Redis模块的高级使用方式
Redis 模块是Redis的高级功能,允许我们实现特定的自定义数据类型。本质上,模块是一个动态库,可以在启动时或根据命令按需加载到 Redis 中 MODULE LOAD 。模块可以用多种语言编写,包括 C 和 Rust。
我们自己使用 Redis 模块实现新的数据类型是一项艰巨的工作。值得庆幸的是,有许多流行且广泛使用的模块可以解决全文搜索(RediSearch)、时间序列处理(RedisTimeSeries)和原生 JSON 支持(RedisJSON)等问题。让我们概述一下一些使用更广泛的 Redis 模块。
本节提供了 RediSearch、RedisJSON 和 RedisTimeSeries 模块的高级概述,以及与它们相关的重要命令。
要完成本教程的这一部分,您需要 安装最新版本的 Go 和 Docker。所有上述模块都作为Redis Stack的一部分提供 ,它将 Redis 与各种相关的软件包和服务捆绑在一起。您可以使用 Docker 启动 Redis Stack 本地实例 :
docker run -d --name redis-stack -p 6379:6379 redis/redis-stack:latest
在开始之前,让我们创建一个 Go 模块来托管示例:
go mod init go-redis-modules
RedisJSON
在 Redis 中处理 JSON 数据时,传统方法有其局限性。默认情况下,Redis 将值视为简单字符串,缺乏对查询或操作 JSON 等结构化数据的内置支持。因此,开发人员经常将 JSON 存储为 字符串化 值,从而牺牲了对各个字段执行高效操作或利用嵌套结构的能力。这种方法需要解析整个 JSON 文档,即使是微小的更新,导致效率低下并增加处理开销。
RedisJSON 模块通过向 Redis 引入本机 JSON 处理功能来解决这些挑战。它允许您像任何其他本机数据类型一样存储、更新和检索 JSON。
RedisJSON 提供了一组丰富的 JSON 文档操作。以下是一些最常用的命令:
- JSON.SET:在 Redis 中设置 JSON 值。
- JSON.GET:检索与给定键关联的 JSON 值。
- JSON.DEL:从 Redis 中删除 JSON 值。
- JSON.TYPE:返回JSON值的类型,指示它是对象、数组、字符串、数字、布尔值还是null。
- JSON.ARRAPPEND:将一个或多个值附加到 JSON 数组的末尾。
- JSON.ARRLEN:返回 JSON 数组的长度,提供其包含的元素数量。
- JSON.OBJKEYS:检索 JSON 对象的键,返回所有存在键的数组。
- JSON.OBJLEN:返回JSON对象的大小。
- JSON.NUMINCRBY:将 JSON 文档中的数值增加指定的量。
- JSON.STRAPPEND:在 JSON 文档中附加字符串。
下面的示例演示了如何在 Go 应用程序中使用各种 RedisJSON 命令。请注意,我们使用的是 go-redis 客户端。
package main
import (
"context"
"errors"
"fmt"
"log"
"github.com/redis/go-redis/v9"
)
func main() {
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
ctx := context.Background()
// JSON.SET
err := rdb.Do(ctx, "JSON.SET", "mydoc", ".", `{"name":"John","credits":30,"cars":["honda","toyota"]}`).Err()
if err != nil {
log.Fatal(err)
}
// JSON.GET
val, err := rdb.Do(ctx, "JSON.GET", "mydoc").Result()
if err != nil {
log.Fatal(err)
}
fmt.Println("JSON.GET result -", val)
// JSON.ARRAPPEND
_, err = rdb.Do(ctx, "JSON.ARRAPPEND", "mydoc", ".cars", `"audi"`).Int()
if err != nil {
log.Fatal(err)
}
fmt.Println("added audi to list of cars using JSON.ARRAPPEND")
// JSON.GET
val, err = rdb.Do(ctx, "JSON.GET", "mydoc").Result()
if err != nil {
log.Fatal(err)
}
fmt.Println("lastest document", val)
// JSON.NUMINCRBY
_, err = rdb.Do(ctx, "JSON.NUMINCRBY", "mydoc", ".credits", 5).Result()
if err != nil {
log.Fatal(err)
}
fmt.Println("incremented credits by 5 using JSON.NUMINCRBY")
// JSON.STRAPPEND
_, err = rdb.Do(ctx, "JSON.STRAPPEND", "mydoc", ".name", `", Jr."`).Int()
if err != nil {
log.Fatal(err)
}
fmt.Println("updated name using JSON.STRAPPEND")
// JSON.GET
val, err = rdb.Do(ctx, "JSON.GET", "mydoc").Result()
if err != nil {
log.Fatal(err)
}
fmt.Println("latest document", val)
// JSON.DEL
_, err = rdb.Do(ctx, "JSON.DEL", "mydoc").Int()
if err != nil {
log.Fatal(err)
}
fmt.Println("deleted document using JSON.DEL")
err = rdb.Do(ctx, "JSON.GET", "mydoc").Err()
if errors.Is(err, redis.Nil) {
fmt.Println("document 'mydoc' could not be found")
}
}
要运行上述代码,请将其复制到名为的文件中 main.go 并执行以下命令:
# get dependencies
go get github.com/redis/go-redis/v9
