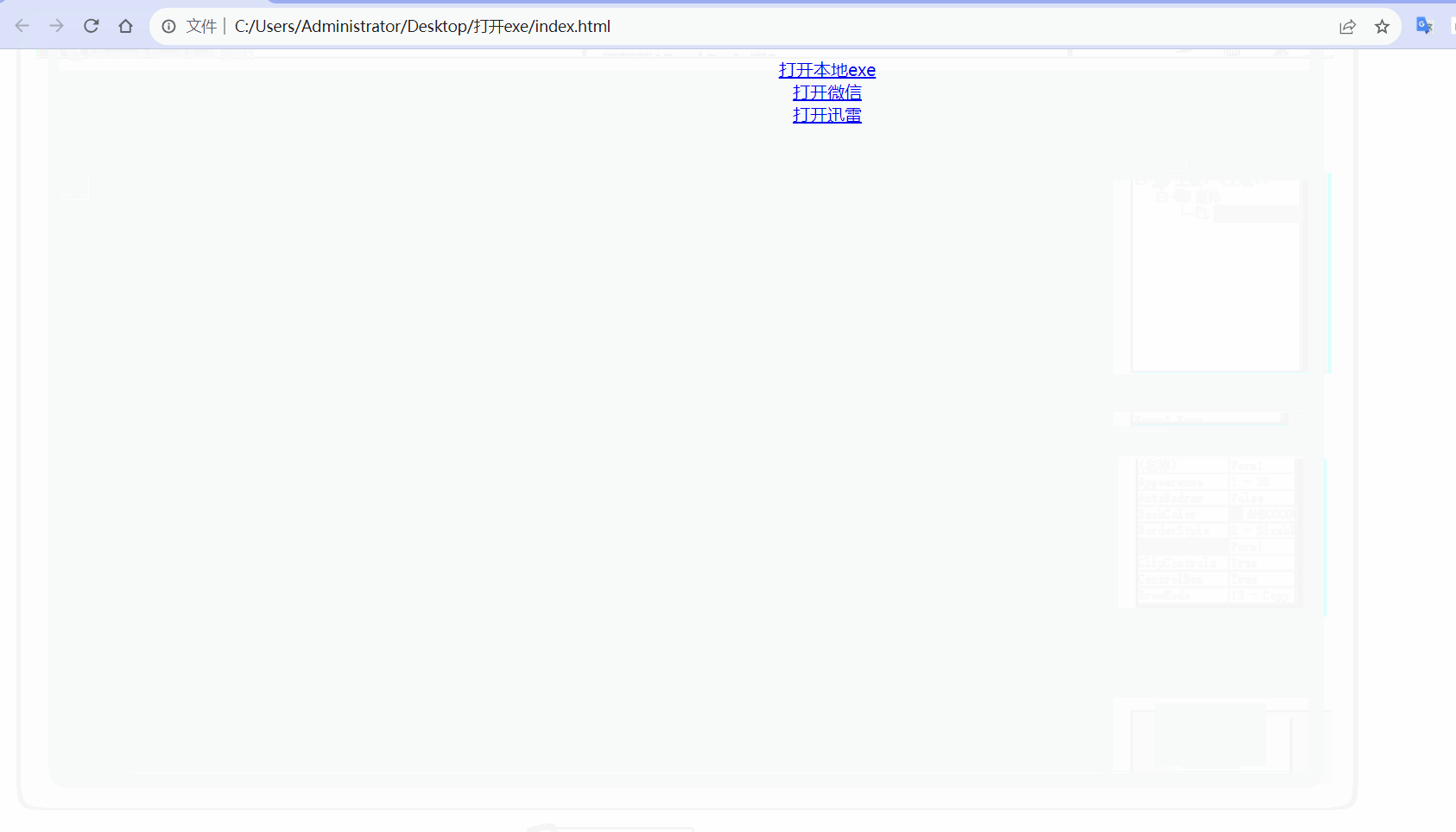
计算机 - - - 浏览器网页打开本地exe程序,网页打开微信,网页打开迅雷
效果 在电脑中安装了微信和迅雷,可以通过在地址栏中输入weixin:打开微信,输入magnet:打开迅雷。 同理:在网页中使用a标签,点击后跳转链接打开weixin:,也会同样打开微信。 运用同样的原理,在网页中点击超…...

C_6练习题
一、单项选择题(本大题共20小题,每小题2分,共40分。在每小题给出的四个备选项中,选出一个正确的答案,并将所选项前的字母填写在答题纸的相应位置上。) 下列叙述中正确的是()。 A.C语言程序将从源程序中第一个函数开始执行 B.可以在程序中由用户指定任意一个函数作为…...

XUbuntu22.04之安装pkg-config(一百九十二)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

flameshow性能优化技巧:如何快速定位Go程序中的CPU热点
flameshow性能优化技巧:如何快速定位Go程序中的CPU热点 【免费下载链接】flameshow A terminal Flamegraph viewer. 项目地址: https://gitcode.com/gh_mirrors/fl/flameshow 🔥 想要快速定位Go程序中的性能瓶颈吗?flameshow是一个强大…...

C++ vector容器总结
vector基本概念功能:vector数据结构和数组非常相似,也称为单端数组vector与普通数组区别:不同之处在于数组是静态空间,而vector可以动态扩展动态扩展:并不是在原空间之后续接新空间,而是找更大的内存空间&a…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...
【php语法学习,iscc校赛wp】)
学习日志(三)【php语法学习,iscc校赛wp】
1. 任务 1.1.1.1.1.1. 知识部分 rce看【之前的笔记?】php的知识点学习继续jwt token好像是比赛的题目考察内容,我看看php伪协议 1.1.1.1.1.2. 题目 参加iscc比赛【五一】rce题目 1.1.1.1.1.3. 环境配置 把vscode搞好,上学期没有把Php配…...

昇腾CANN cmake 实战:CANN CMake 构建系统——跨平台编译配置与模块化管理
8 个 CANN 仓库各需独立构建(ops-transformer/ops-nn/hccl/ge/…)→ 手写 8 套 CMakeLists.txt(CANN 路径判断、跨 NPU 型号编译、第三方库兼容)。cmake 仓库提供统一的 FindCANN.cmake CANNConfig.cmake 模板——任何仓库只需 f…...