# run program
go run main.go
请注意,我们不需要获取整个 JSON 文档来更新它。RedisJSON 提供精细操作来处理 JSON 数据,从而提高应用程序性能(减少延迟)并降低成本(减少网络带宽)。
RediSearch
RediSearch模块通过强大的全文搜索功能增强了Redis。它引入了基于倒排索引的搜索引擎,允许高效且可扩展的文本搜索。使用 RediSearch,您可以索引文本数据、执行复杂的搜索查询并检索相关搜索结果。
它提供关键字搜索、精确短语匹配、布尔运算、分页、排序和过滤等功能。
RediSearch 根据搜索结果与查询的匹配程度对搜索结果进行评分,使您能够对搜索结果进行排名和确定优先级。
以下是一些最常用的 RediSearch 命令:
- FT.CREATE:使用指定的架构和配置选项创建新的搜索索引。
- FT.SEARCH:对指定索引执行搜索查询,根据给定的搜索条件返回匹配的文档。
- FT.AGGREGATE:对指定索引进行聚合查询,根据给定的聚合条件返回聚合结果。
- FT.INFO:检索有关搜索索引的信息,包括统计信息、配置设置和架构详细信息。
- FT.DROPINDEX:删除搜索索引,删除所有文档和关联数据。
下面的示例演示了如何在 Go 应用程序中使用各种 RediSearch 命令。请注意redisearch-go客户端的用法 。
package main
import (
"fmt"
"math/rand"
"strconv"
"github.com/RediSearch/redisearch-go/redisearch"
"github.com/gomodule/redigo/redis"
)
var pool *redis.Pool
var client *redisearch.Client
var cities = []string{"new york", "london", "paris"}
func init() {
pool = &redis.Pool{Dial: func() (redis.Conn, error) {
return redis.Dial("tcp", "localhost:6379")
}}
client = redisearch.NewClientFromPool(pool, "user-index")
}
func main() {
schema := redisearch.NewSchema(redisearch.DefaultOptions).
AddField(redisearch.NewTextFieldOptions("name", redisearch.TextFieldOptions{})).
AddField(redisearch.NewTextFieldOptions("city", redisearch.TextFieldOptions{}))
indexDefinition := redisearch.NewIndexDefinition().AddPrefix("user:")
client.CreateIndexWithIndexDefinition(schema, indexDefinition)
fmt.Println("redisearch index created")
conn := pool.Get()
for i := 1; i <= 10; i++ {
hashName := "user:" + strconv.Itoa(i)
val := redis.Args{hashName}.AddFlat(map[string]string{"user_id": strconv.Itoa(i), "city": cities[rand.Intn(len(cities))]})
conn.Do("HSET", val...)
fmt.Println("created hash -", hashName)
}
docs, total, _ := client.Search(redisearch.NewQuery("*"))
fmt.Println("no. of indexed documents =", total)
docs, total, _ = client.Search(redisearch.NewQuery("@city:(paris|london)"))
fmt.Println("found", total, "users in london or paris")
for _, doc := range docs {
fmt.Println("document ID -", doc.Id)
fmt.Println("document attributes -", doc.Properties)
}
err := client.DeleteDocument("user:1")
if err != nil {
fmt.Println("failed to delete document (hash) user:1", err)
}
fmt.Println("deleted document (hash) user:1")
_, total, _ = client.Search(redisearch.NewQuery("*"))
fmt.Println("no. of indexed documents =", total)
err = client.DropIndex(true)
if err != nil {
fmt.Println("failed to drop index", err)
}
fmt.Println("dropped index and documents")
_, total, _ = client.Search(redisearch.NewQuery("*"))
fmt.Println("no. of indexed documents =", total)
}
要运行上述代码,请将其复制到名为的文件中 main.go 并执行以下命令:
go get github.com/RediSearch/redisearch-go/redisearch
go get github.com/gomodule/redigo/redis
go run main.go
我们使用 Hash 作为文档,但 RediSearch 也可以使用 RedisJSON。当添加或删除文档时,索引会自动更新。本示例演示了一些简单的操作,包括获取所有文档,以及通过城市属性上的 ORclause 进行过滤,以获取居住在 "伦敦 "或 "巴黎 "的用户。
Redis时间序列
在 Redis 中处理大量时间序列数据时,有一些常用的技术。这些涉及将数据存储在 Redis 排序集中,其中分数表示时间戳,成员表示数据值。另一种方法是使用带有时间戳的字符串键作为键名称的一部分。每个键值对代表时间序列中的一个特定数据点。
然而,这些技术在处理大量时间序列数据时存在一些局限性。传统的 Redis 数据结构(如字符串键或排序集)的查询能力有限,并且难以执行复杂的聚合。此外,在处理大型数据集时,将每个数据点存储为单独的键值对可能会消耗大量内存,这通常是时间序列的情况。
RedisTimeSeries模块是原生的时序数据结构,为时序数据提供高效的存储和查询能力。它添加了查询功能,例如检索某个时间范围内的数据、执行聚合(例如求和、计数、平均值)、下采样和插值。它还允许我们定义自动过期或缩减数据采样的保留策略,从而实现高效的数据保留并降低存储要求。RedisTimeSeries 还与生态系统中的其他工具集成,例如 Prometheus 和 Grafana。
RedisTimeSeries 提供了丰富的命令集。以下是一些最常用的:
- TS.CREATE:使用指定的键、标签和保留策略创建新的时间序列。
- TS.ADD:将新数据点添加到时间序列,并将其与时间戳和值相关联。
- TS.RANGE:从指定时间范围内的时间序列中检索一系列数据点。
- TS.MRANGE:检索指定时间范围内多个时间序列的数据点。
- TS.GET:从时间序列中检索最新的数据点。
- TS.MGET:从多个时间序列中检索最新的数据点。
- TS.INCRBY:在特定时间戳处增加时间序列中数据点的值。
- TS.DECRBY:在特定时间戳处减少时间序列中数据点的值。
- TS.INFO:检索有关时间序列的元数据信息,例如样本数量、内存使用情况和保留策略。
- TS.QUERYINDEX:对时间序列执行基于索引的查询,根据指定的过滤器和聚合检索数据点。
下面的示例演示了如何在 Go 应用程序中使用各种 RedisTimeSeries 命令。请注意,我们使用的是 redistimeseries-go 客户端。
package main
import (
"fmt"
"log"
"math/rand"
"time"
redistimeseries "github.com/RedisTimeSeries/redistimeseries-go"
)
const tsName = "temperature:living_room"
func main() {
client := redistimeseries.NewClient("localhost:6379", "", nil)
// TS.CREATE
err := client.CreateKeyWithOptions(tsName, redistimeseries.DefaultCreateOptions)
if err != nil {
log.Fatal(err)
}
fmt.Println("created time series key", tsName)
tempOptions := []float64{24, 24.5, 25}
var storedTS []int64
for i := 1; i <= 10; i++ {
// TS.ADD
res, err := client.AddAutoTs(tsName, tempOptions[(rand.Intn(len(tempOptions)))])
storedTS = append(storedTS, res)
if err != nil {
log.Fatal(err)
}
time.Sleep(1 * time.Millisecond)
}
fmt.Println("added time series data")
// TS.GET
lastDataPoint, err := client.Get(tsName)
if err != nil {
log.Fatal(err)
}
fmt.Printf("lastest data point - timestamp: %v, temp: %v\n", lastDataPoint.Timestamp, lastDataPoint.Value)
// TS.RANGE
dataPoints, err := client.RangeWithOptions(tsName, storedTS[0], storedTS[len(storedTS)-1], redistimeseries.DefaultRangeOptions)
if err != nil {
log.Fatal(err)
}
fmt.Println("TS.RANGE result")
for _, dp := range dataPoints {
fmt.Printf("timestamp: %v, temp: %v\n", dp.Timestamp, dp.Value)
}
}
要运行上述代码,请将其复制到名为的文件中 main.go 并执行以下命令:
go get github.com/RedisTimeSeries/redistimeseries-go
go run main.go
Redis 模块:最佳实践
本节介绍了一些在这些模块的实际部署中优化可扩展性和性能的最佳实践。
RedisJSON
- 优化 JSON 结构以实现高效访问:设计 JSON 结构时,请考虑应用程序的访问模式。尽可能展平 JSON 层次结构以避免深层嵌套。这使您可以有效地访问特定字段,而无需获取整个 JSON 文档。使用 RedisJSON 的路径表达式来检索或修改特定的 JSON 元素,而无需解析整个文档。
- 考虑内存管理和数据大小:RedisJSON 将 JSON 文档存储为 Redis 字符串。请记住,Redis 的最大字符串大小限制为 512 MB。如果您的 JSON 文档很大,请考虑将它们分成更小的部分或使用压缩。
- 您可以使用 RedisJSON 作为 RedisSearch 的索引:此集成使您能够高效地执行复杂的搜索操作并根据搜索条件检索 JSON 文档。
Redis搜索
- 仔细选择和优化搜索架构:设计搜索架构时,请考虑应用程序的特定搜索要求。定义需要可搜索的字段并选择适当的字段类型(例如, text、 numeric、 tag)。仔细分析数据并选择最相关的字段以包含在搜索索引中。避免包含不必要的字段,以最小化索引大小并优化搜索性能。
- 利用查询优化技术: RedisSearch 提供各种查询优化技术来提高搜索性能。利用查询过滤器来减少搜索空间并根据特定条件缩小结果范围。
- 此外,请考虑使用词干、同义词和其他特定于语言的分析器来提高搜索准确性。
Redis时间序列
- 选择最佳时间段:根据数据的频率和粒度选择适当的时间间隔。考虑存储空间和查询性能之间的权衡。较小的存储桶提供更详细的数据,但会导致更大的内存使用量。
- 利用查询优化技术:RedisSearch 提供各种查询优化技术来提高搜索性能。使用查询过滤器来减少搜索空间并缩小结果范围。
- 使用压缩和下采样:如果您有高频数据且内存资源有限,请考虑启用压缩和下采样配置。这有助于减少内存使用而不影响数据准确性。
https://www.jdon.com/69677.html
相关文章:

Redis模块的高级使用方式
Redis 模块是Redis的高级功能,允许我们实现特定的自定义数据类型。本质上,模块是一个动态库,可以在启动时或根据命令按需加载到 Redis 中 MODULE LOAD 。模块可以用多种语言编写,包括 C 和 Rust。 我们自己使用 Redis 模块实现新…...

Failed to restart network.service: Unit network.service not found.
执行systemctl restart network命令,报错Failed to restart network.service: Unit network.service not found. 执行 yum install network-scripts命令 再次执行,正常...

wiki.js一个开源知识库系统
1 什么是wiki wiki.js是一个开源Wiki应用程序,官网介绍为: A modern, lightweight and powerful wiki app built on NodeJS 访问Github:github 访问Wike:js.wiki 省流总结 开源知识库平台,和语雀有一样的功能&…...

关于Java抽象类和接口的总结和一点个人的看法
꒰˃͈꒵˂͈꒱ write in front ꒰˃͈꒵˂͈꒱ ʕ̯•͡˔•̯᷅ʔ大家好,我是xiaoxie.希望你看完之后,有不足之处请多多谅解,让我们一起共同进步૮₍❀ᴗ͈ . ᴗ͈ ა 本文由xiaoxieʕ̯•͡˔•̯᷅ʔ 原创 CSDN 如需转载还请通知˶⍤⃝˶个人主页&am…...

vue中ref的用法
vue中ref的用法 在项目中使用ref时有时候直接取值,有时候返回的却是一个数组,不知其中缘由,后查了一下ref用法,所以总结一下. 1.绑定在dom元素上时,用起来与id差不多,通过this.$refs来调用: <div id"passCarEchart" ref"passCarEch…...

【华为OD题库-012】模拟消息队列-Java
题目 让我们来模拟一个消息队列的运作,有一个发布者和若干消费者 ,发布者会在给定的时刻向消息队列发送消息。>若此时消息队列有消费者订阅,这个消息会被发送到订阅的消费者中优先级最高(输入中消费者按优先级升序排列)的一个。>若此时…...

Android修行手册 - 阴影效果的几种实现以及一些特别注意点
点击跳转专栏>Unity3D特效百例点击跳转专栏>案例项目实战源码点击跳转专栏>游戏脚本-辅助自动化点击跳转专栏>Android控件全解手册点击跳转专栏>Scratch编程案例点击跳转>软考全系列点击跳转>蓝桥系列点击跳转>ChatGPT和AIGC 👉关于作者 专…...
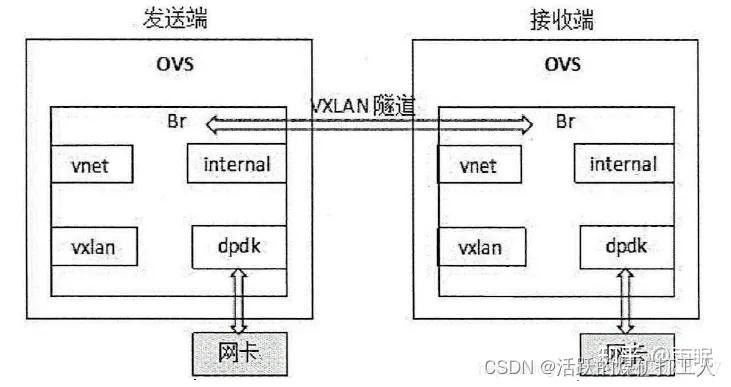
【星海出品】SDN neutron (五) openvswitch
1、ovs-vswitchd组件是交换机的主要模块,运行在用户态,其主要负责基本的转发逻辑、地址学习、外部物理端口绑定等。还可以运用OVS自带的ovs-ofctl工具采用openflow协议对交换机进行远程配置和管理。 2、ovsdb-server组件是存储OVS的网桥等配置、日志以及…...
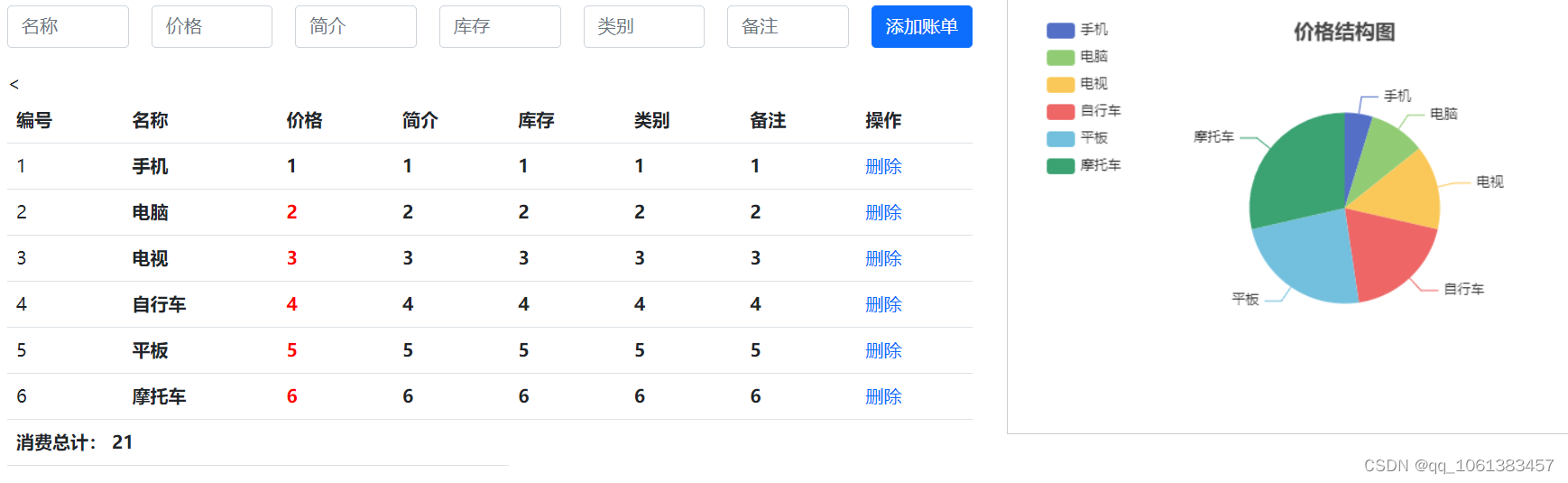
springboot整合vue2实现简单的新增删除,整合ECharts实现图表渲染
先看效果图: 1.后端接口 // 查询所有商品信息 // CrossOrigin(origins "*")RequestMapping("/list1")ResponseBodypublic List<Goodsinfo> list1(){List<Goodsinfo> list goodsService.list();return list;}// 删除 // …...

<蓝桥杯软件赛>零基础备赛20周--第5周--杂题-2
报名明年4月蓝桥杯软件赛的同学们,如果你是大一零基础,目前懵懂中,不知该怎么办,可以看看本博客系列:备赛20周合集 20周的完整安排请点击:20周计划 每周发1个博客,共20周(读者可以按…...
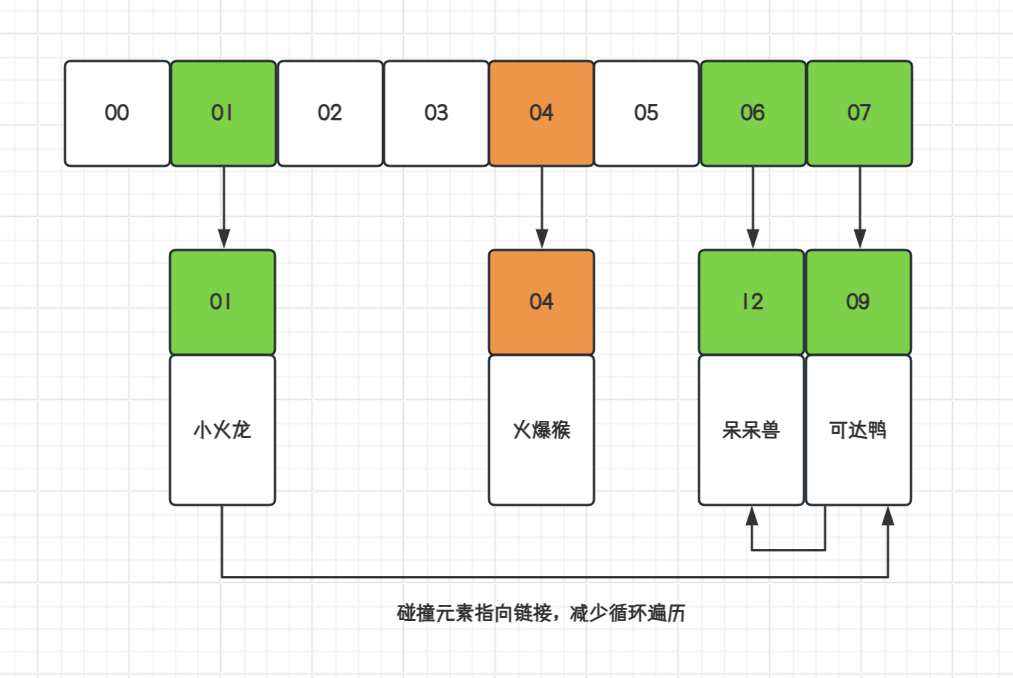
数据结构哈希表(散列)Hash,手写实现(图文推导)
目录 一、介绍 二、哈希数据结构 三、✍️实现哈希散列 1. 哈希碰撞💥 2. 拉链寻址⛓️ 3. 开放寻址⏩ 4. 合并散列 一、介绍 哈希表,也被称为散列表,是一种重要的数据结构。它通过将关键字映射到一个表中的位置来直接访问记录&#…...

【嵌入式设计】Main Memory:SPM 便签存储器 | 缓存锁定 | 读取 DRAM 内存 | DREM 猝发(Brust)
目录 0x00 便签存储器(Scratchpad memory) 0x01 缓存锁定(Cache lockdown) 0x02 读取 DRAM 内存 0x03 DREM Banking 0x04 DRAM 猝发(DRAM Burst) 0x00 便签存储器(Scratchpad memory&#…...
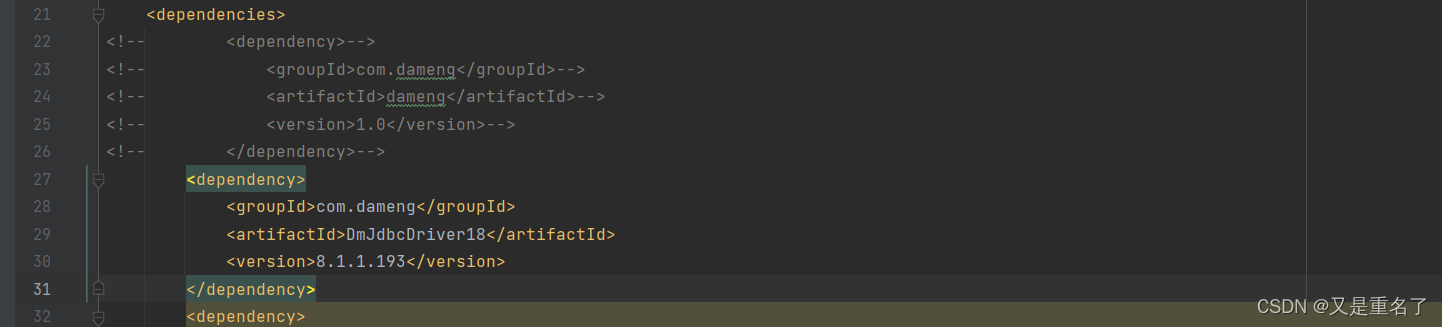
dameng数据库数据id decimal类型,精度丢失
问题处理 这一次也是精度丢失,但是问题呢还是不一样,这一次所有的id都被加一了,只有id字段被加一,还有的查询查出来封装成对象之后对象的id字段被减一了,数据库id字段使用的decimal(20,6)&…...
python图神经网络,注意力机制、Transformer模型、目标检测算法、强化学习等
近年来,伴随着以卷积神经网络(CNN)为代表的深度学习的快速发展,人工智能迈入了第三次发展浪潮,AI技术在各个领域中的应用越来越广泛 本文重点为:注意力机制、Transformer模型(BERT、GPT-1/2/3/…...
安装包 amd,amd64, arm,arm64 都有什么区别
现在的安装包也不省心,有各种版本都不知道怎么选。 根据你安装的环境配置。 amd: 32位X86 amd64: 64位X86 arm: 32位ARM arm64: 64位ARM amd64是X86架构的CPU,64位版。amd64又叫X86_64。主流的桌面PC&am…...
Ansible 企业实战详解
一、ansible简介1. ansible是什么2.ansible的特点ansible的架构图 二、ansible 任务执行1、ansible 任务执行模式2、ansible 执行流程3、ansible 命令执行过程 二 .Ansible安装部署1.yum安装2.ansible 程序结构3、ansible配置文件查找顺序4、ansible配置文件5.ansible自动化配置…...

云贝教育 |【技术文章】pg缓存插件介绍
一、pg_buffercache 主要作用是查看pg的共享池中缓存的对象信息 1.1 创建扩展 postgres# create extension pg_buffercache; CREATE EXTENSION 1.2 查看视图pg_buffercache postgres# \d pg_buffercacheView "public.pg_buffercache"Column | Type | Co…...

Kohana框架的安装及部署
Kohana框架的安装及部署 tipsKohana安装以及部署1、重要文件作用说明1.1 /index.php1.2 /application/bootstrap.php 2、项目结构3、路由配置3.1、隐藏项目入口的路由3.2、配置默认路由3.3、配置自定义的路由(Controller目录下的控制器)3.4、配置自定义的路由(Controller/direc…...

无重复字符的最长子串 Golang leecode_3
刚开始的思路,先不管效率,跑出来再说,然后再进行优化。然后就有了下面的暴力代码: func lengthOfLongestSubstring(s string) int {// count 用来记录当前最长子串长度var count int// flag 用来对下面两个 if 语句分流var flag …...
Vue项目的学习一
1、Vue项目里面的.js文件里面对象添加属性 例如:在对象:row,需要在对象row里面添加一个属性状态:type,使用里面的Vue.set函数 Vue.set(参数1,参数2,参数3) Vue.set(row,type,false)解析: 参数1࿱…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...

C++ vector容器总结
vector基本概念功能:vector数据结构和数组非常相似,也称为单端数组vector与普通数组区别:不同之处在于数组是静态空间,而vector可以动态扩展动态扩展:并不是在原空间之后续接新空间,而是找更大的内存空间&a…...
)
在线文档协作工具选型必看:14款产品对比(2026版)
一、在线文档协作工具的概念解析及其核心功能 在线文档协作工具是基于云端的文档创建、编辑、共享与协同沟通平台,核心目标是让团队在同一份资料上“实时共同工作”,减少反复传文件、版本混乱与沟通成本。 企业常见的核心能力包括: 多人实…...